
Метрика числа ошибок в программе
Если мы ограничим понятие работы в программировании умственной деятельностью затрачиваемой на превращение заранее разработанного алгоритма в реализацию на языке которым исполнитель свободно владеет то метрические характеристики и понятия введенные выше дадут нам возможность проникнуть в суть процесса программирования и образуют исходную систему для его количественной оценки Простое соотношение между этими метрическими характеристиками и работой выполняемой программистом может быть получено с помощью шести шагов описанных ниже в общих чертах
Вывод уравнения работы
1. Как и ранее допустим что любая реализация какого-либо алгоритма заключается в N-кратном выборе из словаря состоящего из элементов
2. Предположим далее что каждый выбор из словаря неслучаен Исследования методов сортировки показали что за исключением хеширования самым быстрым способом поиска в упорядоченном списке является двоичный поиск при котором список многократно делится пополам до тех пор пока не будет найден нужный элемент Полученное в результате число сравнений равно двоичному логарифму числа элементов в списке Следовательно эффективный процесс эквивалентный двоичному поиску требует log2 сравнений для нахождения элемента
3. На основании шагов 1 и 2 можно заключить что программа порождается выполнением N log2 мысленных сравнений
4. Поскольку объем программы V определяется как
из шага 3 следует что он равен числу мысленных сравнений затрачиваемых на порождение программы
5. Каждое мысленное сравнение содержит ряд элементарных мысленных различений число которых является мерой сложности задачи Из предыдущих результатов вытекает что именно уровень программы L является величиной обратной ее сложности
6. Так как объем V равен числу мысленных сравнений а величина обратная уровню программы те 1/L, есть среднее число элементарных мысленных различений входящих в каждое мысленное сравнение общее число элементарных мысленных различений Е требуемых для порождения программы должно задаваться выражением
Можно выявить более глубокий смысл уравнения работы если вспомнить уравнение (31)
и подставить его в уравнение (42)
Уравнение (43) показывает что мысленная работа по реализации любого алгоритма с данным потенциальным объемом в каждом языке пропорциональна квадрату объема программы Как будет детально показано далее из уравнения (43) следует что так как «квадрат суммы больше суммы двух квадратов» правильное разбиение на модули может уменьшить работу по программированию реализаций разбитых на отдельные части Теперь перейдем от подсчета элементарных мысленных различений к измерению времени
Расчет времени, необходимого для программирования.
Рассмотрим понятие введенное психологом Джоном Страудом в работе «Тонкая структура психологического времени» ДжСтрауд определил «момент» как время требуемое человеческому мозгу для выполнения наиболее элементарного различения Он обнаружил что в течение времени бодрствования человек воспринимает эти «моменты» со скоростью «от пяти до двадцати раз» в секунду Следует отметить что в диапазон приведенных Страудом цифр попадает и число кадров в секунду превращающее кинофильм из последовательности отдельных снимков в непрерывное изображение Обозначая через S число страудовских «моментов» в секунду мы можем записать
В дальнейшем S называется числом Страуда Естественно что любой человек занимающийся реализацией алгоритма может в зависимости от степени своей сосредото-ченности отвлечь какую-то часть мысленных различений на посторонние предметы Пользуясь терминологией вычислительной техники можно сказать что если он находится «в режиме разделения времени» S представляет собой лишь верхнюю границу С другой стороны если программист выполняет эквивалент машинной операции «запретить все прерывания» и сосредоточивает внимание на программировании то применимо действительное значение S
Для того чтобы перевести в единицы времени уравнение (42) имеющее размерность двоичных разрядов или различений разделим обе его части на число различений в единицу времени В результате получим
Символ ^ здесь указывает на то что с помощью этого уравнения вычисляется приближенное а не наблюдаемое время программированияУравнение (44) можно выразить через основные параметры если подставить в него вместо V правую часть уравнения (21) а вместо L - правую часть уравнения (35)
При этом естественно =2
В предыдущем выводе подразумевалось что все программы совершенны т е не имеют несовершенств Хотя это допущение более или менее обосновано для опубли-кованных программ оно необязательно Поэтому откажемся от него по крайней мере в первом приближении подставив вместо N в уравнение (45) Если при этом задается уравнением длины приходим к выражению
где за исключением числа Страуда S все параметры в правой части доступны непосред-ственному измерению для любой реализации алгоритма
Уровень языка.
Материал, изложенный в лекции 3, выявил полезное соотношение между уровнем программы L и ее объемом V. Для любого алгоритма, который переводится с одного языка на другой, с увеличением объема уровень уменьшается в той же пропорции. В результате произведение L на V равняется потенциальному объему V * данного алгоритма. С другой стороны, если язык реализации остается одним и тем же, а разрешено менять сам алгоритм, имеется другое, но похожее соотношение. В этом случае с увеличением потенциального объема V * уровень программы L уменьшится в том же отношении. Следовательно, произведение L на V * остается неизменным для любого языка. Это произведение, называемое уровнем языка, обозначается через и записывается в виде:
Изменения уровня от языка к языку
Следует ожидатьчто чем более универсальным будет язык общего назначения тем больше проявиться способов его использования для данной цели Поскольку многие из этих способов находятся на различных уровнях с ростом среднего значения увеличатся и отклонения от него Кроме этой гипотезы вводится еще одна более существенная согласно которой среднее значение полученное на ряде программ свидетельствует о количественном росте при увеличении развитости языка Для проверки второй гипотезы необходимо иметь интуитивно упорядоченный список языков Так, принято считать что Фортран выше языка ассемблера ПЛ-1 выше Фортрана а английский язык еще выше чем ПЛ-1 Результаты, полученные рядом исследователей, рассматривавших реализации одной группы алгоритмов на различных языках, включая английский, сведены в табл.6.
Сколько ошибок в программе? Это вопрос, который волнует каждого программиста. Особую актуальность придает ему принцип кучкования ошибок, согласно которому нахождение в некотором модуле ошибки увеличивает вероятность того, что в этом модуле есть и другие ошибки. Точного ответа на вопрос о количестве ошибок в программе очень часто дать невозможно, а вот построить некоторую оценку — можно. Для этого существуют несколько статических моделей. Рассмотрим одну из них: Модель Миллса.
В 1972 г. суперпрограммист фирмы IBM Харлан Миллс предложил следущий способ оценки количества ошибок в программе. Пусть у нас есть программа. Предположим, что в ней N ошибок. Назовем их естественными. Внесем в нее дополнительно M искусственных ошибок. Проведём тестирование программы. Пусть в ходе тестирования было обнаружено n естественных ошибок и m искусственных. Предположим, что вероятность обнаружения для естественных и искусственных ошибок одинакова. Тогда выполняется соотношение:
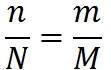
Мы нашли один и тот же процент естественных и искусственных ошибок. Отсюда количество ошибок в программе:

Количество необнаруженных ошибок равно (N-n).
Например, пусть в программу внесено 20 искусственных ошибок, в ходе тестирования было обнаружено 12 искусственных и 7 естественных ошибок. Получим следущую оценку количества ошибок в программе:

Количество необнаруженных ошибок равно (N-n) = 12 — 7 = 5.
Легко заметить, что в описанном выше способе Миллса есть один существенный недостаток. Если мы найдем 100% искусственных ошибок, это будут означать, что и естественных ошибок мы нашли 100%. Но чем меньше мы внесем искусственных ошибок, тем больше вероятность того, что мы найдём их все. Внесем единственную исскуственную ошибку, найдем ее, и на этом основании объявим, что нашли все естесственные ошибки! Для решение такой проблемы Миллс добавил вторую часть модели, предназначенную для проверки гипотезы о величине N:
Предположим, что в программе N естественных ошибок. Внесём в неё M искусственных ошибок. Будем тестировать программу до тех пор, пока не найдем все искусственные ошибки. Пусть к этому моменту найдено n естественных ошибок. На основании этих чисел вычислим величину C:
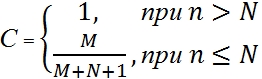
Величина C выражает меру доверия к модели. Это вероятность того, что модель будет правильно отклонять ложное предположение. Например, пусть мы считаем, что естественных ошибок в программе нет (N=0). Внесем в программу 4 искусственные ошибки. Будем тестировать программу, пока не обнаружим все искусственные ошибки. Пусть при это мы не обнаружим ни одной естественной ошибки. В этом случае мера доверия нашему предположению (об отсутствии ошибок в программе) будет равна 80% (4 / (4+0+1)). Для того чтобы довести ее до 90% количество искусственных ошибок придется поднять до 9. Следущие 5% уверенности в отсутствии естественных ошибок обойдутся нам в 10 дополнительных искусственных ошибок. M придется довести до 19.
Если мы предположим, что в программе не более 3-х естественных ошибок (N=3), внесем в нее 6 искусственных (M=6), найдем все искусственные и одну, две или три (но не больше!) естественных, то мера доверия к модели будет 60% (6 / (6+3+1)).
Значения функции С для различных значений N и M, в процентах:
Таблица 1 — с шагом 1;
Таблица 2 — с шагом 5;
Из формул для вычисления меры доверия легко получить формулу для вычисления количества искусственных ошибок, которые необходимо внести в программу для получения нужной уверенности в полученной оценке:

Количество исскуственных ошибок, которые необходимо внести в программу, для достижения нужной меры доверия, для различных значений N:
Таблица 3 — с шагом 1;
Таблица 4 — с шагом 5;
Модель Миллса достаточно проста. Ее слабое место — предположение о равновероятности нахождения ошибок. Чтобы это предположение оправдалось, процедура внесения искусственных ошибок должна обладать определенной степенью «интеллекта». Ещё одно слабое место — это требование второй части миллсовой модели отыскать непременно все искусственные ошибки. А этого может не произойти долго, может быть, и никогда.
В рамках Quality Assurance могут и должны быть использованы различные метрики и показатели качества продукта и процесса разработки. Метрики можно разделить на группы по параметрам, на основании которых они рассчитываются, по этапам жизненного цикла разработки, на которых они применяются, по целям и задачам, по стейкхолдерам, для которых они предназначены. Этот список можно продолжать и дальше.
В этой статье я решил собрать вместе и рассмотреть самые основные, на мой взгляд, группы критериев и измерителей для QA процесса. А в каждой группе я перечислю только самые важные и показательные, опять же на мой взгляд, метрики а также разберу, для чего они необходимы, в каких ситуациях полезны и как их использовать.

Какими должны быть метрики?
Сама по себе метрика в контексте ПО — это численное выражение какого-либо свойства, качества самого продукта или процесса его разработки. Иными словами, это то, с помощью чего мы можем измерить, сравнить и оценить ПО.
Теперь буквально пара комментариев по поводу значений и свойств метрик:
- Основная цель любой метрики — это улучшение процесса разработки и самого программного продукта. Метрика позволяет увидеть, в какой точке на пути к целям мы находимся в данный момент, приближаемся к ним или удаляемся, достигаются ли критерии успешности.
- Метрики не должны существовать ради самого процесса измерения. Необходимо использовать только те метрики, которые действительно имеют практическое значение и будут влиять на дальнейшее развитие продукта или оптимизацию процесса. Отсюда следует простое правило – сначала нужно определить зоны для изменения\улучшения, а потом решать, как их оценивать.
Основные группы метрик для QA
Теоретически возможно придумать свою характеристику, формулу или показатель практически для каждого, даже самого незначительного действия, этапа или статуса процесса QA. Можно учитывать каждый артефакт, все переходы дефектов по статусам, вычислять количество тестов в наборе. Однако, самый важный вопрос, который сразу следует задать себе, когда возникает желание что-то измерить: «Зачем нужна эта информация, как ее можно использовать?». При формирования набора метрик, следует отталкиваться от целей, планов по улучшению процессов и продукта.
1. Требования к разрабатываемому ПО.
Совершенно точно мы должны понимать, что разрабатываем и тестируем, и степень этого понимания необходимо уметь оценить. Потенциальные риски или пропущенные проблемы на уровне спецификации могут привести к самым серьезным и дорогим ошибкам.
2. Качество разрабатываемого продукта.
Тут все очевидно: необходимо иметь возможность оценивать качество разработки и ПО, чтобы делать прогнозы и оценку рисков. Важно понимать, насколько продукт является качественным и надежным, опираясь не только на наличие или отсутствие найденных ошибок, но как раз прогнозируя, много ли потенциальных проблем.
3. Возможности команды QA.
Здесь тоже просто: для того, чтобы управлять процессом тестирования, планировать работы и прогнозировать сроки, требуется всегда иметь не только актуальный статус задач, но и знать возможности команды QA.
4. Качество работы команды тестирования.
Помимо качества самого продукта нужно измерять эффективность самого процесса QA и команды тестирования. Чтобы постоянно оптимизировать и улучшать качество работы, требуется знать, где мы находимся сейчас, что позволяет двигаться вперед, а что отбрасывает назад.
5. Обратная связь и удовлетворенность продуктом.
Последняя область, но, конечно же, не по значимости, а по отзывам стэйкхолдеров процесса, потребителей наших услуг, пользователей продукта. Очень важно иметь возможность измерять общую степень удовлетворенности продуктом, выделять тенденции и делать соответствующие выводы. Правильно подобранные для этой группы метрики позволят вовремя выявить возможные проблемы и оперативно применить обратную связь для улучшения процессов.
Группа 1 — Требования к разрабатываемому ПО
Эта группа метрик позволит оценить, насколько мы проработали требования (user story) к ПО, определить уязвимые места и наиболее сложные, потенциально проблемные фичи ПО, понять, где требуется особый контроль.
1. Тестовое покрытие требования
«Общее количество тестов» / «Общее количество требований»
Назначение метрики: выявить слабые места в тестовом покрытии, подсветить риски.
- Данная метрика будет работать, только если требования хорошо декомпозированы на равнозначные. Иначе она превратится в индикатор наличия или отсутствия тестов для каждого из требований.
- Для требований, у которых коэффициент будет равен или близок к 0, нужно рассмотреть возможность добавления тестов.
Метрика вычисляется как количество связей каждого требования с остальными требованиями. При этом используется среднее по всем требованиям значение.
Назначение метрики: дать основание для оценки сроков тестирования и учета возможных рисков. Зная степень взаимного влияния требований друг на друга, можно, например, запланировать дополнительное время и кейсы для сквозного тестирования, проработать регрессионные проверки, посмотреть в сторону интеграции и т.п.
- По своему опыту могу отметить, что приемлемая степень связанности не превышает 0,2-0,3. В ином случае доработка одного из требований будет вести к цепочке переработок, а значит и возможных ошибок в значительной части продукта.
Назначение метрики: показать, как много уже реализованных требований приходится переделывать от релиза к релизу при разработке новых фич. Также метрика дает представление о том, насколько легко масштабируется функционал системы, добавляются новые возможности.
- Для данной метрики коэффициент должен быть как минимум меньше 0,5. В этом случае мы внедряем новых фич в 2 раза больше, чем переделываем существующих. В противном случае команда больше фокусируется на переделывании ранее выпущенных фич, а не на создании новых ценностей для бизнеса.
Группа 2 — Качество разрабатываемого продукта
Данная группа метрик позволяет оценить и сравнить от релиза к релизу как качество ПО, так и качество самой разработки.
1. Плотность дефектов
«Количество дефектов в отдельном модуле» / «Общее количество дефектов в ПО»
Рассчитывается как доля дефектов от общего их числа, приходящихся на отдельный модуль в рамках итерации или релиза.
Назначение метрики: подсветить, какая часть ПО является наиболее проблемной. Эта информация поможет при оценке и планировании работ с данным модулем, а также при анализе рисков.
- Данная метрика поможет обратить наше внимание на проблемный модуль\систему\функциональность, где доля дефектов выше среднего.
Назначение метрики: показать, на что уходят усилия команды — занимается ли она больше разработкой и отладкой новых фич или основную часть времени тратит на исправления в уже существующих частях ПО.
- Например, если коэффициент регрессии больше 0,5, это значит, что больше половины времени мы тратим на восстановление ранее работавших функций ПО. Такую ситуацию требуется исправлять.
Назначение метрики: дать оценку качеству разработки и исправления дефектов, а также сложности продукта или отдельного модуля.
- Чем ближе значение коэффициента к 0, тем меньше повторяются старые ошибки.
- При этом, если значение больше 0,2-0,3, это может говорить либо о технической сложности модуля, либо о проблемах в архитектуре, либо о некачественном исправлении ошибок.
Группа 3 – Возможности и эффективность команды QA
Основная задача данной группы метрик заключается в том, чтобы выразить в цифрах, на что способна команда тестирования. Эти показатели можно и нужно рассчитывать и сравнивать на регулярной основе, анализировать тенденции, наблюдая, как на работу команды влияют те или иные изменения.
1. Скорость работы (velocity) команды QA
«Количество story points за N итераций)» / «N»
Рассчитывается как отношение реализованных story points \ требований \ user stories за несколько итераций \ sprints к количеству выбранных итераций.
Назначение метрики: численно выразить возможности, скорость работы команды для дальнейшего планирования объема работ и анализа трендов развития. Метрика позволяет следить за скоростью работы QA, наблюдать за тем, какие внутренние или внешние воздействия на команду влияют на эту скорость.
2. Среднее время жизни дефекта
«Суммарное время исправления найденных дефектов» / «Количество дефектов»
Общее время, в течение которого были открытыми дефекты, найденные в рамках итерации или релиза, к сумме дефектов.
Назначение метрики: показать, сколько в среднем времени уходит на работу с одним дефектом: на его регистрацию, исправление и воспроизведение. Данный показатель позволит оценить время, необходимое на тестирование, выделить области ПО, с которыми возникают наибольшие сложности.
- Время жизни дефекта — это все время от его регистрации до закрытия за вычетом всех возможных приостановок работы. Показывая дефекты с наибольшим временем исправления, метрика позволит выявить особенно сложные и проблемные модули или «слабое звено» в команде разработки.
Группа 4 — Качество работы команды тестирования
Задача этого набора метрик: оценить, насколько качественно тестировщики выполняют свои задачи, определить уровень компетенций и зрелости команды QA. Обладая таким набором показателей, можно сравнивать команду с ней же на разных отрезках времени или с другими, внешними группами тестирования.
1. Эффективность тестов и тестовых наборов
«Количество обнаруженных ошибок» / «Количество кейсов в тестовом наборе»
Назначение метрики: показать, как много ошибок в среднем позволяют обнаружить наши кейсы. Эта метрика отражает качество тест дизайна и помогает следить за тенденцией его изменения.
- Показатель «убойности» тестов позволяет мониторить эффективность каждого из тестовых наборов, как она меняется с течением времени. Это даст возможность вовремя дополнять их «свежими» тестами.
Назначение метрики: продемонстрировать качество тестирования и эффективность обнаружения ошибок — какая доля дефектов была отфильтрована, а какая прошла на продуктив.
- Конечно, допустимый процент пропущенных ошибок будет зависеть от многих факторов, однако, если он >0,1, то тут явно есть проблема, ведь в таком случае каждый десятый дефект попал на продуктив и привел к сбоям ПО у пользователей.
Отношение времени, потраченного командой непосредственно на целевые QA активности, к общему количеству часов.
Назначение метрики: во-первых, увеличить точность планирования, а во-вторых, отслеживать и управлять эффективностью работы команды.
- К целевым активностям могут относиться: анализ, дизайн, оценки, тестирование, рабочие встречи и многое другое, к нецелевым — простой из-за блокеров, проблемы в коммуникациях, недоступность ресурсов и т.п.
- Конечно, данная метрика никогда не будет равна 1. Практика показывает, что для эффективных команд ее значение может составлять 0,5-0,6.
Назначение метрики: позволяет использовать поправочный коэффициент для последующих оценок.
- Степень точности оценки можно определить для всей команды или отдельных тестировщиков, для всей системы или отдельных модулей ПО.
Группа 5 — Обратная связь и удовлетворенность пользователей
И в заключение, группа метрик, показывающая, как продукт был принят конечными пользователями, насколько он соответствовал их ожиданиям. При этом в рамках оценки взаимодействия с пользователями нам важна не только обратная связь о самом ПО. Еще одна значимая задача этой группы метрик — показать, удовлетворены ли пользователи процессом взаимодействия с командой ИТ в целом и QA в частности.
1. Удовлетворенность пользователей ИТ сервисом
Проводится регулярный опрос удовлетворенности пользователей сервисом ИТ с выставлением баллов.
Назначение метрики: показать, доверяют ли пользователи команде ИТ, понимают ли, как и почему организована ее работа, насколько эта работа оправдывает ожидания.
- Метрика может служить индикатором того, что необходимо сфокусироваться на оптимизации процесса или сделать его понятнее и прозрачнее для пользователей.
- Расчет показателя удовлетворенности можно проводить на основе результатов опроса по итогам поставки ПО. Для этого необходимо собрать все оценки и посчитать средний балл.
- Для расчета этой метрики также проводим опрос пользователей и вычисляем средний балл. Рассчитывая такой показатель на регулярной основе, можно следить за трендом удовлетворенности пользователей.
Назначение метрики: определить степень участия внешних стейкхолдеров (бизнес, инфраструктура, пользователи, поддержка и т.д.) в работе над продуктом. Имея на руках такую метрику, можно сориентироваться, где требуется получить обратную связь, чтобы однажды не столкнуться с проблемами и непониманием.
Если мы ограничим понятие работы в программировании умственной деятельностью затрачиваемой на превращение заранее разработанного алгоритма в реализацию на языке которым исполнитель свободно владеет то метрические характеристики и понятия введенные выше дадут нам возможность проникнуть в суть процесса программирования и образуют исходную систему для его количественной оценки Простое соотношение между этими метрическими характеристиками и работой выполняемой программистом может быть получено с помощью шести шагов описанных ниже в общих чертах
Вывод уравнения работы
1. Как и ранее допустим что любая реализация какого-либо алгоритма заключается в N-кратном выборе из словаря состоящего из элементов
2. Предположим далее что каждый выбор из словаря неслучаен Исследования методов сортировки показали что за исключением хеширования самым быстрым способом поиска в упорядоченном списке является двоичный поиск при котором список многократно делится пополам до тех пор пока не будет найден нужный элемент Полученное в результате число сравнений равно двоичному логарифму числа элементов в списке Следовательно эффективный процесс эквивалентный двоичному поиску требует log2 сравнений для нахождения элемента
3. На основании шагов 1 и 2 можно заключить что программа порождается выполнением N log2 мысленных сравнений
4. Поскольку объем программы V определяется как
из шага 3 следует что он равен числу мысленных сравнений затрачиваемых на порождение программы
5. Каждое мысленное сравнение содержит ряд элементарных мысленных различений число которых является мерой сложности задачи Из предыдущих результатов вытекает что именно уровень программы L является величиной обратной ее сложности
6. Так как объем V равен числу мысленных сравнений а величина обратная уровню программы те 1/L, есть среднее число элементарных мысленных различений входящих в каждое мысленное сравнение общее число элементарных мысленных различений Е требуемых для порождения программы должно задаваться выражением

Е = (42)
Можно выявить более глубокий смысл уравнения работы если вспомнить уравнение (31)

L =
и подставить его в уравнение (42)

E = (43)
Уравнение (43) показывает что мысленная работа по реализации любого алгоритма с данным потенциальным объемом в каждом языке пропорциональна квадрату объема программы Как будет детально показано далее из уравнения (43) следует что так как «квадрат суммы больше суммы двух квадратов» правильное разбиение на модули может уменьшить работу по программированию реализаций разбитых на отдельные части Теперь перейдем от подсчета элементарных мысленных различений к измерению времени
Расчет времени, необходимого для программирования.
Рассмотрим понятие введенное психологом Джоном Страудом в работе «Тонкая структура психологического времени» ДжСтрауд определил «момент» как время требуемое человеческому мозгу для выполнения наиболее элементарного различения Он обнаружил что в течение времени бодрствования человек воспринимает эти «моменты» со скоростью «от пяти до двадцати раз» в секунду Следует отметить что в диапазон приведенных Страудом цифр попадает и число кадров в секунду превращающее кинофильм из последовательности отдельных снимков в непрерывное изображение Обозначая через S число страудовских «моментов» в секунду мы можем записать
В дальнейшем S называется числом Страуда Естественно что любой человек занимающийся реализацией алгоритма может в зависимости от степени своей сосредото-ченности отвлечь какую-то часть мысленных различений на посторонние предметы Пользуясь терминологией вычислительной техники можно сказать что если он находится «в режиме разделения времени» S представляет собой лишь верхнюю границу С другой стороны если программист выполняет эквивалент машинной операции «запретить все прерывания» и сосредоточивает внимание на программировании то применимо действительное значение S
Для того чтобы перевести в единицы времени уравнение (42) имеющее размерность двоичных разрядов или различений разделим обе его части на число различений в единицу времени В результате получим
T^ = ==(44)
Символ ^ здесь указывает на то что с помощью этого уравнения вычисляется приближенное а не наблюдаемое время программированияУравнение (44) можно выразить через основные параметры если подставить в него вместо V правую часть уравнения (21) а вместо L - правую часть уравнения (35)

T =(45)

При этом естественно =2
В предыдущем выводе подразумевалось что все программы совершенны т е не имеют несовершенств Хотя это допущение более или менее обосновано для опубли-кованных программ оно необязательно Поэтому откажемся от него по крайней мере в первом приближении подставив вместо N в уравнение (45) Если при этом задается уравнением длины приходим к выражению

(46)
где за исключением числа Страуда S все параметры в правой части доступны непосред-ственному измерению для любой реализации алгоритма
Уровень языка.
Материал, изложенный в лекции 3, выявил полезное соотношение между уровнем программы L и ее объемом V. Для любого алгоритма, который переводится с одного языка на другой, с увеличением объема уровень уменьшается в той же пропорции. В результате произведение L на V равняется потенциальному объему V * данного алгоритма. С другой стороны, если язык реализации остается одним и тем же, а разрешено менять сам алгоритм, имеется другое, но похожее соотношение. В этом случае с увеличением потенциального объема V * уровень программы L уменьшится в том же отношении. Следовательно, произведение L на V * остается неизменным для любого языка. Это произведение, называемое уровнем языка, обозначается через и записывается в виде:
Изменения уровня от языка к языку
Следует ожидатьчто чем более универсальным будет язык общего назначения тем больше проявиться способов его использования для данной цели Поскольку многие из этих способов находятся на различных уровнях с ростом среднего значения увеличатся и отклонения от него Кроме этой гипотезы вводится еще одна более существенная согласно которой среднее значение полученное на ряде программ свидетельствует о количественном росте при увеличении развитости языка Для проверки второй гипотезы необходимо иметь интуитивно упорядоченный список языков Так, принято считать что Фортран выше языка ассемблера ПЛ-1 выше Фортрана а английский язык еще выше чем ПЛ-1 Результаты, полученные рядом исследователей, рассматривавших реализации одной группы алгоритмов на различных языках, включая английский, сведены в табл.6.
Если мы ограничим понятие работы в программировании умственной деятельностью затрачиваемой на превращение заранее разработанного алгоритма в реализацию на языке которым исполнитель свободно владеет то метрические характеристики и понятия введенные выше дадут нам возможность проникнуть в суть процесса программирования и образуют исходную систему для его количественной оценки Простое соотношение между этими метрическими характеристиками и работой выполняемой программистом может быть получено с помощью шести шагов описанных ниже в общих чертах
Вывод уравнения работы
1. Как и ранее допустим что любая реализация какого-либо алгоритма заключается в N-кратном выборе из словаря состоящего из элементов
2. Предположим далее что каждый выбор из словаря неслучаен Исследования методов сортировки показали что за исключением хеширования самым быстрым способом поиска в упорядоченном списке является двоичный поиск при котором список многократно делится пополам до тех пор пока не будет найден нужный элемент Полученное в результате число сравнений равно двоичному логарифму числа элементов в списке Следовательно эффективный процесс эквивалентный двоичному поиску требует log2 сравнений для нахождения элемента
3. На основании шагов 1 и 2 можно заключить что программа порождается выполнением N log2 мысленных сравнений
4. Поскольку объем программы V определяется как
из шага 3 следует что он равен числу мысленных сравнений затрачиваемых на порождение программы
5. Каждое мысленное сравнение содержит ряд элементарных мысленных различений число которых является мерой сложности задачи Из предыдущих результатов вытекает что именно уровень программы L является величиной обратной ее сложности
6. Так как объем V равен числу мысленных сравнений а величина обратная уровню программы те 1/L, есть среднее число элементарных мысленных различений входящих в каждое мысленное сравнение общее число элементарных мысленных различений Е требуемых для порождения программы должно задаваться выражением

Е = (42)
Можно выявить более глубокий смысл уравнения работы если вспомнить уравнение (31)

L =
и подставить его в уравнение (42)

E = (43)
Уравнение (43) показывает что мысленная работа по реализации любого алгоритма с данным потенциальным объемом в каждом языке пропорциональна квадрату объема программы Как будет детально показано далее из уравнения (43) следует что так как «квадрат суммы больше суммы двух квадратов» правильное разбиение на модули может уменьшить работу по программированию реализаций разбитых на отдельные части Теперь перейдем от подсчета элементарных мысленных различений к измерению времени
Расчет времени, необходимого для программирования.
Рассмотрим понятие введенное психологом Джоном Страудом в работе «Тонкая структура психологического времени» ДжСтрауд определил «момент» как время требуемое человеческому мозгу для выполнения наиболее элементарного различения Он обнаружил что в течение времени бодрствования человек воспринимает эти «моменты» со скоростью «от пяти до двадцати раз» в секунду Следует отметить что в диапазон приведенных Страудом цифр попадает и число кадров в секунду превращающее кинофильм из последовательности отдельных снимков в непрерывное изображение Обозначая через S число страудовских «моментов» в секунду мы можем записать
Читайте также: