
Сколько транзисторов в видеокарте
Между тем, многие спрашивают - а как видеокарта может стоить 30, 50, 100 тысяч рублей? И что в ней такого за эту цену? Вот сегодня как раз и расскажу - почему она столько стоит и какие функции выполняет. Для простоты буду объяснять на примере.
А что отвечает за картинку на мониторе?
Взглянем на плату. Первое, что бросается в глаза - видеочип. Он тут промаркирован как GA102, где GA - поколение (Ampere, первая буква, вероятно, обозначает "Graphics", но тут я не уверен). Дальше идут техпроцесс - размер одного полупроводника (транзистора) в кристалле (в нашем случае - 8 нанометров), а также количество этих самых транзисторов в составе кристалла.
Так на плате выглядит ГП (в примере использовал плату от 3090, так нагляднее)
Тактовая частота - показатель, который обозначает количество тактов, которые делает устройство в секунду (удивительно, не правда ли). Судить по производительности видеокарты по тактовой частоте нельзя, так как производительность будет зависеть от эффективности архитектуры, то есть - от того, как эффективно работают все транзисторы внутри чипа.
Видеопамять служит для хранения все информации, которая может понадобиться ГП: карты освещения, текстур, сами текстуры
Шейдерные блоки, они же - универсальные процессоры, они же - ядра, они же - CUDA-ядра (у Nvidia) - "ядра" видеокарты, которые способны выполнять широкий спектр задач. Каждое из таких ядер по своему строению отдалённо напоминает строение ядра процессора, только память у ядер выведена по блокам (имею в виду кэш). Эти ядра занимаются чем угодно - например, вычислениями (привет, майнеры).
Так выглядит ГП внутри
TMU (Texture Mapping Unit) - блок наложения текстур. Занимается, собственно, наложением текстур на сетку изображения, когда она сформирована процессором (удивительно X2).
Интерфейсы ввода-вывода видеокарты
ROP (Render Output Unit) - это конвейер растровых операций. Если объяснить очень просто - он отвечает за постобработку изображения (блум, виньетка и так далее). Если чуть проще - эти блоки записывают данные от видеокарты в память, занимаются их смешением (то есть видеокарта высчитала изображение и постобработку, например, а ROP наложил одно на другое).
По ходу дела вы видели изображения, под которыми я многое объяснил. Поэтому перечитайте их еще раз, там я рассказал про строение видеокарты, а я пока напишу про то, откуда такой ценник.
Так как же повышалась эффективность GPU?
Вышесказанное довольно убедительно показало, что за прошедшие годы AMD и Nvidia повысили производительность на единицу плотности кристалла и на единицу TDP. Иногда рывки в производительности были впечатляющими.
Взять к примеру Nvidia G92 и TU102. Первый из них это сердце GeForce 8800 GT и 9800 GTX, на его кристалле площадью 324 мм2 размещено 754 миллиона транзисторов. Когда он появился в октябре 2007 года, он был высоко оценен за свою производительность и экономичность.
Через одиннадцать лет Nvidia предложила нам TU102 в виде GeForce RTX 2080 Ti. Этот процессор имеет почти 19 миллиардов транзисторов на площади 754 мм2 – то есть, в 25 раз больше микроскопических компонентов на поверхности, которая лишь в 2,3 раза больше.
Всё это не было бы возможным без усилий TSMC по совершенствованию своей производственной технологии. G92 в 8800 GT был построен на 65-нм техпроцессе, тогда как для производства новейшего TU102 используется специальный масштаб 12FFN. Названия этих методов производства на самом деле ничего не говорят нам о разнице между ними, но зато говорят показатели GPU. Плотность кристалла у нового процессора –24,67 миллиона транзисторов на мм2, тогда как у старого – 2,33 млн.
Более чем десятикратное увеличение плотности кристалла в основном и обуславливает огромную разницу в эффективности двух GPU. Меньшие логические блоки требуют меньше энергии для работы, а сокращение длины проводников между ними увеличивает и скорость обмена данными. Наряду с улучшением производства кремниевых чипов (уменьшение количества дефектов и совершенствование изоляции), всё это приводит к возможности работать на более высоких тактовых частотах при той же мощности, или наоборот – использовать меньшее энергопотребление при той же тактовой частоте.

Процессор AMD Vega 10 с двумя чипами HBM-памяти по 4 Гб слева.
Кстати о частотах. Давайте сравним RV670 от ноября 2007 года в Radeon HD 3870 с Vega 10 в Radeon RX Vega 64, выпущенной в августе 2017 года.
Первый имеет фиксированную тактовую частоту около 775 МГц, тогда как последний имеет как минимум три доступные частоты:
- 850 МГц – при обычной работе на компьютере, 2D-обработка.
- 1250 МГц – для сложных 3D-задач (базовая частота, «base clock»)
- 1550 МГц – для переменных легких/средних 3D-нагрузок («boost clock»)
Мы говорим «как минимум», потому что видеокарта динамически изменяет свою тактовую частоту и потребляемую мощность, между вышеуказанными значениями, в зависимости от текущей рабочей нагрузки и рабочей температуры. Это сегодня мы воспринимаем это как само собой разумеющееся, но 13 лет назад такого управления частотами просто не существовало. Оно, правда, никак не влияет на результаты наших анализов эффективности, поскольку мы брали только пиковую производительность обработки (т.е. на максимальных частотах), но оно влияет на оценку работы карты в глазах потребителя.
Но самым главным поводом постоянного повышения эффективности GPU в течение многих лет послужили изменения в использовании процессора как такового. В июне 2008 года лучшие суперкомпьютеры в мире были оснащены центральными процессорами от AMD, IBM и Intel; спустя одиннадцать лет к этой компании присоединился ещё один производитель: Nvidia.

Nvidia Tesla P100 с процессором GP100
Их процессоры GV100 и GP100 были разработаны почти исключительно для вычислительного сегмента рынка, в них заложено множество ключевых архитектурных функций, и многие из них очень похожи на CPU. Например, их внутренняя память (кэш) напоминает типичный серверный CPU:
- Регистровый файл (register file) на 1 SM = 256 кБ
- L0 кэш на 1 SM = 12 кБ инструкции
- L1 кэш на 1 SM = 128 кБ инструкции/данные
- L2 кэш на GPU = 6 МБ
Для сравнения: Intel Xeon E5-2692 v2, который использовался во многих вычислительных серверах:
- L1 кэш на ядро = 32 кБ инструкции/данные
- L2 кэш на ядро = 256 кБ
- L3 кэш на CPU = 30 МБ
Логические блоки внутри современного GPU поддерживают ряд форматов данных; некоторые имеют специализированные блоки для целочисленных вычислений, вычислений с плавающей точкой и матриц, в то время как другие имеют сложные структуры сразу для всех видов вычислений. Блоки соединены с кэшем и внутренней памятью широкими высокоскоростными интерконнектами. Безусловно, все эти нововведения положительно сказываются на обработке 3D-графики, но для большинства игр они избыточны. Но такие GPU разрабатывались не только для графики, а для более широкого спектра рабочих нагрузок, и для них есть специальное название: GPU общего назначения (GPGPU).
Machine Learning и Data Mining – это те две области, которые извлекли наибольшую выгоду из разработки GPGPU и поддерживаемых пакетов программного обеспечения и API (например, CUDA от Nvidia, FireStream от AMD, а также OpenCL), поскольку они объединяют в себе множество сложных массивно-параллельных вычислений.
Большие GPU, с тысячами унифицированных шейдерных блоков, идеально подходят для таких задач, и AMD с Nvidia (а теперь ещё и Intel присоединяется к их веселью) вкладывают миллиарды
долларов в разработку чипов, обеспечивающих все более высокую вычислительную производительность.

Первая дискретная видеокарта Intel за последние 20 лет. Превью видеокарт Intel Xe, часть 2
На данный момент обе компании разрабатывают универсальные архитектуры для своих GPU, которые могут использоваться в различных секторах рынка, как правило избегая создания полностью специфичных решений отдельно для графики и отдельно для вычислений. Это связано с тем, что основная часть прибыли от производства GPU по-прежнему поступает от продажи 3D-видеокарт, но уже неясно, сохранится ли такое положение дел в дальнейшем. Поскольку спрос на compute-мощности продолжает расти, вполне возможно, что AMD или Nvidia начнут выделять больше своих ресурсов на повышение эффективности чипов для этих рынков и меньше – на рендеринг.
Но что бы ни случилось дальше, мы знаем одно: на следующем этапе высокопроизводительные GPU с миллиардами транзисторов по-прежнему будут чуточку эффективнее своих предшественников. И это хорошая новость, независимо от того, кто это делает и для чего.
Транзисторы, которые не в чипе, а на самой видеокарте служат для преобразования питания. Из 12 вольт делают напряжение, необходимое для питания ядра. Чем мощнее видеокарта, тем больше их. Китайцы могут и сэкономить, но тогда на оставшиеся придется бОльшая нагрузка и соответственно - будут сильнее греться.
Хороший производитель старается всё убрать в микросхемы. И чем больше элементов на плате, тем хуже карта.
на что влияет длинна проводки у вас в квартире?
на что влияет количество букв в слове?
транзистор это просто радиодеталь, позволяющий входным сигналам управлять током в электрической цепи.
Ихаил Ыло Мастер (1297) это дает лишний геморрой производителям, которые их туда напаивают, и рассчитывают. судить о производительности карты по количеству транзисторов -имхо бред.
На увеличении вероятности отказа или выхода из строя. чем больше транзисторов, тем больше вероятность))))
markus mak-frank Искусственный Интеллект (293668) Да чем сложнее система тем больше вероятность выхода её из строя.
Для тебя, как и любого другого пользователя-ни на что, кроме цены :) Видеокарту выбирают не по количеству транзисторов, а по другим критериям.
ни один ответ НЕПРАВИЛЬНЫЙ. Все топовые видеокарты содержат максимальное количество транзисторов в ЧИПЕ! а не на плате, где питанием управляют MOSFETы. А обрезки Чипов в среднем на 30% меньше транзисторов и они стоят в бюджетных видеокартах. Из транзисторов формируется, правильно, логика и управление процессами заложенные драйверами (не путать с софтом). Так вот все транзисторы на Чипе - это потоковые процессоры, текстурные блоки, кэш, ROPы и еще там чего-то. Количество транзисторов влияет очень сильно на скорость прорисовки кадра, обработку треугольников из которых состоит объект вывода, сглаживание, освещение. А уже на втором месте стоит критерий частоты на которой работает Чип и память. Так вот видюха более старая но с набором логики из 7 млрд. транзисторов но с частотой Чипа 800 мгц за один плевок уделывает в тестах более современную видеокарту с чипом из 4 млрд. транзисторов, но работающую на частоте 1100 мгц.
Когда речь заходит о материнских платах, разговор практически никогда не обходится без того, сколько фаз питания процессора применено в той или иной модели. Этот параметр не часто указывается в спецификациях на материнскую плату, но непременно фигурирует в обзорах той или иной модели, да и на многочисленных форумах и обсуждениях системных плат и/или чипсетов о питании CPU речь заходит всегда. Иногда упоминание о количестве фаз присутствует в рекламных материалах или на коробке материнской платы. Фазы питания процессора – что это, что они делают, для чего нужны и сколько их вообще надо? Давайте разбираться.
Чем отличаются верхний и нижний транзисторы
Тут надо прояснить один момент. Нередко можно встретить разные конфигурации цепей VRM. Например, у MSI Z490-A Pro используется по одному транзистору OnSemi 4C029N в верхнем плече и 4C024N в нижнем. У первого максимальный ток равен 46 А, у нижнего - 78 А.
У Gigabyte X570 GAMING X конфигурация несколько иная - верхний транзистор один, ONSemi 4C10N (макс. ток до 40 А), а нижних сразу два, ONSemi 4C06N (макс. ток до 69 А каждый). В последнем случае используется схема 1H2L, т. е один верхний (high) транзистор и два нижних (low).
Зачем такой разброд и шатания? Здесь надо обратить внимание на условия работы этих транзисторов. У верхнего на входе 12 В, а на выходе около 1 В. При заданной мощности ток не особо велик, и составляет, предположим, несколько ампер, ну пусть даже десяток-другой в особо сложных случаях.
А что нижний транзистор? Его диапазон напряжений работы от 1 (примерно) вольта до нуля. При той же мощности токи, которые он должен выдерживать, гораздо выше. Потому и ставят более мощный силовой элемент, или даже пару.
Кстати, если посмотреть на схему силовой сборки, в которую заключены все силовые MOSFET вместе с драйвером, то элемент нижнего плеча изображается более крупным. Теперь понятно почему.
Может быть и такая ситуация, когда для цепей питания ядер процессоров используют схему 1H2L (один верхний транзистор и два нижних), а для питания SoC, графического чипа, используется более простая схема 1H1L, т. е. по одному транзистору в каждом плече.
В случае использования сборок, для ядер может использоваться одна модель силовых элементов, а для SoC другая. Например, на платы ASRock B550 Extreme4 установлены двенадцать Vishay SIC654 и пара Vishay SIC632. Хотя по максимальному току сборки одинаковые, все же сам элемент SIC632 несколько проще.
Встроенная графика не слишком обременительна в плане энергопотребления и до значений в десятки ампер тут дело обычно не доходит. Посему можно использовать меньшее количество элементов или более простые.
Кстати, дискретные элементы в цепях питания процессора используются в моделях материнских плат нижнего ценового диапазона. В материки среднего класса и в топовые модели ставят силовые сборки.
Немного про разъемы
Современные видеокарты оснащены несколькими портами, чтобы была возможность подключить более одного монитора. В свою же очередь каждый монитор имеет разный тип разъемов, о которых пользователю будет полезно узнать.

Video Graphics Array (adapter) – достаточно древняя 15-контактная штука синего цвета, которая специализировалась на выводе аналогового сигнала. Его особенностью было то, что на изображение могло повлиять разные вещи: длина провода (который состоял из 5 метров) или личные свойства видеокарты. Ранее был одним из основных, однако с появлением плоских мониторов стал сдавать свои позиции, ибо разрешение экрана увеличивалось, с чем не справлялся VGA. Используется и по сей день.
Питание видеокарты
Однако все пойдет по наклонной, если вы забудете учесть свой блок питания. Сразу можно сказать, что, если у вас 350w, то выбирать видеокарту нужно очень тщательно, так как современные версии очень требовательны к этому. Известно, что материнская плата не способна отдать нужное количество энергии для энергоёмких видеоадаптеров, что приводит к необходимости использования дополнительного питания.
Почему нельзя обойтись одной фазой
Одну из причин я уже назвал – сглаживание пульсаций выходного напряжения. Есть и еще как минимум одна причина – мощность. Используемые MOSFET-транзисторы, конденсаторы, дроссели имеют предел по максимальному току. Если взять для примера CPU, потребляющий 65 Вт при питающем напряжении в 1 В, ток будет исчисляться несколькими десятками ампер.
Так, используемые элементы могут быть рассчитаны на ток до 30, 40 или более ампер, но, скорее всего, это все равно будет меньше максимального потребления электроэнергии процессором. При этом должна быть возможность установки другого CPU, у которого потребление может оказаться больше, например, 95 Вт.
Для того, чтобы гарантированно обеспечить запас мощности, и используют несколько фаз. Тем самым заодно снижается нагрузка на каждую из них и, соответственно, их нагрев. Это дает возможность использовать большое количество процессоров.
Сколько фаз действительно необходимо? Скажем так, от 4 до 8 в зависимости от процессора и при отсутствии разгона. Этого более чем достаточно. Впрочем, большее их количество не так уж и плохо, особенно при использовании мощных «камней», да еще с разгоном. В разумных пределах, конечно.
Графический процессор (GPU)
GPU (графический процессор) – является «сердцем» видеокарты, который отвечает за математические расчеты изображения, выводящегося на экран. Иными словами – обработка графики. GPU по своим свойствам похож на центральный процессор (CPU) компьютера, однако предназначен для построения изображения.
Thunderbolt

Thunderbolt (бывший Light Peak) – это аппаратный интерфейс для периферийных устройств. Обладает высокой пропускной способностью и функциональностью. По легендам, создан, чтобы улучшить и превзойти USB. Раньше использовался только в продукции Apple. Можно использовать для подключения мониторов с разрешением в 4К.
Эффективность GPU: TDP vs количество транзисторов
Церемониться мы не будем, вот результаты:
Мы видим, что результаты довольно разбросанные, но имеют базовую закономерность: старые графические процессоры, такие как G80 или RV670, гораздо менее эффективны по сравнению с более современными решениями, такими как Vega 20 или GP102. Оно и понятно. В конце концов, чего бы стоили команды инженеров-электронщиков, изо всех сил старающихся постоянно создавать новые продукты, которые становились бы всё менее эффективными с каждым выпуском.
Но некоторые результаты представляют особый интерес. Прежде всего, это TU102 и GV100. Оба чипа сделаны Nvidia и используются в видеокартах GeForce RTX 2080 Ti и Titan V, соответственно.

Можно возразить, что ни один из них не был разработан для общепотребительского рынка. Особенно это касается GV100, поскольку он действительно предназначен для рабочих станций и вычислительных серверов. Поэтому, хотя они и являются самыми эффективными из всех процессоров, но они предназначены для специализированных рынков и стоят намного дороже стандартных.
Еще один GPU, который выделяется как белая ворона – это GP108. Этот чип от Nvidia чаще всего встречается в GeForce GT 1030 – недорогом продукте, выпущенном в 2017 году, и имеющем очень маленький размер. Процессор размером всего 74 мм2 с TDP всего 30 Вт. Однако его относительная производительность с плавающей точкой на самом деле не лучше, чем у Nvidia G80 – первого GPU с унифицированной шейдерной архитектурой (2006).

Графический процессор Nvidia G80. Источник
По другую сторону от GP108 находится чип AMD Fiji, который использовался в серии Radeon R9 Fury. Это получилось не слишком энергоэффективное решение, особенно учитывая, что использование HBM-памяти должно было помочь в этом отношении. Фиджи сильно греется, что плохо сказывается на экономичности полупроводников из-за возросшей утечки. Именно здесь потребляется электрическая энергия, а не в схеме как таковой. Все чипы имеют токи утечки, но с температурой скорость потерь увеличивается.
Но самым интересным моментом является, пожалуй, Navi 10. Это новейший GPU от AMD, производимый TSMC на их передовом 7-нм техпроцессе. В то же время, Vega 20 произведён на том же техпроцессе почти два года назад, но выглядит более эффективным. В чём же дело?

Под этими вентиляторами стоит GPU Vega 20. Источник
Vega 20 (AMD использовала его только в одной потребительской видеокарте – Radeon VII) был последним процессором, созданным AMD в архитектуре GCN (Graphics Core Next). Она объединяет огромное количество унифицированных шейдерных ядер в единый узел, в котором основное внимание уделено формату FP32. Однако программирование устройства для достижения этой производительности было нелегким делом, и ему не хватало гибкости.
Navi 10 использует новейшую архитектуру RDNA, которая решает эту проблему. Решение новое, созданное на относительно новом техпроцессе, поэтому можно ожидать повышения эффективности по мере того, как TSMC развивает свой техпроцесс, а AMD обновляет архитектуру.
Если брать во внимание только массовые продукты, то наиболее эффективные GPU на нашем графике – это GP102 и GP104. Это чипы Nvidia на архитектуре Pascal и мы найдём их в таких видеокартах как GeForce GTX 1080 Ti, GTX 1070 и GTX 1060. Рядом с GP102, не обозначенный меткой, расположился TU104. Это новейший Turing-чип от Nvidia, устанавливаемый в линейку GeForce RTX: 2060, 2070 Super, 2080, 2080 Super и многие другие.

Обзор и тестирование видеокарты MSI GeForce GTX 1080 Ti GAMING X TRIO
Они также изготовлены TSMC, но с использованием техпроцесса, специально разработанного для продуктов Nvidia, называемого 12FFN, который сам по себе является усовершенствованной версией 16FF.
Улучшения направлены на увеличение плотности кристалла при одновременном уменьшении утечек. Этим, возможно, объясняется то, что процессоры Nvidia выглядят более эффективными.
Регулирование выходного напряжения
Современные процессоры требуют разного напряжения питания в процессе работы. Зависит это от нагрузки, и не забудем про разгон, при котором также необходимо изменять напряжение, в данном случае повышать его. Каким образом происходит автоматическая регуляция?
Зная требуемое значение, остается его сравнить с тем, которое подается в нагрузку. Для этого существует цепь обратной связи. Сравнение референсного напряжения и того, которое считано с нагрузки, позволяет определить, требуется ли изменить его уровень. Делается это изменением скважности PWM-импульсов. Таким образом поддерживается оптимальное напряжение питания процессора.
Видеопамять
Работа видеокарты сосредоточена на постоянном выводе цифрового изображения на экран. Существует необходимость в сохранении выводящейся, а также остающейся за пределами экрана информации. Это задача возложена на видеопамять карты.
Память видеокарты по своим свойствам похожа на оперативную память компьютера.
Зачастую память карты используют для маркетинга, особенно в слабых (не игровых и не профессиональных) видеокартах. Кричащие 4 гб памяти почему-то сразу вызывают доверие у неподготовленного покупателя. Но один и тот же объём памяти радикально отличается на разных видеоадаптерах, если говорить о реальной производительности в требовательных задачах и современных играх. Например, даже самая бюджетная из игровых видеокарт nVidia GTX 1050 с двумя гигабайтами памяти во всех задачах покажет себя лучше, чем любой представитель карт серии GT.
Объём видеопамяти – важный, но не ключевой показатель.
Видеопамять в основном делается по стандарту GDDR. В наше время, у пользователей зачастую можно обнаружить память типа GDDR5. Ранее была распространена GDDR3.
Очевидно, что чем выше цифра, тем лучше, так как в каждой новой версии были ряды изменений, которые увеличивали пропускную способность и скорость тактовой частоты. Сейчас среди активных разработчиков можно заметить AMD, Hynix и Qimonda.
Очень важным элементом является шина памяти видеокарты и ее пропускная способность. Именно она гоняет информацию между процессором графического адаптера и его памятью. Частота памяти и шина влияют на производительность видеокарты. Частота измеряется в Мгц (мегагерцах), и чем больше она, тем быстрее работает память. Шина измеряется в bit, от 64 – до 448 bit. Чем “шире” шина, тем быстрее память взаимодействует с графическим процессором (GPU).
Самый распространенный размер шины – 128bit. Однако топовый уровень – это 256 и 384. Благодаря размеру шины и тактовой частоте, в принципе, и строится ее пропускная способность. Чем выше эти показатели, тем быстрее графический процессор обменивается данными с видеопамятью.
CrossFire
Объединение видеокарт в CrossFire проще. Здесь разными могут быть не только призводители, но и модели видеокарт. Так же как и в SLI, видеокарты соединяются друг с другом с помощью специального мостика, видеопамять также не суммируется.
Проблема заключается в том, что не все материнские платы поддерживают SLI или CrossFire. Как правило, это игровые решения.
Эффективность GPU: TDP vs площадь кристалла
Если не учитывать техпроцесс, и вместо количества транзисторов на кристалле использовать в анализе лишь площадь кристалла, то мы увидим совершенно иную картину.

На этом графике эффективность увеличивается так же, но теперь мы видим, что некоторые ключевые позиции поменялись местами. TU102 и GV100 «осыпались», тогда как Navi 10 и Vega 20 подпрыгнули. Это связано с тем, что первые два процессора представляют собой огромные чипы (754 мм2 и 815 мм2), тогда как последние два от AMD намного меньше (251 мм2 и 331 мм2).
Оставим на графике только самые последние разработки, чтобы подчеркнуть различия:

Становится очевидным, что AMD пренебрегает энергоэффективностью в пользу уменьшения размеров кристалла.
Другими словами, AMD хотят получить больше GPU чипов с каждой произведённой кремниевой пластины, в то время как Nvidia, похоже, придерживается стратегии увеличения энергоэффективности каждого чипа в ущерб его размеру и, соответственно, стоимости изготовления (чем больше чип, тем меньше их можно разместить на одной пластине).
Продолжат ли AMD и Nvidia впредь следовать выбранным стратегиям? Первые уже заявили, что в RDNA 2.0 они намерены на 50% улучшить соотношение «производительность на ватт», поэтому мы ждём их новые GPU дальше справа, по нашему графику. А что насчет Nvidia?
А они, к сожалению, печально известны своей молчаливостью относительно своих планов. Но известно, что их новые процессоры будут производить TSMC и Samsung на том же техпроцессе, который использовался для Navi. Были некоторые заявления о том, что мы увидим значительное снижение энергопотребления, и в то же время большое увеличение количества унифицированных шейдеров. Поэтому, судя по всему, Nvidia также не нарушит тенденций на нашем графике.
Заключение. Фазы питания процессора – что это
«Режим питания нарушать нельзя», говорил один мультяшный персонаж. И это питание должно быть не только качественным, но и подаваться без сбоев. Причем в переложении на компьютерный мир необходимо учитывать изменяющиеся условия, при которых не только потребление процессора изменяется при разных ситуациях, но и он сам может быть заменен более прожорливым.
Система питания CPU, содержащая n-ое количество фаз, обеспечивает надежную его работу. Кстати, все сказанное верно и для видеокарт. Электропитание GPU осуществляется аналогично. А то, что производители стараются запихнуть на свои материнские платы, особенно дорогие, побольше этих фаз… С этим придется смириться. Вряд ли есть реальная необходимость в 24-х фазах, но покупатель всегда ведь ведется на красивые слова и любит большие цифры, конечно, если только это не ценник.
Сказка о Двух Числах
В этой статье мы рассмотрим, насколько хорошо разработчики GPU смогли воспользоваться увеличением размеров кристалла и энергопотребления, чтобы предложить нам больше вычислительной мощности. Прежде чем идти дальше, вы можете освежить в памяти устройство видеокарты или пройтись по истории современного GPU. С этой информацией вам будет легче ориентироваться.
Чтобы понять, как менялась эффективность графического процессора, и менялась ли вообще, мы использовали отличную базу данных TechPowerUp, выбрав образцы процессоров за период последних 14 лет. Такой период обусловлен тем, что именно 14 лет назад GPU перешли на унифицированную структуру шейдеров.
Вместо того чтобы выделять отдельные вычислительные блоки процессора для обработки треугольников и пикселей, унифицированные шейдеры являются арифметическими логическими единицами, предназначенными для любых вычислений, связанных с трехмерной графикой. Благодаря этому, мы можем последовательно замерить относительную производительность каждого GPU по параметру количества его операций с плавающей точкой в секунду (FLOPS – FLoating-point Operations Per Second).
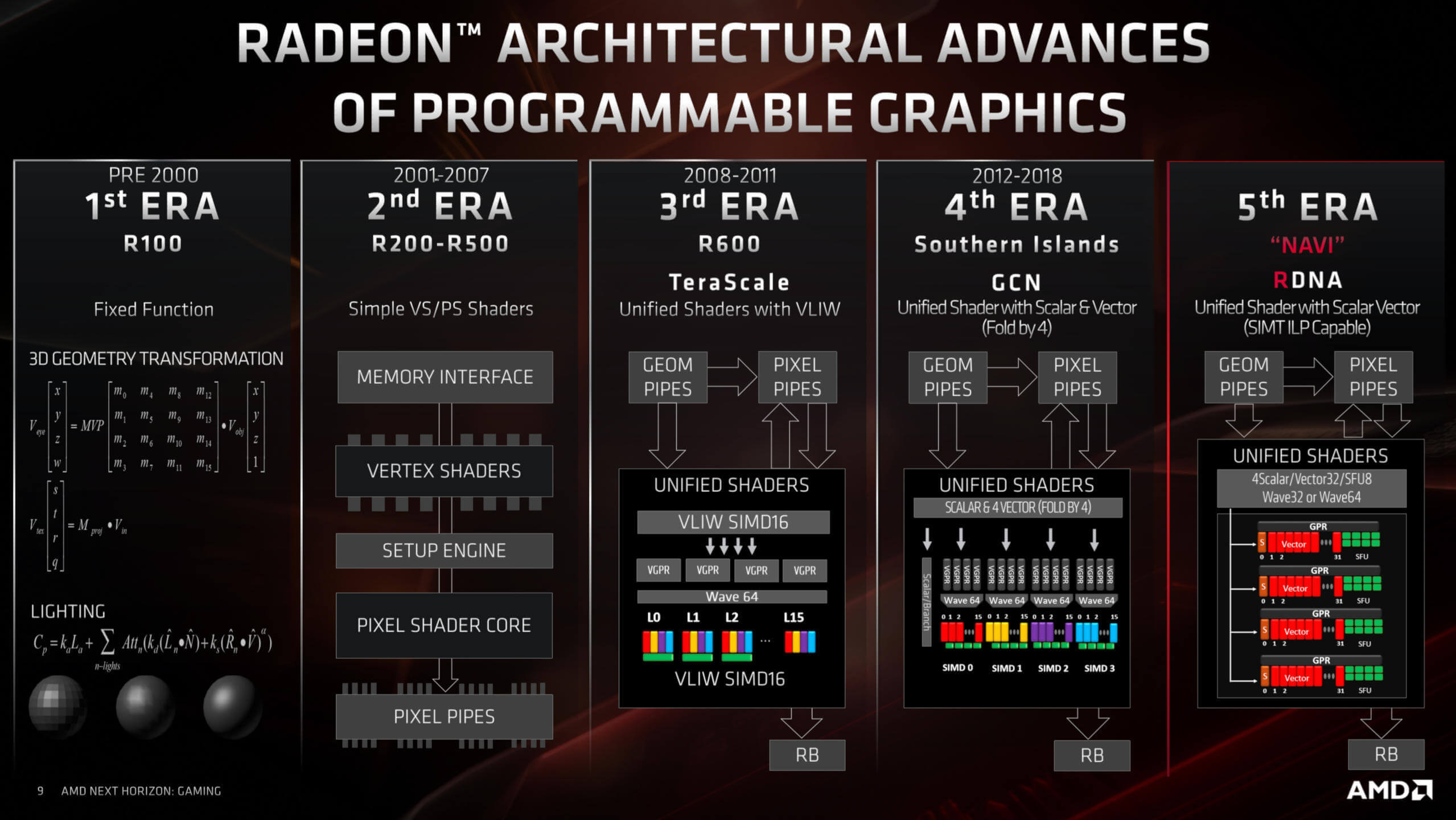
AMD использует унифицированную шейдерную архитектуру почти 12 лет
Вендоры часто стараются указывать значения FLOPS в качестве показателя максимальной производительности GPU. И хотя на самом деле это далеко не единственный показатель, определяющий скорость работы графического процессора, FLOPS дает нам цифры, с которыми мы можем работать.
То же касается и размеров кристалла, означающего рабочую площадь чипа. Однако чипы могут быть одинаковы по размеру, но сильно отличаться по количеству транзисторов.
Например, процессор Nvidia G71 (GeForce 7900 GT) 2005 года имеет размер 196 мм2 и имеет 278 миллионов транзисторов, а TU117, выпущенный в начале прошлого года (GeForce GTX 1650), всего лишь на 4 мм2 больше, но в нём 4,7 миллиарда этих маленьких переключателей.
Диаграмма основных GPU Nvidia, показывающая изменения в плотности транзисторов за последние годы
Естественно, из этого следует, что современные транзисторы намного меньше, чем в старых чипах, и это очень важно. Так называемый технологический процесс – общая разрешающая способность при изготовлении процессора, – используемый производителями оборудования, с годами менялся и постепенно становился все меньше и меньше. Поэтому мы проанализируем эффективность с точки зрения плотности кристалла, которая является мерой того, сколько миллионов транзисторов приходится на один мм2 площади кристалла.
Потребляемая кремниевыми чипами энергия действительно в основном превращается в тепло, но проблема использования TDP не в этом. Дело в том, что разные вендоры указывают это число при разных условиях, не обязательно во время пиковых FLOPS. Кроме того, это значение мощности для всей видеокарты в целом, включая встроенную память, а не только для основного её потребителя – собственно GPU. Можно измерить энергопотребление видеокарты напрямую, как это делали, например, TechPowerUp для своих обзоров GPU. Когда они тестировали GeForce RTX 2080 Super с заявленным производителем TDP 250 Вт, они обнаружили, что энергопотребление в среднем составило 243 Вт, и достигло максимума в 275 Вт во время тестирования.
Но всё-же мы решили учитывать показатель TDP в нашем анализе ради простоты и удобства, условившись весьма осторожно делать любые выводы касаемо производительности, основанные исключительно на её зависимости от номинальной тепловой мощности.
Сейчас мы проведем прямое сравнение по двум показателям: GFLOPS и плотность кристалла. Один GFLOPS равен 1000 миллионам операций с плавающей точкой в секунду, и мы имеем дело со значением для вычислений одинарной точности (FP32), выполняемых исключительно унифицированными шейдерами. Наше сравнение примет форму графика:
Ось X отображает GFLOPS на единицу TDP – чем больше, тем лучше. Чем меньше, тем нерациональней используется энергопотребление. То же справедливо для оси Y, где у нас GFLOPS на единицу плотности кристалла. Чем больше транзисторов удастся поместить на один квадратный мм, тем выше получится производительность. Таким образом, общая эффективность работы GPU (учитывая количество транзисторов, размер кристалла и TDP) возрастает по мере приближения к правому верхнему углу графика.
Все значения в районе верхнего левого угла в основном говорят о том, что «благодаря вычислительной мощности кристалла, этот GPU обеспечивает хорошую производительность, но за
счет использования относительно большого количества энергии». Идем к правому нижнему углу, и там у нас будут GPU, которые «очень энергоэффективные, но сравнительно слабенькие».
Короче говоря, мы оцениваем эффективность работы GPU исходя из его потребляемой мощности пропорционально количеству транзисторов.
А почему так дорого?
Ну смотрите, за 70 тысяч нам продают кусок кремния (песок) и много SMD-шек за 75 тысяч рублей, так? На самом деле, нет и даже близко НЕ.
Во-первых, кремний нужно очень тщательно очистить от примесей химическим путем. На огромном заводе нужно с помощью сотен рабочих и дорогого оборудования делать каждую видеокарту, плюс - системы охлаждения к ней.
Дешево ли обходится содержание такого здания?
При этом разработка видеокарты, которая требует привлечения инженеров ультра-класса - удовольствие далеко не из дешёвых. Себестоимость материалов видеокарты небольшая - до 10 тысяч рублей, если смотреть простым взглядом. Однако:
- Зарплата рабочим
- Дорогое оборудование
- Год-два разработки новой архитектуры
- Маркетинг
- Вагон и маленькая тележка патентов
Это то, за что вы платите, когда покупаете видеокарту. ИМХО - это того стоит. Хотя бы потому что производить настолько сложную электронику, как кристалл видеопроцессора, в домашних условиях просто невозможно. И именно в этом кроется цена видеокарты.
А нынешний подъем цены в три раза связан с дефицитом видеокарт. Он как бы был и до майнеров, но не такой явный, зато как только полки опустели - карты моментально поднялись в цене сначала в два, а потом в три раза.
Не секрет, что видеокарты делятся на два типа: интегрированные (встроенные) и дискретные. Дискретные вставляются в разъем PCI Express и являются полноценной, самостоятельной частью ПК. Из-за этого устройство дискретной видеокарты гораздо сложнее и заслуживает отдельной темы. Разберёмся, из каких компонентов состоит видеокарта и за что они отвечают.

Частота
Одна из важнейших характеристик графического процессора – тактовая частота. С ней всё просто. Она измеряется в мегагерцах и чем выше его показатель, тем быстрее идет обработка информации. Частота современных видеокарт достигает отметки в 1000-1400 Мгц.
Всегда ли фаза действительно фаза
Маркетинг играет большую роль в нашей жизни. Смартфон с камерой на 16 мегапикселей априори считается лучше такого же, но с камерой «всего лишь» на 13 мегапикселей. Ну а если используется 23 мегапикселя – то это уже вообще круть!

Аналогично и с материнскими платами. В описаниях, спецификациях или рекламных материалах на ту или иную модель можно найти гордое упоминание о системе питания, использующей -дцать фаз. А у конкурента схожая по функционалу плата вполне может имеет -дцать и еще 4 фазы. Чтобы не ходить далеко за примером, возьмем плату ASRock X370 Taichi под новехонькие Ryzen. Если обратиться к сайту производителя, то в спецификациях видим упоминание, что используется 16-фазная система питания.
А ведь используемый PWM-контроллер IR35201 – восьмифазный. Получается, производитель платы врет? Нет, ну может, немного лукавит. Дело в том, что дросселей, конденсаторов, электронных ключей и проч. действительно 16. Тонкость в том, что используются устройства, называемые делителями (doublers).

Суть работы этих элементов следует из названия – разделить, распределить сигналы от одного канала PWM-контроллера на две цепочки «драйвер-ключ-фильтр». На выходе очень похоже на две фазы, только управляются они одним сигналом, работают синфазно, никакого смещения между ними для сглаживания пульсаций нет. Тогда зачем они?
Ответ – мощность. Данная плата гарантирует поддержку процессоров с потреблением до 300 Вт! Распределяя нагрузку по такому количеству фаз, удается снизить проходящий через каждую из них ток и, как результат, уменьшить нагрев силовых элементов. Впрочем, если используется действительно мощный CPU, да еще и с разгоном, то для охлаждения просто необходим радиатор. Лучше бы даже с обдувом.
Думаю, все сказанное хорошо проиллюстрирует следующая картинка.

Возможен вариант без использования делителей. В таком случае ставится несколько PWM-контроллеров, которые работают синхронно. Если использовать уже упомянутый восьмифазный IR35201, установив 2 таких на плату, то вполне можно получить на выходе 16 фаз. Почти честных фаз, т. к. временнОго сдвига по всем фазам не будет.
По одной фазе от каждого PWM-контроллера будет работать синхронно, т. е. получим 8 пар (при условии, что используются 2 PWM-контроллера) фаз без временного смещения управляющего сигнала. Строго говоря, сглаживание будет такое же, как и при использовании 8 фаз, но вот мощность будет существенно выше.
А ведь можно найти платы, в которых и по 24 фазы…
s-Video

S-Video – это так же аналоговый разъем, который часто можно встретить на телевизорах и редко на видеокартах. Качество его хуже, чем у VGA, однако его кабель достигает 20 метров, все еще сохраняя при этом хорошую картинку. Информация передается трёхканально.
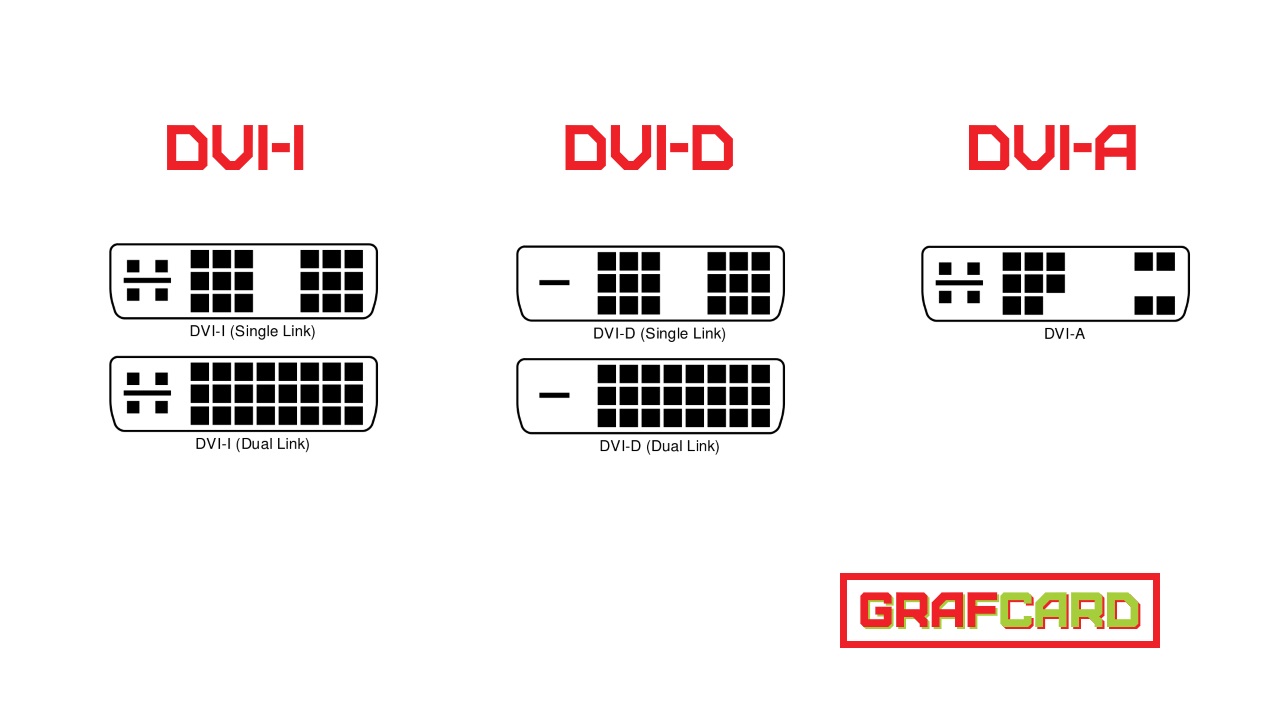
DVI обогнал всем известный VGA тем, что приобрел способность передавать цифровой сигнал. Этот разъем уже более знаком современному миру, так как благодаря нему можно подключать мониторы, уже, высокого разрешения, чего нельзя было раньше. Длина его кабеля достигает 10 метров, однако это уже не влияет на качество выводимого изображения. Благодаря своей уникальности, он вмиг приобрел популярность среди другого оборудования, по типу проекторов и прочего. Бывает трех видов: только цифровой DVI-D , весьма редкий – аналоговый DVI-A и совмещающий два прошлых DVI-I. Благодаря специальным переходникам может подключаться к монитору, который имеет лишь разъем VGA.

HDMI имеет несколько преимуществ перед DVI. Главной его особенностью является то, что кроме видео канала, у него так же имеется и аудио. Благодаря этому достиг большой популярности среди известных компаний, получив поддержки. Также из плюсов можно отметить его компактность и отсутствие креплений, которые наблюдаются у DVI. К тому же, кроме видеокарты, он отлично «сотрудничает» с другими устройствами.
Техпроцесс
Важным показателем является техпроцесс, это один из первых пунктов среди характеристик видеоадаптеров. Измеряется в нанометрах.
Грубо говоря, основной движущей силой являются транзисторы. Если взять современные видеокарты, то можно заметить, что показатель нанометров все меньше и меньше с каждым поколением видеочипов. Все это обусловлено тем, что чем меньше размер транзисторов, тем больше их можно разместить на одном видеочипе.
С уменьшением размера транзисторов, в целом у видеокарт уменьшается также:
- Энергопотребление;
- Тепловыделение (TDP);
Производительность при этом увеличивается, так как на одной площади можно разместить больше вычислительной мощности.
Чем меньше техпроцесс, тем лучше.
Интерфейсы подключения видеокарт
Интерфейсы подключения служат для соединения комплектующих и материнской платы. Различные периферийные устройства (сетевые и звуковые карты, ТВ-тюнеры и т.п.) как правило подключаются через PCI. Это стандартная шина ввода-вывода, но речь не о ней, т.к. для видеокарт используются другие слоты. До 2006 года был популярен интерфейс AGP, затем ему на смену пришёл PCIexpess (PCIe).
AGP был создан по технологиям PCI, но предназначен исключительно для видеокарт. Он отличается более высокой пропускной способностью. Последняя обновленная версия AGP 8x обладает пропускной способностью 2.1 Гб/с. Платы с AGP выпускались до 2006 года. Больше не производится, т.к. появился более совершенный интерфейс – PCIexpress.

PCI Express, отличии от AGP, обладает большей пропускной способностью, постоянно модернизируется и имеет обратную совместимость. На данный момент существуют 4 версии, следуя порядковому номеру. Самой последней является, PCIe 4.0. С каждым разом разработчики увеличивали пропускную способность интерфейса. Сейчас им удалось достигнуть отметки в 16 Гбит/с. Не стоит забывать про то, что PCI Express видеоадаптера и материнской платы зачастую не совпадают. Однако особого риска и страха здесь нет. Видеокарта будет работать на старой материнке, хоть и не сможет работать на всю свою мощность. При обратной совместимости вообще не возникает проблем.
RTX 3080
Это High-END видеокарта, которую найти в продаже сейчас непросто. Виной тому - майнеры, которые опустошают полки магазинов. Для простого игрока владение такой видеокартой означает стабильно высокий FPS в играх, и даже претензии на 144-гц в разрешении до QHD. Также эта видеокарта умеет запускать игры в 8К, причем в них даже не будет слайд-шоу, если включить DLSS.
Сейчас расскажу про характеристики, посмотрим на цену, а дальше я объясню простым языком - за что конкретно отвечает каждый пункт.
- Ядро - GA102
- Техпроцесс, нм - 8
- Транзисторов, млн - 28300
- Частота работы ядра, МГц - 1440–1710
- Частота работы шейдерных блоков, МГц - 1440–1710
- Шейдерных блоков - 8704
- TMU - 272
- ROP - 96
- Частота работы памяти (DDR), МГц - 1188 (19000)
- Шина памяти - 320-bit
- Объем памяти - 10240 MB GDDR6X
- TDP - 320W
И естественно, зная их прежнюю и текущую цену, я могу уверенно вам рекомендовать не покупать эти видеокарты по такой цене. Они сейчас ВТРОЕ дороже рынка, и на то есть простая причина - майнеры. Однако даже если разделить 220 на 3, получится почти 75 тысяч, что тоже очень много.
Однако именно 75К эта видеокарта стоит, и это - факт. Все современные игры она вытягивает на наилучших настройках графики, да и какое-то время, года два - будет вытягивать и будущие игры не хуже нынешних. Для QHD разрешения она будет актуальна ещё очень долго - тоже факт.
Но как и с любыми топовыми видеокартами, эта не лишена недостатков (это я так плавно перехожу к тому, что все эти термины означают). Показатель энергопотребления (а значит и тепловыделения) обозначается как TDP. У нас это 320 ватт.
DisplayPort

DISPLAYPORT, в принципе, далеко не ушел от HDMI, так как они оба способны выводить качественное изображение на большой экран вместе с аудио сопровождением. Однако у DISPLAY-я есть переходники на другие, популярные виды разъемов. В отличии с HDMI производители имеют возможность не платить налог, что увеличивает его популярность. Однако шанс встретить его среди бытовых пользователей, все еще, намного меньше. Максимальный размер кабеля достигает 15 метров. Пропускная способность выше, чем у HDMI, хоть и меняется в зависимости от его версии.
SLI и CrossFire
Отдельно про SLI и CrossFire. Для начала стоит сказать, что разница между ними состоит в производителях и связках видеокарт. Не секрет, что вы можете подключить множество видеокарт, если только хватит ваших PCI Express слотов. SLI – фирменная технология nVidia, CrossFire – разработка AMD.
Благодаря SLI можно подключить две видеокарты одной серии с помощью специального мостика. Производительность возрастает, но видеопамять не суммируется. При объединении видеокарт в связку SLI важно знать, что они должны быть не только одного поколения, но и одной серии. Производители при этом могут быть разными. Например, GTX 1080 в SLI заработает только с другой GTX 1080.
Что такое фазы питания
Чтобы знать, о чем собственно речь, давайте обратимся к фотографии материнской платы, вернее, к части ее, расположенной возле процессорного сокета. Вот типичная картина того, что можно увидеть на любой плате.

Что-то похожее вы сможете найти и на своей. Разница будет только в количестве компонентов, окружающих сокет.
Если рассматривать устройство каждой фазы питания, то можно выделить несколько блоков по своему назначению.

Все обозначения постепенно станут понятны.
Итак, что это такое? Современные блоки питания (БП) выдают напряжения ±12 В, ±5 В и +3.3 В. Однако современным процессорам необходимо гораздо меньше – порядка одного вольта, отклоняясь в ту или иную сторону в зависимости от нагрузки. При этом, если посмотреть на спецификации CPU, мы найдем такой параметр, как «Расчетная мощность» (он же TDP – расчетная тепловая мощность). В данном случае это величина, относящаяся к системе охлаждения, которая должна справляться с такой тепловой мощностью. Данное значение не эквивалентно энергопотреблению процессора, тем более оно меняется в зависимости от нагрузки и нагрева, но весьма близко к нему.
Так, если обратиться к спецификации CPU Intel Core i7-7700, то расчетная мощность составляет 65 Вт. В нашем случае не столь важно, сколько точно потребляет данный процессор. Просто предположим, что его энергопотребление и составляет 65 Вт.
Значит, система питания CPU должна обеспечить подвод такой мощности. Т. к. готового напряжения от блока питания мы не получаем, значит, придется подготовить нужное его значение. Для этого и служит система питания CPU.
Охлаждение
Не менее важным моментом является охлаждение устройства. Как уже было сказано – видеокарта очень требовательна к энергии, потому она больше всего склонна к перегреву. Чтобы избежать подобного существуют разные типы охлаждений. Есть пассивный, он нацелен на то, чтобы поглощать и рассеивать энергию. Активный, в свою очередь, это привычные нам кулеры или система водного охлаждения.
Первые 3D-видеокарты появились 25 лет назад, и с тех пор их мощность и сложность выросли в таком масштабе, как ни один другой чип компьютера. В те времена графические процессоры были меньше 100 мм2 размером, имели около 1 миллиона транзисторов и потребляли всего несколько ватт энергии.
Сегодня же типичная видеокарта может иметь 14 миллиардов транзисторов на кристалле размером 500 мм2 и потреблять более 200 Вт энергии. Возможности этих бегемотов будут неизмеримо больше, чем у их древних предшественников, но стали ли они эффективнее со всеми этими транзисторами и ваттами энергии?
Устройство и принцип действия
В качестве исходного напряжения берется +12 В, которое поступает непосредственно от используемого БП. Теперь надо выполнить преобразование, понизив напряжение до нужного значения. Этим занимается VRM (Voltage Regulation Module — модуль регулирования напряжения).
Сам VRM состоит из нескольких частей, это:
- PWM-контроллер (ШИМ-контроллер).
- Драйвер.
- MOSFET-транзисторы.
- Дроссель (индуктивность).
- Конденсатор.

Сейчас часто драйвер и пара MOSFET-транзисторов объединены в один корпус, а не являются дискретными элементами. Сути дела это не меняет. В одном корпусе или в разных - все это перечень компонентов, составляющих фазу питания CPU.
Основным управляющим элементом выступает PWM-контроллер. (Напомню, что аббревиатура PWM расшифровывается как широтно-импульсная модуляция – ШИМ). Он генерирует прямоугольные импульсы с установленной частотой, амплитудой и скважностью. Они подаются на электронный ключ (драйвер).

Скважность импульса определяет уровень выходного напряжения, которая вычисляется как отношение периода к длительности импульса. Таким образом, этот электронный ключ постоянно подключает/отключает входное напряжение, равное +12 В, к этому напряжению подключена нагрузка.
Сам электронный ключ состоит из пары MOSFET-транзисторов (n-канальные полевые МОП-транзисторы) под управлением драйвера. Эти транзисторы попеременно открываются-закрываются таким образом, что при открытии одного второй закрыт. Один из транзисторов своим стоком подключен к шине питания 12 В, второй - истоком к общему проводу. Сигнал от PWM-контроллера поступает на затворы, открывая и закрывая их в соответствии с частотой подаваемых сигналов.

Полученный модулированный сигнал с амплитудой 12 В поступает в LC-фильтр, т. е. через последовательно включенный дроссель (индуктивность) и параллельно подключенный конденсатор, что является нагрузкой. Возникающая ЭДС индукции не позволяет току возрастать мгновенно. В это же время происходит и заряд конденсатора. После закрытия электронного ключа та же ЭДС обеспечивает прежнее направление тока и не допускает резкого его снижения, помогает и разряжающийся конденсатор.
Чтобы не вдаваться в подробности, скажу так: в конечном итоге из импульсного сигнала выделяется постоянная составляющая, и на выходе со сглаживающего LC-фильтра получаем постоянное напряжение нужного значения. Правда, выходное напряжение будет содержать некоторый уровень пульсаций относительно среднего значения.

Для минимизирования пульсаций используют несколько таких цепей, т. е. фаз питания, которые работают таким образом, что подаваемые от PWM-контроллера импульсы в каждую фазу смещены друг относительно друга. Величина этого смещения зависит от количества используемых фаз. Т. е. смещение вычисляется как отношение периода переключения MOSFET-транзисторов к количеству фаз.
Тем самым выходной сигнал с каждого сглаживающего фильтра также смещен по отношению к другому. Также смещены будут и пульсации выходного напряжения. Результирующее напряжение будет иметь уже гораздо меньший уровень пульсаций. И это одно из преимуществ именно многофазных цепей питания – получение более стабильного уровня подаваемого на процессор напряжения.
Читайте также: