
Storcli замена диска в raid
нужно ли что то после замены диска еще проводить какие то манипуляции в самой утилите Intel® Rapid Storage Technology или он сам автоматические подхатится и начнет инициализирваться?
или нужно будет удалять (разбивать этот рейд) и потом снова его собирать?
Вопрос в том, что на сервере данные в единственном экземпляре((((
Простой 2 комментария
Вынуть умерший диск, вставить новый, подождать пока закончится синхронизация
комп не мой, исправляю за сис админом который даже об этом не думаю.
Ноль и десятка - это две большие разницы. И не надо читать про то чего у тебя нет - только зря время терять. Замени дохлый диск - контроллер сам отребилдится.
А когда он всё закончит - влезь в настройку контроллера и посмотри, умеет ли он hot spare. Если умеет - подключай пятый диск и регай его как горячую замену. В следующий раз когда один из дисков помрёт, контроллер сам подключит и отребилдит этот диск - останется только заменить сдохший, и новый теперь будет горячей заменой.
Если это RAID-10 - просто вытаскиваешь диск, вставляешь новый. Утилита сама его подтянет в рейд. Прогресс будет отображаться в главном окне Rapid'а.
В комментах ты дал ссылку на мануал, где говорится, что надо пересобирать рейд вручную - это справедливо только для RAID-0, т.к. там все данные теряются.
Ну и самое главное - без бэкапов ничего не делать.
freeSTUD, так повреждён рейд или диск? Если диск - конечно можно, для того в RAID-10 избыточность и заложена. Если сам массив повредился - нет, нельзя.
Newbie2, еще небольшой вопросик, тут винда на тех дисках (рейде) где жива в вечной загрузке(логотип windows и постоянно крутится кружочек из точек), посоветуйте как правильно с нее забрать данные?
подключить какой нибудь liveCD и на внешний диск сбросить или какой можете посоветовать способ?
freeSTUD,
1. Да, liveCD и подгрузка драйверов на контроллер, если он аппаратный. Если софтовый, то винда и так распознает массив и даст скопировать данные.
2. В вечной загрузке? Пробуйте в безопасный режим загрузиться, не должно быть так. Возможно это из-за просадки производительности массива происходит. У 5-го уровня, например, когда пересборка массива идет, то 99% активности диска приходится именно на неё, производительность дисковой системы для ОС сильно падает, буквально до нескольких сотен кб/с. На RAID-10 по идее сильной просадки быть не должно.
Newbie2,
1) Вас понял!
2) пробовал во всех режимах и у меня rebuild на 500 гиговом диске почти сутки делается и еще походу делаться будет и дальше это нормально или нет?
спасибо большое за информацию!
а от себя можете посоветовать:
1) какой лучше использовать рейд
2) в надежности какой безопасней железка или софтовый?
freeSTUD,
2) Сутки без нагрузки или под нагрузкой? Если под нагрузкой - нормально, если вхолостую, то нет. А строка прогресса двигается?
1) Смотря для чего. Если отказоустойчивоть + скорость, то 10 уровень - оптимальный выбор. Если это архив какой-нибудь с малым количеством обращений - можно и 1 уровень. 5 уровень вообще никогда не рекомендую, плохой он.
2)По надёжности - имхо, одинаково. Аппаратный быстрей и гораздо гибче, но в случае выхода из строя самого контроллера вам обеспечен неиллюзорный секс. Надо при этом помнить, что то, что встроено в материнку лучше не использовать вообще никогда. Там от контроллера одно название.

Всем привет сегодня после того как получилось подружить HP ProLiant DL380 G7 и LSI 9361 8i, хочется разобрать возможность управления RAID контроллером LSI в VMware ESXI 5.5 через командную строку, что на мой взгляд не так удобно как в случае с графическим интерфейсом, но имеет и свои плюсы, более быстрое в случае когда вы набили руку.
Напомню что графический способ подразумевал установку утилиты MSM, почитать это можно в статье как установить MegaRAID SMIS Providers на VMware ESXi 5.5. Для того чтобы вы могли воспользоваться функционалом StorCLI для lsi raid, вам нужно его поставить, ранее я рассказывал Как установить StorCLI в Vmware ESXI 5.5, советую ознакомится. И так приступимс.
storcli команды
Общие команды storcli show
Первым делом переходим в каталог расположения утилиты делается это командой
Посмотреть версию storcli
либо если не переходить в каталог с программой

Получить справочную информацию по всем командам утилиты storcli

Посмотреть подсоединенные контроллеры
Нашелся один RAID контроллер.

Для более детальной информации вводим следующую команду.
Как видите тут выводится модель raid контроллера, у меня это Avago MegaRAID SAS 9361-8i, количество портов.

Так как я выяснил, что мой контроллер идет под номером 0, то в дальнейшем он будет выступать под видом /c0.
Посмотрим теперь реально всю информацию о данном RAID контроллере, для этого воспользуемся командой storcli
В итоге получаем вот такую простыню, как можете заметить информации реально вагон, для примера версии всех прошивок, всех утилит, статусы компонентов и количество ошибок.
Из полезного еще, можно посмотреть число virtual drive и физических дисков.
- показывает количество групп дисков;
- для каждой группы дисков - тип RAID, состояние, наличие фоновых задач, размер, использование кеша дисков, PI, SED, наличие свободного места, не всегда отрабатывает;
- для каждого диска - номер группы дисков, номер в группе (Row), номер корзины и слота в корзине, идентификатор устройства (DID), состояние, наличие фоновых задач, размер, использование кеша дисков, интерфейс, носитель, размер сектора, модель, раскручен ли;
- для каждого виртуального диска - номер группы дисков, тип RAID, состояние, тип доступа (RW), консистентность, тип кеширования, размер, имя;
- для BBU - модель, состояние, температура, режим работы, дата изготовления, дата следующего тестирования
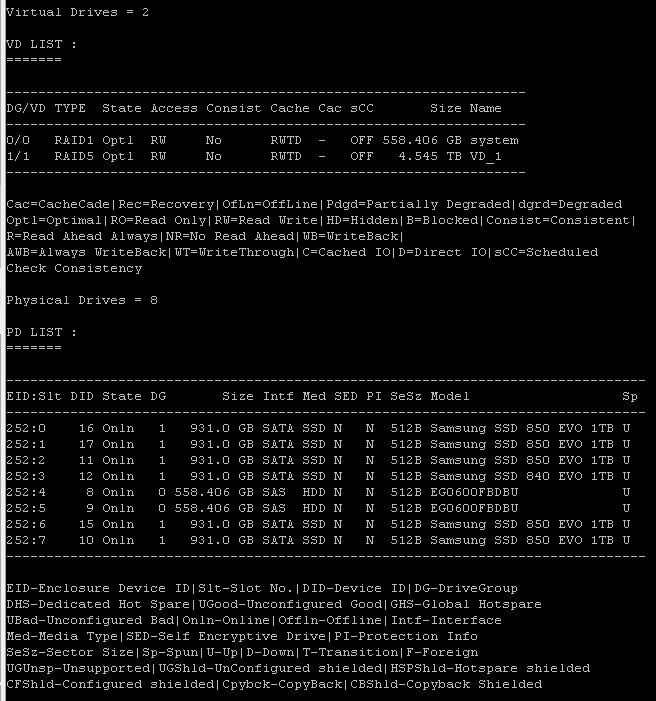
Интервал сброса кэша, по умолчанию стоит 4 секунды

Если происходит проверка консистентности и если находится ошибка, должен ли контроллер прекратить ее или нет.
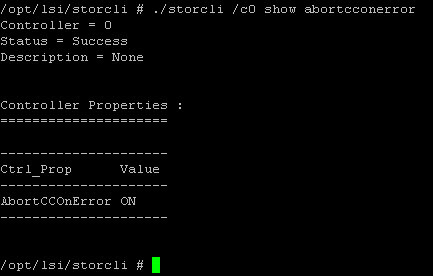
Так и не понял для чего данная команда Use Disk Activity For Locate, типа использовать дисковую активность для локализации диска.
Посмотреть включены ли alarm
Узнать количество плохих секторов badblocks
Узнать статус включены ли предупреждения от BBU батарейки
Узнать приоритет фоновой инициализации, по умолчанию это значение 30 %, максимально 100, минимальное 0.
Задать поведение контроллера при ошибках во время загрузки
Работа с Virtual Drive
Первым делом приведу команду которая покажет вам существующие virtual drive на вашем Raid контроллере.
У меня это виртуальный диск на RAID1, размером 558 гб.

Если добавите параметр all, то получите исчерпывающию информацию, из чего состоит данный Virtual Drive (EID дисков), размер stripe и многое еще.

Далее нужно понять какие диски у нас есть, делается это командой
Вы получите список дисков на вашем сервере, если опять добавите параметр all, то информации будет в разы больше. Тут из полезного EID диска, его статус.

Создаем Virtual Drive, сразу советую вам почитать про виды RAID и виды кэша контроллера LSI. Вводим команду
./storcli /c0 add vd type=r0 size=1024000 name=raid0 drives=252:0-1 strip=128 pdcache=off direct wb ra
В результате ее выполнения вы получите виртуальный диск размером 1тб raid0, размером strip 128 с выключенным кэшем записи на диске и режимами кэша Read ahead, Direct I/O, Write back.
Возможные параметры virtual drive
- add vd > указываем что создается виртуальный диск
- type > тип raid 0|1|5|6|00|10|50|60
- size > размер указывается в мегабайтах, если поставить all, будет размечено все пространство.
- name > любое имя на латинице
- drives > список дисков
- strip > размер страйпа возможны варианты 8|16|32|64|128|256|1024
- pdcache > включение локального кэширования записи на дисках 0n/off
- Политика ввода вывода direct > Direct I/O еще возможный вариант cached > Cached I/O
- Политика записи wb > Write back, wt > Write through, awb > Always Write Back
- spares > добавить диск горячей замены, не работает с raid0
Пример команды с диском горячей замены, где 252:3, диск в 3 слоте.
./storcli /c0 add vd type=r0 size=1024000 name=raid0 drives=252:0-1 strip=128 pdcache=off direct wb ra spares=252:3
Проверим теперь список виртуальных дисков. Как видите наш vd успешно добавлен.

- ssdcaching > on|off режим CacheCade
- emulationType > этот параметр задает как будет происходить эмуляция логического размера физического диска. Если выставить Default (0), то если в виртуальном диске будут диски 512E, то он их и будет считать 512E, если все диски 512N, то и они будут 512N, другими словами, все как есть так и будет. Если выставить Disabled (1), то vd всегда все будут считать как 512N, если у вас даже будет 512E формат дисков. Ну и Forced (2) показывает на virtual drive размер блока как 512E, если его даже нет. Более подробно про типы читайте в статье Advanced Format.
- ds > Default|Auto|None|Max|MaxNoCache > режим энергосбережения
- autobgi > on|off включение или выключение фоновых процессов.
Иницилизируем созданный virtual drive
Посмотреть процесс инициализации по всем сразу
Удалить virtual drive выполняется командой, где v1 номер vd.
Изменить настройки virtual drive
Очень важно уметь выполнять настройки на существующих виртуальных томах. И так у нас есть том 1 тб и режимами кэширования direct wb ra, размер stripe изменить уже не получиться, только удаление тома, а вот имя и режимами кэширования, да и расширение можно осуществить.
Изменим для начала имя текущего тома, напомню оно raid0, задаем команду и теперь оно будет new_raid0

Возможные значения

Работа с CacheCade
Создаем CacheCade командой
./storcli / cx add vd cc type =r [ 0 , 1 , 10 ] drives = [ EnclosureID:SlotID | :SlotID-SlotID | :SlotID,SlotID ] WT | WB ( assignvds = 0 , 1 , 2 )
Все почти стандартно, кроме того что диск взял большего размера и менял на ходу (удаление делал echo 1 >/sys/block/sdd/device/delete хотя буква стала почему то sdE), но структуру перенес с другого диска и при добавлении вот такая фигня

он у тебя добавлен как hot spare
сбойный диск ты удалял через mdadm /dev/md0 --remove?
да, удалял, вижу что спаре, как заставить на него ребилдиться
я не уверен, но можно попробовать пересобрать через mdadm --assemble
А зачем ты структуру переносил со старого диска? Можно было просто создать на новом диске раздел нужного размера, добавить его в массив и он бы синхронизировался
это меня пугает (((
зачем ты структуру переносил со старого диска?
ну не со старого, а с тех что уже стоят
вот так точно делать не стоило
попробуй удалить этот диск из массива, очистить суперблок, удалить с диска все данные, создать на нем раздел нужного размера и по новой добавить его в массив. В этом случае mdadm увидит новый пустой диск и добавит его вместо отсутствующего
сбойный диск ты удалял через mdadm /dev/md0 --remove
очистить суперблок, удалить с диска все данные
да там никаких данных то не было, сейчас попробую вручную пересоздать разделы
да там никаких данных то не было, сейчас попробую вручную пересоздать разделы
ты просто перенес на новый диск структуру с уже работающего, включая суперблок. mdadm просто не понимает что ему делать с копией диска, который у него уже есть
а не подскажете как перенести тогда структуру без суперблока? а то сектора что то никак не поймаю чтобы были такие же как на работающем
погуглил сейчас, в общем я не прав - sfdisk -d | sfdisk переносит только структуру разделов и ничего более
пересоздал вручную, все тоже самое, висит как спаре
а mdadm --fail ты делал перед удалением диска? У тебя mdadm похоже почему то считает что дисков в рейде все еще 4 и поэтому не использует hot spare для замены сбойного
Есть raid1 из 2 дисков, есть 2 дополнительных диска, нужно добавить эти 2 диска в массив и мигрировать на raid10 без потери данных. Ситуация усложняется тем, что boot расположен не в raid, а находит только на одном из дисков, и для усиления отказоустойчивости сервера загрузчик нужно переместить в raid1.
Все описанные действия проводились на рабочем боевом сервере. Схема универсальная, подойдет для любых других начальных условий. Так же аналогично можно мигрировать с raid10 на raid1.
Имеем:
На диске /dev/sdd1 находится /boot
На массиве /dev/md1 находится /
На массиве /dev/md2 находится swap
Если у вас с загрузчиком вопрос уже решен, можете перейти сразу к разделу с миграцией.
Переносим загрузчик
На диске /dev/sdd есть данные и есть загрузчик, поэтому его будем считать эталоном, все остальные диски можно считать пустыми. Для надежности, загрузчик мы не будем размещать на raid10, а оставим на raid1 из 2х дисков (можно и на 3х и на 4х), для большей отказоустойчивости.
Создаем на диске sdb разделы один в один как на sdd. Либо вручную, например, с помощью
Либо просто дублируем разделы
Сам загрузчик находится на /dev/sdd1, поэтому деградированный raid1 /dev/md4 создадим следующим образом
После создания любого нового массива, нужно обновить информацию о всех raid, иначе после перезагрузки все развалится
Теперь перезагрузим сервер, и после перезагрузки увидим странный массив /dev/md127 от которого нужно избавиться, и наш /dev/md4, который может не появиться, т.к. вместо него /dev/md127. Решить эту проблему достаточно просто, достаточно остановить эти 2 массива и добавить заново /dev/md4
Для надежности стоит еще раз перезагрузиться и после этого мы подходим к самой ответственной части, нужно отредактировать загрузчик GRUB2 так, чтобы он грузил сервер с созданного массива. Для этого нужно узнать UUID старого диска с загрузчиком /dev/sdd1 и нового массива /dev/md4
Пример получившегося нового конфига
insmod raid
insmod mdraid
insmod part_msdos
insmod part_msdos
insmod part_msdos
insmod part_msdos
insmod ext2
set root='(md/4)'
search --no-floppy --fs-uuid --set 59f76eb9-00d2-479e-b94e-6eb54fc574d4
set locale_dir=($root)/grub/locale
menuentry 'Debian GNU/Linux, with Linux 2.6.32-5-amd64' --class debian --class gnu-linux --class gnu --class os insmod raid
insmod mdraid
insmod part_msdos
insmod part_msdos
insmod part_msdos
insmod part_msdos
insmod ext2
set root='(md/4)'
search --no-floppy --fs-uuid --set 59f76eb9-00d2-479e-b94e-6eb54fc574d4
echo 'Loading Linux 2.6.32-5-amd64 . '
linux /vmlinuz-2.6.32-5-amd64 root=/dev/md1 ro quiet
echo 'Loading initial ramdisk . '
initrd /initrd.img-2.6.32-5-amd64
>
menuentry 'Debian GNU/Linux, with Linux 2.6.32-5-amd64 (recovery mode)' --class debian --class gnu-linux --class gnu --class os
Очень важно, чтобы теперь вы не перезагружались, поэтому что изменив этот файл, загрузчик уже будет думать, что информация для загрузки находится на /dev/md4, а там пока еще ничего нет. Чтобы оставить себе лазейку, не редактируйте секцию recovery mode, так вы сможете загрузиться со старыми данными, правда для этого вам понадобится доступ через KVM-IP или чтобы сотрудник ДЦ выбрал при загрузке recovery mode.
Теперь необходимо обновить ram-диск, иначе система просто не загрузится
После того, как мы внесли изменения в загрузчик, можно переносить содержимое /boot на созданный массив /dev/md4
Мы должны убедиться, что загрузчик GRUB2 установлен на 2х жестких дисках (или 4х, смотря сколько вы захотели добавить в массив), а так же на массиве /dev/md4. Самый надежный способ это сделать, выполнить
где нужно выбрать все диски, на которые нужно добавить загрузчик.
Кроме загрузчика, и сама система должна правильно понять, что загрузчик теперь в другом месте, для этого достаточно отредактировать файлы /etc/fstab и /etc/mtab. Нас интересует строка, где монтируется /boot. UUID нам не понадобится, вместо него указываем название нашего raid-массива.
В файле /etc/fstab
В файле /etc/mtab
Теперь можно перезагружаться, и если вы все сделали правильно, система загрузится с /dev/md4, а /dev/sdd1 уже не используется. Осталось только дособрать наш деградированный массив
Мигрируем с raid1 на raid10 без потери данных
Ситуация все та же, есть raid1 массив из 2х дисков и 2 свободных диска, нужно собрать это все в raid10 и чтобы данные были целы.
Для новых дисков нужно создать структуру разделов идентичную тем, что уже в raid
На /dev/md4 находится /boot
На /dev/md1 находится /
На /dev/md2 находится swap
/boot мы не будем трогать, оставим его как raid1, данные сохранить нужно только на /dev/md1 (массив состоит из /dev/sda6, /dev/sdb6, /dev/sdc6, /dev/sdd6).
Чтобы сохранить данные, мы соберем деградированный raid10 массив из 3 дисков, и перенесем туда данные с raid1, после этого разберем raid1 и доделаем raid10.
Для начала вытащим 1 диск из raid1, т.к. нам нужно минимум 3 диска для создания raid10
Собираем деградированный RAID10 как /dev/md3 и монтируем его. Обязательно добавим запись о новом массиве, чтобы после перезагрузки он оставался
Если случайно перезагрузились до того, как записали данные о массивах, то выполните
Переносим данные с /dev/md1 на /dev/md3
Всё, данные сохранены на raid10 и миграция почти завершена. Теперь нужно указать системе, чтобы она использовала новый /dev/md3, вместо старого /dev/md1. Для этого надо отредактировать файлы /etc/fstab и /etc/mtab.
В файле /etc/fstab нужно сделать замену UUID /dev/md1 на UUID /dev/md3
В файле /etc/mtab нужно просто заменить везде вместо /dev/md1 новый /dev/md3
Когда меняется устройство для /boot или / нужно обязательно редактировать конфигурацию загрузчика /boot/grub/grub.cfg и выполнять update-initramfs, иначе грузится не будет.
И после этого обязательно выполнить
Нужно перезагрузиться, чтобы корень / стал новым массивом /dev/md3 и обращений к старом raid1 уже не было. Закончить создание raid10 нужно добавлением того диска, который сейчас в raid1 (/dev/sdd6). Но для начала нужно его остановить и очистить раздел
И только теперь добавить диск в массив raid10 и обновить данные о массивах
Вот и все, миграция с raid1 на raid10 без потери данных завершена.
P.S. В итоге я вернулся обратно на raid1, т.к. в моем случае, сам переход с raid1 на raid10 не дал каких-либо внушительных результатов, намного лучше себя показал raid1 из 4х дисков.
Собственно хотелось бы понять последовательность действий.
Как правило когда RAID создается, то все диски форматируются.
Если у меня из 2 дисков 1 вышел из строя, что нужно делать по шагам?
Мои предположения:
1) Разбить рэйд
2) заменить битый диск на новый
3) собрать рэйд
На 3 шаге,я предполагаю, система отформатирует оба диска и я останусь ни с чем.
И попутно - как можно оба диска заменить в RAID-1 вместе с переносом всех данных?

У RAID есть forced rebuild, с которым регулярно косячит масса людей, уничтожая данные при замене диска, и "правильный" rebuild, который выполняется с учётом замены только одного диска.
Форматированием, как я понимаю, вы называете именно forced rebuild, либо инициализацию.
В зависимости от того, как вы создавали массив, у вас должны быть средства управления им. Наверняка где-то там вы и увидели информацию о том, что один из дисков необходимо заменить. Изучите соответствующую справку/документацию на предмет того, как правильно заменять диски без потери данных.
Однако, с учётом того, сколько случаев потери данных при замене диска в RAID мы видим, я бы всё равно рекомендовал сделать копию хотя бы важных данных перед заменой (а лучше всех). Наличие копии данных также позволит вам просто создать новый RAID1 с нуля и потом скопировать на него файлы.

1)Отключаете неисправный.
2)Подключаете исправный.
3)Даете команду контроллера на rebuild.
1)Убрать старые диски.
2)Поставить новые диски.
3)Дать команду контроллеру на построение RAID.
4)Восстановить все данные из бэкапа.
А есть способ переноса данных плавно?
Ну типа поменяли 1 диск, синхронизировали, поменяли 2 диск, синхронизировали?
sbh, Можно и так.
Это собственно вариант замены одного диска - замена одного диска, без остановки работы.
После того как замените и убедитесь что все отлично - меняем другой диск.
АртемЪ, помоему если заменить диск - контроллер скажет что новый не является членом рэйда. чтобы его добавить нужно создать рйэд, а в момент создания оба диска форматируются.
sbh, Вы отключаете один диск- рэйд работает в режиме degrade - потеря избыточности.
Добавляете диск и делаете ребилд массива - рэйд снова в работе.
Вообще RAID1 делают для единственной цели - обеспечить непрерывную работу, даже в случае отказа диска.
Поэтому любой контроллер способен справится с ситуацией отказа или удаления одного из дисков, и корректно перестроить массив при добавлении нового диска.
Какие именно команды нужно давать контроллеру - тут зависит от контроллера, надо читать доки.
Читайте также: