
Защита оперативной памяти linux
Я уверен, что каждый пользователь в своей жизни хоть раз сталкивался с явлением переполнения оперативной памяти или OOM (Out Of Memory). Все помнят как это происходит: система встаёт раком колом, ядро начинает грузить свопом жёсткий диск на 100%, хорошо если можно хоть курсором двигать, хотя это уже делу не поможет. В этом случае помогает только перезагрузка. А ведь мы же только Libre Office с Chromium на 2 ГБ ОЗУ запустили! Не понятно, почему ядро Linux так плохо справляется с переполнением оперативки, но с этим явлением можно успешно бороться своими силами и при минимуме накладных затрат.
В борьбе с явлением OOM нам поможет Nohang — демон для GNU/Linux, предотвращающий наступление явления переполнения оперативной памяти устройства путём принудительного завершения «прожорливого» процесса.
Проверка
Проверяем состояние демона Nohang:
Статус работы должен быть указан зелёным цветом:
Если так — Nohang запущен и работает нормально, можно приступать к экспериментам.
Сохраняем все несохранённые данные во всех приложениях, делаем резервные копии важных данных!
Это я на всякий случай 😏 Что ж, инициируем процесс накачки оперативной памяти пустыми данными:
И смотрим что из этого получится 😀 По идее, вы можете почувтвовать непродолжительный дискомфорт, проявляющийся в зависании системы на несколько секунд, после чего Nohang должен отработать по tail и управление системы вернётся в ваши руки. А точнее, скорее всего так и произойдёт, что можно будет считать успешным достижением поставленной цели.
Эта статья — частичный перевод исчерпывающего руководства Дэвида Хоуэлса (David Howells) и Пола Маккени (Paul E. McKenney) распространяемого в составе документации Linux (Documentation/memory-barriers.txt онлайн версия).
Must read для разработчиков ядра/драйверов и очень познавательно для прикладных программистов.
Arch Linux, Manjaro Linux
Составляющие приватности
Опытный хакер-линуксоид самостоятельно сделает операционку под свои нужды, нафарширует ее любимыми инструментами и зашифрует каждый бит. Однако это займет уйму времени, а потому данный способ подходит лишь самым красноглазым. Для всех остальных есть готовые варианты, в которых уже продуманы тысячи мелочей, собраны и настроены проверенные средства защиты приватности.
При внешнем разнообразии эти дистрибутивы имеют много общих черт, поскольку сохранение тайны личной жизни построено на одинаковых подходах. Обеспечение приватности состоит из следующих этапов, которые решаются на локальном и сетевом уровне:
- гарантированное удаление следов работы и любых уникальных (а значит — потенциально компрометирующих) данных, использованных во время сеанса;
- шифрование тех данных, которые нужно сохранить (например, электронные кошельки, документы, аудиовидеозаписи, прочие личные файлы и конфиги);
- сокрытие самого факта хранения зашифрованных данных (методами стеганографии и их маскировкой среди более заметных криптоконтейнеров, заведомо не содержащих ценной информации);
- изоляция приложений и выделение некоторых сервисов в отдельные виртуальные машины (sandbox, Xen, VirtualBox и другие средства виртуализации) для снижения вероятности деанонимизации при заражении трояном;
- патчи ядра для усиленного контроля за взаимодействием процессов и сведения к минимуму риска деанонимизации через эксплоиты;
- средства экстренного завершения работы ОС с быстрым удалением наиболее компрометирующих данных на случай угрозы физического изъятия загрузочного накопителя;
- ранняя подмена MAC-адреса сетевых устройств (обычно она происходит еще на этапе загрузки);
- предотвращение раскрытия IP-адреса (контроль состояния VPN, anti DNS leak, фильтрация скриптов, использование цепочки прокси-серверов с высокой анонимностью, проксирование трафика всех приложений через Tor и т. п.);
- реализация анонимных каналов связи (чаты, почта, обмен файлами);
- обход региональных блокировок (автоматическая настройка использования публичных DNS-серверов, бесплатных VPN, быстрых прокси, Tor, I2P, Freenet).
Разумеется, каждый конкретный дистрибутив имеет свои ограничения и не предоставляет все перечисленные выше инструменты в одной сборке, но это и не требуется на практике. Многие пункты в данном списке дублируют функциональность друг друга либо вовсе взаимоисключающи.
Мы не будем рассуждать о человеческом факторе, который сводит на нет надежность любой системы. Ограничимся техническими аспектами и просто напомним, что не существует средств, полностью запрещающих людям совершать ошибки.
MOFO Linux
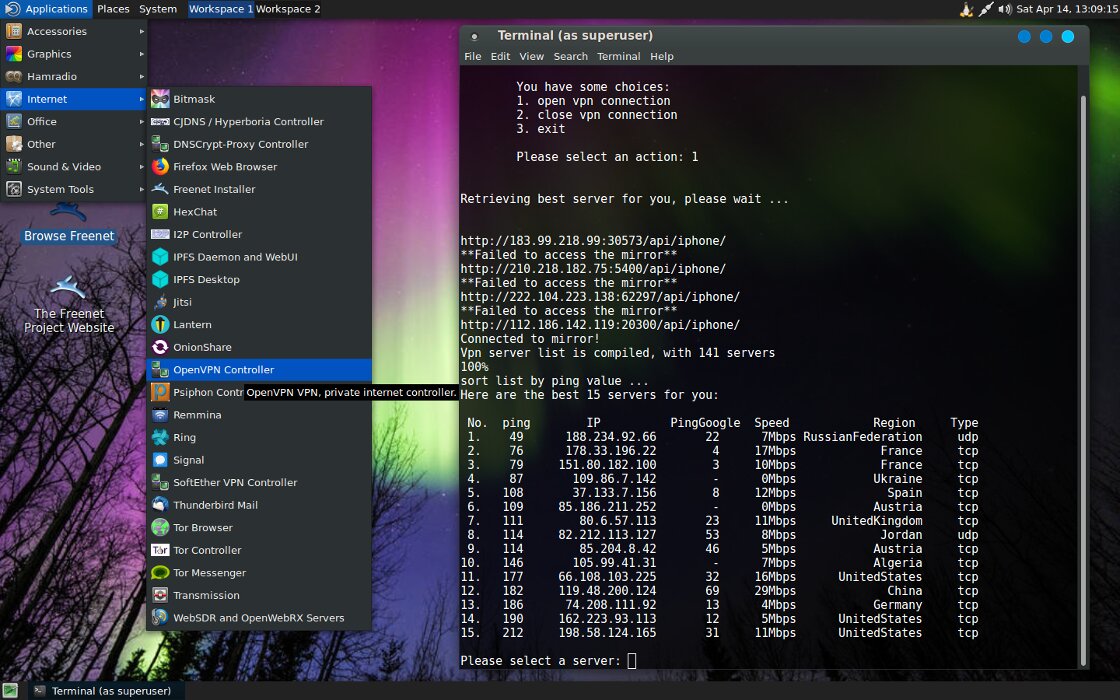
Настройка OpenVPN
Помимо Tor и VPN, MOFO поддерживает I2P плюс Lantern и Psiphon, как шустрые прокси. Правда, сейчас Psiphon глючит, а у Lantern без ограничения скорости на бесплатном тарифе доступно только 500 Мбайт в месяц, но всегда можно купить платный аккаунт.
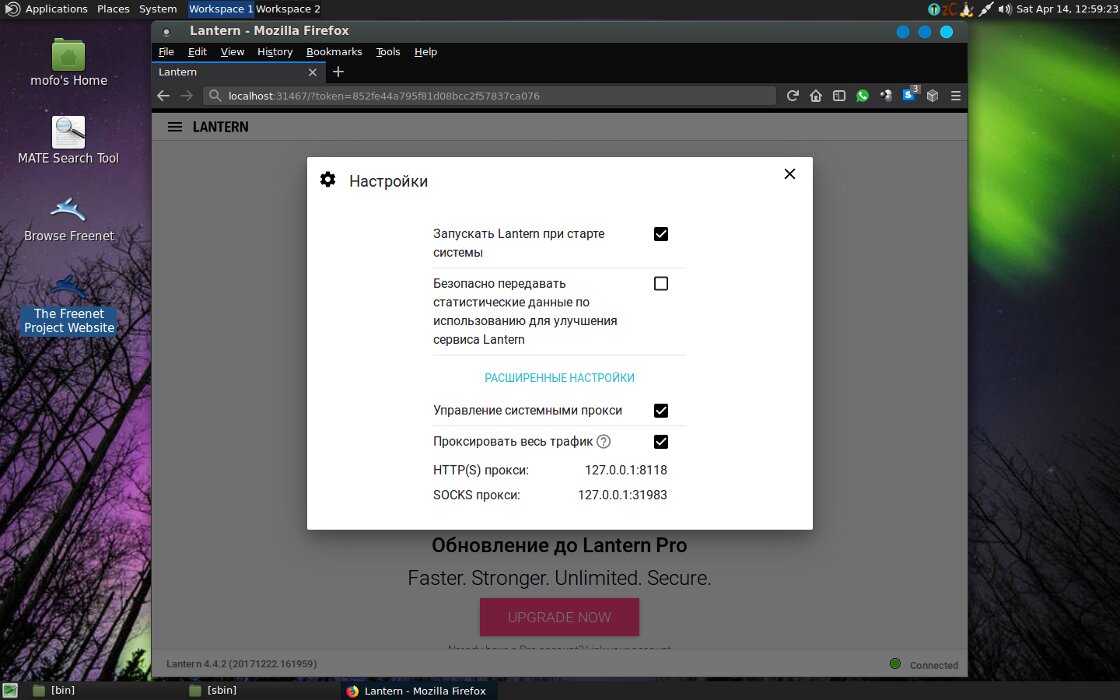
Lantern в MOFO
Прямо из графического меню в пару кликов устанавливается клиент Freenet — одноранговой анонимной сети с распределенным хранением зашифрованных данных. В ней есть свои сайты и форумы, которые практически невозможно цензурировать.
В MOFO добавлена ссылка на установку пакета поддержки распределенной файловой системы IPFS (Interplanetary File System), созданной на основе технологий P2P. Благодаря IPFS можно расшаривать локальные файлы и создавать сайты, которые не исчезнут из-за блокировок (об IPFS мы тоже уже писали). MOFO также поддерживает сетевой протокол Cjdns. С его помощью можно создать виртуальную IPv6-сеть с шифрованием трафика.
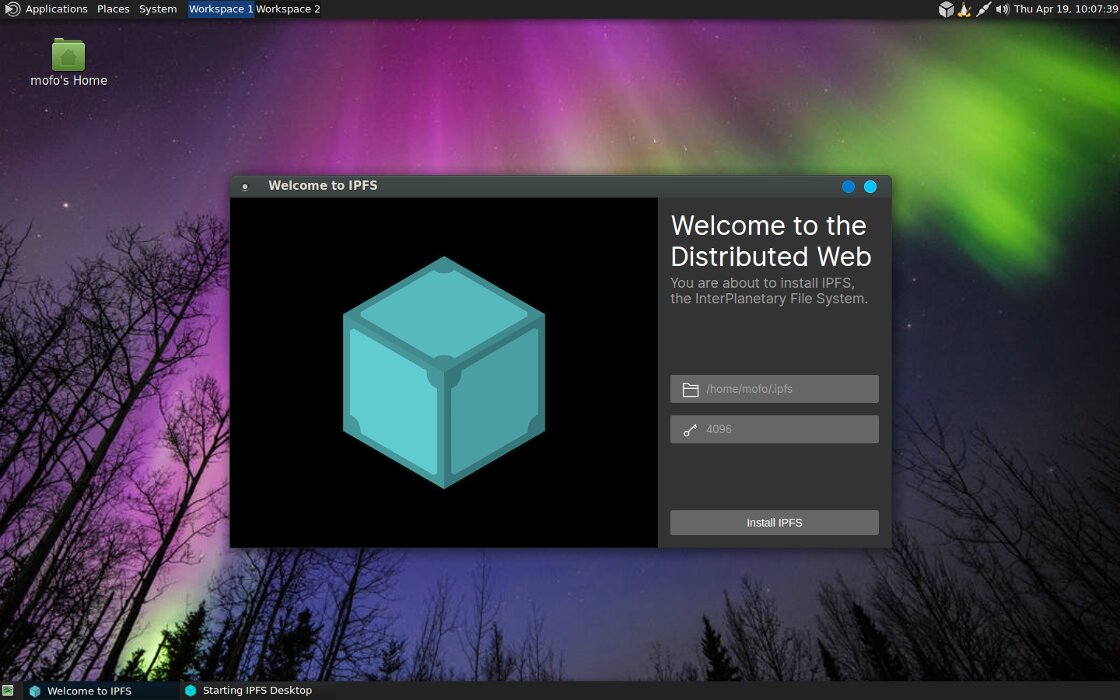
Установка IPFS
Криптографическую защиту личных данных в MOFO обеспечивает eCryptfs — многоуровневая файловая система с шифрованием на лету. Она работает поверх существующей ФС (ext3, ext4 или XFS) и не требует создания специального раздела.
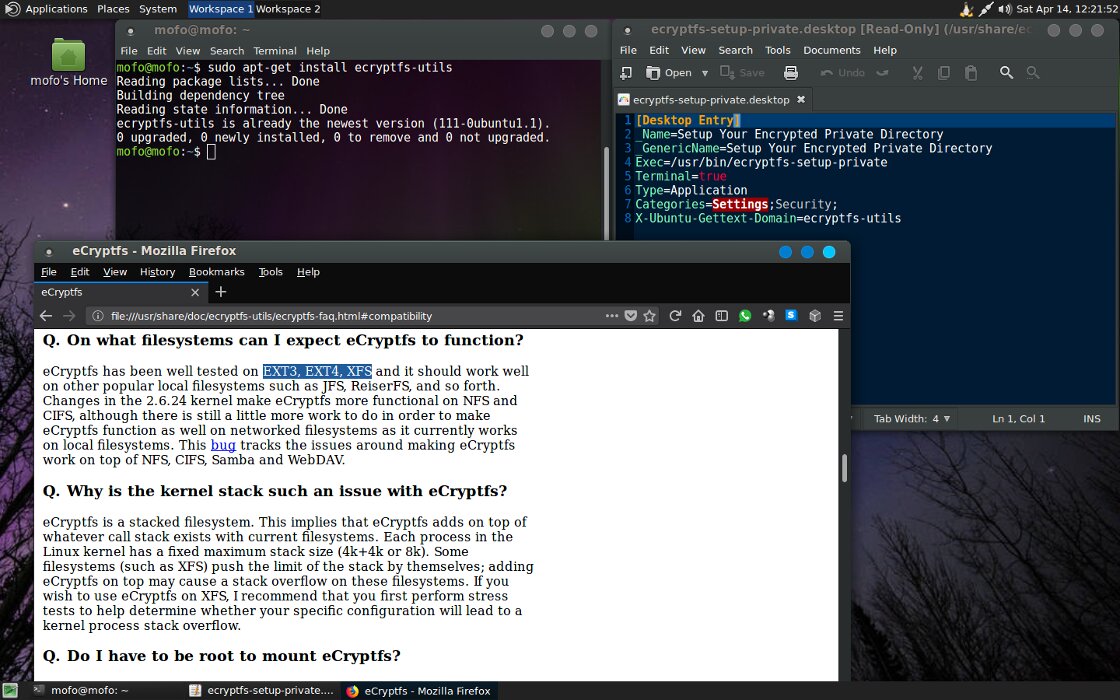
Включаем шифрование
Дополнительно в MOFO предустановлена утилита ZuluCrypt с поддержкой формата криптоконтейнеров TrueCrypt и VeraCrypt.
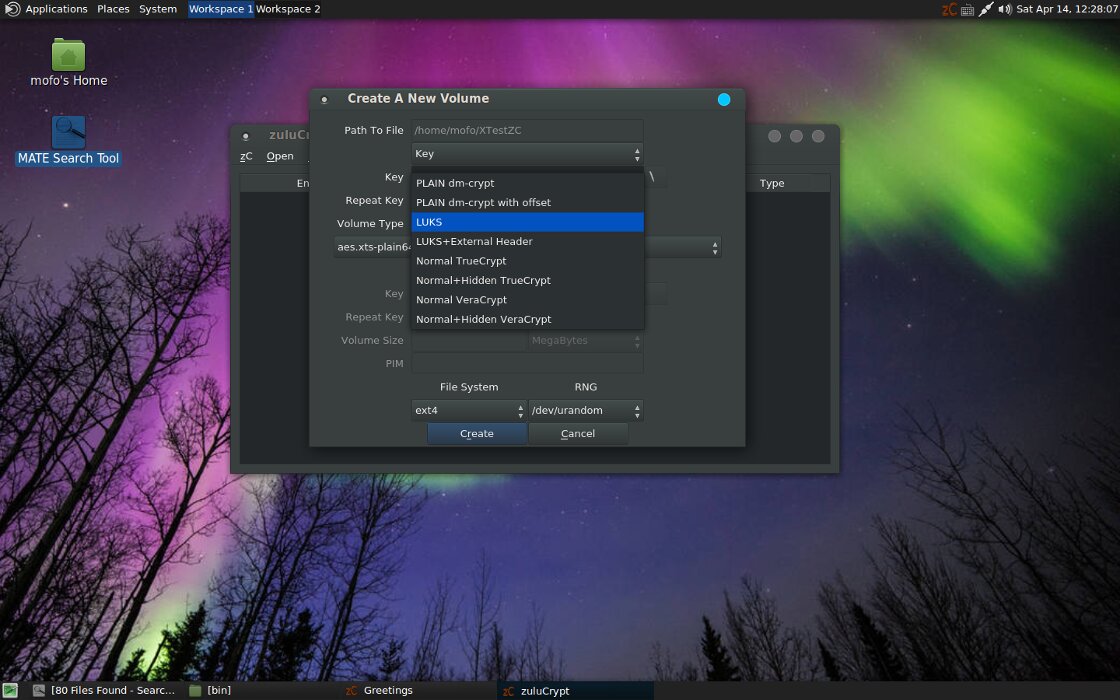
ZuluCrypt — варианты зашифрованных томов
На момент тестирования была доступна версия mofolinux-6.0 от 18 февраля 2018 года. По умолчанию пароль администратора не задан.
Принцип работы
Nohang в виде демона постоянно находится в оперативной памяти устройства (потребляет ~10 Мб ОЗУ) и следит за свободным количеством оперативной памяти и своп-раздела. Как только наступает условие явной нехватки ОЗУ и свопа (эти параметры указываются в конфигурационном файле приложения) Nohang принудительно завершает «жирное» приложение, вызвавшее нехватку оперативной памяти устройства.
В качестве примера — скриншот окна монитора ресурсов KDE, на котором отображена работа демона Nohang.
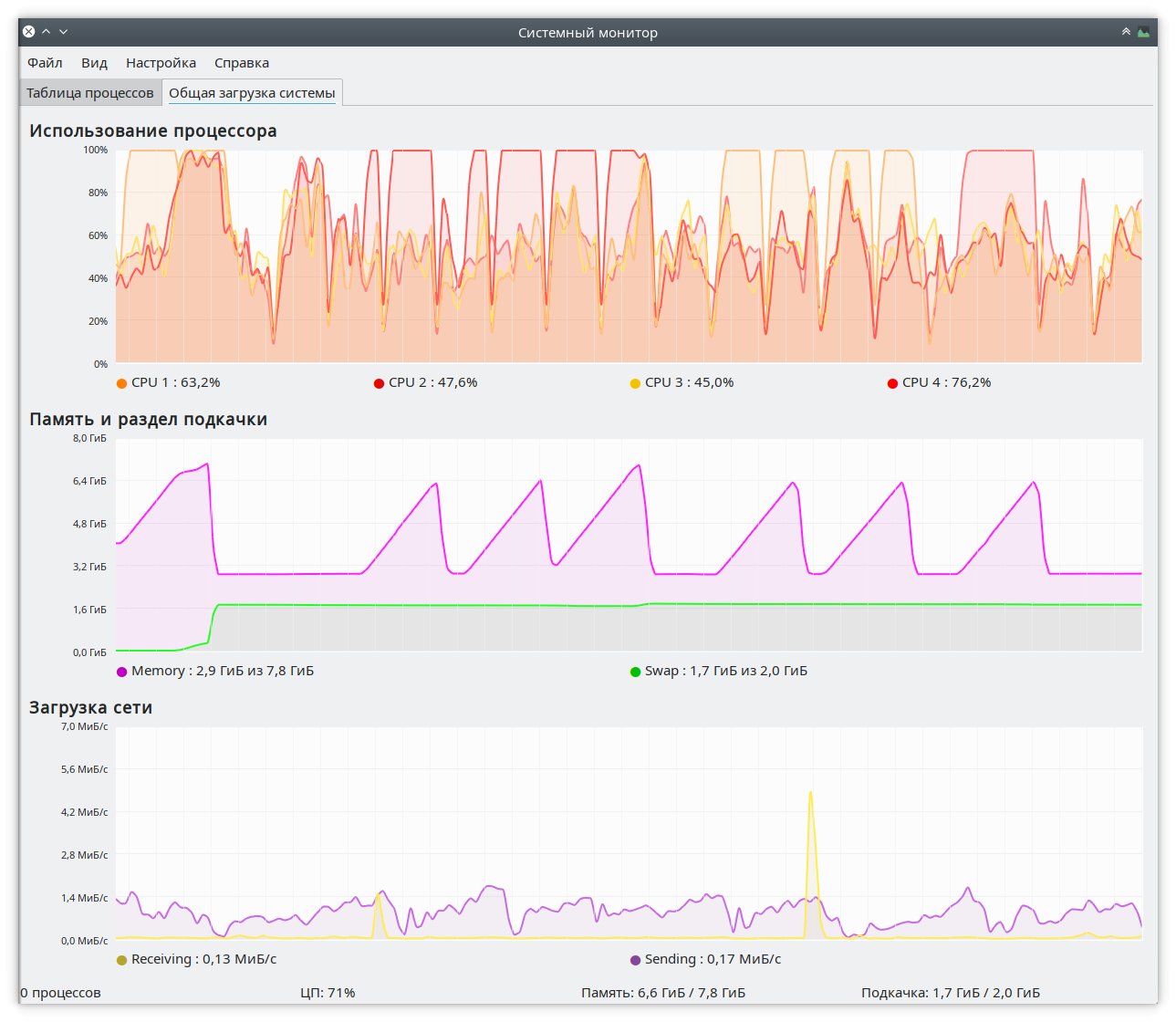
Наглядная демонстрация работы Nohang по предотвращению переполнения ОЗУ
На среднем графике видны факты наступления состояния OOM (переполнения памяти) ОЗУ компьютера, на котором производился эксперимент. Оперативная память накачивалась бесполезными пустыми данными с помощью команды:
Осторожно! Выполнение данной команды может привести (и без установленных утилит вроде Nohang — 100% приведёт) к переполнению оперативной памяти устройства и его зависанию, сколько бы ОЗУ в нём не было установлено!
Как видно, после первой попытки своп заполнился на 100% (в качестве свопа использовался раздел zRam) так же, как и ОЗУ, после чего Nohang прибивает процесс tail и оперативная память снова освобождается, возвращаясь к значению свободного места, которое имела до начала эксперимента. Интересно то, что своп остаётся заполненным практически на 100%, но при следующих попытках исчерпать всю доступную ОЗУ это не приводит к зависанию всей системы, и Nohang снова завершает прожорливый процесс tail, освобождаю ОЗУ. По субъективным ощущениям для пользователя, происходит кратковременное подтормаживание системы на пару секунд, после чего контроль над системой возвращается без каких-либо проблем. В общем — сказка!
Установка Nohang в различных дистрибутивах Linux
Так как не все, как я, используют в своей работе Arch Linux, рассмотрим процесс установки Nohang для всех самых популярных дистрибутивов.
Продолжение доступно только участникам
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Вариант 2. Открой один материал
Явные барьеры в ядре.
- Барьеры компилятора.
- Барьеры процессора.
- Барьеры записи в области ввода/вывода отображённые в память (MMIO).
Явный барьер компилятора предотвращает перемещение операций доступа к памяти компилятором с одной стороны барьера на другую:
Это единственный барьер уровня компилятора.
Барьер компилятора не оказывает никакого эффекта на поведение процессора, который может переупорядочивать операции доступа к памяти по своему усмотрению.
Следующие 8 функций представляют собой барьеры процессора в Linux:
Все барьеры уровня процессора, за исключением барьера зависимости по данным, включают в себя барьер компилятора.
Замечание: в случае зависимости по данным можно было бы ожидаеть, что компилятор организует инструкции чтения в правильном порядке (например, a[b] сначала прочтёт значение b, а потом — a[b]), однако стандарт языка С не даёт такой гарантии.
При компиляции однопроцессорного ядра, SMP-версии барьеров превращаются в барьеры компилятора, потому что один процессор всегда наблюдает собственные операции с памятью в правильном порядке.
Замечание: SMP-барьеры должны использоваться для управления порядком операций с разделяемой памятью в SMP-системах, но на деле достаточно использования блокирующих примитивов синхронизации.
Безусловные барьеры не следует использовать для управления эффектами SMP, поскольку это приводит к снижению производительности на однопроцессорных системах. Их основная область использования — упорядочивание операций доступа к устройствам ввода/вывода отображаемым в память.
Следующая функция представляет собой барьер записи в область ввода/вывода отображённого в память:
Эта функция является вариантом обязательного барьера записи и обеспечивает частичное упорядочивание операций записи в регион MMIO. Её эффект может простираться вглубь за границу интерфейса между процессором и подсистемой памяти.
WARNING
Длительная и полная анонимность практически недостижима на практике. Более того, настойчивые попытки ее добиться гарантированно привлекут к тебе внимание. Подробнее см. проект XKeyscore. О нем и его наследии в NSA и GCHQ можно почитать на onion-ресурсах.
Debian GNU/Linux, Ubuntu, Linux Mint
Устанавливаем из Github:
Если уведомления на рабочем столе не нужны, заменяем «sudo make install-desktop» на «sudo make install»
Эффекты процессорного кеша.
То, как операции над кешируемой памятью наблюдаются компонентами системы во многом зависит от кеша, расположенного между процессором и памятью и системы поддержания его когерентности.
С точки зрения рассматриваемых барьеров доступа к памяти, процессорный кеш и система поддержания его когерентности являются частью системной памяти; эффект барьеров доступа к памяти проявляется на границе, изображённой пунктирной линией на диаграмме:
Хотя операции обращения к памяти могут быть выполнены процессором без обращения ко внешней шине, например из кеша, для остальных процессоров системой поддержки когерентности кеша по-прежнему поддерживается видимость того, что межпроцессорное взаимодействие происходит через внешнюю память, посредством миграции строк кеша к которым осуществляется доступ.
Процессорное ядро выполняет инструкции в том порядке, который ему удобен, гарантируя при этом сохранение причинно-следственных связей в выполняемой программе. Некоторые инструкции генерируют запросы чтения или записи, которые помещаются в очередь запросов к подсистеме памяти. Процессорное ядро помещает их в очередь в подходящем порядке и продолжает выполнение, до тех пор пока ему не понадобится получить результат какой-либо из этих инструкций.
Барьеры доступа к памяти контролируют порядок, в котором запросы переходят со стороны процессора на сторону памяти, а так же наблюдаемость эффектов операций, производимых над памятью другими компонентами системы.
2020 год. Повсюду карантин. И эта статья тоже про карантин, но он другого рода.
Я расскажу об экспериментах с карантином для динамической памяти ядра Linux. Это механизм безопасности, противодействующий использованию памяти после освобождения (use-after-free или UAF) в ядре Linux. Я также подведу итоги обсуждения моей патч-серии в списке рассылки ядра (Linux Kernel Mailing List, LKML).

UAF в ядре Linux — очень популярный для эксплуатации тип уязвимостей. Есть множество публичных прототипов ядерных эксплойтов для UAF:
Для эксплуатации UAF обычно применяется техника heap spraying. Цель данной техники — разместить данные, контролируемые атакующим, в определенном участке динамической памяти, которая также называется «кучей». Техника heap spraying для эксплуатации UAF в ядре Linux основана на том, что при вызове kmalloc() slab-аллокатор возвращает адрес участка памяти, который был недавно освобожден:

То есть создание другого ядерного объекта такого же размера с контролируемым содержимым позволяет переписать освобожденный уязвимый объект:

Примечание: heap spraying для эксплуатации переполнения буфера в куче — отдельная техника, которая работает иначе.
В июле 2020 года у меня возникла идея, как можно противостоять технике heap spraying для эксплуатации UAF в ядре Linux. В августе я нашел время поэкспериментировать. Я выделил карантин для slab-аллокатора из функциональности KASAN и назвал его SLAB_QUARANTINE .
При активации этого механизма освобожденные аллокации размещаются в карантинной очереди, где ожидают реального освобождения. Поэтому они не могут быть мгновенно реаллоцированы и переписаны эксплойтами UAF. То есть при активации SLAB_QUARANTINE аллокатор ядра ведет себя следующим образом:
13 августа я отправил первый ранний прототип карантина в LKML и начал более глубокое исследование параметров безопасности этого механизма.
Для исследования свойств безопасности карантина для динамической памяти ядра я разработал два теста lkdtm (опубликованы в серии патчей).
Первый тест называется lkdtm_HEAP_SPRAY . Он выделяет и освобождает один объект из отдельного kmem_cache , а затем выделяет 400 000 аналогичных объектов. Другими словами, этот тест имитирует оригинальную технику heap spraying для эксплуатации UAF:
Если отключить CONFIG_SLAB_QUARANTINE , освобожденный объект немедленно реаллоцируется и переписывается:
Если включить CONFIG_SLAB_QUARANTINE , 400 000 новых аллокаций не переписывают освобожденный объект:
Это происходит из-за того, что для прохождения объекта через карантин требуется и выделение, и освобождения памяти. Объекты выпускаются из карантина, когда выделяется новая память, но только если карантин превысил свой предельный размер. А размер карантина увеличивается при освобождении памяти.
Поэтому я разработал второй тест под названием lkdtm_PUSH_THROUGH_QUARANTINE . Он выделяет и освобождает один объект из отдельного kmem_cache и затем выполняет kmem_cache_alloc()+kmem_cache_free() для этого кэша 400 000 раз.
При этом тесте объект проходит через карантин и реаллоцируется после своего возвращения в список свободных объектов аллокатора:
Как можно заметить, количество аллокаций, необходимых для переписывания уязвимого объекта, почти не изменяется. Это плохо для защиты и хорошо для атакующего, поскольку дает возможность для стабильного обхода карантина за счет более длительного спрея. Поэтому я разработал рандомизацию карантина. В сущности это небольшая хитроумная доработка во внутреннем механизме работы с карантинной очередью.
В карантине объекты хранятся в «пачках». Рандомизация работает так: сначала все пачки наполняются ядерными объектами. А потом, когда карантин превысил предельный размер и должен выпустить лишние объекты, выбирается произвольная пачка, из которой освобождается примерно половина всех ядерных объектов, которые тоже выбираются произвольно. Теперь карантин отпускает освобожденный объект в непредсказуемый момент:
Однако такая рандомизация сама по себе не предотвратит эксплуатацию: объекты в карантине содержат данные атакующего (полезную нагрузку эксплойта). Это значит, что целевой объект ядра, реаллоцированный и переписанный спреем, будет содержать данные атакующего до следующей реаллокации (очень плохо).
Поэтому важно очищать объекты ядерной кучи до помещения их в карантин. Более того, заполнение их нулями в некоторых случаях позволяет обнаружить использование памяти после освобождения: происходит разыменование нулевого указателя. Такой функционал уже существует в ядре и называется init_on_free . Я интегрировал его с CONFIG_SLAB_QUARANTINE .
В ходе этой работы я обнаружил ошибку в ядре: в CONFIG_SLAB функция init_on_free осуществляется слишком поздно, и ядерные объекты отправляются на карантин без очистки. Я подготовил исправление в отдельном патче (принят в mainline).
Для более глубокого понимания того, как работает CONFIG_SLAB_QUARANTINE с рандомизацией, я подготовил дополнительный патч, с подробным отладочным выводом (патч не для принятия в mainline). Пример такого отладочного вывода:
Операция PUT осуществляется в ходе освобождения ядерной памяти. Операция REDUCE осуществляется в ходе выделения ядерной памяти, когда превышен размер карантина. Объекты ядра, выпущенные из карантина, возвращаются в список свободных объектов аллокатора. Также в этом выводе можно видеть, что при осуществлении операции REDUCE карантин отпускает часть объектов из произвольно выбранной пачки.
Я провел несколько тестов производительности моего прототипа на реальном оборудовании и на виртуальных машинах:
- Тестирование пропускной способности сети с помощью iperf :
сервер: iperf -s -f K
клиент: iperf -c 127.0.0.1 -t 60 -f K - Нагрузочный тест ядерного планировщика задач:
hackbench -s 4000 -l 500 -g 15 -f 25 -P - Сборка ядра в конфигурации по умолчанию:
time make -j2
Я тестировал ванильное ядро Linux в трех режимах:
- init_on_free=off
- init_on_free=on (механизм из официального ядра)
- CONFIG_SLAB_QUARANTINE=y (включает в себя init_on_free )
Тестирование пропускной способности сети с помощью iperf показало, что:
- init_on_free=on дает пропускную способность на 28% ниже, чем init_on_free=off .
- CONFIG_SLAB_QUARANTINE дает пропускную способность на 2% ниже, чем init_on_free=on .
Нагрузочный тест ядерного планировщика задач:
- hackbench работает на 5,3% медленнее с init_on_free=on по сравнению с init_on_free=off .
- hackbench работает на 91,7% медленнее с CONFIG_SLAB_QUARANTINE по сравнению с init_on_free=on . При этом тестирование на виртуальной машине QEMU/KVM показало снижение производительности на 44%, что существенно отличается от результатов тестирования на реальном оборудовании (Intel Core i7-6500U CPU).
Сборка ядра в конфигурации по умолчанию:
- При init_on_free=on сборка ядра осуществлялась на 1,7% медленнее, чем с init_on_free=off .
- При CONFIG_SLAB_QUARANTINE сборка ядра осуществлялась на 1,1% медленнее, чем с init_on_free=on .
Как вы можете видеть, результаты тестов сильно варьируются и зависят от типа рабочей нагрузки.
Примечание: для этой версии прототипа карантина НЕ проводилась оптимизация производительности. Моей главной задачей было исследование свойств безопасности механизма. Я решил, что оптимизацией производительности лучше заняться позже, если станет ясно, что идея удачная.
В LKML получилось интересное обсуждение CONFIG_SLAB_QUARANTINE . Спасибо разработчикам ядра, которые уделили время и дали детальную обратную связь на мою серию патчей. Это Кейс Кук (Kees Cook), Андрей Коновалов, Александр Потапенко, Мэттью Уилкокс (Matthew Wilcox), Дэниел Майкей (Daniel Micay), Кристофер Ламетер (Christopher Lameter), Павел Мачек (Pavel Machek) и Эрик Бидерман (Eric W. Biederman).
Особенно я благодарен Яну Хорну (Jann Horn) из команды Google Project Zero. Он придумал контратаку, с помощью которой все-таки удается обойти CONFIG_SLAB_QUARANTINE и проэксплуатировать UAF в ядре Linux.
Примечательно, что наша дискуссия с Яном состоялась одновременно со стримом Кейса в Twitch, в ходе которого он тестировал мои патчи (рекомендую посмотреть запись).
Цитата из переписки с идеей контратаки:
То есть атакующий может воспользоваться другим slab-кэшем в ядерном аллокаторе, выделить и освободить в нем большое количество объектов, что приведет к вытеснению целевого объекта из карантина обратно в список свободных объектов. После этого атакующий может воспользоваться стандартной техникой heap spraying для эксплуатации UAF.
Я сразу поделился этой перепиской в чате стрима Кейса в Twitch. Он доработал мой тест PUSH_THROUGH_QUARANTINE по идее Яна и выполнил атаку. Бабах!
Очень советую прочитать эту переписку в LKML целиком. Там обсуждаются новые идеи противодействия эксплуатации UAF в ядре.
Я исследовал свойства безопасности карантина для динамической памяти ядра Linux, провел эксперименты, показывающие его влияние на эксплуатацию уязвимостей use-after-free. Получился быстрый и интересный проект. Надежное средство защиты, примененное в mainline, создать не удалось, но мы получили полезные результаты и идеи, которые пригодятся в дальнейших работах по защите ядра Linux.
А пока что позвольте закончить небольшим стихотворением, которое пришло мне в голову перед сном:
Нужно занять всю свободную память (на самом деле нет, всего лишь 90%), чтобы другие утилиты не могли аллоцировать ни чего. Нужно для проверки всяких там ватчдоков.
Но calloc\malloc я так понимаю аллоцируют только в куче? А как отжать физическую память?

полижи файл в tmpfs и отключи своп заранее

Запусти хром и наоткрывай вкладок
Хм, хорошая идея:
Т.е. в /run можно кинуть?
Это pokky linux embedded


Форк-бомбу уже предлагали?
Для этого есть более подходящие языки :D
Куча вообще-то тоже размещается в физической памяти. malloc вместе с memset - это собственно оно, но конечно система будет сопротивляться.
Но calloc\malloc я так понимаю аллоцируют только в куче? А как отжать физическую память?
man 2 mlock
DESCRIPTION mlock(), mlock2(), and mlockall() lock part or all of the calling process's virtual address space into RAM, preventing that memory from being paged to the swap area.
Вариант с tmpfs рабочий, мы так делали (swap был отключен). Только «чтобы другие утилиты не могли аллоцировать ни чего» - с нахрапа не получится. Независимо от количества свободной памяти, ядро с дефолтными настройками все равно даст аллоцировать новую память; а если ее не будет - будет прибивать другие процессы - см. OOM killer и overcommit_memory.
Kroz ★★★★★ ( 12.10.18 14:41:19 )
Последнее исправление: Kroz 12.10.18 14:42:28 (всего исправлений: 3)

Напиши hello world на java.
А cgroups под эти ваши embeded не завезли?
А cgroups под эти ваши embeded не завезли?
Там почти всё выпилили, так что маловероятно
Сделай вдоль, маленький мамкин какер.
Тут непринципиально. А так да.
Но calloc\malloc я так понимаю аллоцируют только в куче? А как отжать физическую память?
Запиши в то что вернул маллос мусора, выделятся физические страницы.
Сделай вдоль, маленький мамкин какер.
Соси аноним, с вероятностью в 99% по старше тебя буду.
Займись этим разрешаю

для проверки «ватчдоков» проще сделать юзера, у которого лимит на память, и под ним запускать.
Ну я с этой проблемой раньше не сталкивался, а гуглиться только всяческая хреномуть. Учту в будущем, но пока /tmpfs вполне хватило.
яваскриптер пытается писать на сях?
Ты ошибся, но вопреки стандарту я бы его вообще везде писал при завершении инструкции/конструкции.
Точка запятой явно указывает на завершение инструкции/конструкции. Является не обязательным в ряде случаев, но необязательность это не нарушение или ненужность,а возможность. Так то можно и структуры по сути писать без семиколона, но нельзя. Семиколон явность, ставить его или нет вопрос удобства/необходимости , а не чего либо ещё.
Deleted ( 12.10.18 19:01:36 )
Последнее исправление: Deleted 12.10.18 19:01:52 (всего исправлений: 1)

Нужно занять всю свободную память (на самом деле нет, всего лишь 90%), чтобы другие утилиты не могли аллоцировать ни чего.
Зачем забивать всю память, просто установи лимиты памяти для нужны процессов например с помощью cgroups.

Точка запятой явно указывает на завершение инструкции/конструкции
точка с запятой это лишний такт процессора который впустую потратиться(дада не надо тут про копиляторы оптимиирующие, и что Си уже по факту джаваскрипт обрезанный, без стандартов)
всеже это попрежнему актуально в 2018 если пишешь даже под 1ггц армы, или другие архитектуры где компилятор еще соблюдает стандарты
ощутимо будет наличие ; после блока <> и ее отсутствие
Но calloc\malloc я так понимаю аллоцируют только в куче? А как отжать физическую память?
Выделить и записать туда что-нибудь, например, нули. Только это плохой совет!
Соси аноним, с вероятностью в 99% по старше тебя буду.
Ты же толстишь, да?
для проверки «ватчдоков» проще сделать юзера, у которого лимит на память, и под ним запускать.
это не просто проще, это самое правильное..ограничения по ресурсам ставятся лимитами.
и это должно было быть предложено в первых двух постах (куда катиться этот сраный мир/лор..)
во времена зелёной травы и синего неба, ядру можно было прямо указать сколько физ.памяти можно заюзать под самоё себя и подо всякое в юзерспейсах. Очень-очень давно не проверял, но боюсь что со всякими виртуализациями эта фича похерена.
PS/ кстати про виртуалки :-) если нужны стресс-тесты - то можно (да пожалуй и нужно) обрезать на их уровне. Тут уж ядро ну никак не выкрутится из общих лимитов.
MKuznetsov ★★★★★ ( 12.10.18 22:32:01 )
Последнее исправление: MKuznetsov 12.10.18 22:38:38 (всего исправлений: 3)
просто сейчас мало кто тестирует приложения на лимиты. считается, что память бесконечна, как и карманы юзера, который может купить и проц помощнее :)
виртуалки с ограниченным ресурсом тоже хорошая идея, но протаскивание железа в виртуалки может оказаться проблемой.
я бы предложил написать прогу на java, которая имитирует саму себя и пишет хелло-ворлды. Вот тогда не 90, а все 190% озу будут заняты

Возможно, ты уже пользовался дистрибутивом Tails или даже запускаешь его ежедневно. Но это не единственная операционка, способная скрыть твое присутствие в сети и помогающая обойти региональные блокировки. В этой статье мы изучим пять конкурентов Tails, каждый — со своими интересными особенностями.
Kodachi
В прошлом выпуске мы разбирали дистрибутивы для форензики, а Kodachi позиционируется как anti-forensic-разработка, затрудняющая криминалистический анализ твоих накопителей и оперативной памяти. Технически это еще один форк Debian, ориентированный на приватность. В чем-то он даже более продуман, чем популярный Tails.
Последняя стабильная версия Kodachi 3.7 была написана в январе прошлого года. Операционка родом из Омана (где с интернет-цензурой знакомы не понаслышке), что добавляет ей колорита.
В качестве среды рабочего стола для Kodachi была выбрана Xfce, а общий интерфейс операционки стилизован под macOS. Статус подключения к Tor и VPN, а также большинство текущих параметров загрузки системы выводятся в режиме реального времени и отображаются прямо на рабочем столе.

Графический интерфейс Kodachi
Среди ключевых особенностей Kodachi — принудительное туннелирование трафика через Tor и VPN, причем бесплатный VPN уже настроен.
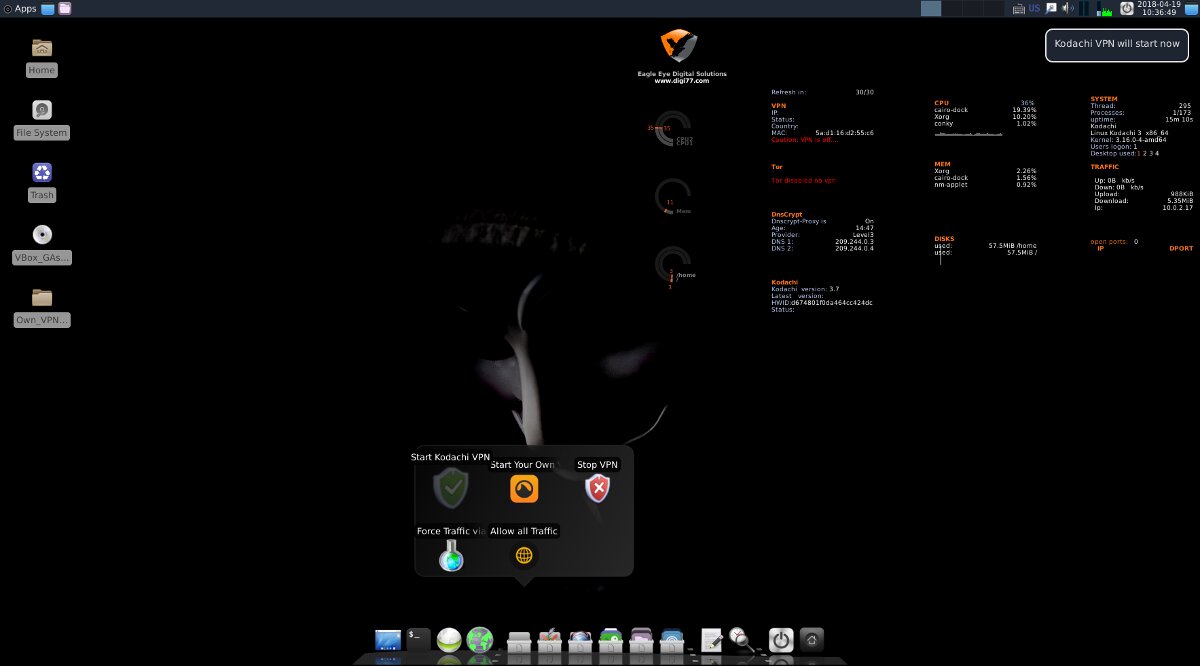
Запуск Kodachi VPN
Плюс в Kodachi интегрирована поддержка DNScrypt — это протокол и одноименная утилита, шифрующая запросы к серверам OpenDNS методами эллиптической криптографии. Она устраняет целый ряд типичных проблем, вроде DNS leak и оставления следов работы в сети на серверах провайдера.
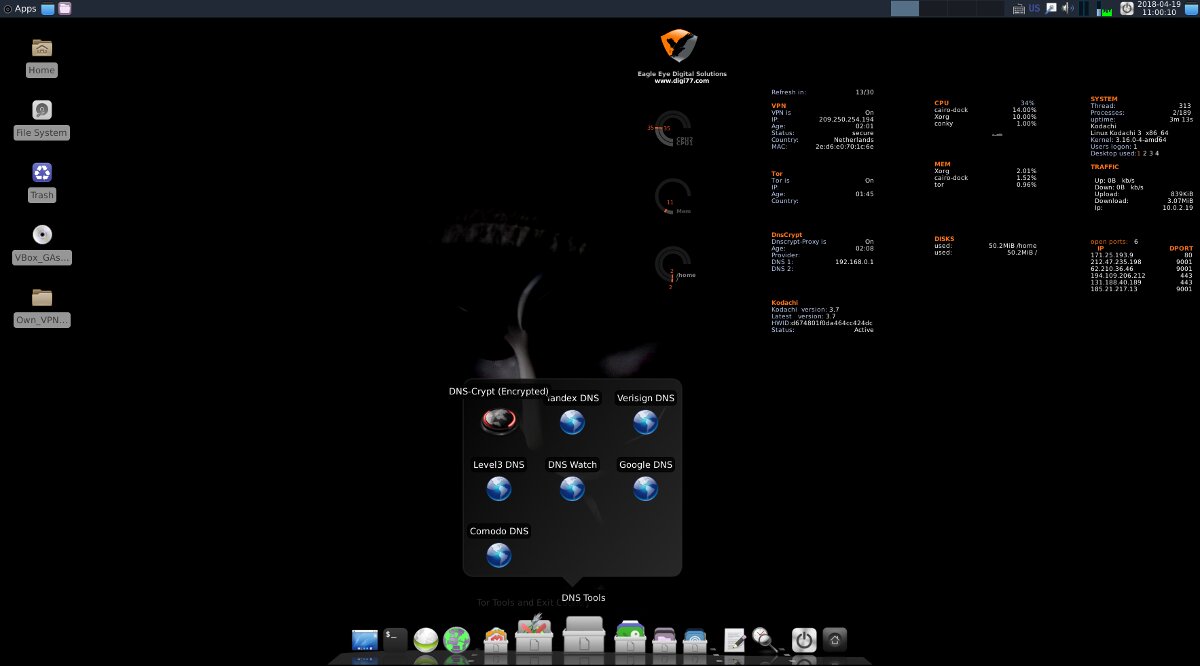
Kodachi DNS tools
Другое отличие Kodachi — интегрированный Multi Tor для быстрой смены выходных узлов с выбором определенной страны и PeerGuardian для сокрытия своего IP-адреса в Р2Р-сетях (а также блокировки сетевых узлов из длинного черного списка).
Помимо PeerGuardian, в качестве брандмауэра используется Uncomplicated Firewall (uwf) с графической оболочкой guwf .
Приложения в Kodachi легко изолировать при помощи встроенной песочницы Firejail (о ней мы уже рассказывали). Особенно рекомендуется делать это для браузера, почты и мессенджера.

Firejail sandbox
Операционка плотно нафарширована средствами криптографии (TrueCrypt, VeraCrypt, KeePass, GnuPG, Enigmail, Seahorse, GNU Privacy Guard Assistant) и заметания следов (BleachBit, Nepomuk Cleaner, Nautilus-wipe).
Набор предустановленных утилит
Встроенные системные приложения
В Kodachi реализована защита от атаки методом холодной перезагрузки. Во время cold boot attack можно частично восстановить данные, недавно (секунды назад) хранившиеся в оперативной памяти. Чтобы этого избежать, Kodachi затирает оперативную память случайными данными при выключении компьютера.
Инструменты быстрого реагирования собраны в разделе Panic room . В нем есть программы затирания данных на диске и в оперативной памяти, перезапуска сетевых подключений, блокировки экрана (xtrlock) и даже команда полного уничтожения операционки.
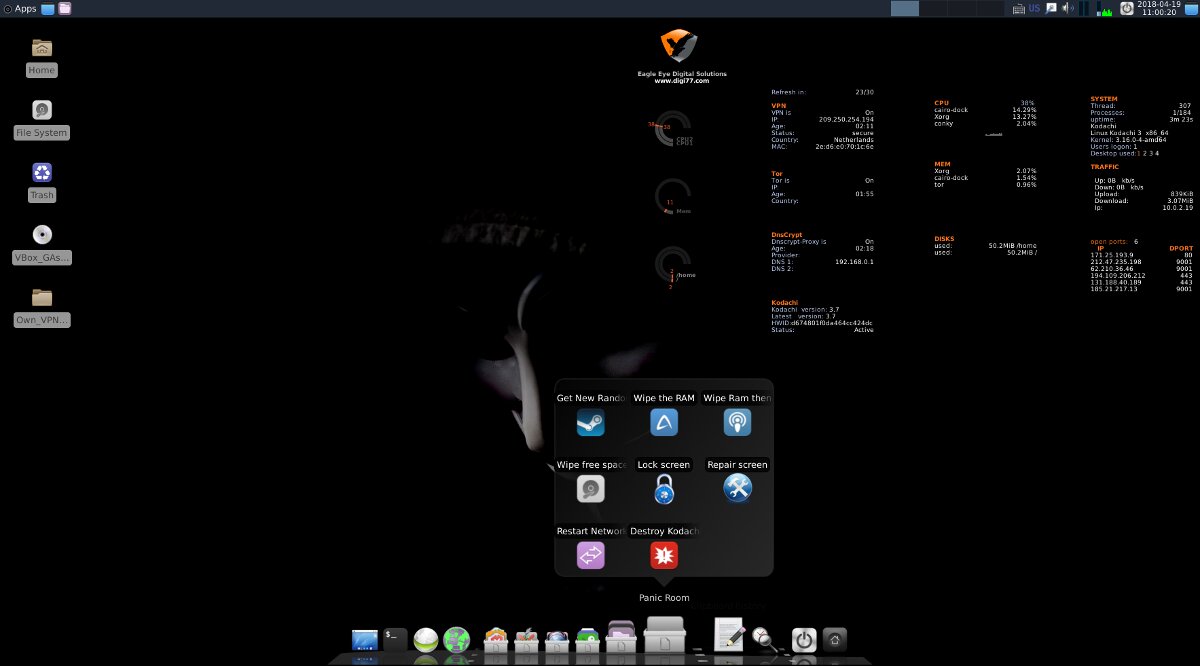
Набор параноика
Kodachi работает с USB-Flash как типичный Live-дистрибутив (чтобы не оставлять следов на локальном компьютере), но при желании ты можешь запустить ее в виртуалке (если доверяешь основной ОС). В любом случае по умолчанию ты логинишься как пользователь с именем kodachi и паролем r@@t00 . Чтобы использовать sudo, введи username root и такой же пароль r@@t00 .
Fedora, RHEL, openSUSE
Что такое барьеры доступа к памяти?
Как показано выше, независимые операции доступа к памяти могут выполняться в произвольном порядке, что может стать проблемой для взаимодействия между процессорами или между процессором и внешним устройством. Требуется механизм для указания компилятору и процессору на необходимость соблюдения порядка.
Барьеры доступа к памяти являются таким механизмом. Они приводят к частичному упорядочиванию операций доступа к памяти по обе стороны барьера.
Процессоры и другие системные устройства используют множество приёмов для повышения производительности, в их числе переупорядочивание операций, откладывание и совмещение операций доступа к памяти, раннее чтение данных, предсказание переходов и различные типы кеширования. Барьеры доступа к памяти служат для подавления этих механизмов.
Существует 4 основных типа барьеров:
Барьеры записи гарантируют, что все операции записи в память, для инструкций предшествующих барьеру, будут выполнены процессором до любой операции записи в память, для инструкций следующих за барьером, с точки зрения остальных компонентов системы.
Барьеры записи упорядочивают только операции записи в память, не следует полагать, что они могут оказывать какой-либо эффект на операции чтения.
Барьеры зависимости по данным — это ослабленная версия барьеров чтения. В случаях, когда две операции чтения выполняются таким образом, что вторая операция зависит от результата первой (например, первая операция получает адрес, из которого будет читать вторая), барьер зависимости по данным гарантирует, что данные по адресу второй операции чтения будут актуальными на момент выполнения этой операции.
Барьеры зависимости по данным оказывают эффект только на взаимозависимые операции чтения, не следует полагать, что они могут оказывать эффект на операции записи, независимые или перекрывающиеся операции чтения.
Другие процессоры генерируют последовательности операций записи в память, результаты которых может наблюдать рассматриваемый процессор. Барьер зависимости по данным гарантирует, что при наличии перед барьером операций чтения из адресов, в которые была запись другим процессором, результаты всех остальных операций записи, предшествовавших ей, так же будут доступны процессору проходящему барьер, по окончании его прохождения.
Замечание: зависимость между чтениями должна быть действительно по данным; если адрес второй операции чтения зависит от результата выполнения первой, но не напрямую, а вычисляется на основании результата первого чтения, например, условными операторами, то это зависимость по управлению, и в этом случае следует использовать барьер чтения или барьер доступа. См. раздел «Барьеры зависимости по управлению».
Барьер чтения — это барьер зависимости по данным с гарантией, что все операции чтения, для инструкций предшествующих барьеру, будут выполнены процессором до любой операции чтения, для инструкций следующих за барьером, с точки зрения остальных компонентов системы.
Барьеры чтения упорядочивают только операции чтения из памяти, не следует полагать, что они могут оказывать какой-либо эффект на операции записи.
Барьер доступа к памяти гарантирует, что все операции чтения и записи, для инструкций предшествующих барьеру, будут выполнены до любых операций чтения или записи, для инструкций следующих за барьером, с точки зрения остальных компонентов системы.
Барьеры доступа к памяти упорядочивают как операции чтения, так и записи.
-
Операции захвата блокировки (LOCK).
Такие операции ведут себя как барьер с односторонней проницаемостью. Они гарантируют, что все операции доступа к памяти, для инструкций следующих за операцией захвата блокировки, будут выполнены после захвата блокировки, с точки зрения остальных компонентов системы.
Операции доступа к памяти, для инструкций предшествующих захвату блокировки, могут быть выполнены как до, так и после её захвата.
Такие операции тоже ведут себя как барьер с односторонней проницаемостью. Они гарантируют, что все операции доступа к памяти, для инструкций предшествующих операции освобождения блокировки, будут выполнены до освобождения блокировки, с точки зрения остальных компонентов системы.
Операции доступа к памяти, для инструкций следующих за освобождением блокировки, могут быть выполнены как до, так и после её освобождения.
Гарантируется, что операции захвата и освобождения блокировки не переупорядочиваются.
Барьеры доступа к памяти требуются только в случае межпроцессорного взаимодействия, или взаимодействия процессора со внешним устройством. Барьеры доступа к памяти не нужны в коде, который не участвует в таких видах взаимодействия.
Замечание: изложенные гарантии — минимальные. Различные процессорные архитектуры могут давать более сильные гарантии для барьеров, на них, однако, не следует полагаться в архитектурно-независимом коде.
- Нет гарантии, что операции доступа к памяти, для инструкций предшествующих барьеру, будут завершены в момент окончания прохождения барьера; условно можно считать, что барьер «проводит черту» в очереди запросов процессора, которую не могут пересекать запросы определённых типов.
- Нет гарантии, что барьер доступа к памяти, выполненный на одном процессоре, окажет какой-либо эффект на другой процессор или другое устройство в системе. Косвенный эффект выражается в наблюдаемой другими устройствами последовательности обращений к памяти, выполняемых этим процессором (см., однако, следующий пункт).
- Нет гарантии, что процессор будет наблюдать эффекты доступа к памяти со стороны других процессоров в правильном порядке, даже если те будут использовать барьеры доступа к памяти, в случае если этот процессор сам не использует соответствующие барьеры (см.раздел «Парные барьеры в случае SMP»).
- Нет гарантии, что никакие промежуточные устройства не будут переупорядочивать обращения к памяти. Механизмы поддержания когерентности процессорного кеша должны передавать эффект от барьеров между процессорами, но могут нарушать их взаимный порядок.
Модель использования барьеров зависимости по данным имеет ряд тонкостей, необходимость которых не всегда очевидна.
Рассмотрим следующую последовательность событий:
В коде присутствует явная зависимость по данным, и создаётся впечатление, что по окончании последовательности Q может быть равен либо &A либо &B, а так же, что (Q == &A) влечёт (D == 1), а (Q == &B) влечёт (D == 4).
Однако, с точки зрения CPU2, P может быть обновлен раньше чем B, в результате чего получится (Q == &B) и (D == 2) (о_О).
Хоть и может показаться, что подобное поведение является нарушением причинно-следственных связей, либо проблемой когерентности, это не так. Такое поведение наблюдается на некоторых типах процессоров (например, DEC Alpha).
Для исправления ситуации требуется барьер зависимости по данным (или более сильный) между чтением адреса и чтением данных по этому адресу:
В таком случае третий исход ((Q == &B) и (D == 2)) невозможен.
Замечание: такая противоестественная ситуация легче всего воспроизводима на машинах с разделённым кешем, когда, например, один кеш-банк обслуживает чётные, а другой — нечётные строки кеша. В случае, когда P и B попадают в строки разной чётности, неравномерность нагрузки на банки кеша может привести к описанному эффекту.
Наличие зависимости по управлению требует использования барьера чтения, барьера зависимости по данным будет недостаточно. Рассмотрим следующий код:
Барьер в этом примере не возымеет желаемого эффекта, поскольку фактически зависимость по данным между (p) и (x = *q) отсутствует, а имеет место зависимость по управлению. Процессор может попытаться предсказать результат.
Что действительно требуется в данной ситуации:
При организации межпроцессорного взаимодействия определённые типы барьеров всегда должны использоваться парно. Отсутствие парности почти наверняка является ошибкой.
Барьер записи должен всегда иметь пару в виде барьера зависимости по данным, барьера чтения или обобщённого барьера доступа к памяти. Аналогично, барьер зависимости по данным и барьер чтения должны иметь пару в виде барьера записи или обобщённого барьера доступа к памяти:
Барьер чтения всегда должен присутствовать, вопрос только в том, какой силы примитив следует для него выбрать.
Замечание: операции записи перед барьером записи обычно имеют парные операции чтения с другой стороны барьера чтения или зависимости по данным и наоборот:
Первый: барьеры записи вносят частичный порядок в операции записи. Рассмотрим следующую последовательность событий:
Эта последовательность достигает системы поддержки когерентности памяти в порядке, который остальные части системы могут наблюдать как неупорядоченный набор записей < ЗАПИСЬ A, ЗАПИСЬ B, ЗАПИСЬ C >, происходящих до неупорядоченного набора записей < ЗАПИСЬ D, ЗАПИСЬ E >:
Второй: барьеры зависимости по данным вносят частичный порядок в зависимые по данным операции чтения. Рассмотрим следующую последовательность событий:
Без барьеров CPU 2 может наблюдать события, производимые CPU 1 в произвольном порядке, не смотря на использование барьера записи CPU 1:
В приведённом примере CPU 2 наблюдает значение B == 7, не смотря на то, что чтение *C (которое должно вернуть B) идёт после чтения C.
Однако, при наличии барьера зависимости по данным между чтением C и чтением *C (т.е. B) на CPU 2,
картина выглядит так:
Третий: барьер чтения частично упорядочивает операции чтения. Рассмотрим следующую последовательность событий:
Без барьеров CPU 2 может наблюдать события, производимые CPU 1 в произвольном порядке, не смотря на использование барьера записи CPU 1:
Однако, при наличии барьера чтения между чтением B и чтением A на CPU 2,
частичный порядок, обеспеченный CPU 1, будет наблюдаем CPU 2 правильно:
Многие процессорные архитектуры могут выполнять чтение из памяти заранее: в случаях, когда процессор видит команду чтения из памяти в конвейере и не использует внешнюю шину для других команд, команда на чтение может быть выдана заранее — даже если поток выполнения команд не добрался до инструкции чтения. Это даёт возможность инструкции чтения завершиться очень быстро, поскольку к моменту её выполнения процессор может уже получить прочитанное из памяти значение.
Может случиться, что прочитанное значение не понадобится — например, если команда перехода встретится раньше команды чтения. В таких случаях прочитанное значение будет отброшено или сохранено в кеше.
Рассмотрим следующий пример:
который может генерировать следующие команды:
Помещение барьера чтения или зависимости по данным перед второй операцией чтения
вынудит процессор пересмотреть заранее прочитанное значение, в зависимости от использованного типа барьера. Если заранее прочитанная область памяти не менялась, значение будет использовано:
однако, если область памяти была перезаписана другим процессором, заранее прочитанное значение будет отброшено и команда чтения будет выдана повторно:
Настройка
Все параметры Nohang настраиваются в конфигурационном файле
В принципе, всё можно оставить как есть, параметры по-умолчанию там оптимальны для любой конфигурации железа.
Обобщённая модель доступа к памяти.
Рассмотрим следующую модель системы:
Каждый процессор выполняет программу, генерирующую последовательность операций доступа к памяти. Абстрактный процессор имеет слабую модель упорядочивания доступа к памяти, так, что фактически операции доступа могут выполняться в произвольном порядке, если при этом не нарушаются причинно-следственные связи заложенные в исполняемом коде. Аналогично, компилятор свободен в организации сгенерированного кода, при условии, что результат выполнения этого кода будет соответствовать исходному тексту программы.
На приведённом рисунке операции с памятью выполняемые процессором наблюдаются остальными компонентами системы, как операции пересекающие границы между этим процессором и системой (обозначенные пунктирными линиями).
Многие устройства имеют управляющий интерфейс в виде набора регистров с определёнными адресами в памяти; порядок доступа к управляющим регистрам важен для правильной работы. Например, сетевой адаптер может иметь набор внутренних регистров, доступ к которым выполняется через регистр адреса (A) и регистр данных (D). Для чтения внутреннего регистра 5 может быть использован следующий код:
этот код может породить следующие последовательности доступа к памяти:
вторая последовательность почти наверняка вернёт неправильный результат, поскольку регистр адреса будет установлен после чтения регистра данных.
Процессор гарантирует, как минимум, следующее:
-
Операции доступа к памяти, зависящие одна от другой, выполняются в правильном порядке в пределах одного процессора. Иными словами, для кода
процессор сгенерирует такие операции доступа к памяти:
процессор сгенерирует только такую последовательность доступа к памяти:
-
Не следует полагать, что операции доступа к памяти для независимых чтений и записей будут сгенерированы в каком-то определённом порядке. Иными словами, для кода
может быть сгенерирована одна из следующих последовательностей:
может быть сгенерирована одна из следующих последовательностей:
— одна из следующих:
Включение оповещений на рабочем столе
Чтобы включить всплывающие оповещения о нехватке ОЗУ и завершении приложений Nohang, нужно в файле конфигурации изменить следующие параметры на значение «True» чтобы получилось вот так:
После чего сохранить изменения в конфигурационном файле и перезапустить Nohang для применения новой конфигурации:
Читайте также: