
Power query в excel и power bi сбор объединение и преобразование данных
В книге описан Power Query, инструмент для продвинутого бизнес-анализа, встроенный в Excel, Power BI и другие продукты Microsoft и предназначенный для подключения к источникам данных и их преобразования. Рассказано, как обрабатывать таблицы Excel без использования сложных формул и макросов, выбирать данные из нескольких источников, объединять несовпадающие таблицы, сохранять контекст при формировании запросов. Особое внимание уделено базовым и продвинутым методам отмены свертывания столбцов (Unpivot) и совместной работе над отчетами Дано введение в язык формул M и показано, как правильно формировать запросы, избегая сбоев и «ловушек». Рассмотрены вопросы текстовой аналитики и извлечения знаний из текстов, а также аналитики социальных сетей. В конце книги приведен заключительный проект, объединяющий и закрепляющий полученные навыки.
Простая подготовка и анализ данных с помощью Power Query
• Быстрая подготовка данных для анализа в Excel и Power BI
• Решение типичных проблем подготовки данных с помощью нескольких щелчков мыши и простого редактирования формул
• Объединение данных из нескольких источников, нескольких запросов и несовпадающих таблиц
• Базовые и продвинутые методы отмены свертывания столбцов (Unpivot)
• Настройка преобразований и создание гибких гибридных приложений с помощью языка формул M
• Решение проблем совместной работы с помощью Power Query
• Получение важной информации о текстовых каналах
• Заключительный проект, объединяющий и закрепляющий полученные навыки
Power Query — это инструмент для продвинутого бизнес-анализа, предназначенный для подключения к источникам данных и их преобразования. Теперь для обработки таблиц и подключения к данным больше не нужны сложные формулы и макросы. Power Query встроен в Excel, Power BI и другие продукты Microsoft.
Ведущий эксперт по Power Query Гил Равив поможет вам избавиться от трудоемкой подготовки данных вручную, научит быстро получать данные практически из любого источника и сразу же на месте приводить их к нужному вам виду. Вы решите несколько полных аналитических задач и закрепите полученные навыки в реальном финальном проекте длиной в главу. Прочитав книгу, вы будете готовы обрабатывать любые данные и превращать их в полезные знания.
Примите поздравления. Вы приступаете к последней главе. Пришло время подтвердить ваши навыки по обработке данных и проверить возможности в заключительном проекте.
Отчет о доходах компании Wide World Importers
Вы – специалист по данным в компании Wide World Importers. После атаки хакеров вас попросили восстановить отчет о доходах компании на основе старых данных. Ваш предшественник вел отчеты в трех файлах Excel за 2015-2017 годы. В каждом из них содержалось 12 листов – по одному на каждый месяц. А выручка 2018 года была экспортирована в формате csv. Нужно импортировать данные с 36 листов, объединить их с данными 2018 года и создать единый отчет.
Загрузите папку C14E01 и целевую таблицу в файле C14E01 — Goal.xlsx. Изучите файлы 2015.xlsx, 2016.xlsx и 2017.xlsx. Каждый лист содержит сводную таблицу формата 2*3:
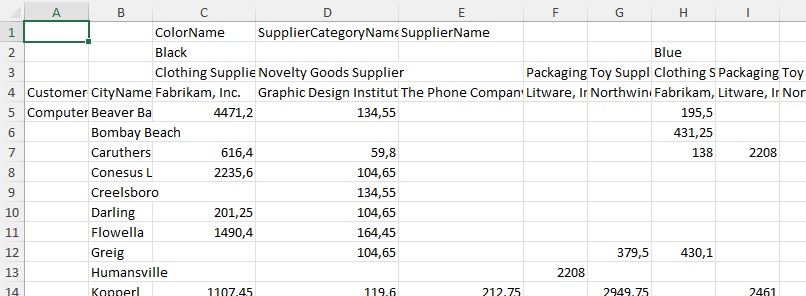
Рис. 1. Исходные данные за 2015–2017 гг. в файлах Excel; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
В строках представлены категории и города клиентов, а в столбцах – цвет продукта, категория и наименование поставщика.
Данные о доходах за 2018 году находятся в файле со значениями, разделенными запятыми (CSV):
Рис. 2. Исходные данные за 2018 г. в файле *.csv
Попробуйте решить проблему самостоятельно. Потратьте пару часов, пытаясь это сделать. Если вам потребуется помощь, можно прочитать текст ниже.
Не знаете, как поступить? Вы можете разбить задачу на этапы:
- Импортируйте все файлы Excel из папки.
- Создайте новый столбец с 36 строками объектов Table (по таблице на лист в трех файлах).
- Для каждого листа удалите первую строку, столбец и строку итогов.
- Примените функцию FnUnpivotSummarizedTable.
- Импортируйте файл 2018.csv и выполните сведение столбца.
- Соедините доходы за четыре года. Обратите внимание, что даты представлены по-разному.
Часть 1. Подготовка таблиц
Начнем с преобразования сводных помесячных данных за 2015-2017 гг. в таблицу фактов. Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из папки. Выберите путь для папки C:\Data\C14\C14E01 и щелкните Открыть. В следующем окне щелкните Преобразовать данные. Откроется окно редактора Power Query.
Выберите элемент управления фильтром столбца Name и снимите галочку с файла 2018.csv. Щелкните Ok. Переименуйте запрос из C14E01 в Revenues. В заголовке столбца Content щелкните на значке Объединить файлы. В окне Объединить файлы выделите папку Параметр 1 [12] и кликните Ok. Power Query автоматически создаст ряд запросов:
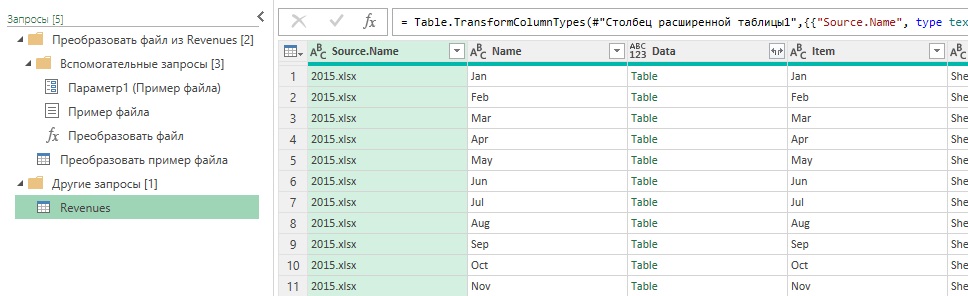
Рис. 3. Импорт всех листов из всех Excel-файлов из папки
Убедитесь, что активен запрос Revenues и удалите последние три столбца. Удалите расширение xlsx из столбца Source.Name для извлечения года и переименуйте столбец в Year. (Имеется несколько способов удалить расширение файла. Если вы не уверены, как это сделать, вернитесь к главе 3.) Переименуйте столбец с Name на Month. В столбце Data находятся объекты Table. Если кликнуть левой кнопкой мыши на пустое пространство справа от слова Table, в нижней части окна увидим предварительный просмотр таблицы:
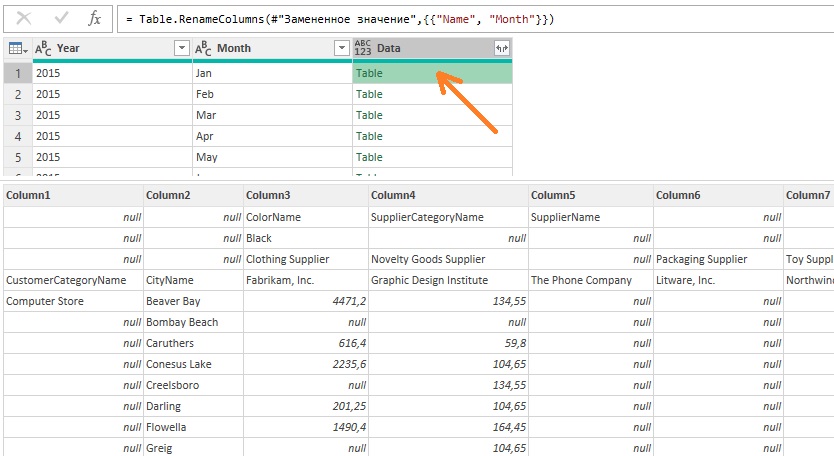
Рис. 4. Первая строка каждой таблицы не несет информации и помешает отмене сведения столбца
Следует удалить первую строку и общие итоги в последнем столбце и последней строке. Пройдите Добавление столбца –> Настраиваемый столбец. Настройте окно Настраиваемый столбец:
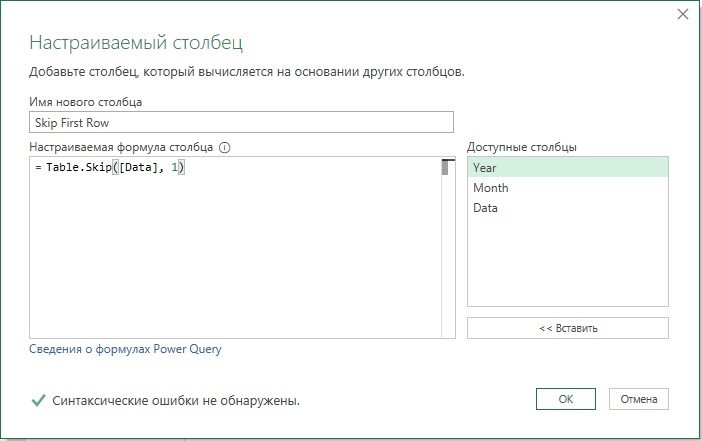
Рис. 5. Параметры окна Настраиваемый столбец
Нажмите Ok. Новый столбец возвращает объект Table такой же, как и в столбце Data но без первой строки. Можете проверить, кликнув левой кнопкой мыши на пустое пространство справа от слова Table в столбце Skip First Row. Удалите столбец Data. Пройдите Добавление столбца –> Настраиваемый столбец. В окне Настраиваемый столбец в поле Имя нового столбца введите No Grand Total Column. В поле Формула пользовательского столбца введите:
Эта формула удаляет последний столбец. С помощью функции Table.ColumnNames вы получаете имена столбцов таблицы в столбце Skip First Row, а List.Last возвращает имя последнего столбца. Опять же, можете проверить, что из всех таблиц удалены столбцы Column19, содержавшие общие итоги.
Удалите столбец Skip First Row. Пройдите Добавление столбца –> Настраиваемый столбец. В окне Настраиваемый столбец в поле Имя нового столбца введите Summarized Table. В поле Формула пользовательского столбца введите:
Проверить удаление последний строки не удастся, так как предварительный просмотр таблицы показывает лишь несколько первых строк. Удалите столбец No Grand Total Column.
Альтернативный способ удаления первой строки, столбца и строки итогов состоит в написании пользовательской функции. Находясь в редакторе Power Query пройдите Главная –> Создать источник –> Другие источники –> Пустой запрос. В строку формул введите код:
Назовите запрос FnCleanSummarizedTable. Создайте дубль запроса Revenues. В запросе Revenues (2) удалите шаги от Добавлен пользовательский объект до последнего. Пройдите Добавление столбца –> Вызвать настраиваемую функцию:
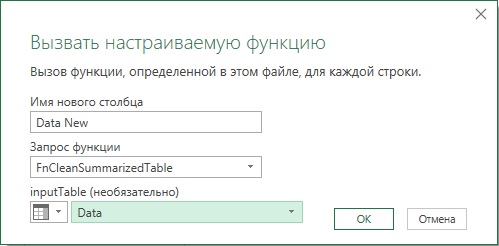
Рис. 6. Удаление первой строки и итогов с помощью пользовательской функции
Часть 2. Вызов функции отмены сведения столбца
Для отмены сведения столбцов применим пользовательскую функцию FnUnpivotSummarizedTable, рассмотренную ранее. Пройдите Главная –> Закрыть и загрузить в… –> Только создать подключение. Сохраните файл под именем C14E01 — Result.xlsx. Загрузите файл C07E03 — Solution.xlsx с сайта Microsoft Press или файл C07E02 — Result.xlsx из архива. Откройте файл Excel. На панели Запросы и подключения щелкните правой кнопкой мыши на FnUnpivotSummarizedTable и выберите Копировать. Вернитесь в файл C14E01 — Result.xlsx. Откройте редактор PQ. Правой кнопкой мыши щелкните где-либо в фоновой области панели Запросы и выберите Вставить.
В качестве альтернативы, находясь в редакторе PQ файла C14E01 — Result.xlsx, пройдите Главная –> Создать источник –> Другие источники –> Пустой запрос. А затем Главная –> Расширенный редактор. Выделите и удалите всё содержимое в окне Расширенный редактор. Вставьте код:
List . Count ( RowFields ) ) , Combiner . CombineTextByDelimiter ( ":" , QuoteStyle . None ) , "Merged" ) ,
Нажмите Готово. Переименуйте Запрос1 в FnUnpivotSummarizedTable.
Итак, вы тем или иным способом создали функцию FnUnpivotSummarizedTable. На панели Запросы выберите Revenues. Пройдите Добавление столбца –> Настраиваемый столбец. В окне Настраиваемый столбец введите имя столбца Unpivoted и код:
Удалите столбец Summarized Table. Разверните столбец Unpivoted. На панели Развернуть отмените флажок Использовать имя исходного столбца в качестве префикса и щелкните Ok. В результате в панели предварительного просмотра можно увидеть, что для всех рабочих листов операция отмены свертывания столбцов выполнена корректно.
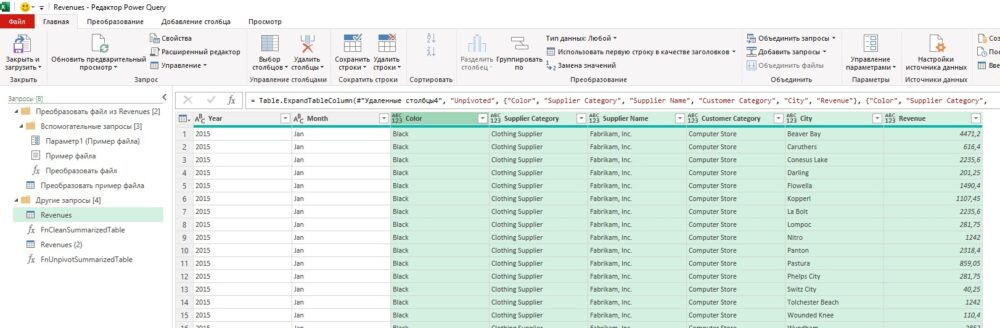
Рис. 7. Таблица доходов за 2015-2017 гг.
Теперь можно обработать доходы за 2018.
Часть 3. Последовательность свертывания столбцов для доходов 2018 года
Займемся файлом 2018.csv. Этот файл содержит разделенные запятыми значения пар атрибут/значение, и можно предположить, что каждая многострочная запись о доходах начинается с атрибута Date (см. рис. 2).
Находясь в редакторе PQ пройдите Главная –> Создать источник –> Файл –> Текстовый или CSV-файл. Выберите файл 2018.csv и нажмите Импорт. В окне 2018.CSV нажмите Ok. Переименуйте запрос в 2018 Revenues. Пройдите Преобразование –> Использовать первую строку в качестве заголовка. Пройдите Добавление столбца –> Столбец индекса. Пройдите Добавление столбца –> Условный столбец. Настройте окно:
Рис. 8 Окно Добавление условного столбца
Щелкните Ok. Выберите столбец Row ID и пройдите Преобразование –> Заполнить –> Вниз. Удалите столбец Индекс. Выберите столбец Attribute и пройдите Преобразование –> Столбец сведения. В окне Столбец сведения в поле Столбец значений выберите Value. Раскройте раздел Расширенные параметры. В поле Функция агрегированного значения выберите Не агрегировать. Щелкните Ok. Удалите столбец Row ID.
Теперь можно объединить результаты за 2015-2017 гг. и за 2018 г.
Часть 4. Объединение доходов
Теперь имеются два запроса, причем Revenues включает столбцы Year и Month, а 2018 Revenues – столбец Date. Выберите запрос Revenues. Выделите первые два столбца, Year и Month, и пройдите Преобразование –> Объединить столбцы. В окне Объединить столбцы выберите разделитель пробел, введите Date в поле Имя нового столбца, щелкните Ok. Пройдите Главная –> Добавить запросы –> Добавить запросы. В окне Добавление в качестве второй выберите таблицу 2018 Revenues. Щелкните Ok.
Измените тип столбца Revenue на Десятичное число, а столбца Date – на Дата. Загрузите запросы: Revenues – Только создать подключение и Добавить эти данные в модель данных, а запрос 2018 Revenues – Только создать подключение. Файл решения C14E01 — Solution.xlsx.
Сравнение таблиц и отслеживание действий хакеров
В предыдущем упражнении вы восстановили отчет о доходах после кибератаки. Согласно исследованию группы по кибербезопасности, злоумышленники подделали значения доходов в хранилище данных. Ваша задача состоит в сравнении доходов в вашем отчете с измененными данными в файле C14E02 — Compromied.xlsx для определения, какие записи подделаны хакерами. Хотя найти различия можно с помощью сводных таблиц или мер DAX, попытайтесь решить задачу с помощью Power Query.
Вот несколько подсказок, которые помогут вам:
- Хакеры внесли изменения в столбец Revenue. Можно объединить две таблицы для нахождения несоответствий. Используйте все столбцы, кроме столбца Revenue, для слияния, а затем разверните столбец Revenue из второй таблицы. Примените фильтр к двум столбцам Revenue для нахождения различий.
- Чтобы найти новые строки, добавленные хакерами, можно объединить таблицу из вашего отчета с скомпрометированной таблицей. Тип соединения – анти-соединение справа. Таким образом, будут обнаружены строки, которые есть в скомпрометированной таблице и нет в вашем отчете.
Импортируйте таблицу Revenues из файла C14E01 — Solution.xlsx. Переименуйте запрос в Correct. Импортируйте таблицу Revenues из файла C14E02 — Compromised.xlsx. Переименуйте запрос в Compromised. На панели Запросы выберите Correct. Пройдите Главная –> Объединить запросы –> Объединить запросы в новый. В окне Слияние в таблице Correct, удерживая нажатой клавишу , выбирайте столбцы Date, Color, Supplier Category, Supplier Name, Custom Category и City. Обязательно сохраняйте порядок следования столбцов. В качестве второй выберите таблицу Compromised. В таблице Compromised, удерживая нажатой клавишу , выбирайте поля Date, Color, Supplier Category, Supplier Name, Custom Category и City.
В поле Тип соединения выберите Внутреннее (только совпадающие строки). Щелкните Ok. Переименуйте новый запрос в Compromised Rows и разверните столбец Compromised. На панели Развернуть отмените выбор всех столбцов, кроме Revenue. Снимите галочку Использовать исходное имя столбца как префикс. Переименуйте новый столбец в Compromised.Revenue.
Чтобы отфильтровать строки, в которых доходы в столбцах Revenue и Compromised.Revenue не равны необходимо применить фильтр, который недоступен в пользовательском интерфейсе. Можно сгенерить код фильтра через пользовательский интерфейс, а затем изменить его в строке формул. Щелкните мышью на элементе фильтра в заголовке столбца Revenue и выберите Числовые фильтры –> Не равно –> 12345. В строке формул увидим:
В основе редактора Power Query лежат два основополагающих принципа:
- Пользовательский интерфейс переводит шаги в код.
- Предварительный просмотр данных помогает формировать логику преобразования.
Эти принципы весьма удобны, но… они же являются виновниками большинства ошибок, которые приводят к сбоям при обновлении или потере данных. Одна из частых ситуаций, приводящих к сбоям обновления, возникает при изменении имени столбца в исходной таблице. А потеря данных может возникать из-за некорректной фильтрации.
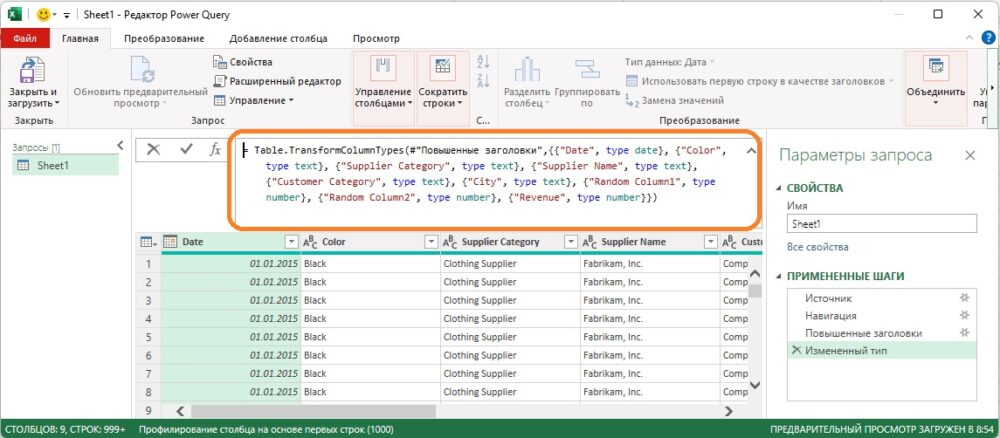
Рис. 1. Жесткая ссылка на имена столбцов; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Прежде чем перейти к подводным камням и методам их преодоления, рассмотрим несколько первоочередных принципов. Эти принципы помогают минимизировать влияние ловушек. Они подразделяются на три темы: осведомленность, лучшие практики, модификация кода.
Осведомленность
Следуйте этим рекомендациям после каждого шага преобразования:
- Убедитесь, что данные на панели предварительного просмотра выглядят правильно. Прокрутите вниз для просмотра большего числа строк. Прокрутите вправо, чтобы увидеть все столбцы.
- Всегда отображайте строку формул. Это имеет решающее значение для предотвращения попадания в ловушки.
- Просмотрите код в строке формул. Обратите внимание на жестко закодированные элементы в формуле, такие как имена и значения столбцов. Например, если удалить столбец Column1 в запросе, то можно заметить в строке формул, что столбец на самом деле назван Column1 (с завершающим пробелом в названии). Если владелец источника данных заметит это, то вполне вероятно сделает исправление, и обновление потерпит неудачу. Просмотр строки формул повысит вашу осведомленность и позволит предотвратить сбои в будущем.
Лучшие практики
Придерживайтесь нескольких хорошо зарекомендовавших себя методик:
- Сохраняйте копии отчета до обновления. Если произошел сбой при обновлении можно сравнить отчеты и выявить причину сбоев.
- Общайтесь с коллегами, предоставляющими внешние данные. Убедитесь, что коллеги осведомлены о ваших отчетах, взаимодействуйте с ними, чтобы они знали, что их работа является частью вашей отчетности.
- Некоторых ловушек можно избежать, сделав правильный выбор операции (например, удаление столбца) или, наоборот, избегая выполнения некоторых ненужных преобразований (например, изменение типа или порядка столбцов).
Модификации кода
Имеется ряд модификаций, которые можно выполнить на уровне формул для создания надежных запросов. И хотя существует множество таких модификаций, наиболее распространенный способ основан на функции Table.ColumnNames. Она позволяет преобразовать ссылку на жестко закодированное имя столбца в динамическую ссылку, которая не дает сбоев.
Ловушка 1. Игнорирование строки формул
Если в редакторе PQ строка формул не активна, пройдите Просмотр –> Строка формул. С помощью строки формул легко обнаружить статические ссылок на имена столбцов. Загрузите файл C10E01.xlsx и сохраните его в папке C:\Data\C10\. Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги.
Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Shit1, кликните Преобразовать данные (см. рис. 1). В редакторе PQ в строке формул видно, что шаг Измененный тип ссылается на имена столбцов. Эти значения имен – именно то, что следует искать в строке формул, если желаете избежать ловушек.
Видно, что имеются два столбца с именами Random Column1 и Random Column2. Предположим, что эти столбцы содержат случайные числа, и они не нужны в вашем отчете. В реальных сценариях вы встретите имена столбцов, которые могут иметь произвольный или временный контекст. Можно сохранить их в отчете или удалить, но на шаге Измененный тип становится ясно, что код уже жестко запрограммирован со ссылкой на эти столбцы. Если эти столбцы не важны, то велика вероятность, что в будущем вы не найдете их в исходной таблице, поскольку владелец внешнего источника данных может их удалить.
Пройдите Главная –> Закрыть и загрузить. Сохраните файл под именем C10E01 — Solution.xlsx. Откройте файл C10E01.xlsx и удалите столбцы Random Column1 и Random Column2. Сохраните файл C10E01.xlsx. Вернитесь к файлу C10E01 — Solution.xlsx. Пройдите Данные –> Обновить всё. Обновление завершится ошибкой:
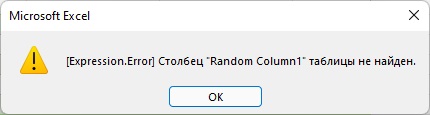
Рис. 2. Ошибка обновления

В данной статье я хочу рассказать о некоторых возможностях бесплатной и крайне полезной, но пока еще мало известной надстройки над MS Excel под названием Power Query.
Power Query позволяет забирать данные из самых разных источников (таких как csv, xls, json, текстовых файлов, папок с этими файлами, самых разных баз данных, различных api вроде Facebook opengraph, Google Analytics, Яндекс.Метрика, CallTouch и много чего еще), создавать повторяемые последовательности обработки этих данных и загружать их внутрь таблиц Excel или самого data model.
И вот под катом вы можете найти подробности всего этого великолепия возможностей.
Совместимость и технические подробности
Power Query доступен бесплатно для всех версий Windows Excel 2010, 2013 и встроен по умолчанию в Windows Excel 2016. Для пользователей MacOS X Power Query недоступен (впрочем, даже без этого маковский Excel отвратителен на ощупь и продвинутые пользователи, включая меня, чаще всего работают с нормальным Excel через Parallels или запуская его на удаленной виндовой машинке).
Также, Power Query встроен в новый продукт для бизнес аналитики — Power BI, а еще, ходят слухи, что Power Query будет появляться и в составе других продуктов от Microsoft. Т.е. Power Query ждет светлое будущее и самое время для адептов технологий Microsoft (и не только) заняться его освоением.
Как оно работает
После установки Power Query в интерфейсе Excel 2010–2013 появляется отдельная одноименная вкладка.

В новом Excel 2016 функционал Power Query доступен на вкладке Data (данные), в блоке “Get & Transform”.

Сначала, в интерфейсе Excel мы выбираем конкретный источник данных, откуда нам их нужно получить, и перед нами открывается окошко самого Power Query с предпросмотром первых строчек загруженных данных (область 1). В верхней части окошка располагается Ribbon с командами по обработке данных (область 2). И в правой части экрана (область 3) у нас расположена панель с последовательностью всех действий, которые применяются к данным.

Возможности Power Query
У Power Query очень много возможностей и я хочу остановиться на некоторых из числа моих любимых.
Как я уже писал выше, Power Query замечателен тем, что позволяет подключаться к самым разным источникам данных. Так он позволяет загружать данные из CSV, TXT, XML, json файлов. Притом процесс выбора опций загрузки тех-же CSV файлов гибче и удобнее, чем он реализован штатными средствами Excel: кодировка автоматически выбирается часто правильно и можно указать символ разделителя столбцов.
Объединение файлов лежащих в папке
Power Query умеет забирать данные из указанной папки и объединять их содержимое в единые таблицы. Это может быть полезно, например, если вам периодически приходят какие-то специализированные отчеты за отдельный промежуток времени, но данные для анализа нужны в общей таблице. Гифка
Текстовые функции
- Разделить столбец по символу или по количеству символов. И в отличие от Excel можно задать максимальное количество столбцов, а также направление откуда нужно считать символы — слева, справа.
- Изменить регистр ячеек в столбце
- Подсчитать количество символов в ячейках столбца.
Числовые функции
К столбцам с числовыми значениями по нажатию на кнопки на Ribbon можно применять:
- Арифметические операции
- Возводить в степени, вычислять логарифмы, факториалы, корни
- Тригонометрические операции
- Округлять до заданных значений
- Определять четность и т.д.
Функции для работы с датами, временем и продолжительностью
К столбцам со значениями даты и времени по нажатию на кнопки на Ribbon можно применять:
- Автоматическое определение формата вписанной даты (в excel c этим большая боль)
- Извлекать в один клик номер месяца, дня недели, количество дней или часов в периоде и т.п.
Unpivot — Pivot
В интерфейсе Power Query есть функция “Unpivot”, которая в один клик позволяет привести данные с одной метрикой разложенные по столбцам по периодам к форме, которая будет удобна для использования в сводных таблицах (понимаю что трудно написал — смотрите пример). Также, есть функция с обратным действие Pivot. Гифка
Операция Merge — смерть ВПР
Функция ВПР (VLOOKUP) одна из наиболее используемых функций в MS Excel. Она позволяет подтягивать данные в одну таблицу из другой таблицы по единому ключу. И вот как раз для этой функции в Power Query есть гораздо более удобная альтернатива — операция Merge. При помощи этой операции соединение таблиц нескольких таблиц в одну по ключу (по простому или по составному ключу, когда соответствие нужно находить по нескольким столбцам) выполняется буквально в 7 кликов мыши без ввода с клавиатуры.
Операция Merge — это аналог join в sql, и ее можно настроить чтобы join был разных типов — Inner (default), Left Outer, Right Outer, Full Outer.
Upd.Мне тут подсказали, что Power Query не умеет делать Aproximate join, а впр умеет. Чистая правда, из коробки альтернатив нет. Гифка
Подключение к различным базам данных. Query Folding.
Power Query также замечателен тем, что умеет цепляться к самым разным базам данных — от MS SQL и MySQL до Postgres и HP Vertica. При этом, вам даже не нужно знать SQL или другой язык базы данных, т.к. предпросмотр данных отображается в интерфейсе Power Query и все те операции, которые выполняются в интерфейсе прозрачно транслируются в язык запросов к базе данных.
А еще в Power Query есть понятие Query Folding: если вы подключены к совместимой базе данных (на текущий момент это MS SQl), то тяжелые операции по обработке данных Power Query будет стараться выполнить на серверной стороне и забирать к себе лишь обработанные данные. Эта возможность радикально улучшает быстродействие многих обработок.
Язык программирования “М”
Надстройка Power Query — это интерпретатор нового, скриптового, специализированного для работы с данными, языка программирования М.
На каждое действие, которое мы выполняем с данными в графическом интерфейсе Power Query, в скрипт у нас пишется новая строчка кода. Отражая это, в панели с последовательностью действий (область 3), создается новый шаг с говорящим названием. Благодаря этому, используя панель с последовательностью действий, мы всегда можем посмотреть как выглядят у нас данные на каждом шаге обработки, можем добавить новые шаги, изменить настройки применяемой операции на конкретном шаге, поменять их порядок или удалить ненужные шаги. Гифка
Также, мы всегда можем посмотреть и отредактировать сам код написанного скрипта. И выглядеть будет он примерно так:

Язык M, к сожалению, не похож ни на язык формул в Excel, ни на MDX и, к счастью, не похож на Visual Basic. Однако, он очень прост в изучении и открывает огромные возможности по манипуляции данными, которые недоступны с использованием графического интерфейса.
Загрузка данных из Яндекс.Метрики, Google Analytics и прочих Api
Немного овладев языком “M” я смог написать программки в Power Query, которые умеют подключаться к API Яндекс.Метрики и Google Analytics и забирать оттуда данные с задаваемыми настройками. Программки PQYandexMetrika и PQGoogleAnalytics я выложил в опенсорс на гитхаб под лицензией GPL. Призываю пользоваться. И я буду очень рад, если эти программы будут дорабатываться энтузиастами.
Для Google Analytics подобного рода экспортеров в разных реализациях достаточно много, но вот для Яндекс.Метрики, насколько я знаю, мой экспортер был первым публично доступным, да еще и бесплатным :)
Power Query умеет формировать headers для post и get запросов и забирать данные из интернета. Благодаря этому, при должном уровне сноровки, Power Query можно подключить практически к любым API. В частности, я для своих исследований дергаю данные по телефонным звонкам клиентов из CallTouch API, из API сервиса по мониторингу активности за компьютером Rescuetime, занимаюсь парсингом нужных мне веб-страничек на предмет извлечения актуальной информации.
Еще раз про повторяемость и про варианты применения
Как я уже писал выше, скрипт Power Query представляет собой повторяемую последовательность манипуляций, применяемых к данным. Это значит, что однажды настроив нужную вам обработку вы сможете применить ее к новым файлам изменив всего один шаг в скрипте — указав путь к новому файлу. Благодаря этому можно избавиться от огромного количества рутины и освободить время для продуктивной работы — анализа данных.
Я занимаюсь веб-аналитикой и контекстной рекламой. И так уж получилось, что с момента, как я познакомился с Power Query в ее интерфейсах я провожу больше времени, чем в самом Excel. Мне так удобнее. Вместе с тем возросло и мое потребление другой замечательной надстройки в MS Excel — PowerPivot.
- разбираю семантику для Толстых проектов,
- Делаю частотные словари,
- Создаю веб-аналитические дашборды и отчеты для анализа конкретных срезов,
- Восстанавливаю достижение целей в системах веб-аналитики, если они не настроены на проекте,
- Сглаживаю прогноз вероятности методами Андрея Белоусова (+Байеса:),
- Делаю аудит контекстной рекламы на данных из K50 статистика,
- И много других разных ad-hoc analysis задач, которые нужно сделать лишь однажды
Вот bi систему, про которую я рассказывал на Yac/M 2015 (видео) я делал полнстью при помощи Power Query и загружал данные внутрь PowerPivot.
Пару слов про локализацию
На сайте Microsoft для пользователей из России по умолчанию скачивается Power Query с переведенным на русским язык интерфейсом. К счастью, локализаторы до перевода на русский языка программирования (как это сделано с языком формул в excel) не добрались, однако жизнь пользователям неоднозначными переводами сильно усложнили. И я призываю вас скачивать, устанавливать и пользоваться английской версией Power Query. Поверьте, она будет гораздо понятнее.

В нашем менеджерском труде есть много хорошего и не очень. Но ничто не портит нам жизнь так, как многочисленные эксельки, в которых постоянно нужно что-то ВПР-ить, СУММ-ировать, СУММПРОИЗВ-одить и заниматься прочими рутинными операциями, отнимающими кучу времени и сил. Есть инструмент, позволяющий если не убрать, то минимизировать рутину везде, где есть паттерны данных. Итак, вашему вниманию предлагается чуть более глубокое погружение в принципы работы PowerQuery.
Сразу же хочу сориентировать по поводу того, что уже есть на Хабре по данной теме:
-
— Отличный обзор возможностей PowerQuery для новичков. Даёт представление об инструменте на примерах. Если вы никогда не использовали PowerQuery, то начать, наверное, стоит с этой статьи. Автор введёт в курс дела.
— Погружение в функции языка «M» на примере локализации списка месяцев. Автор кратко коснулся мощнейшей функции List.Accumulate описание которой заслуживает отдельного материала на Хабре. В качестве тизера к такой публикации, могу сказать, что List.Accumulate принимает на вход абсолютно любой тип аргументов.
Что такое Power Query (PQ)
Дабы не повторять уже сказанное в материалах, ссылки на которые указаны выше, буду краток: Power Query — это инструмент для преобразования формы представления любых логически организованных данных. То есть на входе может быть любая каша, но в которой есть хоть какая-то логика. А на выходе — таблица. По мнению некоторых экспертов, PQ является ETL инструментом. То есть служит для Extract – извлечения, Transform – преобразования и Load – выгрузки данных. По опыту, данная работа занимает до 60% рабочего времени, например, менеджера по контекстной рекламе и до 90% времени аналитика. Важная особенность данной работы состоит в том, что её, как правило, нужно повторять изо дня в день, неделю за неделей. Бесконечно переносить данные, копипастить, вычислять. Для особо тяжёлых случаев программисты пишут решение, в котором всё это делается автоматически. Проблема состоит в том, что решения дороги, а программисты почти всегда заняты более насущными вопросами, чем автоматизация рутинных операций менеджера. PQ позволяет решить указанные трудности:
- Автоматически вытащить данные почти откуда угодно
- Преобразовать данные в соответствии с заранее созданной моделью, без необходимости заново повторять одни и те же действия вручную
- Представить полученные данные в том виде (видах), которые необходимы
На сегодняшний день Power Query доступен только для MS Excel, работающего под ОС Windows. До Excel 2013 включительно, распространялся в виде подключаемого модуля. Начиная с Excel 2016 стал встроенным.
Методы преобразования данных «кнопками» подробно разобраны в статьях указанных выше, особенно в первой. Далее статья будет несколько сложновата для новичков, поскольку мы разбираем подноготную, а конкретно то, что можно увидеть при нажатии на кнопку «Расширенный редактор» в редакторе запросов.

Кнопка «Расширенный редактор»
Как устроен язык «M»
Важно всегда иметь в виду, что конструкция let …. in … является просто “syntactic sugar”. let по факту представляет из себя запись с множеством пар вида «имя=значение», а in это просто ссылка на некоторое значение в этой записи (причём не обязательно последнее). Сложновато. Но давайте попробуем разобраться. В языке «M» есть следующие типы значений:

Абсолютна идентична этой:
Вычисления происходят на базе значений, полученных в результате предыдущих действий. Чем-то это напоминает цепочку формул Excel:
A1=A2+A3
A2=A3+2
A3=5
В случае с PQ обращение идёт не к ячейкам, а к значениям. Выражения, которые входят в запись или список, вычисляются методом «ленивых» вычислений. То есть пока мы прямо не сошлёмся на значение, получаемое в результате выполнения некоторого выражения, оно не будет выполнено.
Коротко о секциях
В заключении хотелось бы напомнить, что любые, даже самые сложные конструкции языка «M» по своей сути состоят из типов, указанных выше. В подавляющем большинстве случаев, это записи и списки, плюс немного встроенных функций для преобразований. Чтобы было проще ориентироваться в многообразии доступного функционала, приведу несколько полезных ссылок, которыми сам пользуюсь регулярно.
Читайте также: