
Создание таблицы 1с в sql
Драйвер ODBC для Visual FoxPro поддерживает для этой команды собственный синтаксис языка Visual FoxPro. Сведения, относящиеся к драйверу, см. в разделе Примечания к драйверам.
Синтаксис
Аргументы
CREATE TABLE | DBF TableName1
Указывает имя создаваемой таблицы. Параметры TABLE и DBF идентичны.
ИМЯ лонгтабленаме
Задает длинное имя для таблицы. Длинное имя таблицы может быть указано только в том случае, если база данных открыта, так как длинные имена таблиц хранятся в базах данных.
Длинные имена могут содержать до 128 символов и могут использоваться вместо коротких имен файлов в базе данных.
FREE
Указывает, что таблица не будет добавлена в открытую базу данных. FREE не требуется, если база данных не открыта.
(FieldName1 FieldType [( Нфиелдвидс [, нпреЦисион])]
Указывает имя поля, тип поля, ширину поля и точность поля (число десятичных разрядов) соответственно.
FieldType — это одна буква, указывающая тип данныхполя. Для некоторых типов данных полей требуется указать нфиелдвидс или нпреЦисион .
нфиелдвидс и нпреЦисион игнорируются для типов D, G, I, L, M, P, T и Y. нпреЦисион по умолчанию равен нулю (без десятичных знаков), если нпреЦисион не включена для типов B, F или N.
NULL
Допускает значения NULL в поле.
NOT NULL
Предотвращает значения NULL в поле.
Если опустить NULL и NOT NULL, текущее значение параметра SET NULL определяет, разрешены ли в поле значения NULL. Однако если опустить значение NULL, а не NULL и включить ключевое слово PRIMARY или UNIQUE, текущее значение параметра SET NULL игнорируется, а в поле по умолчанию устанавливается значение NOT NULL.
Проверка lExpression1
Задает правило проверки для поля. lExpression1 может быть определяемой пользователем функцией. При добавлении пустой записи проверяется правило проверки. Если правило проверки не допускает значения пустого поля в присоединенной записи, возникает ошибка.
EExpression1 по умолчанию
Задает значение по умолчанию для поля. Тип данных eExpression1 должен совпадать с типом данных поля.
PRIMARY KEY
Создает первичный индекс для поля. Первичный тег индекса имеет то же имя, что и поле.
UNIQUE
Создает индекс кандидата для поля. Имя тега индекса-кандидата совпадает с именем поля.
индексы кандидатов (созданные путем включения уникального параметра в CREATE TABLE или ALTER table-SQL) не совпадают с индексами, созданными с помощью параметра unique в команде INDEX. Индекс, созданный с помощью параметра UNIQUE в команде INDEX, допускает наличие повторяющихся ключей индекса. индексы кандидатов не допускают дублирования ключей индекса. Дополнительные сведения о параметре UNIQUE см. в разделе index .
Значения NULL и дублирующиеся записи не допускаются в поле, используемом для первичного или индекса-кандидата. Однако Visual FoxPro не выдаст ошибку, если вы создадите первичный или потенциальный индекс для поля, которое поддерживает значения NULL. Visual FoxPro выдаст ошибку, если вы попытаетесь ввести значение null или повторяющееся в поле, используемое для первичного или индекса-кандидата.
ССЫЛКИ на TableName2[Tag TagName1]
Указывает родительскую таблицу, для которой устанавливается постоянная связь. Если опустить тег TagName1, связь устанавливается с использованием первичного ключа индекса родительской таблицы. Если у родительской таблицы нет первичного индекса, Visual FoxPro выдает ошибку.
Включите тег TagName1 , чтобы установить связь на основе существующего тега индекса для родительской таблицы. Имена тегов индекса могут содержать до 10 символов.
Родительская таблица не может быть свободной таблицей.
нокптранс
Предотвращает перевод на другую кодовую страницу для полей со знаками и полями MEMO. Если таблица преобразуется в другую кодовую страницу, поля, для которых была указана НОКПТРАНС, не переводятся. НОКПТРАНС можно указать только для полей символов и MEMO.
В следующем примере создается таблица с именем MyTable, содержащая два поля символов и два поля MEMO. Второе поле символа, char2 и второе поле MEMO, memo2, включают НОКПТРАНС для предотвращения перевода.
Тег EEXPRESSION2 первичного ключа TagName2
Указывает первичный индекс для создания. eExpression2 указывает любое поле или сочетание полей в таблице. TAG TagName2 указывает имя создаваемого тега первичного индекса. Имена тегов индекса могут содержать до 10 символов.
Поскольку у таблицы может быть только один первичный индекс, это предложение нельзя включить, если первичный индекс для поля уже создан. Visual FoxPro выдает ошибку, если в CREATE TABLE включается более одного предложения ПЕРВИЧного ключа.
УНИКАЛЬНЫЙ тег eExpression3 TagName3
Создает индекс кандидата. eExpression3 указывает любое поле или сочетание полей в таблице. Однако если вы создали первичный индекс с одним из параметров ПЕРВИЧного ключа, то не можете включить поле, указанное для первичного индекса. TAG TagName3 указывает имя тега для создаваемого тега индекса-кандидата. Имена тегов индекса могут содержать до 10 символов.
Таблица может иметь несколько потенциальных индексов.
ВНЕШНИЙ ключ eExpression4 тег TagName4[нодуп]
Создает внешний (неосновной) индекс и устанавливает связь с родительской таблицей. eExpression4 указывает ключевое выражение для внешнего индекса, а TagName4 указывает имя создаваемого тега ключа внешнего индекса. Имена тегов индекса могут содержать до 10 символов. Включите НОДУП, чтобы создать потенциальный внешний индекс.
Можно создать несколько внешних индексов для таблицы, но выражения внешнего индекса должны указывать различные поля в таблице.
ССЫЛКИ на TableName3[Tag TagName5]
Указывает родительскую таблицу, для которой устанавливается постоянная связь. Включите тег TagName5 , чтобы установить связь на основе тега индекса для родительской таблицы. Имена тегов индекса могут содержать до 10 символов. По умолчанию, если опустить тег TagName5, связь устанавливается с использованием первичного ключа индекса родительской таблицы.
ИЗ массива ArrayName
Задает имя существующего массива, содержимое которого имеет имя, тип, точность и масштаб для каждого поля в таблице. Содержимое массива может быть определено с помощью функции афиелдс().
Комментарии
Новая таблица открывается в самой нижней доступной рабочей области и доступна по ее псевдониму. Новая таблица открывается исключительно независимо от текущего значения параметра SET EXCLUSIVE.
Если база данных открыта и предложение FREE не включено, Новая таблица добавляется в базу данных. Нельзя создать новую таблицу с тем же именем, что и таблица в базе данных.
если база данных открыта, CREATE TABLE SQL требует эксклюзивного использования базы данных. Чтобы открыть базу данных для монопольного использования, включите ЭКСКЛЮЗИВное использование в открытой базе данных.
Если при создании новой таблицы база данных не открыта, включая предложения NAME, CHECK, DEFAULT, FOREIGN KEY, PRIMARY KEY и REFERENCEs, выдает ошибку.
CREATE TABLE синтаксис использует запятые для разделения определенных параметров CREATE TABLE. Кроме того, в круглых скобках, содержащих определения столбцов, должны быть помещены значения NULL, NOT NULL, проверки, значения по умолчанию, ПЕРВИЧный ключ и уникальное выражение.
Примечания к драйверам
когда приложение отправляет инструкцию odbc SQL CREATE TABLE в источник данных, драйвер ODBC для visual FoxPro преобразует команду в команду visual фокспрокреате TABLE, используя синтаксис, приведенный в следующей таблице.
(тип данных «столбец-Идентификатор »
[,столбец-Идентификатор типа данных
При создании таблицы с помощью драйвера Драйвер закрывает таблицу сразу после создания, чтобы разрешить доступ к ней другим пользователям. Это отличается от Visual FoxPro, в результате чего таблица остается открытой только при создании. Однако если хранимая процедура в источнике данных, содержащая инструкцию CREATE TABLE, выполняется, то таблица остается открытой.
Если источником данных является база данных (DBC-файл), драйвер ODBC для Visual FoxPro создает таблицу с именем лонгтабленаме с тем же именем, что и имя базового-Table-name.
Использование языка описания данных (DDL)
Нельзя включить DDL в следующие места:
в инструкции пакетной SQL, для которой требуется транзакция
В режиме фиксации вручную после инструкции, которая потребовала транзакцию, если только приложение не вызывает SQLTransact.
В этот раз хотелось бы снова поговорить о прямых запросах к СУБД. Да, автор статьи слышал о том, что 1С крайне не рекомендует этим заниматься. Однако же заниматься этим мы будем с одной оговоркой – базы, с которыми предстоит поработать имеют отличное от 1С происхождение. Уже предчувствую возгласы – есть же «Внешние источники данных» в конфигурации, ими и пользуйтесь. Пользовались, умеем, однако же мнения публики об этом объекте конфигурации весьма противоречивы и многие из них далеко не восторженные. Основное преимущество их – понятная всякому, даже начинающему, программисту 1C методика работы с ними – либо аналогично объектам вроде документов и справочников, либо очень напоминающая непериодический независимый регистр сведений.
Вместе с тем есть и неприятные особенности. Прежде всего – отдельные типы данных «внешний источник» переваривает со скрипом. А чтобы положить в этот источник ссылку объекта в том виде, в каком она хранится в СУБД приходится указывать тип «Уникальный идентификатор», преобразовывать идентификаторы объектов в строки и заниматься перестановками групп символов. Случалось и так, что при указании строки подключения в пользовательском режиме ошибался, но вместо повторного запроса таковой просто получил бесконечные исключения при попытке обращения к нему.
В тоже время, для работы с иными базами данных «Внешний источник данных» нам совершенно не обязателен. Ведь научить 1C выполнять запросы к MS SQL или иной СУБД большой проблемы не составляет. Зато преимуществ получается сразу довольно много. Как ни крути, а СУБД – запросы как способ интеграции во многом выигрывают даже у WEB-сервисов, а у выгрузок/загрузок через файловую систему подавно.
Начнем с самого простого. Имеем стороннюю базу с полезными нам данными. Имеем 1С, которой эти данные полезны, но которая их не имеет. Как же их достать? В MS SQL отлаживаем запрос, на стороне 1С обеспечиваем формирование его текста с необходимыми условиями отбора и создаем пару функций, позволяющих подключиться к СУБД и получить из нее таблицу значений. Ну а дальше вопрос её обработки, зависящий от конкретной задачи и особенностей выбранного пути её решения.
В общем-то на этом вопрос получения данных из внешней базы закрывается. Но остается второй, куда более обширный вопрос – как же наоборот, выгрузить данные из 1С в базу данных на «чистом» SQL? Web-сервисы, COM-соединения и промежуточные файлы не рассматриваем ввиду тематики статьи, хотя они имеют место быть и часто даже оказываются уместными, про эти вещи и без меня написано достаточно. А в рамках данной статьи нам будут интересны именно пути, предполагающие прямое взаимодействие с SQL.
Способ 1. Очевидный (но не лучший).
Уверен, что это первое, что приходит в голову разработчику, по крайней мере не из касты 1С – вооружаемся SQL-профайлером, любой консолью запросов и любой обработкой, раскрывающей структуру хранения базы данных и готовим прямой запрос к данным 1С. Далее этот запрос размещается где-нибудь в недрах стороннего продукта и обеспечивает получение данных. Это в теории. На практике же кроме использования на уровне СУБД нумерованных имен вместо отражающих смысл хранимой информации вылезают «подводные камни», подробнее о которых можно посмотреть здесь. Но в любом случае на выходе имеем нечто подобное:
Из плюсов можно отметить разве что возможность передать эти задачи IT-специалистам из областей, отличных от 1С и в частности – занимающимся поддержкой целевой базы. Правда тут тоже есть свои ньюансы, т.к. радиус кривизны рук сильно варьируется не только среди 1С-ников, и на сервере с СУБД могут «завестись» интересные задания, гоняющие одни и те же данные через десяток таблиц и пытающиеся обработать миллионы строк из какого-нибудь регистра с себестоимостью в нашей 1С, а разобраться в них, не принимая участия в непосредственном создании окажется крайне затруднительно. Но не забывайте, что когда-нибудь могут попросить помочь с этим разобраться и Вас.
Способ 2. Удобный (хотя и не столь очевидный)
Мысль эта посещает не сразу, а когда посещает часто бывает уже поздновато, но все-таки: Если со стороны внешней базы не получается прочесть данные с нормальными именами полей, то почему бы не заставить 1С работать на запись? Реализация этого мероприятия несколько сложнее, чем чтения из внешней базы, тем не менее ничего сверхъестественного из себя не представляет. Прежде всего потребуется еще одна функция, которая будет выполнять SQL запросы, не предполагающие возврат какого-либо результата.
Далее обратим внимание на структуру данных, таблиц, в которые будем писать. Помимо целевых полей, нам потребуется ключ, позволяющий однозначно идентифицировать принадлежность строк данных во внешней базе объектам 1С. Иначе говоря, смотрим как 1С хранит ссылки объектов и добавляем во всякой таблице с выгружаемыми нами данными поля с аналогичным типом данных и размерностью, т.е. binary(16)
Определяемся предполагает ли наша разработка соответствие одному объекту базы 1С одной записи внешней таблицы (как пример – отражение записи справочника), или же записей может быть несколько (отражение или имитация движений документов или табличных частей объектов). Для второго случая добавляем поле с номерами строк.
Не обязательно, но полезно при разборе полетов – Дата и время фактической записи во внешнюю таблицу.


Осталось самое главное – обеспечить запись данных в SQL. Как именно это будет выполняться – в подписке при непосредственном изменении (записи) объекта в 1C, регламентным заданием по расписанию, или по требованию пользователя зависит только от контекста задачи и личных вкусов разработчика. Нам же важен сам механизм. В зависимости от наличия одной строки (идентифицируется Ссылкой однозначно) или группы строк (т.е. строка идентифицируется по Ссылке и автономеру строки) запись будет слегка отличаться.
Принцип работы таков:
- Обеспечиваем выборку и при необходимости программную обработку данных. Функциям в качестве основного аргумента подходит как результат запроса, так и таблица значений.
- Собираем параллельно два запроса в формате SQL, первый удаляет из внешней таблицы записи по значению ключевого поля, второй добавляет свежие. Не забываем, что длина неограниченной строки в реальной жизни ограничена и составляет в районе 200 000+ символов, после которых растет только значение, определяемое через СтрДлина(), но не сама строка. Данный факт сам собой задает нам размер объема данных, которые могут быть обработаны за одно обращение к SQL. После превышения предельной длины строки немедленно выполняем запросы и приступаем к формированию новых. Тем самым, обработка данных ведется блоками. Даже если бы нам очень не хотелось морочиться с её обеспечением, это пришлось бы сделать применительно к большинству практических задач.
- По завершении обхода еще раз выполняем запрос и записывает тем самым последнюю порцию данных.
Примеры обращения:
И, наконец проверяем результат:


С некоторых пор при экспорте данных из 1С на уровне SQL стараюсь работать только на запись. Проблем с быстродействием замечено не было. Затраты времени – минимальны, фактически процесс разработки сводится к написанию запроса. Думается, что и для поклонников каноничного объекта «Внешние источники данных» аналогичный инструмент может быть легко реализован, хотя и без гарантий отсутствия некоторых проблем с совместимостью и преобразованиями типов. Среди основных достоинств замечены:
Как быть программисту 1С, если для интеграции базы 1С: Предприятие 8.3 есть техническое задание со стороны разработчика внешней базы данных. Но самой базы данных нет ? А она уже нужна: для отладки выгрузки данных. В тех.задании коллегами описана структура таблиц внешней базы данных. Тогда Вам можно создать такую базу данных самостоятельно. С помощью скрипта для MS SQL.
Всё чаще возникают задачи для обмена со сторонними базами данных.
Для платформы 1С:Предприятие 8.3.12 вполне подходит механизм "Внешние источники данных".

Внешние Источники Данных в 1С: Предприятии могут иметь два типа : "Объектные" и "Необъектные"
Начнём с простого примера : "Объектные таблицы"
К таблицам "Объектного" типа относятся таблицы с первичным ключом, который состоит из одного поля.
В 1С: Предприятии такому типу таблиц соответствует объект типа "Справочник" у которого есть поле "Код" (длина поля "Код" больше нуля)

Если создать текст скрипта :
То при его выполнении в MS SQL Server Management Studio можем получить таблицы с полями :

Для создания в MS SQL таблицы, соответствующей регистру накопления, следует написать такой сценарий :

В результате мы получим таблицы :

При создании таблицы в MS SQL, соответствующей "шапке" документа, может быть создана "Объектная" таблица. Если первичный ключ "PRIMARY KEY" состоит из одного, уникального ключа. Как в этом случае :

Такой вариант был выбран разработчиком ТЗ : номер документа уникален для всей базы данных. В результате будут созданы таблицы :

Табличная часть будет создана в результате работы скрипта :

Из сценария получается, что номенклатура в табличной части используется без повторений. Таково пожелание разработчика ТЗ.
И созданная таблица будет иметь "Необъектный тип" :

Скрипты для MS SQL (Я использую : Версия 15.0.18183.0, "О программе SQL Server Management Studio") я создавал в конфигураторе 1С:Предприятия 8.3.12.1790. Внешние источники данных импортировал в конфигурацию ERP 2.4.6 на этом же релизе платформы.
Для работы примера в MS SQL следует создать пустую базу "MyFirstDataBaseFor1C" - так как скрипт (скачиваемый файл) работает с таким наименованием.
При подключении внешнего источника из MS SQL можно использовать название "srcFirstDataBase". Это по желанию. "src" - от слова Source (Источник)
Специальные предложения









Администратор базы данных (DataBase Administrator — DBA) — специалист, управляющий работой базы данных. Обычно обязанности DBA подразделяют на основные и дополнительные
Основные обязанности DBA :
Установка нового программного обеспечения. Установка новых версий Oracle, приложений и другого программного обеспечения, относящегося к администрированию СУБД. Предусматривает также обязательное тестирование устанавливаемых программ перед введением их в рабочую среду.
· Конфигурирование программного и аппаратного обеспечения. В большинстве случаев доступ к настройке программного и аппаратного обеспечения имеет только системный администратор, поэтому DBA должен производить установку программ, конфигурирование программного и аппаратного обеспечения только совместно с системным администратором.
· Обеспечение безопасности. Является одной из основных обязанностей DBA. Управление безопасностью и администрирование включают в себя: добавление и удаление пользователей, управление квотами, аудит и разрешение проблем безопасности.
· Настройка производительности. Даже хорошо настроенная система нуждается в постоянной проверке производительности и периодической ее перенастройке. Иногда для этого достаточно изменить параметры системы или индексы, а может быть, перестроить структуру таблиц.
· Резервное копирование и восстановление системы. Одна из главных обязанностей DBA — постоянно сохранять данные в системе. Чтобы делать это эффективно, необходимо разработать процедуру резервного копирования и стратегию восстановления данных. Очень важно периодически тестировать отработанную схему резервного копирования и восстановления данных.
· Процедура постоянного [планового) обслуживания. Обслуживание СУБД лучше всего производить рано утром либо по выходным дням, чтобы не нарушать работу пользователей. Обслуживание включает в себя: архивирование, тестирование и настройку системы. Администратор должен составить календарь планового обслуживания СУБД и довести его до сведения клиентов.
· Локализация неисправностей и восстановление системы после сбоя. Поскольку сбой системы приводит к возможности потери доступа пользователей к своим данным, DBA обязан как можно быстрее восстановить работу системы, т.е. он должен уметь предусмотреть сбой и заранее иметь план восстановления системы после сбоя.
Дополнительные обязанности DBA :
Сводятся, как правило, к оказанию помощи отдельным клиентам и могут включать в себя следующие задачи администрирования :
· Анализ данных. Проводится для того, чтобы дать отдельным разработчикам или пользователям рекомендации по повышению производительности или эффективности хранения данных.
· Предварительная разработка БД. Поскольку DBA знает систему «изнутри», он может на предварительной стадии разработки структуры БД указать команде разработчиков на потенциальные проблемы и помочь в увеличении производительности программ.
· Оказание консультаций разработчикам по хранимым SQL-процедурам. DBA довольно часто привлекается к разрешению проблем SQL-кода и разработке (написанию) хранимых процедур, т.е. он должен быть готов стать консультантом для разработчиков и пользователей.
· Разработка производственных стандартов и соглашений по именам. Это одна из основных организационных проблем управления. Поскольку в разработке и развертывании приложений могут принимать участие несколько различных групп, DBA должен принимать активное участие в решении проблемы их соответствия производственным стандартам и соглашениям по именам.
· Документирование среды. DBA должен документировать каждый аспект среды СУБД, включая конфигурирование оборудования, обновление и изменение программного обеспечения, вопросы, связанные с изменением системы и ее параметров, и уметь полностью восстановить ее по документации в случае необходимости.
· Планирование нагрузки системы и необходимого объема памяти. Неотъемлемой частью работы DBA является определение необходимости приобретения дополнительных серверов, дополнительной дисковой и оперативной памяти в целях удовлетворения возрастающих потребностей пользователей. Прогнозируя ожидаемую потребность аппаратных средств, администратор обеспечивает надежность работы информационной системы предприятия.
В данной статье пойдет речь о том как в 1С 8.1-8.2 можно использовать прямые запросы к СУБД MS SQL. Статья навеяна реальным внедрением. Я постарался описать общие моменты которые необходимо знать для того что бы спуститься на уровень СУБД и начать использовать прямые запросы к СУБД в обход 1С Сервера приложений.
Введение.
В одной из компаний где я когда-то работал, имелась собственная разработка на 1С 8.2 платформе.
Однажды мы пришли к понимаю что наша система работает не очень быстро. Оставалось понять в каком направлении двигаться, что бы оптимизировать работу системы. После долгих исследований и экспериментов, мы решили в серьез взяться за перенос некоторых операций на плечи СУБД, а именно на плечи MS SQL с помощью выполнения прямых запросов на стороне SQL Server, в обход сервера приложений 1С.
Тот случай был единственным где подобное решение было рациональным. Но те навыки что я получил в тот момент, с легкостью можно использовать для интеграций системы 1С с другими информационными системами.
Cтруктура базы данных 1С на уровне СУБД выглядит не совсем внятно.
Постараюсь описать что же из себя представляет эта структура. Описание будет не полное. Постараюсь описать лишь самое интересное и важное, из того что нужно понимать спускаясь на уровень СУБД.
Рассматриваем структуру хранения данных.
Каждый объект метаданных имеет определенный вид наименования таблиц. Например РегистрСведений начинается с "_InfoRg. ", далее идет номер (идентификатор/индекс) регистра. А вот таблички начинающиеся с _InfoRgChng это таблицы содержащие в себе регистрацию изменений в регистре. Перечислять в данной статье все префиксы я не буду. Это можно сделать с помощью средсв 1С. По мере необходимости.
Ещё интереснее у нас хранятся данные составных полей. Точнее те поля, которые могут примнимать разнотипные значения.
Допустим у нас есть поле. И оно может хранить в себе Строку, Дату, Число, ссылку на справочник клиентов, и ссылку на справочник сотрудников. В 1С мы видим одно единственное поле. На деле же такое поле в базе данных будет иметь ряд полей. Давайте рассмотрим этот пример. Предположим что индекс нашего поля - 8818.
| Наименование поля | Описание |
| _Fld8818_TYPE(binary(1)) | В данном поле хранится тип значения, который хранится в текущей записи. Тип представляет из себя индекс. Целое число. |
| _Fld8818_N(Numeric(x)) | Здесь будет храниться значение числа. Тип числа (разрядность и длинна равная x) будет зависеть от настроек в самом конфигураторе 1С |
| _Fld8818_T(datetime) | В данном поле будет храниться значение типа Дата и Время |
| _Fld8818_S(nvarchar(1024)) | В этом поле значение в виде строки. Причем длина строки зависит от настроек. |
| _Fld8818_RTRef(binary(4)) | В данном поле, при условии что в записи хранится ссылка, будет указан тип ссылки. То есть, на какую таблицу ссылается ссылка, справочник это или документ, что за документ или справочник. |
| _Fld8818_RRRef(binary(16)) | А это уже будет сама ссылка на конкретную запись, в конкретной таблице |
Если с простыми типами данных все ясно, то тип ссылки не так прост.
Наверняка вы зададите вопрос: Как можно определить тип ссылки? То есть, что означает индекс хранящийся в поле _Fld8818_RTRef?
Если мы переведем этот индекс из шестнадцатеричной системы счисления в десятичную, и затем посмотрим на список таблиц базы данных, то обязательно найдем таблицу, в имени которой содержится данный индекс. То есть мы можем по этому индексу получить таблицу, в которой содержится элемент, на который ссылается ссылка в нашем поле.
Зная индекс, мы можем найти необходимую таблицу простым запросом:
Где 1950 — искомый индекс.
Получаем структуру хранения средствами платформы 1С.
Остается вопрос, как нам определить, как некоторая таблица в конфигурации 1С, именуется на уровне СУБД, а так же, соответствие полей на уровне СУБД и конфигурации?
В этом нам поможет встроенная функция поставляемая вместе с платформой:
Данная функция возвращает структуру в которой мы можем по имени объекта в МетаДанных, получить имя объекта в базе данных. Точно так же в структуре содержаться и все поля объектов, и их наименования в базе данных. Но здесь уже начинаются подводные грабли. Которых вроде как и нет, и в тоже время они есть.
Важный момент. При вызове метода, обязательно нужно передать во второй параметр значение «Истина». Что это означает? Этот параметр означает будет ли структура отображать данные в формате 1С: Предприятие, либо в формате СУБД. В чем же разница?
Допустим мы отображаем данные в формате 1С: Предприятие.
Например, если мы попытаемся с помощью этой структуры узнать как называется в базе данных поле «Клиент», то получим к примеру такое имя «Fld1234». Вроде бы все хорошо. Но если мы попытаемся написать запрос к MS SQL:
Мы в 80% случаев — получим ошибку. Почему? А потому что это лишь общий вид наименования поля. Но стоит знать о том что во первых любое имя поля начинается с нижнего подчеркивания. Казалось бы прибавим к наименованию поля символ "_" и делов то! Но нет. Далее ещё интересней. В зависимости от содержимого поля и его типа, поле имеет определенный постфикс в наименовании. Например RRef — это значит что в поле содержится ссылка. А если просто значение то этого постфикса нет. А помните составные типы данных? Там вообще может быть куча различных постфиксов, при этом полей начинающихся на "_Fld1234" будет гораздо больше чем одно. И как же нам обойти это?
Легко. Те кто знает MS SQL, сразу догадались что на помощь придет системное представление INFORMATION_SCHEMA.COLUMNS
С помощью этого представления мы можем отобрать информацию по наименованию таблицы, и по тому ключевому наименованию поля.
Пример запроса:
Данный запрос выдаст нам ряд полей, имена которых начинаются на "_Fld1234". Нам же останется эти данные обработать в нашей программе для использования в запросах к базе.
Но какие минусы у этого метода? Во первых для того что бы обратиться к базе, нам необходимо настроенное подключение к БД, через 1С. То есть дополнительные настройки. Но они нам в любом случае пригодятся, но представьте, у вас большой запрос. Нужно получить имена 20 полей. И каждый раз при этом обращаться к базе и искать там имена полей? Получать и использовать подключение? Это не очень оптимально. Плюс к тому полученные из базы данные, придется ещё как-то обрабатывать. Дополнительные действия. Да и словом - изобретение велосипеда.
Вот тут то нам и приходит на помощь функция
Когда значение параметра ИменаБазыДанных = Истина, то функция в результирующую структуру сразу передает всю необходимую информацию по объектам. Включая все физические поля Базы данных. Если поле составное, то в структуре будут видны все физические поля составного поля. Это значительно облегчает нашу работу.
Использование прямых запросов. Отборы. Соединения и обращения через точку.
Как же нам использовать отбор в прямых запросах? Как отобрать данные по конкретному документу? Или по конкретному значению?
Все довольно просто, но снова есть нюансы.
Поля формата Дата. По умолчанию при использовании MS SQL сервера, дата 1С в базу помещается с прибавлением к году 2000. То есть дата в системе 1С «01.01.2013» будет выглядеть как «01.01.4013». Но и это ещё не все. Для того что бы в запросе произвести сравнение даты и оно прошло корректно, нам необходимо дату конвертировать в определенный формат.
По умолчанию в базе данных MSSQL используется формат ymd. Это означает что в дате сперва указан год, месяц и затем число. А выглядит дата следующим образом: 4013-01-01. Для использования в условиях сравнения или для прочих манипуляций нам эту дату нужно обрамлять в опострофы, так же как и строки.
Для преобразования даты в формат SQL я написал для себя такую простенькую функцию:
Данная функция возвращает готовую дату, в нужном формате в виде строки, остается только подставить в текст запроса. Если у вас в MS SQL по каким то причинам установлен иной формат даты, можно на момент исполнения запроса его поменять. Делается это так:
Либо надо будет переделать представление даты в своем запросе.
Теперь нам нужно отобрать записи по определенному элементу справочника. Как это сделать?
Изначально, когда я не знал о существовании функции ЗначениеВСтрокуВнутр(), для своих нужно я написал пару функций, для получения ссылок на справочники и на документы. Выглядят они так:
Как видно в коде, мы строим простой запрос, и получаем из базы значение ID, которое храниться в базе данных. Объект — это у нас наименование справочника либо документа, а код — код элемента справочника или документа.
Функция master.dbo.fn_varbintohexstr() — позволяет преобразовать значение формата binary в строку.
Но использовать эту функцию — не обазательно.
Полученный ID имеет примерно такой вид: 0xa8ed00221591466911e17da9fd549878
В запросе мы его можем сравнивать как строку
Но в таком случае запрос будет отрабатывать дольше. Так как на преобразование в строку тоже нужно время.
Поэтому лучше сравнение делать таким образом:
Предыдущий вариант использовать можно, но на самом деле, имеется более универсальный и оптимальный способ получить ссылку. Он приведен в функции что показана ниже:
А давайте представим что нам нужно в запросе сделать внутреннее соединение. И сравнение должно происходить с полем через точку?
То есть, для сравнения нам необходимо проверять одно условие, что дата в основной таблице, равна дате, которая содержится в документе, ссылка на который содержится в присоединяемой таблице.
В 1С это будет выглядеть примерно так
Как же описать это с помощью MS SQL? В том месте запроса, где описываются соединения, компилятор запросов ещё не знает о том что в таблице регистра есть ссылка на регистратор, и что это в свою очередь есть документ, а у этого документа есть дата. Описать ещё одно соединение? Не поможет. Словом я пытался это сделать всяко. Но в итоге решение свелось к вложенному запросу. (если кто-то найдет реальную альтернативу, буду рад узнать ваш способ).
Выше приведенный фрагмент на чистом SQL будет выглядить так:
В запросе мы видим, что во вложенном запросе делаем выборку из таблицы документа, где ID документа равен ID который записан в поле нашей таблицы «Источник», и далее полученное значение _Date_Time сравниваем с датой из нашей таблицы. Все логично и просто. Думаю теперь мы понимаем, во что превращаются наши обращения к полям и объектам через точку, в запросах 1С, когда они транслируются на SQL запрос. И теперь становится понятно почему такие обращения затормаживают работу запросов.
Очень рекомендую вам поэксперементировать с различными запросами, используя инструмент SQL Server Profiler. С его помощью вы сможете увидеть, во что превращаются ваши запросы написанные на языке запросов 1С, пройдя трансляцию на сервере приложений 1С. Особенно интересно вам будет посмотреть что из себя представляют такие виртуальные таблицы как "СрезПоследних".
Тот пример который я описал выше, с внутренним соединеним, 1С сервер скорее всего реализует немного по другому. Но у него свои методы, с использованием переменных, значения которых заполняются серверов приложений перед выполнением запроса.
Ниже я приведу один пример.
Допустим у нас есть запрос в формате 1С:
Как мы видим, ситуация аналогичная, как я приводил выше, только соединение не внутреннее, а левое. Как же 1С Сервер приложений траслирует такой запрос?
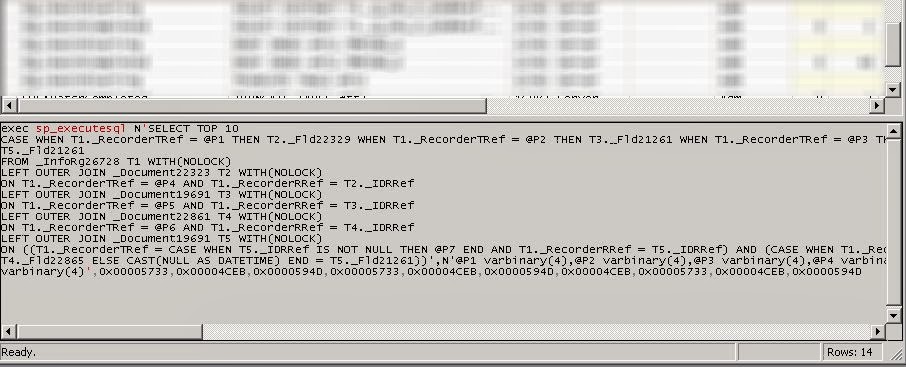
С помощью SQL Server Profiler мы сможем это увидеть. На картинке выше, показан запрос сервера приложений. Как я и писал выше, мы видим что сервер приложений использует переменные, в которые заранее пишет соответствующие ID. Но нам при использовании прямых запросов, проще было использовать именно вложенный запрос, для нас это универсальное решение, так как не придется подставлять значения переменным.
Будет замечательно если вы самостоятельно изучите различные запросы в таком виде. Возможно это поможет вам оптимизировать ваши запросы.
Для решения каких задач нам могут понадобиться прямые запросы к базе данных?
Думаю данная возможность понадобиться при активной разработки своих собственных решений, либо при реструктуризации готовых решений. В тех случаях, когда в отладочных целях, либо ещё по каким-то причинам, нам придётся переносить большие объемы данных с одной таблицы в другую, либо разбивать данные на несколько таблиц.
Для интеграции 1С с другими, сторонними разработками. Например вывод данных из 1С в какую-нибудь стороннюю программу анализа продаж или что-то похожее.
Оптимизация массивных обработок данных. Когда нам необходимо обработать большое количество данных, при этом внося какие-то изменения, корректировки и т.п. Например копирование записей регистра сведений с изменением какого-либо поля средствами 1С, займет куда больше времени, чем выполнение операции T-SQL Update
Учимся получать доступ к СУБД из 1С.
Для работы с СУБД на прямую, в обход сервера приложений 1С, нам потребуется использовать COM объекты - ADO.
Первым делом нам понадобится строка подключения к базе данных. У нас даже есть возможность формировать эту строку через стандартный интерфейс Windows. Это значительно облегчает процесс подключения к БД.
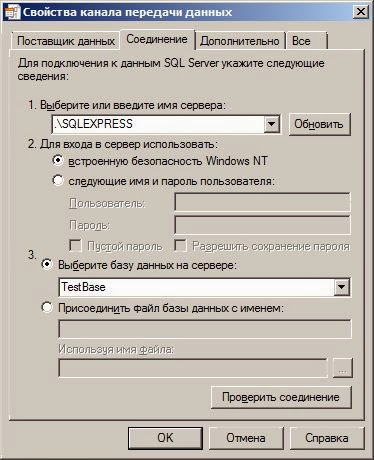
Интерфейс настройки подключения к базе данных.
Давайте рассмотрим пример работы с ADO.
В данном фрагменте кода, мы создаем объект подключения к базе данных. А так же с помощью объекта DataLinks, получаем строку подключения к базе данных используя пользовательский интерфейс настройки этого самого подключения.
После того как мы получим строку подключения, нам скорее всего захочется отдельные её части разместить на форме, для того что бы пользователь мог исправлять отдельно взятые опции подключения. Следовательно строку необходимо распарсить. Я пока (на момент написания статьи) нашел лишь один способ это сделать, и привожу его ниже. Если кто-то подскажет более элегантный способ парсинга строк, будет здорово.
Теперь мы сохранили параметры подключения базы данных на форме, при желании можем их сохранить в базу данных.
Далее надо предусмотреть вариант, когда пользователь (чаще всего мы сами), изменит наименование базы данных или тайм аут прямо в форме обработки, минуя форму редактирования строки подключения. На такой случай создадим такую функцию, которая будет формировать строку подключения собирая данные из визуальных контролов формы. Выглядит она примерно так:
Теперь когда все (или почти все) вопросы со строкой подключения решены, давайте попытаемся воспользоваться ею, для обращения к базе данных.
В первую очередь, думаю нам понадобится функция для проверки подключения. Опишем её таким образом:
После выполнения данной функции нам станет ясно, можно ли работать дальше, или соединение с базой установить не удалось, и следовательно дальше что-либо делать с подключением — бесполезно. Кстати, для оптимизации функцию получения объекта ADODB.Connection можно разместить в общем модуле, в настройках которого выставлено «Повторное использование». Это позволит не создавать каждый раз новый объект подключения, а будет использоваться уже созданный объект. В теории это позволит сократить время вызова соединения, а так же совсем чуть-чуть сэкономит ресурсы системы.
Причем заметьте, что свойству ActiveConnection мы присваиваем ранее созданное подключение к базе. Теперь когда объект у нас создан, нам остается лишь воспользоваться им. Если нам необходимо просто выполнить запрос, который не вернет никаких результатов, то будет достаточно одной простой команды, которая показана ниже.
Если запустить эту обработку в первой и второй базе ( обе одной конфигурации УПП 1.3 (1.3.38.4)), то имеем для первой базы имя таблицы SQL = Reference131, для второй имя таблицы SQL = Reference162. Если смотреть структуру полей таблиц, то видим, что имена полей различны.
Вопрос: подтвердите или опровергните вывод: таблицы SQL создаются динамически и могут иметь различные имена (имена полей в том числе). При создании новой базы загрузкой конфигурации из *.cf –файла, получим таблицы новой базы с именами, отличными от имен таблиц базы, из которой был выгружен файл конфигурации *.cf .
cf это метаданные 1С к sql отношения не имеют. из того же cf можно вообще сделать файловую базу.
а вообще - проводлжайте наблюдать, вас столько открытий ждет
В базе1 добавили новый справочник, появилась таблица _Reference131.
В базе1 удалил справочник, таблица _Reference131 удалилась.
В базе1 добавили новый справочник, появилась таблица _Reference132
На базу2 накатили обновление из базы1. в базе2 появился справочник с таблицей _Reference131
но если загрузить в 2 разных базы чистых одинаковый Цф - то и структура с большой долей вероятности будет одинакова
>но если загрузить в 2 разных базы чистых одинаковый Цф - то и структура с большой долей вероятности будет одинакова
одинаковы будут id по которым происходит "быстрая" сверка. также это будет гарантировать что данные не отвалятся при нахлабучивании изменений одной конфы на другую через "загрузить"
(6) Ага. Следует заметить, что отсортированный по имени объектов cf-ник и такой же без сортировки скорее всего даст разные имена таблиц и полей, если, конечно, количество объектов метаданных в каждом типе больше 1 :)
Ребята. Всем СПАСИБО!!
НЕОБХОДИМО из SQL-таблиц получать информацию для другого программного продукта (НЕ 1С). получается, что надо создавать таблицу соответствий что ли, чтооб не изменять код при чтении данных 1С из таблиц в другом программном продукте(базу 1С планируем обновлять. ведь можно разными способами получить базу данных обновленную чистую для учета с нового года, например).
Кто-нибудь решал такую проблему? Может кто подскажет оптимальное решение.
(15) снабди своё 1С вебсервисом, который будет отдавать то , что надо, и ни чего лишнего. Иначе однажды утром 1С не заведется потому. что какой-то осел нечаянно сказал DROP DATABASE не в то окно
(15) Образение через com в 1с и получение структуры оттуда.
Но обычно более эффективным считается работа от обратного, когда 1с отдает в нужном виде.
(15) Другой продукт каждый раз при коннекте каким то образом инициирует ПолучитьСтруктуруХраненияБазыДанных(МассивИменМетаданных)
в конфиге и дальше работает через этот мапинг до конца коннекта.
Как реализовать вызов этой процедуры - уже технические формальности
Я создавал базу данных соответствий НазвваниеОбъекта- таблица SQL.так же с реквизитами. дальше запросом получал соответствие и формировал динамически запрос к базе данных. если менялось название какой либо таблицы или реквизита то я просто в базе соответствий менял значение. и запрос опять давал корректный результат. Это все делалось для сверки с 1С другой учетной системы
(21) это легко оспорить в суде и вертеть потом на вертеле. Другое дело, что это не разумно и не безопасно. Вот это уже вертеть чревато
(24) если данные только получать для отчетов и сверок- то это ничем не чревато. а вот если писать в базу то тут существует опасность.
(25) ему придется отдать насторону огин и пароль к кишкам, из которых получить можно что угодно и ни кто не знает, что потом будет по факту получаться и куда передаваться. Это все равно, что голую задницу в интернет выставить
Создай базу данных в которой будут вьюхи и процедуры(которые будут читать данный из рабочий базы)-как уже сказали зверя создать только на чтение.
я не рискнул вьюхи и процедуры создавать в рабочей базе. данные получал в другую базу во вьюхи.
(33) есть штатный безопасный механизм, дающий любой необходимый программный интерфейс к чему угодно. Вебсервисы. Надо научиться ими пользоваться, а не городить велосипеды с квадратными колесами.
все-таки, еще раз вопрос - что в 1С не хватает ? (38) + - изобретать велосипид, БД зависимый. Типа, круто, на asm ваять, а vb - отстой
(38) прямые (Ровные запросы, а не оптимизированные кривым оптимизатором 1С) запросы гораздо быстрее выполняются напрямую-если важна скорость
(34) Значит все средства интеграции, которые предлагает 1С штатно, мы вертели на вертеле? Или просто лень почитать?
(43) прямыми (Ровные запросы, а не оптимизированные кривым оптимизатором 1С) сделаешь базу кривой. В резюме, потом напиши, что сделал суперские оптимизированные запросы
(47) абсолютно не при чем. "За державу обидно".
Меня устраивает "оптимизатор запросов 1С", хоть и не фан. Как, говорилось на этом форуме не раз, готовить запросы надо уметь.
данные из 1С попадают в систему весовых терминалов. обрабатываются там. затем обратно в 1С. кто работает с весовым оборудованием. средства 1С дают хорошие возможности.
(51) Часть блокировок живет в памяти сервера. Сторонне приложение о них не в курсе.
(56) Например у тебя больше чем 1 кластер ( рабочих процессов) как ты их блокировать то будешь?
v8: Разделяемый или Исключительный режим блокировки
(55) в продолжение темы для "адептов":
Для чего надо делать так (0):
ускорить шибко тугой запрос на уровне СУБД, или, запудрить тех, кто будет это хозяйство разбирать
Для чего не надо делать так:
3. даются средства высокого уровня, зачем лезть в кору
4. потом, после реализатора "нетленки" долго нужно разбираться - из прямых запросов к БД, т.к. это уровень не бизнес-логики
(60)
запудрить тупых рисовальщиков формочек и отчётов
0 что значит бд зависимо? 1с примерно одинаково гененрирут названия полей для разных субд (всего 3 варианта)
2 с учетом оговорок смысла не имеет. тк практически любой объект бд- метаданных можно привести к состоянию требующему разрешённому и рекомендованному фирмой 1с вмешательству.
3. вот тут верно. тк 1с8 на риалтайм систему не тянет.
лучше через коннектор.
мне через саповский коннектор в 10 раз удобней было работать с САП
чем на прямую в скл сервер писать.
4. если делать через view с именами метаданных - то все равно.
(64) Рабочие процессы это реально разные процессы со всоей виртуальной памятью.
Другой кластер это другой компьютер а база у всех одна.
Так как ты будешь хранить эти блокировки? Неужто это будет эффективнее чем хранить блокировки в самой БД?
Меня интересует технический процесс.
(65) (66) Народ, желтые книжки почитайте, я с них цитирую. Конечно я в исходниках платформы не копался, но оснований не верить нет.
Блокировок БД бывает недостаточно, поэтому вводятся блокировки прикладного уровня. Сам не раз реализовывал, в других системах. Некоторые СУБД предоставляют механизмы для того, чтобы и прикладные блокировки жили в БД. Грубо говоря API к своему менеджеру блокировок. Но в случае 1С кроссплатформенность и кросс-СУБД диктует свои правила. Поэтому прикладные блокировки живут в памяти сервера 1С. Очевидно они не могут быть свои у каждого рабочего процесса, поэтому в памяти менеджера кластера.
И не путайте "рабочий процесс" и "кластер".
(69)
"желтые книжки почитайте" -
- какую главу. если Вы сами не использовали что-то
то к ЖК лучше не аппилировать, тк это 1с.
В ней заявленое может не работать, рабочее может быть не декларированным.
поэтому и интересно, можете ли Вы точнее чем общий отсыл к
ЖК или интернет подтвердить работу кластера с разными бд.
(70 >подтвердить работу кластера с разными бд.
Не понял
Главу постараюсь найти.
(38) Ты опоздал, вроде как веб сервисами пользоваться умеют уже все, а поднимать веб сервер дорогого стоит
(71) Нашел.
Клиент-серверный вариант. Руководство администратора. 2.1.3. Сервисы кластера
На ИТС тоже есть.
Мало того в 8 ке применяется оптимистическая блокировка. Управляемые блокировки используют хинты SERIALIZABLE,REPEATABLEREAD
Оптимистическая блокировка осуществляется на уровне поля ._Version v8: Кэши разные нужны, кэши нужные важны.
Пессимистическая на уровне блокировок в транзакции. Нет смысла городить огород там, где он не нужен. Но вот если будут реальные примеры объектных блокировок осообенно в контексте нескольких серверов приложений.
Правда, перечитал еще раз про упр. блокировки, и появилось сомнение в (50). Если они действительно держатся ТОЛЬКО до конца транзакции, то ЧИТАТЬ извне вроде можно. Но не уверен до конца.
(76) Так и объектные блокировки имеют смысл без транзакции.
Управляемые блокировки только на уровне транзакции и на уровне БД. Не управляемы это уже уровень изоляции REPEATABLE READ. Но тогда и на уровне блокировок запросов нет смысла в объектных блокировках для клиент сервера. Для Локальных баз на уровне LockFile
(78) Давай прежде всего не путать объектные блокировки и управляемые. Первые с танзакциями не связаны, они чисто прикладные.
Вот про это я и говорю зачем мешать объектные блокировки и транзакционными блокировками бд. Объектные блокировки так или иначе не взаимодействуют с блокировками БД. Тогда какой в них смысл? Управляемые блокировки это блокировки БД в режиме изоляции Read Commited с помощью хинтов SERIALIZABLE,REPEATABLEREAD. Автоматические это уже на уровне Изоляции REPEATABLE READ.
(81) Давай ты прочитаешь (82), с терминологией и общей концепцией все устаканится, потом продолжим.
Правда, там в тексте упоминается 8.1, кое-что могло и устареть.
(81) > Управляемые блокировки это блокировки БД в режиме изоляции Read Commited с помощью хинтов SERIALIZABLE,REPEATABLEREAD.
Это неправда, при наложении управляемой блокировки никакие блокировки в БД не накладываются.
(84)
раньше
(до 14 релиза)
накладывались блокировки субд.
сейчас может исправили.
ух разошлись про блокировки. Ну и что, выяснили что нибудь? Если, выяснили, то через несколько релизов платформы 1С забудьте. Вам же ясно говорят, нечё лезть куда ни надо
(88) Внутри одного из менеджеров кластера (процесс) запускается служба (в терминах 1С) транзакционных блокировок, конечно, это маршалинг, но если рабочих процессов больше одного, то без этого управляемые блокировки не организовать. Если рабочий процесс один то в предыдущих версиях этот механизм блокировок размещался в рабочем процессе, с тех пор рекомендация, на х64 запускать один рабочий процесс, если нет веских причин поступить по-другому.
(88) Так и сказано управляемые блокировки используют Read Commited (или Snapshot Isolation в 8.3), а блокировки в разрезе объектов 1С держит менеджер блокировок.
(89) Так это и есть официально объяснение лицензионного запрета, вы там наулучшаете, а мы в свою очередь всё переделаем внутри в новой версии и в неё уже автоматом ничего не сконвертируется при обновлении, и могут обвинить в этом не улучшателя, а производителя.
(90) Объясни зачем городить огород если все это можно решить на уровне БД, для рабочих процессов больше 1?
Могут быть кластеры на нескольких серверах. Где выигрыш если рабочих процессов больше чем 1?
(91) Зачем в запрсах применять хинты
FROM _AccRg5523 T3 WITH(SERIALIZABLE)
LEFT OUTER JOIN _Acc6_ExtDim5518 T4 WITH(REPEATABLEREAD)
(91) Глупо изобретать велосипед, там где он уже эффективно работает. Snapshot Isolation хорорша при чтении данных снимка данных до начала транзакции. Если же ты хочешь, что бы данные не изменялись до конца транзакции нужно накладывать блокировки явно.
(92) Например, надо заблокировать одно значение субконто в регистре бухгалтерии по всем счетам, предложи как это сделать блокировками на уровне СУБД.
Менеджер блокировок просто запишет в своих структурах: Пространство блокировок (РБ.Хозрасчетный), Субконто, Его значение. И будет держать его до конца транзакции.
Всё дело в том, что, именно, сервер 1С хранит в себе бизнес модель на предметном уровне. Например, меня огорчает, что журнал регистрации не хранится в БД, но у производителя свои взгляды на продукт.
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
go
SELECT spid, blocked FROM master..sysprocesses WHERE blocked > 0 AND lastwaittype LIKE 'LCK_%'
go
BEGIN TRANSACTION
go
(93) .1 это точно управляемый режим новых версий 8.2?
.2 так это ради Оракла, который версионник, а не блокировочник как MS SQL, поэтому все блокировки они решили делать сами с учётом внутренней природы бизнес объектов (справочники, документы и тд.) и не объектов (регистры). А работать должно везде одинаково!
(96) Для автоматического режима хинт REPEATABLEREAD не имеет смысла.
(97) Для Оракла есть FOR UPDATE и DBMS_LOCK. Но не являюсь хоть каким то знатоком Оракула.
Блокировки могут быть еще в режиме 4 (разделяемая блокировка таблицы share mode, генерируется, например, оператором lock table in share mode) и 5 (разделяемая блокировка таблицы и монопольная блокировка строк share row exclusive; генерируется, например, оператором lock table in share row exclusive mode). Но эти режимы встречаются крайне редко.
Читайте также: