
Как сделать рекурсию в excel
На данный момент в Microsoft Excel имеется почти пять сотен функций рабочего листа, доступных через окно Мастера функций - кнопка fx в строке формул. Это весьма приличный набор, но, тем не менее, почти каждый пользователь рано или поздно сталкивается с ситуацией, когда в этом списке не оказывается нужной ему функции - просто потому, что её нет в Excel.
До сих пор единственным способом решить эту проблему были макросы, т.е. написание своей пользовательской функции (UDF = User Defined Function) на Visual Basic, что требует соответствующей программистской квалификации и бывает, порой, совсем непросто. Однако, с последними обновлениями Office 365 ситуация изменилась в лучшую сторону - в Excel была добавлена специальная "обёрточная" функция LAMBDA. С её помощью задача по созданию собственных функций теперь решается легко и красиво.
Давайте рассмотрим принцип её использования на следующем примере.
Как вы, скорее всего, знаете в Excel есть несколько функции для разборки даты позволяющие определить номер дня, месяца, недели и года для указанной даты. Но почему-то нет функции, определяющий номер квартала, который тоже часто нужен, правда? Давайте исправим этот недостаток и создадим с помощью LAMBDA собственную новую функцию для решения этой задачи.
Шаг 1. Пишем формулу
Начём с того, что вручную привычным образом напишем формулу в ячейке листа, которая вычисляет то, что нам нужно. В случае с номером квартала это можно сделать, например, так:

Шаг 2. Заворачиваем в LAMBDA и тестируем
Теперь пришло время применить новую функцию LAMBDA и завернуть в неё нашу формулу. Синтаксис у функции следующий:
=LAMBDA( Переменная1 ; Переменная2 ; . ПеременнаяN ; Выражение )
где сначала перечисляются имена одной или нескольких переменных, а последним аргументом всегда идёт формула или вычисляемое выражение, которое их использует. Имена переменных не должны быть похожи на адреса ячеек и не должны содержать точки.
В нашем случае переменная будет только одна - дата, для которой мы считаем номер квартала. Переменную для неё давайте назовем, допустим, d. Тогда завернув нашу формулу в функцию LAMBDA и подменив адрес исходной ячейки A2 на придуманное имя переменной, мы получим:

Обратите внимание, что после такого преобразования наша формула (по сути - правильная!) стала выдавать ошибку, т.к. теперь в неё не передается исходная дата из ячейки А2. Для тестирования и уверенности, можно передать ей аргументы, дописав их после функции LAMBDA в круглых скобках:

Шаг 3. Создаем имя
Теперь самая легкая и приятная часть. Открываем Диспетчер имен на вкладке Формулы (Formulas - Name Manager) и создаём новое имя кнопкой Создать (Create) . Придумываем и вводим имя для нашей будущей функции (например, НОМКВАРТАЛА), а в поле Ссылка (Reference) аккуратно копируем из строки формул и вставляем нашу функцию LAMBDA, только без последнего аргумента (А2):

Всё. После нажатия на ОК созданную функцию можно использовать в любой ячейке на любом листе этой книги:

Использование в других книгах
Поскольку созданные с помощью LAMBDA пользовательские функции представляет из себя, по сути, именованные диапазоны, то можно легко сделать их доступными не только в текущей книге. Достаточно будет скопировать ячейку с функцией и вставить в любое место листа другого файла.
LAMBDA и динамические массивы
Пользовательские функции, создаваемые с помощью функции LAMBDA успешно поддерживают работу с новыми динамическими массивами и их функциями (ФИЛЬТР, УНИК, СОРТ), добавленными в Microsoft Excel в 2020 году.
Допустим, мы хотим создать новую пользовательскую функцию, которая сравнивала бы два списка и выдавала разницу между ними - те элементы из первого списка, которые отсутствуют во втором. Жизненная задача, не правда ли? Раньше для такого использовали либо функции а-ля ВПР (VLOOKUP) , либо сводные таблицы, либо запросы Power Query. Теперь же можно обойтись одной формулой:

В английской версии это будет:
Здесь функция СЧЁТЕСЛИ подсчитывает количество вхождений каждого элемента первого списка во второй, а затем функция ФИЛЬТР отбирает только те из них, у кого этих вхождений не оказалось. Завернув эту конструкцию в LAMBDA и создав на её основе именованный диапазон с названием, например, ПОИСКОТЛИЧ - мы получим удобную функцию, выдающую результат сравнения двух списков в виде динамического массива:

Если в качестве исходных данных будут не обычные, а "умные" таблицы - наша функция тоже справится без проблем:

Другой пример - динамическое разделение текста путём превращения его в XML и последующего разбора по ячейкам с помощью функции ФИЛЬТР.XML, которое мы недавно разбирали. Чтобы не воспроизводить эту сложную формулу каждый раз вручную, проще будет завернуть её в LAMBDA и создать на её основе динамический диапазон, т.е. новую компактную и удобную функцию, назвав её, например, РАЗДТЕКСТ:

Первым аргументом этой функции будет ячейка с исходным текстом, а вторым - символ-разделитель, в возвращать результат она будет в виде горизонтального динамического массива. Код функции при этом будет следующим:
Список примеров можно продолжать бесконечно - в любой ситуации, где вам часто приходится вводить одну и ту же длинную и громоздкую формулу функция LAMBDA сделает жизнь ощутимо проще.
Рекурсивный перебор символов
Все предыдущие примеры демонстрировали только одну, наиболее очевидную, сторону функции LAMBDA - её применение в качестве "обёртки" для заворачивания в неё длинных формул и упрощения их ввода. На самом деле, у LAMBDA есть ещё одна, гораздо более глубокая, сторона, превращающая её почти что в полноценный язык программирования.
Дело в том, что принципиально важной особенностью LAMBDA-функций является возможность реализации в них рекурсии - логики вычислений, когда в процессе расчета функция вызывает сама себя. С непривычки, возможно, звучит жутковато, но в программировании рекурсия - обычное дело. Даже в макросах на Visual Basic можно её реализовать, а теперь, вот, как видите, дошло и до Excel. Давайте попробуем разобраться в этой технике на практическом примере.
Предположим, нам требуется создать пользовательскую функцию, которая удаляла бы из исходного текста все заданные символы. Полезность такой функции, думаю, доказывать вам не нужно - с её помощью было бы очень удобно очищать замусоренные входные данные, правда?
Однако, по сравнению с предыдущими, нерекурсивными примерами, нас ожидают две сложности.
- Нам придётся придумать название для нашей функции до того, как мы начнём писать её код, т.к. в нём это название уже будет использоваться для вызова функцией самой себя.
- Ввести такую рекурсивную функцию в ячейку и отлаживать её, указав после LAMBDA аргументы в скобках (как мы делали ранее) не получится. Придётся создавать функцию сразу "с нуля" в Диспетчере Имен (Name Manager) .
Назовём нашу функцию, допустим, ОЧИСТКА и хотелось бы, чтобы у неё было два аргумента - текст, который нужно почистить и список исключаемых символов в виде текстовой строки:

Создадим, как делали ранее, на вкладке Формулы в Диспетчере имён именованный диапазон, назовём его ОЧИСТКА и введём в поле Диапазон следующую конструкцию:
Здесь переменная t - это исходный очищаемый текст, а d - список символов на удаление.
Работает всё это следующим образом:
Итерация 1
Фрагмент ПОДСТАВИТЬ(t;ЛЕВСИМВ(d);""), как легко догадаться, заменяет в исходном тексте t первый слева символ из удаляемого набора d на пустую текстовую строку, т.е. удаляет букву "А". В качестве промежуточного результата получаем:
Вш зкз н 125 руб.
Итерация 2
Затем функция вызывает сама себя и в качестве входных данных (первый аргумент) получает уже то, что осталось после очистки на предыдущем шаге, а вторым аргументом задавая строку исключаемых символов начиная не с первого, а со второго символа, т.е. "БВГДЕЁЖЗИКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ.," без начальной "А" - это делает функция ПСТР. Как и до этого, функция берет первый слева символ из оставшихся (Б) и заменяет его в данном ей тексте (Зкз н 125 руб.) на пустую строку - получаем в качестве промежуточного результата:
Вш зкз н 125 ру.
Итерация 3
Функция опять вызывает сама себя, получая в качестве первого аргумента то, что осталось от зачищаемого текста на предыдущей итерации (Вш зкз н 125 ру.), а в качестве второго - урезанный слева ещё на один символ набор исключаемых знаков, т.е. "ВГДЕЁЖЗИКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ.," без начальной "Б". Затем опять берёт из этого набора первый символ слева (В) и удаляет его из текста - получаем:
И так далее - надеюсь, вы ухватили идею. С каждой итерацией список удаляемых символов будет обрезаться слева и мы будем искать и заменять на пустоту очередной символ из набора.
Когда все символы закончатся нам необходимо будет выйти из цикла - эту роль как раз и выполняет функция ЕСЛИ (IF) , в которую завернута наша конструкция. Если символов для удаления не осталось (d=""), то функция не должна больше вызывать саму себя, а просто должна вернуть зачищаемый текст (переменная t) в его финальном виде.
Рекурсивный перебор ячеек
Похожим образом можно реализовать и рекурсивный перебор ячеек в заданном диапазоне. Предположим, что мы хотим создать лямбда-функцию с именем ЗАМЕНАПОСПИСКУ для оптовой замены фрагментов в исходном тексте по заданному списку-справочнику. Выглядеть всё это в результате должно так:

Т.е. у нашей функции ЗАМЕНАПОСПИСКУ будет три аргумента:
- ячейка с текстом для обработки (исходный адрес)
- первая ячейка столбца со значениями для поиска из справочника
- первая ячейка столбца со значениями на замену из справочника
Функция должна проходить сверху-вниз по справочнику и заменять последовательно все варианты из левого столбца Найти на соответствующие варианты из правого столбца Заменить. Реализовать такое можно следующей рекурсивной лямбда-функцией:

Здесь в переменной t хранится исходный текст из очередной ячейки столбца Адрес, а переменные n и z указывают на первые ячейки в столбцах Найти и Заменить, соответственно.
Как и в предыдущем примере, сначала эта функция заменяет в исходном тексте с помощью функции ПОДСТАВИТЬ (SUBSTITUTE) данные по первой строке справочника (т.е. СПб на Санкт-Петербург ), а затем вызывает сама-себя, но со сдвигом по справочнику вниз на следующую строку (т.е. заменяет С-Пб на Санкт-Петербург ). Затем вызывает себя ещё раз со сдвигом вниз - и заменяет уже Питер на Санкт-Петербург и т.д.
Сдвиг вниз на каждой итериации реализован стандартной экселевской функцией СМЕЩ (OFFSET) , у которой в данном случае три аргумента - исходный диапазон, сдвиг по строкам (1) и сдвиг по столбцам (0).
Ну, и как только мы достигаем конца справочника (n=""), то должны закончить рекурсию - прекращаем вызывать сами себя и выводим то, что накопилось после всех выполненных замен в переменной исходного текста t.
Вот и всё. Никаких хитрых макросов или запросов Power Query - вся задача решается одной функцией.
Рекурсивным называется уравнение, в котором переменная появляется по обе стороны от знака равенства. Следующие уравнения можно назвать рекурсивными:
x = 1/(х+1)
x = COS(x)
x = К0РЕНЬ(x+5)
x = 2^(1/х)
x = 5 + (1/x)
Вы можете решать рекурсивные уравнения, используя преднамеренную циклическую ссылку.
Этот метод использует итеративные вычисления. По умолчанию Excel их не выполняет, так что вам нужно изменить настройки, установив флажок Включить итеративные вычисления в разделе Формулы диалогового окна Параметры Excel (рис. 129.1).

Рис. 129.1. Для решения рекурсивных уравнений необходимо включить возможность итеративных вычислений
Первый шаг заключается в преобразовании рекурсивного уравнения в ссылающуюся на саму себя формулу. Для решения первого уравнения введите следующую формулу в ячейку А1:
=1/(A+1) . Формула сходится к 0,618033989, что является значением х, удовлетворяющим уравнению.
Excel использует итеративный процесс для вычисления решения. Максимальное количество итераций, выполняющееся для каждого вычисления, указано в разделе Формулы диалогового окна Параметры Excel. Вам, возможно, потребуется нажать F9 несколько раз, прежде чем решение перестанет изменяться.
Однако иногда этот метод не работает. Например, формула допускает возможность деления на нуль. Решение заключается в проверке на ошибки. Если формула выводит ошибку, то измените незначительно повторное значение. Так, предыдущая формула может быть переписана с использованием функции ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(1/(A1+1);A1+0.01) .
Функция ЕСЛИОШИБКА работает только с Excel 2007 и более поздними версиями. Следующий вариант формулы совместим с предыдущими версиями Excel:
=ЕСЛИ(ЕОШ(1/(A1+1));A1+0,01;1/(A1+1)) .
На рис. 129.2 показан рабочий лист, где вычисляется несколько рекурсивных уравнений в столбце В. Формулы в столбце D обеспечивают проверку результатов. Например, формула в столбце D2 будет следующей:
=1/(B2+1) .
Формулы в столбце Е отображают разницу между значениями в столбцах В и D. Если решение верное, то столбец Е выводит 0 (или значение, очень близкое к 0).

Рис. 129.2. Для вычисления нескольких рекурсивных уравнений применяются циклические ссылки
Рекурсивная процедура вызывает саму себя. как правило, это не самый эффективный способ написания кода Visual Basic.
В следующей процедуре используется рекурсия для вычисления факториала исходного аргумента.
Рекомендации по рекурсивным процедурам
Ограничение условий. Необходимо разработать рекурсивную процедуру для проверки по крайней мере одного условия, которое может завершить рекурсию, и необходимо также обработать случай, когда ни одно из таких условий не будет удовлетворено разумным числом рекурсивных вызовов. При отсутствии хотя бы одного условия, которое может быть выполнено без ошибок, ваша процедура выполняет высокий риск выполнения в бесконечном цикле.
Использование памяти. Приложение имеет ограниченный объем пространства для локальных переменных. Каждый раз, когда процедура вызывает саму себя, она использует больше пространства для дополнительных копий своих локальных переменных. Если этот процесс будет продолжаться неограниченно, он приводит к StackOverflowException ошибке.
Эффективность. Почти всегда можно заменить цикл для рекурсии. Цикл не имеет дополнительной нагрузки на передачу аргументов, инициализацию дополнительного хранилища и возврат значений. Производительность может быть значительно выше без рекурсивных вызовов.
Взаимная рекурсия. Вы можете столкнуться с очень низкой производительностью или даже с бесконечным циклом, если две процедуры вызывают друг друга. Такой проект представляет те же проблемы, что и одна Рекурсивная процедура, но может быть труднее для обнаружения и отладки.
Вызов с круглыми скобками. Function При рекурсивном вызове процедуры необходимо следовать имени процедуры с круглыми скобками, даже если нет списка аргументов. В противном случае имя функции берется, как представляет возвращаемое значение функции.
Тестирование. При написании рекурсивной процедуры следует тщательно протестировать ее, чтобы убедиться, что она всегда соответствует определенному ограничению. Также следует убедиться, что не хватает памяти из-за слишком большого количества рекурсивных вызовов.
Рис. 1. Пример циклической ссылки
Рис. 2. Параметры Excel
В открывшемся окне «Параметры Excel» перейдите на вкладку Формулы и отметьте «Включить итеративные вычисления» (рис. 3). Помните, что эта опция включается для приложения Excel в целом (а не для одного файла), и будет действовать, пока вы ее не отключите.
Рис. 3. Включить итеративные вычисления
На этой же вкладе, можно выбрать, как будут вестись вычисления: автоматически или вручную. При автоматическом вычислении Excel сразу рассчитает конечный результат, при вычислениях, вручную, можно будет наблюдать результат каждой итерации (простым нажатием F9 запуская каждый новый цикл вычисления).
Решим уравнение третьей степени: х 3 – 4х 2 – 4х + 5 = 0 (рис. 4). Для решения этого уравнения (и любого другого уравнения совершенно произвольного вида) понадобится всего одна ячейка Excel.
Рис. 4. График функции f(x)
Для решения уравнения нам понадобится рекуррентная формула (то есть, формула, выражающая каждый член последовательности через один или несколько предыдущих членов):
(1) x = x – f(x)/f’(x), где
f(x) – функция, задающая уравнение, корни которого мы ищем; f(x) = х 3 – 4х 2 – 4х + 5
f’(x) – производная нашей функции f(x); f’(x) = 3х 2 – 8х – 4; производные основных элементарных функций можно посмотреть здесь.
Если вы заинтересовались, откуда взялась формула (1), можете почитать, например, здесь.
Итоговая рекуррентная формула имеет вид:
(2) х = x – (х 3 – 4х 2 – 4х + 5)/(3х 2 – 8х – 4)
Выберем любую ячейку на листе Excel (рис. 5; в нашем примере это ячейка G19), присвоим ей имя х, и введем в нее формулу:
Можно вместо х использовать адрес ячейки… но согласитесь, что имя х, смотрится привлекательнее; следующую формулу я ввел в ячейку G20:
Рис. 5. Рекуррентная формула: (а) для поименованной ячейки; (б) для обычного адреса ячейки
Как только мы введем формулу и нажмем Enter, в ячейке сразу же появится ответ – значение 0,77. Это значение соответствует одному из корней уравнения, а именно второму (см. график функции f(x) на рис. 4). Поскольку начальное приближение не задавалось, итерационный вычислительный процесс начинался со значения, по умолчанию хранимого в ячейке х и равного нулю. Как же получить остальные корни уравнения?
Для изменения стартового значения, с которого рекуррентная формула начинает свои итерации, предлагается использовать функцию ЕСЛИ: [1]
Здесь значение «-5» – начальное значение для рекуррентной формулы. Изменяя его, можно выйти на все корни уравнения:
| Начальное значение | Корень уравнения |
| 1 | 0,77 |
| -5 | -1,40 |
| 8 | 4,63 |
[1] Идея подсмотрена здесь
7 комментариев для “Excel. Использование циклических ссылок для решения уравнений итерационным способом”
Офигенный сайт!
И как всегда когда не нужно все находишь!
Блин у меня по экономическому моделированию в Excell курсовик был в институте, вот время помню кучу потерял а тут все в одном флаконе:)
Все равно инфа пригодится, даже очень!
И нам зараза в этом гребанном институте мать их так этих учителей даже близко ничего подобного не рассказывали. Я не про этот пример говорю а про остальные..
«Вычисление стандартного отклонения для данных с тенденцией», «Нормальное распределение» и т.п.. даже объяснить не могли или не хотели как это все применять, а тут все наглядно и понятно! Огромное спасибо! Не зря я на этот сайт наткнулся, чую он мне еще окажет неплохую помощь))))
В упор не понимаю откуда берется предел для определения корней уравнения, если «Здесь значение «-5» – начальное значение для рекуррентной формулы. Изменяя его, можно выйти на все корни уравнения»
У меня график получается, который с осью Х не имеет вообще пересечений, мож где накосячила?
Пожалуйста подскажите, а то у меня взрыв мозга будет скоро…((((
Тамара, если Вы строите график на основе моих данных, откройте файл Excel; если Вы используете собственные данные, пришлите мне на mail Ваш файл, попробую помочь))
Спасибо заранее за беспокойство, вот такое уравнение у^3-20у^2-158у-420=0, если не трудно объясните пожалуйста как вы определяте предел в каких знчениях надо считать корни.
Excel, как универсальный табличный редактор, давно и неплохо справляется с большинством задач прогнозирования (см. список литературы в конце заметки). Однако, не всегда вычисления в Excel являются простыми и понятными. И вот в версии 2016 года разработчики Microsoft добавили семейство функций ПРЕДСКАЗ (FORECAST), которые позволяют в несколько кликов решать большой круг задач прогнозирования на основе экспоненциального сглаживания.
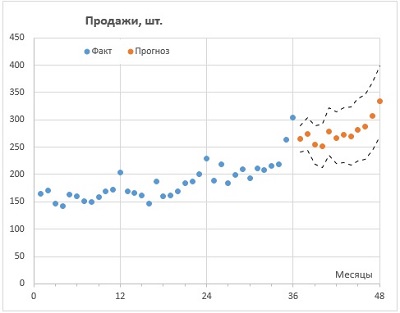
Рис. 1. Прогнозирование продаж в Excel с помощью семейства функций ПРЕДСКАЗ
Об экспоненциальном сглаживании
Экспоненциальное сглаживание также известно, как метод ETS: ошибки (Errors), тренд (Trend), сезонный фактор (Seasonal). Для составления прогноза используются все исторические данные, но коэффициенты, определяющие вклад, убывают в прошлое по экспоненте (отсюда и название). Это позволяет, с одной стороны, чутко реагировать на свежие данных, с другой стороны, сохранять информацию об историческом поведении всего временного ряда. Если данным присущ тренд, он вычисляется в каждой точке данных (а не на основе регрессии всего временного ряда). Наконец, с помощью автокорреляции в данных выявляется сезонность.
Преимущество модели в том, что она не использует никаких предположений относительно характера тренда (или его отсутствия) и периодичности сезонных колебаний (или их отсутствия). Все коэффициенты в модели подбираются на основе минимизации суммы квадратов ошибок, то есть, разности между прогнозом на исторических данных и самих данных. Если вас интересует, как это происходит, рекомендую работу Формана (см. список литературы).
Собственно, оптимизируются три коэффициента:
α – разброс относительно среднего
Разработчики Microsoft не предоставили пользователям возможность влиять на выбор коэффициентов, за исключением периода сезонности (об этом ниже).
Обзор функций семейства ПРЕДСКАЗ
В Excel представлено 5 функций:
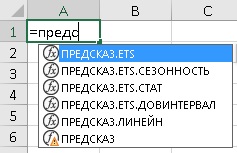
Рис. 2. Семейство функций ПРЕДСКАЗ в Excel
ПРЕДСКАЗ.ETS рассчитывает будущее значение на основе существующих (ретроспективных) данных методом экспоненциального сглаживания. Т.е., дает прогноз одним числом.
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ возвращает доверительный интервал для прогнозной величины. Доверительный интервал следует отложить по обе стороны от среднего значения. Вместе с ПРЕДСКАЗ.ETS позволяет построить «коридор» прогноза.
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ возвращает длину повторяющегося фрагмента, обнаруженного в заданном временном ряду. Например, 12, если исторические данные представляют из себя продажи за месяц.
ПРЕДСКАЗ.ETS.СТАТ возвращает восемь статистических значений, являющихся результатом прогнозирования временного ряда. Вряд ли вы будете использовать эту функцию. Она нужна для более тонкого исследования параметров прогнозной модели.
ПРЕДСКАЗ.ЛИНЕЙН вычисляет будущее значение с помощью линейной регрессии исторических данных. До версии 2016 в Excel вместо семейства функций была единственная функция ПРЕДСКАЗ, которая работала также, как и ПРЕДСКАЗ.ЛИНЕЙН. Функция ПРЕДСКАЗ оставлена для обратной совместимости, но скоро перестанет поддерживаться. Далее в заметке ПРЕДСКАЗ.ЛИНЕЙН не рассматривается, так как не относится к функциям, использующим алгоритм экспоненциального сглаживания.
ПРЕДСКАЗ.ETS
В качестве примера рассмотрим месячный пассажиропоток в аэропорту (пример от MS). Исторические данные были собраны за период с января 2009 по декабрь 2912 г.
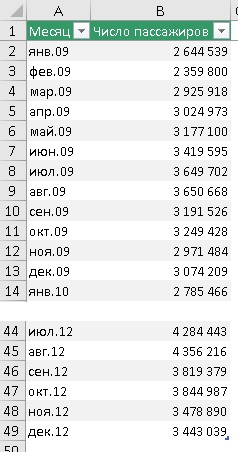
Рис. 3. Исторические данные
Продолжим временную шкалу еще на год, и создадим столбец для прогноза. Обычно прогноз располагают в отдельном столбце для того, чтобы при построении графика представить исторические и прогнозные значения разными линиями.
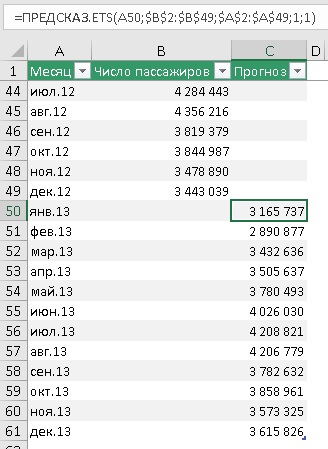
Рис. 4. Прогнозные значения на основе функции ПРЕДСКАЗ.ETS
Подробнее о формуле в ячейке С50:
Первый аргумент – целевая_дата = А50 – янв.13, т.е., в ячейке С50 ищется прогноз пассажиропотока для января 2013 г. Ссылка относительная, что позволит при протягивании функции вниз по столбцу ссылаться на новое значение: в С51 – на А51, в С52 – на А52 и т.д.
Второй аргумент – значения = $B$2:$B$49. Здесь расположены исторические данные пассажиропотока. Ссылка абсолютная, чтобы при протягивании формулы ячейки, на которые ссылаются не изменились.
Третий аргумент – временная_шкала = $A$2:$A$49. Здесь расположены даты временной шкалы или номера периодов. Важно чтобы они отстояли друг от друга на фиксированный интервал. Если интервал не будет фиксированным, Excel всё еще будет исходить из гипотезы, что интервал фиксированный, а некоторые данные пропущены. Как обрабатываются такие ситуации описано ниже. Сортировать массив по значениям временной шкалы не обязательно, так как ПРЕДСКАЗ.ETS сама отсортирует данные прежде, чем выполнить расчеты.
Четвертый аргумент – [сезонность] = 1. Это необязательный аргумент. Значение по умолчанию равно 1. Для него Excel автоматически определяет сезонность и использует положительные целые числа в качестве длины сезонного шаблона. Значение 0 предписывает не использовать фактор сезонности, в результате чего прогноз будет линейным. Если для этого параметра задано положительное целое число, алгоритм использует его в качестве длины шаблона сезонности. Например, вы знаете, что сезонность равна 4 (квартальная периодичность), но предполагаете, что она слабая, и автоматический алгоритм Excel может ее не выявить, и будет считать, что сезонности нет. Для начала я рекомендовал бы использовать значение по умолчанию.
Пятый аргумент – [заполнение_данных] = 1. Это необязательный аргумент. Хотя временная шкала требует постоянный шаг между точками данных, FORECAST.ETS поддерживает до 30% отсутствующих данных и автоматически настраивает их. 0 указывает, что алгоритм учитывает отсутствующие точки в качестве нулей. Если задано значение 1 (вариант по умолчанию), функция определяет отсутствующие значения как среднее между соседними точками.
Шестой аргумент – [агрегирование] – в нашем примере опущен. Это необязательный аргумент. Он нужен, если даты временной шкалы или номера периодов содержат дубли. Функция ПРЕДСКАЗ.ETS выполнит агрегирование точек с одинаковой меткой времени. Параметр агрегирования — это числовое значение, определяющее способ агрегирования нескольких значений с одинаковой меткой времени. Для значения по умолчанию 0 используется метод СРЗНАЧ; также доступны варианты СУММ, СЧЁТ, СЧЁТЗ, МИН, МАКС и МЕДИАНА.
Читайте также: