
Программы для распознавания текста для linux
Оригинал: 5 Scanning Tools for Linux Desktop
Автор: Martins D. Okoi
Дата публикации: 6 декабря 2018 года
Перевод: А. Кривошей
Дата перевода: июнь 2019 г.
Судя по информации, которую я собрал на форумах, работать со сканерами в Linux не очень приятно. Но так быть не должно, потому что на самом деле есть эффективные опции для сканера, которые вы можете легко настроить на своем компьютере.
Именно по этой причине мы представляем вам наш список 5 утилит для сканирования в Linux. Все они бесплатные и с открытым исходным кодом.
1. XSane
XSane - это приложение, которое позволяет управлять сканерами с помощью библиотеки SANE (Scanner Access Now Easy). Это самая многофункциональная утилита для сканирования в этом списке, так что вы можете просто остановиться здесь.
Он даже может работать со сканерами, которые были разработаны для систем Mac и Windows, благодаря тому, что она сама не поддерживает сканеры, но работает с любым сканером, поддерживаемым библиотекой SANE. Вы можете использовать ее для сканирования файлов, создания фотокопий, создания факсов и в качестве плагина GIMP.
2. Skanlite
Skanlite - это легкая утилита для сканирования, которую с любовью используют в сообществе KDE.
Его функции включают в себя сохранение изображений в форматах JPG, PNG, PPM, XPM, XBM и BMP, автосохранение, предварительную настройку качества сканирования, и возможность сохранения частей отсканированных документов в виде отдельных файлов.
3. Gscan2pdf
Gscan2pdf - это приложение с графическим интерфейсом, которое позволяет сканировать документы и сохранять их в файлах PDF и DjVu.
Оно совместимо практически со всеми дистрибутивами Linux и предлагает несколько функций редактирования, таких как извлеченние встроенных изображений в PDF, вращение, повышение резкости изображений, выбор страниц для сканирования, выбор стороны для сканирования, цветовой режим, разрешение и т. д.
Gscan2pdf также поддерживает OCR (оптическое распознавание символов) и множество функций, которые доступны из терминала, если вам нужна дополнительная функциональность.
4. Simple Scan
Simple Scan - это легковесная утилита для сканирования со множеством функций редактирования. Она позволяет сканировать документы одним нажатием кнопки, поворачивать и/или обрезать изображение и сохранять его в формате JPG, PNG или PDF.
По умолчанию она использует разрешение 300 точек на дюйм для фотографий и 150 точек на дюйм для текста - настройки, которые вы можете изменить в меню настроек.
Simple Scan - это приложение для сканирования по умолчанию во многих дистрибутивах Linux, включая рабочий стол GNOME, поэтому вы оно может быть уже установлено у вас.
5. GIMP с Quitelnsane
Как вы правильно поняли, GIMP способен работать с вашим сканирующим устройством, все, что вам нужно сделать, это установить Quitelnsane.
Quitelnsane - это графический интерфейс для SANE (Scanner Access Now Easy), и вы можете использовать его с GIMP для сканирования документов и их простого редактирования перед сохранением в предпочитаемом формате.
Существуют также альтернативы, такие как VueScan и TurboPrint Control, но они не являются ни бесплатными, ни открытыми. Существуют ли инструменты сканирования, достойные этого списка, которые мы пропустили? Не стесняйтесь писать свои мысли в разделе комментариев ниже.
Для Linux имеются разнообразные инструменты командной строки и с графическим интерфейсом для преобразования изображений в текст. В этой статье будут рассмотрены программы, с помощью которых вы можете после сканирования страниц книги или документов перевести их в текстовый формат.
OCR программы в Linux с графическим интерфейсом
OCRFeeder
OCRFeeder — это система анализа макета документов и оптического распознавания символов.
Откройте в этой программе изображения и она автоматически определит контуры областей, в которых находятся изображения и текст и выполнит OCR (распознавание текста) этого документа. Программа может сохранять полученные результаты в разные форматы, главным из них является ODT.
Программа имеет законченный GTK+ графический пользовательский интерфейс, который позволяет пользователям корректировать любые нераспознанные символы, определять или корректировать границы областей текста, устанавливать стили параграфов, очищать введённые изображения, импортировать PDF, сохранять и загружать проект, экспортировать всё в несколько форматов и так далее.
В общем, это программа по функциям схожая с Abbyy FineReader, в некотором смысле, можно сказать, что OCRFeeder это аналог Abbyy FineReader для Linux, по крайней мере, в его базовой функциональности.
В своей работе OCRFeeder использует сторонние движки оптического распознавания символов, например, по умолчанию она использует Tesseract. Для установки нужно установить и графический интерфейс OCRFeeder и Tesseract. В Debian и производных Tesseract устанавливается в качестве зависимости, поэтому необязательно указывать этот пакет явно. Но при этом помните, что вместе с Tesseract устанавливается по умолчанию только распознавание английского языка, для дополнительной поддержки русского, нужно явно указать этот пакет. Про распознавание других языков, а также про работу с Tesseract будет рассказано в этой же статье далее.
Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные:
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
Как пользоваться OCRFeeder
Для запуска программы найдите её в меню (скорее всего, в разделе Офис):

Или в командной строке выполните команду:
Внешний вид программы:

Для анализа у меня есть тестовое изображение:

Загрузим его в программу (для этого нажмите знак плюс +). Вам необязательно добавлять изображения по одному — можно добавлять целыми папками или импортировать PDF документ.
Для распознавания в меню Документ выберем «Распознать документ» (будут распознаны все страницы, которые загружены в программу), либо «Распознать страницу» (будет распознана страница, которая выделена в данный момент).
В правом нижнем углу появляются результаты распознавания текста:
Как видим, результаты не идеальные, но вполне удовлетворительные — после небольшой ручной корректировки, этот текст пригоден для использования.
Как обычно с системами OCR — чем лучше качество исходного текста (имеют значение ровность, размер, контрастность и другое), тем лучше получается результат (хотя в любом случае требуется вычитка и корректировка полученного при распознавании текста):

По умолчанию языком для распознавания установлен тот же язык, что имеет ваша система, то есть, скорее всего, русский язык. Вы можете изменить язык в Меню → Настройки → Распознавание → Default language. Если вы выбрали неверный язык, то движок оптического распознавания символов вернёт плохие результаты. Если вы выбрали язык, который не поддерживается движком, то он может вернуть пустую страницу.
Вы можете экспортировать для распознавания PDF документы. А полученные результаты сохранять в различных форматах:
Также вы можете сохранить весь проект целиком в собственном формате программы.
Если вы запускаете OCRFeeder из командной строки, то вы можете использовать несколько опций для ускорения процесса добавления изображений.
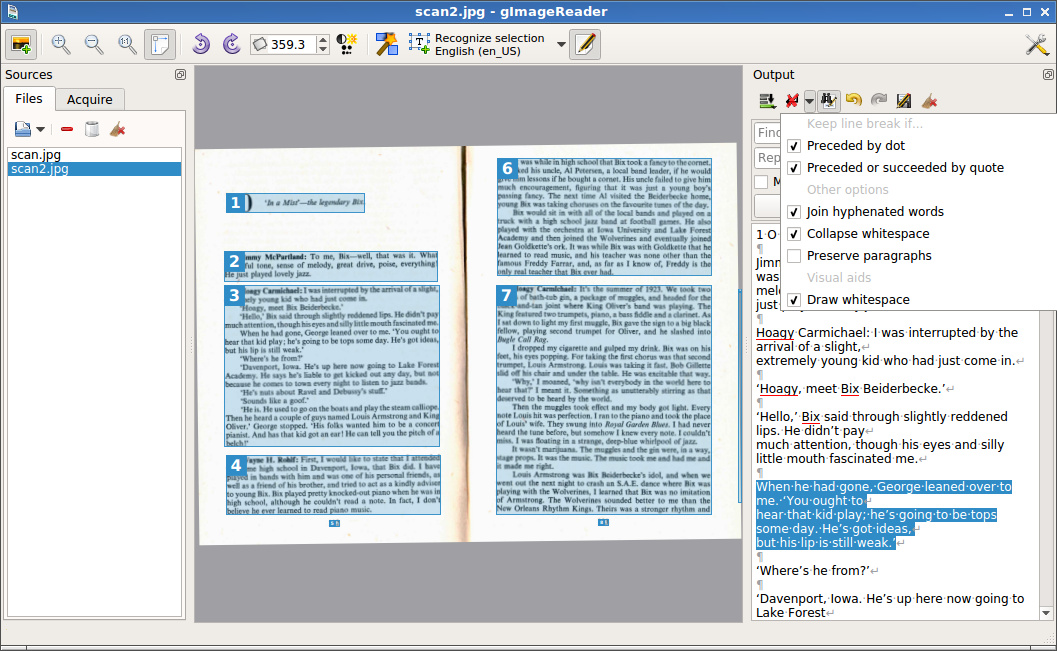
gImageReader
gImageReader — это графический GTK+ интерфейс для tesseract-ocr.
Tesseract — пожалуй, самое точное программное обеспечение с открытым исходным кодом для оптического распознавания символов (OCR) и может распознавать текст на более чем 60 языках.
gImageReader поддерживает автоматическое определение макета страницы, но пользователь также может вручную задать и отредактировать области распознавания. Есть возможность импортировать изображения с диска, устройств сканирования, буфера обмена и скриншотов. gImageReader также поддерживает многостраничные документы PDF. Распознанный текст отображается непосредственно рядом с изображением и базовое редактирование текста включает поиск/замену и удаление сломанных строк если это возможно. Также поддерживается проверка орфографии для выводимого текста если установлены соответствующие словари.

- Импорт PDF документов и изображений с диска, сканирующих устройств, буфера обмена и скриншотов
- Обработка нескольких изображений и документов за один проход
- Ручное или автоматическое определение области распознавания
- Распознавание в простой текст или в документ hOCR
- Распознанный текст отображается рядом с исходным изображением
- Последующая обработка текста, включая проверку орфографии
- Геренирование PDF документов из hOCR документов
Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные:
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
ocrgui
ocrgui — это графический интерфейс для OCR программ (Tesseract, GOCR). Программа давно не обновлялась и может отсутствовать в стандартных репозиториях.

Установка OCRFeeder в Arch Linux, BlackArch и их производные:
screentranslator
Это экранный переводчик, программа захватывает область экрана, распознаёт текст и выполняет его перевод. Если вам не нужен перевод, то его можно отключить.

Установка OCRFeeder в Arch Linux, BlackArch и их производные:
В настройках укажите путь к tesseract: /usr/bin/tesseract
Утилиты командной строки для OCR
Далее будут рассмотрены движки оптического распознавания символов, которые имеют интерфейс командной строки. Эта информация может пригодиться продвинутым пользователям, привыкшим иметь дело с консолью, а также пользователям OCRFeeder, поскольку эта программа умеет работать с каждым из рассмотренных ниже OCR инструментов, и знание их особенностей и различий помогут вам правильно выбрать используемый движок OCR:

Tesseract
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом. Его можно использовать напрямую, с помощью API для извлечения печатного текста из изображений, а также программы с графическим интерфейсом, такие как OCRFeeder, могут использовать Tesseract. Этот движок поддерживает большое количество языков. Пакет включает в себя утилиту командной строки.
Обратите внимание на опцию -l, после которой нужно указать используемый язык. Если он не указан, то подразумевается английский. Можно указать несколько языков, разделённых знаком плюс. Tesseract использует 3-символьные коды языков ISO 639-2.
Доступны следующие языки:
Ocrad
Ocrad включает анализатор разметки, способный разделять столбцы или блоки текста, какие обычно бывают на печатных страницах.
Для лучшего результата символы должны быть по крайней мере 20 пикселей в высоту. Если они меньше, попробуйте опцию --scale. Сканированные изображения на 300 dpi обычно дают размер символов достаточно хорошего размера для ocrad.
Слитые, очень смелые или очень светлые (сломанные) символы обычно не распознаются правильно. Старайтесь избегать их.
Если файлы не указаны, то ocrad считывает изображения из стандартного ввода. Если опция -o не указана, ocrad отправляет текст в стандартный вывод.
Статусы выхода: 0 для нормального выхода, 1 при проблемах в среде (файл не найден, неверные флаги, ошибки ввода/вывода и т.д.), 2 говорит о повреждённом или неверном файле ввода, 3 для ошибки внутренней консистенции (например, баг), которая вызвала панику в ocrad.
gocr — это мультиплатформенная программа распознавания текстов (OCR). Она принимает файлы изображений pnm, pbm, pgm, ppm, some pcx и tga. В настоящее время программа должна быть способна хорошо работать со сканами, в которых есть текст в один столбец и нет таблиц. Поддерживается размер шрифта от 20 до 60 пикселей.
Опции (больше подробностей в мануале man gocr):
Провести анализ разметки:
Расширенная база данных:
Использовать файл jpeg переданный по трубе:
Cuneiform
Cuneiform — это многоязычная система OCR (распознавания текста). В дополнении к распознаванию текста, она также анализирует разметку и распознаёт формат текста.
Поддерживаются следующие языки: болгарский, хорватский, чешский, датский, голландский, английский, эстонский, французский, немецкий, венгерский, итальянский, латышский, литовский, польский, португальский, румынский, русский, сербский, словенский, испанский, шведский, турецкий и украинский.
--dotmatrix
Режим распознавания оптимизирован для текстов, напечатанных на принтерах с точечной матрицей
--fax
Использовать режим распознавания, оптимизированный для текстов, переданных по факсу.
--singlecolumn
Отключить анализ разметки страницы и исходить из того, что изображение состоит из одной колонки текста.
-f формат
Выбрать формат вывода. Доступны следующие форматы:
- html (HTML формат),
- hocr (hOCR HTML формат),
- native (родной формат Cuneiform 2000),
- rtf (RTF формат),
- smarttext (простой текст с TeX параграфами),
- text (простой текст).
По умолчанию это plain text.
-l язык
По умолчанию Cuneiform распознаёт английский текст. Для изменения языка используйте переключатель командной строки, после -l после которого следует код языка (обычно трёхбуквенный код ISO 639-2).
Поддерживаются следующие языки:
-o вывод
Если вы не указали файл вывода с переключателем -o, то Cuneiform запишет результаты в файл ‘cuneiform-out.format’. Расширение файла зависит от вашего формата вывода.
Форматы ввода
Cuneiform может обрабатывать любые изображения с единичной страницой, которые GraphicsMagick знает как открывать. Посмотрите мануала gm(1) для полного списка поддерживаемых форматов изображений.
ocropy
ocropy — это написанный на Python OCR пакет, использующий рекуррентные нейронные сети (ранее назывался OCRopus).
ocropy — это коллекция программ для анализа документов, это не простая OCR система, которая распознаёт тексты в графическом интерфейсе или с запуском одной команды. Функции ocropy разбиты на отдельные модули и, например, для простого распознавания текста может потребоваться ввести несколько команд для подготовки документа.
В дополнении к самим скриптам распознавания, имеется ряд скриптов для базового редактирования и коррекции, измерению процента ошибок, определению матриц путаницы и т. п.

OCRFeeder — программа для автоматического распознавания текста. Поддержка импорта и экспорта документов. Автоматическое определение макета документа.
В качестве входных данных программа принимает файлы изображений (поддерживаются все популярные форматы) или PDF файлы, а также изображения со сканера (через программу SANE).
OCRFeeder автоматически анализирует файлы и выполняет распознавание, умеет анализировать макет документа, различая графику, текст, блоки текста, параграфы и абзацы.
Интерфейс программы выполнен достаточно аккуратно. В центре главного окна находится рабочая область — редактор документа. Слева миниатюры страницы, а справа панель форматирования, коррекции текста и дополнительные параметры.
OCRFeeder позволяет через графический интерфейс выполнять коррекцию текста, исправлять нераспознанные символы, устанавливать стили абзацев, удалять изображения, выделять и корректировать блоки текста на странице. Поддерживается проверка орфографии.
Поддерживается несколько форматов экспорта распознанных документов: ODT (OpenDocument Format), обычный текстовый файл, HTML, PDF. Основным является формат ODT.
Рабочий проект можно сохранить для последующего редактирования.
Также есть режим работы программы через командную строку (исполняемый файл ocrfeeder-cli).
OCRFeeder использует «внешние» движки распознания текста. Это могут быть, например, Tesseract, Ocrad, GOCR, Cuneiform. Результат распознавания может сильно зависеть от конкретного движка. У меня, например, Tesseract почему-то вообще не заработал. Если конкретный движок поддерживает русский язык, тогда программа сможет его распознать. Выбирать движок можно прямо из программы.
Изначально OCRFeeder был разработан как проект магистерской диссертации по информатике программиста Хоакима Роши (Joaquim Rocha).
Одна из областей, в которых отставание Linux от Windows считается значительным и трудно преодолимым, является оптическое распознавание текста. Так как необходимость распознать текст время от времени появляется практически у каждого пользователя компьютера, потребность в программном обеспечении такого рода надо признать актуальной проблемой. В связи с этим недавно я решил потратить немного времени и провести сравнительное тестирование имеющихся систем оптического распознавания текста (OCR), доступных в Linux. Для полноты картины рассматривались как локально устанавливаемые программы, так и онлайновые сервисы.
Методика тестирования
ABBYY FineReader for Linux
В процессе установки программа запросила ключ, после чего благополучно активировалась. Программа имеет множество ключей командной строки, позволяющих гибко настроить параметры распознавания. Я использовал команду вида:
В целом здесь все понятно. Ключи -if и -of задают распознаваемый файл и файл, в который записывается результат работы программы. С помощью -f задается формат вывода. Необходимо отметить, что если в тексте имеются слова на иностранном языке, необходимо обязательно задать его вторым после ключа -rl. В противном случае программа будет пытаться распознать все на русском.
ABBYY Fine Reader Online
Для полноты картины необходимо рассмотреть еще один продукт от ABBYY - онлайновый сервис ABBYY Fine Reader Online . Ранее он позволял после несложной регистрации распознавать бесплатно до 10 страниц в день, теперь же бесплатно можно распознать только три страницы сразу после регистрации, после чего необходимо платить. Минимальный пакет стоит 3$ за 20 страниц. Сервис поддерживает большое количество языков и форматов файлов.
Cuneiform
На второе место по известности среди систем OCR можно смело поставить программу cuniform. Первоначально программа CuneiForm была разработана компанией Cognitive Technologies как коммерческий продукт. CuneiForm поставлялся с некоторыми моделями сканеров. Однако после нескольких лет перерыва разработки, 12 декабря 2007 года анонсировано открытие исходных текстов программы, которое состоялось 2 апреля 2008 года.
По умолчанию в Ubuntu 10.10 доступна достаточно старая версия 0.7. Однако после добавления соответствующего PPA можно стать обладателем версии 1.0. Для Cuneiform написаны два графических интерфейса - YAGF и Cuneiform-Qt .
Для тестирования я использовал версию 1.0.0, установленную из вышеуказанного PPA. Распознавание производилось с помощью команды вида:
В руководстве cuneiform приводится опция --fax, которая включает оптимизацию работы программы для распознавания документов, переданных с помощью факса, однако при ее использовании результат получается хуже, поэтому я не привел его в таблице.
GOCR - это свободная кроссплатформенная система оптического распознавания текстов, работающая из командной строки. Программа пока находится в ранней стадии разработки, поэтому имеет ряд серьезных недостатков (например, распознает только одноколоночный текст). Кроме того, изучение man-страницы показало, что опций, позволяющих задать язык распознавания, программа не имеет, что подтвердилось экспериментом - русский текст gocr пытается распознать как английский. Естественно, в таблицу я данную программу включать не стал.
Ocrad
Tesseract
Tesseract - свободная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х. Затем ее разработка была заморожена на 10 лет. В августе 2006 г Google купил её и открыл исходные тексты под лицензией Apache 2.0 для продолжения разработки. В настоящий момент программа уже работает с UTF-8, поддержка языков (включая русский с версии 3.0) осуществляется с помощью дополнительных модулей.
Так как в репозиториях Ubuntu присутствует 2-я версия программы, а русский язык поддерживается только с релиза 3.0.0, программу я собирал из исходных текстов по инструкциям, найденным в сети.
Итак, скачиваем здесь архив с исходными текстами (в моем случае это tesseract-3.00.tar.gz, но с выходом новых версий название может быть другим), распаковываем его и переходим в директорию с исходными кодами.
Для корректной работы tesseract необходим пакет leptonica - ПО с открытым исходным кодом, необходимое для приложений, работающих и анализирующих изображения. Устанавливаем его:
Кроме того, для работы tesseract необходимо установить следующие пакеты: libpng12-dev, libjpeg62-dev, libtiff4-dev, zlib1g-dev, libtool build-essential. Устанавливаем и их, а затем из директории с исходным кодом начинаем конфигурирование и сборку программы:
При подтверждении опций необходимо изменить имя пакета (номер 2) на tesseract-ocr.

Все остальные опции принимаем по умолчанию. В результате будет установлен tesseract 3.0, а также собран deb-пакет, поэтому в следующий раз программу можно будет устанавливать обычным способом с помощью GDebi.
С первого раза программа у меня не собралась, пожаловавшись на отсутствие каталога /usr/local/share/tessdata. После того, как я создал его вручную, процесс завершился благополучно.
Теперь необходимо скачать с сайта программы пакет поддержки русского языка (rus.traineddata.gz), распаковать его и скопировать содержимое архива (а это должен быть один файл rus.traineddata) в директорию /usr/local/share/tessdata/.
Изображения перед распознаванием необходимо прнобразовать в формат tiff.
Для распознавания я использовал команду вида:
Если программа не заработала и возникают ошибки, связанные с отсутствием необходимых библиотек или правами доступа, выполните следующие команды:
Теперь все должно работать.
Для tesseract имеется графический интерфейс tesseract-gui , который тоже надо собирать из исходного кода. У меня он запустился, но распознавать текст почему-то не захотел. Еще есть система OCRopus , которая может использовать движок tesseract. Собственно поэтому я ее отдельно рассматривать не стал.
SILVERCODERS OCR Server
Данная программа представляет собой мощную коммерческую серверную систему распознавания, предназначенную для предприятий и поддерживающую 189 языков, среди них и русский. Она разработана специально для интегрирования в корпоративные системы документооборота. Триальной версии для свободного скачивания нет, поэтому опробовать мне эту систему не удалось.
Free OCR
Free OCR - бесплатный онлайн-сервис для оптического распознавания текста, использующий движок tesseract. Размер загружаемого изображения ограничен 2 Мб. Поддерживаются форматы JPG, GIF, TIFF BMP и PDF (только первая страница, в скором времени обещают поддержку первых 10 страниц). Также, существует лимит на 10 изображений в час.
Сервис распознает множество языков - русский, украинский, английский, немецкий, французский, турецкий, большинство восточноевропейских языков.
img2txt
img2txt - многоязычный онлайн-сервис для оптического распознавания текста. Поддерживаются форматы JPG, PNG, TIFF с размером файла до 2 Мб. В будущем обещают поддержку PDF и DJVU. На Википедии сервис обозначен как коммерческий и проприетарный, однако на самом сайте никакой информации об типе лицензии и используемом движке нет. Мои три тестовые страницы распознались без проблем. Никакой оплаты или хотя бы регистрации не просили.
OnlineOCR
NewOCR
NewOCR - бесплатный OCR сервис, поддерживающий 29 языков распознавания, включая русский. Позволяет загружать файлы в форматах JPEG, PNG, GIF, BMP, многостраничный TIFF размером до 5 Мб, а также многостраничные PDF размером до 20 Мб. Поддерживается многоколоночное форматирование текста.
Кроме того, необходимо отметить, что на рынке имеется еще одна коммерческая система распознавания от компании vividata , однако стоимость этой программы составляет $2400 (!) плюс по $100 за каждый дополнительный язык, отдельная плата, например, за модуль вывода в PDF ($1200) и т.д., поэтому я даже не стал заморачиваться с ее установкой. Ко всему прочему программа видимо очень давно не обновлялась (файлы в установочном архива датируются 2001 годом) и сами разработчики сомневаются в том, что она заработает на современных дистрибутивах. Поэтому тестировать vividata я не стал.
Также я решил включить в таблицу Google Docs, так как эта служба в настоящее время также позволяет производить распознавание русского текста. По имеющимся данным она использует tessract, однако нельзя исключить, что в своем сервисе Google использует какие-нибудь дополнительные наработки, поэтому интересно сравнить ее с остальными.
Результаты сравнительного тестирования систем оптического распознавания
| Программа (сервис) | Точность распознавания, % | ||
| Образец 1 | Образец 2 | Образец 3 | |
| FineReader for Linux | 100% | 100% | 87% |
| FineReader Online | 100% | 100% | 94% |
| Cuneiform 1.0.0 | 94% | 94% | 17% |
| Tesseract 3.0.0 | 97% | 98% | 5% |
| Free OCR | 96% | 93% | 61% |
| img2txt | 96% | 94% | 24% |
| NewOCR | 94% | 94% | 41% |
| Google Docs | 93% | 96% | 58% |
Выводы
Результаты, приведенные в таблице, показывают, что при хорошем качестве распознаваемого материала все участвовавшие в тестировании программы обеспечивают высокое качество распознавания, причем снижение разрешения с 300 до 200 dpi практически не влияет на результат. В то же время при распознавании некачественного материала ABBYY Fine Reader явно вырывается вперед, что неудивительно, учитывая ресурсы, задействованные в разработке данного приложения. Однако в целом можно отметить, что широко распространенное суждение о том, что для Linux нет хороших систем оптического распознавания текста, сегодня уже не выдерживает критики.
Для нерегулярного домашнего применения подойдет любая из представленных в обзоре бесплатных систем, а для организации, деятельность которой связана с частым использованием систем распознавания, особенно если дело касается факсов и другого материала посредственного качества, стоит подумать о покупке Fine Reader, тем более, что открытый API позволяет интегрировать его в любую корпоративную систему документооборота.
Знаете как называлась эта статья вначале? Она называлась «Бесплатные программы для распознавания текста (OCR) под Windows»… Задумка была рассмотреть программы, которые используют движок для распознавания текста tesseract-ocr (сейчас его развивает Гугл). Сначала намечался обзор по большому количеству программ, потом их осталось три, потом я хотел рассказать о двух программах, которые бесплатные, но могут конкурировать с ABBYY FineReader, затем я решил, что и одна программа — тоже неплохо. Но, в конце-концов, я пришёл к выводу, что программы или бесплатные или хорошие (хотя бы рабочие).
Если вы читаете эту статью, значит с распознаванием текста на Linux мне повезло больше. Почему tesseract-ocr и почему на нём сошёлся свет клином? tesseract-ocr — это бесплатный, с открытым исходным кодом движок, который когда-то давно показывал хорошие результаты, потом долго, до 2006 года его никто не развивал. А с 2006 года за него взялась Гугл. Проект не заброшен, в настоящее время примерно раз в год происходят обновления версии. Гугл некачественно не делает, и сейчас можно констатировать, tesseract-ocr — это хороший бесплатный движок для распознавания текста. Дело в том, что разработать собственную систему OCR, пожалуй, под силу только большим корпорациями и распространяться эта система может, следовательно, только как коммерческий продукт. В результате бесплатные программы для распознавания текста являются, фактически, оболочкой (надстройкой, графическим интерфейсом) для одного или нескольких бесплатных движков распознавания текста. tesseract-ocr — вещь хорошая и распознаёт хорошо (на уровне коммерческих продуктов), но кому интересно работать в командной строке, чтобы её использовать? Кому интересное распознавать по одному изображению? Кто бы отказался от возможности пакетной обработки графических файлов, в том числе PDF, в качественном пользовательском интерфейсе?
Сейчас, по сути, мы и будем оценивать качество реализации пользовательского интерфейса и других полезных функций в программах, которые используют tesseract-ocr в качестве своего движка, важнейшего компонента.
И ещё важное замечание. Если кто-то ругает бесплатную программу для распознавания текста, это совсем не значит, что программа плохая и что она будет плохо работать. Вполне возможно, что тот, кто ругает программу по распознаванию текста (особенно указывая на низкое качество распознавания), использует другой движок, другой OCR (например, вместо tesseract-ocr использует cuneiform или какой-нибудь ещё). Не нужно этому доверять. В программе (многие из них это поддерживают), просто выберите хороший движок OCR и, весьма вероятно, результат вас поразит.
Итак, приступим к тестированию хороших прграмм для распознавания текста (OCR) под Linux.
Предварительная подготовка
- tesseract-ocr — движок для распознавания текста (может использоваться в командной строке)
- tesseract-ocr-rus — содержит дополнительные данные для русского языка
- cuneiform — ещё один движок OCR
программы, на котором вы можете найти разные ссылки, в том числе на скомпилированные пакеты, исходный код, блог автора (там есть его семейная фотография — мне было любопытно посмотреть) и пр.
В репозиториях Linux Mint версия OCRFeeder 0.7.11, а последней версией, выпущенной автором, является OCRFeeder 0.8.1. Свежие версии добавили новые функции (например, поддержка многостраничных файлов изображений TIFF) и исправили разные ошибки. Поэтому если вы можете ставить программы из исходных кодов — то стоит сделать так.
Все остальные, ставьте из репозитория, даже та версия, которая там есть, работает прекрасно.
После установки в меню «Офис» появляется значок программы. Запускаем её. Всё интуитивно понятно. Можно целиком импортировать PDF файл. Можно распознавать отдельные страницы или файл полностью. Результат распознавания текста выше всякий похвал! Я специально взял для пример PDF файл со средним качеством сканирования.
Я в восторге от программы: распознаёт быстро, поддерживает пакетную обработку изображений, без проблем импортирует PDF файлы, может распознавать как по одной странице, так и весь файл целиком, высокое качество распознавания текста (сильно зависит от качества сканирования!), можно сохранить все распознанные страницы в один файл, можно сохранять в .odt (формат LibreOffice). Я попробовал ещё один документ, с высоким качеством сканирования — результат отличный.
Следующей в нашем почётном списке качественных программ для распознавания текста становится YAGF.
Думаю, что русскоговорящим будет особенно приятно узнать, что автором является русскоговорящий Андрей Боровский (не знаю где он живёт и какое у него гражданство). Русскоязычная страничка программы
Программа активно развивается, и опять, в репозитории только версия YAGF 0.9.2 от 3 сентября 2012 года (!), а крайней, которую выпустил автор, является YAGF 0.9.5 от 28 января 2015 года. За это время была добавлена поддержка многостраничных TIFF изображений, импорт DjVu, автосохранение, новые языки и т. д. Поэтому если вы знаете, что нужно делать с тарболом, то рекомендую ставить из исходных кодов. Остальные довольствуемся тем, что есть в репозитории.
После установке в меню Офис появится ещё один значок. Запускаем программу. Всё интуитивно понятно, только при импорте PDF файла программа предлагает выбрать страницы (диапазон страниц), которые нас интересуют и папку, куда будут сохранены промежуточные изображения (на которые будет разбит PDF файл).
Далее всё как и с предыдущей программой: возможность распознать отдельные страницы или файл целиком, высокое качество распознавания, возможность сохранить все страницы в один файл, для сохранения можно выбрать формат простого текстового файла или HTML.
В своём обзоре я использовал не самые новые версии хороших бесплатных программ для распознавания текста на Linux. Я доволен результатом. Будем наедятся, что авторы не забросят свои наработки.
Честно говоря, меня поразила низкая активность пользователей, например, в комментариях (как в репозиториях, так и в блоге OCRFeeder). Неужели это интересно четверым людям? Неужели никто больше не сканирует? Судя по популярности пиратского ABBYY FineReader, вопросы сканирования интересуют очень многих. Пользователи устанавливают в свои компьютеры несколько десятков крякнутых программ, а затем рассказывают, что под Linux нет специализированного софта. Софта предостаточно, и бесплатные версии, доступные для свободной установки на Linux, зачатую, не уступают дорогим коммерческим продуктам под Windows.
Тем не менее, не нужно обольщаться. Экосистема свободного софта довольно хрупкая. Каждая из рассмотренных программ разрабатывается одним человеком. Т.е. если он слишком занят, или потерял интерес — программа становится заброшенной.
Я, как и многие из читающих, не могу помочь написанием кода или материально (мне бы самому кто помог). Но я, как минимум, могу помочь популяризировать проекты с открытым исходным кодом. И многие из читающих это могут сделать — рассказать о них в блоге, на своём сайте или в социальной сети.
Я призываю вас делать это. Не нужно воспринимать программы с открытым исходным кодом (и вообще бесплатные проекты) как данность. Нужно помогать авторам в меру своих сил. Как минимум, то, что может сделать каждый из нас, это рассказать об этих проектах, стремиться сделать их популярными. Ведь популярному проекту проще найти помощь, поддержку среди обширной аудитории.
Читайте также: