
Программы управления памятью переводов
Сегодня я расскажу о средствах, помогающих в работе переводчику. А именно - о системах памяти переводов (они же TM (Translation Memory), CAT-Tools (Computer-Assisted Translation Tools) или просто "кошки"))).
Их существует великое множество, самая известная из которых - смею предположить, Традос. Также есть MemoQ, Memsource и множество иных. В данном посте я расскажу о принципе их работы на примере ТМ Memsource, с которой мне лично довелось работать. В остальных системах принцип аналогичный, судя по прочитанным материалам во ВсеПротянутой Паутине (WorldWideWeb дословно можно перевести именно так)).
Итак, приступим:
1. Открываем браузер и вводим адрес www.memsource.com.
2. Регимся. Тут есть нюанс: так как полная версия стоит достаточно приличных денег (100/130/180 евро в месяц, в стоимость включены аккаунты для одного/трех/пяти менеджеров проектов и 10 лингвистов. Соответственно каждая версия рассчитана на бюро переводов (100 евро), средние и большие переводческие компании (130/180 евро) , и разработчики это понимают, они предложили пользователям выбор: либо купить полную версию, либо воспользоваться бесплатной (рассчитана на индивидуальных переводчиков). Ограничений бесплатной версии всего два: можно загружать файлы весом не более 10 Мб, и не более двух в одном проекте. Я не Рокфеллер и даже не Ротшильд, посему пользовался бесплатной онлайн-версией.
3. После регистрации и подтверждения мыла логинимся и видим слева менюшку и три вкладки посередине окна: проекты, базы терминов и базы памяти переводов. Нажимаем кнопку "создать проект", загружаем файл с оригиналом, указываем срок выполнения (чтобы не забыть потом), обзываем проект как-нибудь, создаем базу терминов и базу памяти переводов (чтобы не запутаться потом, лучше всего назвать их также как проект) и сохраняем. Базы памяти переводов и базы терминов пока не касаемся, ибо в свежесозданном аккаунте их еще нет.
ВАЖНОЕ ПРИМЕЧАНИЕ: система криво работает с PDF, посему если оригинал в этом формате, идем на convert standard.com, выбираем опцию "PDF в Word", грузим наш оригинал и нажимает кнопочку CONVERT. По окончании конвертации автоматически загрузится вордовский файл, для приличия спросив куда емусохраниться (или, если не спросит, автоматически сохранится в стандартной папке загрузок (Мои документы - Загрузки). Его и нужно после загрузить в систему для начала перевода.
4. Во вкладке "Проекты" видим только что созданный проект, входим в него и открываем загруженный исходник - в новой вкладке автоматически открывается web me source editor, имеющий вид фрейма, вверху которого - панель инструментов, внизу - две колонки, соответственно для оригинала и перевода, а сбоку справа - панелька MT (Machine translation), автоматически выдающая варианты перевода каждого сегмента (предложения), на которые система автоматически разбила оригинал.
5. Ставим курсор в первую строчку перевода - автоматически подставляется машинный перевод. Если он Вас устраивает, то в панели инструментов нажмите символ - он появится чуть справа от перевода, означая что перевод фрагмента подтвержден, он правильный и занесен в базу памяти переводов. Если машинный перевод не нравится, впишите свой перевод и опять же нажмите кнопку в панели инструментов. Курсор автоматически перескочит на следующую строчку и подставит машинный перевод, с которым Вы уже знаете как поступить.
6. В процессе перевода можно переключиться на вкладку с проектами и, обновив страницу, увидеть какой объем (в процентах) уже переведен. В системе используется облачное хранение данных, потому даже если Вы случайно закрыли вкладку с переводом не сохранив (к слову, там и кнопки "сохранить" нет, я проверял), все что Вы сделали, сохранится при повторном открытии. Посему при окончании перевода просто закрываем вкладку и обновляем страницу с проектами.
7. Выделяем готовый перевод на вкладке проектов - активируются неактивные до того кнопки меню, среди которых выбираем "скачать - готовый файл". Начнется загрузка вордовского документа с переводом. И вот здесь нас ждет бонус. Помните, мы делали вордовский документ из pdf? Естественно в нем было какое-то оформление - шрифты, картинки, схемы и так далее. Так вот, ВСЁ оформление сохраняется в готовом файле с переводом. Да-да, со всеми картинками, схемами, таблицами и прочим.
8. Отправляем готовый перевод заказчику.
9. Профит!
На этом все на сегодня. Успехова в переводах, коллеги, и да пребудет с Вами Контекст!)))
Продолжаем разговор о системах Translation Memory. Поводом для проведения глубокого исследования серверных решений TM стала насущная производственная необходимость бюро переводов Prima Vista, поэтому все системы прошли "боевую" проверку.
В первой части статьи мы привели критерии выбора для исследования систем TM, рассмотрели SDL Studio GroupShare и OmegaT, на практике выявили плюсы и минусы этих систем. В этой части подробно разберем MemoQ, Wordfast, Déjà Vu, а также сделаем заключение по проведенному исследованию.
Другие статьи о программном обеспечении для переводчиков
- С облачными TM-системами переводчики учатся и работают по-новому
- Перевод текста чертежей AutoCAD
- Обзор программ Translation Memory
- Гибридные технологии машинного перевода: практическая оценка современного состояния на примере PROMPT DeepHybrid
MemoQ
Подходящая компания — это такая компания,
где нас могут чем-нибудь угостить.
.JPG)
Компания Kilgray – одна из тех, что претендуют на вторую строчку воображаемого пьедестала, на вершине которого гордо стоит SDL. И претендует по праву. Во-первых, она предлагает спектр решений, практически «слизанный» с SDL International, а именно: клиент MemoQ в версиях Translator Pro и Project Manager, сервер MemoQ и дополнительные продукты, расширяющие возможности основных программ. На первый взгляд MemoQ выглядит не хуже SDL Trados Studio. Он умеет все, что умеет SDL Trados Studio, имеет некоторые дополнительные функции, которые отсутствуют в SDL Trados Studio, в среднем функционирует быстрее, а также способен работать с файлами SDL Trados Studio (файлами проектов и двуязычными файлами .sdlxliff).
Что же показала практика? У нас нет большого опыта работы с MemoQ, а значит, нет и статистики, которая позволила бы в полной мере оценить сильные и слабые стороны программы. Тем не менее мы поставили пробную версию сервера и клиентские части и проверили основные функции. При непродолжительной работе мы столкнулись со сбоями в работе, что в некоторой степени подпортило первоначально сугубо положительное впечатление. Kilgray заявляет о чрезвычайно оперативной поддержке, и хочется верить, что недостатки будут со временем устраняться, но мы все-таки оценивали программное обеспечение «здесь и сейчас».
- Очень широкие функциональные возможности как клиентской, так и серверной части. Сервер MemoQ – единственный из изученных нами, который дает возможность хранить не только базы переводов и терминов, но и файлы проектов, то есть является аналогом SDL GroupShare 3-го уровня.
- Хорошее впечатление произвели скорость и корректность работы с базами данных.
- Возможность разделения отдельных файлов на части и преобразования файлов в двуязычные таблицы для тех редких, но важных переводчиков, которые не признают систем CAT.
- Достаточно прочное место на рынке и большое количество компаний и переводчиков, которые пользуются MemoQ. Конечно же, с оговоркой, что SDL – абсолютный лидер, и здесь речь идет лишь о втором месте.
Contra
- Основной и самый существенный минус с учетом перечисленных выше плюсов – это недостаточная распространенность. Хотя MemoQ пользуется большой круг пользователей, его место в отрасли несравнимо с тем местом, которое занимает SDL Trados.
- Большие функциональные возможности, обусловленные конкурентной борьбой и погоней за SDL Trados, имеют и негативные последствия – изучить функции и особенности MemoQ нелегко. Интерфейс из-за множества элементов нельзя назвать простым и интуитивно-понятным. Разобраться во всем без руководства довольно трудно или даже практически невозможно.
- Программа неидеальна. Были выявлены сбои («глюки»), хотя они и устранимы. Тем не менее, учитывая малый практический опыт, решение связать свою судьбу с MemoQ будет сопряжено с большими рисками, чем с Trados Studio.
- Сервер работает только на ОС Windows Server. Сервер SDL GroupShare способен работать на ОС Windows7 Professional.
Wordfast
— Ушастик, а у тебя случаются дни,
когда все хорошее не случается?
— Да, каждый Божий день.
На сайте Wordfast приводится таблица, в которой Wordfast по всем показателям (якобы по независимой экспертной оценке) существенно опережает Trados, однако данные сравнения приводятся аж для 2006 года! С тех пор утекло много воды, и существенным изменениям подверглась не только программная начинка SDL Trados, но и Wordfast. Наличие ссылки на такие данные на первой странице сайта компании говорит о том, что она сильно «зависла» в прошлом и едва ли может считаться динамичной и оперативно реагирующей на нужды рынка.
Практическая работа, хотя и небольшая, продемонстрировала скоростные характеристики Wordfast. Это, несомненно, самая быстрая среда перевода. То, что программа Wordfast способна усвоить, она усваивает быстро. Но при этом она далеко не всеядна. Во-первых, она не может импортировать файлы из SDL Trados Studio, что ставит под вопрос огромное количество заказов, поступающих в этом формате, вынуждая идти на различные хитрости. Во-вторых, она способна импортировать не все базы .tmx. Наша «тяжелая» база, подготовленная в Trados 2007, вызвала ошибку и не была импортирована ни в одной из версий Wordfast из-за неприемлемых знаков.
Сервер Wordfast позволяет работать только с базами памяти. На нем нельзя сохранять проекты, как в случае с MemoQ Server и SDL GroupShare. Однако подкупает его необыкновенная простота. Весь сервер – это 2-мегабайтная программа, которую можно запустить в любой операционной системе. Ее не нужно устанавливать и особым образом настраивать. Кроме того, для нее не требуется устанавливать SQL-сервер, так как она использует свой фирменный протокол баз данных.
- Простота клиентов и экстремальная простота сервера. Сервер устанавливается и настраивается буквально «за пять минут», при этом он легко переносится с компьютера на компьютер.
- Быстрота работы клиентов. Все открывается и обрабатывается очень быстро (когда нет сбоев. ).
- Совершенно бесплатная веб-версия Wordfast Anywhere, отличающаяся достаточно богатым функционалом и способная подключаться к серверу Wordfast.
Contra
- Главный минус, опять-таки, малая распространенность Wordfast. Судя по всему, эта программа используется еще меньше, чем MemoQ.
- Несовместимость с SDL Trados. Преобразования форматов возможны, но требуют значительной работы.
- Не такие богатые функциональные возможности, как у MemoQ и SDL Trados. Впрочем, они расширяются (например, добавлена даже поддержка формата .pdf).
- Сервер не позволяет хранить проекты.
- Несмотря на заявленную оперативность поддержки, версии обновляются не так часто, а на сайте представлена информация 7-летней давности.
Déjà Vu
У меня правильнописание какое-то хромое.
Вообще-то оно хорошее правильнописание,
но только почему-то хромает и буквы опаздывают…
.JPG)
Разрабатывается и продвигается испанской компанией Atrill. На рынке уже давно, с 1993 года. Распространенность среди пользователей порядочная, но в последнее время наблюдается некоторое снижение уровня поддержки со стороны компании. Имеет репутацию дружелюбной и простой в освоении программы. Популярность среди LSP не так высока. Обладает рядом фирменных «фишек», среди которых можно упомянуть Assemble (сборка перевода сегмента из более мелких фрагментов, которые имеются в памяти переводов, лексиконе, терминологических базах), AutoWrite (аналог AutoSuggest от SDL), DeepMiner (интеллектуальная сегментация исходного текста с целевой функцией, соответствующей максимальному количеству совпадений с имеющимися базами). Если основываться на отзывах, работа на уровне подсегментов является одной из сильнейших особенностей Déjà Vu.
Мы опробовали Déjà Vu на нескольких файлах Word со сложным форматированием. В принципе как клиент делает свою работу успешно. Однако в связи с неполной совместимостью с форматами SDL и более слабым сервером мы решили сместить акцент в испытаниях на другие программы.
- Как клиент хорош – удобен и интуитивно-понятен.
- Хорошая работа на уровне подсегментов с использованием технологий Assemble и DeepMiner.
Contra
- Серверное решение не слишком популярно и имеет не такой мощный функционал, как SDL GroupShare или MemoQ Server.
- Отсутствует проверка правописания на лету, нужно нажимать F7. Даже в этом случае правописание работает не слишком хорошо. Слова могут не добавляться, редактирование затруднено и т. д.
- QA реализован так себе, если сравнивать с Trados и MemoQ. Хотя лично нам удобней сторонние программы QA, работающие в пакетном режиме.
- Подтвержденные сегменты остаются таковыми даже после групповой операции поиска и замены.
- Не очень хорошая совместимость с Trados. Да, SDLXLIFF переводятся, но могут портиться. Пакеты и проекты Trados Studio не читаются.
Заключение
— Ну, если вы больше ничего не хотите…
— А разве еще что-нибудь есть?
Попробуем обобщить сказанное выше и сделать свой выбор. Мы пришли к выводу, что на рынке серверных решений (именно серверных, то есть с возможностью поднять свой собственный сервер) по функционалу нашим запросам отвечают лишь две среды – SDL Studio GroupShare и MemoQ Server. Почему?
OmegaT очень хороша, но ряд ограничений (в частности, неполная совместимость с Trados и отсутствие возможностей управления правами пользователей) вряд ли позволят сделать ее основным инструментом в нашей компании. Wordfast – да, быстро, но где же серверные проекты? Где полная совместимость с форматами Trados? Преимущества Déjà Vu лежат в основном в области работы с подсегментами, и в паре MemoQ vs. Déjà Vu мы отдаем преимущество MemoQ. MemoQ лучше поддерживает форматы Trados, быстрее развивается, имеет родственное облачное решение MemSource.
Итак, MemoQ и Trados.
MemoQ является серьезным конкурентом SDL. Если подбирать решение для работы преимущественно штатными силами, MemoQ Server – неплохой вариант, который практически ни в чем не уступает SDL. В самом деле, штатников мы можем обучить чему угодно. Однако работа с внештатными переводчиками может вызвать затруднения, учитывая, что даже с самой распространенной средой SDL Trados знакомы далеко не все. А в освоении MemoQ ничуть не проще Trados. Распространенность решений SDL тянет за собой еще одно преимущество – мы не боимся этой программы. В Интернете и в нашей личной копилке опыта есть куча решений всевозможных проблем, нестандартных ситуаций и т. д. Отметим еще один важный факт: SDL не нужно «париться» о поддержке форматов MemoQ, а вот специалисты Kilgray вынуждены «копаться» в проприетарных форматах, таких как SDLXLIFF. Это создает им широкие возможности для дополнительных ошибок.
В сухом остатке имеем следующее. По функционалу решения SDL и Kilgray близки, но мы отдаем предпочтение SDL GroupShare из соображений меньшего риска наших инвестиций и большей надежности. Здесь мы учитываем и большой личный опыт, и распространенность, и, по сути де-факто, положение отраслевого стандарта.
Внимательный читатель заметил, что до сих пор мы не говорили о ценах. Цены на серверные решения программ Translation Memory, как правило, не публикуются на сайтах разработчиков, а являются предметом переговоров с поставщиком. В целом общие ориентиры таковы: OmegaT бесплатна. Чуть дороже Wordfast – за сервер придется выложить около трех тысяч евро. Далее идут Déjà Vu и MemoQ. Здесь стоит рассчитывать на сумму от шести тысяч евро. Наконец, самая дорогая программа, как и следовало ожидать, SDL Group Share. Однако разница с тем же MemoQ не так велика, и она не стала для нас значимым аргументом. Кроме того, компания Т-Сервис разработала для российских бюро переводов специальные ценовые предложения, которые практически сводят на нет «экономию» от MemoQ.
SDL GroupShare – отличный выбор при развертывании собственного сервера. О том, что предлагает рынок, если вы не прочь поселиться на «облаке», читайте в одной из наших следующих статей.
Работу современного переводчика сложно представить без средств автоматизации, к которым относятся не только программы работы с памятью переводов, но и системы управления терминологией, программы OCR, подсчета статистики, различные DTP-инструменты, словари и прочее. Центральное место занимают, конечно, системы Translation Memory. На рынке их много, здесь есть из чего выбрать как переводчику-одиночке, так и LSP, будь то небольшая рабочая группа или крупное бюро переводов.
Критерии, по которым выбирают для себя инструменты фрилансер и компания, близки, но все-таки они разные. Если вы работаете на себя, можно основное внимание уделить удобству клиентской части. Если же речь идет о компании, не обойтись без средств интеграции для работы в группе. Мы попытаемся сделать обзор доступных решений, позволяющих организовать работу команды переводчиков, редакторов и руководителей проектов. Стимулом к этому исследованию послужила реальная производственная необходимость бюро переводов Prima Vista.
В этой статье рассмотрены SDL Studio GroupShare и OmegaT. Во второй части статьи - обзор MemoQ, Wordfast, Déjà Vu и заключение по исследованию.
Другие статьи о программном обеспечении для переводчиков
- С облачными TM-системами переводчики учатся и работают по-новому
- Перевод текста чертежей AutoCAD
- Обзор программ Translation Memory
- Гибридные технологии машинного перевода: практическая оценка современного состояния на примере PROMPT DeepHybrid
Критерии выбора
Тебе меду или того и другого?
И того и другого. И можно без хлеба!
Итак, наша цель – выбрать программное обеспечение для автоматизации работы бюро переводов, и выполнения крупных проектов силами штатного отдела перевода и внештатных переводчиков. Главная функция программы – совместное использование баз памяти переводов, терминологических баз и проектов в реальном времени. Внедрение должно способствовать решению следующих задач:
- Повышение качества переводов в плане единства терминологии и согласованности.
- Сокращение сроков выполнения крупных проектов.
- Укрепление позиций компании как надежного поставщика лингвистических услуг.
- Создание базы для оптимизации бизнес-процессов в компании.
Исходя из этих задач, мы сформулировали требования к инструментам:
- Память переводов должна быть доступна в режиме онлайн как штатникам, так и внештатникам. Поэтому требуется общий доступ в реальном времени как по локальной сети, так и через Интернет.
- Кроме памяти переводов желательно иметь общий доступ к терминологическим базам и проектам.
- Внештатники не должны получать в свое распоряжение всю базу переводов по данному проекту или заказчику в виде файлов. Иными словами, у них должны быть лишь свои накопленные сегменты и результаты поиска и подстановок по «главным» базам проекта.
- Необходимо учесть вопросы конфиденциальности информации. Поэтому мы ориентируемся на свой сервер, разворачиваемый и поддерживаемый силами компании. Однако совсем отказываться от «облачных» решений мы не будем, и жизнеспособной может быть гибридная схема.
- Желательна возможность введения в общий workflow даже тех переводчиков, которые не желают пользоваться какими-либо решениями Translation Memory. Например, это может быть реализовано через автоматическую обработку двуязычных таблиц.
- Хорошо бы иметь функции гибкого управления правами пользователей и общим доступом к ресурсам.
Предварительный анализ позволил выбрать пять решений, которые мы не только изучили «теоретически», но и попробовали в деле. Облачные технологии оставим для отдельной статьи. Кроме того, исключены программы, которые, как мы считаем, не заслуживают серьезного рассмотрения.
SDL Studio GroupShare
Сова! Открывай! Медведь пришел!
SDL – лидер рынка Translation Memory, поставщик самых распространенных решений, в том числе серверных. Многие относятся к Trados, как к Windows: поругивают за громоздкость, глюки, интерфейс, медленное реагирование на пожелания пользователей, высокие цены, но тем не менее активно пользуются.
.JPG)
Мы видим две причины широкого распространения решений SDL. Во-первых, это собственно их широкое распространение. В самом деле, если значительная доля LSP работает с Trados, предоставляя субподрядчикам соответствующие пакеты, базы памяти и файлы, выбор зачастую падает на SDL исключительно из соображений совместимости и защиты инвестиций в программное обеспечение и обучение сотрудников. Во-вторых, SDL Trados Studio и Group Share – действительно отличные программы, в которых после должной настройки и обучения комфортно работается как переводчику, так и руководителю проектов. Так как компания SDL является законодательницей мод, остальные участники рынка сравнивают себя с ней и борются, как максимум, за второе место. Признанием некоторой своей ущербности для них является то, что к числу основных преимуществ они относят поддержку форматов Trados.
Общий опыт работы с решениями SDL и Trados у нас довольно большой – около восьми лет. Если говорить о клиентском программном обеспечении, свою задачу оно решает успешно. Много «оснастки» для управления крупными проектами – это и пакеты, и разные уровни пользователей, и поддержка большого числа разных форматов исходных файлов. Главное, что стоит подчеркнуть: программа проверена на большом объеме реальной многолетней работы. Так что с точки зрения клиентской части вложения в нее будут иметь минимальный риск.
Теперь собственно о GroupShare. Это серверное решение, обеспечивающее общий доступ команды к базам переводов, терминологическим базам и проектам. Работает под Windows Server (также возможна установка на Windows7 Professional) и позволяет организовать доступ как из локальной сети, так и через Интернет.
Мы прогнали основные операции создания серверного проекта и работы с ним в удаленном режиме. Все работает отлично. Консоль управления сервером доступна в виде Web-интерфейса и позволяет выполнять основные операции обслуживания баз, проектов, контроля версий и прочее, но в целом это не слишком сложное приложение, и основная работа по-прежнему делается на клиентской стороне, то есть в SDL Trados Studio.
- Лидер рынка, то есть риск вложений в приобретение программного обеспечения и обучение персонала минимален. Компания вряд ли исчезнет в обозримом будущем, скорее сама поглотит конкурентов.
- Серверная версия поддерживает все три возможности работы в команде: общие базы переводов, общие терминологические базы и, наконец, общие проекты, опубликованные на сервере. То есть можно просто давать переводчикам данные учетной записи на сервере и обойтись без пересылки файлов, баз и подпроектов.
- Клиентское программное обеспечение всесторонне испытано, сюрпризы маловероятны.
- Гибкое управление правами пользователей на сервере.
- Гибкое ценовое регулирование со стороны SDL в зависимости от необходимого функционала – GroupShare поставляется в трех вариантах (три уровня по терминологии компании «Т-Сервис»). Первый – только TM Server, на втором добавляется MultiTerm Server и, наконец, на третьем – Project Server.
- Внештатные переводчики могут пользоваться базами переводов, не получая их в свое полное распоряжение.
Contra
- SDL – крупная компания, и она не всегда молниеносно реагирует на чаяния пользователей. Например, сложно представить себе современное серверное решение без функции разделения одного файла между группой переводчиков. В SDL Trados Studio для этого используется внешняя утилита SDL XLIFF Split and Merge, которая лишь недавно вошла в комплект поставки SDL Trados Studio 2011.
- Общая перегруженность и некоторая неочевидность интерфейса «из коробки». Отчасти это связно с тем, что как менеджеры, так и переводчики используют одно и то же клиентское программное обеспечение. Можно, конечно, настроить «под себя» и убрать все лишнее, но для некоторых переводчиков это может стать проблемой и оттолкнуть от решений SDL.
- Сравнительно медленное выполнение основных операций – достаточно много времени уходит на обработку баз, экспорт/импорт и т. д. Не сказать, чтобы это было непреодолимым препятствием в работе, но скорость явно не относится к главным преимуществам решений SDL.
OmegaT
Вот горшок пустой.
Он предмет простой.
Он никуда не денется.
Безд-возд-мезд-но! То есть даром!
.JPG)
OmegaT – последний из бесплатных проектов в сфере Translation Memory, который жив и активно развивается в наше время. Программа написана на Java и является в определенной степени мультиплатформенной (Windows, Linux, Mac). В значительной мере несет в себе как плюсы, так и минусы идеологии Open Source. Несмотря на бесплатность, по функционалу ее можно смело поставить в один ряд с лидерами рынка, такими как Trados, MemoQ и Wordfast.
Подход к проектам и форматам файлов простой и элегантный. В качестве формата памяти перевода используется TMX, что позволяет обмениваться данными с другими программами. От двуязычных рабочих файлов разработчики вообще отказались. Все переводимые файлы сегментируются во время загрузки проекта, и переведенные сегменты сохраняются в отдельном файле TMX («память проекта»). Когда требуется получить целевой файл, в него просто подставляются данные из этого файла TMX.
Что касается организации групповой работы переводчиков, эта функция реализована не так давно, но опять же сделана в рамках общей идеологии Open Source. Используется давно известный в среде программистов метод контроля версий «изменение - слияние». Суть его в следующем: поднимается сервер контроля версий (в OmegaT можно использовать SVN или Git), на нем создается репозиторий с проектом OmegaT, и все переводчики получают права доступа к этому серверу (собственно, IP или символьный адрес и пароль). При первом обращении к серверу на компьютер переводчика закачивается созданный проект. В дальнейшем OmegaT периодически обращается к серверу и «синхронизирует» версии рабочих файлов, выполняя слияние вносимых изменений по контексту. Такой подход позволяет одновременно редактировать один и тот же файл всей команде. Так как двуязычных файлов нет, синхронизируются файл TMX, представляющий собой память проекта, и файл глоссария в формате TXT. Как говорится, все гениальное просто.
Так как программа бесплатна, можно сразу воспользоваться полной версией. Одна из особенностей OmegaT – после установки функционал и интерфейс куцый, и желательно скачать и поставить ряд плагинов, скриптов, произвести настройку системы под себя. Тогда она раскроется в полной мере. Отметим, что все эти операции нет необходимости выполнять всякий раз при переносе программы на другой компьютер. Можно просто переписать каталог с установленной OmegaT, так как в реестре и где-то еще она не следит и является по сути portable. Единственно, нужно прописать в запускаемом bat-файле сохранение настроек в каталоге программы, а не в каталоге активного пользователя.
Мы выполнили достаточно крупный проект в OmegaT, загрузив его на сервер SVN. Система показала полную работоспособность, файл в Word 2007 обработан корректно, целевой файл большого объема с достаточно сложным форматированием не был испорчен. Все работает быстро.
Говоря об автоматизированном переводе, обычно подразумевают программы, осуществляющие перевод на основе технологии машинного перевода (Machine Translation). Однако существует и другая технология — Translation Memory, которая хотя и не столь широко известна российским пользователям, но, тем не менее, имеет ряд преимуществ.
Бурное развитие технического прогресса привело к увеличению числа технических устройств, машин и другой сложной техники, без которых жизнь современного человека практически немыслима. Например, объем документации для европейского самолета Airbus исчисляется десятками тысяч страниц. Как показывают данные исследования, проведенного в конце 2004 года ассоциацией LISA 1 (LISA 2004 Translation Memory Survey), 42% опрошенных переводят около 1 млн. слов в год, у 24% компаний — участников опроса ежегодный объем переводов составляет 1-5 млн., 12% переводят от 5 до 10 млн., объем переводов остальных компаний — от 10 до 500 и более миллионов слов в год. В частности, большинство производителей сегодня не ограничиваются своим локальным рынком и активно осваивают региональные рынки. При этом локализация продукции, в том числе перевод описания продукта на местный язык, является одним из обязательных условий для выхода на новый рынок.
В то же время, хотя производители регулярно выпускают новые версии своих продуктов — автомобилей, экскаваторов, компьютеров и мобильных телефонов, программного обеспечения, — далеко не все из них принципиально отличаются от предыдущих моделей. Подчас новая модель телефона представляет собой слегка измененную (или рестайлинговую) предыдущую модель. Новые версии продаются лучше, поэтому производителям приходится регулярно обновлять свои продукты. В результате документация по каждому из таких продуктов зачастую на 70-90% совпадает с той, что была у предыдущей версии.
Два фактора — большой объем требующих перевода документов и их высокая повторяемость — послужили стимулом к созданию технологии Translation Memory (сокращенно именуется TM, общепринятый русский перевод этого термина отсутствует). Суть технологии TM можно образно передать одной фразой: «Не переводить один и тот же текст дважды». Иначе говоря, Translation Memory используется для повторного использования ранее сделанных переводов. Это позволяет серьезно сократить время на подготовку перевода, особенно при работе с текстами, имеющими высокую степень повторяемости.
Технологию Translation Memory часто путают с машинным переводом (Machine Translation), которая, безусловно, тоже полезна и интересна, но ее описание не является целью настоящей статьи. Использование технологии ТМ повышает скорость перевода за счет уменьшения объема механической работы. Однако важно отметить, что TM не выполняет перевод за переводчика, а является мощным инструментом для сокращения затрат при переводе повторяющихся текстов.
Технология ТМ работает по принципу накопления результатов перевода: в процессе перевода в базе ТМ сохраняются исходный текст и его перевод. Для облегчения обработки информации и сравнения различных документов система Translation Memory разбивает весь текст на отдельные кусочки, которые называются сегментами. Такими сегментами чаще всего являются предложения, но могут быть приняты и другие правила сегментации. При загрузке нового текста система TM осуществляет сегментирование и сравнивает сегменты исходного текста с уже имеющимися в подключенной базе переводов. Если системе удается найти полностью или частично совпадающий сегмент, то его перевод отображается с указанием совпадения в процентах. Сегменты, которые отличаются от сохраненного текста, выделяются подсветкой. Таким образом, переводчику остается только перевести новые сегменты и отредактировать частично совпадающие.
Как правило, задается порог совпадений на уровне не ниже 75%, так как если установить меньший процент совпадений, то увеличатся затраты на редактирование текста. Каждое изменение или новый перевод сохраняются в ТМ, так что нет необходимости переводить одно и то же дважды!
Важно также постоянно пополнять базу Translation Memory, сохраняя в базе (или в базах, если перевод выполняется по различным тематикам) пары сегментов «исходный текст — правильный перевод». Это позволит значительно сократить время, необходимое для перевода сходных текстов. Помимо снижения трудоемкости перевода система TМ позволяет выдержать единство терминологии и стиля во всей документации.
Использование технологии ТМ обеспечивает переводчику следующие преимущества:
Отдельно отметим, что в западных странах, где технология Translation Memory давно уже стала де-факто обязательным инструментом переводчика, средства, потраченные на создание базы переводов, рассматриваются не как затраты, а, скорее, как инвестиции в стабильную и качественную работу, что увеличивает не только прибыль, но и стоимость самой компании.
Рынок систем Тranslation Мemory
Бесспорным лидером на рынке систем Translation Memory являются программы SDL-TRADOS. Летом 2005 года произошло объединение двух крупнейших разработчиков систем ТМ — компаний SDL и TRADOS (программные продукты под торговой маркой TRADOS хорошо известны многим пользователям), и теперь они выпускают совместный продукт, который является законодателем стандартов в области Translation Memory.
Новая система SDL-TRADOS имеет расширенные (настраиваемые пользователем) функциональные возможности нечеткого соответствия (поиск по совпадениям в базе переводов), а также инструментарий для проверки качества переводимых документов. Программа осуществляет проверку орфографии и защищает содержимое блоков памяти с помощью технологии шифрования.
Система поддерживает такие форматы, как Word DOC и RTF, online help RTF, PowerPoint, FrameMaker, FrameMaker +SGML, FrameBuilder, Interleaf, QuickSilver, Ventura, QuarkXPress, PageMaker, SGML/HTML/XML, включая HTML Help, RC (Windows Resource), Bookmaster (DCF) и Troff. Помимо системы SDL-TRADOS, на IT-рынке имеются и другие системы ТМ. Особенно широко представлены французские производители.
— это самостоятельное приложение с систематизированным меню. Система может создавать базы ТМ, а также базы данных терминологии и подключать словари. Процесс перевода осуществляется в специальной оболочке Project, куда при ее создании прикрепляется файл, который необходимо перевести, и подключаются дополнительные настройки: база ТМ, словари и др. Текст переводится в специальной таблице, где напротив каждой графы его оригинала нужно заполнить вариант перевода. К преимуществам также относится дополнительная функция для перевода файлов различных форматов, которая позволяет сохранить исходное форматирование файла.
Помимо поддержки форматов Word, система может переводить документы Excel и PowerPoint. При переводе можно использовать и базы ТМ других программ: Trados версий 2, 3 и 5, документы формата TMX и базы программы IBM Translation Manager. Кроме того, система может работать без лицензии с базами перевода объемом до 110 Кбайт.
ТМ в России
Помимо иностранных компаний, разработкой систем класса Тranslation Мemory занимается российская компания ПРОМТ — всемирно известный разработчик систем машинного перевода (Machine Translation).
Разработка продукта PROMT Translation Suite 7.0 — это дебют компании ПРОМТ в области применения технологии Translation Memory. Уникальность продукта заключается в интеграции сразу двух технологий перевода: Translation Memory и Machine Translation. Помимо работы с базой ТМ в виде самостоятельного приложения путем создания специального документа «Проект», система PROMT Translation Suite 7.0 самостоятельно переводит те сегменты текста, которые отсутствуют в базе ТМ.
Для облегчения работы с незнакомым текстом в продукте также имеется интегрированный электронный словарь, который позволяет оперативно просмотреть варианты перевода слова (рис. 1).
Рис. 1. Окно программы PROMT Translation Suite с развернутой панелью справки по словарной статье
Основные достоинства PROMT Translation Suite:
- Интеграция двух технологий — интеграция машинного перевода с технологией Translation Memory позволяет значительно снизить расходы на перевод текстов. Как правило, даже наличие обширной базы Translation Memory не гарантирует 100%-ного совпадения сегментов оригинального текста с базой переводов. Как показывает практика, даже при высокой степени совпадения, не менее 30-40% текста переводчикам приходится переводить вручную. Наличие функции машинного перевода позволяет ускорить процесс перевода. По ряду оценок, использование МТ повышает производительность труда переводчика на 40-60% в зависимости от сложности текста.
- Дружественный интерфейс — в отличие от большинства систем TM, продукт PROMT Translation Suite предлагает удобный и интуитивно понятный интерфейс. Фактически пользователь может начать переводить сразу же после инсталляции, не нуждаясь в дорогостоящем тренинге по обучению работе с продуктом.
- Наличие русской локализации — данный продукт имеет русский интерфейс и документацию на русском языке.
- Привлекательная цена — PROMT Translation Suite в комплектации с системой машинного перевода с английского на русский и обратно стоит 400 долл.
Как настроить систему Тranslation Memory
Процесс перевода с помощью системы Translation Memory можно условно разделить на следующие этапы:
- Сегментирование исходного текста в соответствии с заданными правилами сегментации.
- Поиск совпадений между сегментами исходного текста и сегментами, хранящимися в базе переводов. Найденные совпадения программа подставляет в текст перевода с указанием процента совпадения.
- Перевод ненайденных сегментов и редактирование частично совпадающих сегментов.
- Сохранение корректных переводов в базе TM для последующего использования.
Для упрощения изложения в рамках данной статьи мы сознательно не рассматриваем этапы извлечения текста из исходного документа и последующей верстки переведенного текста в случае перевода документов в таких форматах, как XML, PDF и др.
Рассмотрим возможности настройки системы Translation Memory на примере уже упоминавшейся нами программы PROMT Translation Suite.
Правила сегментации текста
Одна из основных задач во время настройки системы — правильное сегментирование текста. Успех поиска совпадающих сегментов в базе зависит от того, насколько правильно заданы правила сегментации текста (рис. 2).
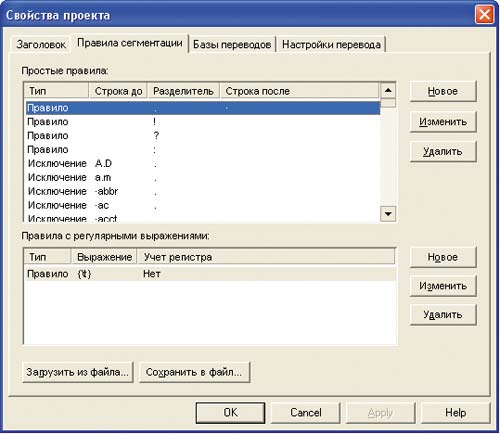
Существует два типа условий сегментации:
- правило — задает условия, при которых определенные символы (точка, запятая и т.д.) являются границами сегментов;
- исключение — задает условия, при которых определенные символы не являются границами сегментов.
Базовый набор правил сегментации автоматически добавляется в каждый проект перевода при его создании. Для того чтобы получить возможность редактирования этих правил, необходимо выбрать команду Свойства в контекстном меню искомого проекта (второй способ: меню Проект -> Все проекты -> Свойства -> Правила сегментации).
В системе можно задать две группы правил сегментации: простые правила и правила с регулярными выражениями.
Простые правила задают условия, определяющие последовательность символов, которые надо или не надо считать границей сегмента. К простым правилам относится строка до разделителя (возможна пустая или определенная последовательность символов), символ разделителя (всегда один!) и строка после разделителя.
Правила с регулярными выражениями существуют для создания более гибких условий сегментации, что также отнюдь не лишне. Если должным образом не задать такие условия, то, например, предложение «Команда выиграла матч со счетом 3:1» может быть неправильно сегментировано. В данном случае необходимо задать исключение (то есть символ, который система не будет считать границей сегмента) в виде строки до разделителя с помощью регулярного выражения « \d+ » (обозначает любое количество цифр), символа разделителя «:» и строки после разделителя с помощью регулярного выражения « \d+ » (любое количество цифр). В этом случае система не обратит внимание на двоеточие между цифрами.
Работа с непереведенными сегментами
В процессе перевода система анализирует текст, находит полностью или частично совпадающие предложения в базе ТМ и подставляет их в текст перевода. В каждом сегменте сбоку указывается процент совпадений, нижний предел которого можно устанавливать самостоятельно, задавая настройки перед переводом.
Нельзя также забывать о необходимости постоянного пополнения баз ТМ для сокращения затрат на перевод в дальнейшем. Для того чтобы добавить корректно переведенные сегменты в базу, щелкните правой клавишей мыши по выделенному сегменту и выберите команду Добавить выделенные сегменты в базу (или нажмите соответствующую кнопку на панели инструментов). Сохранение новых сегментов перевода в базе не только повышает эффективность работы с системой, но и экономит время при переводе последующих текстов.
Кроме того, следует пользоваться командой контекстного меню Завершить перевод сегментов после окончания редактирования сегментов. В этом случае можно избежать случайного внесения изменений в уже отредактированный сегмент.
Импорт баз переводов
Одна из наиболее полезных опций системы PROMT Translation Suite — возможность импорта баз переводов (во внутреннем формате программы (*.pts) и баз переводов ассоциированной памяти PROMT (*.apd)), а также сегментов из файлов (во внутреннем формате *.pts и в формате TMX Level 1 (*.tmx)). Используя эту возможность системы, можно избавить себя от составления базы переводов с нуля в том случае, если база ТМ по необходимой тематике уже создана, например, другими сотрудниками компании.
Процесс импорта баз переводов PROMT Translation Suite сравнительно прост. Необходимо открыть меню База -> Импортировать и выбрать команду База переводов, а затем найти нужный файл базы и обязательно указать тип файла *.pts.
Особое внимание следует уделить возможности импорта сегментов файлов TMX.
Файлы TMX — это универсальный формат обмена данными для систем Translation Memory, поэтому с их помощью вы можете переносить содержимое баз данных, даже если раньше работали с другой системой ТМ. Чтобы импортировать сегменты из файла ТМХ, нужно выбрать в том же меню База -> Импортировать команду Сегменты и необходимый ТМХ-файл. После этого следует выбрать ту базу переводов, в которую необходимо добавить сегменты из ТМХ-файла, и нажать кнопку Выбрать.
В заключение отметим, что технология Translation Memory является мощным инструментом для решения проблемы эффективного перевода повторяющихся текстов. В этом обзоре мы не только рассказали о сути технологии TM, но и описали представленные на рынке системы. В частности, российским пользователям можно порекомендовать обратить внимание на систему PROMT Translation Suite, разработанную российской компанией ПРОМТ.
Важным преимуществом системы PROMT Translation Suite, по сравнению с зарубежными аналогами, является наличие интегрированной технологии машинного перевода. Это позволяет значительно ускорить создание собственных баз Translation Memory и повысить эффективность работы с системой.
Постоянное пополнение баз переводов новыми сегментами сведет к минимуму работу переводчика вручную при переводе текстов схожей тематики.


Гибкая ценовая политика —
неотъемлемая часть
умного сервиса.
У нас Вы всегда
будете понимать
за что платите.

«ЛингваКонтакт» —
это еще и крупнейшие
переводческие курсы России.
Профессию переводчика
мы знаем со всех сторон!

В наш век стремительного развития информационных технологий и невиданного до сих пор тесного взаимодействия самых, казалось бы, отдалённых культур потребность в предоставлении быстрых и качественных переводческих услуг становится особенно актуальной. И не удивительно, что сфера письменного перевода , считавшаяся до недавнего времени территорией приложения исключительно человеческого интеллекта, с появлением уже первых компьютеров начала медленно, но заметно видоизменяться. И не могло быть иначе, ведь облегчение труда и постоянный поиск новых решений заложен в самой сути человека.
Как это часто бывает, технический прогресс в сфере коммуникаций не только поставил перед человечеством новые задачи, но и принёс с собой средства для их решения. В сфере письменных переводов одним из таких решений стала технология под названием Translation Memory (ТМ) и использующие её средства автоматизированного перевода (CAT — computer assisted translation).

Важно заметить, что средства автоматизированного перевода ни в коем случае нельзя путать с машинным переводом. Это два совершенно разных подхода к автоматизации перевода компьютерными средствами, две совершенно разные «философии» переводческого процесса. В случае машинного перевода весь перевод — от начала и до конца — делает машина, компьютер, используя для этого имеющиеся в её распоряжении словари и алгоритмы перевода. Как следствие, результат такой работы далёк от того, что можно назвать «качественным переводом» ровно по той причине, что искусственный интеллект до сих не изобретен человечеством. Во втором же случае речь идёт только об инструментах, облегчающих и ускоряющих традиционный процесс человеческого перевода, который выполняется и контролируется непосредственно переводчиком. Бюро переводов «ЛингваКонтакт» никогда не занималось и не занимается машинным переводом.
Translation Memory (TM) или «память переводов» (ПП) представляет собой базу данных, где хранятся все ранее выполненные переводы с её использованием. Для удобства переводчика программы, использующие технологию Translation Memory, разбивают переводимый текст на так называемые сегменты — фрагменты текста, оригинал и перевод которых и хранится в памяти. За единицу сегментирования (минимальную единицу перевода) такие программы обычно принимают предложение или часть сложноподчинённого предложения, но в зависимости от настроек ею также могут быть слово, фраза либо целый абзац.
Кроме собственно создания и работы с памятью переводов, современные программы автоматизированного перевода позволяют:
— создавать и использовать глоссарии и словари пользователей;
— создавать памяти переводов из пар уже ранее переведенных текстов без использования средств автоматизированного перевода;
— проводить анализ текста и делать выборку из его ключевых слов, которые потом можно добавлять в глоссарии;
— осуществлять так называемый «предварительный перевод» (pretranslation) на основе уже имеющихся баз ПП.
Наиболее эффективно применение данной технологии для перевода:
— больших проектов, содержащих много однотипных фрагментов и терминов: разного рода научных и технических текстов, документаций, финансовых и юридических текстов;
— одного проекта группой из нескольких переводчиков — в этом случае технология ПП (облачная) позволяет добиться единообразия терминологии и стиля;
— новых версий уже ранее переведённых текстов — это значительно сокращает время на поиск и перевод новых фрагментов;
— файлов, содержащих разметку: файлы с веб-контентом (HTML, XML и др.) и файлы издательских систем (FrameMaker, Interleaf, Pagemaker и др.).
В то же время эта технология оказывается практически бесполезной при переводе художественных, публицистических и рекламных текстов. Другими словами, всего того, что требует творческого подхода и незаурядных решений.
Вот так выглядит интерфейс SDL Trados, интегрированной в MS Word:
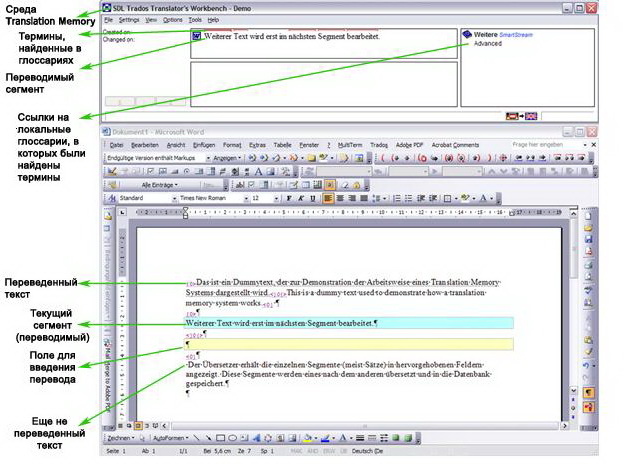
Краткий обзор основных средств автоматизированного перевода
Сегодня на рынке представлено несколько десятков программ, поддерживающих работу с технологией Translation Memory. Самыми известными из них являются SDL Trados, Déjà vu, Wordfast, MultiTrans, STAR Transit и Omega-T. Кроме самого очевидного — цены (например, программа Omega-T является полностью бесплатной) — эти программные среды отличаются:
— интерфейсом редактирования текста: некоторые программы интегрируются в MS Word (например, все версии SDL Trados до версии SDL Trados 2007 включительно), другие же имеют свой собственный интерфейс;
— алгоритмами разбиения текста на сегменты (сегменты состоят из предложений, фраз или слов);
— наличием дополнительных функций (например, в программе MemoQ, в отличии от других, существует возможность оценки в процентном отношении однородности текста, т.е. наличия в нём повторяющихся элементов на уровне слов и фраз);
— возможностью интеграции средств машинного перевода;
— количеством поддерживаемых форматов файлов;
— наличием возможности работать с памятью переводов в режиме он-лайн.
Выбор CAT-программы часто зависит больше от личных предпочтений переводчика или требований бюро переводов, с которым он сотрудничает (к примеру, многие западные бюро переводов работают с форматом TTX, а он полноценно поддерживается только средой SDL Trados).
Переводчики бюро переводов «ЛингваКонтакт» знают и владеют на высоком уровне самыми распространенными CAT-инструментами. Кроме того, в нашем арсенале «помощников переводчика» есть не только средства работы с памятью переводов, но также и множество других программ и утилит (инструменты Quality Assurance, создание терминологических баз, межформатная конвертация и пр.), без которых едва ли можно добиться высокого качества и скорости работы. На счету «ЛингваКонтакт» десятки тысяч переведённых страниц с использованием TM-средств!
Вы можете быть уверены, что Ваш текст будет переведён качественно и в срок, в каком бы формате и какой бы сложности он ни был!
Читайте также: