
Как включить многопоточность в 1с
Наверное, каждый из нас сталкивался с ситуацией, когда нужно выполнить большой объем вычислений или передать/получить большой объем информации за ограниченный промежуток времени. А сколько из нас остановилось на последовательном алгоритме и закрыли глаза на продолжительность выполнения? Ну и что, что 20 часов ведется расчет/отправка/получение (подчеркнуть нужное) каких-то данных? Ну, я «выжал» из системы все, что можно, быстрее не получится… При этом серверное железо загружено на минимум.
На самом деле, почти всегда доступна альтернатива в виде распараллеливания выполняемой задачи. Конечно, параллельные алгоритмы несколько сложнее — балансировка нагрузки, синхронизации между потоками, а так же, в случае разделяемых ресурсов, борьба с ожиданием на блокировках и избегание deadlock’ов. Но, как правило, оно того стоит.
Об этом мы сегодня и поговорим… в контексте 1С Предприятия.
Практически во всех современных языках есть необходимый инструментарий для реализации параллелизма. Но не везде этот инструментарий удобен для использования. Кто-то скажет: «Ну и что тут сложного и не удобного? Платформенный механизм фоновых заданий в руки и вперед!». На практике оказалось не так все просто. А что если задача бизнес-критичная? Тогда нужно обеспечить, во-первых, гарантированное выполнение заданий и, во-вторых, мониторинг работы подсистемы выполнения заданий.
- администратор для проведения регламентных работ завершил все сессии;
- внешний ресурс, требуемый на момент выполнения задания, был недоступен в течении какого-то времени;
- у части заданий после очередного обновления могут появится ошибки в коде, фоновое будет остановлено по эксепшену и, кроме записи в журнал регистрации, никому ничего не сообщит.
Хочется иметь возможность гибкого управления запускаемыми заданиями с обратной связью, с учетом ошибок, с гарантированным запуском, и все это примерно с той же легкостью, какая существует в других языках и фреймворках для параллельных заданий.
Для облегчения собственной жизни была разработана универсальная библиотека, позволяющая легко создавать параллельные алгоритмы с гарантированным выполнением в среде 1С Предприятия на базе фоновых заданий.
Область применения
- Использование параллельных вычислений в автоматизации бизнес процессов;
- Параллельное выполнение запросов в долгих отчетах/обработках;
- Процессы загрузки/выгрузки данных;
- Организация нагрузочного тестирования.
Основной принцип работы
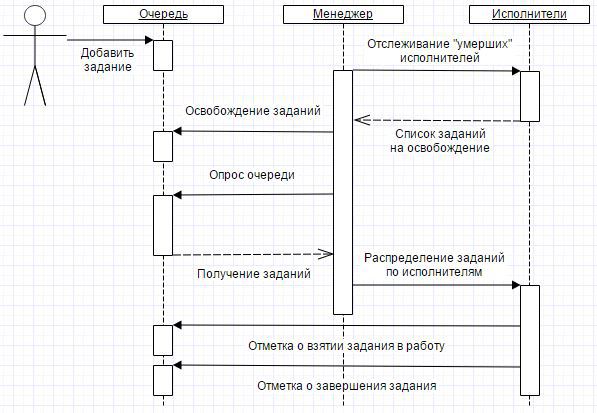
Добавляется задание очень просто — нужно указать точку входа (путь к экспортному методу с серверным контекстом в общем модуле или модуле менеджера) и кортеж с параметрами в виде структуры:
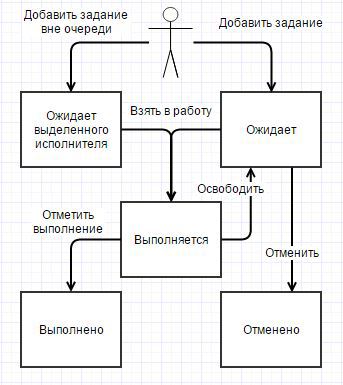
При этом происходит запись в регистр сведений мзЗадания. Первоначально задание имеет состояние Ожидает. Метод возвращает КлючЗадания для возможного отслеживания прогресса в основном клиентском потоке. Кортеж с параметрами так же расширяется свойством КлючЗадания, чтобы при выполнении задания был контекст, он иногда может быть полезен.
Далее, раз в минуту просыпается Менеджер, который первым делом проверяет исполнителей и освобождает задания, исполнители которых «умерли». Проверка заключается в следующем. Если задание в состоянии Выполняется и прописанное в качестве исполнителя фоновое не активно (удалено администратором, возникла исключительная ситуация в коде и т.д.), то задание возвращается в очередь. Для этого у задания выставляется состояние Ожидает.
Следующим шагом запрашиваются из очереди задания в соответствии с настройками балансировки нагрузки (сейчас это только ограничение на количество одновременно работающих исполнителей).
После этого Менеджер под каждое задание запускает Исполнителя. В качестве исполнителей выступают те самые фоновые задания платформы 1С.
При запуске Исполнитель делает отметку, что взял задание в работу — прописывает свой уникальный идентификатор у задания в свойстве КлючИсполнителя и выставляет состояние задания в Выполняется.
Когда задание выполнено, Исполнитель так же делает соответствующую отметку в задании — состояние Выполнено.
Для использования подсистемы в оперативном режиме есть метод ДобавитьЗаданиеВнеОчереди. При этом сразу запускается Исполнитель, минуя Менеджера, и забирает новое задание. Сигнатура такая же, как у основного метода ДобавитьЗадание. На такие задания ограничение на количество исполнителей НЕ распространяется, НО квота используется.
- У фоновых заданий вроде как есть метод отмены, но он работает для меня не прозрачно. Очень часто наблюдал картину, когда длительное фоновое задание дорабатывало до конца несмотря на отправленную команду отмены;
- Не хочется оставлять систему в неконсистентном состоянии. Кто знает, как именно написан код задания и что он делает в базе данных?
- ДождатьсяВыполнения(КлючиЗаданий, Таймаут = 5) — усыпляет текущий поток до выполнения указанного списка заданий, либо до истечения указанного времени;
- ОжидатьСостояниеЗадания(КлючЗадания, ОжидаемоеСостояние, Таймаут = 5) — усыпляет текущий поток до установления указанного состояния у задания, либо до истечения указанного времени;
- ОжидатьИзмененияСостояния(КлючЗадания, ТекущееСостояние, Таймаут = 5) — усыпляет текущий поток до изменения состояния у задания с указанного на любое другое, либо до истечения указанного времени.
Настройка
Для настройки есть специальная обработка «Управление менеджером заданий»:

- Ограничение на количество исполнителей — для балансировки нагрузки на сервере 1С. Принимает значение от 0 до 9999. При значении 0 задания в работу браться не будут.
- Глубина хранения истории (дни) — если указано значение отличное от 0, тогда подсистема сама будет чистить информацию по старым выполненным заданиям оставляя последние N дней указанных в настройке.
- Количество активных исполнителей;
- Количество заданий в очереди (в состоянии Ожидает);
- Всего активных заданий (п.1 + п.2).
Расширенный мониторинг сильно зависит от области применения и оставлен на откуп потребителям подсистемы.
Примеры использования
Использование параллельных вычислений в автоматизации бизнес процессов
Например, расчет заработной платы можно распараллелить по сотрудникам, потому что расчет зарплаты одного сотрудника, как правило, не зависит от расчета зарплаты другого сотрудника. (Приведенный код всего лишь иллюстрирует возможности подсистемы, и никак не связан с типовыми конфигурациями 1С.)
Параллельное выполнение запросов в долгих отчетах/обработках
Процессы загрузки/выгрузки данных
Организация нагрузочного тестирования
Исходники и прочее
Подсистема доступна на github/TaskManagerFor1C. CF файл открыт, так что можно ознакомиться с исходными кодами.
Подсистема разрабатывалась через тестирование (TDD), тесты доступны во внешней обработке /Тесты/Тесты_МенеджерЗаданий.epf. Для запуска тестов нужен инструментарий xUnitFor1C.
Обратная связь приветствуется. С удовольствием отвечу на все возникшие по инструменту вопросы.
Многопоточность - это свойство системы выполнять одновременно более одной операции (в пределе - более одной программы), позволяя в ряде случаев добиться существенного роста производительности программного продукта.
Пролог.
Предположим, что коней у нас много и заполнение без многопоточности займет много времени.
Опишем для начала рабочую процедуру:
Данная процедура должна располагаться в общем модуле и быть экспортной, т.к. именно ее будет вызывать управляющая процедура, формируя фоновые задания.
Теперь опишем управляющую процедуру:
В принципе, управляющая процедура может и не быть процедурой - она может продолжить код получения данных
Собственно, что мы сделали? Создали массив заданий и определили параметры обработки (количество потоков, количество данных в потоке). Далее заполнили массив данными, проверили, есть ли свободное место в массиве, если нет - дождались, и передали в фоновое задание для обработки. После чего поместили ГУИД ФЗ в массив.
Заключение.
Многопоточные вычисления все больше будут использоваться в дальнейшем, т.к. процессорная архитектура достигла пределов роста вверх по частоте - теперь она растет вширь по количеству ядер, объему памяти, емкости накопителей. Все это должно привести к прогрессу в области параллельных вычислений.
Специальные предложения









(3) insurgut, в действительности фоновое задание запускается отлельным потоком на сервере 1с. Дальше потоком рулит ОС, выделяя ему память и ядро. Если процессорных ядер больше одного - происходит реальное распараллеливание, но даже на одном ядре код нескольких потоков может выполняться быстрее, т.к. waitы и sleepы - задержки - позволяют другим потокам в это время чтото делать.
В реальной жизни существует масса задач, скорость выполнения которых обратно пропорциональна количеству процессов (если их не больше количества ядер). Операции ввода-вывод, кстати, используют задержки, которые могут утилизироваться многопоточностью.
(7) если не ошибаюсь (что не исключено ;)), один процесс RPHOST выполняется на 1 ядре. И получается все зависит от того, какой RPHOST (если их несколько) будет выполнять тот или иной поток. Ситуация, что все они будут выполнятся на одном и том же рпхосте не исключена. И беда в том, что повлиять на это возможности уже нет (конечно и тут я могу ошибаться, поправьте если что). Но в любом случае, как вы сами и указали, все многопоточность сведется к одной последовательной операции чтения с диска. Но тут на помощь нам идет сам SQL, который возможно заранее все уже выгрузил в память.
P.S. Очень интересно было бы увидеть данные по приросту скорости выполнения при использовании приведенного метода многопоточности на реальной базе :)
(8) rphost выполняется не на одном ядре, он как раз может утилизировать все ядра. То, что это так можно убедиться запустив сервер 1с с одним процессом и увидев, что нагрузка попадает на все ядра. Из-за убеждения, что один процесс использует только одно ядро многие рекомендуют запускать рабочих процессов по числу ядер. На курсе 1с:Эксперт про это как раз рассказывают.
(8) insurgut, Вам, конечно, уже ответили, но я могу несколько дополнить. В случае вычисления в фоновом задании выражения на встроенном языке без обращения к ресурсам сервера SQL вы ограничены ресурсами сервера 1С, но если у происходит обращение к серверу СУБД - картина меняется. Т.к. АДО-механизм использует задержки при обращении к серверу, ожидая ответ, то второй поток даже на одном ядре может инициировать в это время еще одно соединение с сервером СУБД, утилизируя его вычислительные ресурсы. Отсюда мораль: если бОльшую часть работы мы перенесем на сервер СУБД, то можно запустить больше потоков на сервере 1С.
P.S. Очень интересно было бы увидеть данные по приросту скорости выполнения при использовании приведенного метода многопоточности на реальной базе :)
Посмотрел код, получается, если массив заданий заполнен -ищем первое отработавшее задание и удаляем его из списка. Если же таких отработанных заданий в массиве будет несколько, то на мой взгляд будет оптимальнее их сразу все удалить, тогда для следующей порции данных уже не надо будет пробегать по массиву и искать неактивное задание (т. е предлагаю убрать оператор "Прервать")
(4) fancy, это же пример. а по факту потом можно оптимизировать и оптимизировать. Автору спасибо за статью!
Предложенная идея была озвучена в курсе по Оптимизации Бурмистрова Александра сколько - то там месяцев назад. Ничего нового, чего-то там записать в независимый РС несколькими ФЗ. При имеющейся архитектуре 1С да и перечню решаемых задач (ну рассчитайте себестоимость в несколько потоков!) многопоточность пока неактуальна!
(6) DoctorRoza, не актуальна пока вы не группа компаний по 20 - 50 пользователей в каждой. В противном случае появляются задачи для которых есть возможность и необходимость распараллеливания вычислений.
Многопоточность можно применять по-разному, кто мешает к примеру запустить несколько потоков с разными функциями, которые к примеру получают разные данные из базы. На выходе, получим почти одновременно выполненные запросы и таблицы с ответами.
Пришлось как-то изучить Java. Только самые азы. Так вот там все построено на многопоточности.
(6 Более того, я например сейчас работаю со специализированной конфой, написанной где-то в 2011 - 2012 году, где эта технология применяется в полный рост.
А если взять в расчет файловую базу, то там как многопоточность организовывать? Через обработчик ожидания? Серверными все, конечно, понятно, а вот как обстоит дело с файловыми? Кто-нибудь пробовал?
(13) amon_ra, вряд ли при чтении из файловой базы удастся добиться ускорения при многопоточности, т.к. все упрется в клиентскую машину (ОС, диски, ядра, . ). Если ядер много, то что-то вычислить на встроенном языке без обращения к БД будет быстрее, но для этого уже механизм фоновых заданий вряд ли подойдет.
Кстати, ФЗ может иногда отваливаться - вместе с убиваемым менеджером кластера rphost'ом. У нас так печать работает в 5 потоков на Linux-сервера печати на базе CUPS. Т.к. они постоянно вылетали, и до включения полнейшего лога сервака мы не понимали, почему. В итоге сделали регистр, куда клались данные, отсортированные по потокам, и каждые 10 минут запускали задание, которое проверяло, есть ли фоновые задания с определенным именем. Если нет, и в регистре не пусто - запускало по новой и отправляло письмо админам. В итоге нашли проблему - одновременное подключение внешней компоненты печати ШК. Обернули в "мутекс" - все стало стабильно. Как-то отключили "допечатывание" - 2 недели проработало без этого - даже не заметили. Ни одно задание не отвалилось, ни один rphost не умер.
многопоточность в 1С это и есть сферический конь в вакууме. в отдельной взятой высосанной из пальца задаче вы его сможете применить, но не более того.
(19) spezc, обоснуйте свою позицию. У нас в организации многопоточность применяется от пакетного формирования печатных форм механизма автоматической печати и до обмена данными. Везде это приводит к весьма существенному улучшению производительности. Например, формирование печатных форм вместо трех часов занимает 50 минут (при пяти потоках).
Это мой пример контроля помеченных на удаление с получением результата. Этот пример отработает не быстрее штатного т.к. функция "НайтиПоСсылкам()" и так многопоточная. Остальную часть этой обработки я так и не доделал. Ожидал, что прироста на поиске я не получу, а вот на удалении большого количества должен.
(25) для тех, кто все же не понял, как мы выходим из цикла, на всякий случай внес комментарии в код. Г-н rtnm, будучи хорошим специалистом, совершенно верно подметил, что цикл так просто не кончается. Но, слава Богу, есть программисты и получше. В данном конкретном случае цикл завершается оператором "прервать" после удаления первого отработавшего задания из массива фоновых заданий. После этого количество заданий будет больше, чем количество элементов массива, что приведет к выходу и из второго цикла.
Есть другой путь - процедура ОжиданиеЗавершения(массивФЗ). Но тогда мы теряем асинхронность. Мы запустили 10 заданий, они могут выполняться разное время, но ожидая завершения всех заданий мы теряем в производительности. надеюсь, теперь всем все понятно.
(27) вообще, речь о том, что код управляющей процедуры зря тратит процессорное время, гоняя свой цикл без устали.
Если управляющая функция находится на клиенте, то стоит присмотреться к ПодключитьОбработчикОжидания, а если на сервере (это ваш случай), то к ФоновыеЗадания.ОжидатьЗавершения с выставленным таймаутом
Вот такие "добрые дяди" с ожиданием завершения и удивляются, почему это эффективность маловата. Стоит также иметь ввиду, что получение фонового задания ждет ответа от сервера - в это время никаких инструкций не выполняется.
(29) минус вам за ваш слог в комментариях. Если бы вы в статье написали, что ФоновыеЗадания.ОжидатьЗавершения (с указанным таймаутом) работает как-то не очень, то моих комментариев вы бы и не увидели. По существу, вы проверяли что ФоновыеЗадания.ОжидатьЗавершения (с указанным таймаутом) сейчас работает как-то не очень?
Любая программа может быть написана при помощи:
бесконечных циклов;
команд выхода из цикла;
операторов ветвления (if-then);
последовательностью команд, исполняемых одна после другой;
Примечание: обратите внимание, что универсальный оператор GOTO (безусловный переход) не нужен, а достаточно специального оператора выхода из цикла, при этом, в случае n вложенных циклов потребуется n специальных операторов выхода из цикла (кроме небольшого количества языков с расширенным синтаксисом операторов выхода) или один оператор GOTO и одна метка.
/////////////////////////////
rtnm. учите мат.часть - это очень полезно. И запомните, если Вас всегда хвалят и всегда с Вами согласны - вы не развиваетесь. Я объективную развернутую критику крайне приветствую, но Ваше "Управляющая функция жестко зациклена - не стоит демонстрировать такой код." просто показывает, что в программировании, увы, Вы ничего не смыслите. Уж извините, но как есть.
На скорость работы 1С влияют разные факторы: от «кривых» запросов до оборудования. Это означает, что оптимизацию лучше проводить комплексно. А еще – чтобы разобраться с нуля во всех возможных причинах замедления, потребуется некоторое время.
Но есть несколько способов, которые заставят 1С работать быстрее минимальными усилиями: нужно просто поменять некоторые настройки, отключить кое-какие процессы… : )
В этой статье разберем 7 таких приемов. Минут 15 на чтение – и можно смело идти применять их на практике!
Даже если Вы пока не замечаете проблем с 1С, прочитайте статью. Убедитесь, что в настройках Вашей системы нет ошибок и все возможности платформы используются по максимуму – чтобы и в будущем проблем с производительностью не было : )
1. Настроить параллелизм в MS SQL Server
Если запрос читает большой объем данных, чаще всего это говорит о том, что он не очень оптимальный.
По правилам следовало бы такой запрос найти и оптимизировать, чтобы все жили долго и счастливо. К сожалению, наш мир не идеален, и далеко не всегда есть возможность переписать медленный запрос. Иногда с ним приходится мириться.
Для «тяжелых» запросов в MS SQL предусмотрен механизм распараллеливания. Он автоматически делит запрос, который читает большой объем данных, на несколько потоков и выполняет их параллельно.
Проблемы из-за распараллеливания
По идее распараллеливание должно ускорять выполнение запроса. Так и есть. Однако оно повышает нагрузку на процессор, поэтому, если использовать механизм необдуманно, это может приводить к негативным последствиям.
Например, бывает, что «тяжелый» запрос, разделившись на потоки, начинает загружать несколько ядер процессора, что сказывается на общей производительности системы.
Распараллеливание может стать причиной ожиданий на СУБД с типом CXPACKET: при параллельном выполнении запроса одни потоки будут ждать исполнения других, что также снизит скорость работы.
К тому же иногда из-за ошибки распараллеливания по вине СУБД происходит дедлок. Дедлок подразумевает, что разные потоки одного запроса блокируют друг друга.
Что предлагают в документации
В официальной документации говорится о том, что лучше вообще отключить механизм распараллеливания, установив для базы данных настройку Max degree of parallelism = 1. В этом случае один запрос будет выполняться в один поток, что позволит избежать проблем, описанных выше.

Рисунок 1. Настройка параллелизма в MS SQL Server для выполнения запроса на одном ядре (в один поток)
Ситуации, при которых не стоит отключать распараллеливание
Официальная рекомендация действительно справедлива, но лишь отчасти. Ее можно применить, если, например, постоянная нагрузка на процессор выше 30%. В этом случае включение параллелизма может еще больше нагрузить процессор и совсем «положить» его.
Но такие ситуации — редкость. Зачастую на современных серверах СУБД процессоры не загружены более чем на 20–30%. У них остается еще достаточный запас по мощности, поэтому внезапная нагрузка на сервер из-за «тяжелого» запроса несильно повлияет на остальных пользователей.
Приведем несколько ситуаций, при которых не стоит отключать распараллеливание:
- Описанный в документации случай, когда один запрос при распараллеливании замедляет всех — не самый распространенный паттерн. Чаще неоптимальный запрос выполняется медленно в один поток, хотя мог бы выполняться гораздо быстрее в несколько потоков, при этом несильно загружая процессор.
- Если отключить распараллеливание на уровне сервера, тогда и регламентные операции по умолчанию тоже будут выполняться в один поток. Чтобы этого избежать, нужно указывать настройку распараллеливания (MAXDOP = 0) для регламентного задания дефрагментации/реиндексации, чего многие, к сожалению, не делают.
- Новый механизм реструктуризации работает гораздо быстрее, если включено распараллеливание. Об этом сказано и в документации. Там же предлагается каждый раз перед реструктуризацией включать параллельность, а после обновления — отключать. Но все мы люди, и часто разработчики просто забывают установить параметр в нужное значение. В итоге реструктуризация больших таблиц даже с новым механизмом идет медленно.
- Ожидания CXPACKET зачастую интерпретируются неправильно. Их наличие далеко не всегда говорит о проблемах с распараллеливанием. Если хочется больше узнать об этом, подробности Вы найдете в статье Troubleshooting the CXPACKET wait type in SQL Server.
Так что же делать?
Мы разобрались, почему просто отключить механизм распараллеливания и забыть о нем — не лучшая идея. Что же тогда делать?
В качестве решения можно рассмотреть следующий подход: оставить настройку Max degree of parallelism = 0, но установить настройку Cost threshold for parallelism = 30.

Рисунок 2. Настройка параллелизма в MS SQL Server для выполнения запроса на нескольких ядрах (в несколько потоков)
Такая настройка означает, что MS SQL будет самостоятельно решать, сколько потоков использовать для выполнения одного запроса, но распараллеливание будет включаться, только если стоимость плана запроса будет выше 30.
Стоимость плана измеряется в неких условных единицах и отражает, насколько «тяжелым» является запрос для исполнения. Чем выше стоимость, тем сильнее запрос нагружает систему. При настройках по умолчанию параллельность включается, если стоимость плана выше 5. Значение 30 — не какая-то сакральная величина: просто, с точки зрения автора, оно подходит для большинства систем.
Благодаря такой настройке параллельность будет использоваться только для действительно сложных запросов. Запросы полегче продолжат выполняться в один поток — им распараллеливание все равно не дает заметного ускорения.
Следует отметить, что это решение не освобождает от необходимости оптимизировать «тяжелые» запросы, но оно хотя бы не мешает другим операциям выполняться быстро.
2. Проверить, сколько ядер используют MS SQL Server и 1С
Если у Вас мощный сервер — это еще не значит, что Вы используете его на полную мощность.
Причины у этого могут быть разные. Например, такое происходит, если при настройке окружения не учли ограничения MS SQL или приобрели не ту версию 1С.
Давайте разберем подробнее оба случая.
Проверить, сколько ядер используют MS SQL Server
Разные версии MS SQL имеют разные ограничения. Их важно учитывать при настройке окружения. Например, версия MS SQL Standard 2016 может использовать либо 4 сокета, либо 24 ядра, исходя из того, чего меньше (данные из таблицы на сайте Microsoft Ignite).

Рисунок 3. Ограничения разных версий MS SQL Server
Допустим, у Вас есть многопроцессорный сервер, т. е. сервер с несколькими сокетами. На нем размещена виртуальная машина, на которую установлен сервер MS SQL. При этом в виртуальной машине настроено 12 процессоров по 2 ядра. Сколько ядер будет использовать MS SQL?
MS SQL будет использовать 4 процессора, следовательно, всего 8 ядер из 24. Остальные ядра будут не загружены. Правильным решением будет настроить на виртуальной машине 4 процессора по 6 ядер на каждом, либо 2 по 12 ядер. В этом случае MS SQL сможет использовать все 24 ядра.

Рисунок 4. Неправильная и правильная настройки процессоров. В схеме № 1 MS SQL использует только 4 процессора из 12, а в схеме № 2 — все 12
Вот пример неверной настройки, когда вместо 12 ядер в виртуальной машине было настроено 12 сокетов — по одному ядру на каждый сокет. Видно, что загружены только 4 ядра из 12.

Рисунок 5. Неравномерная загрузка ядер при неправильной настройке виртуальной машины
Чтобы узнать, сколько логических процессоров (ядра, в том числе и гиперпоточные) задействует Ваш экземпляр MS SQL, следует выполнить следующий запрос

Рисунок 6. Отображение реального количества логических процессоров, используемых MS SQL Server
SQL Server detected 1 sockets with 4 cores per socket and 8 logical processors per socket, 8 total logical processors; using 8 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
Из этого текста следует, что все хорошо — число найденных ядер равно числу используемых.
SQL Server detected 4 sockets with 12 cores per socket and 12 logical processors per socket, 48 total logical processors; using 24 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
В этом случае половина процессорных мощностей простаивает.
Проверить, сколько ядер используют 1С
Важно помнить, что у 1С тоже есть ограничения по количеству используемых ядер. Например, версия ПРОФ может использовать только 12 ядер и, если поставить ее на 24-ядерный сервер, то половина процессорных мощностей будет простаивать.
Если на сервере больше 12 ядер и Вы хотите, чтобы 1С использовала их все, необходимо приобрести версию КОРП.
3. Проверить настройку Turbo Boost
Для сервера 1С критически важна частота процессора — чем она выше, тем лучше.
В большинстве процессоров есть возможность динамически менять частоту в зависимости от нагрузки — это позволяет процессору работать на частоте выше номинальной. У Intel такая технология называется Turbo Boost, у AMD — Turbo Core.

Рисунок 7. Схема работы технологии Turbo Boost
Turbo Boost включается в BIOS, но чтобы он полноценно работал, необходимо в настройках электропитания операционной системы установить режим электропитания Высокая производительность. Если этого не сделать, ОС будет занижать частоту процессора для экономии электричества.

Рисунок 8. Установка режима электропитания
4. Включить механизм версионирования в MS SQL для 8.2
Все еще много конфигураций работает в режиме совместимости с 8.2 или на самой платформе 8.2.
В управляемом режиме блокировок в 8.2 читающие запросы в транзакции устанавливают блокировки. Из-за этого при параллельной работе нескольких пользователей пишущие транзакции блокируют читающие, что приводит к излишним ожиданиям на блокировках.
Если у Вас такая конфигурация и в ней используется режим управляемых блокировок, необходимо обязательно в MS SQL включить режим версионирования READ_COMMITTED_SNAPSHOT.
Это можно сделать с помощью следующей команды:
При этом в базе не должно быть пользователей, иначе команда не будет выполнена.
После выполнения команды поведение системы будет аналогично 8.3: читающие запросы в транзакции не будут блокировать данные, следовательно, количество ожиданий на блокировках сократится.
Проблема в том, что периодически, например при обновлении, платформа будет возвращать прежний режим. Необходимо постоянно следить за тем, чтобы данный режим был включен. Например, можно сделать регламентное задание на MS SQL, которое будет регулярно выполнять вышеприведенных запрос.
5. Проверить выполнение регламентных операций СУБД и 1С
Как на СУБД, так и на 1С обязательно должны выполняться регламентные операции. Настройки регламентных операций — тема обширная и выходит за рамки этой статьи. Просто важно помнить, что без регламентных операций производительность системы будет падать.
Зачастую о регламентах забывают при апгрейде сервера, обновлениях, смене СУБД или смене паролей для запуска служб MS SQL, поэтому даже если все было настроено, лучше проверить еще раз, что регламентные операции по-прежнему выполняются.
Регламентные операции для СУБД
Для СУБД обязательными являются обновление статистики и дефрагментация/реиндексация индексов.
Обновление статистики — важнейшая регламентная операция. Если статистика не актуальна, то запросы на больших таблицах будут выполняться медленно.
Фрагментация индексов негативно влияет на скорость работы дисковой подсистемы и на объем оперативной памяти. Чем выше фрагментация на диске, тем больший объем оперативной памяти будут занимать данные.
Регламентные операции для 1С
В 1С в первую очередь имеются в виду сдвиг границы и пересчет итогов.
В идеале граница рассчитанных итогов должна быть на конец предыдущего месяца — тогда остатки за предыдущие периоды будут получаться быстро.

Рисунок 9. Установка периода рассчитанных итогов
Не стоит устанавливать период рассчитанных итогов далеко в будущем, иначе любая запись в регистр будет вызывать обновление итогов за все будущие месяцы. Это не только замедлит работу пользователя, но и увеличит время блокировки данных, что может привести к ожиданиям на блокировках.
Пересчет итогов также является важной регламентной операцией. При ее выполнении из таблицы удаляются нулевые итоги, которые могут занимать значительный объем. Также пересчет сворачивает строки, возникающие при работе механизма разделения итогов, что тоже уменьшает размер таблицы.
Полный пересчет итогов на больших базах занимает много времени, поэтому часто его предпочитают вообще не делать. Однако эту операцию необходимо проводить регулярно, чтобы не накапливать большое количество строк с нулевыми итогами. В качестве альтернативы можно выполнять пересчет только текущих итогов — эта операция выполняется гораздо быстрее.
6. Использовать таблицы итогов регистров сведений
Можно относительно легко ускорить запросы к срезам регистра сведений, если эти срезы выполняются без указания даты.
Ускорение достигается за счет механизма итогов для среза первых и последних. Если включить эту возможность, будут созданы отдельные таблицы, где хранятся только первые или только последние значения ресурсов по комбинации измерений.

Рисунок 10. Разрешение таблицы итогов регистра сведений
Включение этих флагов потребует времени для реструктуризации, особенно если таблица регистра сведений большая. Иногда это может занять очень много времени, поэтому лучше проводить такое обновление ночью или в выходные — так оно не помешает работе пользователей.
После обновления появятся отдельные таблицы срезов, обращение к которым будет идти, если в запросе не указана дата получения среза. Это сильно ускоряет чтение, особенно когда в регистре десятки миллионов строк и более.
У этого средства есть незначительный минус. На запись в регистр будет уходить чуть больше времени, т. к. помимо основной таблицы нужно будет обновлять и таблицы итогов.
7. Убрать лишнее
Этот способ ускорения системы заключается в том, чтобы отключить все, что не используется, но забирает ресурсы. Особенно это касается типовых конфигураций.
Кому-то покажется, что это совет от капитана Очевидность. Но стоит отбросить сарказм — есть множество баз, в которых работают все стандартные регламентные задания и оставлены настройки по умолчанию.
Проведите ревизию включенных регламентных заданий. Действительно ли все эти задания нужны? Может, часть относится к механизмам, которые Вы не используете?
Ситуация усугубляется, когда на сервере расположено большое количество баз: часть из них для разработки, часть — для тестов, еще часть кто-то когда-то зачем-то создал. В каждой из них выполняются задания, обновление полнотекстового поиска и т. д.
Все это никак не помогает производительности Вашей системы, поэтому стоит отключить все лишнее.
Первое, на что нужно обратить внимание при ревизии — это полнотекстовый поиск. Если он не используется, тогда лучше его отключить, чтобы он зря не «съедал» ресурсы системы.

(нажмите, чтобы увеличить картинку)
Рисунок 11. Отключение полнотекстового поиска 1С
Если же полнотекстовый поиск используется, тогда стоит оставить свойство «Полнотекстовый поиск» в значении Использовать только для тех реквизитов, где он действительно необходим. У остальных объектов следует его отключить.
Чек-лист быстрого ускорения системы
Итак, быстрые способы ускорить систему минимальными усилиями:
- Настроить параллелизм в MS SQL Server.
- Проверить, сколько ядер используют MS SQL Server и 1С.
- Проверить настройку Turbo Boost.
- Включить механизм версионирования в MS SQL для 8.2.
- Проверить выполнение регламентных операций СУБД и 1С.
- Использовать таблицы итогов регистров сведений.
- Убрать лишнее.
К любым рекомендациям следует относиться с осторожностью, в том числе и к тем, что представлены в этой статье. При изменении параметров обязательно наблюдайте за поведением системы, отмечайте произошедшие перемены, делай выводы и, исходя из них, решайте, что делать дальше.
Если 1С тормозит …
Но если Вы хотите подойти к вопросу оптимизации комплексно, рекомендуем наш курс «Ускорение и Оптимизация 1С. Базовый курс 2022».
В процессе автоматизации деятельности предприятия при помощи 1С: Предприятие часто
возникают задачи интеграции и обмена с оборудованием и другими сторонними информационными
системами, например, банками, веб-сайтами, информационными системами партнеров.
Традиционно 1С: Предприятие выступает в качестве потребителя услуг, и реже – в качестве
поставщика. До этого момента у разработчиков популярными технологиями при получении
информации от 1C были COM и веб-сервисы, которые появились только в версии 8.1.
Внешняя обработка позволяет задать порт, по которому будет осуществляться прослушивание
и число создаваемых потоков для обработки одновременных запросов. По умолчанию установлен
порт 8082 и 50 потоков.
После нажатия на кнопку Старт сервер переходит в рабочее состояние и осуществляет
обработку запросов на заданный порт. Например, теперь можно обратиться из вашего
браузера по адресу localhost:8082 и открыть
страницу, которую вернет сервер. В запросе же можно передавать параметры, например,
так: localhost:8082/test?x=1
За что ответственен каждый участок кода, можно понять из комментариев, приведенных
внутри исходного кода.

Свойство Request позволяет получить параметры и содержимое, переданные клиентом
при запросе. Информация о запросе, помещенная в свойство Request содержит такие
основные свойства как:
Через свойство Response осуществляется возврат контента клиенту, передача информации
об ошибке или перенаправление. Сопровождаться все может выставлением необходимых
заголовков. Многие свойства ответа (Response) схожи со свойствами запроса. Значимые
среди них следующие:

Следующий код метода ОбработатьЗапрос преобразует сформированную строку РезультатHTML
с HTML-кодом в набор байт и записывает этот набор байт в выходной поток, который
будет возвращен клиенту. Ссылка на выходной поток получена через параметр метода.
Начало получения запросов происходит в методе HandleRequests до тех пор, пока обработка
не прекратится пользователем. При поступлении запроса, запрос передается в метод
ContextReady и работа процесса прослушивания продолжается.
Многопоточный сервер, описанный в статье, по простоте настройки и функциональности
превосходит традиционные методы доступа извне к информационным базам 1С: Предприятие
8.х. Это простой по запуску метод, позволяющий одновременно обрабатывать несколько
запросов. При этом приложение 1С не блокируется, и пользователь может продолжать
работу после запуска сервера.
Основное преимущество предложенного подхода – полная подконтрольность программисту
процесса от получения запроса до формирования ответа. Например, на этапе получения
запроса может быть выполнен парсинг URL, получена информация о том, как себя идентифицировал
пользователь, а также полная информация о клиенте (поддерживаемые языки, записанные
куки, заголовки, метод доступа). Ответ же можно вернуть практически любой, начиная
от ошибки 404 Not found, заканчивая разными графическими форматами, форматами Word,
Excel и популярными форматами на основе XML (JSON, HTML, RSS).
Конкретно для предложенного подхода на данный момент не выявлено явных недостатков.
Есть вероятность того, что 1С: Предприятие в силу своих ограничений не сможет обеспечить
на своей стороне должного распараллеливания и значительного увеличения производительности.
Тем не менее опыты проведенные ранее для 1С: Предприятие 8.2 показали, что в схожем
применении 1С достигается увеличение производительности, и 1С работает при этом
стабильно.
Второй момент заключается в том, что известные методы, в том числе и этот, предоставления
услуг со стороны 1С не предназначены для массовых обращений и будут всегда уступать
с этой точки зрения профессиональным серверам, например, IIS.
При размещении 1С в облачной инфраструктуре и среде виртуализации наиболее важными и непростыми задачами являются повышение скорости работы платформы «1С» и настройка СУБД. Для достижения максимальной производительности инфраструктуры 1С рекомендуется правильно выбирать архитектуру инфраструктуры, режимы работы, проверить и выполнить ряд важных настроек.
В зависимости от количества пользователей, размера баз данных и ограничений бюджета (с учетом стоимости дополнительных лицензий на сервер «1С:Предприятие 8» и лицензий на СУБД) платформа «1С» может работать в файловом и клиент-серверном вариантах (на основе трехуровневой архитектуры «клиент-сервер» (рис. 1): клиентское приложение, кластер серверов «1С:Предприятия 8», СУБД).

Рис. 1
Как правильно выбрать вариант/режим работы 1С: файловый или SQL?
Обычно для 1-10 пользователей выбирается файловый режим
От 10 и более пользователей выбирается режим работы с использованием SQL
В файловом варианте все пользователи могут работать на одной виртуальной машине в облаке, например на терминальном сервере.
Для клиент-серверного варианта лучше выбрать не менее двух виртуальных машин:
Сервер с клиентским приложением, например терминальный сервер с клиентской частью «1С» (толстый клиент)
Сервер «1С» и СУБД (MS SQL или PostgreSQL)
Как рассчитать мощности сервера для 1С в файловом режиме работы?
В обоих вариантах: файловом и SQL, для работы с пользовательским приложением 1С в классическом режиме, например, «удаленного рабочего стола» (так называемый «толстый клиент»), необходимы следующие минимальные ресурсы виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + 0,25 * количество пользователей
Объем памяти RAM = 1 или 2 ГБ для ОС + 0,5 ГБ * количество пользователей
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (0,1-10) ГБ * количество пользователей. Для ОС и 1С рекомендуется использовать самые быстрые диски
Как рассчитать мощности сервера для 1С в варианте работы с SQL?
В клиент-серверном варианте работы 1С, в котором используется СУБД SQL, рекомендуется разместить 1С Сервер и сервер SQL на отдельном виртуальном сервере в общей с клиентским сервером локальной подсети. Необходимы следующие минимальные мощности для этого виртуального сервера:
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (10-1000) ГБ в зависимости от объема и количества баз данных. Для ОС и СУБД рекомендуется использовать самые быстрые диски
------------
ОС - операционная система, например, Windows Server
Здесь Сервер 1С - ПО "сервер "1С:Предприятия 8"
Наиболее важными и непростыми задачами являются повышение продуктивности использования платформы «1С» в облаке и настройка СУБД. Типичные проблемы при развертывании и эксплуатации облачной инфраструктуры для «1С» следующие:
Неправильный выбор мощностей
Неквалифицированная настройка сервисов виртуальной инфраструктуры
Недостаточное внимание к тестированию производительности платформы «1С»
Для достижения максимальной производительности рекомендуется проверить и выполнить ряд настроек. Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
На SQL-сервере необходимо выключить все ненужные службы, например FullText Search и Integration Services, установить максимально возможный объем оперативной памяти, максимальное количество потоков (Maximum Worker Threads) и повышенный приоритет сервера (Boost Priority), задать ежедневную дефрагментацию индексов и обновление статистики, настроить автоматическое увеличение файла базы данных (не менее 200 Мбайт) и файла лога (не менее 50 Мбайт), а также полную реиндексацию не реже одного раза в неделю. При размещении серверов SQL и «1С:Предприятие» на одной ВМ следует включить протокол Shared Memory.
Следуя перечисленным выше рекомендациям, можно добиться увеличения быстродействия платформы «1С» в облаке в 1,5–2 раза.
Квалифицированное размещение ИТ-сервисов, в том числе «1С», на облачной платформе позволяет:
Существенно сократить расходы
Повысить уровни безопасности (доступ к данным, резервное копирование, антивирусная защита и др.) и технического обслуживания
Обеспечить централизованное администрирование и мониторинг
Организовать эффективную и безопасную удаленную работу
Воспользоваться гибкими возможностями масштабирования, лицензирования и оперативного перехода на необходимые версии конфигураций «1С»
ЧЕК-ЛИСТ ПО ОПТИМИЗАЦИИ ИНФРАСТРУКТУРЫ 1С С MS SQL
1. Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
Создание базы данных
Добавление файлов, журналов или данных в существующую базу данных
Увеличение размера существующего файла (включая операции автоувеличения)
Восстановление базы данных или файловой группы
Для включения настройки:
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc)
Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
На правой панели дважды кликните Выполнение задач по обслуживанию томов
2. Включить параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc
В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows
Разверните узлы Настройки безопасности и Локальные политики
Выберите папку Назначение прав пользователя
Политики будут показаны на панели подробностей
На этой панели дважды кликните параметр Блокировка страниц в памяти
В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу
В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server
Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server
3. Включить каталоги с файлами базы данных в правила исключения для антивируса.
Если антивирус будет сканировать файлы базы, это может сильно замедлить работу СУБД.
Для опытных администраторов: антивирус на сервер СУБД лучше не устанавливать.
4. Включить каталоги с файлами базы данных в список исключений для системы автоматического копирования.
Если на сервере установлена система автоматического копирования файлов, то, когда она будет копировать файлы базы, это может привести к замедлению работы. Копии базы необходимо делать средствами самой СУБД.
5. Отключить механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С.
Чтобы отключить его только для дисков, нужно:
Найти в реестре ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk
Установить значение параметра EnableFairShare в 0
6. Отключить сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
Открыть свойства каталога
На закладке Общие нажать кнопку Другие
Снять флаг «Сжимать» содержимое для экономии места на диске
7. Установить параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Дополнительно
Установить значение параметра равное единице
8. Ограничить максимальный объем памяти сервера MS SQL Server.
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Память
Указать значение параметра Максимальный размер памяти сервера
9. Включить флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Процессоры
Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок
10. Установить размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
Для установки размера авторасширения необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
11. Разнести файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Запомнить имена и расположение файлов
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
Поставить флаг Удалить соединения и нажать Ок
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
Нажать кнопку Добавить и указать файл mdf с нового диска
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
12. Вынести файлы базы TempDB на отдельный диск.
Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
Запустить Management Studio и подключиться к нужному серверу
Создать окно запроса и выполнить скрипт:
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = 'Новый_Диск:\Новый_Каталог\tempdb.mdf')
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = 'Новый_Диск:\Новый_Каталог\templog.ldf')
Перезапустить MS SQL Server
13. Включить Shared Memory, если сервер 1С расположен на том же компьютере, что и сервер СУБД.
Протокол Shared Memory позволит общаться приложениям через оперативную память, а не через протокол TCP/IP.
Для включения Shared Memory необходимо:
Запустить диспетчер конфигурации SQL Server
Зайти в пункт SQL Native Client – Клиентские протоколы – Общая память – Включено
Поставить значение Да и нажать Ок
Протокол Именованные каналы нужно выключить аналогичным образом
14. Перезапустить службу MS SQL Server
Внимание! Когда все настройки выполнены, необходимо перезапустить службу MS SQL Server
Читайте также: