
Стек в процессоре это
Наиболее важными из простейших структур данных являются стек и очередь . Эти структуры встречаются в программировании буквально на каждом шагу, в самых разнообразных ситуациях. Особенно интересен стек , который имеет самые неожиданные применения. В свое время при разработке серии ЭВМ IBM 360 в начале 70-х годов XX века фирма IBM совершила драматическую ошибку, не предусмотрев аппаратную реализацию стека. Эта серия содержала много других неудачных решений, но, к сожалению, была скопирована в Советском Союзе под названием ЕС ЭВМ (Единая Серия), а все собственные разработки были приостановлены. Это отбросило советскую промышленность на много лет назад в области разработки компьютеров.
Очередь
Очередь как структура данных понятна даже людям, не знакомым с программированием. Очередь содержит элементы, как бы выстроенные друг за другом в цепочку. У очереди есть начало и конец. Добавлять новые элементы можно только в конец очереди, забирать элементы можно только из начала. В отличие от обычной очереди, которую всегда можно при желании покинуть, из середины программистской очереди удалять элементы нельзя.
Очередь можно представить в виде трубки. В один конец трубки можно добавлять шарики — элементы очереди, из другого конца они извлекаются. Элементы в середине очереди, т.е. шарики внутри трубки, недоступны. Конец трубки, в который добавляются шарики, соответствует концу очереди, конец, из которого они извлекаются — началу очереди. Таким образом, концы трубки не симметричны, шарики внутри трубки движутся только в одном направлении.
В принципе, можно было бы разрешить добавлять элементы в оба конца очереди и забирать их также из обоих концов. Такая структура данных в программировании тоже существует, ее название — " дек ", от англ. Double Ended Queue, т.е. очередь с двумя концами. Дек применяется значительно реже, чем очередь.
Использование очереди в программировании почти соответствует ее роли в обычной жизни. Очередь практически всегда связана с обслуживанием запросов, в тех случаях, когда они не могут быть выполнены мгновенно. Очередь поддерживает также порядок обслуживания запросов. Рассмотрим, к примеру, что происходит, когда человек нажимает клавишу на клавиатуре компьютера. Тем самым человек просит компьютер выполнить некоторое действие. Например, если он просто печатает текст, то действие должно состоять в добавлении к тексту одного символа и может сопровождаться перерисовкой области экрана, прокруткой окна, переформатированием абзаца и т.п.
Любая, даже самая простая, операционная система всегда в той или иной степени многозадачна. Это значит, что в момент нажатия клавиши операционная система может быть занята какой-либо другой работой. Тем не менее, операционная система ни в какой ситуации не имеет права проигноровать нажатие на клавишу. Поэтому происходит прерывание работы компьютера, он запоминает свое состояние и переключается на обработку нажатия на клавишу. Такая обработка должна быть очень короткой, чтобы не нарушить выполнение других задач. Команда, отдаваемая нажатием на клавишу, просто добавляется в конец очереди запросов, ждущих своего выполнения. После этого прерывание заканчивается, компьютер восстанавливает свое состояние и продолжает работу, которая была прервана нажатием на клавишу. Запрос, поставленный в очередь, будет выполнен не сразу, а только когда наступит его черед.
Реализация очереди на базе массива
Как уже было сказано, программисту массив дан свыше, все остальные структуры данных нужно реализовывать на его основе. Конечно, такая реализация может быть многоэтапной, и не всегда массив выступает в качестве непосредственной базы реализации. В случае очереди наиболее популярны две реализации: непрерывная на базе массива, которую называют также реализацией на базе кольцевого буфера, и ссылочная реализация , или реализация на базе списка. Ссылочные реализации будут рассмотрены ниже.
При непрерывной реализации очереди в качестве базы выступает массив фиксированной длины N , таким образом, очередь ограничена и не может содержать более N элементов. Индексы элементов массива изменяются в пределах от 0 до N - 1 . Кроме массива, реализация очереди хранит три простые переменные: индекс начала очереди, индекс конца очереди, число элементов очереди. Элементы очереди содержатся в отрезке массива от индекса начала до индекса конца.
При добавлении нового элемента в конец очереди индекс конца сперва увеличивается на единицу, затем новый элемент записывается в ячейку массива с этим индексом. Аналогично, при извлечении элемента из начала очереди содержимое ячейки массива с индексом начала очереди запоминается в качестве результата операции, затем индекс начала очереди увеличивается на единицу. Как индекс начала очереди, так и индекс конца при работе двигаются слева направо. Что происходит, когда индекс конца очереди достигает конца массива, т.е. N - 1 ?
Ключевая идея реализации очереди состоит в том, что массив мысленно как бы зацикливается в кольцо. Считается, что за последним элементом массива следует его первый элемент (напомним, что последний элемент имеет индекс N - 1 , а первый — индекс 0). При сдвиге индекса конца очереди вправо в случае, когда он указывает на последний элемент массива, он переходит на первый элемент. Таким образом, непрерывный отрезок массива, занимаемый элементами очереди, может переходить через конец массива на его начало.
Стек — самая популярная и, пожалуй, самая важная структура данных в программировании. Стек представляет собой запоминающее устройство, из которого элементы извлекаются в порядке, обратном их добавлению. Это как бы неправильная очередь, в которой первым обслуживают того, кто встал в нее последним. В программистской литературе общепринятыми являются аббревиатуры, обозначающие дисциплину работы очереди и стека. Дисциплина работы очереди обозначается FIFO, что означает первым пришел — первым уйдешь (First In First Out). Дисциплина работы стека обозначается LIFO, последним пришел — первым уйдешь (Last In First Out).
Стек можно представить в виде трубки с подпружиненым дном, расположеной вертикально. Верхний конец трубки открыт, в него можно добавлять, или, как говорят, заталкивать элементы. Общепринятые английские термины в этом плане очень красочны, операция добавления элемента в стек обозначается push, в переводе "затолкнуть, запихнуть". Новый добавляемый элемент проталкивает элементы, помещеные в стек ранее, на одну позицию вниз. При извлечении элементов из стека они как бы выталкиваются вверх, по-английски pop ("выстреливают").
Примером стека может служить стог сена, стопка бумаг на столе, стопка тарелок и т.п. Отсюда произошло название стека, что по-английски означает стопка. Тарелки снимаются со стопки в порядке, обратном их добавлению. Доступна только верхняя тарелка, т.е. тарелка на вершине стека. Хорошим примером будет также служить железнодорожный тупик, в который можно составлять вагоны.
Использование стека в программировании
Стек применяется довольно часто, причем в самых разных ситуациях. Объединяет их следующая цель: нужно сохранить некоторую работу, которая еще не выполнена до конца, при необходимости переключения на другую задачу. Стек используется для временного сохранения состояния не выполненного до конца задания. После сохранения состояния компьютер переключается на другую задачу. По окончании ее выполнения состояние отложенного задания восстанавливается из стека, и компьютер продолжает прерванную работу.
Почему именно стек используется для сохранения состояния прерванного задания? Предположим, что компьютер выполняет задачу A . В процессе ее выполнения возникает необходимость выполнить задачу B . Состояние задачи A запоминается, и компьютер переходит к выполнению задачи B . Но ведь и при выполнении задачи B компьютер может переключиться на другую задачу C , и нужно будет сохранить состояние задачи B , прежде чем перейти к C . Позже, по окончании C будет сперва восстановлено состояние задачи B , затем, по окончании B , — состояние задачи A . Таким образом, восстановление происходит в порядке, обратном сохранению, что соответствует дисциплине работы стека.
Стек позволяет организовать рекурсию, т.е. обращение подпрограммы к самой себе либо непосредственно, либо через цепочку других вызовов. Пусть, например, подпрограмма A выполняет алгоритм, зависящий от входного параметра X и, возможно, от состояния глобальных данных. Для самых простых значений X алгоритм реализуется непосредственно. В случае более сложных значений X алгоритм реализуется как сведение к применению того же алгоритма для более простых значений X . При этом подпрограмма A обращается сама к себе, передавая в качестве параметра более простое значение X . При таком обращении предыдущее значение параметра X , а также все локальные переменные подпрограммы A сохраняются в стеке. Далее создается новый набор локальных переменных и переменная, содержащая новое (более простое) значение параметра X . Вызванная подпрограмма A работает с новым набором переменных, не разрушая предыдущего набора. По окончании вызова старый набор локальных переменных и старое состояние входного параметра X восстанавливаются из стека, и подпрограмма продолжает работу с того места, где она была прервана.
На самом деле даже не приходится специальным образом сохранять значения локальных переменных подпрограммы в стеке. Дело в том, что локальные переменные подпрограммы (т.е. ее внутренние, рабочие переменные , которые создаются в начале ее выполнения и уничтожаются в конце) размещаются в стеке, реализованном аппаратно на базе обычной оперативной памяти. В самом начале работы подпрограмма захватывает место в стеке под свои локальные переменные, этот участок памяти в аппаратном стеке называют обычно блок локальных переменных или по-английски frame ( "кадр "). В момент окончания работы подпрограмма освобождает память, удаляя из стека блок своих локальных переменных.
Кроме локальных переменных, в аппаратном стеке сохраняются адреса возврата при вызовах подпрограмм. Пусть в некоторой точке программы A вызывается подпрограмма B. Перед вызовом подпрограммы B адрес инструкции, следующей за инструкцией вызова B , сохраняется в стеке. Это так называемый адрес возврата в программу A . По окончании работы подпрограмма B извлекает из стека адрес возврата в программу A и возвращает управление по этому адресу. Таким образом, компьютер продолжает выполнение программы A , начиная с инструкции, следующей за инструкцией вызова. В большинстве процессоров имеются специальные команды, поддерживающие вызов подпрограммы с предварительным помещением адреса возврата в стек и возврат из подпрограммы по адресу, извлекаемому из стека. Обычно команда вызова назывется call , команда возврата — return .
В стек помещаются также параметры подпрограммы или функции перед ее вызовом. Порядок их помещения в стек зависит от соглашений, принятых в языках высокого уровня. Так, в языке Си или C++ на вершине стека лежит первый аргумент функции, под ним второй и так далее. В Паскале все наоборот, на вершине стека лежит последний аргумент функции. (Поэтому, кстати, в Си возможны функции с переменным числом аргументов, такие, как printf , а в Паскале нет.)
В Фортране-4, одном из самых старых и самых удачных языков программирования, аргументы передаются через специальную область памяти, которая может располагаться не в стеке, поскольку до конца 70-х годов XX века еще существовали компьютеры вроде IBM 360 или ЕС ЭВМ без аппаратной реализации стека. Адреса возврата также сохранялись не в стеке, а в фиксированных для каждой подпрограммы ячейках памяти. Программисты называют такую память статической в том смысле, что статические переменные занимают всегда одно и то же место в памяти в любой момент работы программы. При использовании только статической памяти рекурсия невозможна, поскольку при новом вызове предыдущие значения локальных переменных разрушаются. В эталонном Фортране-4 использовались только статические переменные, а рекурсия была запрещена. До сих пор язык Фортран широко используется в научных и инженерных расчетах, однако, современный стандарт Фортрана-90 уже вводит стековую память, устраняя недостатки ранних версий языка.
Реализация стека на базе массива
Реализация стека на базе массива является классикой программирования. Иногда даже само понятие стека не вполне корректно отождествляется с этой реализацией.
Базой реализации является массив размера N , таким образом, реализуется стек ограниченного размера, максимальная глубина которого не может превышать N . Индексы ячеек массива изменяются от 0 до N - 1 . Элементы стека хранятся в массиве следующим образом: элемент на дне стека располагается в начале массива, т.е. в ячейке с индексом 0. Элемент, расположенный над самым нижним элементом стека, хранится в ячейке с индексом 1, и так далее. Вершина стека хранится где-то в середине массива. Индекс элемента на вершине стека хранится в специальной переменной, которую обычно называют указателем стека (по-английски Stack Pointer или просто SP).
Когда стек пуст, указатель стека содержит значение минус единица. При добавлении элемента указатель стека сначала увеличивается на единицу, затем в ячейку массива с индексом, содержащимся в указателе стека, записывается добавляемый элемент. При извлечении элемента из стека сперва содержимое ячейки массива с индексом, содержащимся в указателе стека, запоминается во временной переменной в качестве результата операции, затем указатель стека уменьшается на единицу.
В приведенной реализации стек растет в сторону увеличения индексов ячеек массива. Часто используется другой вариант реализации стека на базе вектора, когда дно стека помещается в последнюю ячейку массива, т.е. в ячейку с индексом N - 1 . Элементы стека занимают непрерывный отрезок массива, начиная с ячейки, индекс которой хранится в указателе стека, и заканчивая последней ячейкой массива. В этом варианте стек растет в сторону уменьшения индексов. Если стек пуст, то указатель стека содержит значение N (которое на единицу больше, чем индекс последней ячейки массива).

Итак, начнем. Как только мы вызываем функцию, в стеке для нее создается стековый кадр. Стековый кадр содержит локальные переменные, а также аргументы, которые были переданы вызывающей функцией. Помимо этого кадр содержит служебную информацию, которая используется вызванной функцией, чтобы в нужный момент возвратить управление вызвавшей функции. Точное содержание стека и схема его размещения в памяти могут быть разными в зависимости от процессорной архитектуры и используемой конвенции вызова. В данной статье мы рассматриваем стек на архитектуре x86 с конвенцией вызова, принятой в языке C (cdecl). На рисунке вверху изображен стековый кадр, разместившийся у верхушки стека.
Сразу бросаются в глаза три процессорных регистра. Указатель стека, esp, предназначается для того, чтобы указывать на верхушку стека. Вплотную к верхуше всегда находится объект, который был добавлен в стек, но еще оттуда не снят. Точно также в реальной жизни обстоят дела со стопкой тарелок или пачкой 100-долларовых банкнот.
Хранимый в регистре esp адрес изменяется по мере того, как объекты добавляются и снимаются со стека, однако он всегда указывает на последний добавленный и еще не снятый со стека объект. Многие процессорные инструкции изменяют значение регистра esp как побочный результат своего выполнения. Реализовать работу со стеком без регистра esp было бы проблематично.
В случае с процессорами Intel, ровно как и со многими другими архитетурами, стек растет в направлении меньших адресов памяти. Поэтому верхушка, в данном случае, соответствует наименьшему адресу в стеке, по которому хранятся валидные используемые данные: в нашем случае это переменная local_buffer. Думаю, должно быть понятно, что означает стрелка от esp к local_buffer. Здесь все, как говорится, по делу – стрелка указывает точно на первый байт, занимаемый local_buffer, и это соответствует тому адресу, который хранится в регистре esp.
Далее на очереди еще один регистр, используемый для отслеживания позиций в стеке – регистр ebp – базовый указатель или указатель базы стекового кадра. Данный регистр предназначен для того, чтобы указывать на позицию в стековом кадре. Благодаря регистру ebp текущая функция всегда имеет своего рода точку отсчёта для доступа к аргументам и локальным переменным. Хранимый в регистре адрес изменяется, когда функция начинает или прекращает выполнение. Мы можем довольно просто адресовать любой объект в стековом кадре как смещение относительно ebp, что и показано на рисунке.
В отличии от esp, манипуляции с регистром ebp осуществляется в основном самой программой, а не процессором. Иногда можно добиться выигрыша в производительности просто отказавшись от страндартного использования регистра ebp – за это отвечают некоторые флаги компилятора. Ядро Linux – пример того, где используется такой прием.
Наконец, регистр eax традиционно используется для хранения данных, возвращаемых вызвавшей функции — это высказывание справедливо для большинства поддерживаемых в языке C типов.
Теперь давайте разберем данные, содержащиеся в стековом кадре. Рисунок показывает точное побайтовое содержимое кадра, c направлением роста адресов слево-направо – это то, что мы обычно видим в отладчике. А вот и сам рисунок:

Локальная переменная local_buffer – это массив байт, представляющий собой нуль-терминированную ASCII-строку; такие строки — неизменный атрибут всех программ на C. Размер строки — 7 байт, и, скорее всего, она была получена в результате клавиатурного ввода или чтения из файла. В нашем массиве может храниться 8 байт и, следовательно, один байт остается неиспользуемым. Значение этого байта неизвестно. Дело в том, что, данные то и дело добавлются и снимаются со стека, и в этом «бесконечном танце операции добавления и снятия» никогда нельзя знать заранее, что содержит память, пока не осуществишь в нее запись. Компилятор языка C не обременяет себя тем, чтобы иницилизировать стековый кадр нулями. Поэтому содержащиеся там данные заранее неизвестны и являются в некоторой степени случайными. Уж сколько крови попило такое поведение компилятора у программистов!
Идем далее. local1 – 4-байтовое целое число, и на рисунке видно содержимое каждого байта. Кажется, что это большое число – только взгляните на все эти нули после восьмерки, однако здесь наша интуиция сослужила нам дурную службу.
Процессоры Intel используют прямой порядок байтов (дословно «остроконечный»), и это значит, что числа хранятся в памяти начиная с младшего байта. Иными словами, самый младший значащий байт хранится в ячейке памяти с наименьшим адресом. На рисунках и схемах байты многобайтовых чисел традиционно изображаются в порядке слева-направо. В случае с прямым порядком байт, самый младший значащий байт будет изображен в крайней левой позиции, что отличается от привычного нам способа представления и записи чисел.
Неплохо знать о том, что вся эта «остроконечная / тупоконечная» терминология восходит к произведению Джонатана Свифта «Путешествия Гулливера». Подобно тому, как жители Лилипутии чистили яйцо с острого конца, процессоры Intel тоже обрабатывают числа начиная с младшего байта.
Таким образом, переменная local1 в действительности хранит число 8 (да-да, прям как количество щупалец у осьминога). Что касается param1, то там во втором от начала октете изображена двойка, поэтому в результате получаем число 2 * 256 = 512 (мы умножаем на 256, потому что каждый октет – это диапазон от 0 до 255). param2 хранит число 1 * 256 * 256 = 65536.
Служебная информация стекового кадра включает в себя два компонента: адрес стекового кадра вызвавшей функции (на рисунке — saved ebp) и адрес инструкции, куда необходимо передать управление по завершении данной функции (на рисунке – return address). Эта информация делает возможным возвращение управления, и следовательно, дальнейшее выполнение программы как будто никакого вызова и не было.
Теперь давайте рассмотрим процесс «рождения» стекового кадра. Стек растет не в том направлении, которое обычно ожидают увидеть, и сначала это может сбивать с толку. Например, чтобы увеличить стек на 8 байт, программист вычитает 8 из значения, хранимого в регистре esp. Вычитание – странный способ что-либо увеличить. Забавно, не правда ли!
Возьмем для примера простенькую программу на C:

Предположим, программу запустили без параметров в командной строке. При выполнении «сишной» программы в Linux, первым делом управление получает код, содержащийся в стандартной библиотеке C. Этот код вызовет функцию main() нашей программы, и, в данном случае, переменная argc будет равна 0 (на самом деле, переменная будет равна «1», что соответствует параметру — названию, под которым запущена программа, но давайте для простоты это момент сейчас опустим). При вызове функции main() происходит следующее:

Шаг 2 и 3, а также 4 (описан ниже) соответствуют последовательности инструкций, которая называется «прологом» и встречается практически в любой функции: текущее значение регистра ebp помещается в стек, затем значение регистра esp копируется в регистр ebp, что фактически приводит к созданию нового стекового кадра. Пролог функции main() такой же, как и других функций, с той лишь разницей, что при начале выполнения программы регистр ebp содержит нули.
Если взглянуть на то, что располагается в стеке под argc, то будут видны еще некоторые данные – указатель на строку-название, под которым программа была запущена, указатели на строки-параметры, переданные через командную строку (традиционный C-массив argv), а также указатели на переменные среды и непосредствено сами эти переменные. Однако, на данном этапе нам это не особо важно, так что продолжаем двигаться по направлению к вызову функции add():

Функция main() сначала вычетает 12 из текущего значения в регистре esp для выделения нужного ей места и затем присваивает значения переменным a и b. Значения, хранимые в памяти, изображены на рисунке в шестнадцатеричной форме и с прямым порядком байтов – как и в любом отладчике. После присвоения значений, функция main() вызывает функцию add(), и та начинает выполняться:

Чем дальше, тем интересней! Перед нами еще один пролог, однако теперь уже четко видно как последовательность стековых кадров в стеке оказывается организованной в связный список, и регистр ebp хранит ссылку на первый элемент этого списка. Вот с опорой на это и реализованы трассировка стека в отладчиках и Exception-объекты высокоуровневых языков. Обратим внимание на типичную для начала выполнения функции ситуацию, когда регистры ebp и esp указывают в одно и то же место. И еще раз вспомним, что для наращивания стека осуществляется вычитание из значения, хранящегося в регистре esp.
Важно заметить следующее — при копировании данных из регистра ebp в память происходит непонятное на первый взгляд изменение порядка хранения байтов. Дело в том, что для регистров такого понятия как «порядок байтов» не существует. Иными словами, рассматривая регистр, мы не можем говорить о том, что в нем есть «старшие или младшие адреса». Поэтому отладчики показывают значения, хранимые в регистрах, в наиболее удобном для человеческого восприятия виде: от более значимых к менее значимым цифрам. Таким образом, имея стандартную нотацию «слева-направо» и «little-endian» машину, создается обманчивое впечатление, что в результате операции копирования из регистра в память байты поменяли порядок на обратный. Я хотел, чтобы картина, показанная на рисунках была максимально приближена к реальности – отсюда и такие рисунки.
Теперь, когда самая сложная часть у нас позади, осуществляем сложение:

Здесь у нас появляется неизвестный регистр, чтобы помочь со сложением, но в целом ничего особенного или удивительного. Функция add() выполняет вою работу и, начиная с этого момента все действия в стеке будут осуществляться в обратном порядке. Но об этом расскажем как-нибудь в другой раз.
Все, кто дочитал до этих строк, заслуживает подарок за стойкость, поэтому я с огромной гиковской гордостью презентую Вам вот эту единую схемку, на которой изображены все вышеописанные шаги.
Не так уж все и сложно, стоит только разложить все по полочкам. Кстати, маленькие квадратики очень сильно помогают понимаю. Без «маленьких квадратиков» в информатике вообще никуда. Надеюсь, мои рисунки позволили составить ясную картину происходящего, на которой интуитивно просто показан и рост стека, и изменения содержимого памяти. При ближайшем рассмотрении, наше программное обеспечение не так уж и сильно отличается от простой машины Тьюринга.
На этом завершается первая часть нашего путешествия по стеку. В будущих статьях нас ждут новые погружения в «байтовые» дебри, после чего посмотрим, что же на этом фундаменте способны выстроить высокоуровневые языки программирования. Увидимся на следующей неделе.
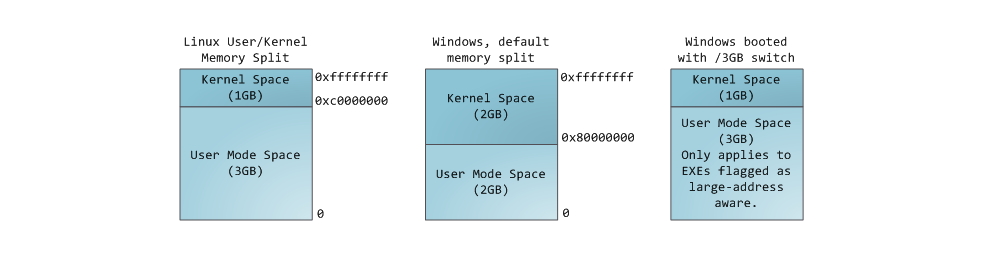
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
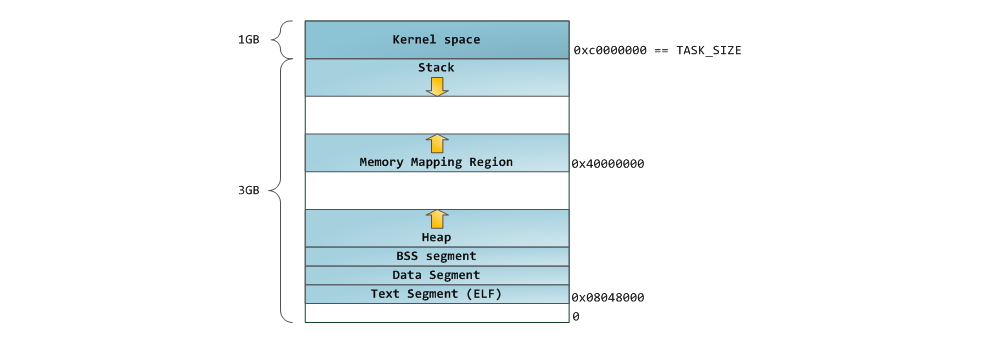
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент. Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
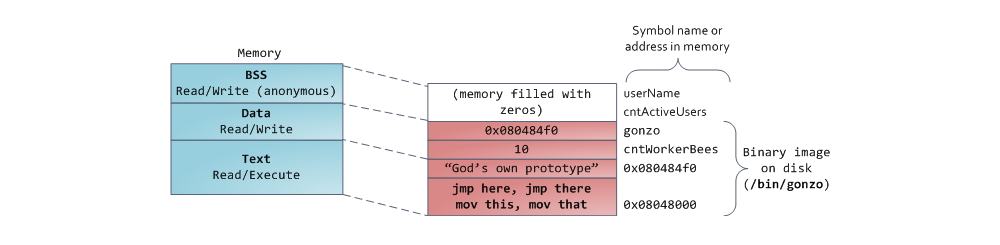
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:
Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.
Привет, я студент второго курса технического университета. После пропуска нескольких пар программирования по состоянию здоровья, я столкнулся с непониманием таких тем, как «Стек» и «Очередь». Путем проб и ошибок, спустя несколько дней, до меня наконец дошло, что это такое и с чем это едят. Чтобы у вас понимание не заняло столько времени, в данной статье я расскажу о том что такое «Стек», каким образом и на каких примерах я понял что это такое. Если вам понравится, я напишу вторую часть, которая будет затрагивать уже такое понятие, как «Очередь»
На Википедии определение стека звучит так:
Стек (англ. stack — стопка; читается стэк) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Поэтому первое, на чем бы я хотел заострить внимание, это представление стека в виде вещей из жизни. Первой на ум мне пришла интерпретация в виде стопки книг, где верхняя книга — это вершина.

На самом деле стек можно представить в виде стопки любых предметов будь то стопка листов, тетрадей, рубашек и тому подобное, но пример с книгами я думаю будет самым оптимальным.
Итак, из чего же состоит стек.
Стек состоит из ячеек(в примере — это книги), которые представлены в виде структуры, содержащей какие-либо данные и указатель типа данной структуры на следующий элемент.
Сложно? Не беда, давайте разбираться.

На данной картинке схематично изображен стек. Блок вида «Данные/*next» и есть наша ячейка. *next, как мы видим, указывает на следующий элемент, другими словами указатель *next хранит адрес следующей ячейки. Указатель *TOP указывает на вершину стек, то есть хранит её адрес.
С теорией закончили, перейдем к практике.
Для начала нам нужно создать структуру, которая будет являться нашей «ячейкой»
Новичкам возможно будет не понятно, зачем наш указатель — типа comp, точнее сказать указатель типа структуры comp. Объясню, для того чтобы указатель *next мог хранить структуру comp, ей нужно обозначить тип этой структуры. Другими словами указать, что будет хранить указатель.
После того как у нас задана «Ячейка», перейдем к созданию функций.
Функции
Функция удаления элемента из «Стека» по данным
Данная функция будет удалять элемент из стека, если число Data ячейки(q->Data) будет равна числу, которое мы сами обозначим.
Здесь могут быть такие варианты:
- Ячейка, которую нам нужно удалить является вершиной стека
- Ячейка, которую нам нужно удалить находится в конце, либо между двумя ячейками
Указатель q в данном случае играет такую же роль, что и указатель в блокноте, он бегает по всему стеку, пока не станет равным NULL(while(q != NULL)), другими словами, пока стек не закончится.
Для лучшего понимания удаления элемента проведем аналогии с уже привычной стопкой книг. Если нам нужно убрать книгу сверху, мы её убираем, а книга под ней становится верхней. Тут то же самое, только в начале мы должны определить, что следующий элемент станет вершиной *top = q->next; и только потом удалить элемент free(q);
Если книга, которую нужно убрать находится между двумя книгами или между книгой и столом, предыдущая книга ляжет на следующую или на стол. Как мы уже поняли, книга у нас-это ячейка, а стол получается это NULL, то есть следующего элемента нет. Получается так же как с книгами, мы обозначаем, что предыдущая ячейка будет связана с последующей prev->next = q->next;, стоит отметить что prev->next может равняться как ячейке, так и нулю, в случае если q->next = NULL, то есть ячейки нет(книга ляжет на стол), после этого мы очищаем ячейку free(q).
Так же стоит отметить, что если не провести данную связь, участок ячеек, который лежит после удаленной ячейки станет недоступным, так как потеряется та самая связь, которая соединяет одну ячейку с другой и данный участок просто затеряется в памяти
Функция создания «Стека»/добавления элемента в «Стек»
При добавлении элемента у нас возникнет две ситуации:
- Стек пуст, и нужно создать его
- Стек уже есть и нужно лишь добавить в него новый элемент
Разберем чуть чуть по-подробнее.
Во-первых, почему функция принимает **top, то есть указатель на указатель, для того чтобы вам было наиболее понятно, я оставлю рассмотрение этого вопроса на потом. Во-вторых, по-подробнее поговорим о q->next = *top и о том, что же означает ->.
-> означает то, что грубо говоря, мы заходим в нашу структуру и достаем оттуда элемент этой структуры. В строчке q->next = *top мы из нашей ячейки достаем указатель на следующий элемент *next и заменяем его на указатель, который указывает на вершину стека *top. Другими словами мы проводим связь, от нового элемента к вершине стека. Тут ничего сложного, все как с книгами. Новую книгу мы кладем ровно на вершину стопки, то есть проводим связь от новой книги к вершине стопки книг. После этого новая книга автоматически становится вершиной, так как стек не стопка книг, нам нужно указать, что новый элемент — вершина, для этого пишется: *top = q;.
Функция вывода данных стека на экран
Самая простая функция:
Здесь я думаю все понятно, хочу сказать лишь то, что q нужно воспринимать как бегунок, он бегает по всем ячейкам от вершины, куда мы его установили вначале: *q = top;, до последнего элемента.
Главная функция
Хорошо, основные функции по работе со стеком мы записали, вызываем.
Посмотрим код:
Вернемся к тому, почему же в функцию мы передавали указатель на указатель вершины. Дело в том, что если бы мы ввели в функцию только указатель на вершину, то «Стек» создавался и изменялся только внутри функции, в главной функции вершина бы как была, так и оставалась NULL. Передавая указатель на указатель мы изменяем вершину *top в главной функции. Получается если функция изменяет стек, нужно передавать в нее вершину указателем на указатель, так у нас было в функции s_push,s_delete_key. В функции s_print «Стек» не должен изменяться, поэтому мы передаем просто указатель на вершину.
Вместо цифр 1,2,3,4,5 можно так-же использовать переменные типа int.
Полный код программы:
Так как в стек элементы постоянно добавляются на вершину, выводиться элементы будут в обратном порядке
В заключение хотелось бы поблагодарить за уделенное моей статье время, я очень надеюсь что данный материал помог некоторым начинающим программистам понять, что такое «Стек», как им пользоваться и в дальнейшем у них больше не возникнет проблем. Пишите в комментариях свое мнение, а так же о том, как мне улучшить свои статьи в будущем. Спасибо за внимание.
Стеком называется структура данных, организованная по принципу LIFO («Last In — First Out» или «последним пришёл — первым ушёл»). Стек является неотъемлемой частью архитектуры процессора и поддерживается на аппаратном уровне: в процессоре есть специальные регистры (SS, BP, SP) и команды для работы со стеком.
Обычно стек используется для сохранения адресов возврата и передачи аргументов при вызове процедур (о процедурах в следующей части), также в нём выделяется память для локальных переменных. Кроме того, в стеке можно временно сохранять значения регистров.
Схема организации стека в процессоре 8086 показана на рисунке:

Стек располагается в оперативной памяти в сегменте стека, и поэтому адресуется относительно сегментного регистра SS. Шириной стека называется размер элементов, которые можно помещать в него или извлекать. В нашем случае ширина стека равна двум байтам или 16 битам. Регистр SP (указатель стека) содержит адрес последнего добавленного элемента. Этот адрес также называется вершиной стека. Противоположный конец стека называется дном 🙂
Дно стека находится в верхних адресах памяти. При добавлении новых элементов в стек значение регистра SP уменьшается, то есть стек растёт в сторону младших адресов. Как вы помните, для COM-программ данные, код и стек находятся в одном и том же сегменте, поэтому если постараться, стек может разрастись и затереть часть данных и кода (надеюсь, с вами такой беды не случится :)).
Для стека существуют всего две основные операции:
- добавление элемента на вершину стека (PUSH);
- извлечение элемента с вершины стека (POP);
Добавление элемента в стек
Выполняется командой PUSH. У этой команды один операнд, который может быть непосредственным значением, 16-битным регистром (в том числе сегментым) или 16-битной переменной в памяти. Команда работает следующим образом:
- значение в регистре SP уменьшается на 2 (так как ширина стека — 16 бит или 2 байта);
- операнд помещается в память по адресу в SP.

push -5 ;Поместить -5 в стек push ax ;Поместить AX в стек push ds ;Поместить DS в стек push [x] ;Поместить x в стек (x объявлен как слово) push word [bx] ;Поместить в стек слово по адресу в BX
Существуют ещё 2 команды для добавления в стек. Команда PUSHF помещает в стек содержимое регистра флагов. Команда PUSHA помещает в стек содержимое всех регистров общего назначения в следующем порядке: АХ, СХ, DX, ВХ, SP, BP, SI, DI (значение DI будет на вершине стека). Значение SP помещается то, которое было до выполнения команды. Обе эти команды не имеют операндов.
Извлечение элемента из стека
Выполняется командой POP. У этой команды также один операнд, который может быть 16-битным регистром (в том числе сегментым, но кроме CS) или 16-битной переменной в памяти. Команда работает следующим образом:
- операнд читается из памяти по адресу в SP;
- значение в регистре SP увеличивается на 2.
Обратите внимание, что извлеченный из стека элемент не обнуляется и не затирается в памяти, а просто остаётся как мусор. Он будет перезаписан при помещении нового значения в стек.

pop cx ;Поместить значение из стека в CX pop es ;Поместить значение из стека в ES pop [x] ;Поместить значение из стека в переменную x pop word [di] ;Поместить значение из стека в слово по адресу в DI
Соответственно, есть ещё 2 команды. POPF помещает значение с вершины стека в регистр флагов. POPA восстанавливает из стека все регистры общего назначения (но при этом значение для SP игнорируется).
Пример программы
Имеется двумерный массив — таблица 16-битных значений со знаком размером n строк на m столбцов. Программа вычисляет сумму элементов каждой строки и сохраняет результат в массиве sum. Первый элемент массива будет содержать сумму элементов первой строки, второй элемент — сумму элементов второй строки и так далее.
use16 ;Генерировать 16-битный код org 100h ;Программа начинается с адреса 100h jmp start ;Переход к метке start ;---------------------------------------------------------------------- ; Данные n db 4 ;Количество строк m db 5 ;Количество столбцов ;Двумерный массив - таблица c данными table: dw 12,45, 0,82,34 dw 46,-5,87,11,56 dw 35,21,77,90,-9 dw 44,13,-1,99,32 sum rw 4 ;Массив для сумм каждой строки ;---------------------------------------------------------------------- start: movzx cx,[n] ;Счётчик строк mov bx,table ;BX = адрес таблицы mov di,sum ;DI = адрес массива для сумм xor si,si ;SI = смещение элемента от начала таблицы rows: xor ax,ax ;Обнуление AX. В AX будет считаться сумма push cx ;Сохранение значения CX movzx cx,[m] ;Инициализация CX для цикла по строке calc_sum: add ax,[bx+si] ;Прибавление элемента строки add si,2 ;SI = смещение следующего элемента loop calc_sum ;Цикл суммирования строки pop cx ;Восстановление значения CX mov [di],ax ;Сохранение суммы строки add di,2 ;DI = адрес следующей ячейки для суммы строки loop rows ;Цикл по всем строкам таблицы mov ax,4C00h ;\ int 21h ;/ Завершение программы
Как видите, в программе два вложенных цикла: внешний и внутренний. Внешний цикл — это цикл по строкам таблицы. Внутренний цикл вычисляет сумму элементов строки. Стек здесь используется для временного хранения счётчика внешнего цикла. Перед началом внутреннего цикла CX сохраняется в стеке, а после завершения восстанавливается. Такой приём можно использовать для программирования и большего количества вложенных циклов.
Turbo Debugger
В отладчике Turbo Debugger стек отображается в нижней правой области окна CPU. Левый столбец чисел — адреса, правый — данные. Треугольник указывает на вершину стека, то есть на тот адрес, который содержится в регистре SP. Если запустить программу в отладчике, то можно увидеть, как работают команды «push cx» и «pop cx».

Упражнение
Объявите в программе строку «$!olleH». Напишите код для переворачивания строки с использованием стека (в цикле поместите каждый символ в стек, а затем извлеките в обратном порядке). Выведите полученную строку на экран. Свои результаты пишите в комментариях 🙂
Читайте также: