
Как обработать данные в эксель
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку "Пакет анализа".
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки "Надстройка анализа", вы можете загрузить надстройку VBA так же, как и надстройку "Надстройка анализа". В поле Доступные надстройки выберите "Надстройка анализа — VBA".
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий , имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений , используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения "различаются". В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные "различаются".
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа "Описательная статистика" применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа "Экспоненциальное сглаживание" применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
Инструмент "Анализ Фурье" применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.
Инструмент "Гистограмма" применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа "Скользящее среднее" применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент "Генерация случайных чисел" применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа "Регрессия" применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа "Выборка" создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
Z-тест. Средство анализа "Две выборки для середины" выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
В этом посте Ренат Шагабутдинов, ассистент генерального директора издательства «Манн, Иванов и Фербер», делится классными Excel-лайфхаками. Приведённые советы будут полезны для всех, кто занимается различной отчётностью, обработкой данных и созданием презентаций.
Ренат уже не в первый раз выступает гостевым автором на Лайфхакере. Ранее мы публиковали отличный материал от него о том, как составить план тренировок: основные книги и онлайн-ресурсы, а также пошаговый алгоритм создания тренировочного плана.
В этой статье собраны несложные приёмы, позволяющие упростить работу в Excel. Особенно они пригодятся тем, кто занимается управленческой отчётностью, готовит разнообразные аналитические отчёты, основанные на выгрузках из 1С и других отчётах, формирует из них презентации и диаграммы для руководства. Не претендую на абсолютную новизну — в том или ином виде эти приёмы наверняка обсуждались на форумах или упоминались в статьях.
Простые альтернативы ВПР и ГПР, если искомые значения не в первом столбце таблицы: ПРОСМОТР, ИНДЕКС+ПОИСКПОЗ
Функции ВПР (VLOOKUP) и ГПР (HLOOKUP) работают только в том случае, если искомые значения находятся в первом столбце или строке той таблицы, из которой вы планируете получить данные.
В остальных случаях есть два варианта:
- Использовать функцию ПРОСМОТР (LOOKUP).
У неё следующий синтаксис: ПРОСМОТР (искомое_значение; вектор_просмотра; вектор_результата). Но для её корректной работы нужно, чтобы значения диапазона вектор_просмотра были отсортированы по возрастанию: - Использовать сочетание функций ПОИСКПОЗ (MATCH) и ИНДЕКС (INDEX).
Функция ПОИСКПОЗ возвращает порядковый номер элемента в массиве (с её помощью вы можете найти, в какой строке таблицы искомый элемент), а функция ИНДЕКС возвращает элемент массива с заданным номером (который мы и узнаем с помощью функции ПОИСКПОЗ). Синтаксис функций:
• ПОИСКПОЗ (искомое_значение; массив_поиска; тип_сопоставления) — для нашего случая нам нужен тип сопоставления «точное сопоставление», ему соответствует цифра 0.
• ИНДЕКС (массив; номер_строки; [номер_столбца]). В данном случае номер столбца указывать не нужно, так как массив состоит из одной строки.
Как быстро заполнить пустые ячейки в списке
Задача — заполнить ячейки в столбце со значениями сверху (чтобы тематика стояла в каждой строке таблицы, а не только в первой строке блока книг по тематике):
Выделяем столбец «Тематика», нажимаем на ленте в группе «Главная» кнопку «Найти и выделить» → «Выделить группу ячеек» → «Пустые ячейки» и начинаем ввод формулы (то есть ставим знак равно) и ссылаемся на ячейку сверху, просто нажимая стрелку вверх на клавиатуре. После этого нажимаем Ctrl + Enter. После этого можно сохранить полученные данные как значения, так как формулы больше не нужны:
Как найти ошибки в формуле
Вычисление отдельной части формулы
Чтобы разобраться в сложной формуле (в которой в качестве аргументов функции используются другие функции, то есть одни функции вложены в другие) или найти в ней источник ошибок, часто нужно вычислить её часть. Есть два простых способа:
- Чтобы вычислить часть формулы прямо в строке формул, выделите эту часть и нажмите F9:
В данном примере была проблема с функцией ПОИСК (SEARCH) — в ней были перепутаны местами аргументы. Важно помнить, что если вы не отмените вычисление части функции и нажмёте Enter, то вычисленная часть так и останется числом. - Нажмите на кнопку «Вычислить формулу» в группе «Формулы» на ленте:
В появившемся окне можно вычислять формулу по шагам и определить, на каком этапе и в какой функции возникает ошибка (если она есть):
Как определить, от чего зависит или на что ссылается формула
Чтобы определить, от каких ячеек зависит формула, в группе «Формулы» на ленте нажмите на кнопку «Влияющие ячейки»:
Появляются стрелки, указывающие, от чего зависит результат вычислений.
Если отображается символ, выделенный на картинке красным цветом, то формула зависит от ячеек, находящихся на других листах или в других книгах:
Щёлкнув на него, мы увидим, где именно находятся влияющие ячейки или диапазоны:
Рядом с кнопкой «Влияющие ячейки» находится кнопка «Зависимые ячейки», работающая аналогично: она отображает стрелки от активной ячейки с формулой к ячейкам, которые зависят от неё.
Кнопка «Убрать стрелки», расположенная в том же блоке, позволяет убрать стрелки к влияющим ячейкам, стрелки к зависимым ячейкам или же оба типа стрелок сразу:
Как найти сумму (количество, среднее) значений ячеек с нескольких листов
Допустим, у вас есть несколько однотипных листов с данными, которые вы хотите сложить, посчитать или обработать как-то иначе:
Для этого в ячейку, в которой вы хотите видеть результат, введите стандартную формулу, например СУММ (SUM), и укажите в аргументе через двоеточие название первого и последнего листов из списка тех листов, что вам нужно обработать:
Вы получите сумму ячеек с адресом B3 с листов «Данные1», «Данные2», «Данные3»:
Такая адресация работает для листов, расположенных последовательно. Синтаксис следующий: =ФУНКЦИЯ (первый_лист:последний_лист!ссылка на диапазон).
Как автоматически строить шаблонные фразы
Используя базовые принципы работы с текстом в Excel и несколько простых функций, можно готовить шаблонные фразы для отчётов. Несколько принципов работы с текстом:
- Объединяем текст с помощью знака & (можете заменить его функцией СЦЕПИТЬ (CONCATENATE), но в этом нет особого смысла).
- Текст всегда записывается в кавычках, ссылки на ячейки с текстом — всегда без.
- Чтобы получить служебный символ «кавычки», используем функцию СИМВОЛ (CHAR) с аргументом 32.
Пример создания шаблонной фразы с помощью формул:
В данном случае, кроме функции СИМВОЛ (CHAR) (для отображения кавычек) используется функция ЕСЛИ (IF), позволяющая изменять текст в зависимости от того, наблюдается ли положительная динамика продаж, и функция ТЕКСТ (TEXT), позволяющая отобразить число в любом формате. Её синтаксис описан ниже:
ТЕКСТ (значение; формат)
Формат указывается в кавычках точно так же, как если бы вы вводили пользовательский формат в окне «Формат ячеек».
Автоматизировать можно и более сложные тексты. В моей практике была автоматизация длинных, но рутинных комментариев к управленческой отчётности в формате «ПОКАЗАТЕЛЬ упал/вырос на XX относительно плана в основном из-за роста/снижения ФАКТОРА1 на XX, роста/снижения ФАКТОРА2 на YY…» с меняющимся списком факторов. Если вы пишете такие комментарии часто и процесс их написания можно алгоритмизировать — стоит один раз озадачиться созданием формулы или макроса, которые избавят вас хотя бы от части работы.
Как сохранить данные в каждой ячейке после объединения
При объединении ячеек сохраняется только одно значение. Excel предупреждает об этом при попытке объединить ячейки:
Чтобы объединить ячейки и при этом сохранить данные в каждой из них (возможно, у вас есть формула, как в этом абстрактном примере; возможно, вы хотите объединить ячейки, но сохранить все данные на будущее или скрыть их намеренно), объедините любые ячейки на листе, выделите их, а затем с помощью команды «Формат по образцу» перенесите форматирование на те ячейки, которые вам и нужно объединить:
Как построить сводную из нескольких источников данных
Если вам нужно построить сводную сразу из нескольких источников данных, придётся добавить на ленту или панель быстрого доступа «Мастер сводных таблиц и диаграмм», в котором есть такая опция.
Сделать это можно следующим образом: «Файл» → «Параметры» → «Панель быстрого доступа» → «Все команды» → «Мастер сводных таблиц и диаграмм» → «Добавить»:
После этого на ленте появится соответствующая иконка, нажатие на которую вызывает того самого мастера:
При щелчке на неё появляется диалоговое окно:
В нём вам необходимо выбрать пункт «В нескольких диапазонах консолидации» и нажать «Далее». В следующем пункте можно выбрать «Создать одно поле страницы» или «Создать поля страницы». Если вы хотите самостоятельно придумать имя для каждого из источников данных — выберите второй пункт:
В следующем окне добавьте все диапазоны, на основании которых будет строиться сводная, и задайте им наименования:
После этого в последнем диалоговом окне укажите, где будет размещаться отчёт сводной таблицы — на существующем или новом листе:
Как рассчитать количество вхождений текста A в текст B («МТС тариф СуперМТС» — два вхождения аббревиатуры МТС)
В данном примере в столбце A есть несколько текстовых строк, и наша задача — выяснить, сколько раз в каждой из них встречается искомый текст, расположенный в ячейке E1:
Для решения этой задачи можно воспользоваться сложной формулой, состоящей из следующих функций:
- ДЛСТР (LEN) — вычисляет длину текста, единственный аргумент — текст. Пример: ДЛСТР (“машина”) = 6.
- ПОДСТАВИТЬ (SUBSTITUTE) — заменяет в текстовой строке определённый текст другим. Синтаксис: ПОДСТАВИТЬ (текст; стар_текст; нов_текст). Пример: ПОДСТАВИТЬ (“автомобиль”;“авто”;“”)= “мобиль”.
- ПРОПИСН (UPPER) — заменяет все символы в строке на прописные. Единственный аргумент — текст. Пример: ПРОПИСН (“машина”) = “МАШИНА”. Эта функция понадобится нам, чтобы делать поиск без учёта регистра. Ведь ПРОПИСН(“машина”)=ПРОПИСН(“Машина”)
Чтобы найти вхождение определённой текстовой строки в другую, нужно удалить все её вхождения в исходную и сравнить длину полученной строки с исходной:
ДЛСТР(“Тариф МТС Супер МТС”) – ДЛСТР(“Тариф Супер”) = 6
А затем разделить эту разницу на длину той строки, которую мы искали:
6 / ДЛСТР (“МТС”) = 2
Именно два раза строка «МТС» входит в исходную.
Осталось записать этот алгоритм на языке формул (обозначим «текстом» тот текст, в котором мы ищем вхождения, а «искомым» — тот, число вхождений которого нас интересует):
Если для построенной диаграммы на листе появились новые данные, которые нужно добавить, то можно просто выделить диапазон с новой информацией, скопировать его (Ctrl + C) и потом вставить прямо в диаграмму (Ctrl + V).
2. Мгновенное заполнение (Flash Fill)
Предположим, у вас есть список полных ФИО (Иванов Иван Иванович), которые вам надо превратить в сокращённые (Иванов И. И.). Чтобы сделать это, нужно просто начать писать желаемый текст в соседнем столбце вручную. На второй или третьей строке Excel попытается предугадать наши действия и выполнит дальнейшую обработку автоматически. Останется только нажать клавишу Enter для подтверждения, и все имена будут преобразованы мгновенно. Подобным образом можно извлекать имена из email, склеивать ФИО из фрагментов и так далее.
3. Копирование без нарушения форматов
Вы, скорее всего, знаете о волшебном маркере автозаполнения. Это тонкий чёрный крест в правом нижнем углу ячейки, потянув за который можно скопировать содержимое ячейки или формулу сразу на несколько ячеек. Однако есть один неприятный нюанс: такое копирование часто нарушает дизайн таблицы, так как копируется не только формула, но и формат ячейки. Этого можно избежать. Сразу после того, как потянули за чёрный крест, нажмите на смарт-тег — специальный значок, появляющийся в правом нижнем углу скопированной области.
Если выбрать опцию «Копировать только значения» (Fill Without Formatting), то Excel скопирует вашу формулу без формата и не будет портить оформление.
4. Отображение данных из таблицы Excel на карте
В Excel можно быстро отобразить на интерактивной карте ваши геоданные, например продажи по городам. Для этого нужно перейти в «Магазин приложений» (Office Store) на вкладке «Вставка» (Insert) и установить оттуда плагин «Карты Bing» (Bing Maps). Это можно сделать и по прямой ссылке с сайта, нажав кнопку Get It Now.
После добавления модуля его можно выбрать в выпадающем списке «Мои приложения» (My Apps) на вкладке «Вставка» (Insert) и поместить на ваш рабочий лист. Останется выделить ваши ячейки с данными и нажать на кнопку Show Locations в модуле карты, чтобы увидеть наши данные на ней. При желании в настройках плагина можно выбрать тип диаграммы и цвета для отображения.
5. Быстрый переход к нужному листу
Если в файле количество рабочих листов перевалило за 10, то ориентироваться в них становится трудновато. Щёлкните правой кнопкой мыши по любой из кнопок прокрутки ярлычков листов в левом нижнем углу экрана. Появится оглавление, и на любой нужный лист можно будет перейти мгновенно.
6. Преобразование строк в столбцы и обратно
Если вам когда-нибудь приходилось руками перекладывать ячейки из строк в столбцы, то вы оцените следующий трюк:
- Выделите диапазон.
- Скопируйте его (Ctrl + C) или, нажав на правую кнопку мыши, выберите «Копировать» (Copy).
- Щёлкните правой кнопкой мыши по ячейке, куда хотите вставить данные, и выберите в контекстном меню один из вариантов специальной вставки — значок «Транспонировать» (Transpose). В старых версиях Excel нет такого значка, но можно решить проблему с помощью специальной вставки (Ctrl + Alt + V) и выбора опции «Транспонировать» (Transpose).
7. Выпадающий список в ячейке
Если в какую-либо ячейку предполагается ввод строго определённых значений из разрешённого набора (например, только «да» и «нет» или только из списка отделов компании и так далее), то это можно легко организовать при помощи выпадающего списка.
8. Умная таблица
Если выделить диапазон с данными и на вкладке «Главная» нажать «Форматировать как таблицу» (Home → Format as Table), то наш список будет преобразован в умную таблицу, которая умеет много полезного:
- Автоматически растягивается при дописывании к ней новых строк или столбцов.
- Введённые формулы автоматом будут копироваться на весь столбец.
- Шапка такой таблицы автоматически закрепляется при прокрутке, и в ней включаются кнопки фильтра для отбора и сортировки.
- На появившейся вкладке «Конструктор» (Design) в такую таблицу можно добавить строку итогов с автоматическим вычислением.
9. Спарклайны
Спарклайны — это нарисованные прямо в ячейках миниатюрные диаграммы, наглядно отображающие динамику наших данных. Чтобы их создать, нажмите кнопку «График» (Line) или «Гистограмма» (Columns) в группе «Спарклайны» (Sparklines) на вкладке «Вставка» (Insert). В открывшемся окне укажите диапазон с исходными числовыми данными и ячейки, куда вы хотите вывести спарклайны.
После нажатия на кнопку «ОК» Microsoft Excel создаст их в указанных ячейках. На появившейся вкладке «Конструктор» (Design) можно дополнительно настроить их цвет, тип, включить отображение минимальных и максимальных значений и так далее.
10. Восстановление несохранённых файлов
Представьте: вы закрываете отчёт, с которым возились последнюю половину дня, и в появившемся диалоговом окне «Сохранить изменения в файле?» вдруг зачем-то жмёте «Нет». Офис оглашает ваш истошный вопль, но уже поздно: несколько последних часов работы пошли псу под хвост.
В Excel 2013 путь немного другой: «Файл» → «Сведения» → «Управление версиями» → «Восстановить несохранённые книги» (File — Properties — Recover Unsaved Workbooks).
В последующих версиях Excel следует открывать «Файл» → «Сведения» → «Управление книгой».
Откроется специальная папка из недр Microsoft Office, куда на такой случай сохраняются временные копии всех созданных или изменённых, но несохранённых книг.
11. Сравнение двух диапазонов на отличия и совпадения
Иногда при работе в Excel возникает необходимость сравнить два списка и быстро найти элементы, которые в них совпадают или отличаются. Вот самый быстрый и наглядный способ сделать это:
- Выделите оба сравниваемых столбца (удерживая клавишу Ctrl).
- Выберите на вкладке «Главная» → «Условное форматирование» → «Правила выделения ячеек» → «Повторяющиеся значения» (Home → Conditional formatting → Highlight Cell Rules → Duplicate Values).
- Выберите вариант «Уникальные» (Unique) в раскрывающемся списке.
12. Подбор (подгонка) результатов расчёта под нужные значения
Вы когда-нибудь подбирали входные значения в вашем расчёте Excel, чтобы получить на выходе нужный результат? В такие моменты чувствуешь себя матёрым артиллеристом: всего-то пара десятков итераций «недолёт — перелёт» — и вот оно, долгожданное попадание!
Microsoft Excel сможет сделать такую подгонку за вас, причём быстрее и точнее. Для этого нажмите на вкладке «Данные» кнопку «Анализ „что если“» и выберите команду «Подбор параметра» (Insert → What If Analysis → Goal Seek). В появившемся окне задайте ячейку, где хотите подобрать нужное значение, желаемый результат и входную ячейку, которая должна измениться. После нажатия на «ОК» Excel выполнит до 100 «выстрелов», чтобы подобрать требуемый вами итог с точностью до 0,001.
Если этот обзор охватил не все полезные фишки MS Excel, о которых вы знаете, делитесь ими в комментариях!
Чтобы лучше представить, как функция "Идеи" упрощает, быстрее и интуитивнее анализ данных, функция была переименована в Анализ данных. Возможности и функциональные возможности одинаковы и по-прежнему соответствуют тем же нормативным актам о конфиденциальности и лицензировании. Если вы работаете в Полугодовом канале (корпоративный), вы можете по-прежнему видеть "Идеи", пока Excel не будет обновлен.

Анализ данных в Excel помогает вам изучить ваши данные с помощью запросов на естественном языке, которые позволяют задавать вопросы о данных без написания сложных формул. Кроме того, Анализ данных создает наглядные визуальные представления сводных данных, тенденций и закономерностей.
Есть вопрос? Мы ответим!
Просто выделите ячейку в диапазоне данных и нажмите кнопку Анализ данных на вкладке Главная. Анализ данных в Excel обработает данные и отобразит их информативные наглядные представления в области задач.
Если вы хотите получить более конкретные сведения, введите свой вопрос в поле запроса в верхней части панели и нажмите ВВОД. Анализ данных выдаст ответы с использованием графических элементов, например таблиц, диаграмм и сводных таблиц, которые можно будет вставить в книгу.
Если вы хотите проанализировать свои данные или просто хотите узнать об имеющихся возможностях, по щелчку в поле запроса функция Анализ данных предложит персонализированные вопросы.
Попробуйте воспользоваться предлагаемыми вопросами
Просто задайте вопрос
Выберите текстовое поле в верхней части панели "Анализ данных", и вы увидите список предложений, составленный на основе ваших данных.
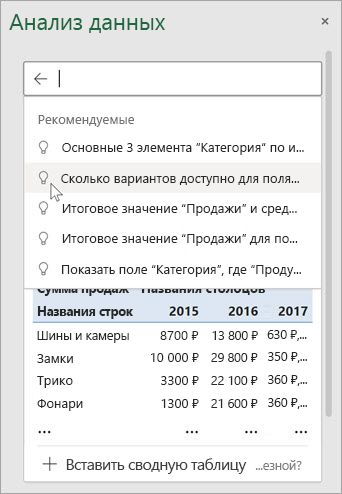
Кроме того, вы можете ввести конкретный вопрос о своих данных.
Подписчики Microsoft 365 могут пользоваться функцией Анализ данных на английском, французском, испанском, немецком, китайском (упрощенное письмо) и японском языках. Если вы являетесь подписчиком Microsoft 365, убедитесь, что у вас установлена последняя версия Office. Подробнее о разных каналах обновления Office см. в статье Обзор каналов обновления приложений Microsoft 365.
Функция запросов на естественном языке в компоненте Анализ данных предоставляется клиентам поэтапно. Сначала она будет предложена подписчикам Microsoft 365 в Актуальном канале на английском языке.
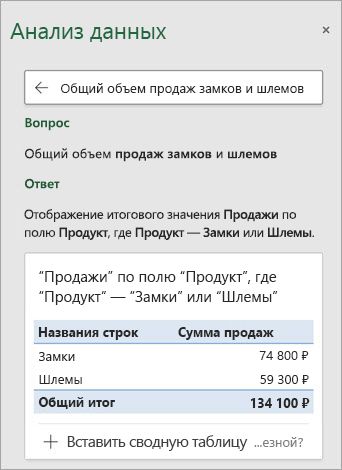
Получение конкретных сведений с помощью Анализ данных
Если у вас нет конкретного вопроса, Анализ данных не только отвечает на вопросы на естественном языке, но и анализирует данные, а также создает наглядные визуальные представления сводных данных, тенденций и закономерностей.
Вы можете сэкономить время и получить более конкретный анализ, выбрав только нужные вам поля. Когда вы выбираете поля и способ их обобщения, Анализ данных исключает другие доступные данные, что ускоряет процесс и обеспечивает предоставление предложений, меньших по количеству, но точнее сформулированных. Например, вам может потребоваться только общая сумма продаж за год. Или же можно попросить Анализ данных показать средний уровень продаж по годам.
Выберите Какие поля интересуют вас больше всего?

Выберите поля и способ обобщения содержащихся в них данных.

Анализ данных предоставляет меньшие по количеству, но точнее сформулированные предложения.
Примечание: Параметр Не является значением в списке полей относится к полям, для которых обычно не выполняется суммирование или вычисление средних значений. Например, вы не можете вычислить сумму отображаемых лет, но вы можете вычислить сумму значений отображаемых лет. Параметр Не является значением, используемый с другим полем, в котором производится суммирование или вычисление среднего значения, работает как метка строки, однако при самостоятельном использовании Не является значением подсчитывает уникальные значения выбранного поля.
Анализ данных лучше всего работает с очищенными табличными данными.

Вот некоторые советы по эффективному использованию функции Анализ данных.
Анализ данных лучше всего работает с данными, отформатированными в виде таблицы Excel. Чтобы создать таблицу Excel, щелкните в любом месте диапазона данных и нажмите клавиши CTRL+T.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
При наличии сложных или вложенных данных для преобразования перекрестных таблиц или таблиц с несколькими строками заголовков можно использовать надстройку Power Query.
Анализ данных не работает? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных может не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных размером более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Вы можете отфильтровать данные, скопировать в другое место и обработать с помощью функции Анализ данных.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Анализ данных не будет работать, когда Excel находится в режиме совместимости (то есть когда файл имеет формат XLS). Сохраните файл в формате XLSX, XLSM или XLSB.
Объединенные ячейки также могут представлять сложность для анализа. Если вы хотите выровнять данные по центру, например в заголовке отчета, то в качестве временного решения удалите все объединенные ячейки, а затем выровняйте ячейки по центру выделения. Нажмите клавиши CTRL+1 и перейдите на Выравнивание > По горизонтали > По центру выделения.
Анализ данных лучше всего работает с очищенными табличными данными.
Вот некоторые советы по эффективному использованию функции Анализ данных.
Анализ данных лучше всего работает с данными, отформатированными в виде таблицы Excel. Чтобы создать таблицу Excel, щелкните в любом месте диапазона данных и нажмите клавиши +T.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
Анализ данных не работает? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных может не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных размером более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Вы можете отфильтровать данные, скопировать в другое место и обработать с помощью функции Анализ данных.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Анализ данных не может анализировать данные, когда Excel находится в режиме совместимости (то есть когда файл имеет формат XLS). Сохраните файл в формате XLSX, XLSM или XLSB.
Объединенные ячейки также могут представлять сложность для анализа. Если вы хотите выровнять данные по центру, например в заголовке отчета, то в качестве временного решения удалите все объединенные ячейки, а затем выровняйте ячейки по центру выделения. Нажмите клавиши CTRL+1 и перейдите на Выравнивание > По горизонтали > По центру выделения.
Анализ данных лучше всего работает с очищенными табличными данными.
Вот некоторые советы по эффективному использованию функции Анализ данных.
Анализ данных лучше всего работает с данными, отформатированными в виде таблицы Excel. Чтобы создать таблицу Excel, щелкните в любом месте диапазона данных и выберите Главная > Таблицы > Форматировать как таблицу.
Убедитесь, что у вас правильно отформатированы заголовки столбцов. Заголовки должны быть представлены в виде одной строки уникальных непустых имен столбцов. Не используйте двойные строки заголовков, объединенные ячейки и т. д.
Анализ данных не работает? Скорее всего, проблема у нас, а не у вас.
Вот некоторые причины, по которым Анализ данных может не работать с вашими данными:
Анализ данных в настоящее время не поддерживает анализ наборов данных размером более 1,5 миллионов ячеек. Временного решения этой проблемы пока нет. Вы можете отфильтровать данные, скопировать в другое место и обработать с помощью функции Анализ данных.
Строковое даты, такие как "01-01-2017", анализируются как текстовые строки. В качестве временного решения можно создать для них новый столбец и отформатировать как даты с помощью функции ДАТА или ДАТАЗНАЧ.
Анализ данных постоянно совершенствуется
Даже если ни одно из указанных выше условий не выполняется, поиск рекомендаций может оказаться безрезультатным. Это объясняется тем, что служба пытается найти определенный набор классов аналитических сведений, и ей не всегда это удается. Мы постоянно работаем над расширением типов анализа, поддерживаемых службой.
Вот текущий список доступных типов анализа:
Ранг. Ранжирует элементы и выделяет тот, который существенно больше остальных.

Тренд. Выделяет тенденцию, если она прослеживается на протяжении всего временного ряда данных.

Выброс. Выделяет выбросы во временном ряду.

Большинство. Находит случаи, когда большую часть итогового значения можно связать с одним фактором.

Если вы не получили результатов, отправьте нам отзыв, выбрав на вкладке Файл пункт Отзывы и предложения.
Так как Анализ данных выполняет анализ с помощью служб искусственного интеллекта, возможно, вас беспокоит безопасность данных. Вы можете ознакомиться с дополнительными сведениями в заявлении о конфиденциальности корпорации Майкрософт.
Анализ данных использует материалы сторонних производителей. Подробности см. в разделе Сведения о лицензировании для функции "Анализ данных".
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Читайте также: