
Что означает черточка в истории браузера
Заголовок, выраженный словами, понадобился только для поисковой находимости. Но речь пойдёт о роли символьной в JavaScript.
Впервые на неё я обратил внимание, когда переводил FAQ про asm.js и читал спецификации этого подмножества языка JavaScript. служит, например, для указания типа значения, возвращаемого из функции: после значения — значит, перед нами знаковое целое.
Вдругорядь я заметил в примере кода на Гитхабе, где происходило преобразование к целому числу результата деления на 1024².
Тогда глаза мои открылись, и я увидел прекрасные возможности:
Итак, во-первых, перед нами удобное средство отбрасывания дробной части.
- По отношению к отрицательным числам оно полезно тем, что дробное число превращается не в ближайшее меньшее целое число (возрастая по модулю), как это случилось бы а в ближайшее меньшее по модулю целое число (возрастая по значению). Нередко именно это и требуется.
- По отношению к положительным числам оно полезно уж тем одним, более чем на порядок короче по сравнению Поэтому она может и должна вызывать у разработчиков привыкание не меньшее, чем та принятая в jQuery о которой я говорил четыре дня назад, что с неё никто добровольно не перейдёт обратно например.
- Оно умеет выковыривать целые числа (и отбрасывать дробную часть у дробных чисел), извлекая их из строк (с отбрасыванием начальных и конечных пробелов) и даже из одноэлементных массивов.
- По отношению к данным всех остальных типов (которые не умеет извлечь) это средство действует как универсальный обнулитель. Нередко именно это и требуется.
При таком сопоставлении тотчас явствует, что плюс преобразует числу, делая возможными и такие экзотические варианты дробных чисел, как минус бесконечность (получаемая, например, или NaN преобразует числу, и оттого экзотические варианты обнуляются.
Рекомендую этот приём к широкому применению в вашем джаваскриптовом коде по мере нужды.
В данной статье мы разберемся с тем, как быстро восстановить удаленную историю из популярных браузеров, а также предоставим несколько быстрых и легких способов по восстановлению утерянной истории интернет проводников.
Содержание:
История браузера – специальная функция браузера, позволяющая автоматически вести журнал посещений абсолютно всех сайтов. Находясь в данный момент на любом из сайтов, в истории Вашего браузера появится соответствующая запись посещения.
С помощью истории можно быстро найти уже посещенный заинтересовавший сайт, или любой другой ресурс. Помимо этого, в истории отображается посещение даже в пределах одного сайта, что позволяет, к примеру, вернутся к прочтению конкретной статьи, продолжению просмотра видео, посещению интересующей страницы и т.д.
Почему удаляется история?
История браузера представляет собой достаточно большой объем информации, который пополняется новыми записями при каждом посещении сайтов. Постоянно накапливающиеся данные вызывают замедленную работу программы-обозревателя и попросту засоряют память компьютера (особенно это актуально для пользователей слабых ПК, офисных машин и бюджетных ноутбуков). Именно поэтому в браузерах присутствует встроенная функция очистки истории, позволяющая полностью удалить все записи .
Помимо этого, пользователь может собственноручно удалять записи истории по одной в произвольном порядке. Нередко история удаляется из-за использования утилит для быстрой очистки компьютера . Программы вроде CCleaner, Wise Care 365, Clean Master и другие позволяют производить комплексную очистку системы, которая затрагивает истории всех установленных браузеров. Это можно легко упустить, если случайно начать процесс очистки, не убрав пункты «Очистка журнала посещений» .
Восстановление истории из кэша DNS
DNS (Система доменных имен) – встроенная функция операционной системы, ведущая независимый журнал посещенных сайтов в сети. С её помощью можно быстро получить список посещенных сайтов.
К сожалению, через DNS нельзя просмотреть конкретные страницы, что значительно ограничивает данную функцию. Также функция ведет полный учет выходов в интернет , поэтому в ней сохраняются все записи о подключениях в интернете, а не только те, что были выполнены с браузера. Это означает, что для любой программы, соединяющейся с серверами, сайтом или любым онлайн ресурсом, будет сделана соответствующая запись в кэше .
Тем не менее, восстановление истории из кэша DNS не привязано к обозревателям (очистка истории браузера не влияет на кэш DNS), поэтому данный способ сможет подойти для самых различных ситуаций.
Чтобы восстановить историю из кэша DNS необходимо выполнить следующие шаги:
Шаг 1. Нажимаем правой кнопкой мыши по кнопке «Пуск» и выбираем пункт «Выполнить» . В открывшемся окне вводим команду cmd и «Ок» .










Тенденции
Лучшие публикации
Здесь самые лучшие по мнению пикабушников посты из Горячего за сегодня, неделю, месяц или любую дату.
Такие дела)
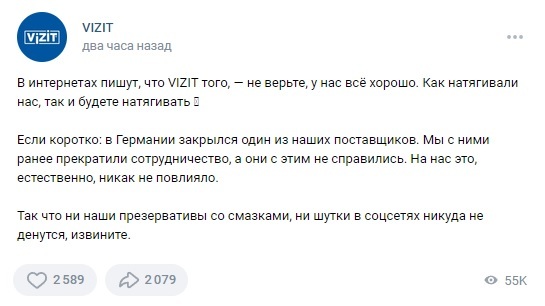

И так бывает

ОНИЖЕДЕТИ!!11

Как всегда.

Может случилось чего?

Жестокое нападение ежа на спящего медведя

Американцев обвинил в "открытом нацизме"
На одной из центральных "рекламных" улиц Нью-Йорка Таймс-сквер появился мультимедийный билборд, посвящённый России и Дню Победы в Великой Отечественной войне.
На мультимедийном постере 9 Мая названо "днём позора" России.
Согласно информации, кто конкретно стал инициатором размещения билборда, неизвестно. Однако пользователи соцсетей не оставили без внимания ситуацию и обвинили американцев в "открытом нацизме".
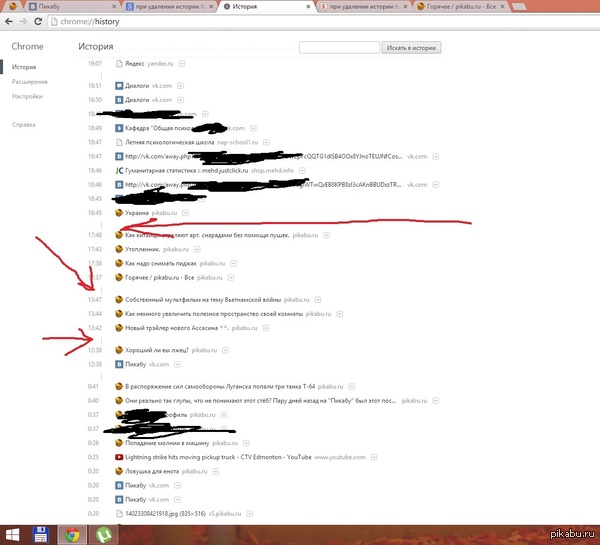
Заметил одну вещь. Если удалить историю, он появляется. Может ли это служить идентификатором того, что история в тот момент очищалась?
Но с другой стороны возникает другой вопрос. История удаляется минимум за час. Но от одной записи до другой бывает и меньше времени проходило. Есть какие соображения?
Такие дела)
И так бывает
ОНИЖЕДЕТИ!!11
Как всегда.
Может случилось чего?
Жестокое нападение ежа на спящего медведя
Американцев обвинил в "открытом нацизме"
На одной из центральных "рекламных" улиц Нью-Йорка Таймс-сквер появился мультимедийный билборд, посвящённый России и Дню Победы в Великой Отечественной войне.
На мультимедийном постере 9 Мая названо "днём позора" России.
Согласно информации, кто конкретно стал инициатором размещения билборда, неизвестно. Однако пользователи соцсетей не оставили без внимания ситуацию и обвинили американцев в "открытом нацизме".
Страх и ненависть Эмбер Херд


Самим рассказывать надо

День Победы
Фотограф Анатолий Грахов

Мерзкие хоббитцы


Отправь другу
Учитель физики показывает принцип Бернулли
На англ. но все интуитивно понятно
Озарение
Только что понял, зачем в жигулях делали такой тюнинг как на фото.
Всё потому что в ВАЗе должна быть роза.


Худеем однако
Мы с подругой худеем: она по какой-то хитрой системе, а я просто стараюсь меньше жрать. Дом ее очень хлебосольный: забежишь на чай и получишь кучу вкусняшек: и сыр, и колбасу, и осетинский пирог, и купленные к твоему приходу пироженки. Ляпота!
Забегаю на фоне похудения, и подруга ставит передо мной миску с сырой морковкой. Божечки мои, думаю, посидим-похрустим как кролики. Похрустели. Смотрю, мнется чего-то. А потом махнула рукой и наметала на стол и сыр, и колбасу, и осетинский пирог. Мы только пирожные есть не стали - мы же худеем в конце концов.)

Примечание: публикация основана на содержании репозитория What happens when.
Мы перенесли перевод в репозиторий GitHub и отправили Pull Request автору материала — оставляйте свои правки к тексту, и вместе мы сможем значительно улучшить его.
1. Нажата клавиша «g»
Далее в статье содержится информация о работе физической клавиатуры и прерывания операционной системы. Но много чего происходит и помимо этого — когда вы нажимаете клавишу «g», браузер получает событие и запускается механизм автоподстановки. В зависимости от алгоритма браузера и его режима (включена ли функция «инкогнито») в выпадающем окне под строкой URL пользователю будет предложено определённое количество вариантов для автоподстановки.
2. Клавиша «enter» нажата до конца
В качестве некой нулевой точки можно выбрать момент, когда клавиша Enter на клавиатуре нажата до конца и находится в нижнем положении. В этой точке замыкается электрическая цепь этой клавиши и небольшое количество тока отправляется по электросхеме клавиатуры, которая сканирует состояние каждого переключателя клавиши и конвертирует сигнал в целочисленный код клавиши (в данном случае — 13). Затем контроллер клавиатуры конвертирует код клавиши для передачи его компьютеру. Как правило, сейчас передача происходит через USB или Bluetooth, а раньше клавиатура подключалась к компьютеру с помощью коннекторов PS/2 или ADB.
В случае USB-клавиатуры:
- Для работы USB-контуру клавиатуры требуется 5 вольт питания, которые поступают через USB-контроллер на компьютере.
- Сгенерированный код клавиши хранится в регистре внутренней памяти клавиатуры, который называется «конечной точкой» (endpoint).
- USB-контроллер компьютера опрашивает эту конечную точку каждые 10 микросекунд и получает хранящийся там код клавиши.
- Затем это значение поступает в USB SIE (Serial Interface Engine) для конвертации в один или более USB-пакетов, которые формируются по низкоуровневому протоколу USB.
- Эти пакеты затем пересылаются с помощью различных электрических сигналов через D+ и D- контакты с максимальной скоростью 1,5 Мб/сек — поскольку HID-устройства (Human Interface Device) всегда были «низкоскоростными».
- Этот последовательный сигнал далее декодируется в USB-контроллере компьютера и интерпретируется универсальным драйвером HID-устройства (клавиатуры). Затем значение кода клавиши передаётся на «железный» уровень абстракции операционной системы.
2.1 Возникло прерывание [не для USB-клавиатур]
Клавиатура отправляет сигналы в свою «линию запросов прерываний» (IRQ), которая затем сопоставляется с «вектором прерывания» (целое число) контроллером прерываний. Процессор использует «таблицу дескрипторов прерываний» (IDT) для сопоставления векторов прерываний с функциями («обработчики прерываний») ядра. Когда появляется прерывание, процессор (CPU) обновляет IDT вектором прерывания и запускает соответствующий обработчик. Таким образом, в дело вступает ядро.
2.3 (В OS X) Событие NSEVent KeyDown отправлено приложению
Сигнал прерывания активирует событие прерывания в драйвере I/O Kit клавиатуры. Драйвер переводит сигнал в код клавиатуры, который затем передаётся процессу OS X под названием WindowServer . В результате, WindowsServer передаёт событие любому подходящему (активному или «слушающему») приложению через Mach-порт, в котором событие помещается в очередь. Затем события могут быть прочитаны из этой очереди потоками с достаточными привилегиями, чтобы вызывать функцию mach_ipc_dispatch . Чаще всего это происходит и обрабатывается с помощью основного цикла NSApplication через NSEvent в NSEventype KeyDown .
2.4 (В GNU/Linux) Сервер Xorg слушает клавиатурные коды
В случае графического X server, для получения нажатия клавиши будет использован общий драйвер событий evdev . Переназначение клавиатурных кодов скан-кодам осуществляется с помощью специальных правил и карт X Server. Когда маппинг скан-кода нажатой клавиши завершён, X server посылает символ в window manager (DWM, metacity, i3), который затем отправляет его в активное окно. Графический API окна, получившего символ, печатает соответствующий символ шрифта в нужном поле.
3. Парсинг URL
Теперь у браузера есть следующая информация об URL:
Resource «/»
Показать главную (индексную) страницу
3.1 Это URL или поисковый запрос?
Когда пользователь не вводит протокол или доменное имя, то браузер «скармливает» то, что человек напечатал, поисковой машине, установленной по умолчанию. Часто к URL добавляется специальный текст, который позволяет поисковой машине понять, что информация передана из URL-строки определённого браузера.
3.2 Список проверки HSTS
3.3 Конвертация не-ASCII Unicode символов в название хоста
4. Определение DNS
- Браузер проверяет наличие домена в своём кэше.
- Если домена там нет, то браузер вызывает библиотечную функцию gethostbyname (отличается в разных ОС) для поиска нужного адреса.
- Прежде, чем искать домен по DNS gethostbyname пытается найти нужный адрес в файле hosts (его расположение отличается в разных ОС).
- Если домен нигде не закэширован и отсутствует в файле hosts , gethostbyname отправляет запрос к сетевому DNS-серверу. Как правило, это локальный роутер или DNS-сервер интернет-провайдера.
- Если DNS-сервер находится в той же подсети, то ARP-запрос отправляется этому серверу.
- Если DNS-сервер находится в другой подсети, то ARP-запрос отправляется на IP-адрес шлюза по умолчанию (default gateway).
4.1 Процесс отправки ARP-запроса
Кэш ARP проверяется для каждого целевого IP-адреса — если адрес есть в кэше, то библиотечная функция возвращает результат: Target IP = MAC .
Если же записи в кэше нет:
- Проверяется таблица маршрутизации — это делается для того, чтобы узнать, есть ли искомый IP-адрес в какой-либо из подсетей локальной таблицы. Если он там, то запрос посылается с помощью интерфейса, связанного с этой подсетью. Если адрес в таблице не обнаружен, то используется интерфейс подсети шлюза по умолчанию.
- Определяется MAC-адрес выбранного сетевого интерфейса.
- Отправляется ARP-запрос (второй уровень стека):
Sender MAC: interface:mac:address:here
Sender IP: interface.ip.goes.here
Target MAC: FF:FF:FF:FF:FF:FF (Broadcast)
Target IP: target.ip.goes.here
В зависимости от того, какое «железо» расположено между компьютером и роутером (маршрутизатором):
- Если компьютер напрямую подключён к роутеру, то это устройство отправляет ARP-ответ (ARP Reply).
- Если компьютер подключён к сетевому концентратору, то этот хаб отправляет широковещательный ARP-запрос со всех своих портов. Если роутер подключён по тому же «проводу», то отправит ARP-ответ.
- Если компьютер соединён с сетевым коммутатором, то этот свитч проверит локальную CAM/MAC-таблицу, чтобы узнать, какой порт в ней имеет нужный MAC-адрес. Если нужного адреса в таблице нет, то он заново отправит широковещательный ARP-запрос по всем портам.
- Если в таблице есть нужная запись, то свитч отправит ARP-запрос на порт с искомым MAC-адресом.
- Если роутер «на одной линии» со свитчем, то он ответит (ARP Reply).
Sender MAC: target:mac:address:here
Sender IP: target.ip.goes.here
Target MAC: interface:mac:address:here
Target IP: interface.ip.goes.here
Теперь у сетевой библиотеки есть IP-адрес либо DNS-сервера либо шлюза по умолчанию, который можно использовать для разрешения доменного имени:
- Порт 53 открывается для отправки UDP-запроса к DNS-серверу (если размер ответа слишком велик, будет использован TCP).
- Если локальный или на стороне провайдера DNS-сервер «не знает» нужный адрес, то запрашивается рекурсивный поиск, который проходит по списку вышестоящих DNS-серверов, пока не будет найдена SOA-запись, а затем возвращается результат.
5. Открытие сокета
- Этот запрос сначала проходит через транспортный уровень, где собирается TCP-сегмент. В заголовок добавляется порт назначения, исходный порт выбирается из динамического пула ядра ( ip_local_port_range в Linux).
- Получившийся сегмент отправляется на сетевой уровень, на котором добавляется дополнительный IP-заголовок. Также включаются IP-адрес сервера назначения и адрес текущей машины — после этого пакет сформирован.
- Пакет передаётся на канальный уровень. Добавляется заголовок кадра, включающий MAC-адрес сетевой карты (NIC) компьютера, а также MAC-адрес шлюза (локального роутера). Как и на предыдущих этапах, если ядру ничего не известно о MAC-адресе шлюза, то для его нахождения отправляется широковещательный ARP-запрос.
В конечном итоге пакет доберётся до маршрутизатора, управляющего локальной подсетью. Затем он продолжит путешествовать от одного роутера к другому, пока не доберётся до сервера назначения. Каждый маршрутизатор на пути будет извлекать адрес назначения из IP-заголовка и отправлять пакет на следующий хоп. Значение поля TTL (time to live) в IP-заголовке будет каждый раз уменьшаться после прохождения каждого роутера. Если значение поля TTL достигнет нуля, пакет будет отброшен (это произойдёт также если у маршрутизатора не будет места в текущей очереди — например, из-за перегрузки сети).
5.1 Жизненный цикл TCP-соединения
a. Клиент выбирает номер начальной последовательности (ISN) и отправляет пакет серверу с установленным битом SYN для открытия соединения.
b. Сервер получает пакет с битом SYN и, если готов к установлению соединения, то:
- Выбирает собственный номер начальной последовательности;
- Устанавливает SYN-бит, чтобы сообщить о выборе начальной последовательности;
- Копирует ISN клиента +1 в поле ACK и добавляет ACK-флаг для обозначения подтверждения получения первого пакета.
- Увеличивает номер своей начальной последовательности;
- Увеличивает номер подтверждения получения;
- Устанавливает поле ACK.
- Когда одна сторона отправляет N байтов, то увеличивает значение поля SEQ на это число.
- Когда вторая сторона подтверждает получение этого пакета (или цепочки пакетов), она отправляет пакет ACK, в котором значение поля ACK равняется последней полученной последовательности.
- Сторона, которая хочет закрыть соединение, отправляет пакет FIN;
- Другая сторона подтверждает FIN (с помощью ACK) и отправляет собственный FIN-пакет;
- Инициатор прекращения соединения подтверждает получение FIN отправкой собственного ACK.
6. TLS handshake
Сервер отвечает специальным кодом, который обозначает статус запроса и включает ответ следующей формы:
200 OK
[заголовки ответа]
304 Not Modified
[заголовки ответа]
и, соответственно, клиенту не посылается никакого контента, вместо этого браузер «достаёт» HTML из кэша.
— Сервер разбирает запрос по следующим параметрам:
— Сервер проверяет, имеет ли клиент право использовать этот метод (на основе IP-адреса, аутентификации и прочее).
— Если на сервере установлен модуль перезаписи ( mod_rewrite для Apache или URL Rewrite для IIS), то он сопоставляет запрос с одним из сконфигурированных правил. Если находится совпадающее правило, то сервер использует его, чтобы переписать запрос.
— Сервер находит контент, который соответствует запросу, в нашем случае он изучит индексный файл.
— Далее сервер разбирает («парсит») файл с помощью обработчика. Если Google работает на PHP, то сервер использует PHP для интерпретации индексного файла и направляет результат клиенту.
8. За кулисами браузера
Задача браузера заключается в том, чтобы показывать пользователю выбранные им веб-ресурсы, запрашивая их с сервера и отображая в окне просмотра. Как правило такими ресурсами являются HTML-документы, но это может быть и PDF, изображения или контент другого типа. Расположение ресурсов определяется с помощью URL.
Способ, который браузер использует для интерпретации и отображения HTML-файлов описан в спецификациях HTML и CSS. Эти документы разработаны и поддерживаются консорциумом W3C (World Wide Wib Consortium), которая занимается стандартизацией веба.
Интерфейсы браузеров сильно похожи между собой. У них есть большое количество одинаковых элементов:
- Адресная строка, куда вставляются URL-адреса;
- Кнопки возврата на предыдущую и следующую страницу;
- Возможность создания закладок;
- Кнопки обновления страницы (рефреш) и остановки загрузки текущих документов;
- Кнопка «домой», возвращающая пользователя на домашнюю страницу.
Высокоуровневая структура браузера
Браузер включает следующие компоненты:
9. Парсинг HTML
Движок рендеринга начинает получать содержимое запрашиваемого документа от сетевого механизма браузера. Как правило, контент поступает кусками по 8Кб. Главной задачей HTML-парсера является разбор разметки в специальное дерево.
Получающееся на выходе дерево («parse tree») — это дерево DOM-элементов и узлов атрибутов. DOM — сокращение от Document Object Model . Это модель объектного представления HTML-документа и интерфейс для взаимодействия HTML-элементов с «внешним миром» (например, JavaScript-кодом). Корнем дерева является объект «Документ».
Алгоритм разбора
HTML-нельзя «распарсить» с помощью обычных анализаторов (нисходящих или восходящих). Тому есть несколько причин:
- Прощающая почти что угодно природа языка;
- Тот факт, что браузеры обладают известной толерантностью к ошибкам и поддерживают популярные ошибки в HTML.
- Процесс парсинга может заходить в тупик. В других языках код, который требуется разобрать, не меняется в процессе анализа, в то время как в HTML с помощью динамического кода (например, скриптовые элементы, содержащие вызовы document.write() ) могут добавляться дополнительные токены, в результате чего сам процесс парсинга модифицирует вывод.
Алгоритм состоит из двух этапов: токенизации и создания дерева.
Действия после завершения парсинга
После этого браузер начинает подгружать внешние ресурсы, связанные со страницей (стили, изображения, скрипты и так далее).
На этом этапе браузер помечает документ, как интерактивный и начинает разбирать скрипты, находящиеся в «отложенном» состоянии: то есть те из них, что должны быть исполнены после парсинга. После этого статус документа устанавливается в состояние « complete » и инициируется событие загрузки (« load »).
Важный момент: ошибки «Invalid Syntax» при разборе не может быть, поскольку браузеры исправляют любой «невалидный» контент и продолжают работу.
10. Интерпретация CSS
- Во время разбора браузер парсит CSS-файлы, содержимое тегов и атрибутов «style» c помощью «лексической и синтаксической грамматики CSS».
- Каждый CSS-файл разбирается в объект StyleSheet , каждый из таких объектов содержит правила CSS с селекторами и объектами в соответствии с грамматикой CSS.
- Парсер CSS может быть как восходящим, так и нисходящим.
11. Рендеринг страниц
- Путём перебора DOM-узлов и вычисления для каждого узла значений CSS-стилей создаётся «Дерево рендера» (Render Tree или Frame Tree).
- Вычисляется предпочтительная ширина каждого узла в нижней части дерева — для этого суммируются значения предпочтительной ширины дочерних узлов, а также горизонтальные поля, границы и отступы узлов.
- Вычисляется реальная ширина каждого узла сверху-вниз (доступная ширина каждого узла выделяется его потомкам).
- Вычисляется высота каждого узла снизу-вверх — для этого применяется перенос текста и суммируются значения полей, высоты, отступов и границ потомков.
- Вычисляются координаты каждого узла (с использованием ранее полученной информации).
- Если элементы плавающие или спозиционированы абсолютно или относительно, предпринимаются более сложные действия. Более подробно они описаны здесь и здесь.
- Создаются слои для описания того, какие части страницы можно анимировать без необходимости повторного растрирования. Каждый объект (фрейма или рендера) присваивается слою.
- Для каждого слоя на странице выделяются текстуры.
- Объекты (рендеры/фреймы) каждого слоя перебираются и для соответствующих слоёв выполняются команды отрисовки. Растрирование может осуществляться процессором или возможна отрисовка на графическом процессоре (GPU) через D2D/SkiaGL.
- Все вышеперечисленные шаги могут требовать повторного использования значений, сохранённых с последнего рендеринга страницы, такая инкрементальная работа требует меньше затрат.
- Слои страницы отправляются процессу-компоновщику, где они комбинируются со слоями для другого видимого контента (интерфейс браузера, iframe-элементы, addon-панели).
- Вычисляются финальные позиции слоёв и через Direct3D/OpenGL отдаются композитные команды. Командные буферы GPU освобождаются для асинхронного рендеринга и фрейм отправляется для отображения на экран.
12. Рендеринг GPU
- Во время процесса рендеринга уровни графических вычислений могут использовать процессор компьютера или графический процессор (GPU).
- Во втором случае уровни графического программного обеспечения делят задачу на множество частей, что позволяет использовать параллелизм GPU для вычисления плавающей точки, которое требуется для процесса рендеринга.
13. Вызванное пользователем и пост-рендеринговое исполнение
После завершения рендеринга, браузер исполняет JavaScript-код в результате срабатывания некоего часового механизма (так работают дудлы на странице Google) или в результате действий пользователя (ввод поискового запроса в строку и получение рекомендаций в ответ). Также могут срабатывать плагины вроде Flash или Java (но не в рассматриваемом примере с домашней страницей Google). Скрипты могут потребовать обработки дополнительных сетевых запросов, изменять страницу или её шаблон, что приведёт к следующему этапу рендеринга и отрисовки.
Читайте также: