
При копировании текста из pdf в word непонятные символы
там где? он скинул файл? мне теперь любопытно
с самой пдфкой ничего не сделал, нужно именно в изображение конвертнуть тем или иным способом
ну или можешь попробовать всю пдфку конвертнуть в жипег и разом прогнать
д
medical
equipment
МЕДИЦИНСКАЯ
БАЛЬНЕОЛОГИЧЕСКАЯ ВАННА
Technomex, Польша
T-MP DISCOVERY
T-MP UWM
Ванна T-MP Discovery предназначена для классических бальнеоло-
гических процедур с применением лекарственных настоев или ме-
дикаментов. Прекрасно подходит для принятия ванн использова-
нием местных минеральных вод.
Современный дизайн и эргономичная форма чаши ванны позволяют
пациенту расслабиться во время процедуры и обеспечивают более
эффективную терапию.
Дополнительными модификациями ванны являются:
• T-MP/B/Discovery - модель для грязевых процедур
• T-MP/S/Discovery — модель для солевых растворов
• T-MP/S/B/Discovery - модель для соленой воды, сероводорода
и грязевых ванн
• T-MP/K Discovery - модель для принятия ванн с углекислотой
СПЕЦИФИКАЦИЯ
Ванна T-MP UWM предназначена для проведения подводного руч-
ного массажа при помощи гибкого шланга со сменными наконечни-
ками. Интегрированные в конструкцию ванны регулятор давления и
манометр позволяют точно дозировать силу водяной струи, исходя-
щей из гидромассажного шланга от 0 до 6 бар (атмосфер).
Объем
Модель ванны
Тип
Габаритные
размеры (мм)
2200 x 950 x 980
01.501.119
T-MP Discovery
240
Электронная панель управления позволяет легко программировать
время автоматического гидромассажа. В зависимости от необходи-
мого эффекта для увеличения интенсивности воздействия в воду
могут добавляться биологически активные субстанции (масла, экс-
тракты трав).
Ванна имеет два уровня наполнения: на 200 и 350 литров.
01.501.121
T-MP/B/Discovery
240
2200 x 950 x 980
01.501.120
240
2200 x 950 x 900
T-MP/S/Discovery
T-MP/S/B/Discovery
01.501.124
240
2200 x 950 x 900
Вследствие небольшого объема ванна идеально подходит для про-
ведения ручного подводного массажа детей и подростков.
СПЕЦИФИКАЦИЯ
Модель ванны
Тип
Объем (л)
Габаритные
размеры (мм)
01.501.004
T-MP UWM
250
2080 x 840 x 740
СТАНДАРТНЫЕ ЦВЕТА ВАНН
2004
10217
6027

Електронні книги увійшли у наше повсякденне життя та продовжують зміцнювати свою позицію. PDF – один із найпопулярніших форматів, який можна зустріти на інтернет просторах, відвідуючи сайти та магазини. Але бувають прикрі ситуації, коли текст, який ми хочемо скопіювати, просто перетворюється на незрозумілі символи. Хтось на них каже ієрогліфи, хтось кракозябри… Як же виправити таку ситуацію?
Я не певен, що наступні поради допоможуть для всіх вирішити проблему, але часткове вирішення її все ж можливе.
Давайте зразу відкинемо відскановані та нерозпізнані PDF документи, із яких просто неможливо скопіювати текст. Це рівноцінне спробі копіювання тексту із звичайної фотографії, що зроблена на ваш смартфон. В такому випадку текст потрібно розпізнати спеціальною програмою, на кшталт ABBYY FineReader.
Наша книга (тестова) повністю підтримує копіювання тексту та зображень. Але при спробі перенести такий текст у Microsoft Office Word, можна бачити такі нечитабельні символи як на скриншоті зверху статті.
Спосіб 1 (довгий).
Вся проблема у шрифтах та системі кодування. PDF документ, із якого проводиться копіювання має вбудовані шрифти. І якщо такі шрифти відсутні у вашій операційній системі, то ви побачите такі кракозябри.
Щоб можна було бачити нормальні букви, при перенесенні тексту потрібно інсталювати відповідні шрифти.
Щоб дізнатися які саме потрібно інсталювати на комп’ютер шрифти, потрібно відкрити наш PDF документ підтримуваною програмою (на прикладі PDF-XChange Viewer ). Далі ідемо у «Файл» → «Свойства документа» (можна натиснути сполучення клавіш Ctrl + D).
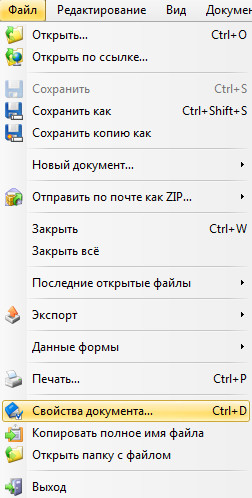
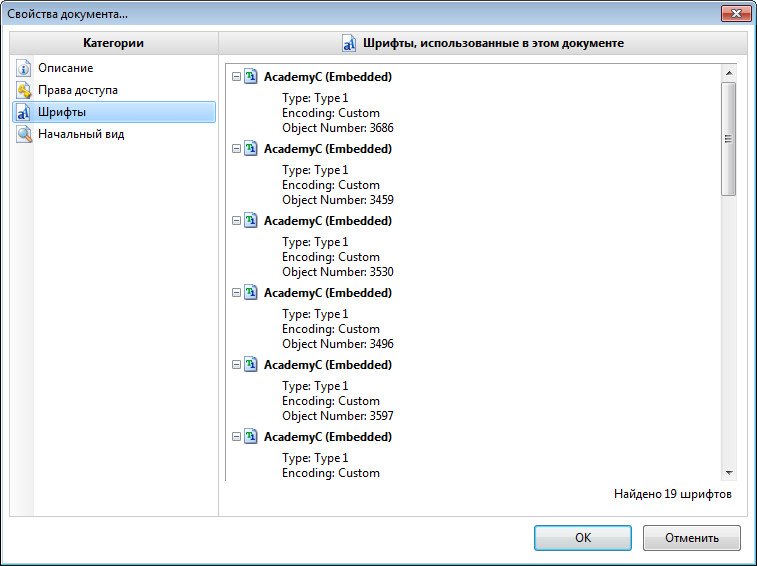
Далі натискаємо на параметр «Шрифты» і бачимо список шрифтів, які встановлені у документі. Їх і потрібно знайти в інтернеті та встановити на комп’ютер. Для цього на завантаженому шрифті два рази натискаємо лівою клавішею миші (тобто, відкриваємо його), а тоді натискаємо на кнопку «Установить».
Далі копіюємо та вставляємо текст із PDF документа, виділяємо його у Microsoft Office Word (або в іншому офісному редакторі, який у вас встановлений) та вибираємо із списку недавно інстальований шрифт. Все має бути нормально. Знизу на скриншоті видно, що я навмисне застосував потрібний шрифт лише на одне речення, іншу частину тексту прочитати неможливо.

Спосіб 2 (швидко та зручно).
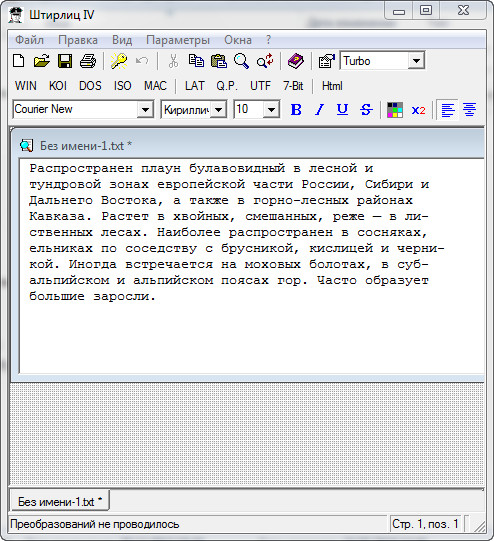
Інший , більш правильний та простіший варіант – це використання програми (або плагіна до редактора Notepad++ ), яка називається Shtirlitz. Програма стара, давно не оновлювалася, проте працює відмінно. Прямо на льоту виконується вставка нормального тексту. Ніяких шрифтів не потрібно. Після копіювання тексту із даної програми та подальшим вставлянням його в редактор Microsoft Office Word, всі букви та символи будуть читатися і із використанням будь-якого шрифту. Перший варіант не дає змоги змінити шрифт. Тобто, завжди, та на кожному комп’ютері потрібно буде інсталювати потрібні шрифти для читання лише певного документа. А якщо таких документів декілька сотень? Тому бажано скористатися цією програмою для декодування.
Спосіб 3 (онлайн).
Хто не хоче використовувати програму Shtirlitz або вона не працює, може використати наступні онлайн сервіси для перекодування (окремі сервіси мають обмеження по об’єму тексту).
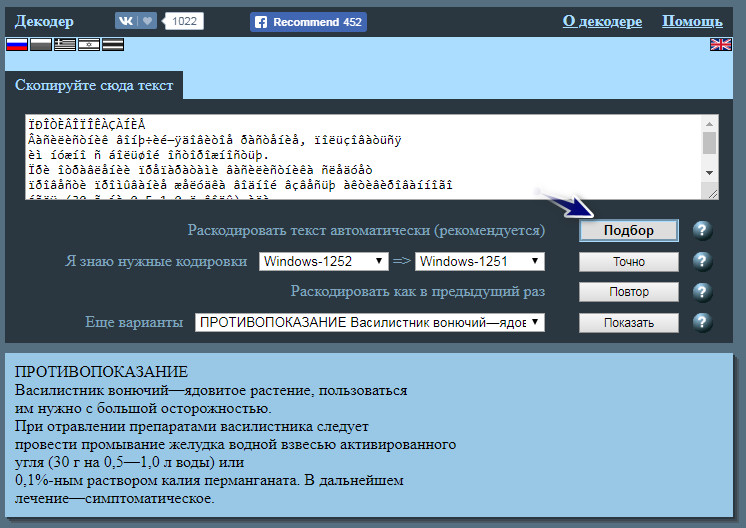
Там можна бачити вікно, де написано «Скопируйте сюда текст». Вставляємо наш незрозумілий текст та натискаємо на кнопку «Подбор». Такий спосіб буде правильно використати якщо для вас невідома система кодування. Декодер спробує підібрати її автоматично. Якщо ви знаєте вихідне кодування своєї кракозябри, то можете сміливо натискати кнопку «Точно», вказавши перед цим кодування, напроти тексту «Я знаю нужные кодировки».
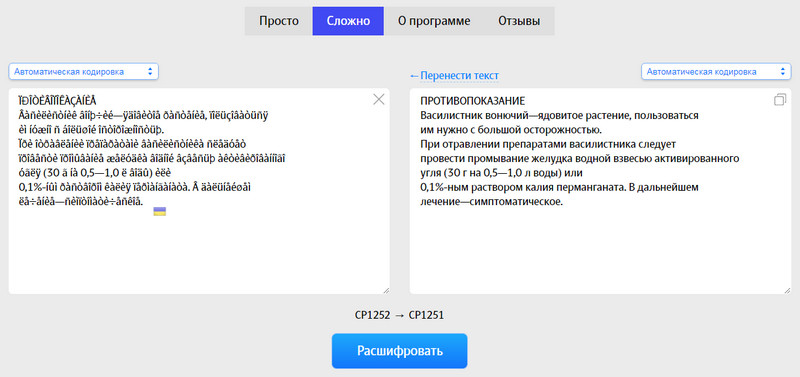
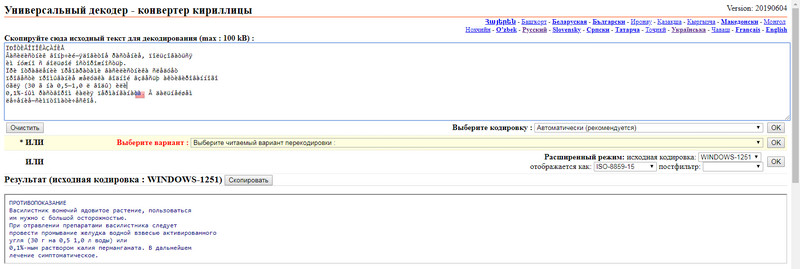
Є також два режими: автоматичний та режим експерта. У другому можна вказувати вихідне та кінцеве кодування. Рекомендується автоматичний режим. Після того як вставили текст, напроти слів «Выберите кодировку :», потрібно вибрати «Автоматически (рекомендуется)» та натиснути на кнопку «Ок».
Всі три сервіси відмінно працювали на моїй тестовій книзі у форматі PDF із кракозябрами.
Спосіб 4 (за допомогою макросів дл я Microsoft Office Word ).
Ще один варіант для програми Microsoft Office Word. Ніяких шрифтів ставити не потрібно. Створюємо макрос із наступним кодом:
Код 1: «Перекодування 1252 у 1251»
Sub Corr1252_1251()
Dim s$, i&, j&
s = Selection
For i = 1 To Len(s)
j = AscW(Mid$(s, i, 1))
If j < 256 Then
Mid$(s, i, 1) = Chr(j)
' Debug.Print i & vbTab & Mid$(s, i, 1) & vbTab & j & vbTab & Chr(j)
End If
Next
Selection.Text = s
End Sub
Код 2: «Перекодування 1252 у 1251 (врахування російської букви Ё)»
Sub changeToRus()
'
' Замена кракозябр на кириллические буквы
' CP1252 -> CP1251
'
For i = 192 To 255
a1 = i
a = Trim("^u") & Trim(Str(a1))
' Формирование запроса для поля Найти
sRus = Array("А", "Б", "В", "Г", "Д", "Е", "Ж", "З", "И", "Й", "К", "Л", "М", "Н", "О", _
"П", "Р", "С", "Т", "У", "Ф", "Х", "Ц", "Ч", "Ш", "Щ", "Ъ", "Ы", "Ь", "Э", "Ю", "Я", _
"а", "б", "в", "г", "д", "е", "ж", "з", "и", "й", "к", "л", "м", "н", "о", _
"п", "р", "с", "т", "у", "ф", "х", "ц", "ч", "ш", "щ", "ъ", "ы", "ь", "э", "ю", "я")
' Формирование массива кириллических букв для поля Заменить
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = a
.Replacement.Text = sRus(i - 192)
.Forward = True
.Wrap = wdFindContinue
.MatchCase = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
' Выполнение замены по тексту
Next i
' Замена Ё и ё
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(168)
.Replacement.Text = "Ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(184)
.Replacement.Text = "ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Виділяємо вставлений текст з ієрогліфами. Тоді запускаємо макрос на виконання та отримуємо нормальний текст, який можна спокійно редагувати, змінювати шрифти і так далі.
Для додавання готового макросу у Word робимо наступне:
Відкриваємо редактор та переходимо у «Вид».

Там знаходимо кнопку « Макросы » та натискаємо на неї.
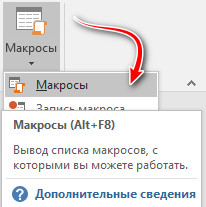
Даємо для макросу ім’я (будь-яке, воно буде автоматично змінене при повному копіюванні коду, що вище).
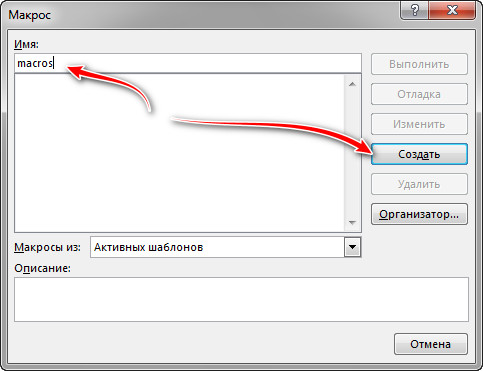
Відкриється вікно у якому можна помітити назву нашого макросу. При бажанні можете оставити своє ім’я. Але краще, щоб не було помилок, повністю замінити увесь код на готовий (код дивіться зверху).
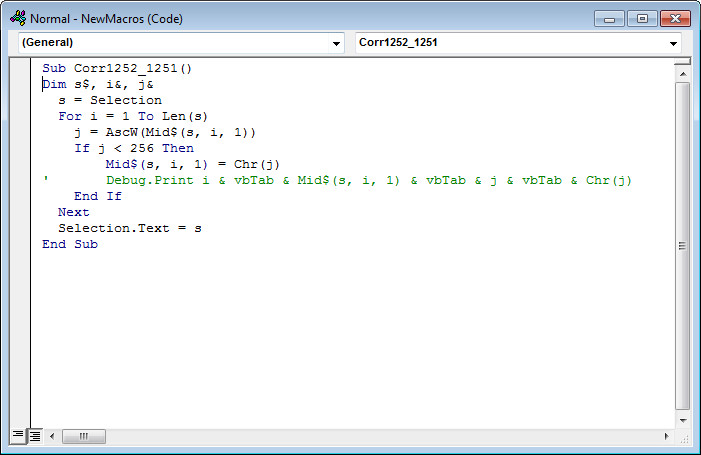
Як видно, макрос починається так:
Sub назвамакросу()
далі іде код макросу
End Sub
Назва макросу може будь-яка, але не цифри і не повинно бути пробілів. Може бути так: декодування_кракозябрів_із_ё. Але не може бути так: декодування кракозябрів із ё.
Тобто, для нас потрібно замінити для нашого створеного пустого макросу увесь текст із кодом, який показаний вище.
Після того як замінили, потрібно закрити вікно редагування макросів (можна натиснути на іконку збереження, хоча зміни зберігаються автоматично). Далі виділяємо наш ієрогліфічний текст, відкриваємо макроси, вибираємо із списку (якщо їх у вас декілька) потрібний та натискаємо на кнопку «Выполнить».

Ваш текст повинен стати читабельним.

Як не крути, але це не повне вирішення ситуації. Пошук після даних дій у самому PDF документі працювати не буде. Проблема залишається. Хто може підказати її вирішення, прохання писати в коментарях.
Я не уверен, что следующие советы помогут для всех решить проблему, но частичное решение ее все же возможно.
Давайте сразу отбросим отсканированые и нераспознанные PDF документы, из которых просто невозможно скопировать текст. Это равносильно попытке копирования текста из обычной фотографии, сделанной на ваш смартфон. В таком случае текст нужно распознать специальной программой, вроде ABBYY FineReader.
Наша книга (тестовая) полностью поддерживает копирование текста и изображений. Но при попытке перенести такой текст в Microsoft Office Word, можно видеть такие нечитабельные символы как на скриншоте сверху статьи.
Способ 1 (длинный).
Вся проблема в шрифтах и системе кодирования. PDF документ, с которого производится копирование имеет встроенные шрифты. И если такие шрифты отсутствуют в вашей операционной системе, то вы увидите такие кракозябры .
Чтобы можно было видеть нормальные буквы, при переносе текста нужно устанавливать соответствующие шрифты .
Чтобы узнать какие именно нужно инсталлировать на компьютер шрифты, нужно открыть наш PDF документ поддерживаемой программой (на примере PDF-XChange Viewer ). Далее идем в «Файл» → «Свойства документа» (можно нажать сочетание клавиш Ctrl + D).
Далее нажимаем на параметр «Шрифты» и видим список шрифтов, установленных в документе. Их и нужно найти в интернете и установить на компьютер. Для этого на загруженном шрифте два раза нажимаем левой клавишей мыши (то есть, открываем его), а потом нажимаем на кнопку «Установить» .
Далее копируем и вставляем текст из PDF документа, выделяем его в Microsoft Office Word (или в другом офисном редакторе, который у вас установлен) и выбираем из списка недавно установленный шрифт. Все должно быть нормально. Снизу на скриншоте видно, что я намеренно применил нужный шрифт только на одно предложение, другую часть текста прочитать невозможно.
Способ 2 (быстро и удобно).
Другой, более правильный и простой вариант – это использование программы (или плагина к редактору Notepad ++ ), которая называется Shtirlitz. Программа старая, давно не обновлялась, однако работает отлично. Прямо на лету выполняется вставка нормального текста. Никаких шрифтов не требуется. После копирования текста с данной программы и дальнейшей вставкой его в редактор Microsoft Office Word, все буквы и символы будут читаться и с использованием любого шрифта. Первый вариант не позволяет изменить шрифт. То есть, всегда, и на каждом компьютере нужно будет инсталлировать нужные шрифты для чтения только определенного документа. А если таких документов несколько сотен? Поэтому желательно воспользоваться этой программой для декодирования.
Способ 3 (онлайн).
Кто не хочет использовать программу Shtirlitz или она не работает, может использовать следующие онлайн сервисы для перекодирования (отдельные сервисы имеют ограничения по объему текста).
Там можно видеть окно, где написано «Скопируйте сюда текст». Вставляем наш непонятный текст и нажимаем на кнопку «Подбор». Такой способ будет правильно использовать если вам неизвестна система кодирования. Декодер попытается подобрать ее автоматически. Если вы знаете исходное кодирование своей кракозябры, то можете смело нажимать кнопку «Точно», указав перед этим кодирование, напротив текста «Я знаю нужные кодировки».
Есть также два режима: автоматический и режим эксперта. Во втором можно указывать исходное и конечное кодирование. Рекомендуется автоматический режим. После того как вставили текст, напротив слов «Выберите кодировку : » , нужно выбрать «Автоматически (рекомендуется)» и нажать на кнопку «Ок».
Все три сервиса отлично работали на моей тестовой книге в формате PDF с кракозябрами.
Способ 4 (с помощью макросов для Microsoft Office Word ).
Еще один вариант для программы Microsoft Office Word. Никаких шрифтов ставить не нужно. Создаем макрос со следующим кодом:
Код 1: «Перекодирование 1252 в 1251»
Sub Corr1252_1251()
Dim s$, i&, j&
s = Selection
For i = 1 To Len(s)
j = AscW(Mid$(s, i, 1))
If j < 256 Then
Mid$(s, i, 1) = Chr(j)
' Debug.Print i & vbTab & Mid$(s, i, 1) & vbTab & j & vbTab & Chr(j)
End If
Next
Selection.Text = s
End Sub
Код 2: «Перекодирование 1252 в 1251 (с учетом русской буквы Ё)»
Sub changeToRus()
'
' Замена кракозябр на кириллические буквы
' CP1252 -> CP1251
'
For i = 192 To 255
a1 = i
a = Trim("^u") & Trim(Str(a1))
' Формирование запроса для поля Найти
sRus = Array("А", "Б", "В", "Г", "Д", "Е", "Ж", "З", "И", "Й", "К", "Л", "М", "Н", "О", _
"П", "Р", "С", "Т", "У", "Ф", "Х", "Ц", "Ч", "Ш", "Щ", "Ъ", "Ы", "Ь", "Э", "Ю", "Я", _
"а", "б", "в", "г", "д", "е", "ж", "з", "и", "й", "к", "л", "м", "н", "о", _
"п", "р", "с", "т", "у", "ф", "х", "ц", "ч", "ш", "щ", "ъ", "ы", "ь", "э", "ю", "я")
' Формирование массива кириллических букв для поля Заменить
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = a
.Replacement.Text = sRus(i - 192)
.Forward = True
.Wrap = wdFindContinue
.MatchCase = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
' Выполнение замены по тексту
Next i
' Замена Ё и ё
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(168)
.Replacement.Text = "Ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(184)
.Replacement.Text = "ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Выделяем вставленный текст с иероглифами. Тогда запускаем макрос на выполнение и получаем нормальный текст, который можно спокойно редактировать, изменять шрифты и т.д.
Для добавления готового макроса в Word делаем следующее:
Открываем редактор и переходим в «Вид».
Там находим кнопку «Макросы» и нажимаем на нее.
Даем для макроса имя (любое, оно будет автоматически изменено при полном копировании кода выше).
Откроется окно в котором можно заметить название нашего макроса. При желании можете оставить свое имя. Но лучше, чтобы не было ошибок, полностью заменить весь код на готовый (код смотрите сверху).
Как видно, макрос начинается так:
Sub названиемакроса()
дальше идет код макроса
End Sub
Название макроса может любым, но не цифры и не должно быть пробелов. Может быть так: декодирование_кракозябр_с_ё. Но не может быть так: декодирование кракозябр с ё.
То есть, для нас нужно заменить для нашего созданного пустого макроса весь текст с кодом, который показан выше.
После того как заменили, нужно закрыть окно редактирования макросов (можно нажать на иконку сохранения, хотя изменения сохраняются автоматически). Далее выделяем наш иероглифический текст, открываем макросы, выбираем из списка (если их у вас несколько) нужный и нажимаем на кнопку «Выполнить».
Ваш текст должен стать читабельным.
Как ни крути, но это не полное решение ситуации. Поиск после данных действий в самом PDF документе работать не будет. Проблема остается. Кто может подсказать ее решение, просьба писать в комментариях.
Адекватного решения на просторах интернета я не нашел.
Пост для таких же как и я.
Решение оказалось простым это программа Adobe Acrobat.
Инструкция: 1) Открываем приложение Adobe Acrobat
2) В левом столбике нажимаем "Мой компьютер" -> "рабочий стол"
3) Выбираем нужный нам файл ( у меня он был на рабочем столе)
4) В правом столбике (правой части экрана) ищем иконку в виде листика со стрелочкой в кружке, при наведение будет написано "Экспорт PDF" нажимаем
5) Далее нажимаем "Экспорт" и выбираем папку куда сохранить файл.

Студенческое общество
829 постов 3.5K подписчик
@moderator, а можно добавить возможность менять сообщество также, как редактируем теги? Народ частенько промахивается, а сделать ничего нельзя каждый раз.
Автору: совет дельный, конечно, но PDF формат был разработан Adobe, которая, собственно, и делает Acrobat специально для работы с этим форматом, поэтому совсем неудивительно, что без Акробата у вас были проблемы с копированием из файла, особенно если файл был специально так сделан, например.
Да ты просто гений!
Спасибо, полезная информация, хоть и немного не своевременно, но может кому-то еще это реально поможет.
Где ты был 5 лет назад, но спасибо
Когда переживаешь о приятелях
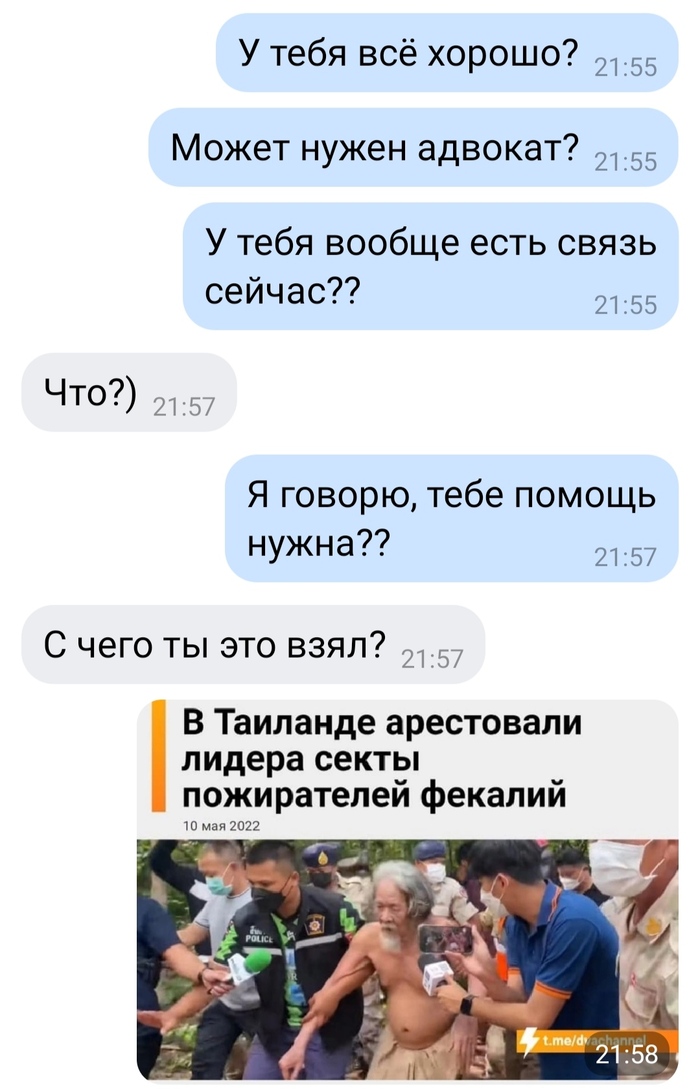
Попытался.. и нарвался

Ответ на пост «В нашем доме поселился замечательный сосед. »
В соседнем районе от Вас.

Альфа

Как точно


Ответ на пост «Как "жалит" крапива под микроскопом»
Ловите лайфхак, может пригодится кому.
Отдыхали летом с супругой в деревне и она случайно ужалилась крапивой, ай-ой чешется. И тут мой выход. Срываю одуванчик, расщепляю его ножку и смазываю им место "укуса". Глаза супруги надо было видеть. Когда человек в 30 лет узнаёт что есть противоядие от врага детства номер один.

ПыСы отпускает сразу же. Узнал о нём от деревенских пацанов лет в 10. Если эта информация поможет хоть одному человеку, буду счастлив)))

Кто успел, того и тапки

Сеньор, "; drop table users; ,я уронил сервак

Ответ на пост «Тушёнка»
А мне вот интересно: если бы в Великобритании выпустили тушёнку "Ирландец томлёный с мощами святого Патрика", или в Испании - "Баск в собственном соку", или в Турции - "Курд тушёный, халяльный", какая реакция была бы у остального "цивилизованного" мира?
Ну и ходи пешком


Полезный совет для худеющих

Когда Россия в сердце.
Не смотря на снятую кожу.
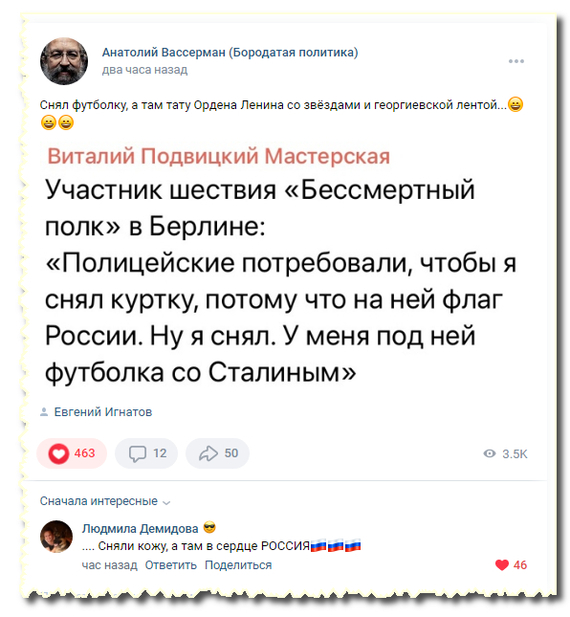
Увидел правду
«Я полностью беру ответственность за то, что скажу. Будучи на Украине, я сталсвидетелем военных преступлений. Все они были совершены украинской армией. Но во Франции мы не говорим об этом!»
Адриен Боке
Тут демобилизованный французский военный, автор книги «Вставай и иди благодаря науке», отправился на Украину с гуманитарной миссией и провёл там три недели. По возвращении он принял непростое решение, которое может стоить ему жизни или, как минимум, создать много проблем: он решил донести до французов информацию о преступлениях, свидетелем которых стал на Украине.
Вот цитаты из его интервью:
Когда я вернулся во Францию с Украины, я был шокирован: телеканалы приглашают в качестве экспертов людей, которые не были на Украине и не знают ничего о том, что там сейчас творится. Однако, они осмеливаются рассуждать об этих событиях. Между тем, что я слышу с телеэкрана и тем, что я видел своими глазами, - пропасть.
Бойцы «Азова» повсюду. С неонацистскими нашивками. Меня шокирует то, что Европа снабжает оружием неонацистов. На их форме повсюду вышита символика эсесовцев. Они не только не скрывают своих взглядов. Они их афишируют. Я работал с этими людьми и лечил их. Они открыто говорят о том, что готовы уничтожать чернокожих и евреев.
Будучи там, я ничего не мог сделать. Только наблюдать и снимать видео. Я располагаю этими кадрами и буду использовать их в качестве свидетельства преступлений Украины.
Я стал свидетелем того, как украинские военные простреливали колени пленным русским солдатам и стреляли в голову служащим в звании выше офицерского.
Я лично видел американских кинооператоров, осуществлявших фальшивую киносъёмку с места событий, устраивающих инсценировки.
Все разрушенные гражданские здания, выдаваемые Украиной за бомбардировки по мирному населению, - ни что иное как результат неточной стрельбы украинцев по военным объектам.
ВСУ по ночам прячут боеприпасы в жилых домах, даже не ставя в известность жителей. Это называется использованием людей в качестве щита.
Буча - это инсценировка. Тела погибших были перемещены из других мест и намеренно размещены таким образом, чтобы произвести шокирующую съёмку».
Как-то раз мне на стол принесли PDF-файл с просьбой скопировать содержимое текста, мол сами не могут т.к. при копировании текст превращается в квадраты, крякозяблы и странные символы. «Кодировка, защита или недостающие шрифты», подумал я, это ж легко. Однако пережимы pdf, снятие защиты через онлайн сервисы и прочие простые решения не помогли. При копировании со всех созданных вариантов данного pdf имеем такую картину:
p, blockquote 1,0,1,0,0 -->
Поиски решения
Открываем PDF в программе Acrobat reader, скачать его можно по ссылке идем в редактирование — защита — параметры защиты. Самой защиты на моем PDF не оказалось, однако на вкладке Шрифты указаны отсутствующие у меня на компе шрифты с заказной кодировкой. Скорее всего дело в этом, можно погуглив найти и установить недостающий шрифт, однако в моем случае такое решение не прокатит. Шрифт MSTT31c, кодировка — заказная.
p, blockquote 2,0,0,0,0 -->

Быстрое решение
Дабы особо не ломать голову, выбираем самое простое решение. Мы попросту разобьем данный PDF на JPEG файлы и заново пересоберем, используя Pdf 24 Creator или его аналоги. (см. Конвертация PDF в JPEG и обратно).
p, blockquote 3,1,0,0,0 -->
Открываем программу — тыкаем Pdf конструктор, ищем наш файл и перетаскиваем в правую часть окна и тыкаем сохранить. В появившемся окне жмем «Настраиваемый» и выбираем Jpeg. DPI оставляйте как есть и жмите продолжить. Вам предложат путь куда вы сохраните весь ваш файл в виде изображений.
Не закрывая программу идем в папку куда сохранили изображения и перетаскиваем их на правую часть. Сохраняем как PDF, получаем слепленный из изображений файл, с которого пока что нельзя копировать ничего. Осталось чуть-чуть.
p, blockquote 5,0,0,0,0 -->

Снова открываем программу, на этот раз жмем Recognize text, выбираем язык документа, желаемое качество, жмем Add files и выбираем созданный на прошлом шаге файл. И всё, жмем Start, по завершению из нашего PDF можно с легкостью копировать текст. Надеюсь помог =)
Читайте также: