
Формулы google таблицы которых нет в excel
Продолжая тему мануала по гугл таблицам решил сегодня написать пост про массивы.
Сразу скажу, что я не представляю как эта история реализована в Excel, поэтому не смогу сравнить синтаксис и область применения, да и большая часть формул, которые я покажу - не будут работать в детище чипирователя великой Руси.
Что такое массив (array)?
Прежде всего это объект. Объект, который содержит в себе набор данных. Массивы в ГТ могут быть одномерными (строка или столбец) и многомерными - целиковая таблица (дефакто это одномерный массив состоящий из одномерных массивов).
Сейчас я покажу как они записываются, но нужно отметить нюанс. Для русской и английской версии синтаксис будет отличаться. Я буду использовать английский вариант, т.к. он удобнее как мне кажется.
Формула типа = будет являться "вертикальным" массивом, "верхний" элемент которого равен 1, а "нижний" - 2.
Формула типа = <1\2>будет являться "горизонтальным" массивом", "левый" элемент - 1, "правый" - 2. В английской версии эта формула записывается как =.
Формула типа = < < 1;2>, > будет выглядеть так:

В своем посте про switch case я показывал, как такого рода массивы могут быть использованы в функции ВПР (VLOOKUP). Ссылка: Swtich case в гугл таблицах или не самый очевидный ВПР (GS8)
И это далеко не единственный способ задать массив.
Второй вариант - arrayformula(). Эта функция не имеет русского эквивалента. arrayformula повторяет формулу, которая в ней записана для каждого элемента массива. На выходе, как правило, она также дает массив. Пример:

Что характерно - в случае arrayformula и еще ряда функция (таких как ВПР (второй аргумент), filter, счётеслимн и т.д.) они принимают аргументы в качестве массива, при этом не требуют от пользователя явной записи в виде массива (через фигурные скобки). Даже простая функция СУММ принимает на вход именно массив. Зная это - мы можем делать вложенные функции.
Приведу повторно пример из поста: Фильтры и ВПРы в ГТ (GS2)
У нас есть следующая таблица:

Давайте с помощью фильтр достанем из нее все слова, внутри которых есть бука "е".
Тут нам поможет функция REGEXMATCH() - соответствие текста определенному регулярному выражению. О самих регулярках мы поговорим в будущем. Пока нам нужно только находить букву Е. Сама функция REGEXMATCH() возвращает 1 или 0, т.е. входит регулярка в текст или не входит. Наглядно это выглядит так:

Н.Б. Формула прописана только в ячейке H1. Благодаря формуле массива она сама протянулась вдоль диапазона G1:G10.
Теперь поместим формулу из ячейки H1 в самый обычный фильтр.

Результат оказывается похожим на правду.
Н.Б. Фильтр понимает, что все значения и все сверки ему нужно пройти построчно. Поэтому внутри самого фильтра arrayformula можно не использовать.

Как мы используем arrayformula в работе?
Обычная история - есть пополняемый реестр, в котором нужно постоянно протягивать формулы.
Например, заполняемая форма. Положим у нас есть форма, которую заполняют сотрудники при тратах корп денег и нам нужно по логину почты сотрудника для каждой записи формы протянуть его ФИО. Делается это с помощью обычного ВПР. В excel нам помогла бы умная таблица, которая сама протягивает за нас формулы. Здесь такого нет. Давайте чуть усложним кейс и положим, что мы не знаем сколько сотрудников будут заполнять, а делать справочник заранее нам долго. Тогда нам понадобится список всех НОВЫХ логинов, которых мы еще не внесли в справочник. Приступим.
Первым делом сделаем имитацию формы. Вот такая получилась заготовка:

Первым делом прописываем фильтр, который будет показывать нам новые логины. Нам потребуется комбинация isna(vlookup()). Детально про нее я рассказывал в посте: Фильтры и ВПРы в ГТ (GS2)
Получилось следующим образом:

Внесем один из логинов в справочник и пропишем в столбец М формулу массива, которая будет автоматически для всех строк таблицы подтягивать ФИО.


Выглядит это таким образом.Теперь заполнение таблицы будет поэтапным (нам не нужно заранее собирать справочник для ВПРа), формулы подтягиваться будут постоянно. Особенно это удобно для таблиц, работа которых происходит на бекенде, чтобы не нужно было в них постоянно заходить и эти формулы протягивать.
Какие могут быть ошибки связанные с фильтрами или массивами?
Первое - синтаксис. ГТ автоматически закроет для вас обычные скобки, но за фигурными - нужно следить самостоятельно. Если получаете ошибку типа "Formula parse error" - с большой вероятность вы налажали с фигурными скобками.
Второе - если использовать arrayformula по беконечному диапазону (типа А:А), при это расположить ее в ячейке B2 - таблица будет пытаться постоянно достроить саму себя, т.к. формула массива всегда будет обработать на одну строку больше чем есть. Это бесконечный цикл. Нужно удалять формулу, чистить лишние строки и переписывать.
Есть ряд формул, которые очень тяжело ложатся в массивы, т.к. не подразумевают перебор, а хавают в себя все что дают. Например функция join().

Там где есть риск ручных правок - лучше не использовать такие формулы или выстраивать архитектуру доки таким образом, чтобы ручных правок не было.

Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
Оглавление:
Если результат формулы занимает больше одной ячейки
Сначала про важную особенность отображения результатов формул в Google Таблицах. Если ваша формула возвращает более одной ячейки, то весь этот массив отобразится сразу и займет столько ячеек и столбцов, сколько для него потребуется (в Excel для этого нужно было бы во все эти ячейки ввести формулу массива). На следующем примере посмотрим, как это работает.
Поможет отсортировать диапазон данных по одному или нескольким столбцам и сразу вывести результат.
=SORT(сортируемые данные; столбец_для_сортировки; по_возрастанию; [столбец_для_сортировки_2, по_возрастанию_2; . ])
Пример на скриншоте ниже, мы ввели формулу только в ячейку D2 и сортируем данные по первому столбцу (вместо ИСТИНА/ЛОЖЬ можно вводить TRUE/FALSE).
(здесь и далее — примеры для российских региональных настроек таблицы, рег. настройки меняются в меню файл → настройки таблицы)

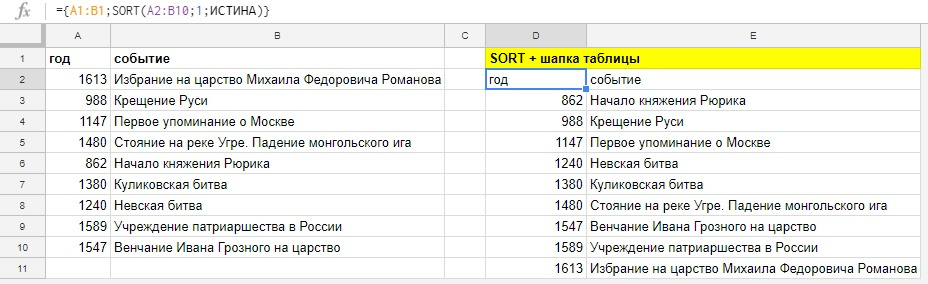
Как в SORT добавить заголовки таблицы?
С помощью фигурных скобок <> создаем массив из двух элементов, шапки таблицы A1:B1 и функции SORT, элементы отделяем друг-от-друга с помощью точки с запятой.
Как объединить несколько диапазонов данных и отсортировать (и не только)?
Давайте рассмотрим, как можно объединять диапазоны для использования в функциях. Это касается не только SORT, этим приемом можно пользоваться в любых функциях, где это возможно, например в ВПР или ПОИСКПОЗ.
Кто читал предыдущий пример уже догадался, что делать: открываем фигурную скобку и собираем массивы для объединения, отделяя их друг-от-друга точкой с запятой и закрываем фигурную скобку.

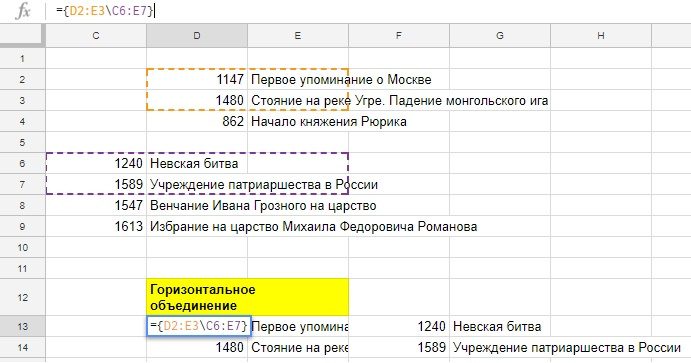
Можно объединить массивы и не использовать их в формуле, а просто вывести на лист, скажем, собрав данные с нескольких листов вашей книги. Для вертикального объединения необходимо соблюсти только одинаковое кол-во столбцов во всех фрагментах (у нас везде по два столбца).

А на скриншоте ниже — пример горизонтального объединения, в нем вместо точки с запятой используется обратный слэш и нужно, чтобы кол-во строк во фрагментах совпадало, иначе вместо объединенного диапазона формула вернет ошибку.
(точка с запятой и обратный слэш — это разделители элементов массива в российских региональных настройках, если у вас не работают примеры, то через файл — настройки таблицы, убедитесь, что у вас стоят именно они)
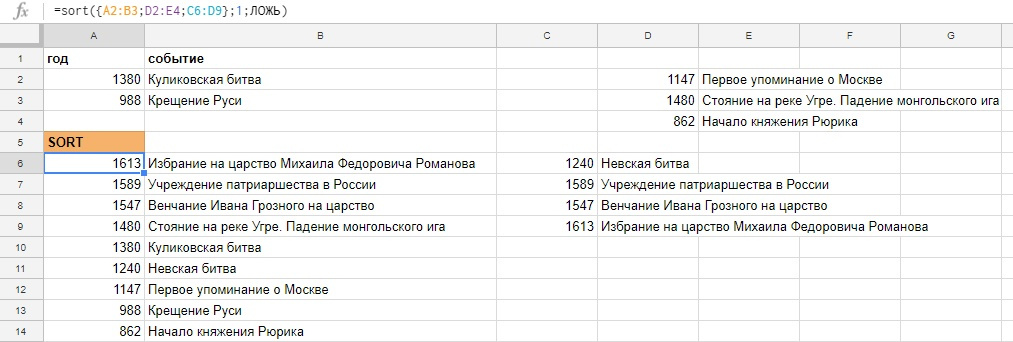
Ну а теперь вернемся к горизонтальному массиву и вставим его в функцию SORT. Будем сортировать данные по первому столбцу, по убыванию.
Объединение можно использовать в любых функциях, главное — соблюдать одинаковое количество столбцов для вертикального или строк для горизонтального объединения.
Все разобранные примеры можно рассмотреть поближе в
Google Документе.
FILTER
С помощью FILTER мы можем отфильтровать данные по одному или нескольким условиям и вывести результат на рабочий лист или использовать результат в другой функции, как диапазон данных.
Одно условие
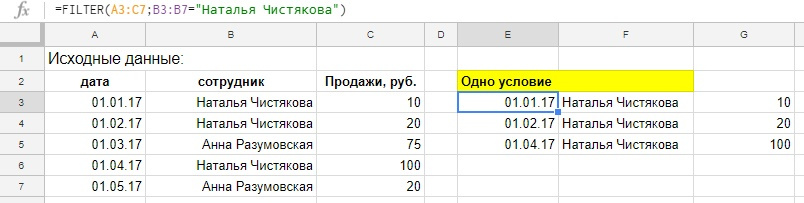
Пример, у нас есть таблица с продажами наших сотрудников, выведем из нее данные по одному работнику.
Введем в ячейку E3 вот такую формулу:
Обратите внимание, синтаксис немного отличается от привычных формул, вроде СУММЕСЛИН, там диапазон условия и само условие отделялось бы при помощи точки с запятой.
Введенная в одну ячейку формула возвращает нам массив из 9-ти ячеек с данными, но после примеров с функцией SORT мы этому уже не удивляемся.
Помимо знака равенства (=) в условиях можно использовать еще >, >=, <> (не равно), , а для чисел или дат можно использовать все эти знаки.
Два условия и работа с датой
Давайте усложним формулу и добавим в нее еще одно условие, по дате продаж, оставим все продажи начиная с 01.02.17
Так будет выглядеть формула, если вводить аргументы условия сразу в нее, обратите внимание на конвертацию текстовой записи даты при помощи ДАТАЗНАЧ:
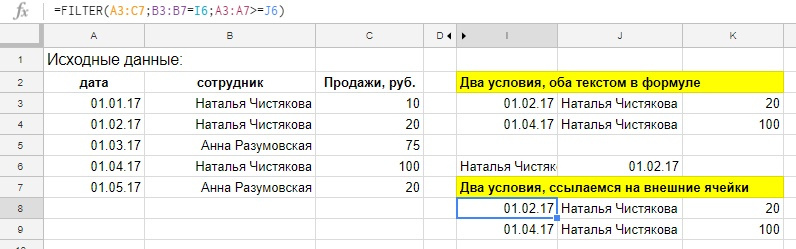
Интерактивный график при помощи FILTER и SPARKLINE
А знаете, как еще можно использовать функцию FILTER? Мы можем не выводить результат функции на рабочий лист, а использовать его как данные для другой функции, например, спарклайна. Спарклайн — это функция, которая строит график в ячейке на основе наших данных, у спарклайна существует много настроек, таких, как вид графика, цвет элементов, но сейчас мы не будем на них останавливаться и воспользуемся функцией без дополнительных настроек. Перейдем к примеру.
Выпадающий список. Наш график будет меняться в зависимости от выбранного сотрудника в выпадающем списке, список делаем так:
- выделяем ячейку Е2;
- меню Данные → Проверка данных;
- правила: Значение из диапазона и в диапазоне выбираем столбец с сотрудниками из исходных данных, не переживайте, что фамилии повторяются, в выпадающем списке останутся лишь уникальные значения;
Нажимаем «Сохранить» и получаем выпадающий список в выбранной ячейке:
Ячейка с выпадающим список станет условием для формулы FILTER, напишем ее.
И вставим эту формулу в функцию SPARKLINE, которая на основе полученных данных будет рисовать в ячейке график.

Так это выглядит в динамике:
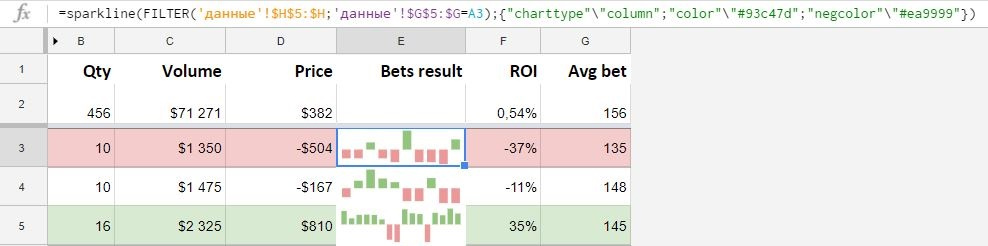
А вот как нарядно может выглядеть SPARKLINE с дополнительным настройками, в реальной работе, диаграмма выводит результаты деятельности за один день, зеленые столбцы — положительные значения, розовые — отрицательные.
IMPORTRANGE
Для переноса данных из одного файла в другой в Google Таблицах используется функция IMPORTRANGE.
В каких случаях она может пригодиться?
- Вам нужны актуальные данные из файла ваших коллег.
- Вы хотите обрабатывать данные из файла, к которому у вас есть доступ «Только для просмотра».
- Вы хотите собрать в одном месте таблицы из нескольких документов, чтобы обрабатывать или просматривать их.
Синтаксис формулы следующий:
spreadsheet_key (ключ) — последовательность символов атрибута «key=» (ключа) в ссылке на таблицу (после «spreadsheets/…/»).
Пример формулы с ключом:
В вашем файле будет отображаться диапазон A1:CM500 с Листа1 из файла, который находится по соответствующей ссылке.

Если в исходном файле может меняться количество столбцов или строк, вводите во втором аргументе функции открытый диапазон (см. также подраздел «Диапазоны вида A2:A»), например:
! Имейте в виду, что если вы загружаете открытый диапазон (например, A1:D), то вы не сможете вставить никакие данные вручную в столбцы A:D в файле, где находится формула IMPORTRANGE (то есть в конечном, куда загружаются данные). Они как бы “зарезервируются” под весь открытый диапазон — ведь его размерность неизвестна заранее.
Ссылку на файл и ссылку на диапазон можно вводить не в формулу, а в ячейки вашего документа и ссылаться на них.
Так, если в ячейку A1 вы введете ссылку на документ (без кавычек), из которого нужно загрузить данные, а в ячейку B1 — ссылку на лист и диапазон (тоже без кавычек), то импортировать данные можно будет с помощью следующей формулы:

Вариант со ссылками на ячейки предпочтительнее в том смысле, что вы всегда можете легко перейти к исходному файлу (щелкнув по ссылке в ячейке) и/или увидеть, какой диапазон и из какой вкладки импортируется.
Импорт форматирования из исходной таблицы
Как мы уже заметили, IMPORTRANGE загружает только данные, но не форматирование исходной таблицы. Как с этим быть? Заранее «подготовить почву», скопировав форматирование из исходного листа. Для этого зайдите на исходный лист и скопируйте его в вашу книгу:

После нажатия кнопки Копировать в… выберите книгу, в которую будете импортировать данные. Обычно нужная таблица есть на вкладке Недавние (если вы действительно недавно работали с ней).
После копирования листа выделите все данные (нажав на левый верхний угол):

И нажмите Delete. Все данные исчезнут, а форматирование останется. Теперь можно ввести функцию IMPORTRANGE и получить полное соответствие исходного листа — как в части данных, так и в части формата:

IMPORTRANGE как аргумент другой функции
IMPORTRANGE может быть аргументом другой функции, если диапазон, который вы импортируете, подходит на эту роль.
Рассмотрим простой пример — среднее значение по продажам из диапазона, находящегося в другом документе.
Это исходный документ. Пусть данные будут добавляться и нам нужно среднее по продажам 2016 (то есть от ячейки D2 и до упора вниз).

Сначала импортируем этот диапазон:

Получаем результат, который будет обновляться при добавлении новых строк в исходном файле в столбце D.
IMAGE: добавляем изображения в ячейки
Функция IMAGE позволяет добавлять в ячейки Google Таблиц изображения.
У функции следующий синтаксис:
URL – единственный обязательный аргумент. Это ссылка на изображение. Ссылку можно указать напрямую в формуле, взяв в кавычки:

Или же поставить ссылку на ячейку, в которой ссылка хранится:

Последний вариант удобнее в большинстве случаев. Так, если у вас есть список книг и ссылки на обложки, достаточно одной формулы, чтобы отобразить их все:

На практике бывает, что ссылки на изображения хранятся на отдельном листе, и вы достаете их с помощью функции ВПР (VLOOKUP) или как-то иначе.

Аргумент mode может принимать четыре значения (если его пропустить, по умолчанию будет первое):
- изображение растягивается до размеров ячейки с сохранением соотношения сторон;
- изображение растягивается без сохранения соотношения сторон, целиком заполняя
- изображение вставляется с оригинальным размером;
- вы указываете размеры изображения в третьем и четвертом аргументам функции [height] и [width]. [height], [width], соответственно, нужны только при значении аргумента mode = 4. Они задаются в пикселях.

Четвертый режим может быть удобен, если вам нужно подбирать точный размер изображения в пикселях, меняя параметры height (высота) и width (ширина). Картинка будет сразу обновляться.
Обратите внимание, что при всех режимах, кроме второго, могут оставаться незаполненные области в ячейке, и их можно залить цветом:

GOOGLETRANSLATE и DETECTLANGUAGE: переводим текст в ячейках
В Google Таблицах есть занятная функция GOOGLETRANSLATE, позволяющая переводить текст прямо в ячейках:

Синтаксис функции следующий:
text – это текст, который нужно переводить. Можно взять текст в кавычки и записать прямо в формулу, но удобнее сослаться на ячейку, в которой текст записан.
[source_language] – язык, с которого мы переводим;
[target_language] – язык, на который мы переводим.
Второй и третий аргументы задаются двухзначным кодом: es, fr, en, ru. Их тоже можно указать в самой функции, но можно брать из ячейки, а язык исходного текста и вовсе можно автоматически определять.

А как быть, если мы хотим переводить на разные языки? И при этом не хотим каждый раз указывать язык исходника вручную?
Тут пригодится функция DETECTLANGUAGE. У нее единственный аргумент – текст, язык которого нужно определить:
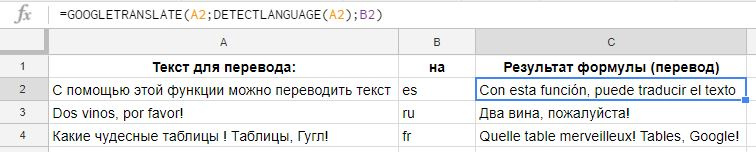
Как и с любой другой функцией, прелесть здесь в автоматизации. Можно быстро поменять текст или язык; быстро перевести одну фразу на 10 языков и так далее. Конечно, мы понимаем, что это текст онлайн-переводчика – качество будет соответствующим.
Евгений Намоконов и Ренат Шагабутдинов, а еще мы ведем канал в телеграмме, где разбираем разные кейсы с Google Таблицами, если вам интересно — заглядывайте в гости, ссылку можно найти в моем профиле.
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
Оглавление:
Если результат формулы занимает больше одной ячейки
Сначала про важную особенность отображения результатов формул в Google Таблицах. Если ваша формула возвращает более одной ячейки, то весь этот массив отобразится сразу и займет столько ячеек и столбцов, сколько для него потребуется (в Excel для этого нужно было бы во все эти ячейки ввести формулу массива). На следующем примере посмотрим, как это работает.
Поможет отсортировать диапазон данных по одному или нескольким столбцам и сразу вывести результат.
=SORT(сортируемые данные; столбец_для_сортировки; по_возрастанию; [столбец_для_сортировки_2, по_возрастанию_2; . ])
Пример на скриншоте ниже, мы ввели формулу только в ячейку D2 и сортируем данные по первому столбцу (вместо ИСТИНА/ЛОЖЬ можно вводить TRUE/FALSE).
(здесь и далее — примеры для российских региональных настроек таблицы, рег. настройки меняются в меню файл → настройки таблицы)
Как в SORT добавить заголовки таблицы?
С помощью фигурных скобок <> создаем массив из двух элементов, шапки таблицы A1:B1 и функции SORT, элементы отделяем друг-от-друга с помощью точки с запятой.
Как объединить несколько диапазонов данных и отсортировать (и не только)?
Давайте рассмотрим, как можно объединять диапазоны для использования в функциях. Это касается не только SORT, этим приемом можно пользоваться в любых функциях, где это возможно, например в ВПР или ПОИСКПОЗ.
Кто читал предыдущий пример уже догадался, что делать: открываем фигурную скобку и собираем массивы для объединения, отделяя их друг-от-друга точкой с запятой и закрываем фигурную скобку.
Можно объединить массивы и не использовать их в формуле, а просто вывести на лист, скажем, собрав данные с нескольких листов вашей книги. Для вертикального объединения необходимо соблюсти только одинаковое кол-во столбцов во всех фрагментах (у нас везде по два столбца).
А на скриншоте ниже — пример горизонтального объединения, в нем вместо точки с запятой используется обратный слэш и нужно, чтобы кол-во строк во фрагментах совпадало, иначе вместо объединенного диапазона формула вернет ошибку.
(точка с запятой и обратный слэш — это разделители элементов массива в российских региональных настройках, если у вас не работают примеры, то через файл — настройки таблицы, убедитесь, что у вас стоят именно они)
Ну а теперь вернемся к горизонтальному массиву и вставим его в функцию SORT. Будем сортировать данные по первому столбцу, по убыванию.
Объединение можно использовать в любых функциях, главное — соблюдать одинаковое количество столбцов для вертикального или строк для горизонтального объединения.
Все разобранные примеры можно рассмотреть поближе в
Google Документе.
FILTER
С помощью FILTER мы можем отфильтровать данные по одному или нескольким условиям и вывести результат на рабочий лист или использовать результат в другой функции, как диапазон данных.
Одно условие
Пример, у нас есть таблица с продажами наших сотрудников, выведем из нее данные по одному работнику.
Введем в ячейку E3 вот такую формулу:
Обратите внимание, синтаксис немного отличается от привычных формул, вроде СУММЕСЛИН, там диапазон условия и само условие отделялось бы при помощи точки с запятой.
Введенная в одну ячейку формула возвращает нам массив из 9-ти ячеек с данными, но после примеров с функцией SORT мы этому уже не удивляемся.
Помимо знака равенства (=) в условиях можно использовать еще >, >=, <> (не равно), , а для чисел или дат можно использовать все эти знаки.
Два условия и работа с датой
Давайте усложним формулу и добавим в нее еще одно условие, по дате продаж, оставим все продажи начиная с 01.02.17
Так будет выглядеть формула, если вводить аргументы условия сразу в нее, обратите внимание на конвертацию текстовой записи даты при помощи ДАТАЗНАЧ:
Интерактивный график при помощи FILTER и SPARKLINE
А знаете, как еще можно использовать функцию FILTER? Мы можем не выводить результат функции на рабочий лист, а использовать его как данные для другой функции, например, спарклайна. Спарклайн — это функция, которая строит график в ячейке на основе наших данных, у спарклайна существует много настроек, таких, как вид графика, цвет элементов, но сейчас мы не будем на них останавливаться и воспользуемся функцией без дополнительных настроек. Перейдем к примеру.
Выпадающий список. Наш график будет меняться в зависимости от выбранного сотрудника в выпадающем списке, список делаем так:
- выделяем ячейку Е2;
- меню Данные → Проверка данных;
- правила: Значение из диапазона и в диапазоне выбираем столбец с сотрудниками из исходных данных, не переживайте, что фамилии повторяются, в выпадающем списке останутся лишь уникальные значения;
Нажимаем «Сохранить» и получаем выпадающий список в выбранной ячейке:
Ячейка с выпадающим список станет условием для формулы FILTER, напишем ее.
И вставим эту формулу в функцию SPARKLINE, которая на основе полученных данных будет рисовать в ячейке график.
Так это выглядит в динамике:
А вот как нарядно может выглядеть SPARKLINE с дополнительным настройками, в реальной работе, диаграмма выводит результаты деятельности за один день, зеленые столбцы — положительные значения, розовые — отрицательные.
IMPORTRANGE
Для переноса данных из одного файла в другой в Google Таблицах используется функция IMPORTRANGE.
В каких случаях она может пригодиться?
- Вам нужны актуальные данные из файла ваших коллег.
- Вы хотите обрабатывать данные из файла, к которому у вас есть доступ «Только для просмотра».
- Вы хотите собрать в одном месте таблицы из нескольких документов, чтобы обрабатывать или просматривать их.
Синтаксис формулы следующий:
spreadsheet_key (ключ) — последовательность символов атрибута «key=» (ключа) в ссылке на таблицу (после «spreadsheets/…/»).
Пример формулы с ключом:
В вашем файле будет отображаться диапазон A1:CM500 с Листа1 из файла, который находится по соответствующей ссылке.
Если в исходном файле может меняться количество столбцов или строк, вводите во втором аргументе функции открытый диапазон (см. также подраздел «Диапазоны вида A2:A»), например:
! Имейте в виду, что если вы загружаете открытый диапазон (например, A1:D), то вы не сможете вставить никакие данные вручную в столбцы A:D в файле, где находится формула IMPORTRANGE (то есть в конечном, куда загружаются данные). Они как бы “зарезервируются” под весь открытый диапазон — ведь его размерность неизвестна заранее.
Ссылку на файл и ссылку на диапазон можно вводить не в формулу, а в ячейки вашего документа и ссылаться на них.
Так, если в ячейку A1 вы введете ссылку на документ (без кавычек), из которого нужно загрузить данные, а в ячейку B1 — ссылку на лист и диапазон (тоже без кавычек), то импортировать данные можно будет с помощью следующей формулы:
Вариант со ссылками на ячейки предпочтительнее в том смысле, что вы всегда можете легко перейти к исходному файлу (щелкнув по ссылке в ячейке) и/или увидеть, какой диапазон и из какой вкладки импортируется.
Импорт форматирования из исходной таблицы
Как мы уже заметили, IMPORTRANGE загружает только данные, но не форматирование исходной таблицы. Как с этим быть? Заранее «подготовить почву», скопировав форматирование из исходного листа. Для этого зайдите на исходный лист и скопируйте его в вашу книгу:
После нажатия кнопки Копировать в… выберите книгу, в которую будете импортировать данные. Обычно нужная таблица есть на вкладке Недавние (если вы действительно недавно работали с ней).
После копирования листа выделите все данные (нажав на левый верхний угол):
И нажмите Delete. Все данные исчезнут, а форматирование останется. Теперь можно ввести функцию IMPORTRANGE и получить полное соответствие исходного листа — как в части данных, так и в части формата:
IMPORTRANGE как аргумент другой функции
IMPORTRANGE может быть аргументом другой функции, если диапазон, который вы импортируете, подходит на эту роль.
Рассмотрим простой пример — среднее значение по продажам из диапазона, находящегося в другом документе.
Это исходный документ. Пусть данные будут добавляться и нам нужно среднее по продажам 2016 (то есть от ячейки D2 и до упора вниз).
Сначала импортируем этот диапазон:
Получаем результат, который будет обновляться при добавлении новых строк в исходном файле в столбце D.
IMAGE: добавляем изображения в ячейки
Функция IMAGE позволяет добавлять в ячейки Google Таблиц изображения.
У функции следующий синтаксис:
URL – единственный обязательный аргумент. Это ссылка на изображение. Ссылку можно указать напрямую в формуле, взяв в кавычки:
Или же поставить ссылку на ячейку, в которой ссылка хранится:
Последний вариант удобнее в большинстве случаев. Так, если у вас есть список книг и ссылки на обложки, достаточно одной формулы, чтобы отобразить их все:
На практике бывает, что ссылки на изображения хранятся на отдельном листе, и вы достаете их с помощью функции ВПР (VLOOKUP) или как-то иначе.
Аргумент mode может принимать четыре значения (если его пропустить, по умолчанию будет первое):
- изображение растягивается до размеров ячейки с сохранением соотношения сторон;
- изображение растягивается без сохранения соотношения сторон, целиком заполняя
- изображение вставляется с оригинальным размером;
- вы указываете размеры изображения в третьем и четвертом аргументам функции [height] и [width]. [height], [width], соответственно, нужны только при значении аргумента mode = 4. Они задаются в пикселях.
Четвертый режим может быть удобен, если вам нужно подбирать точный размер изображения в пикселях, меняя параметры height (высота) и width (ширина). Картинка будет сразу обновляться.
Обратите внимание, что при всех режимах, кроме второго, могут оставаться незаполненные области в ячейке, и их можно залить цветом:
GOOGLETRANSLATE и DETECTLANGUAGE: переводим текст в ячейках
В Google Таблицах есть занятная функция GOOGLETRANSLATE, позволяющая переводить текст прямо в ячейках:
Синтаксис функции следующий:
text – это текст, который нужно переводить. Можно взять текст в кавычки и записать прямо в формулу, но удобнее сослаться на ячейку, в которой текст записан.
[source_language] – язык, с которого мы переводим;
[target_language] – язык, на который мы переводим.
Второй и третий аргументы задаются двухзначным кодом: es, fr, en, ru. Их тоже можно указать в самой функции, но можно брать из ячейки, а язык исходного текста и вовсе можно автоматически определять.
А как быть, если мы хотим переводить на разные языки? И при этом не хотим каждый раз указывать язык исходника вручную?
Тут пригодится функция DETECTLANGUAGE. У нее единственный аргумент – текст, язык которого нужно определить:
Как и с любой другой функцией, прелесть здесь в автоматизации. Можно быстро поменять текст или язык; быстро перевести одну фразу на 10 языков и так далее. Конечно, мы понимаем, что это текст онлайн-переводчика – качество будет соответствующим.
Евгений Намоконов и Ренат Шагабутдинов, а еще мы ведем канал в телеграмме, где разбираем разные кейсы с Google Таблицами, если вам интересно — заглядывайте в гости, ссылку можно найти в моем профиле.
Обычно мы пишем про хостинги, в частности про зарубежный shared хостинг в США. Но чтобы писать, нужно иметь аналитические данные под рукой. Вот как раз тут требуется помощь Google Docs, если файл получится предположительно меньше 400 000 строк.
За несколько месяцев работы с таблицами Google пришлось много раз анализировать посредством формул разного рода данные. Как и ожидалось — то, что можно было решить в MS Excel, можно реализовать и в Google таблицах. Но многочисленные попытки решить проблемы с помощью любимого поисковика приводили только к новым вопросам и почти к нулевым ответам.
Посему, было решено облегчить жизни другим и прославить себя.
Кратко о главном
- буквенно — цифровое (БУКВА = СТОЛБЕЦ; ЦИФРА = СТРОКА) например «А1».
- стилем R1C1, в системе R1C1 и строки и столбцы обозначаются цифрами.

Рисунок 2
Как видно из Рисунка 3, значения ячеек идут относительно той ячейки, в которой будет написана формула со знаком равно. Для сохранения эстетичного вида формул, в них прописаны символы [0], которые можно и не писать: R[0]C[1] = RC[1].

Рисунок 3
Отличие Рисунка 2 от Рисунка 3 в том, что Рисунок 3 — это универсальная формулировка, не привязанная к строкам и столбцам (смотрите на значения строк и столбцов), чего не скажешь о рисунке 2. Но стиль RC в spreadsheet, в основном, используется для написания скриптов javascript.
Типы ссылок (типы адресации)
- Относительные ссылки (пример, A1);
- Абсолютные ссылки (пример, $A$1);
- Смешанные ссылки (пример, $A1 или A$1, они наполовину относительные, наполовину абсолютные).
Относительные ссылки
Относительная ссылка «запоминает», на каком расстоянии (в строках и столбцах) вы щелкнули ОТНОСИТЕЛЬНО положения ячейки, где поставили " https://habrastorage.org/r/w1560/getpro/habr/post_images/419/55a/02d/41955a02d1e46ecf4854c5cd1711bb29.jpg" alt="ok" data-src="https://habrastorage.org/getpro/habr/post_images/419/55a/02d/41955a02d1e46ecf4854c5cd1711bb29.jpg"/>
Рисунок 4
Упростим пример, применив знак $ (Рисунок 5).

Рисунок 5
Но не всегда нужно закреплять все столбцы и строки, иногда используется закрепление только строки или только столбца.(Рисунок 6)
Ошибки формул
Если вы неправильно напишете формулу, об этом вас известит комментарий о синтаксической ошибке в формуле (Рисунок 7).

Рисунок 7
Хотя ошибки могут быть не только синтаксические, но и, например, математические, такие как деление на 0 (Рисунок 7) и другие (Рисунок 7.1, 7.2, 7.3). Для того чтобы увидеть примечание, в котором показана какая ошибка произошла, наведите курсор на красный треугольник в правом верхнем углу ошибки.
Рисунок 7.1
Рисунок 7.2
Рисунок 7.3
Для удобства восприятия таблицы все ячейки с формулами будем окрашивать в фиолетовый цвет.
Для того чтобы увидеть формулы «в живую» необходимо нажать горячую клавишу Ctrl + или выбрать в меню сверху Вид (Просмотр) > Все формулы. (Рисунок 8).

Рисунок 8
О том, как пишутся формулы
В формулировке формул в справочнике и в формулах, которые используются для работы на данный момент, присутствуют отличия. Они заключаются в том, что вместо «запятой», которая использовалась раньше во многих формулах, уже используется «точка с запятой» (изменения произошли более полугода назад).
Для того чтобы посмотреть, на что ссылается формула на данной странице (Рисунок 9), необходимо щелкнуть мышкой в строке формул справа от надписи Fx (Fx находится под основным меню, слева).
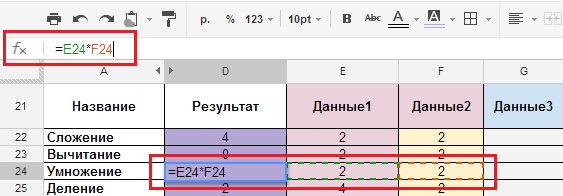
Рисунок 9
ВАЖНО: Для правильного функционирования формул, они должны быть написаны ЛАТИНСКИМИ буквами. Русская (кириллическая) “А” или “С” и латинская “А” или “С” для формулы — это 2 разные буквы.
Формулы
Арифметические формулы.
Расписывать, конечно, вечные операции сложения, вычитания и т.д., никто не будет, но они помогут понять сами азы. На нескольких примерах вы поймете, как они работают в этой среде. В документе, ссылка на который дана в конце статьи, приведены все формулы, мы же просто остановимся на скриншотах.
Сложение, вычитание, умножение, деление.
- Описание: формулы сложения, вычитания, умножения и деления.
- Вид формулы: “Ячейка_1+Ячейка_2”, “Ячейка_1-Ячейка_2”, “Ячейка_1*Ячейка_2”, “Ячейка_1/Ячейка_2”
- Сама формула: =E22+F22, =E23-F23, =E24*F24, =E25/F25.
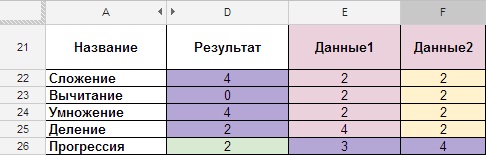
Рисунок 10
Прогрессия.
- Описание: формула для увеличения всех последующих ячеек на единицу (нумерация строк и столбцов).
- Вид формулы: =Предыдущая ячейка + 1.
- Сама формула: =D26+1

Рисунок 11
Округление.
- Описание: формула для округления числа в ячейке.
- Вид формулы: =ROUND(ячейка с числом); счетчик (сколько цифр надо округлить после запятой).
- Сама формула: =ROUND(E28;2).

Рисунок 12
Округление “ROUND” происходит по математическим законам, если после запятой стоит цифра 5 или больше, то целая часть увеличивается на единицу, если 4 и меньше, то остается неизменной, также округление можно сделать с помощью меню ФОРМАТ — > Числа -> «1000,12» 2 десятичных знака (Рисунок 13). Если же вам необходимо большее количество знаков, то нужно нажать ФОРМАТ — > Числа -> Персонализированные десятичные -> И указать количество знаков.
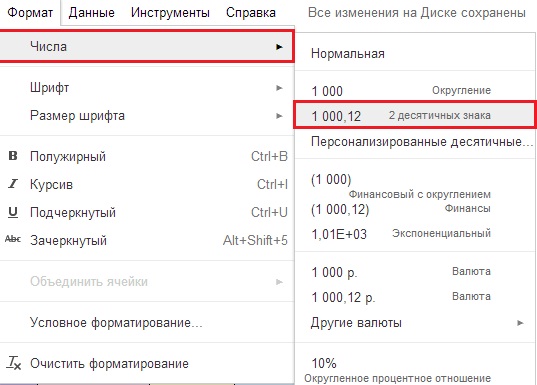
Рисунок 13
Сумма, если ячейки идут не последовательно.
- Описание: суммирование чисел, которые находятся в разных ячейках.
- Вид формулы: =SUM(число_1; число_2;… число_30).
- Сама формула: "=SUM(E30;H30)" пишем через ";" если разные ячейки.
- Описание: суммирование чисел, которые идут друг за другом (последовательно).
- Вид формулы: =SUM(число_1: число_N).
- Сама формула: =SUM (E31:H31)" пишем через ":" если это непрерывный диапазон.
- Имеем начальные данные в диапазоне ячеек E31:H31, а результат в ячейке D31 (Рисунок15).
Среднее арифметическое.
- Описание: суммируется диапазон чисел и делится на количество ячеек в диапазоне.
- Вид формулы: =AVERAGE (ячейка с числом либо число_1; ячейка с числом либо число_2;… ячейка с числом либо число_30).
- Сама формула: =AVERAGE(E32:H32)

Рисунок 16
Конечно, есть и другие, но мы идем дальше.
Текстовые формулы.
Из великого количества текстовых формул, с помощью которых можно сделать все, что угодно с текстом, самая востребованная, на мой взгляд — это формула для «склеивания» текстовых значений. Существует несколько вариантов ее исполнения:
Склеивание текстовых значений (формулой).
- Описание: «склеивание» текстовых значений (вариант А).
- Вид формулы: =CONCATENATE(ячейка с числом/текстом либо текст_1; ячейка с числом/текстом либо текст_2; …, ячейка с числом/текстом либо текст_30).
- Сама формула: =CONCATENATE(E36;F36;G36;H36).

Рисунок 17
Склеивание числовых значений.
- Описание: “склеивание” текстовых значений руками, без использования специальных функций (вариант B — ручное написание формулы, сложность формулы любая.).
- Вид формулы: =ячейка с числом/текстом 1&" "&ячейка с числом/текстом 2&" "&ячейка с числом/текстом 3&" "& ячейка с числом/текстом 4 (" " — пробел, знак & означает склеивание, все текстовые значения пишутся в кавычках “”).
- Сама формула: =E37&" "&F37&" "&G37&" "&H37.

Рисунок 18
Склеивание числовых и текстовых значений.
- Описание:«склеивание» текстовых значений руками, без использования специальных функций (вариант С — смешанный тип, сложность формулы любая).
- Вид формулы: = «текст_1 » &ячейка_1&«текст_2»&ячейка_2&«текст_3»&ячейка_3
- Важно: весь текст, который будет написан в “” будет неизменным для формулы.
- Сама формула: =«Еще 1 » &E38&" использования "&F38&" как НАМ "&G38.
Рисунок 19
ЛОГИЧЕСКИЕ И ПРОЧИЕ
Перенос данных из любых листов одного и того же файла.
- Описание: перенос данных из любых листов одного и того же файла (для Excel можно как переносить из листа одной книги в другой лист той же книги, так и из листа одной книги в лист другой книги).
- Вид формулы: = «Название_Листа»! ячейка_1
- Сама формула:=Data!A15 (Data — лист, А15 — ячейка на том листе).
Рисунок 20
Рисунок 20.1
Массив формул.
Большинство программ для работы с таблицами содержат два типа формул массива: «для нескольких ячеек» и «для одной ячейки».
Таблицы Google разделяют эти типы на две функции: CONTINUE (ПРОДОЛЖИТЬ) и ARRAYFORMULA.
Формулы массива для нескольких ячеек позволяют формуле возвращать несколько значений. Вы можете использовать их, даже не зная этого, просто вводя формулу, возвращающую несколько значений.
Формулы массива «в одной ячейке» позволяют записывать формулы с помощью ввода массива, а не выходных данных. При заключении формулы в состав функции =ARRAYFORMULA можно передать массивы или диапазоны функциям и операторам, которые, как правило, используют только аргументы, не принадлежащие массивам. Данные функции и операторы будут применяться по одному для каждой записи в массиве, и возвращать новый массив со всеми выходными данными.
Если вы хотите изучить вопрос более детально, вам следует посетить support.google.
Говоря простыми словами, для работы с формулами, которые возвращают массивы данных, во избежание синтаксических ошибок, необходимо заключать их в массив формул.
Суммирование ячеек с условием ЕСЛИ.
- Описание: суммирование ячеек с условием ЕСЛИ (формула SUMIF).
- Вид формулы: = SUMIF(‘Лист’! диапазон; критерии; ‘Лист’! суммарный_диапазон)
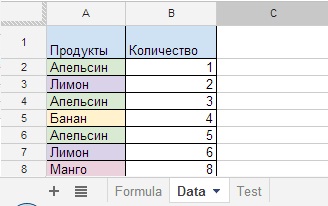
Рисунок 21
Имеем начальные данные в листе Data (Рисунок 21), а результат на листе Formula в столбце D (Рисунок 22). В столбцах E, F, G показаны аргументы, применяемые в формуле, а в столбце H общий вид формулы, которая находится в столбце D и высчитывает результат.

Рисунок 22
Пример выше показывает общий вид работы формулы “Сумма Если” с одним условием, но чаще всего используется “Сумма ЕСЛИ” (с множеством условий).
Суммирование ячеек ЕСЛИ, множество условий.
- Описание: сумма ЕСЛИ (с множеством условий).
- Вид формулы: = SUMIF(‘Data’! диапазон_1&‘Data’! диапазон_2; критерии_1&критерий_2; ‘Data’! суммарный_диапазон).
- Сама формула:=(ARRAYFORMULA(SUMIF((Data!E:E&Data!F:F);(B53&C53);Data!G:G)))
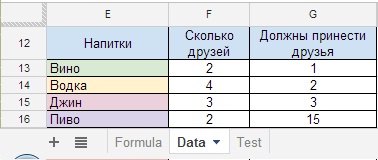
Рисунок 23
Допустим, что на листе Formula, в ячейке В53 (критерий_1 = Пиво) должно быть название напитка, а ячейка С53 (критерий_2 = 2), это количество друзей, которые принесут Пиво. В итоге в ячейке D53 окажется результат, что нам нужно докупить 15 бутылок пива. (Рисунок 23.1) то есть, формула определит сумму по двум критериям — пиво и количество друзей.

Рисунок 23.1
Если таких позиций будет больше, строки 16 и 21(Рисунок 24), то количество пузырей в колонке G суммируется (Рисунок 24.1).
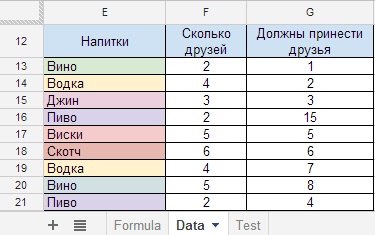
Рисунок 24
Итого:

Рисунок 24.1
Теперь приведем более интересный пример:
Ха… вечеринка продолжается, и вы вспоминаете, что нужен торт, но непростой, а супер – мега торт, с разными специями, которые, как назло, еще и зашифрованы под цифровые обозначения. Задача состоит в том, чтобы купить специи в нужном количестве пакетиков каждой из специи. Нужное количество повар зашифровал в таблицу (Рисунок. 25.1), столбцы A и B (в соседних столбцах делаем наши вычисления).
Каждая специя имеет свой порядковый номер: 1,2,3,4. (Рисунок 25).
- Описание: подсчет количества одинаковых цифр в больших массивах при дополнительных условиях.
- Вид формулы: СЧИТАТЬ ЕСЛИ(‘Formula’! диапазон_A55: А61+’Formula’! диапазон_B55:B61; УсловиеА”Специи”+УсловиеБ”число от 1 до 4”; Лист”Formula’! диапазон_B55:B61)/УсловиеБ ”число от 1 до 4”)
- Сама формула: =((ARRAYFORMULA(SUMIF('Formula'!$A$55:$A$61&'Formula'!$B$55:$B$61; $F$55&$E59;'Formula'!$B$55:$B$61)))/$E59)
- Описание: вычисление процента специй.
- Вид формулы: Количество*100%/Общее_количество
- Сама формула: =F58*$G$56/F$56
Подсчет значений в объединенных ячеек.
- Описание: формула для подсчета значений, в которых присутствует символ @.
- Вид формулы: СЧИТАТЬ ЕСЛИ(В столбце F листа “Formula” есть текст с содержимым @).
- Сама формула: =COUNTIF('Formula'!F65:F68; "*@*").
Подсчитывает количество чисел в списке аргументов.
- Описание: подсчет количества ячеек, содержащих цифры без текстовых переменных.
- Вид формулы: COUNT(значение_1; значение_2; … значение_30)
- Сама формула: =COUNT(E45;F45;G45;H45)

Рисунок 27.
Ячейки, содержащие текст и цифры также не считаются.

Рисунок 27.1.
Подсчет количества ячеек содержащих цифры с текстовыми переменными.
- Описание: подсчет количества ячеек, содержащих цифры с текстовыми переменными.
- Вид формулы: COUNTA(значение_1; значение_2; … значение_30)
- Сама формула: =COUNTA(E46:H46)

Рисунок 28.
Также, формула считает ячейки, содержащие только знаки препинания, табуляции, но не считает пустые ячейки.

Рисунок 28.1
Подстановка значений при условиях.
- Описание: подстановка значений при условиях.
- Вид формулы: "=IF(AND((Условие1);(Условие2)); Результат равен 0, если условие 1 и 2 выполняется; если не выполняется, то результат равен 1)"
- Сама формула: "=IF(AND((F73=5);(H73=5));0;1)"
- Вид формулы:"=COUNTA(Диапазон_А)-COUNTIF(Диапазон_А; «автоответ»)-COUNTIF(Диапазон_А; "-")-COUNTIF(Диапазон_А; «занято»)"
- Сама формула: =COUNTA($E74:$H75)-COUNTIF($E74:$H75; «автоответ»)-COUNTIF($E74:$H75; "-")-COUNTIF($E74:$H75; «занято»)

Рисунок 30
Вот мы и подошли к концу нашего маленького ликбеза по формулам в Google SpreadSheet и у меня большие надежды, что я пролил свет на некоторые аспекты аналитической работы с формулами.
Формулы, честно говоря, были в прямом смысле выстраданы. Каждая из них создавалась в течение долгого времени. Надеюсь, вам понравилась моя статья и примеры, приведенные в ней.
И в завершение, в качестве подарка. И да простят меня разработчики!
Формула «УБИЙЦА ДОКУМЕНТА».
Если Вам необходимо скрыть документ от чужих глаз навсегда, то эта формула для Вас.
Сама формула:"=(ARRAYFORMULA(SUMIF($A:$A&$C:$C;$H:$H&F$2; $C:$C)))". $H:$H регулирует распространение формулы. После того как фомлулу запустите (Рисунок 31), ниже в ячейках она начнет размножать следующую функцию CONTINUE(ячейка; строка; столбец).
Google Таблицы (Google Spreadsheets) — табличный, а не текстовый редактор, тем не менее там часто приходится иметь дело именно с текстом. Рассказываем о соответствующих функциях.
ДЛСТР (LEN)
ДЛСТР (LEN) — функция для вычисления длины строки. Пригодится, если работаете в Google Sheets с контент-планами, текстами объявлений, метатегами — сразу можно проверить, соответствует текст нужным критериям или нет.
Синтаксис простой, аргумент один — текстовая строка (можно указать прямо в формуле или взять из ячейки). Например, =ДЛСТР("Блог CyberMarketing про интернет-маркетинг") вернет значение 42. Учитываются все символы, включая пробелы и переводы строки.
Если нужно проверить тайтлы страниц, а сами они пока неизвестны, можно вложить в LEN функцию IMPORTXML: =ДЛСТР(IMPORTXML(B2;"//title")) В данном случае результатом станет длина метатега TITLE, полученного для URL, который лежит в ячейке B2.

Так работает IMPORTXML, вложенный в LEN
СТРОЧН (LOWER), ПРОПИСН (UPPER)
СТРОЧН (LOWER) приводит все символы к нижнему регистру, а ПРОПИСН (UPPER) — наоборот, к верхнему. Обе текстовые функции принимают один аргумент — строку в кавычках или ячейку с текстом. Получается, конструкция =ПРОПИСН(СТРОЧН("CYBERMARKETING")) выведет ту же самую строку — "CYBERMARKETING".
Но на практике часто можно обойтись без этих функций. Для поиска без учета регистра есть ПОИСК (SEARCH) — о ней чуть позже. А, например, у QUERY, которую мы разбирали в предыдущей статье, есть свои встроенные функции — upper() и lower() — для приведения строк к единому регистру.
СЦЕПИТЬ (CONCATENATE), JOIN, TEXTJOIN
Все три функции объединяют несколько строк в одну. Работают похожим способом, но есть некоторые отличия.
CONCATENATE (СЦЕПИТЬ) дословно сцепляют несколько строк между собой по очереди. Синтаксис: =СЦЕПИТЬ("Hello";", ";"World";"!")

Простой пример использования CONCATENATE. Но такой способ, подойдет, пожалуй, только для немецкого языка.
Чтобы они не слипались между собой, придется каждый раз добавлять между ними пробел (или другой символ). Например: =СЦЕПИТЬ(A15;" ";B15;" ";C15;" ";D15) Или создавать таблицу, где в одном столбце — нужные слова, в другом — соединители. (Если в параметре указан диапазон — минимум по 2 ячейки в высоту и ширину — функция будет объединять значения по строкам.)

В таком случае только надо оставить последнюю ячейку пустой — иначе в конце созданной строки будет лишний пробел
Как вы понимаете, СЦЕПИТЬ далеко не самая удобная функция. JOIN же позволяет сразу задать единый разделитель для всех строк в массиве/диапазоне: =JOIN(" ";A16:A19) даст такой же результат, как на предыдущем скриншоте — при этом не надо беспокоиться за возможный лишний символ в конце строки.
В JOIN можно спокойно объединять сразу несколько массивов данных, например: =JOIN("&";;) А если не указать разделитель, то все будет работать так же, как и у CONCATENATE.
Следующая функция подойдет лучше, если в массиве/диапазоне встречаются пустые строки — ведь в JOIN они создают лишние пробелы. А TEXTJOIN делает все то же самое, только есть дополнительный аргумент, который указывает: включать пустые строки или нет. Синтаксис: =TEXTJOIN(" ";ИСТИНА;A16:B20), где первый параметр передает пробел в качестве разделителя, второй говорит, что нужно игнорировать пустые строки, а третий — дает диапазон значений для соединения.

Здесь все правильно соединяется — ничего лишнего
Кстати, помимо функций, можно использовать такой оператор как ‘&’. К примеру, ="Cyber"&"Marketing" спокойно сработает и выдаст "CyberMarketing". Очень удобная фишка при создании всяких динамических таблиц (дашбордов/конструкторов), где нужно кастомизировать запрос для QUERY.
А подробнее о том, что делать с ключевыми словами, вы сможете узнать с помощью статей, вебинаров, курсов по SEO от CyberMarketing.
СЖПРОБЕЛЫ (TRIM)
Если проблема с пробелами все же есть, ее поможет решить специальная функция — СЖПРОБЕЛЫ (TRIM). Она чистит их в начале и конце текста, а также убирает повторяющиеся символы, например, двойные пробелы.
Синтаксис простой и понятный, аргумент один — строка целиком или ссылка на ячейку: =СЖПРОБЕЛЫ(" Hello, World! ")

Так работает СЖПРОБЕЛЫ
Незаменимая штука при работе с большими таблицами, где сотни ключевых фраз, метатегов или других необработанных данных, собранных из разных источников.
ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID)
Все три функции извлекают из строки один или несколько символов: первая берет их слева, вторая — справа, третья — прямо из середины. Примеры:
- =ЛЕВСИМВ("Привет, мир!";6) — тут получится просто "Привет".
- =ПРАВСИМВ("Привет, мир!"; 4) — здесь от строки останется только "мир!".
- =ПСТР("Привет, мир!"; 4; 3) — выведет лишь "вет".
С ЛЕВСИМВ и ПРАВСИМВ все должно быть и так понятно (кстати, последним параметром может быть ноль, тогда функция просто вернет пустую строку). А вот ПСТР работает так: вторым аргументом принимает номер символа, с которого нужно начать извлечение подстроки, а третьим — длину извлекаемой подстроки. (Важно: отсчет начинается с 1, а не с нуля.)
Конечно, в работе редко бывает заранее известно, где в какой строке и на сколько символов надо отступить. Как правило, такие функции используют в сочетании с другими, например, ДЛСТР и ПОИСК/НАЙТИ.
SPLIT
SPLIT разделяет текст — по одному или нескольким символам-разделителям — и выводит полученные фрагменты в разные ячейки. Сами символы при этом не возвращает. Простой пример: =SPLIT(A10;"/")
1. Текст, который нужно разделить на части. Строкой или ссылкой на ячейку.
2. Символ(-ы) для разделения — тоже строкой, в кавычках.
3. Тип разделителя (необязательно). По умолчанию ИСТИНА — функция разделяет текст по каждому символу, который указан во втором параметре. Если поставить ЛОЖЬ, то разделение будет происходить только по всей последовательности символов.

4. Тоже необязательный параметр, который определяет, нужно ли удалять пустые ячейки после разделения. По умолчанию ИСТИНА — два последовательных разделителя будут считаться одним. Если ЛОЖЬ, то между этими разделителями будет создана пустая ячейка.

Пожалуй, это не пригодится, SPLIT и так занимает слишком много ячеек
Главный недостаток — множество лишних «технических» ячеек, которые могут мешать, может понадобиться их скрывать. Извлекать отдельные фрагменты текста можно и другими способами.
REGEXMATCH, REGEXEXTRACT, REGEXREPLACE
Все эти три функции работают с регулярными выражениями — специальным языком для гибких манипуляций с текстами. REGEXMATCH ищет совпадения, REGEXEXTRACT извлекает по шаблону нужный фрагмент, а REGEXREPLACE заменяет одну часть текста на другую. Синтаксис похожий: первый аргумент — текст, а второй — само регулярное выражение; в REGEXREPLACE есть еще третий — текст, который нужно вставить.
- =REGEXEXTRACT("https://www.cybermarketing.ru/video-courses/promo/poiskovoe-prodvizhenie.html";"[^/]+$") — результатом будет "poiskovoe-prodvizhenie.html".
- =REGEXMATCH("mail_mail.123@gmail.com";"^([a-z0-9_-]+\.)*[a-z0-9_-]+@[a-z0-9_-]+(\.[a-z0-9_-]+)*\.[a-z]$") — ИСТИНА, так как в строке корректный адрес электронной почты.
- =REGEXREPLACE("Google — это один из самых посещаемых сайтов в мире, второй по популярности поисковик Рунета и лидер мобильного трафика. Поэтому нет никаких сомнений, что контекстная реклама Google Adwords — эффективный канал для продвижения бизнеса. Google Адвордс позволит охватить большую аудиторию поиска Google и пользователей мобильных устройств на базе Android.";"(Adwords)|(Адвордс)|(Эдвордс)";"Ads") — здесь в тексте будет везде правильно написано название сервиса.
UNIQUE, COUNTUNIQUE
Функция UNIQUE берет только те строки, которые ни разу не повторяются, то есть позволяет почистить набор данных от дубликатов. Весьма полезная штука в SEO, PPC, веб-аналитике. Уникальные строки возвращаются в том же порядке, в котором располагаются в диапазоне/массиве.
Синтаксис: =UNIQUE(A2:A100) или =UNIQUE() — тут в столбец выйдут по порядку 5 элементов этого массива, а не 6, потому что два из них неуникальные.
Если нужно не выводить, а только подсчитать количество уников, есть функция COUNTUNIQUE. В нее можно передавать набор из произвольного числа аргументов: значений и диапазонов. Синтаксис: =COUNTUNIQUE(1; 1; 2; 3; 5; 8; 13; A2; B6:B9)
ПОИСК (SEARCH), НАЙТИ (FIND)
Обе функции делают одно и то же: возвращают порядковый номер символа, на котором запрос впервые встречается в тексте. Первым аргументом передаем, что искать, вторым — где искать, третьим — с какого символа искать (поиск идет с начала, учитываются все символы, в том числе пробелы). (В отличие от ЛЕВСИМВ и ПРАВСИМВ, нельзя передать ноль в качестве последнего аргумента.)
Разница лишь в том, что НАЙТИ (FIND) учитывает регистр, а ПОИСК (SEARCH) — нет. Примеры:
Результаты выполнения функции — позиции символов/подстрок — пригодятся, например, для дальнейшей работы с ЛЕВСИМВ, ПРАВСИМВ или ПСТР. Но сами по себе они не понадобятся, если нужно просто проверить: есть в тексте нужное слово или нет. TRUE или FALSE вместо бесполезных цифр поможет получить ЕОШИБКА (ISERROR) (или похожая функция ЕСЛИОШИБКА) в сочетании с функциями IF или IFS (иногда еще нужен NOT). К примеру:
- =IF(ISERROR(SEARCH("paid";"https://www.cybermarketing.ru/video-courses/paid/prodvinutyj-kurs-seo.html";1));"Курс бесплатный";"Курс платный") — здесь функция вернет именно "Курс платный".
- =IFS(НЕ(ЕОШИБКА(НАЙТИ("paid";"https://www.cybermarketing.ru/video-courses/promo/kontekstnaya-reklama.html")));"Курс платный";НЕ(ЕОШИБКА(НАЙТИ("promo";"https://www.cybermarketing.ru/video-courses/promo/kontekstnaya-reklama.html")));"Курс бесплатный") — а здесь получится "Курс бесплатный" (для двух вариантов, конечно, слишком сложно, но для большого количества развилок — вполне).
ПОДСТАВИТЬ (SUBSTITUTE)
- Текст, для которого нужны поиск и замена.
- Строка, которую нужно найти и удалить.
- Строка, которую нужно подставить вместо.
- Порядковый номер вхождения строки, которую нужно заменить (необязательно). (По умолчанию все совпадения будут заменяться.)
На злобу дня: =ПОДСТАВИТЬ("Привет, мир!";"мир";"карантин") — "Привет, карантин!". Еще пример: =ПОДСТАВИТЬ("Привет, мир!";"р";"г";2) —"Привет, миг!" (‘р’ встречается раньше, но специально указано, что брать следует второй символ по счету).
Важно: функция SUBSTITUTE не различает, является строка отдельным словом или частью другого. Замена будет производиться в любом случае. В более сложных кейсах лучше использовать функции REGEX — для работы с языком регулярных выражений.
DETECTLANGUAGE и GOOGLETRANSLATE
DETECTLANGUAGE умеет определять язык текста, а GOOGLETRANSLATE — переводить текст с одного языка на другой.
DETECTLANGUAGE принимает один аргумент — текст или диапазон. (Работает только с одномерным столбцом, при передаче диапазона вида A2:B8 выдаст ошибку — обойти можно только через массив.) Если в диапазоне будут тексты на нескольких языках, функция определит язык лишь первого попавшегося фрагмента.
GOOGLETRANSLATE работает с тремя параметрами (два последних необязательные):
- Текст, который нужно перевести.
- Язык оригинала в таком же формате, каким оперирует DETECTLANGUAGE. (Кстати, можно указать "auto" и он будет определен автоматически — то есть вкладывать одну функцию в другую для этих целей не нужно.)
- Язык перевода — аналогично — двумя буквами. (По умолчанию функция берет язык операционной системы, но это не всегда работает, поэтому лучше указывать отдельно.)
С диапазонами не получится, только с отдельными ячейками/строками.
ТЕКСТ (TEXT) И ЗНАЧЕН (VALUE)
Функция ТЕКСТ (TEXT) преобразует числовой формат в текстовый — это может понадобится, например, для динамических таблиц с использованием QUERY, красивого представления данных в отчетах. Первый аргумент — число, дата и/или время, второй — шаблон для форматирования. (‘?’, ‘*’, а также дробные форматы не поддерживаются.) Примеры:
(Все варианты можно посмотреть в справке, а также в разделе «Формат» → «Числа» → «Другие форматы».)
ЗНАЧЕН (VALUE) делает совершенно противоположное — преобразует текст или дату в число. На вход принимает единственный аргумент — строку. Изменение формата может понадобиться, например, когда мы извлекаем данные из текста с помощью REGEXEXTRACT, а потом их нужно использовать для функций суммирования, подсчета среднего арифметического и т. п.
ЕТЕКСТ (ISTEXT)
ЕТЕКСТ (ISTEXT) проверяет, есть в ячейке текст или нет. Если там текстовое значение, возвращает ИСТИНА, если найдет число или пустую ячейку — ЛОЖЬ. Так:
- =ЕТЕКСТ("123") — TRUE, так как данные, заключенные в кавычки, передаются как строка.
- =ЕТЕКСТ(123) — FALSE, потому что числа передаются без кавычек.
- =ЕТЕКСТ("") — тоже TRUE, строка пустая, но все же это строка.
Эта функция чаще используется в условных конструкциях (IF, IFS).
СОВПАД (EXACT)
СОВПАД (EXACT) — специальная функция Таблиц для сравнения двух строк: если они полностью совпадают, вернется TRUE, если нет — FALSE. Важны и пробелы, и регистры. К примеру, =СОВПАД("Cybermarketing";"CyberMarketing") выдаст ЛОЖЬ, так как по одному символу они отличаются.
Если регистр не важен, гораздо проще использовать обычные операторы, например: =ЕСЛИ("CyberMarketing"="Cybermarketing";"Совпадают";"Не совпадают") — здесь будет "Совпадают".
ГИПЕРССЫЛКА (HYPERLINK)
ГИПЕРССЫЛКА (HYPERLINK) создает в ячейку гиперссылку. Первый аргумент — полный URL, второй (необязательный) — текст ссылки.
Если протокол не указан, по умолчанию используется "http://". Если текстом ссылки указана пустая строка "", ячейка отображается пустой, но ссылка все равно будет работать.
На практике эта функция нужна редко, только если важно скрыть целый URL за анкором. В остальных случаях Google Таблицы автоматически делают адреса страниц/сайтов кликабельными.
А о том, как правильно работать со ссылками на сайте, вы сможете узнать с помощью статей, вебинаров, курсов по SEO от CyberMarketing.
Читайте также: