
Ошибка интерпретации файла изображения формата jpeg not a jpeg file starts with 0xef 0xbf
I'm hitting an error trying to convert the following image to PDF. While grabbing the image size to work out how to scale it on the page I'm seeing this error:
Any help would be appreciated. Also I'll try to track down another sample which is free to use.
The text was updated successfully, but these errors were encountered:
haraldk commented Jan 7, 2016
Thanks for reporting!
Can you also provide the code you run when you get the exception?
I'm able to reproduce the issue, but only when trying to read the second image (the JPEGImageReader thinks this file contains two images, for some reason). I think maybe fixing the getNumImages method will resolve the issue, unless you are doing something else?
haraldk commented Jan 7, 2016
After some more investigation, I've found that the image in question actually contains a low res JPEG after the full res image and the Exif thumbnail. So the getNumImages(true) method returning 2 is correct.
The problem instead seems to be that after reading the first image, the logic for locating the second image misinterprets the EOI marker for the Exif thumbnail, and tries to read from there (expecting a SOI), rather than locating the EOI marker for the full res image (where the next SOI marker really is).
I'll see if I can create a fix for this.
tmyroadctfig commented Jan 8, 2016
That makes sense because our PDFing code will enumerate all images in the image and attempt to add each to a page in the PDF.


haraldk commented Jan 8, 2016
I've done some more work on this last night, but unfortunately, the bugs are in the com.sun.imageio.plugins.jpg.JPEGImageReader that I delegate reading to, and they are harder to work around than I thought.
Unless you actually need both the full size and the scaled down version of the image, I suggest you create a workaround and only read the first image (index 0) from JPEGs for now.
haraldk changed the title javax.imageio.IIOException: Not a JPEG file: starts with 0xff 0xff Jan 8, 2016
j-p-sequeira commented Jun 14, 2018 •
You probably already thought of this, but a possible way to fix this problem is to update the delegate by calling delegate.setInput(subInput, . ) when your reader is called with an imageIndex!=0 in a way that you will always call delegate.read(0, param) .
To do this, a subInput must be created without the previous indexes (and probably containing only the wanted index, that is, also omitting the next indexes).
It would be easier (but not efficient) to do this only once when setInput(Object input, . ) is called on your reader. You would divide the input into an ArrayList inputs , with each index of the list containing a single image index. Then, you would do:
The alternative is (but this is hard to maintain) to copy the code from Java's JPEGImageReader into a new class (example JPEGImageReaderDelegate) and delegate in it instead. Then you could fix the skipImage() method not to search only for EOI but to search for EOI followed by a SOI:
Это происходит каждый раз, когда я пытаюсь открыть изображение с любого ftp-сервера, и хотя оно прекрасно открывается в Firefox, vlc media player или любом другом средстве просмотра изображений, но всякий раз, когда я открываю его в средстве просмотра изображений по умолчанию в lubuntu, оно не работает. Обновление eog помогло, хотя. Я прикрепил изображение программы просмотра изображений по умолчанию с ошибками и обновленную программу просмотра изображений, открывающую тот же файл по локальной сети. Следует отметить, что это не проблема с файлом, потому что я могу открыть его после копирования. Проблема заключалась в том, что это два разных приложения: gpicview и eog, но оба этих средства просмотра изображений помечены как "средства просмотра изображений" в меню приложений, и у них одинаковый значок, но они классифицированы по-разному, поскольку старое было в аксессуарах. и более новый - в графике, поэтому я смог различить эти два, иначе разницу можно обнаружить только в свойствах или при запуске программы, чтобы узнать, что есть что. Также может помочь ожидание появления описания / цели при наведении на ярлык в меню приложений. Я приложу скриншот, объясняющий это с устройства, которое я использовал.
На этом снимке экрана вы можете увидеть свойства файлов ярлыков и то, насколько они похожи друг на друга, потому что они имеют одинаковые имя и значок (новый можно увидеть рядом с копией Adobe reader). Я смог их различить только потому, что старый: gpicview в аксессуарах, а новый: eog категоризирован под графикой в меню приложения. Вы также можете видеть, что он говорит: "Просматривайте свои изображения легко", когда я наведите курсор мыши на старое изображение в меню приложения, но с новым оно вместо этого говорит "просматривать и вращать изображения", и они имеют разные имена в свойствах файла, конечно, потому что Сходства в основном в ярлыках, а не в реальных приложениях. Иногда обновление может быть настолько радикальным, что оно не заменяет старую версию, но здесь это не так. Нечто подобное произошло, когда я обновил Firefox на Windows. Недавно я скачал более новую версию Firefox для lubuntu, и я не получил пакет.Deb, вместо этого это был архив.tar.bz2, поэтому я распаковал его и запустил оттуда, но ярлык по умолчанию в меню приложений был как-то связан с эта извлеченная папка в моих загрузках, и она вернулась к более старой версии после того, как я удалил эту папку. Я редактировал этот пост без всего этого ненужного материала минуту назад, но затем мой браузер завис, прежде чем я смог сохранить его, функция автосохранения действительно поможет в таких ситуациях.

Я не мог предоставить обновление в течение стольких месяцев, потому что я пытался выяснить, как загрузить это устройство без использования клавиатуры, поэтому я набираю это с мобильного телефона, но это отдельная тема.
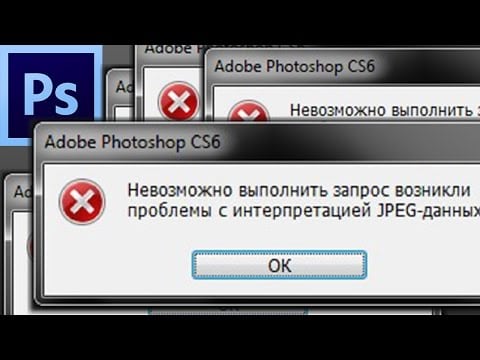
Невозможно выполнить запрос возникли проблемы с интерпретацией jpeg-данных
Почему возникает ошибка в Фотошоп?
Среди возможных причин вылета ошибки при выполнении запроса из-за проблем с интерпретацией jpeg-данных находятся:
- повреждение изображения в результате вирусной атаки, которое видит только фотошоп, обладая более совершенным методом проверки файлов на целостность;
- ошибка в модуле Adobe PhotoShop, который загружает фото в формате jpeg в память – он может некорректно считывать данные либо не учитывать какие-нибудь нюансы;
- слишком большое разрешение файла в формате jpeg.
Способы устранения ошибки при выполнении запроса в связи с проблемами с интерпретацией jpeg-данных
Если файл повредился в результате атаки вирусов, то поможет сканирование системы установленной антивирусной программой, которая найдет и обезвредит зловредный код. Сам антивирус желательно поставить в режим регулярного сканирования, но при вылете каких-либо ошибок необходимо включать и экстренную проверку.
Чаще всего невозможно выполнить запрос по причине возникновения проблем с jpeg при обработке фото именно в указанном формате в Adobe PhotoShop.
Что делать при проблеме воспроизведения картинки
Если вы загружаете в редактор изображение, и с ним нельзя работать далее, то необходимо предпринять следующее:
- открыть фото в более простом редакторе, предъявляющем минимальные требования к качеству изображения (к примеру, в системном Paint);
- пересохранить фото в другом формате – для этого нужно нажать на слово “Файл” в левом верхнем углу редактора, навести курсор на “Сохранить как” и выбрать расширения png, jpeg, bmp, gif или другие;

Выбор формата в Paint
- можно не наводить курсор, а нажать на “Сохранить как”, тогда выйдет меню сохранения, где в выпадающем списке выбирается тип файла;

Выбор формата в выпадающем списке в Paint
- затем снова нужно зайти в фотошоп и открыть сохраненное изображение.
Если проблема интерпретации jpeg-данных возникла на данном этапе, то с помощью этого способа она будет решена.
Способ сжатия изображения
Также можно попробовать сжать изображение с сохранением его качества. Это делается при помощи таких онлайн-сервисов, как Web Resizer, Image Optimizer, PunyPNG и других удобных инструментов, и программ – Paint и Adobe PhotoShop.
Рассмотрим пример на стандартном Paint:
- откройте изображение в редакторе;
- нажмите “Изменить размер”;
- по умолчанию будут выделены поля “Проценты” и “Сохранить пропорции”;
- в поле “Проценты” введите требуемое число (в нашем случае 70%).
- нажмите ОК – фото в нужном размере готово.
Как изменить размер изображения в Paint
Как вариант, попробуйте переустановить Adobe PhotoShop или обновить его до последней версии. Возможно, устаревшая версия программы не справляется с функциями и служит причиной ошибки при выполнении запроса из-за проблем с интерпретацией jpeg-данных.
![]()
Iced Almond Soy Ubuntu, No Foam
Error interpreting JPEG image file (Not a JPEG file: starts with 0xff 0xff)
I am having a problem with certain jpg files. I discovered this when transferring the files to my computer. I checked the files on my camera and it showed the same problems. The error I get is the subject of this. My camera is a coolpix S9700 and has a 32gb sd card in it (formatted by the camera).
Below you will see the results of file and exif. I was able to transfer all the files to my computer but that didn't change anything. I am now wondering if my camera needs attention or if I am using the wrong sd card, or all sorts of other things (one gets a bit paranoid when this occurs) I also just noticed that the folder I have these in just lost about 900 photos (just disappeared for no reason). I am getting a bit concerned about all of this. Its particularly interesting in that I did transfer a subset of these to a flash drive and they were all just fine. I also notice that others have had problems with jpg files in the past.
When I originally took these off my camera, and transferred them to my computer I was able to see every file. Not only that but the thumbnails are also still out there and they too look fine. This is all very strange. I need to know if its my machine or my camera although, given the strange things my machine is doing it may be that. I should also mention that I have tried this on two separate machines with the same results.
I used the file command to get:
~/Pictures$ file DSCN5604.jpg
DSCN5604.jpg: AIX core file fulldump 32-bit, \377\377\377\377\377\377\377\377\377\377\377\377\3 77\377\377\377\377\377\377\377\377\377\377\377\377 \377\377\377\377\377\377\377\377\377\377\377\377\3 77\377\377\377\377\377\377\377\377\377\377\377\377 \377\377\377\377\377\377\377\377\377\377\377\377\3 77 64-bit, \377\377\377\377\377\377\377\377\377\377\377\377\3 77\377\377\377\377\377\377\377\377\377\377\377\377 \377\377\377\377\377\377\377\377\377\377\377\377\3 77\377\377\377\377\377\377\377\377\377\377\377\377 \377\377\377\377\377\377\377\377\377\377\377\377\3 77
I did the same with another problem file and got, exactly, the same results. There were also a couple of .mov files in with the jpg's and when I tried to view those it froze up the machine.
exif returns:
~/Pictures$ exif -x DSCN5604.jpg
'DSCN5604.jpg' is not readable or does not contain EXIF data!
I Ubuntu, Therefore, I Am
After you format using the camera to that, is there any errors?
I have gone through what you are now experiencing got tired of chasing different solutions and bought a new SD Card.(They are Cheap Now)
I was able to use Photorec to recover my pictures though.
I had a repair guy give some good information as described below.
Memory cards are FAT formatted. (Mine is a FAt 16) When a file is deleted in FAT, the space is marked as free, but there can still be hidden fragmentation and corruption. Formatting rewrites the allocation table to make sure the space is continuous and you don't have any file-system errors.
And fragmentation on a FAT file system is more common when deletion is scattered. If you empty the filesystem with deletes then fragmentation isn't a concern.
I use my computer to delete photos from the card after importing them. I reformat the card using my computer.(Fat16) About 3 to 4 times a year.
For me it is useful to not reset the camera's image counter that generates the file names for images on the card. This lets me add images to my photo gallery on my computer without file name collisions.
But Sorry for the information all around your problem at hand.
Слева исходная картинка, загруженная 7 июня 2012, справа — какая она сейчас.

Такая разница очень подозрительна. Попробуем разобраться, что происходило в течение этих 7 лет. Для ознакомления есть статья на Медузе про эту группу, но нас будет интересовать только техническая сторона.
Рассмотрим сильно упрощенную схему кодирования и декодирования JPEG. Показаны только те операции, которые иллюстрируют основные принципы алгоритма JPEG.

Итак, 4 операции:
- DCT — дискретное косинусное преобразование.
- Квантование — округление каждого значения до ближайшей величины, кратной шагу квантования: y = [x/h]*h, где h — шаг.
- IDCT — обратное дискретное косинусное преобразование.
- Округление — обычное округление. Этот этап можно было не показывать на схеме, так как он очевиден. Но далее будет продемонстрирована его важность.
Зеленым цветом выделены операции, сохраняющие всю информацию (не принимая во внимание потери при работе с числами с плавающей запятой), розовым — теряющими. То есть, потери и артефакты появляются не из-за косинусного преобразования, а из-за простого квантования. В статье не будет рассматриваться важный этап — кодирование Хаффмана, так как оно выполняется без потерь.
Рассмотрим эти шаги подробнее.
Так как существует несколько вариаций DCT, то на всякий случай уточню, что JPEG использует DCT второго типа с нормализацией. При кодировании каждое изображение разбивается на квадраты 8x8 (для каждого канала). Каждый такой квадрат можно представить в виде 64-мерного вектора. Косинусное преобразование заключается в нахождении координат этого вектора в другом ортонормированном базисе. Сложно визуализировать 64-мерное пространство, поэтому далее будут приведены 2-мерные аналогии. Можете представлять, что картинка разбивается на блоки 2x1. На графиках, которые будут продемонстрированы далее, оси x соответствуют значения первого пикселя блока, оси y — второго.
Продолжая аналогию на конкретном примере, допустим, что значения двух пикселей из исходного изображения — 3 и 4. Нарисуем вектор (3, 4) в исходном базисе, как показано на рисунке ниже. Исходный базис отмечен синим цветом. Координаты вектора в некотором новом базисе — (4.8, 1.4).

В рассмотренном примере новый базис был выбран случайно. DCT же предлагает вполне конкретный 64-мерный фиксированный базис. Обоснование того, почему в JPEG используется именно он, очень интересно, и описывалось мной в другой статье. Затронем лишь суть. В целом значения всех пикселей равноценны. Но если преобразовать их с помощью DCT, то из получившихся 64 координат в новом базисе (называемых коэффициентами DCT-преобразования) мы можем смело обнулить или грубо округлить их некоторую часть, получив минимальные потери. Это возможно благодаря особенностям сжимаемых изображений.
Квантование
В файле нельзя сохранить дробные значения. Поэтому, в зависимости от шага квантования, значения 4.8, 1.4 будут сохранены так:
- при шаге 1 (самый щадящий вариант): 5 и 1,
- при шаге 2: 4 и 2,
- при шаге 3: 6 и 0.
Обычно шаг выбирается разный для каждого значения. В JPEG-файле есть как минимум один массив, называемый таблицей квантования, хранящий 64 шага квантования. Эта таблица зависит от качества сжатия, задаваемое в любом графическом редакторе.
То же самое, что DCT, но с транспонированным базисом. Математически, x = IDCT(DCT(x)), поэтому если бы не было квантования, то можно было бы восстанавливать без потерь. Но не было бы и сжатия. Из-за использования квантования исходный вектор не всегда можно вычислить точно. На следующем рисунке представлены 2 примера с точным и неточным восстановлением. Наклонной сетке соответствует новый базис, прямой — исходный.

Возникает очевидный вопрос: может ли последовательность перекодирований привести к вектору, сильно отличающегося от исходного? Может.

Интересно было бы перебрать все целочисленные векторы и посмотреть, к чему приведет их перекодирование. Для уменьшения информационного шума, уберем сетку исходного базиса и будем напрямую соединять отрезками исходные и восстановленные векторы (без промежуточного шага). Сначала рассмотрим шаг квантования равный 1 для всех координат. Новый базис на следующем рисунке повернут на 45 градусов и для него имеем 17.1% неточных восстановлений. Цвета отрезков ничего не означают, но они будут полезны для предотвращения их визуального слияния.

Этот базис — на 10.3 градусов с 7.4% неточных восстановлений:


А этот — на 10.4 с 6.4%:

19 градусов с 12.5%:

А вот если задать шаг квантования больше 1, то восстановленные векторы начинают явно концентрироваться близко к узлам сетки. Это шаг 5:


Если изображение перекодировать несколько раз, но с одинаковым шагом, то почти ничего не произойдет по сравнению с однократным перекодированием. Значения как бы «застревают» в узлах сетки и уже не могут «выпрыгнуть» оттуда в другие узлы. Если же шаг разный, то вектор будет «скакать» из одного узла сетки в другой. Это может завести его как угодно далеко. На следующем рисунке показан результат 4 перекодирований с шагами 1, 2, 3, 4. Можно разглядеть крупную сетку с шагом 12. Это значение — наименьшее общее кратное 1, 2, 3, 4.

А на этом — с шагами от 1 до 7. Визуализация показана только для части исходных векторов, чтобы улучшить наглядность.

Округление
А зачем округлять значения после IDCT? Ведь если избавиться от этого этапа, то восстанавливаемое изображение будет представлено дробными значениями, и мы ничего не потеряем при повторном кодировании. С математической точки зрения, мы будем просто переходить от одного базиса к другому без потерь. Здесь необходимо упомянуть о преобразовании цветовых пространств. Хотя JPEG не регламентирует цветовое пространство и позволяет сохранять непосредственно в исходном RGB, но в подавляющем количестве случаев используется предварительная конвертация в YCbCr. Особенности глаза и все такое. А такая конвертация тоже приводит к потерям.
Предположим, мы получили JPEG-файл, сжатый с максимальным качеством, то есть с шагом квантования 1 для всех коэффициентов. Мы не знаем, какой кодек был использован, но обычно кодеки выполняют округление после преобразования RGB -> YCbCr. Так как качество максимально, то после IDCT мы получим дробные, но довольно близкие значения к исходным в пространстве YCbCr. Если округлим, то большинство из них восстановятся в точности.
Но если не округлим, то из-за таких небольших отличий преобразование YCbCr -> RGB может еще больше отдалить их от исходных значений. При последующих перекодированиях разрыв будет увеличиваться все больше. Чтобы хоть как-то визуализировать этот процесс, воспользуемся методом главных компонент для проецирования 64-мерных векторов на плоскость. Тогда для 1000 перекодирований получим примерно такую последовательность изменений:

Абсолютные значения осей здесь не имеют особого смысла, но по относительным можно оценить существенность искажений.

После одного пересохранения с качеством 50:

После любого последующего количества перекодирований с тем же качеством картинка не меняется. Теперь будем плавно снижать качество с 90 до 50 через 1:

Произошло примерно то же, что и на уже приводимом графике:
После одного пересохранения с качеством 20:

Плавно с 90 до 20:

Теперь 1000 раз со случайным качеством от 80 до 90:

Приступим к анализу более 2000 картинок из группы VK. Сначала проверим среднее абсолютное отклонение от самой первой. По оси x — номер картинки (или день), по y — отклонение.

Перейдем к дифференциальному графику, показывающему среднее абсолютное отклонение соседних картинок.

Небольшие колебания в начале — нормальное явление. До 232-й все идет хорошо, картинки полностью идентичны. А 233-я внезапно отличается в среднем на 1.23 для каждого пикселя (по шкале от 0 до 255). Это много. Возможно просто изменились таблицы квантования. Проверим. А заодно сравним с размером получаемых файлов.

Да таблицы менялись. Но не раньше чем у 700-х. Тогда, возможно, происходило промежуточное скрытое перекодирование с низким качеством. Попробуем дважды перекодировать 232-ю. Для первого раза будем перебирать различные уровни качества, а для второго используем ту же таблицу квантования, что и для всех от 1-й до 700-х. Наша цель — получить картинку максимально похожую на 233-ю. На следующем рисунке по оси x — качество промежуточного перекодирования, по y — среднее абсолютное отклонение от 233-й.

Хотя на графике и есть провал при качестве 75%, примерно равный 1, но все еще далеко от желаемого нуля. Добавление 2-го промежуточного этапа и изменение параметров субдискретизации (subsampling) не улучшило ситуацию.
С остальными картинками все примерно то же самое, плюс еще накладывается изменение таблиц квантования. То есть, в какой-то момент картинка резко меняется, затем за несколько дней стабилизируется, но только до тех пор, пока не происходит новый всплеск. Возможно, происходит изменение самого изображения на серверах. Не могу полностью исключить и причастность администратора группы.
К сожалению, я так и не выяснил, что же действительно происходило с изображением. По крайней мере, теперь уверен, что это было не просто пересохранение. Но, самое важное, стал лучше представлять происходящие процессы при кодировании и декодировании. Надеюсь, что и вы тоже.
Читайте также: