
Что не относится к инструментам хранения и обработки больших данных excel
+ Все виды действий с электронными таблицами (создание, редактирование, выполнение вычислений); построение графиков и диаграмм на основе данных из таблиц; работа с книгами и т.д.
- Редактирование таблиц; вывод данных из таблиц на печать; правка графической информации
8. К табличным процессорам относятся:
+ Quattro Pro 10, Lotus 1-2-3
- Microsoft Excel, Freelance Graphics
- Paradox 10, Microsoft Access
9. К встроенным функциям табличных процессоров относятся:
тест 10. Какие типы диаграмм позволяют строить табличные процессоры?
+ График, точечная, линейчатая, гистограмма, круговая
- Коническая, плоская, поверхностная, усеченная
- Гистограмма, график, локальное пересечение, аналитическая
11. Математические функции табличных процессоров используются для:
- Исчисления средних значений, максимума и минимума
- Расчета ежемесячных платежей по кредиту, ставок дисконтирования и капитализации
+ Расчета тригонометрических функций и логарифмов
12. Документ табличного процессора Excel по умолчанию называется:
13. Табличный процессор обрабатывает следующие типы данных:
- Матричный, Временной, Математический, Текстовый, Денежный
- Банковский, Целочисленный, Дробный, Текстовый, Графический
+ Дата, Время, Текстовый, Финансовый, Процентный
14. Статистические функции табличных процессоров используются для:
- Проверки равенства двух чисел; расчета величины амортизации актива за заданный период
+ Вычисления суммы квадратов отклонений; плотности стандартного нормального распределения
- Расчета кортежа из куба; перевода из градусов в радианы
15. Какова структура рабочего листа табличного процессора?
- Строки, столбцы, командная строка, набор функций
- Ячейки, набор функций, строка состояния
+ Строки и столбцы, пересечения которых образуют ячейки
16. Как называется документ, созданный в табличном процессоре?
17. Финансовые функции табличных процессоров используются для:
- Вычисления произведения аргументов; определения факториала числа
- Определения ключевого показателя эффективности; построения логических выражений
+ Расчетов дохода по казначейскому векселю и фактической годовой процентной ставки
18. Табличные процессоры относятся к какому программному обеспечению?
19. В виде чего нельзя отобразить данные в электронной таблице?
тест_20. Дан фрагмент электронной таблицы с числами и формулами.
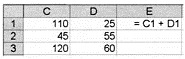
Чему равно значение в ячейке Е3, скопированное после проведения вычислений в ячейке Е1?
21. Расширение файлов, созданных в Microsoft Excel – это:
22. Координата в электронной таблице – это адрес:
+ Клетки в электронной таблице
- Данных в столбце
- Клетки в строке
23. Какие типы фильтров существуют в табличном процессоре Excel?
- Тематический фильтр, автофильтр
+ Автофильтр, расширенный фильтр
- Текстовый фильтр, числовой фильтр
24. Наиболее наглядно будет выглядеть представление средних зарплат представителей разных профессий в виде:
25. 30 ячеек электронной таблицы содержится в диапазоне:
26. Выберите абсолютный адрес ячейки из табличного процессора Excel:
27. Скопированные или перемещенные абсолютные ссылки в электронной таблице:
- Преобразуются в соответствии с новым положением формулы
- Преобразуются в соответствии с новым видом формулы
28. Активная ячейка – это ячейка:
- С формулой, в которой содержится абсолютная ссылка
+ В которую в настоящий момент вводят данные
- С формулой, в которой содержится относительная ссылка
29. Отличием электронной таблицы от обычной является:
+ Автоматический пересчет задаваемых формулами данных в случае изменения исходных
- Представление связей между взаимосвязанными обрабатываемыми данными
- Обработка данных различного типа
тест-30. Совокупность клеток, которые образуют в электронной таблице прямоугольник – это:
31. В табличном процессоре Excel столбцы:
+ Обозначаются буквами латинского алфавита
- Обозначаются римскими цифрами
- Получают имя произвольным образом
32. Символ «=» в табличных процессорах означает:
- Фиксацию абсолютной ссылки
+ Начало ввода формулы
- Фиксацию относительной ссылки
33. Какого элемента структуры электронной таблицы не существует?
34. Числовое выражение 15,7Е+4 из электронной таблицы означает число:
35. В одной ячейке можно записать:
+ Только одно число
- Одно или два числа
- Сколько угодно чисел
36. Подтверждение ввода в ячейку осуществляется нажатием клавиши:
37. Содержимое активной ячейки дополнительно указывается в:
38. Для чего используется функция Excel СЧЕТ3?
- Для подсчета ячеек, содержащих числа
- Для подсчета пустых ячеек в диапазоне ячеек
+ Для подсчета заполненных ячеек в диапазоне ячеек
39. Функция ОБЩПЛАТ относится к:
тест*40. Укажите верную запись формулы:
41. Маркер автозаполнения появляется, когда курсор устанавливают:
+ В правом нижнем углу активной ячейки
- В левом верхнем углу активной ячейки
- По центру активной ячейки
42. Диапазоном не может быть:
+ Группа ячеек D1, E2, F3
43. Можно ли убрать сетку в электронной таблицу Excel?
- Да, если снята защита от редактирования таблицы
+ Ширина ячейки меньше, чем длина полученного результата
- Допущена синтаксическая ошибка в формуле
- Полученное значение является иррациональным числом
45. В электронной таблице выделен диапазон ячеек A1:B3. Сколько ячеек выделено?
Перед вами перевод статьи из блога Seattle Data Guy. В ней авторы выделили 5 наиболее популярных ресурсов для обработки Big Data на текущий момент.

Сегодня любая компания, независимо от ее размера и местоположения, так или иначе имеет дело с данными. Использование информации в качестве ценного ресурса, в свою очередь, подразумевает применение специальных инструментов для анализа ключевых показателей деятельности компании. Спрос на аналитику растет пропорционально ее значимости, и уже сейчас можно определить мировые тенденции и перспективы в этом секторе. Согласно мнению International Data Corporation, в 2019 году рынок Big Data и аналитики готов перешагнуть порог в 189,1 миллиарда долларов.
Инструменты для анализа данных
Инструменты для анализа данных — это ресурсы, которые поддерживают функцию оперативного сбора, анализа и визуализации данных. Они полезны для любой компании, которая уделяет внимание потребительским предпочтениям, данным, рыночным трендам и т. д. Сегодня набирают популярность многие эффективные и общедоступные открытые ресурсы, что усложняет выбор самой успешной платформы. Возможностей для анализа данных сейчас очень много, но хочется найти оптимальный вариант.
В мире информационной аналитики автоматическим сбором, обработкой и анализом данных занимаются как крупные компании, так и небольшие. Чтобы помочь вам выбрать подходящую платформу, мы составили список из 5 топовых аналитических инструментов. Это лучшие продукты, которые существуют на сегодняшний день в этой сфере. Оценивались они по следующим критериям:
- функциональность,
- легкость изучения (и поддержка со стороны комьюнити),
- популярность.
- Apache Cassandra
- Apache Hadoop
- Elasticsearch
- Presto
- Talend
1. Apache Cassandra

Платформа Apache Cassandra, разработанная в 2008 году Apache Software Foundation, представляет собой бесплатный и доступный любому пользователю инструмент для управления базой данных. Apache Cassandra распространяется и работает на основе NoSQL. Управление данными осуществляется через кластерные формы, соединяющие несколько узлов в центрах обработки многокомпонентных данных. В терминологии NoSQL инструмент Apache Cassandra также обозначен как «столбцовая база данных».
В первую очередь, эта система востребована в приложениях для Big Data, которые работают с актуальными данными, например, в сенсорных устройствах и социальных сетях. Кроме того, Cassandra использует децентрализованную архитектуру, которая подразумевает, что функциональные модули, такие как сегментирование данных, устранение отказов, репликация и масштабирование, доступны по отдельности и работают в цикле. Более подробную информацию можно узнать в документации Apache Cassandra.
Ключевые характеристики Apache Cassandra:
- Возможность функционирования на не очень мощном оборудовании.
- Архитектура Cassandra, которая построена на основе технологии Dynamo от Amazon и реализует систему базы данных с использованием ключей.
- Язык запросов Cassandra.
- Развернутое распределение и высокая масштабируемость применения.
- Отказоустойчивость и децентрализованная система.
- Оперативная запись и считывание данных.
- Настраиваемая совместимость и поддержка фреймворка MapReduce.
2. Apache Hadoop

Apache Hadoop представляет собой общедоступный аналитический инструмент для распределенного хранения и обработки больших пакетов данных. Кроме того, Apache Hadoop предоставляет услуги для доступа к данным с помощью набора утилит, которые позволяют выстроить сеть из нескольких компьютеров. Внутренняя структура Apache Hadoop лояльна к поддержке крупных компьютерных кластеров. Более подробную информацию можно узнать в документации Apache Hadoop.
Ключевые характеристики Apache Hadoop:
- Платформа с высокой масштабируемостью для анализа данных на уровне петабайта.
- Возможность хранить данные в любом формате и парсить при чтении (на выбор есть структурированные, частично структурированные и неструктурированные форматы).
- Редкий отказ узлов в кластере. Но даже если это происходит, система автоматически заново воспроизводит данные и переадресовывает остаточные данные.
- Возможность взаимодействовать с другой приоритетной платформой анализа данных. Использование не только NoSQL, но и пакетов, диалогового SQL или доступа с низким значением задержки для бесперебойного процесса обработки данных.
- Экономичное решение, так как открытая платформа функционирует на сравнительно недорогом оборудовании.
3. ElasticSearch

Elasticsearch — это инструмент на основе JSON для поиска и анализа Big Data. Elasticsearch предоставляет децентрализованную библиотеку аналитики и поиск на основе архитектуры REST по решенным вариантам использования. Также платформа Elasticsearch проста в управлении, в высокой степени надежна и поддерживает горизонтальную масштабируемость. Более подробную информацию можно узнать в документации Elasticsearch.
Ключевые характеристики Elasticsearch:
- Сборка и поддержка программ-клиентов на нескольких языках, таких как Java, Groovy, NET и Python.
- Интуитивно понятный API для управления и мониторинга данных, который обеспечивает полный контроль и наглядность.
- Возможность комбинировать несколько видов поиска, включая геопоиск, поиск по метрикам, структурированный и неструктурированный поиск и т. д.
- Использование стандартного API и формата JSON на основе архитектуры REST.
- Расширенные возможности при анализе данных благодаря машинному обучению, параметрам мониторинга, предоставления отчетов и безопасности.
- Актуальная аналитика и параметры поиска для обработки Big Data с помощью Elasticsearch-Hadoop.
4. Presto

Продукт Facebook Presto выделяется за счет стабильной скорости обработки коммерческих данных. Presto функционирует в качестве децентрализованной библиотеки запросов на основе SQL, которая может отлично взаимодействовать с Hadoop, MySQL и другими ресурсами. Для работы с совместными аналитическими запросами по отношению к различным источникам информации Presto использует децентрализованную открытую схему. Система Presto также предоставляет качественную интерактивную аналитику, недаром ее считают одним из лучших общедоступных инструментов для анализа Big Data. Более подробную информацию можно узнать в документации Presto.
Ключевые характеристики Presto:
- Адаптивная многопользовательская система, поддерживающая одновременное выполнение нескольких операций с памятью машины, операций ввода/вывода (I/O) и запросов с интенсивной вычислительной нагрузкой на CPU.
- Обеспечение оптимизации для достижения высокой производительности, включая такую важную опцию, как генерация кода.
- Возможность расширения и дальнейшей интеграции для создания нескольких кластеров.
- Различные настройки и конфигурации для поддержания многочисленных вариантов использования с несколькими ограничениями и параметрами производительности.
- Возможность комбинировать в одном запросе данные из множества источников и организовывать анализ Big Data.
- Поддержка стандартов ANSI SQL (в дополнение к ARRAY, JSON, MAP и ROW).
5. Talend

Talend считается одним из представителей нового поколения инструментов в сфере Big Data и облачной интеграции. Talend остается открытой платформой, которая предлагает свой способ автоматической и упрощенной интеграции Big Data. Среди дополнительных решений от Talend стоит отметить проверку качества данных, управление данными и генерацию собственного кода с помощью графического мастера. Более подробную информацию можно узнать в документации Talend.
Ключевые характеристики Talend:
- Повышение коэффициента «время-эффективность» для планов с участием Big Data.
- Agile DevOps для ускоренной обработки Big Data.
- Упрощение работы Spark и MapReduce за счет генерации собственных кодов.
- Более качественные данные благодаря машинному обучению и обработке информации на естественном языке.
- Упрощение процессов ELT (Extract, Load и Transform) и ETL (Extract, Transform и Load) для Big Data.
- Оптимальная настройка всех процессов в DevOps.
Заключение
Миром правит информация. Чтобы стать лидером, компании необходимо отслеживать данные и уметь правильно с ними работать. Если вы планируете укрепить свои позиции, выявляя потребительские предпочтения, рыночные тренды, эффективные бизнес-модели и будущие перспективы, то следует пристально рассмотреть передовые инструменты для анализа данных.
Не стоит упускать из внимания статистические данные вашей деятельности и недооценивать их значение. Также важно понимать трафик ваших коммерческих данных. Воспользовавшись одним из представленных выше аналитических инструментов (или же любым другим), вы получите много новой информации и сможете значительно увеличить свои шансы на успех. Поэтому, чтобы двигаться в верном направлении, не забывайте о ваших данных, анализируйте их, работайте с ними и берите на вооружение полученный результат.

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):

При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):

MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Современные технологии дают человечеству множество возможностей, которыми не только желательно, но и нужно пользоваться. Самая большая ценность в 21 это информация. Мы собираем и храним информацию, которая накапливается в ходе научных исследований, социальных опросов, работе некоторых приложений (привет! face app) и в процессе работы различных бизнесов. Big Data или Большие Данные, стал одним из самых важных инструментов в руках менеджеров, важным настолько, что трудно представить себе бизнес, который его не внедряет.
Умение работать с Big Data необходимо не только для того, чтобы эффективно извлекать информацию, но и для глубокого ее анализа, а также выстраивания правильной стратегии работы. Кроме того, умение эффективно использовать Большие Данные - это ценный навык для любого современного специалиста.
В этой статье мы расскажем о 5 важных инструментах и навыках работы с Большими Данными, которые будут полезны менеджерам.
Реляционная СУБД (Relational database management system)
Реляционная СУБД (Реляционная система управления базами данных) - это система управления, для которой характерна простота и удобство, а также табличный вид.
Это множество взаимосвязанных таблиц, каждая из которых содержит определенную связанную информацию. Так, из подобной таблицы вы можете узнать, например, номер клиента, его имя, модель его автомобиля и так далее. По сути, подобная база данных поможет вам найти всю необходимую для работы информацию. Табличный вид делает ее удобной для навигации и поиска необходимых данных, а также для составления статистики.
Однако, если вы работаете с большим объемом данных, то реляционная система управления базами данных станет не лучшим решением. Обработка и поиск необходимой информации может занять слишком много времени, если база данных велика. Тем не менее, это один из самых популярных видов баз данных.
Языки программирования
Как ни странно, но даже менеджеру, который не работает напрямую с разработкой программ и приложений, необходимо знать языки программирования. Это поможет не только разговаривать «на одном языке» с программистами, но и облегчит вашу работу, автоматизируя некоторые задачи. Зная даже азы того же языка Python, который становится все более популярным, вы сможете самостоятельно написать бота, скрипт или небольшую программу, которые помогут в сборе информации для дальнейшей обработки и анализа. Также вы сможете эффективнее организовать работу с клиентами и быстрее собирать обратную связь.
К плюсам Python можно отнести не только относительную простоту и легкость освоения, но и то, что он используется повсеместно. На нем можно не только писать программы, но и использовать его для Машинного обучения и аналитики. Кроме того, питон прост в изучении, в сети полно курсов для любого уровня подготовки.
В конце-концов, знания языков программирования сейчас - это не только необходимость для успешной работы и саморазвития, но и серьезный плюс для будущего повышения по карьерной лестнице. Кроме того, вы поймете, что изучать программирование - это интересно. Кто знает, возможно именно это сподвигнет вас на то, чтобы сменить профессию в будущем.
Hadoop
За странным названием Hadoop скрывается мощный инструмент для работы с большим количеством данных, который был написан с помощью языка программирования Java. Файловая система Hadoop (HDFS) дублирует информацию и распределяет ее по разным узлам.
Hadoop можно назвать революционной технологией для Big Data, с ее помощью данные хранятся в исходном необработанном формате и могут быть использованы для размещения, обработки или управления, а также преобразования их в определенный формат. Еще одним преимуществом является надежность - данные точно останутся в целости и сохранности. Hadoop заслуженно считается одной из основных технологий Больших Данных. Более того, многие компании разработали свою экосистему именно основываясь на этом инструменте.
К минусам, пожалуй, можно отнести только сложность освоения данного инструмента. Однако, если вы сможете его постичь, то станете действительно ценным специалистом.
Cassandra
Cassandra - это сервер базы данных или же распределенная БД, построенная по принципу кольцевой архитектуры. Данная система базы данных хороша тем, что имеет открытый исходный код и позволяет анализировать большое количество данных. Высокая производительность и доступность способствует быстрой и комфортной работе.
Кроме того, Cassandra позволяет группировать данные или добавлять избыточную информацию для оптимизации производительности. Это мощный и надежный, а также отказоустойчивый инструмент, который самостоятельно распределяет данные между узлами. Написана Cassandra на языке Java. Система позволяет выполнять как простые, так и сложные запросы.
RDD (Resilient Distributed Dataset)
RDD - это распределенная таблица, которая чем-то схожа с реляционными таблицами, которые мы рассматривали выше. Один из самых популярных инструментов, который использует данную систему, называется Apache Spark. Все действия в Spark проходят через операции над RDD. Другими словами, это инструмент для действительно сложных аналитических заданий, которые выполняются с помощью рабочих узлов. Одним из плюсов данного инструмента является то, что он нативно поддерживает Python и еще несколько популярных языков программирования.
Apache Spark
Apache Spark - это быстрый и удобный инструмент для хранения данных, который, что интересно, можно использовать и для другой подобной платформы. Несмотря на то, что данный инструмент не рассчитан на слишком уж больших объемов данных, он славится своей скоростью работы. Еще один интересный факт заключается в том, что Apache Spark подходит для Машинного обучения, работы с графами и обработкой данных в режиме потока.
Как научиться работать с Большими Данными и применять их для эффективного управления? Подробно рассказываем об этом на курсе Data Driven Management
Рассказываем об основных терминах, методах и инструментах, которые используются при анализе больших данных.

О тенденция развития больших данных мы писали в статье « Почему Big Data так быстро развивается? ». В новой статье расскажем о применениях больших данных простыми словами.
Что такое большие данные?
Big Data – область, в которой рассматриваются различные способы анализа и систематического извлечения больших объемов данных. Она включает применение механических или алгоритмических процессов получения оперативной информации для решения сложных бизнес-задач. Специалисты по Big Data работают с неструктурированными данными, результаты анализа которых используются для поддержки принятия решений в бизнесе.
Одно из определений больших данных звучит следующим образом: «данные можно назвать большими, когда их размер становится частью проблемы». Такие объемы информации не могут быть сохранены и обработаны с использованием традиционного вычислительного подхода в течение заданного периода времени. Но насколько огромными должны быть данные, чтобы их можно было назвать большими? Обычно мы говорим о гигабайтах, терабайтах, петабайтах, эксабайтах или более крупных единицах измерения. Тут и возникает неправильное представление. Даже данные маленького объема можно назвать большими в зависимости от контекста, в котором они используются.
Как классифицируются большие данные?
Выделим три категории:
- Структурированные данные, имеющие связанную с ними структуру таблиц и отношений. Например, хранящаяся в СУБД информация, файлы CSV или таблицы Excel.
- Полуструктурированные (слабоструктурированные) данные не соответствуют строгой структуре таблиц и отношений, но имеют другие маркеры для отделения семантических элементов и обеспечения иерархической структуры записей и полей. Например, информация в электронных письмах и файлах журналов.
- Неструктурированные данные вообще не имеют никакой связанной с ними структуры, либо не организованы в установленном порядке. Обычно это текст на естественном языке, файлы изображений, аудиофайлы и видеофайлы.
Характеристики больших данных
Большие данные характеризуются четырьмя правилами (англ. 4 V’s of Big Data: Volume, Velocity, Variety, Veracity) :
- Объем: компании могут собирать огромное количество информации, размер которой становится критическим фактором в аналитике.
- Скорость, с которой генерируется информация. Практически все происходящее вокруг нас (поисковые запросы, социальные сети и т. д.) производит новые данные, многие из которых могут быть использованы в бизнес-решениях.
- Разнообразие: генерируемая информация неоднородна и может быть представлена в различных форматах, вроде видео, текста, таблиц, числовых последовательностей, показаний сенсоров и т. д. Понимание типа больших данных является ключевым фактором для раскрытия их ценности.
- Достоверность: достоверность относится к качеству анализируемых данных. С высокой степенью достоверности они содержат много записей, которые ценны для анализа и которые вносят значимый вклад в общие результаты. С другой стороны данные с низкой достоверностью содержат высокий процент бессмысленной информации, которая называется шумом.
Традиционный подход к хранению и обработке больших данных
При традиционном подходе данные, которые генерируются в организациях, подаются в систему ETL (от англ. Extract, Transform and Load) . Система ETL извлекает информацию, преобразовывает и загружает в базу данных. Как только этот процесс будет завершен, конечные пользователи смогут выполнять различные операции, вроде создание отчетов и запуска аналитических процедур.
По мере роста объема данных, становится сложнее ими управлять и тяжелее обрабатывать их с помощью традиционного подхода. К его основным недостаткам относятся:
- Дорогостоящая система, которая требует больших инвестиций при внедрении или модернизации, и которую малые и средние компании не смогут себе позволить.
- По мере роста объема данных масштабирование системы становится сложной задачей.
- Для обработки и извлечения ценной информации из данных требуется много времени, поскольку инфраструктура разработана и построена на основе устаревших вычислительных систем.
Термины
Облачные Вычисления
Облачные вычисления или облако можно определить, как интернет-модель вычислений, которая в значительной степени обеспечивает доступ к вычислительным ресурсам. Эти ресурсы включают в себя множество вещей, вроде прикладного программного обеспечение, вычислительных ресурсов, серверов, центров обработки данных и т. д.
Прогнозная Аналитика
Технология, которая учится на опыте (данных) предсказывать будущее поведение индивидов с помощью прогностических моделей. Они включают в себя характеристики (переменные) индивида в качестве входных данных и производит оценку в качестве выходных. Чем выше объясняющая способность модели, тем больше вероятность того, что индивид проявит предсказанное поведение.
Описательная Аналитика
Описательная аналитика обобщает данные, уделяя меньше внимания точным деталям каждой их части, вместо этого сосредотачиваясь на общем повествовании.
Базы данных
Данные нуждаются в кураторстве, в правильном хранении и обработке, чтобы они могли быть преобразованы в ценные знания. База данных – это механизм хранения, облегчающий такие преобразования.
Хранилище Данных
Хранилище данных определяется как архитектура, которая позволяет руководителям бизнеса систематически организовывать, понимать и использовать свои данные для принятия стратегических решений.
Бизнес-аналитика
Бизнес-аналитика (BI) – это набор инструментов, технологий и концепций, которые поддерживают бизнес, предоставляя исторические, текущие и прогнозные представления о его деятельности. BI включает в себя интерактивную аналитическую обработку (англ. OLAP, online analytical processing) , конкурентную разведку, бенчмаркинг, отчетность и другие подходы к управлению бизнесом.
Apache Hadoop
Apache Hadoop – это фреймворк с открытым исходным кодом для обработки больших объемов данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений.
Apache Spark
Apache Spark – это мощный процессорный движок с открытым исходным кодом, основанный на скорости, простоте использования и сложной аналитике, с API-интерфейсами на Java, Scala, Python, R и SQL. Spark запускает программы в 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Его можно использовать для создания приложений данных в виде библиотеки или для выполнения специального анализа в интерактивном режиме. Spark поддерживает стек библиотек, включая SQL, фреймы данных и наборы данных, MLlib для машинного обучения, GraphX для обработки графиков и потоковую передачу.
Интернет вещей
Интернет вещей (IoT) – это растущий источник больших данных. IoT – это концепция, позволяющая осуществлять интернет-коммуникацию между физическими объектами, датчиками и контроллерами.
Машинное Обучение
Машинное обучение может быть использовано для прогностического анализа и распознавания образов в больших данных. Машинное обучение является междисциплинарным по своей природе и использует методы из области компьютерных наук, статистики и искусственного интеллекта. Основными артефактами исследования машинного обучения являются алгоритмы, которые облегчают автоматическое улучшение на основе опыта и могут быть применены в таких разнообразных областях, как компьютерное зрение и интеллектуальный анализ данных.
Интеллектуальный Анализ Данных
Интеллектуальный анализ данных – это применение специфических алгоритмов для извлечения паттернов из данных. В интеллектуальном анализе акцент делается на применении алгоритмов в ходе которых машинное обучение используются в качестве инструмента для извлечения потенциально ценных паттернов, содержащихся в наборах данных.
Где применяются большие данные
Аналитика больших данных применяется в самых разных областях. Перечислим некоторые из них:
- Поставщикам медицинских услуг аналитика больших данных нужна для отслеживания и оптимизации потока пациентов, отслеживания использования оборудования и лекарств, организации информации о пациентах и т. д.
- Туристические компании применяют методы анализа больших данных для оптимизации опыта покупок по различным каналам. Они также изучают потребительские предпочтения и желания, находят корреляцию между текущими продажами и последующим просмотром, что позволяет оптимизировать конверсии.
- Игровая индустрия использует BigData, чтобы получить информацию о таких вещах, как симпатии, антипатии, отношения пользователей и т. д.
Если вы хотите освоить новую профессию или повысить квалификацию в сфере Big Data, стоит обратить внимание на курс факультета аналитики Big Data онлайн-университета GeekBrains . Программа включает основательную математическую подготовку, изучение языка Python и получение навыков практической работы с базами данных. Также изучаются Hadoop и Apache Spark – востребованные инструменты для работы с большими данными. Курс ориентирован на применение машинного обучения в бизнесе и построен по принципам практической работы над проектами с ведущими специалистами отрасли и личным помощником-куратором.
Читайте также: