
Программа для мониторинга для linux

Есть много полезных инструментов, которые помогают отслеживать нагрузку на сервер, начиная с утилит Linux и заканчивая специализированными службами.
Простые утилиты Linux показывают текущее потребление памяти для каждого процесса, нагрузку на CPU, свободное место на диске и статистику по трафику.
Кроме того, есть платные и бесплатные сервисы, которые круглосуточно отслеживают состояние вашего сервера, регистрируют сбои в его работе или в сетевой доступности, а также проверяют производительность приложений.
Использование ресурсов
Один из самых инструментов для проверки использования ресурсов процессами. Утилита top выдаёт простую таблицу с текущим потреблением ресурсов, где сверху указаны процессы с наибольшей нагрузкой.
Непосредственно перед таблицей приводится некоторая общая статистика, включая среднюю нагрузку на CPU за последнюю минуту, 5 минут и 15 минут. Также показано потребление памяти, файла подкачки и состояние процессов.
Список обновляется в реальном времени: можете вывести его на второй монитор и наблюдать постоянно.
Хотя утилита top поставляется почти с каждым дистрибутивом, в большинстве репозиториев также доступна для скачивания улучшенная версия htop .
Установка htop на Ubuntu:
Здесь мы видим почти такую же выдачу, но с подсветкой разными цветами и более интерактивную:
Верхняя часть здесь яснее и лучше организована.
Вот некоторые ключи для более эффективного использования htop :
- M: сортировка процессов по использованию памяти
- P: сортировка процессов по использованию CPU
- ?: справка
- k: прекратить текущие/помеченные процессы
- F2: настройка (здесь можно выбрать опции для отображения)
- /: поиск процессов
Сетевой трафик
nethogs
nethogs — самая простая утилита для просмотра, сколько трафика приходится на каждую службу. На Ubuntu утилита устанавливается следующей командой:
Затем её можно запустить без ключей. Выдача простая:
Есть всего несколько опций для изменения выдачи:
- m: переключение между kb/s, kb, b, mb
- r: сортировка по полученному трафику.
- s: сортировка по отправленному трафику
- q: выход
IPTraf
IPTraf — ещё один способ мониторинга сетевого трафика, с большим количеством опций. Установка на Ubuntu:
Эта утилита предлагает выбрать один из интерактивных интерфейсов:
Например, для обзора всего сетевого трафика выбираем первый пункт меню:
Чтобы IP-адреса резолвились в домены, нужно в конфигурации выбрать пункт 'Reverse DNS lookups'.
Вместе просмотром трафика по портам есть вариант просмотра трафика по сервисам (опция 'TCP/UDP service names'). С обеими включёнными опциями выдача будет выглядеть примерно так:
Есть ещё несколько других интерфейсов, которые можете изучить самостоятельно.
netstat
Утилита netstat — очень гибкий и мощный инструмент для сбора сетевой информации.
По умолчанию netstat выдаёт список открытых сокетов:
Если добавить опцию -a , он покажет список всех портов:
Флаги -t или -u фильтруют TCP- или UDP-соединения, соответственно. Флаг -s выводит статистику. Для постоянного обновления выдачи нужно запускать команду с ключом -c .
Место на диске
Стандартная утилита для просмотра информации о смонтированных разделах — это df . Она выводит список подключенных устройств и информацию о занятом месте.
По умолчанию выдача в байтах, что не очень удобно. Параметр -h активирует выдачу в мегабайтах и гигабайтах:
Для просмотра всего места на всех дисках добавляем опцию --total .
Утилита df позволяет быстро получить общий обзор. Для более детальной информации лучше подходит программа du , которая анализирует текущую директорию и любые поддиректории. Выдача по умолчанию выглядит так:
Опять же, более удобная для восприятия выдача включается ключом -h .
Просмотр размеров файлов и директорий включается флагом -a , общий итог — флагами -c (подробности и сумма) и -s (только сумма).
Улучшенные версии
Улучшенные версии df и du называются pydf и ncdu, на Ubuntu они устанавливаются командами apt-get install pydf и apt-get install ncdu . Они организуют красивую выдачу в псевдографике с расцветкой:
Здесь можно перемещаться по файловой системе клавишами со стрелками.
Использование памяти
Самый простой способ просмотра текущего использования оперативной памяти — команда free . Выдача без опций выглядит таким образом:
Запуск с ключом -m генерирует выдачу в мегабайтах.
Средняя строка -/+ buffers/cache показывает значение используемой памяти минус сумма буферов/кэша, а также количество свободной памяти плюс сумма буферов/кэша.
Дело в том, что Linux как большинство современных ОС пытается использовать максимальный объём доступной оперативной памяти под буферы и кэш. Поэтому имеет значение вторая строка, которая показывает реальный объём потенциально доступной оперативной памяти для приложений, если игнорировать буферы и кэш. Этот объём будет освобождён автоматически, если он понадобится для приложений.
vmstat
Команда vmstat выводит различную информацию о системе, включая память, файл подкачки, операции ввода-вывода и нагрузку на CPU.
В первой колонке r указано количество активных процессов, во второй — количество процессов в состоянии непрерываемого ожидания.
Колонки si и so показывают объём памяти, которая считывается из файла подкачки и записывается в него, соответственно.
Далее показано количество блоков, которые получены или отправлены на устройство блочного ввода вывода (bi, bo), количество прерываний в секунду, включая таймер (in), количество переключений контекста в секунду (cs) и статистика по CPU: процент времени, затраченного на обработку кода в пользовательском пространстве (us), на обработку кода ядра (sy), в спящем состоянии (id) и ожидании ввода-вывода (wa), а также времени, «украденного» у виртуальной машины (st), то есть когда виртуальный CPU ожидает действия реального CPU, когда гипервизор обслуживает другой виртуальный процессор.
Флаг -S M активирует выдачу в мегабайтах. Запуск с опцией -s показывает общую статистику.
Если вам необходимо круглосуточно отслеживать состояние сервера (память, CPU, свободное место, производительность, время отклика и проч.), то можно воспользоваться бесплатным или платным сервисом мониторинга. Таких сервисов много, вот небольшой список в алфавитном порядке:
(бесплатная адаптация Nagios Core)
(бесплатная версия называется Nagios Core)
(бесплатно)
(бесплатный системный монитор)
Для примера, рассмотрим три относительно популярных сервиса для мониторинга.
SolarWinds Server and Application Monitor
Один из самых продвинутых серверных мониторов на рынке — SolarWinds Server and Application Monitor (SAM). Хотя инструмент устанавливается только на Windows Server 2016+, но может отслеживать любое оборудование, в том числе Linux-серверы.

Монитор отслеживает производительность сервера, сообщает о проблемах, а также предоставляет некоторые возможности по управлению: позволяет перезапускать сервер, снимать процессы и перезапускать службы, то есть это инструмент не только для мониторинга, но и для администрирования.

Программа лучше подходит для крупных корпораций. Заявлена совместимость с серверами Dell PowerEdge, HP ProLiant, IBM eServer xSeries, Dell PowerEdge Blade, HP BladeSystem, Microsoft Windows Server и VMware vSphere. В то же время SAM мониторит и облачные инстансы AWS и Azure.

Он показывает статистику по времени отклика, загрузке CPU, памяти и др. Отслеживается производительность отдельных приложений: встроена поддержка более 1200 разных приложений. Также проверяется состояние оборудования: использование CPU, нагрузка на диски, энергопитание, статус вентиляторов и т. д. Статусы кодируются цветом от зелёного до красного, чтобы было легко оценить здоровье системы с первого взгляда.

Монитор автоматически определяет новое оборудование и программное обеспечение в вашем кластере, сразу добавляя его на панель мониторинга. Это одна из ключевых особенностей SAM, также как максимальная автоматизация — подготовленные шаблоны для автоматизации регулярных задач по мониторингу и обслуживанию, заготовки для отчётов и уведомлений.

Обычно у таких сервисов имеется бесплатный пробный период, а стоимость может зависеть от набора используемой функциональности. Здесь тоже есть пробный период, а стоимость SolarWinds Server and Application Monitor начинается от 1275 евро в минимальной функциональности.
Navicat Monitor
Другой пример — Navicat Monitor, который специализируется на мониторинге баз данных. Он поддерживает MySQL, MariaDB, SQL Server, а также облачные СУБД, такие как Amazon RDS, Amazon Aurora, Oracle Cloud, Google Cloud и Microsoft Azure.

Стандартный вид

Компактный вид
Монитор отслеживает время выполнения конкретных запросов, запуская их с заданным интервалом.


Кроме запросов к БД, периодически отправляются и другие запросы к серверам для мониторинга показателей производительности системы ввода-вывода, сети и проч. Собирается статистика по использованию CPU, загрузке памяти и другие стандартные метрики.

Архитектура Navicat Monitor не предусматривает установку программного обеспечения на объекты мониторинга
Минимальная цена Navicat Monitor — $32,99 за один токен в месяц (один токен соответствует мониторингу одного сервера или четырёх баз Azure). Есть полнофункциональная пробная версия на 14 дней.
Zabbix
Zabbix — это бесплатный опенсорсный инструмент, который отслеживает состояние сети, приложений и самого сервера. Поставляется с готовыми шаблонами для мониторинга популярных серверов и ОС, включая HP, IBM, Lenovo, Dell, Linux-серверы, Ubuntu и Solaris. За годы существования Zabbix сообщество подготовило шаблоны для различных сценариев.

Ключевые модули Zabbix следят за нагрузкой CPU, использованием памяти, уровнем ошибок ввода-вывода, свободным местом на диске, статусе вентиляторов, температурой и характеристиками системы питания. Сетевой модуль проверяет трафик, доступность сети, уровень потерь пакетов, качество TCP-соединений и пропускную способность маршрутизаторов.
Zabbix ведёт список установленного программного обеспечения и версий прошивок, чтобы сигнализировать о несанкционированной установке ПО.

Системный администратор может запрограммировать в Zabbix уведомления по произвольным условиям, а также изменить важность действующих уведомлений. На панели управления можно добавить пользователей — и направлять каждому из них определённые типы уведомлений, а скрипты автоматизации позволяют автоматически заводить задачи и присваивать их сотрудникам.
Благодаря функции удалённого доступа и управления Zabbix можно назвать хорошим инструментом администрирования сервера.
Надёжный сервер в аренду и правильный выбор тарифного плана позволят меньше отвлекаться на неприятные уведомления мониторинга — всё будет работать без сбоев и с очень высоким uptime!
Программы мониторинга системы для Linux. Программы для отслеживания использования системных ресурсов.
nvtop

nvtop (NVidia Top) — консольная утилита для мониторинга состояния видео-карт Nvidia. Выводит состояние памяти, температуру, список процессов, график использования и другую информацию.
GSmartControl

GSmartControl — утилита для мониторинга состояния, отображения статуса и настройки параметров жестких дисков и SSD. Является графическим интерфейсом для утилиты smartctl.
KDiskMark

KDiskMark — утилита для тестирования производительности HDD и SSD.
Cpupower-gui

Cpupower-gui — простая утилита для ограничения максимальной и минимальной частоты процессора.
GtkStressTesting

GtkStressTesting — утилита для стресс-тестирования компонентов компьютера.
GreenWithEnvy

GreenWithEnvy (GWE) — утилита для разгона, управления скоростью вращения вентиляторов, получения информации видео-карт от NVIDIA.
Glances

Glances — консольный монитор системных ресурсов, который отображает максимум информации на одном экране.

Top — консольный таск-менеджер для Linux. Позволяет просматривать информацию о процессах и загруженности ресурсов.
Stacer

Stacer — утилита для мониторинга, оптимизации, настройки и очистки системы.

CPU-X — программа для просмотра основной информации о комьютере (процессор, кэш, материнская плата, оперативная память, операционная система, графическая подсистема).
Psensor

Psensor — простая утилита с графическим интерфейсом для мониторинга температуры оборудования компьютера.
Gnome Logs

Gnome Logs (или просто Logs) — простая программа для просмотра системных журналов (systemd).
Очень долго хотел написать статью, но не хватало времени. Нигде (в том числе на Хабре) не нашёл такой простой альтернативы munin, как описанная в этой статье.

Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.

Munin
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
Выполняем команды:
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Альтернативы munin для мониторинга нескольких серверов
- количество метрик не меньше чем у munin (у него их около 30 базовых графиков и ещё около 200 плагинов в комплекте)
- возможность написания собственных плагинов на bash (у меня было два таких плагина)
- иметь небольшие требования к серверу
- возможность вывода метрик с разных серверов на одном графике без правки конфигов
- уведомления на почту, в slack и telegram
- Time Series Database более мощную чем RRDtool
- простая установка
- ничего лишнего
- бесплатно и с открытым исходным кодом
Cacti
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.

Ganglia
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
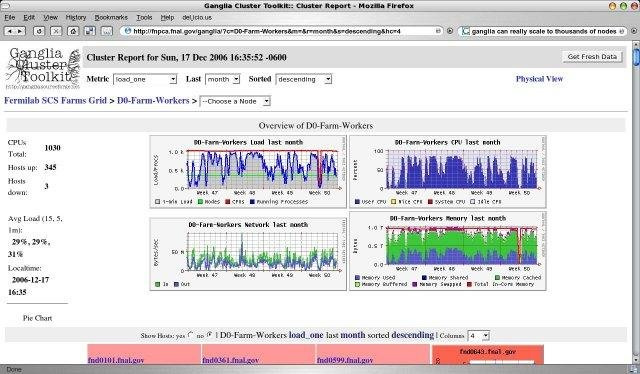
Collectd
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.

Graphite
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.

Zabbix
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.

Nagios
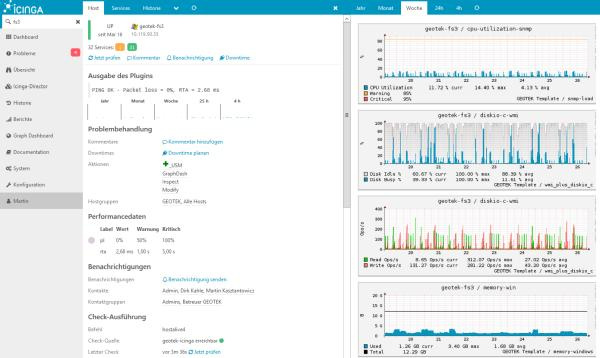
Icinga
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Небольшое отступление
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Netdata
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.

Prometheus
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.

InfluxData (TICK Stack)
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.

Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
Выбираем лучшее
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
Telegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
Акцент на безопасность
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Update: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
1) сначала посмотрел на сравнение систем мониторинга на английской википедии
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.

Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl
P.S.: если я опустил какие-то моменты в описании настройки-установки, то пишите в комментариях и я обновлю статью. Опечатки — в личку.
P.P.S.: конечно этого никто не услышит (исходя из предыдущего опыта написания статей), но я всё равно должен попробовать: не задавайте вопросы в личку на хабре, вк, фб и т.д., а пишите комментарии здесь.
P.P.P.S.: размер статьи и потраченное на неё время сильно выбились из начального «бюджета», надеюсь, что результаты этой работы будут для кого-то полезны.
Программы мониторинга системы для Linux. Программы для отслеживания использования системных ресурсов.
ScreenFetch
screenFetch — простая консольная утилита для вывода информации о системе и ресурсах.
HardInfo

HardInfo — программа для просмотра подробной информации об оборудовании и системе, мониторинга системы, построения отчетов и запуска бенчмарков.
Gnome System Monitor

Gnome System Monitor — программа для мониторинга работы системы. Является штатным системным монитором в рабочей среде Gnome.

CPU-G — программа для просмотра информации о компьютере. В CPU-G можно просматривать информацию об оборудовании компьютера и краткую информацию о системе.

I-Nex — программа под Linux для отображения информации об оборудовании компьютера (аналогично популярной программе CPU-Z). Можно просмотреть информацию о компонентах вашего компьютера и некоторые системные вещи.
Monitorix

Monitorix — бесплатный монитор системных ресурсов. Позволяет просматривать загруженность и использование множества системных ресурсов (как аппаратных, так и программных).
Saidar

Saidar — простая утилита для мониторинга ресурсов компьютера. Программа отображает загруженность процессора, количество свободной и занятой оперативной памяти, использование Swap раздела.

Htop — продвинутый монитор системных ресурсов для Linux. Утилита htop предназначена для расширенного анализа использования системных ресурсов процессами в реальном времени.
В этой статье мы поговорим про системы мониторинга в Linux. Они позволяют отслеживать различные параметры работы сервера Linux, нагрузку на процессор, диск, доступное дисковое пространство и оперативную память. Если у вас под управлением находится только один сервер, то возможно системы мониторинга вам и не нужны. Вы можете в любой момент подключится к серверу по SSH и посмотреть все основные параметры с помощью htop.
Но если вы управляете несколькими производственными серверами, вам будет необходимо всегда иметь общее представление о том, что на них происходит. Системы мониторинга позволяют записать и посмотреть какой была нагрузка на сервер в тот или иной момент времени, а также собрать данные из кластера серверов и предоставить их в удобном формате.
1. Zabbix

Это одна из самых популярных промышленных систем мониторинга для Linux. Zabbix поддерживает сбор информации с нескольких серверов, мониторинг таких часто используемых служб, как Apache, Nginx, PHP-FPM, MySQL, PostgreSQL, Tomcat и многих других, а также обнаруживает и сообщает об различных типичных ошибках. Есть возможность отправки уведомления на электронную почту при возникновении определённого события. Это позволяет реагировать очень быстро на любые ошибки. Все настройки выполняются с помощью удобного веб-интерфейса и хранятся в базе данных MySQL. Вы также можете посмотреть текущие значения различных метрик сервера в разделе Monitoring -> Last data. Доступны графики для основных отслеживаемых параметров.
2. Nagios

3. Cacti

Эта система мониторинга тоже довольно старая и интерфейсом похожа на Nagios. Но цель у неё другая. Cacti разработана для просмотра графиков состояния различных системных параметров за определённое время. Тем не менее, при необходимости здесь тоже можно настроить уведомления. Очень часто используется не столько для мониторинга серверов, сколько для отслеживания нагрузки на сеть с помощью SNMP (Simple Network Management Protocol). Cacti достаточно сложная в настройке, потому что для неё надо создать базу данных, пользователя и установить PHP, Apache и всё подготовить.
4. Monit

Monit - это очень простой инструмент для мониторинга состояния серверов с открытым исходным кодом. Установка программы сводится к загрузке пакета из официальных репозиториев и правки одного конфигурационного файла. Но практически вся настройка мониторинга выполняется в конфигурационных файлах. Веб-интерфейс можно использовать только для просмотра информации о работе сервера и отслеживаемых сервисов. Можно отслеживать доступность портов на удалённых серверах, а также при не доступности какого либо порта или сервиса отправлять уведомление на почту.
5. Icinga 2

Icinga 2 - это улучшенная версия открытой системы мониторинга Icinga, которая в свою очередь была создана как форк Nagios в 2009 году. Для её работы вам уже понадобится создать несколько баз данных MySQL или PostgreSQL. Это одна из программ, имеющих современный интерфейс, которым приятно пользоваться. Позволяет отслеживать события в системе, а также отправлять уведомления на почту при возникновении проблем. Отслеживается место на диске, раздел подкачки, доступность запущенных сервисов, нагрузка на процессор с помощью load_average, а также доступные для обновления пакеты.
6. Observium

Observium - инструмент, написанный на PHP, позволяющий выполнять мониторинг доступности серверов в сети, а также сетевую нагрузку на их интерфейсы с помощью SNMP. Программа имеет простой и приятный интерфейс и её не очень сложно установить. Отслеживаемые серверы можно добавить как с помощью веб-интерфейса, так и в командной строке. Можно настроить отправку уведомлений если какой-либо из серверов стал недоступен.
7. Netdata

8. Munin

Munin - ещё одна очень простая система мониторинга с открытым исходным кодом, использующая RRDTool для генерации графиков. Функциональность стандартная для подобного рода систем - можно просматривать графики производительности, а если случается что-то непредвиденное - то отправлять уведомления на почту. Довольно простая в установке, потому что есть в официальных репозиториях многих дистрибутивов. Можно отслеживать не только сервер, на котором установлена система, а и другие серверы.
9. Prometheus

Это современная система мониторинга Linux с открытым исходным кодом, полностью написанная на Go. Она состоит из нескольких компонентов, которые надо устанавливать отдельно. Основной из них - сервер Prometheus, собирающий данные со всех хостов, позволяющий их анализировать и выводить графики. Для установки на удалённые машины используется компонент Node_exporter - собирающий данные и передающий их на сервер. А для отправки уведомлений об внештатных ситуациях используется компонент Alert_manager. Система не очень сложная в настройке и довольно удобная. Первый релиз состоялся в 2014 году, поэтому всё выглядит довольно современным. В веб-интерфейсе выводится только информация, большинство настроек выполняются редактированием YAML файлов.
10. Graphite

Это более старая система мониторинга, по сравнению с Prometheus, написанная на Python. Graphite тоже состоит из нескольких компонентов. Это агент для сбора данных Carbon, база данных Whisper и интерфейс для отображения графиков Graphite-Web. Как и в большинстве предыдущих систем здесь можно отправлять уведомления о возникновении проблем, а также просматривать графики различных параметров работы сервера.
Сборка из агента, базы данных и веб-интерфейса
Если вас не устраивает ни одна из существующих систем мониторинга, вы можете собрать свою на основе отдельных компонентов. Использовать агент для сбора данных из одной системы, базу данных для хранения собранного, а также удобный веб интерфейс.
В качестве агента сбора данных можно использовать один из перечисленных выше от систем мониторинга или же отдельный, например, Collectd, Telegraf или другие. В качестве базы данных часто используют InfluxDB, написанную на Go, а в качестве веб-интерфейса очень популярна Grafana. Это очень простой и красивый инструмент для рисования графиков на основе меняющихся со временем данных.
Выводы
В этой статье мы рассмотрели системы мониторинга для Linux, которые вы можете использовать в своих проектах. Конечно, это далеко не все решения, а только лучшие из них. Все программы доступны бесплатно или имеют бесплатную версию. А какие системы мониторинга используете вы для решения своих задач? Что-то было упущено в этом списке? Напишите в комментариях!
Читайте также: