
Ядра и потоки процессора в чем разница
В том или ином виде вопрос поднимался в разных местах, но обычно это становится широкой дискуссией про умных или красивых. Попробую сформулировать вопрос четко.
Какая конфигурация компьютера даст больше производительность: с одним процессором на 2N ядер или с дувмя процессорами на N ядер, при условии, что остальные параметры одинаковы? Почему? Если для разных приложений результат разный, то для каких и почему.
Вопрос родился из анонса нового Mac Pro. Он будет однопроцессорный, но у него будет 12 ядер (с учетом HT или нет — не знаю). Многие маководы разочарованы этим. Лучше ли это будет для ресурсоемких по CPU приложений или хуже, чем если бы в нем было два процессора по 6 ядер?
- Вопрос задан более трёх лет назад
- 6964 просмотра
Обмен данными между ядрами быстрее, чем между процессорами. 2 разных процессора с задачами(по одной на каждый), которые никак не пересекаются будут работать быстрее чем 2 ядра с теми же условиями. Т.к. у ядер кэш общий, а у процессоров эксклюзивный. Если планировщик будет хорошо распределять задачи, то, теоретически, много процессоров с меньшим количеством ядер будут эффективнее.
Всё это мое личное мнение, т.к.никаких реальных тестов я не делал.
Т.е. для многопоточных приложений, лучше больше ядер на одном чипе, а для множества однопоточных лучше много ядер на разных чипах? Насколько реально используется внутренний кеш чипа (кстати, а он разделяемый или общий?) для обмена данными между потоками на соседних ядрах? Потоки вообще «понимают», что они выполняются внутри одного чипа или на разных?
нет, все дело в планировщике, это его дело распределять потоки по ядрам\процессорам. Процесс, как таковой, из себя представляет набор потоков. Но для потока\процесса можно запросить исполняться на конкретном CPU(CPU affinity), т.е. вручную управлять его определением к CPU. В связи с этим, можно варьировать потоки по разному и получать разную производительность. Но, я полагаю, что CPU affinity это больше для серверного софта и Mac OS на «персоналка» тут ни при чём.
Насколько реально используется внутренний кеш чипа (кстати, а он разделяемый или общий?) для обмена данными между потоками на соседних ядрах?
Как правило, в современных пользовательских CPU 3 уровня КЭШ. Все они используются в пределах одного кристала весьма интенсивно. Более подробно лучше об этом почитать самостоятельно, слишком объемная тема. Хорошо это описано у таненбаума в его Structured Computer Organization.
Не знаю точно, но, вполне вероятно, что эту информацию можно получить. «По умолчанию» это волновать не должно, программирование всё больше идёт в сторону task-based, что устраняет разработчика даже от потоков, в чистом виде.
В целом вой по-поводу отсутствия 2 кристалов, как мне кажется, производится любителями гигагерцев и гигабайтов. Которые мало смыслят в современном(а может и вообще) железе.
Процессор — самая главная микросхема в компьютере, смартфоне и в самых различных цифровых устройствах. Часто процессор сравнивают с мозгом — да, отчасти это так. Внутри CPU происходят все арифметические вычисления для получения конечного результата.
Первые процессоры не имели ядер и выполняли все операции строго последовательно. Чем выше частота, тем быстрее будет выполняться та или иная операция.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Главное отличие физических ядер от логических
Само собой, логическое ядро - это не дополнительный вычислительный блок, а как бы второй путь к одному блоку, так что "производительность на бумаге" он не увеличивает. НО
Желтым тут показано время, которое конвейер простаивает. Синим и оранжевым - задачи, которые необходимо выполнить (это упрощенно). Как видим, если находится свободное процессорное время, то оно тут же забивается второй программой, как следствие - меньше простоя и больше полезной работы. Это иллюстрация совсем уж идеальных условий, так как столько времени процессор простаивать не может (если программа нормально оптимизирована)
Желтым тут показано время, которое конвейер простаивает. Синим и оранжевым - задачи, которые необходимо выполнить (это упрощенно). Как видим, если находится свободное процессорное время, то оно тут же забивается второй программой, как следствие - меньше простоя и больше полезной работы. Это иллюстрация совсем уж идеальных условий, так как столько времени процессор простаивать не может (если программа нормально оптимизирована)
Теперь при открытии второй программы, первая не перестанет выполняться а будет ожидать процессорное время, и если оно появится - ядро переключится на второй поток и будет исполнять уже его, и, если это нужно, позже снова переключится на первый поток. Таким нехитрым образом на одном ядре можно исполнять сразу два потока команд.
Я понимаю, звучит сложно, но дождитесь видео - там будут более подробные иллюстрации. Продолжим.
Даже больше скажу: если одна программа задействует два потока, то в случае какой-то проблемы с первым потоком ядро опять таки переключится на второй поток и продолжит выполнение программы, а не будет ждать, пока решится проблема на первом потоке.
Если подытожить, то мультипоточность - это когда одно ядро процессора может выполнять несколько потоков команд, но не параллельно (ядро все-таки одно), а последовательно, но может в любой момент переключаться между ними, либо выполнять несколько программ параллельно (пусть и не так эффективно, как полноценные два ядра).
Друзья! Минутка от спонсоров. Хочу порекомендовать вам дебетовую карту Tinkoff All Games, на обложке которой может быть ваш игровой никнейм! Из того, что понравится геймерам - кэшбэк 3% на игры, 1,5% на электронику и развлечения, а 1% - вообще на любые покупки. Кроме того, если вы тратите больше 3000 рублей в месяц, вы получите 4% на остаток деньгами, а не баллами.
В описании современных процессоров указаны количества ядер и потоков. Что обозначают эти цифры, на какие показатели следует ориентироваться при покупке процессора – рассмотрим в статье.
В описании современных процессоров указаны количества ядер и потоков. Что обозначают эти цифры, на какие показатели следует ориентироваться при покупке процессора – рассмотрим в статье.
В спецификации каждого процессора обязательно присутствует информация о количестве ядер и потоков. Правила «чем больше, тем лучше», в этой ситуации никто не отменял, но давайте выясним, в каких задачах виртуальные ядра способны дать ощутимый прирост производительности, а в каких останутся бесполезными.
Что такое поток?
Можно сказать, что поток является виртуальным ядром самого ядра. Поток — параметр исключительно программный, он работает с ядром и способен дать ядру работать параллельно с разными задачами. Сколько потоков — столько и задач. Такая программная хитрость позволяет более рационально использовать вычислительную мощность ядра.
Чем больше программ вы запускаете на компьютере, тем сильнее нагружаете CPU. А он уж сам определяет как задействовать ядра и потоки для максимальной производительности. Для игр и серьезных задач с графикой вычислительная мощность для видеопотока отдается видеокарте для того, чтобы разгрузить графическое ядро CPU. Кстати, процессор видеоадаптера работает примерно также, как и основной.
Но два разобранных в статье параметра не являются самыми ключевыми. Да, чем больше потоков и ядер, тем лучше. Но есть еще и другие параметры, как архитектура процессора, техпроцесс, частота и объем кэш памяти.
Поэтому двухядерный CPU может быть намного лучше, чем четырехъядерный — последний будет проигрывать по другим параметрам.
Всем привет, дорогие друзья. Рад вас видеть! Сегодня поговорим о простом, но непонятном для рядового пользователя явлении - логические ядра процессора, ну или просто - потоки.
Буду писать все максимально просто и понятно. О чем пойдет речь?
- Что такое технология мультипоточности и для чего она нужна;
- Чем логические ядра отличаются от физических;
- Что лучше: 4 ядра и 8 потоков или 6 ядер и 6 потоков?
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Что такое ядро процессора?
Ядро — физический блок, который находится внутри процессора и занимается линейным вычислением арифметических операций. Чем больше ядер, тем быстрее процессор обрабатывает информацию — все ядра могут работать как одновременно для основной, мощной задачи, так и последовательно, выполняя поток задач.
Если в CPU 1 ядро, то оно будет постоянно переключаться между задачами — от этого снижается производительность ПК в целом.
Кстати, до того того, как изобрели многоядерные процессоры для профессиональных пользователей, производились компьютеры с несколькими физическими процессорами.
Читайте далее:
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Чем отличаются ядра и потоки
Ядро – это самостоятельный вычислительный блок в архитектуре процессора, способный выполнять линейную последовательность задач за определенный период времени. Если нагрузить одно ядро несколькими последовательностями задач, то оно будет попеременно переключаться между ними, обрабатывая по одной задаче из каждого потока. В масштабах системы это приводит к замедлению работы программ и сервисов.
Поток – это программно выделенная область в физическом ядре процессора. Такая виртуальная реализация позволяет разделять ресурсы ядра и работать параллельно с двумя разными последовательностями команд. Таким образом операционная система воспринимает поток, как отдельный вычислительный центр, следовательно, ресурс ядра используется более рационально, и скорость вычислений увеличивается.
Прерывания
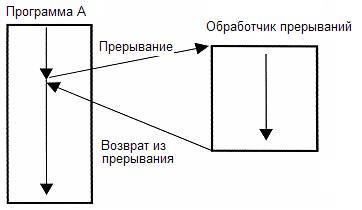
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Что такое технология мультипоточности и для чего она нужна?
Если очень просто - то это второй поток команд, который используется планировщиком задач операционной системы, чтобы использовать ресурсы процессора более эффективно.
А теперь чуть сложнее. Во время работы к вычислительным ядрам процессора идет непрерывный поток команд от планировщика операционной системы. Теперь представим, что у нас процессор на 1 ядро и 1 поток и мы работаем в какой-то программе. У нас все хорошо, так как поток команд от этой программы идет на ядро, оно его обрабатывает - все гуд.
Теперь открываем еще одну программу. Планировщик также помещает ее инструкции в очередь, но ядро у нас всего одно. Тогда, в зависимости от приоритета, одна из программ тупо не будет выполняться, так как выполнять ее не на чем - ядро-то одно.
В 2002 году в intel озадачились этой проблемой. Так как процессор на 2 физических ядра был еще не готов, решили изящно выкрутиться из положения: к одному физическому ядру подводить два потока инструкций. Так и получился Hyper-Threading.
Стоит ли ожидать удвоения производительности?
Виртуальное разделение вычислительной мощности процессора на потоки называется гиперпоточностью. На практике это не физическое увеличение количества ядер, следовательно, и вычислительный потенциал процессора остается постоянным.
Гиперпоточность – это инструмент, позволяющий процессору более оперативно выполнять команды операционной системы и распределять вычислительный ресурс.
Таким образом, удвоенное количество потоков по отношению к ядрам способно повысить эффективность процессора за счет одновременного выполнения нескольких задач каждым ядром. Но прирост, даже по заверениям лидера рынка в производстве процессоров Intel будет находиться в пределах 30%.
А вот об увеличении энергопотребления и чрезмерном нагреве волноваться не стоит. Так как виртуальное разделение выполнено на производстве, то компанией просчитаны все рабочие параметры, такие как мощность и TDP, указанные в спецификации.
Зачем процессору несколько ядер?
Процессор – это вычислительный центр любого компьютера, планшета, смартфона и даже игровой консоли. Именно процессор принимает команды пользователя, вводимые в различных приложениях и программах, обрабатывает их и распределяет задачи между другими узлами системы – видеокартой , оперативной памятью , твердотельным диском .
Вот поэтому процессор – это мозговой центр каждого компьютера, отвечающий за его вычислительные способности и скорость работы.
Первые процессоры были едиными устройствами, которые принимали команды и выполняли их в строгой очередности. Одно ядро позволяло выбирать процессор при покупке только по показателям частоты. А недостаток производительности на первых порах компенсировали созданием двух- и многопроцессорных конфигураций. В таких сборках команды пользователя на ввод обрабатывал первый процессор, а остальные операции по возможности равномерно распределялись между остальными. Для сборки таких систем использовались двухпроцессорные платы или конфигурации на несколько сокетов.
Следующим шагом производители создали многоядерную архитектуру, позволяющую на площади, казалось бы, небольшого микрочипа размещать несколько вычислительных центров, которые по сути являлись самостоятельными процессорами. Так в продаже появились двух-, четырех- и восьмиядерные устройства, которые обрабатывали сразу несколько потоков информации.
Позже корпорация Intel в линейке процессоров Pentium внедрила техническую возможность выполнения одним ядром двух команд за такт, что стало началом новой эпохи в компьютерных технологиях – гиперпоточности процессоров. А сейчас специалисты компании активно работают над новой технологией реализации четырех потоков на одном ядре, и уже в ближайшее время подобные процессоры будут представлены публике.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Что выбирать: ядра или потоки?
Поскольку ядра – это физические «мозговые центры», занимающиеся вычислениями, то за общую производительность центрального процессора отвечают именно они. Поэтому количеством ядер, ну и еще частотой процессора определяется его производительность.
Но и количество потоков также заслуживает внимания. Разберем на примере:
Двухъядерный процессор с двумя потокам нагружается операционной системой четырьмя параллельными последовательностями команд, например, от открытых игр и программ. Команды так и останутся в четырех «очередях», и ядра будут попеременно производить вычисления из каждой. При этом производительность ядра зачастую избыточна для обработки одной команды. Поэтому часть вычислительного потенциала ядра, а значит и процессора останется в резерве.
Если же взять аналогичный процессор с двумя ядрами, но уже на четыре потока, то все четыре очереди будут задействованы одновременно, по максимуму загружая ядра. Следовательно, задачи будут решены быстрее, а простоя вычислительных мощностей удастся избежать.
На практике это дает нам возможность одновременно запускать несколько программ: работать с документами, слушать музыку, общаться в мессенджерах и выполнять поиск в браузере. При этом программы будут работать эффективно, быстро, без торможений и зависаний.
В производственных масштабах для комплектации рабочих станций или серверов также следует отдать предпочтение большему количеству потоков при равных числах ядер. За исключением особых случаев, таких как работа с 1С, когда решающую роль играет тактовая частота, и ряда других приложений, активно использующих TCP/IP стек. В этих случаях распараллеливание вызывает существенную задержку при обработке пакетов .
Таким образом, чем больше ядер будет в процессоре, тем выше его производительность и скорость выполнения различных задач. А удвоенное количество потоков позволяет повысить эффективность процессора и задействовать его технический потенциал на полную.
В заключении интересное видео от компании Intel о том, как они создают микрочипы.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Читайте также: