Как сохранить в эксель из сторхауса
Если Вы только начинаете свой путь знакомства с возможностями Python, ваши познания еще имеют начальный уровень — этот материал для Вас. В статье мы опишем, как можно извлекать информацию из данных, представленных в Excel файлах, работать с ними используя базовый функционал библиотек. В первой части статьи мы расскажем про установку необходимых библиотек и настройку среды. Во второй части — предоставим обзор библиотек, которые могут быть использованы для загрузки и записи таблиц в файлы с помощью Python и расскажем как работать с такими библиотеками как pandas, openpyxl, xlrd, xlutils, pyexcel.
В какой-то момент вы неизбежно столкнетесь с необходимостью работы с данными Excel, и нет гарантии, что работа с таким форматами хранения данных доставит вам удовольствие. Поэтому разработчики Python реализовали удобный способ читать, редактировать и производить иные манипуляции не только с файлами Excel, но и с файлами других типов.
Отправная точка — наличие данных
Когда вы начинаете проект по анализу данных, вы часто сталкиваетесь со статистикой собранной, возможно, при помощи счетчиков, возможно, при помощи выгрузок данных из систем типа Kaggle, Quandl и т. д. Но большая часть данных все-таки находится в Google или репозиториях, которыми поделились другие пользователи. Эти данные могут быть в формате Excel или в файле с .csv расширением.
Данные есть, данных много. Анализируй — не хочу. С чего начать? Первый шаг в анализе данных — их верификация. Иными словами — необходимо убедиться в качестве входящих данных.
В случае, если данные хранятся в таблице, необходимо не только подтвердить качество данных (нужно быть уверенным, что данные таблицы ответят на поставленный для исследования вопрос), но и оценить, можно ли доверять этим данным.
Проверка качества таблицы
Чтобы проверить качество таблицы, обычно используют простой чек-лист. Отвечают ли данные в таблице следующим условиям:
- данные являются статистикой;
- различные типы данных: время, вычисления, результат;
- данные полные и консистентные: структура данных в таблице — систематическая, а присутствующие формулы — работающие.
Бест-практикс табличных данных
Читать данные таблицы при помощи Python — это хорошо. Но данные хочется еще и редактировать. Причем редактирование данных в таблице, должно соответствовать следующим условиям:
Если вы работаете с Microsoft Excel, вы наверняка знаете, что есть большое количество вариантов сохранения файла помимо используемых по умолчанию расширения: .xls или .xlsx (переходим на вкладку “файл”, “сохранить как” и выбираем другое расширение (наиболее часто используемые расширения для сохранения данных с целью анализа — .CSV и.ТХТ)). В зависимости от варианта сохранения поля данных будут разделены знаками табуляции или запятыми, которые составляют поле “разделитель”. Итак, данные проверены и сохранены. Начинаем готовить рабочее пространство.
Подготовка рабочего пространства
Подготовка рабочего пространства — одна из первых вещей, которую надо сделать, чтобы быть уверенным в качественном результате анализа.
Первый шаг — проверка рабочей директории.
Когда вы работаете в терминале, вы можете сначала перейти к директории, в которой находится ваш файл, а затем запустить Python. В таком случае необходимо убедиться, что файл находится в директории, из которой вы хотите работать.
Для проверки дайте следующие команды:
Эти команды важны не только для загрузки данных, но и для дальнейшего анализа. Итак, вы прошли все проверки, вы сохранили данные и подготовили рабочее пространство. Уже можно начать чтение данных в Python? :) К сожалению пока нет. Нужно сделать еще одну последнюю вещь.
Установка пакетов для чтения и записи Excel файлов
Несмотря на то, что вы еще не знаете, какие библиотеки будут нужны для импорта данных, нужно убедиться, что у все готово для установки этих библиотек. Если у вас установлен Python 2> = 2.7.9 или Python 3> = 3.4, нет повода для беспокойства — обычно, в этих версиях уже все подготовлено. Поэтому просто убедитесь, что вы обновились до последней версии :)
Для этого запустите в своем компьютере следующую команду:
В случае, если вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь (там же есть инструкции по установке и help).
Установка Anaconda
Установка дистрибутива Anaconda Python — альтернативный вариант, если вы используете Python для анализа данных. Это простой и быстрый способ начать работу с анализом данных — ведь отдельно устанавливать пакеты, необходимые для data science не придется.
Это особенно удобно для новичков, однако даже опытные разработчики часто идут этим путем, ведь Anakonda — удобный способ быстро протестировать некоторые вещи без необходимости устанавливать каждый пакет отдельно.
Anaconda включает в себя 100 наиболее популярных библиотек Python, R и Scala для анализа данных в нескольких средах разработки с открытым исходным кодом, таких как Jupyter и Spyder. Если вы хотите начать работу с Jupyter Notebook, то вам сюда.
Чтобы установить Anaconda — вам сюда.
Загрузка файлов Excel как Pandas DataFrame
Ну что ж, мы сделали все, чтобы настроить среду! Теперь самое время начать импорт файлов.
Один из способов, которым вы будете часто пользоваться для импорта файлов с целью анализа данных — импорт с помощью библиотеки Pandas (Pandas — программная библиотека на языке Python для обработки и анализа данных). Работа Pandas с данными происходит поверх библиотеки NumPy, являющейся инструментом более низкого уровня. Pandas — мощная и гибкая библиотека и она очень часто используется для структуризации данных в целях облегчения анализа.
Если у вас уже есть Pandas в Anaconda, вы можете просто загрузить файлы в Pandas DataFrames с помощью pd.Excelfile ():
Если вы не установили Anaconda, просто запустите pip install pandas, чтобы установить пакет Pandas в вашей среде, а затем выполните команды, приведенные выше.
Для чтения .csv-файлов есть аналогичная функция загрузки данных в DataFrame: read_csv (). Вот пример того, как вы можете использовать эту функцию:
Разделителем, который эта функция будет учитывать, является по умолчанию запятая, но вы можете, если хотите, указать альтернативный разделитель. Перейдите к документации, если хотите узнать, какие другие аргументы можно указать, чтобы произвести импорт.
Как записывать Pandas DataFrame в Excel файл
Предположим, после анализа данных вы хотите записать данные в новый файл. Существует способ записать данные Pandas DataFrames (с помощью функции to_excel ). Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные на несколько листов в файле .xlsx:
Обратите внимание, что в фрагменте кода используется объект ExcelWriter для вывода DataFrame. Иными словами, вы передаете переменную writer в функцию to_excel (), и указываете имя листа. Таким образом, вы добавляете лист с данными в существующую книгу. Также можно использовать ExcelWriter для сохранения нескольких разных DataFrames в одной книге.
То есть если вы просто хотите сохранить один файл DataFrame в файл, вы можете обойтись без установки библиотеки XlsxWriter. Просто не указываете аргумент, который передается функции pd.ExcelWriter (), остальные шаги остаются неизменными.
Подобно функциям, которые используются для чтения в .csv-файлах, есть также функция to_csv () для записи результатов обратно в файл с разделителями-запятыми. Он работает так же, как когда мы использовали ее для чтения в файле:
Если вы хотите иметь отдельный файл с вкладкой, вы можете передать a \ t аргументу sep. Обратите внимание, что существуют различные другие функции, которые можно использовать для вывода файлов. Их можно найти здесь.
Использование виртуальной среды
Общий совет по установке библиотек — делать установку в виртуальной среде Python без системных библиотек. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимое для использования библиотек, которые потребуются для Python.
Чтобы начать работу с virtualenv, сначала нужно его установить. Потом перейти в директорию, где будет находится проект. Создать virtualenv в этой папке и загрузить, если нужно, в определенную версию Python. После этого активируете виртуальную среду. Теперь можно начинать загрузку других библиотек и начинать работать с ними.
Не забудьте отключить среду, когда вы закончите!
Обратите внимание, что виртуальная среда может показаться сначала проблематичной, если вы делаете первые шаги в области анализа данных с помощью Python. И особенно, если у вас только один проект, вы можете не понимать, зачем вообще нужна виртуальная среда.
Но что делать, если у вас несколько проектов, работающих одновременно, и вы не хотите, чтобы они использовали одну и ту же установку Python? Или если у ваших проектов есть противоречивые требования. В таких случаях виртуальная среда — идеальное решение.
Во второй части статьи мы расскажем об основных библиотеках для анализа данных.
Продолжение следует…
Есть в IT-отрасли задачи, которые на фоне успехов в big data, machine learning, blockchain и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как мир задаче формирования и выгрузки Excel-документов, с которой сталкивался каждый, кто когда-либо писал приложения для бизнеса.

Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат ~ (тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).
Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:

Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:

Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид @имяатрибута ).
Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):

Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри iteration . С помощью атрибута name могут быть заданы разнообразные фильтры для элементов, например
- name="foo" — элементы с именем тэга foo
- name="*" — все элементы
- name="tagname[@attribute='value']" — элементы с определённым именем и значением атрибута
- name="(before)" , name="(after)" — «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- mode="horizontal" — режим вывода по горизонтали (по умолчанию — vertical)
- index=0 — ограничить итерацию только самым первым встреченным элементом
- sourcesheet —лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.
- range – диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).
- worksheet – если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:![]()
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
У класса XML2Spreadsheet есть несколько перегруженных вариантов статического метода process , но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки -sax или установкой в true параметра useSax метода XML2Spreadsheet.process ) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.
Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
Помогите, пожалуйста, советом) А быть может и решением.
гигантская таблица с номенклатурой, в excel, которая обновляется по цене, скажем раз в квартал. Ответственный человек, также раз в квартал, берет ее и переносит данные вручную в Storehouse.
Номенклатура в excel и shouse по наименованию не совпадает.
Тоесть есть какие-то опознавательные знаки, по которым можно найти позицию и в excel и shouse, но наименования не идентичны.
Вопрос - как автоматизировать перенос данных из excel в shouse?
Пока в голове, на уровне дауна, идея - выгружать в xls таблицу номенклатуры с shouse, каким-то макаром сверять с исходной excel по общим "маркерам" в наименованиях и автоматом вносить в выгруженный shouse. затем заливать его обратно.
В том ли направлении смотрю? Может есть готовые решения или кто-то писал что-нибудь подобное "на коленке"?
Буду рад любой помощи, человек чуть ли не умирает от этих таблиц, настолько это муторно и долго.
![Экспорт из Excel в Storehouse Microsoft Excel, Импорт, Экспорт, Помощь]()
![]()
MS, Libreoffice & Google docs
537 постов 13.4K подписчиков
Правила сообщества
2. Публиковать посты соответствующие тематике сообщества
3. Проявлять уважение к пользователям
4. Не допускается публикация постов с вопросами, ответы на которые легко найти с помощью любого поискового сайта.
По интересующим вопросам можно обратиться к автору поста схожей тематики, либо к пользователям в комментариях
Важно - сообщество призвано помочь, а не постебаться над постами авторов! Помните, не все обладают 100 процентными знаниями и навыками работы с Office. Хотя вы и можете написать, что вы знали об описываемом приёме раньше, пост неинтересный и т.п. и т.д., просьба воздержаться от подобных комментариев, вместо этого предложите способ лучше, либо дополните его своей полезной информацией и вам будут благодарны пользователи.
Утверждения вроде "пост - отстой", это оскорбление автора и будет наказываться баном.
Там вроде Interbase в качестве БД, я бы рекомендовал сделать нормальный ETL-процесс, для наименований завести словарь, первично состыковать имена по расстоянию Левенштейна с разбивкой по словам, на каждое изменение цены (загрузку) заводить документ, чтобы это прозрачно отрабатывалось в системе.
Попробуйте не создавать костыль, а поменять процесс полностью. @qawsed90 описал самый эффективный способ, дальше только использовать ИИ. И все равно нужно будет дорабатывать вручную.
Кто-то же обновляет первую таблицу? Может стоит внести в нее сразу номенклатурные коды и по ним вытаскивать изменившиеся цены?
Надо глядеть на объёмы и как происходит загрузка /выгрузка в Storehouse .
Только после этого можно понять обойдётся ли макросами это или надо что то более серьёзное .
Почту оставьте для связи.Если действия человека по работе с таблицей хоть как то можно алгоритмизировать, то и макрос написать можно.
Дилерам написать, спросить, Карбис например, ЮЦЦ навряд ли пишет что то.
Экспорт и импорт
![Экспорт и импорт Мигранты, Экспорт, Импорт, Россия]()
Вообще, подобную картинку видел в сербском интернете, оригинал не нашел, нарисовал свою. Хотя, для Сербии эта проблема по сравнению с Россией стоит далеко не так остро. Да, люди уезжают в страны Европы, приезжают строители из Турции и еще хз откуда. Но их не особо видно и слышно, да и приезжают они работать. С российскими масштабами не сравнить, мягко говоря.
А в России, судя по новостям, ситуация УЖЕ вышла из под контроля. Возникает два вопроса:
1 Неужели те, кто принимают такие решения, не думают о последствиях? Я понимаю, что они живут в другом мире, в котором они никогда не встретятся с мигрантами, но тем не менее.
2 А может им коренные жители России (я не написал "русские") не особо и нужны?
Ну и очень печально смотреть, как те (или их дети), кто еще 30 лет назад выгонял русских, грабил их, убивал, едут сюда. Они хотели независимости. Теперь нажрались своей независимости, живут в жопе (иначе они просто не умеют) и свою жопу тащат сюда.
![]()
Торговля вакцинами – Россия увеличила экспорт в 30 раз и стала одним из мировых лидеров. Сравнение с другими странами
До 2020 г. Россия не являлась значимым игроком на рынке вакцин. Доля страны в мировой торговле вакцинами в 2019 г. – менее 0,5%, экспорт г. не превышал 71 млн $, а импорт – 185 млн $.
Торговля вакцинами в мире до пандемии
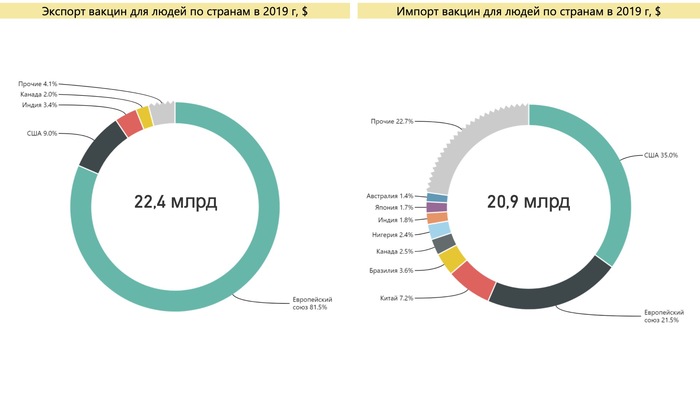
Основными экспортерами вакцин для людей в 2019 г. являлись страны Европейского союза, США, Канада, Индия, на их долю приходилось 96% поставок в денежном выражении. География импорта вакцин была шире, поскольку потребителей кратно больше производителей, однако 47% импорта приходилось на США (35%) и Европейский союз.
![Торговля вакцинами – Россия увеличила экспорт в 30 раз и стала одним из мировых лидеров. Сравнение с другими странами Вакцина, Коронавирус, Экспорт, Импорт, Длиннопост]()
Экспорт и импорт вакцин для людей по странам мира. Источник: расчет автора по данным ООН, ФТС России, статистических ведомств стран
Важная особенность рынка – разделение поставок между богатыми и бедными государствами, страны Европейского союза большую часть вакцин поставляли в США, Канаду и Великобританию. Вакцины в бедные страны Африки, Азии и Латинской Америки преимущественно импортировались из Индии. Ее экспортная доля в денежном выражении составляла только 3,4%, а в количестве – около 25%.
Торговля вакцинами в 2021 году
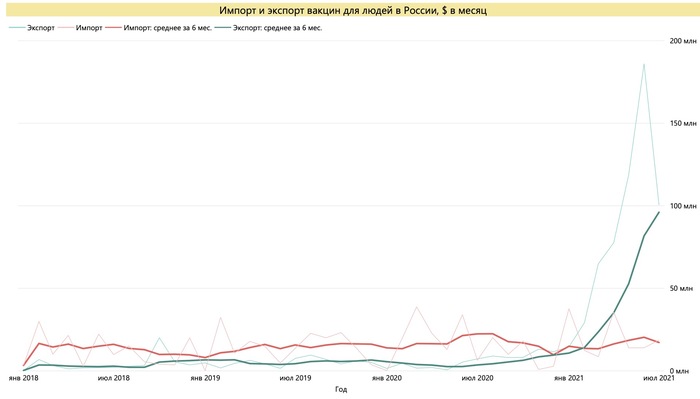
![Торговля вакцинами – Россия увеличила экспорт в 30 раз и стала одним из мировых лидеров. Сравнение с другими странами Вакцина, Коронавирус, Экспорт, Импорт, Длиннопост]()
Экспорт вакцин для людей по странами мира в 2020-2021 гг. Источник: расчет автора по данным ООН, ФТС России, статистических ведомств стран
Торговля вакцинами в России
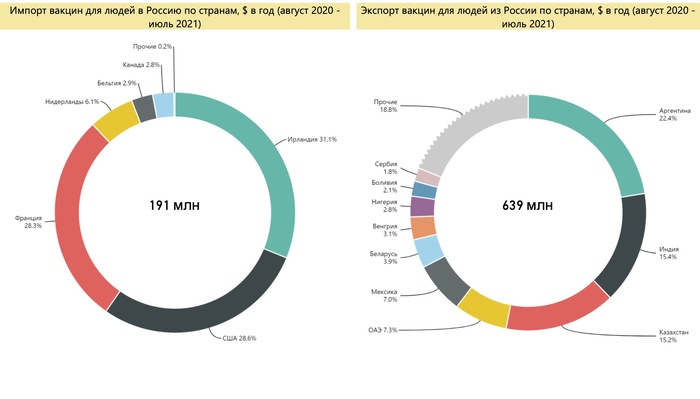
До пандемии Россия была чистым импортером вакцин, которые поставлялись из европейских стран и США, структура импорта не изменилась и в 2020-2021 гг. С начала 2021 г. Россия стала активно наращивать поставки вакцины от COVID-19 в другие страны, за 7 месяцев 2021 г. (г/г) общий экспорт вакцин увеличился почти в 30 раз с 22 млн $ до 590 млн $. К середине 2021 г. Россия вышла на 5 место среди крупнейших экспортеров.
![Торговля вакцинами – Россия увеличила экспорт в 30 раз и стала одним из мировых лидеров. Сравнение с другими странами Вакцина, Коронавирус, Экспорт, Импорт, Длиннопост]()
![Торговля вакцинами – Россия увеличила экспорт в 30 раз и стала одним из мировых лидеров. Сравнение с другими странами Вакцина, Коронавирус, Экспорт, Импорт, Длиннопост]()
Структура импорта и экпорта вакцин для людей в России по странам в 2020-2021 гг. Источник: расчет автора по данным ФТС России
![]()
Национальный доход не размножается делением или почему дорожает лес?
Россия – крупнейшая лесная держава мира. Однако, не так давно инфопространство всколыхнула инфрмация о серьезном подорожании леса на внутреннем рынке.
По данным Ассоциации деревянного домостроения, с апреля 2020-го по апрель 2021 г. доски для строительства подорожали с 11–13 тыс. руб. за 1 кубометр до 22–26 тыс. руб. Цены на внешних рынках превысили российские на 7–30% (в зависимости от типа продукции), что и повлекло рост цен для внутреннего рынка.
Давайте подумаем, а можно ли реально что-то сделать с этой проблемой?
Если отталкиваться от книжной экономической теории – конечно, существует определенная регулирующая связь между спросом и предложением. Если рассматривать Россию как закрытый обособленный рынок, то увеличение предложения способно снизить цену леса. Однако, это если мы представляем эту ситуацию как некоего «сферического коня в вакууме». В реальности, к сожалению, не все так однозначно.
Мы вынуждены учитывать реальное положение вещей. А здесь определяющие 3 фактора:
1. Для того, чтобы существенно повысить предложение леса – нужны инвестиции. Кто выступит инвесторами - частники, государство. По сути - не важно. Важно другое – инвестиции должны быть долгосрочными, тк первый результат не завтра. Для запуска необходимо урегулировать вопросы с государством (получить лицензию на вырубку, найти место под завод, заказать строительство, согласовать контракты, паспорта сделок, подождать изготовление оборудования и тд и тп). Только потом пойдет пред пусковой цикл, пусковой цикл и производств…И мы понимаем, что это не один год. Что сделать? Стимулировать привлекательность отрасли для частных инвестиций субсидиями, низкопроцентными кредитами. И, как мы понимаем, это прерогатива государства..
2. Россия является мировым игроком. Она входит в мировую экономическую систему. А существующее состояние мировой экономической системы говорит о том, что лес в во всем мире, особенно в странах Азии, стоит гораздо дороже, чем в России. И до тех пор, пока кубометр леса на экспорт будет стоить дороже, чем в России, производители будут стремиться сдать его не на внутренний рынок, а на экспорт. Какой вывод моно сделать? На первый взгляд простой - пока не насытится экспортный рынок, в России спрос не будет закрыт полностью. А что это означает? Несмотря на то, что производство увеличилось – предложение не увеличилось, тк все доппризводство идет на экспорт. Спрос растет, предложение не растет, а падает, следовательно - цены растут. Так же следует учитывать мировой тренд на сокращение вырубки лесов в мире, а это значит, что цены на мировом рынке будут только расти….Что сделать? Мне видится, что тут возможна только единственная управляющая роль государства
3. Цепочка перепродавцов. Вся наша экономическая система построена именно на такой модели…Кто-нибудь, где-нибудь в Сибири срубил лес, его купил посредник, отогнал на лесозаготовку. Комбинат обработал, но у него купил более крупный посредник и погнал в область и тд. . И без этого никуда. Цепочка посредников, в каждой из звеньев которой увеличивается цена…
Простых решений не существует, тк есть люди. Поможет некий комплексный план.. Однако, тут тоже надо понимать - если подорожание спорадическое , те вызвано сезонными причинами – это одно. Если это фундаментальное состояние отрасли, в которой не хватает переработчиков – это уже структурный кризис отрасли, то послаблений ждать не следует….
Мир достаточно велик, чтобы удовлетворить нужды любого человека, но слишком мал, чтобы удовлетворить людскую жадность. Махатма Ганди
Про сборку листов из нескольких книг в одну текущую я уже писал здесь. Теперь разберем решение обратной задачи: есть одна книга Excel, которую нужно "разобрать", т.е. сохранить каждый лист как отдельный файл для дальнейшего использования.
![save-sheets-as-files.jpg]()
Примеров подобного из реальной жизни можно привести массу. Например, файл-отчет с листами-филиалами нужно разделить на отдельные книги по листам, чтобы передать затем данные в каждый филиал и т.д.
Если делать эту процедуру вручную, то придется для каждого листа выполнить немаленькую цепочку действий (выбрать лист, правой кнопкой по ярлычку листа, выбрать Копировать, указать отдельный предварительно созданный пустой файл и т.д.) Гораздо проще использовать короткий макрос, автоматизирующий эти действия.
Способ 1. Простое разделение
Нажмите сочетание Alt+F11 или выберите в меню Сервис - Макрос - Редактор Visual Basic (Tools - Macro - Visual Basic Editor) , вставьте новый модуль через меню Insert - Module и скопируйте туда текст этого макроса:
Если теперь выйти из редактора Visual Basic и вернуться в Excel, а затем запустить наш макрос (Alt+F8), то все листы из текущей книги будут разбиты по отдельным новым созданным книгам.
Способ 2. Разделение с сохранением
При необходимости, можно созданные книги сразу же сохранять под именами листов. Для этого макрос придется немного изменить, добавив команду сохранения в цикл:
Этот макрос сохраняет новые книги-листы в ту же папку, где лежал исходный файл. При необходимости сохранения в другое место, замените wb.Path на свой путь в кавычках, например "D:\Отчеты\2012" и т.п.
Если нужно сохранять файлы не в стандартном формате книги Excel (xlsx), а в других (xls, xlsm, xlsb, txt и т.д.), то кроме очевидного изменения расширения на нужное, потребуется добавить еще и уточнение формата файла - параметр FileFormat:
Для основных типов файлов значения параметра FileFormat следующие:
- XLSX = 51
- XLSM = 52
- XLSB = 50
- XLS = 56
- TXT = 42
Способ 3. Сохранение в новые книги только выделенных листов
Если вы хотите раскидать по файлам не все листы в вашей книге, а только некоторые, то макрос придется немного изменить. Выделите нужные вам листы в книге, удерживая на клавиатуре клавишу Ctrl или Shift и запустите приведенный ниже макрос:
Создавать новое окно и копировать через него, а не напрямую, приходится потому, что Excel не умеет копировать группу листов, если среди них есть листы с умными таблицами. Копирование через новое окно позволяет такую проблему обойти.
Способ 4. Сохранение только выделенных листов в новый файл
Во всех описанных выше способах каждый лист сохранялся в свой отдельный файл. Если же вы хотите сохранить в отдельный новый файл сразу группу выделенных предварительно листов, то нам потребуется слегка видоизменить наш макрос:
Способ 5. Сохранение листов как отдельных PDF-файлов
- для этого используется уже другой метод (ExportAsFixedFormat а не Copy)
- листы выводятся в PDF с параметрами печати, настроенными на вкладке Разметка страницы (Page Layout)
- книга должна быть сохранена на момент экспорта
Нужный нам код будет выглядеть следующим образом:
Способ 6. Готовый макрос из надстройки PLEX
Если лень или нет времени внедрять все вышеописанное, то можно воспользоваться готовым макросом из моей надстройки PLEX:
Про сборку листов из нескольких книг в одну текущую я уже писал здесь. Теперь разберем решение обратной задачи: есть одна книга Excel, которую нужно "разобрать", т.е. сохранить каждый лист как отдельный файл для дальнейшего использования.
![save-sheets-as-files.jpg]()
Примеров подобного из реальной жизни можно привести массу. Например, файл-отчет с листами-филиалами нужно разделить на отдельные книги по листам, чтобы передать затем данные в каждый филиал и т.д.
Если делать эту процедуру вручную, то придется для каждого листа выполнить немаленькую цепочку действий (выбрать лист, правой кнопкой по ярлычку листа, выбрать Копировать, указать отдельный предварительно созданный пустой файл и т.д.) Гораздо проще использовать короткий макрос, автоматизирующий эти действия.
Способ 1. Простое разделение
Нажмите сочетание Alt+F11 или выберите в меню Сервис - Макрос - Редактор Visual Basic (Tools - Macro - Visual Basic Editor) , вставьте новый модуль через меню Insert - Module и скопируйте туда текст этого макроса:
Если теперь выйти из редактора Visual Basic и вернуться в Excel, а затем запустить наш макрос (Alt+F8), то все листы из текущей книги будут разбиты по отдельным новым созданным книгам.
Способ 2. Разделение с сохранением
При необходимости, можно созданные книги сразу же сохранять под именами листов. Для этого макрос придется немного изменить, добавив команду сохранения в цикл:
Этот макрос сохраняет новые книги-листы в ту же папку, где лежал исходный файл. При необходимости сохранения в другое место, замените wb.Path на свой путь в кавычках, например "D:\Отчеты\2012" и т.п.
Если нужно сохранять файлы не в стандартном формате книги Excel (xlsx), а в других (xls, xlsm, xlsb, txt и т.д.), то кроме очевидного изменения расширения на нужное, потребуется добавить еще и уточнение формата файла - параметр FileFormat:
Для основных типов файлов значения параметра FileFormat следующие:
- XLSX = 51
- XLSM = 52
- XLSB = 50
- XLS = 56
- TXT = 42
Способ 3. Сохранение в новые книги только выделенных листов
Если вы хотите раскидать по файлам не все листы в вашей книге, а только некоторые, то макрос придется немного изменить. Выделите нужные вам листы в книге, удерживая на клавиатуре клавишу Ctrl или Shift и запустите приведенный ниже макрос:
Создавать новое окно и копировать через него, а не напрямую, приходится потому, что Excel не умеет копировать группу листов, если среди них есть листы с умными таблицами. Копирование через новое окно позволяет такую проблему обойти.
Способ 4. Сохранение только выделенных листов в новый файл
Во всех описанных выше способах каждый лист сохранялся в свой отдельный файл. Если же вы хотите сохранить в отдельный новый файл сразу группу выделенных предварительно листов, то нам потребуется слегка видоизменить наш макрос:
Способ 5. Сохранение листов как отдельных PDF-файлов
- для этого используется уже другой метод (ExportAsFixedFormat а не Copy)
- листы выводятся в PDF с параметрами печати, настроенными на вкладке Разметка страницы (Page Layout)
- книга должна быть сохранена на момент экспорта
Нужный нам код будет выглядеть следующим образом:
Способ 6. Готовый макрос из надстройки PLEX
Если лень или нет времени внедрять все вышеописанное, то можно воспользоваться готовым макросом из моей надстройки PLEX:
Читайте также: