
Создание имитационной модели в эксель
Моделирование — это изучение какого-либо явления, процесса или системы объектов посредством формирования и исследования их моделей.
Введение
В системах, связанных с экономикой, руководящим работникам необходимо постоянно принимать решения следующих категорий:
- Стратегические решения.
- Тактические решения.
- Оперативные решения.
Если принимаемые решения обладают низким интеллектуальным уровнем, то простота представления реальных ситуаций обычно ведёт к неточностям при выработке прогнозов, а, кроме того, к убыткам и добавочным финансовым потерям. Чтобы избежать возникновения подобных ситуаций и обеспечить устойчивое экономическое положение, существуют разнообразные системы поддержки выработки решений, усовершенствование которых превращается в наиболее актуальную проблему при наличии жёсткой конкуренции.
Существенным условием для таких программ считается возможность имитации вырабатываемых решений, апробации вероятных коррекций в экономической системе, появляющихся в результате влияния разных факторов, то есть нахождение ответа на вопрос типа, «что случится, если…». Это позволит существенно сократить риски от осуществления решений и сэкономить ресурсы, чтобы достичь поставленной цели.
Такие возможности предоставляют имитационные модели, которые обладают следующим набором качеств:
- Возможность регулировать уровень сложности модели.
- Присутствие случайных факторов.
- Возможность описать процесс, развивающийся по времени.
- Обязательное использование электронной вычислительной машины.
Имитационные модели предназначаются для того, чтобы оценить варианты намечаемых коррекций, обладать игровой формой для обучения работников, визуально отобразить работу исследуемого объекта во времени и так далее. Реализовать модели можно при помощи универсальных языков программирования, к примеру,Pascal, Basic, пакетов прикладных программ, таких как,Excel, MathCAD, и так далее. Выбор конкретного метода моделирования определяется сложностью задачи, наличием необходимых ресурсов и так далее.
Готовые работы на аналогичную тему
Однако имитационное моделирование применяется экономистами и другими специалистами только в малом проценте случаев, в которых можно было бы при помощи моделей поиметь важную для выработки решений информацию.Причина этого явления кроется в отсутствии инструкций по проведению имитационного моделирования при помощи общеизвестного и доступного инструментария, а именно, пакетов прикладного программного обеспечения, такого как Excel и MathCAD, которые могут обеспечить простую платформу для моделирования.Поэтому примеры формирования имитационных моделей при помощи, например, приложения Excel, помогают их широкому распространению в кругу работников, не владеющих языками моделирования и методиками, имеющимися в средах моделирования.
Электронные таблицы Excel как инструмент формирования имитационных моделей
Имитационное моделирование при помощи табличного процессора является отдельным направлением, имеющем свои особенности. Применение таких систем позволяет лучше понять происходящие процессы, в сравнении с использованием специализированных программ, обладающих высокой стоимостью и требующих много времени для их освоения, а также не позволяющих увидеть применяемые механизмы. Например, специалисты полагают, что имитация при помощи таблиц Excel позволяет лучше представить работу систем массового обслуживания, чем даже теория очередей, а также помогает в развитии интуиции, предоставляет даже не знающим программирования пользователям опыт формирования разных моделей. Специалисты предлагают следующие этапы обучения моделированию в Excel:
- Базовые понятия.
- Введение в теорию вероятности и статистику.
- Процесс имитационного моделирования в ручном режиме.
- Имитационное моделирование при помощи электронных таблиц.
- Генерирование случайных чисел.
- Осуществление анализа исходных данных.
- Осуществление анализа итогов моделирования.
При формировании моделей в Excelприменяются следующие главные подходы к осуществлению имитации:
- Подход, который ориентирован на события.
- Подход, имеющий ориентацию на процессы.
- Подход, направленный на сканирование активностей.
Первый подход служит для описания изменений в системе, которые происходят при совершении любого случайного события, например, получение заявки, завершение обслуживания. При его формировании при помощи электронных таблиц обычно применяется одна строчка для каждого события.
Если используется подход, ориентированный на процесс, то выполняется моделирование очерёдности событий для каждой заявки, и чтобы его реализовать, применяется одна строчка для каждого требования (используется при моделировании систем массового обслуживания).
Сканирование активностей состоит в описании действий, возникающих в системе за фиксированный временной интервал (день, неделя, месяц, год), и при его осуществлении, как правило, применяется одна строчка для каждого отрезка времени. К примеру, это может быть моделирование системы управления запасами.
Использование программного пакета MSExcelобладает следующими преимуществами:
- В составе пакета Excelесть значительное число встроенных функций из области математики, статистики и других областей, включая возможность генерации случайных значений.
- Excelдаёт возможность сохранять информацию и иметь к ней доступ.
- Программный пакетExcelпозволяет строить графики и диаграммы.
- Программный пакет Excel обладает встроенным языкомVBA (VisualBasicforApplication).
- Программный пакет Excelшироко распространён среди специалистов, то есть имеется на компьютере практически у всех.
- Наличие возможности экспорта информационных данных в иные программные приложения.
Помимо этих достоинств, возможен просмотр любой формулы, занесённой в ячейку таблицы, что увеличивает уровень доверия к итогам моделирования.

ИМИТАЦИОННАЯ МОДЕЛЬ – это логико-математическое описание объекта, которое может быть использовано для экспериментирования на компьютере в целях проектирования, анализа и оценки функционирования объекта.
Имитационная модель имеет определенную минимальную опорную структуру, которую пользователь может дополнить и расширить с учетом специфики решаемых задач и базовых методов обработки.

Отличие от математического моделирования
- имитационное моделированиеисследуетматематическиемоделив видеалгоритмов, воспроизводящих функционирование исследуемой системыпутемпоследовательноговыполнениябольшого количестваэлементарныхопераций.
- в имитационных моделях для получения необходимой информации или результатов необходимоосуществлять их «прогон»в отличие от аналитических моделей, которые необходимо «решать».
- имитационные моделинеспособны формироватьсвое собственноерешениев том виде, в каком это имеет место в аналитических моделях, а могут лишьслужитьв качествесредства для анализаповедения системы в условиях, которые определяются экспериментатором.

Имитационные модели
В общем виде структуру имитационной модели в математической форме можно представляет следующим образом: ,
где E – результат действия системы;
x i – переменные и параметры, которыми мы можем управлять;
y i – переменные и параметры, которыми мы управлять не можем;
f – функциональная зависимость между x i и y i , которая определяет величину E .

Имитационные модели
Имитационная модель представляет собой комбинацию таких составляющих, как:
- компоненты;
- переменные;
- параметры;
- функциональные зависимости;
- ограничения;
- целевые функции.
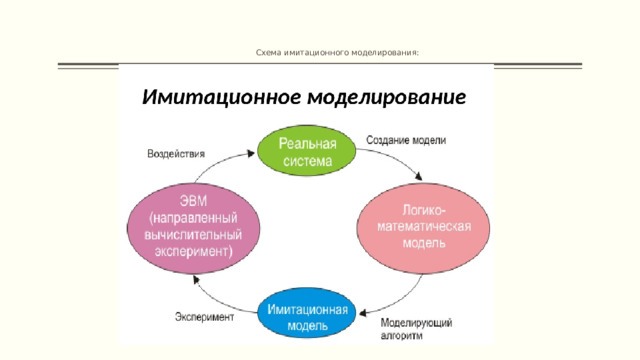
Схема имитационного моделирования:

НЕДОСТАТКИ ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ:
- разработка имитационных моделей требует больших затрат, времени и сил;
- любая имитационная модель сложной системы менее объективна, чем аналитическая модель;
- результаты имитационного моделирования носят как правило частный характер, поэтому для предоставления обоснованных выводов необходимо провести серии модельных экспериментов.

Пример имитационного моделирования на компьютере
Имитационная модель воспроизводит поведение сложной системы, элементы которой могут вести себя случайным образом. Иначе говоря, поведение которых заранее предсказать нельзя.

Модель – эволюция популяций
- Пусть на определенном пространстве случайным образом расселяются живые организмы.
- В дальнейшем происходит процесс смены поколений: в каких-то местах расселения жизнь сохраняется, в каких-то исчезает.
- Эти процессы протекают в соответствии с законами эволюции (формальными правилами).
Цель моделирования — проследить изменения в расселении живых организмов со сменой поколений.

Имитационные модели
Законы эволюции:
- В следующем поколении в пустой ячейке жизнь может либо появиться, либо нет.
- В живой ячейке жизнь может либо сохраниться, либо исчезнуть
- На состояние данной ячейки влияют ее ближайшие соседи: два соседа слева и два соседа справа.
- Если ячейка была живая, и число живых соседей не превышает двух, то в следующем поколении в этой ячейке жизнь сохранится, иначе жизнь исчезнет (погибнет от перенаселения).
- Если в ячейке жизни не было, но среди ее соседей есть 1, 2 или 3 живые ячейки, то в следующем поколении в этой ячейке появится жизнь. В противном случае ячейка останется пустой.

Модельное описание процесса эволюции популяции
- Распределение живых организмов по ячейкам будем кодировать последовательностью из нулей и единиц.
- Ноль обозначает пустую ячейку , единица — живую .
- Например, расселение, отображенное на рис. 4.3, кодируется следующим образом:

n - номер ячейки,
R (n) - значение двоичного числа, соответствующего этой ячейке в текущем поколении.
В рассматриваемом примере R (5) = R (8) = R (12) = 1 .
Все остальные значения ячеек равны нулю.
Значения кода в n -й ячейке для следующего поколения будем обозначать S ( n ) .
Проанализировав правила эволюции, приходим к следующей формуле:
Если 1 R ( n - 2) + R ( n - 1) + R ( n ) + R ( n + 1) + R ( n + 2) 3, то S ( n ) = 1, иначе S ( n ) = 0.

Эта формула работает для значений n от 3 до 18 .
Для ячеек с номерами 2 и 19 в данной сумме нужно убрать по одному слагаемому. Но можно поступить иначе: для этого к отрезку добавим по одной фиктивной ячейке справа и слева.
Их номера будут, соответственно, 0 и 21. В этих ячейках, как и в ячейках 1 и 20, всегда будут храниться нули. Тогда написанную формулу можно применять для n от 2 до 19.
Итак, модель построена и формализована.

Для реализации применим табличный процессо р.
Моделью жизненного пространства будет строка электронной таблицы.
Первая строка — первое поколение,
вторая строка — второе поколение и т. д.
Тогда номера ячеек будут идентифицироваться именами столбцов таблицы.
Ячейка номер 0 — столбец А,
ячейка 1 — столбец В и т. д.,
ячейка 21 — столбец F.
- В первой строке выставляем единицы в ячейках, заселенных в первом поколении. Это будут ячейки F1, I1, М1 . Незаполненные ячейки по умолчанию приравниваются к нулю.
- Теперь в ячейки второй строки нужно записать формулы. Сделать это достаточно один раз. Например, в ячейку С2 занести следующую формулу:
ЕСЛИ(И(А1 + В1 + С1 + D1 + Е1 =1; А1 + В1 + С1 + D1 + Е1
- Далее, копируя эту формулу во все остальные ячейки второй строки с D2 по Т2, получаем картину распределения живых организмов во втором поколении.
- Чтобы получить третье поколение, достаточно скопировать вторую строку (блок С2:Т2) в третью строку (блок СЗ:ТЗ). Так можно продолжать сколько угодно.
Результаты имитационного моделирования процесса эволюции исходного расселения живых организмов вплоть до 10-го поколения

Модель Дж. Конуэя «Жизнь»
В этой модели эволюция популяции живых организмов происходит в двумерном пространстве.
Рассматривается прямоугольная область, разделенная на квадратные ячейки. Тогда у каждой внутренней ячейки имеется 8 соседей. Судьба жизни в ячейке также зависит от состояния соседних клеток.

ИМИТАЦИОННАЯ МОДЕЛЬ – это логико-математическое описание объекта, которое может быть использовано для экспериментирования на компьютере в целях проектирования, анализа и оценки функционирования объекта.
Имитационная модель имеет определенную минимальную опорную структуру, которую пользователь может дополнить и расширить с учетом специфики решаемых задач и базовых методов обработки.
Отличие от математического моделирования
- имитационное моделированиеисследуетматематическиемоделив видеалгоритмов, воспроизводящих функционирование исследуемой системыпутемпоследовательноговыполнениябольшого количестваэлементарныхопераций.
- в имитационных моделях для получения необходимой информации или результатов необходимоосуществлять их «прогон»в отличие от аналитических моделей, которые необходимо «решать».
- имитационные моделинеспособны формироватьсвое собственноерешениев том виде, в каком это имеет место в аналитических моделях, а могут лишьслужитьв качествесредства для анализаповедения системы в условиях, которые определяются экспериментатором.
Имитационные модели
В общем виде структуру имитационной модели в математической форме можно представляет следующим образом: ,
где E – результат действия системы;
x i – переменные и параметры, которыми мы можем управлять;
y i – переменные и параметры, которыми мы управлять не можем;
f – функциональная зависимость между x i и y i , которая определяет величину E .
Имитационные модели
Имитационная модель представляет собой комбинацию таких составляющих, как:
- компоненты;
- переменные;
- параметры;
- функциональные зависимости;
- ограничения;
- целевые функции.
Схема имитационного моделирования:
НЕДОСТАТКИ ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ:
- разработка имитационных моделей требует больших затрат, времени и сил;
- любая имитационная модель сложной системы менее объективна, чем аналитическая модель;
- результаты имитационного моделирования носят как правило частный характер, поэтому для предоставления обоснованных выводов необходимо провести серии модельных экспериментов.
Пример имитационного моделирования на компьютере
Имитационная модель воспроизводит поведение сложной системы, элементы которой могут вести себя случайным образом. Иначе говоря, поведение которых заранее предсказать нельзя.
Модель – эволюция популяций
- Пусть на определенном пространстве случайным образом расселяются живые организмы.
- В дальнейшем происходит процесс смены поколений: в каких-то местах расселения жизнь сохраняется, в каких-то исчезает.
- Эти процессы протекают в соответствии с законами эволюции (формальными правилами).
Цель моделирования — проследить изменения в расселении живых организмов со сменой поколений.
Имитационные модели
Законы эволюции:
- В следующем поколении в пустой ячейке жизнь может либо появиться, либо нет.
- В живой ячейке жизнь может либо сохраниться, либо исчезнуть
- На состояние данной ячейки влияют ее ближайшие соседи: два соседа слева и два соседа справа.
- Если ячейка была живая, и число живых соседей не превышает двух, то в следующем поколении в этой ячейке жизнь сохранится, иначе жизнь исчезнет (погибнет от перенаселения).
- Если в ячейке жизни не было, но среди ее соседей есть 1, 2 или 3 живые ячейки, то в следующем поколении в этой ячейке появится жизнь. В противном случае ячейка останется пустой.
Модельное описание процесса эволюции популяции
- Распределение живых организмов по ячейкам будем кодировать последовательностью из нулей и единиц.
- Ноль обозначает пустую ячейку , единица — живую .
- Например, расселение, отображенное на рис. 4.3, кодируется следующим образом:
n - номер ячейки,
R (n) - значение двоичного числа, соответствующего этой ячейке в текущем поколении.
В рассматриваемом примере R (5) = R (8) = R (12) = 1 .
Все остальные значения ячеек равны нулю.
Значения кода в n -й ячейке для следующего поколения будем обозначать S ( n ) .
Проанализировав правила эволюции, приходим к следующей формуле:
Если 1 R ( n - 2) + R ( n - 1) + R ( n ) + R ( n + 1) + R ( n + 2) 3, то S ( n ) = 1, иначе S ( n ) = 0.
Эта формула работает для значений n от 3 до 18 .
Для ячеек с номерами 2 и 19 в данной сумме нужно убрать по одному слагаемому. Но можно поступить иначе: для этого к отрезку добавим по одной фиктивной ячейке справа и слева.
Их номера будут, соответственно, 0 и 21. В этих ячейках, как и в ячейках 1 и 20, всегда будут храниться нули. Тогда написанную формулу можно применять для n от 2 до 19.
Итак, модель построена и формализована.
Для реализации применим табличный процессо р.
Моделью жизненного пространства будет строка электронной таблицы.
Первая строка — первое поколение,
вторая строка — второе поколение и т. д.
Тогда номера ячеек будут идентифицироваться именами столбцов таблицы.
Ячейка номер 0 — столбец А,
ячейка 1 — столбец В и т. д.,
ячейка 21 — столбец F.
- В первой строке выставляем единицы в ячейках, заселенных в первом поколении. Это будут ячейки F1, I1, М1 . Незаполненные ячейки по умолчанию приравниваются к нулю.
- Теперь в ячейки второй строки нужно записать формулы. Сделать это достаточно один раз. Например, в ячейку С2 занести следующую формулу:
ЕСЛИ(И(А1 + В1 + С1 + D1 + Е1 =1; А1 + В1 + С1 + D1 + Е1
- Далее, копируя эту формулу во все остальные ячейки второй строки с D2 по Т2, получаем картину распределения живых организмов во втором поколении.
- Чтобы получить третье поколение, достаточно скопировать вторую строку (блок С2:Т2) в третью строку (блок СЗ:ТЗ). Так можно продолжать сколько угодно.
Результаты имитационного моделирования процесса эволюции исходного расселения живых организмов вплоть до 10-го поколения
Модель Дж. Конуэя «Жизнь»
В этой модели эволюция популяции живых организмов происходит в двумерном пространстве.
Рассматривается прямоугольная область, разделенная на квадратные ячейки. Тогда у каждой внутренней ячейки имеется 8 соседей. Судьба жизни в ячейке также зависит от состояния соседних клеток.
Модель данных позволяет интегрировать данные из нескольких таблиц, эффективно построение источника реляционных данных Excel книге. В Excel данных модели данных применяются прозрачно, что обеспечивает табличные данные, используемые в сводных таблицах и на сводных таблицах. Модель данных визуализируются как набор таблиц в списке полей, и в большинстве моментов вы даже не узнаете, что она там.
Прежде чем приступить к работе с моделью данных, необходимо получить некоторые данные. Для этого мы используем power query & Transform ( Get & Transform), чтобы вы могли захотеть вернуться на шаг назад и посмотреть видео или воспользоваться учебным руководством по & Преобразование и Power Pivot.
Excel 2016 & Excel для Microsoft 365 — На ленте есть Power Pivot.
Excel 2013 — Power Pivot входит в выпуск Office профессиональный плюс версии Excel 2013, но по умолчанию не включен. Подробнее о запуске надстройки Power Pivot для Excel 2013.
Excel 2010 — скачайте надстройку Power Pivot, а затем установите надстройку Power Pivot,
Excel 2016 & Excel для Microsoft 365 — & Power Query интегрирован с Excel на вкладке Данные.
Excel 2013 : Power Query — это надстройка, которая входит в состав Excel, но ее необходимо активировать. Перейдите в > файлов > надстройки ,а затем в меню Управление в нижней части области выберите Надстройки COM > Перейти. Проверьте, нет ли в Microsoft Power Query Excel, а затем ОК, чтобы активировать его. На ленту будет добавлена вкладка Power Query.
Excel 2010— скачивание и установка надстройки Power Query.. После активации на ленту будет добавлена вкладка Power Query.
Начало работы
Во-первых, вам нужно получить некоторые данные.
В Excel 2016 и Excel для Microsoft 365 используйте data > Get & Transform Data > Get Data (Получить данные), чтобы импортировать данные из любого числа внешних источников данных, таких как текстовый файл, книга Excel, веб-сайт, Microsoft Access, SQL Server или другая реляционная база данных, которая содержит несколько связанных таблиц.
В Excel 2013 и 2010 перейдите в Power Query > Получитьвнешние данные и выберите источник данных.
Excel предложит выбрать таблицу. Если вы хотите получить несколько таблиц из одного источника данных, проверьте параметр Включить выбор нескольких таблиц. При выборе нескольких таблиц Excel автоматически создает модель данных.
Примечание: В этих примерах мы используем книгу Excel с вымышленными сведениями об учащихся в классах и оценках. Вы можете скачать образец книги модели данныхдля учащихся и следуйте этим командам. Вы также можете скачать версию с завершенной моделью данных..
Выберите одну или несколько таблиц и нажмите кнопку Загрузить.
Если вам нужно изменить исходные данные, можно выбрать параметр Изменить. Дополнительные сведения см. в обзоре редактора запросов (Power Query).
Теперь у вас есть модель данных, которая содержит все импортируемые таблицы, и они будут отображаться в списке полей таблицы.
Модели создаются неявно, когда вы импортируете в Excel несколько таблиц одновременно.
Модели создаются явно, если вы импортируете данные с помощью надстройки Power Pivot. В надстройке модель представлена в макете со вкладками так же, как Excel, где каждая вкладка содержит табличные данные. Сведения о том,как импортировать данные с помощью базы данных, см. в этой SQL Server Power Pivot.
Модель может содержать одну таблицу. Чтобы создать модель на основе только одной таблицы, выберите таблицу и нажмите кнопку Добавить в модель данных в Power Pivot. Это может понадобиться в том случае, если вы хотите использовать функции Power Pivot, например отфильтрованные наборы данных, вычисляемые столбцы, вычисляемые поля, ключевые показатели эффективности и иерархии.
Связи между таблицами могут создаваться автоматически при импорте связанных таблиц, у которых есть связи по первичному и внешнему ключу. Excel обычно может использовать импортированные данные о связях в качестве основы для связей между таблицами в модели данных.
Советы по уменьшению размера модели данных см. в Excel и Power Pivot.
Дополнительные сведения см. в учебнике Импорт данных в Excel и Создание модели данных.
Совет: Как узнать, есть ли в книге модель данных? Перейдите в Power Pivot > Управление. Если вы видите данные, похожие на таблицу, то модель существует. Дополнительные сведения см. в этой теме.
Создание связей между таблицами
Далее нужно создать связи между таблицами, чтобы можно было извлекть данные из любой из них. Каждая таблица должна иметь первичный ключ или уникальный идентификатор поля, например Код учащегося или номер класса. Проще всего перетащить эти поля, чтобы соединить их в представлении диаграммы Power Pivot.
Перейдите на > PowerPivot .
На вкладке Главная выберите представление диаграммы.
Будут показаны все импортируемые таблицы, и вам может потребоваться некоторое время, чтобы их можно было отобразить в зависимости от их количество.
Затем перетащите поле первичного ключа из одной таблицы в следующую. Ниже приведен пример представления диаграммы таблиц наших учащихся:

Мы создали следующие ссылки:
tbl_Students | ИД учащегося > tbl_Grades | ИД учащегося
Другими словами, перетащите поле "ИД учащегося" из таблицы "Учащиеся" в поле "ИД учащегося" в таблице "Оценки".
tbl_Semesters | ИД семестра > tbl_Grades | Семестр
tbl_Classes | Номер > tbl_Grades | Номер класса
Имена полей не должны быть одинаковыми для создания связи, но они должны быть одного типа данных.
Соединители в представлении диаграммы имеют 1 с одной стороны, а "*" — на другой. Это означает, что между таблицами существует связь "один-к-многим", которая определяет способ использования данных в таблицах. Дополнительные сведения см. в этой теме: Связи между таблицами в модели данных.
Соединитетели указывают только на связь между таблицами. Они не будут показывать, какие поля связаны друг с другом. Чтобы увидеть ссылки, перейдите в Power Pivot > Управление > конструктором > связи > Управление связями. В Excel вы можете перейти к data > Relationships (Отношения > данных).
Создание и создание с помощью модели данных для создания сводная диаграмма
Книга Excel может содержать только одну модель данных, но она содержит несколько таблиц, которые можно многократно использовать во всей книге. Вы можете добавить дополнительные таблицы в существующую модель данных в любое время.
В Power Pivot, перейдите вуправление .
На вкладке Главная выберите вкладку "PivotTable".
Выберите место для размещения таблицы: новый или текущий.

Затем создайте или создайтесетовую диаграмму. Если вы уже создали связи между таблицами, вы можете использовать любое из их полей в таблице. Мы уже создали связи в образце книги модели данных для учащихся.
Добавление имеющихся несвязанных данных в модель данных
Сначала выберите любую ячейку в данных, которые вы хотите добавить в модель. Это может быть любой диапазон данных, но лучше всего отформатированные как Excel таблицы.
Добавьте данные одним из следующих способов.
Щелкните Power Pivot > Добавить в модель данных.
Выберите Вставка > Сводная таблица и установите флажок Добавить эти данные в модель данных в диалоговом окне "Создание сводной таблицы".
Диапазон или таблица будут добавлены в модель как связанная таблица. Дополнительные сведения о работе со связанными таблицами в модели см. в статье Добавление данных с помощью связанных таблиц Excel в Power Pivot.
Добавление данных в Power Pivot таблицу
В Power Pivot невозможно добавить строку в таблицу, введя текст непосредственно в новой строке, как это можно сделать на листе Excel. Но вы можете добавить строки, скопируяи впав их или обновив исходные данные и обновив модель Power Pivot.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
) и т.д., обеспечивающие следующие дополнительные возможности Excel: генерация случайных чисел, автоматизация запуска экспериментов, анализ и представление выходной информации и т.д. Генерация случайных чисел может быть также выполнена с помощью надстройки Excel, называемой «Пакет анализа данных».
Наконец
, отметим, что в связи с продолжением развития данного программного обеспечения, возможно, будущие версии будут предоставлять больше возможностей и обеспечивать более эффективную имитацию.
2. Имитационное моделирование систем массового
обслуживания
В
разных областях техники, в организации производства, в экономике и медицине
, в социальной сфере, в военном деле и во многих других сферах человеческой деятельности постоянно возникает необходимость решения вероятностных задач, связанных с работой систем массового обслуживания
(СМО). Многообразие приложений теории массового обслуживания определяет постоянно растущий интерес к ней, а сложность возникающих задач не позволяет получить исчерпывающие решения на базе аналитических методов. В таких ситуациях часто прибегают к имитационному моделированию. Для имитации подобных систем предназначен язык моделирования GPSS, а также создаются сложные программные системы
(ObjectSim, Pigrim
[10]), позволяющие реализовать модели систем массового обслуживания с помощью развитой CASE- оболочки путем выбора и связи различных строительных блоков. Среди работ, описывающих моделирование СМО с помощью электронных таблиц можно привести следующие - 7. Авторы рассматривают моделирование систем с неограниченным
, ограниченным по времени и/или длине очереди ожиданием, которые располагают от 1 до 12 обслуживающими устройствами [7]. При этом различают два основных подхода к моделированию СМО: ориентированный на события и ориентированный на процессы. Событийный подход имеет преимущества в отношении гибкости и эффективности вычислений, однако менее подходит для обучения, поскольку скрывает «жизненный цикл» заявок и является менее понятным на интуитивном уровне. Кроме того, для его реализации требуется управляющая событиями подпрограмма, что приводит к необходимости использования внутреннего языка VBA [11]. Рассмотренные ниже модели будут реализованы с использованием процессно-ориентированного подхода.
Рассмотрим структуру СМО. Каждая СМО состоит из определенного числа обслуживающих единиц, которые называются каналами обслуживания. На вход
СМО
поступает поток требований (заявок). Таким образом, различают следующие элементы
СМО:
1. входной поток заявок;
2. очередь;
3. узел обслуживания;
4. выходной поток.
будет многоканальной), числу фаз обслуживания. Время обслуживание может быть случайной величиной или детерминированным.
Также существую системы, в которых обслуженные требования после некоторой задержки опять поступают на вход. Такие системы называются замкнутыми
В
качестве показателей эффективности СМО рассматриваются: среднее время
, которое клиент проводит в очереди, средняя длина очереди, среднее время
, которое клиент проводит в
системе обслуживания
(
TotalTimeSystem
TimeSystem
N
=
, где
TotalTimeSystem
- общее время пребывания в системе для всех заявок, а
N
-число заявок), среднее число клиентов в системе обслуживания
, вероятность того, что система окажется свободной и т.д.
2.1 Одноканальная система массового обслуживания
Рассмотрим простую систему массового обслуживания: число каналов равно единице
, время ожидания неограниченно, время между заявками и время обслуживания заявок являются случайными величинами с показательным законом распределения (среднее значение времени обслуживания равно
to
, среднее время между заявками -
tz
) (рис.2.2).
Рис
. 2.2 – Одноканальная система массового обслуживания
Рассмотрим процесс поступления десяти заявок, если
tz
=0,5 ч.,
to
=1 ч.
В
[6]использован следующий способ моделирования такой системы
(рис.2.3). Величины времени обслуживания и между заявками рассчитываются согласно способу моделирования случайной величины с показательным законом распределения
D9=-$F$4*LN(СЛЧИС())
E9=-$F$3*LN(СЛЧИС()).
В
последнем столбце рассчитывается величина
Wn
Xn Yn
+
−
F7=C7+D7-E7.
Если ее значение является отрицательным, то это означает, что следующая заявка поступит после того, как будет обслужена текущая и потому время ее ожидания будет равно нулю, а в противном случае, время ожидания составит
Wn
Xn Yn
+
−
С
9=0
С
10=ЕСЛИ(F9>0;F9;0).
Изменим исходные данные (
tz
=1 ч.,
to
=0,5 ч.). Из рис. 2.4 можно увидеть, что в
этом случае уменьшится время ожидания обслуживания.
Рис
.2.3 – Результаты моделирования одноканальной СМО при
tz
=0,5 ч.,
to
=1 ч.
Рис
. 2.4 – Результаты моделирования одноканальной СМО при
tz
=1 ч.,
to
=0,5 ч.
Теперь выполним моделирование, учитывая начальное время
tn
. Пусть
tz
=8 мин
.,
to
=7 мин.;
tn
=9 ч. Рассмотрим процесс поступления семи заявок (рис.2.5).
Определение времени между заявками и времени обслуживания (мин.) остается без изменения.
Для того чтобы перевести эти значения в используемый формат времени необходимо осуществить следующие операции
F8=E8/1440
D8=D7+C8/1440.
Т
.е. время поступления очередной заявки равно сумме времени прибытия предыдущей и случайной величины, распределенной по показательному закону.
Время начала обслуживания первой поступившей заявки равно времени ее поступлению
G8=D8.
Начиная со второй заявки, эта величина будет определяться как максимальное значение из момента окончания обслуживания предыдущей заявки и
времени поступления текущей
G9=ЕСЛИ(D9>=H8;D9;H8).
Время окончания обслуживания рассчитывается по формуле
H8=G8+F8.
Рис
. 2.6 – Моделирование одноканальной СМО с не перекрывающимися заявками
Задачи
1. Выполните имитацию работы банка, осуществляющего прием вкладов.
Размер депозита является случайной величиной с нормальным законом распределения
(среднее значение
-
MD
; среднее квадратическое отклонение
-
SD
). Время между приходом двух вкладчиков – случайная величина с показательным законом распределения (среднее значение -
tz
), а
время обслуживания равномерно распределено на интервале [
a
;
b
].
Пусть исходные значения равны величинам:
MD
=30000 руб.;
SD
=10000 руб
.;
tz
=1 час;
a
=20 мин.;
b
=30 мин.;
tn
=9 ч., число заявок равно 5.
Определите время прихода последнего клиента, среднее время пребывания клиента в системе. Какой общий размер вкладов будет осуществлен а) после прихода пяти клиентов; б) к моменту времени 12:00 ч
.?
Рис
.2.7 – Система массового обслуживания «Банк»
2. Проведите 10 экспериментов и рассчитайте величины:
• среднее время ожидания;
• среднее число обслуженных заявок за период с 9:00 до 15:00 ч.
3. Предположите, что
tn
=0 и выполните имитацию описанным на рис. 2.3 способом
4. Пусть банковская автоматизированная система может выходить из строя, что приводит к необходимости вызова специалистов, устраняющих неполадку
. Выполните имитацию периодов нормальной работы системы и ее ремонта, если данные величины являются случайными с показательным законом распределения, а
tz
=30 дней,
to
=3 ч. Рассмотрите процесс поступления
5 заявок (отказов).
2.2 Двухканальная система массового обслуживания
В
том случае, если обслуживание заявок может происходить в нескольких узлах
, то говорят, что данная система является многоканальной. Рассмотрим двухканальную
СМО (рис.2.8). Предположим, что вновь поступившая заявка поступает в тот канал, который раньше других освободился (а при одновременном освобождении заявка поступит в первый узел), тогда процесс моделирования можно представить следующим образом (рис. 2.9) (исходные данные:
tz
=8 мин.,
to
=7 мин.;
0
t
=9 ч.).
Рис
. 2.8 – Двухканальная система массового обслуживания
Рассмотрим основные отличия от предыдущей модели. Для каждого канала выполняется расчет времени начала и окончания обслуживания. Решение о том, в
каком канале будет происходить обслуживание, принимается на основе данных о
времени освобождения каждого из них. Время начала обслуживания заявки
получит магазин а) после того, как было обслужено семь покупателей; б) к моменту времени 10:00 ч.?
2. Предположите, что рассматриваемый поток клиентов – это потенциальные покупатели
, которые с вероятностью
P
могут совершить покупку (
P
=0,6).
3. Пусть время обслуживания – дискретная случайная величина со следующим законом распределения
Значение
, мин
1 2
3 4
Вероятность
0,2 0,2 0,4 0,2
Выполните имитацию, учитывая данное условие.
4. Проведите 10 экспериментов и рассчитайте величины:
• среднее время ожидания;
• средний размер выручки.
Рис
.2.10 – Система массового обслуживания «Магазин»
2.3 Система массового обслуживания с ограниченным по
времени
ожиданием
Ожидание наступления обслуживания может быть ограничено двумя условиями
: длиной очереди и временем. Во втором случае заявка покидает
систему необслуженной, если время ее ожидание превысило некоторое значение
TOMax
, в противном случае – поступает в канал обслуживания (рис. 2.11).
Если время ожидания заявок равно нулю, то система называется СМО без ожидания
(рис. 2.12). В качестве примера можно привести поступление телефонных звонков в справочную службу: если оператор занят разговором с другим клиентом, то поступившие в этом период звонки получают отказ в обслуживании
Рис
. 2.11– Система массового обслуживания с ограниченным по времени ожиданием
Рис
. 2.12 – Система массового обслуживания без ожидания
Считая
, что время между заявками и обслуживания является случайной величиной с показательным законом распределения, выполним имитацию данной системы со следующими исходными данными:
tz
=8 мин.,
to
=7 мин.;
0
t
=9 ч.;
TOMax
= 1 мин. Результаты представлены на рис. 2.13. В столбце «Поступление на
обслуживание
» принимается решение о том, будет ли начато обслуживание заявки
. Для этого рассчитывается промежуток времени между поступлением заявки и освобождением канала и сравнивается с максимальным временем ожидания заявки
Е
9=ЕСЛИ((МАКС(G$8:G8)-C9)>$D$4;"Нет";"Да").
В
случае поступления заявки на обслуживание определяется время его начала и окончания
F9=ЕСЛИ(E9= «Да»;МАКС(C9;G$8:G8); «»)
G9=ЕСЛИ(ЕТЕКСТ(F9);»»;F9+D9).
В
последнем столбце «Ожидание» рассчитывается время ожидания (для всех заявок, независимо от, того были ли они обслужены)
H9=ЕСЛИ(ЕТЕКСТ(G9);МАКС(G$8:G8;C9)-C9;F9-C9).
Так
, из рис.2.13 видно, что в данной реализации период ожидания шестой заявки превысил максимально допустимое значение, и поэтому обслуживания не произошло
Рис
. 2.13 – Моделирование системы массового обслуживания с ограниченным по времени ожиданием
Задачи
1. Менеджер фирмы принимает заказы от клиентов на выполнение различных работ
(рис.2.14). Заказы поступают посредством телефонной связи. Время между двумя звонками является случайной величиной с показательным
законом распределения (среднее значение -
tz
), время обслуживания
(принятия заказа) – случайная величина с нормальным законом распределения
(среднее значение -
to
, среднее квадратическое отклонение
-
sto
). В том случае, если звонок поступил в то время, когда менеджер занят приемом другого заказа, то он получает отказ в обслуживании.
Стоимость заказа клиента равномерно распределена на интервале [
a
;
b
].
Выполните моделирование данной системы при следующих исходных данных
:
tz
=15 мин.;
to
=15 мин.;
sto
=2 мин.;
a
=5000 руб.;
b
=15000 руб.;
tn
=9 ч
. Рассмотрите поступление шести звонков и определите следующие величины
: число отказов в обслуживании; общая сумма заказов; время поступления последнего звонка.
Рис
.2.14 – Система обслуживания «Прием заказов»
2. Проведите 10 экспериментов и рассчитайте величины:
• среднее число отказов в обслуживании;
• среднюю сумму заказов;
• среднее время завершения моделирования (время окончания обслуживания последней заявки).
3. Выполните моделирование, считая, что вероятность совершения заказа клиентом равна
P
(
P
=0,7).
4. Предположите, что фирма наняла еще одного менеджера и вновь поступивший звонок направляется к свободному в данный момент работнику
5. Пусть новое оборудование фирмы позволяет поступившим звонкам ожидать освобождения менеджера в течение времени
TOMax
. Выполните моделирование при
TOMax
=2 мин. (число каналов обслуживания равно единице
), рассчитайте среднее число отказов (за 10 реализаций) и сравните данное значение с полученным во втором задании.
6. Рассмотрите ситуацию, когда максимальное время ожидания каждой заявки определяется также поведением клиентов и его значение – случайная величина с дискретным законом распределения:
Значение
0 1
2
Вероятность
0,25 0,5 0,25
Читайте также: