
Самый большой процессор в мире

В прошлом году компания Cerebras System представила самый большой в мире процессор. Его размеры составили 220 x 220 мм, площадь — 46 225 мм². Процессор включает 1,2 трлн транзисторов. Чип получил название WSE (Wafer Scale Engine). Представители компании разработали и компьютер CS-1, основой которого стал гигантский процессор. Систему официально представили 18 ноября 2019 года.

Сейчас Cerebras System рассказала о новом процессоре, количество транзисторов в котором увеличится более чем в 2 раза — с 1,2 трлн до 2,6 трлн. Резкое увеличение количества элементов в чипе стало возможным благодаря переходу на 7-нм техпроцесс. Кратно выросло и число ядер — их теперь 850 000.
Размеры первого процессора огромны — 22 x 22 см, что сопоставимо с размерами небольшого ноутбука. Он в 55.9 раз больше самого крупного GPU-чипа, Nvidia A100. Ну а CS-1 назван производителем «самым быстрым компьютером для работы с искусственным интеллектом и обучения нейросетей». Охлаждение — жидкостное с внутренним контуром и двумя насосами. Дополнительно установлены четыре крупных кулера, обеспечивающие скорость воздушного потока в 0,95 м 3 /с.

Процессор первого поколения включал 400 000 вычислительных ядер. Его оснастили 18 ГБ памяти формата SRAM, а пропускная способность при этом достигла 9 петабайт в секунду. Система потребляла 18 кВт энергии, которую подавали 12 блоков питания. Масса компьютера с установленным WSE — 254 килограмма. Для включения системы в единую сетевую инфраструктуру использовались 12 портов 100 Gigabit Ethernet (100GBase-SR4).

Wafer Scale Engine в сборе с системой питания и охлаждения
Генеральный директор и соучредитель Cerebras Systems Эндрю Фельдман на презентации новинки рассказывал, что CS-1 в три раза производительней кластеров TPU от Google. Вычислительные решения от поискового гиганта по энергетическим характеристикам оказались хуже разработки компании, потребляя более 100 кВт электроэнергии.
В 2019 году первые экземпляры CS-1 были переданы заказчикам. Среди них — Аргоннская национальная лаборатория министерства энергетики США, Суперкомпьютерный центр Питтсбурга и Ливерморская национальная лаборатория.
На конференции Hot Chips 2020 компания Cerebras System объявила, что перейдет с 16-нм техпроцесса на 7-нм. Производителем процессора останется тайваньская Taiwan Semiconductor Manufacturing Company (TSMC). Представитель разработчика заявил, что в лаборатории тестируется несколько образцов WSE нового поколения.
Ожидается, что Cerebras System увеличит объем доступной памяти чипа и усилит межкомпонентные соединения микросхем для повышения пропускной способности. Скорее всего, компания продолжит предоставлять в аренду вычислительные мощности для обучения нейросетей корпоративных клиентов. Кто станет клиентом, выяснится в ближайшем будущем, но можно быть уверенным в том, что желающих будет много.
Наверняка вы подумали, что это какой-то очередной кликбейт. Что это за самый большой процессор в мире? Похоже сейчас нам будут рассказывать о процессоре, который на 5 процентов больше других, и то если рассматривать этот процессор только с определенной стороны. И да, просмотры и прочтения мы хотим собрать, но…
Сегодня мы расскажем вам о процессоре компании Церебро под названием Cerebras CS-1. И он действительно огромный!
Например, GPU, который считался самым большим раньше — это процессор Nvidia V100, а вот новый процессор Церебро. Он почти в 57 раз больше! Площадь самого чипа — 462 квадратных сантиметра — это почти столько же сколько площадь всей Nvidia 3090, вместе с системой охлаждения и разъемами.



А что вы скажете на то, что этот монстр способен симулировать некоторые физические модели быстрее самих законов физики? Заинтриговали? Что ж, тогда присаживайтесь, наливайте чаек. Сегодня будет разбор по-настоящему огромного однокристального процессора!
Итак, что же это за монстр такой и зачем он нужен? Давайте сразу ответим на второй вопрос — этот процессор создан для машинного обучения и искусственного интеллекта. Кроме того, он сильно расширит возможности для различного сложного моделирования и сможет заглядывать в будущее. Вообще, искусственный интеллект — это невероятно интересная и актуальная тема, а ее главные ограничения — это слабые вычислительные мощности. А если хотите узнать о реальных проектах с использованием искусственного интеллекта — у Илона Маска есть такой в запасе — Open AI.
Если вы думали, что закон Мура со своим увеличением количества транзисторов в процессоре каждые 1,5 года — это быстро, то посмотрите на потребности в области ИИ, ведь спрос на эти вычисления удваивается каждые 3,5 месяца!
Классический подход — это напихать кучу процессоров в серверные стойки, к каждому подвести систему охлаждения и питания, при этом каждый отдельный процессор еще надо связать друг с другом, а это, кстати, неизбежно вызывает задержки.
Скажем так — если вы возьмете двигатель от Ferrari и запихнете ее в старые Жигули, то машина конечно поедет быстрее, но как Ferrari все равно не поедет. Поэтому тут нужен принципиально иной подход, ведь для того, чтобы получить настоящий гиперкар надо взять хорошие тормоза, подвеску, рассчитать аэродинамику: с компьютерами точно также.
Компания Церебро это и сделала — они решили разработать свою систему с нуля, то есть вообще все — от архитектуры самих процессоров, до системы охлаждения и питания.




Это огромная машина, потребляющая 20 килоВатт, и занимающая треть стандартной серверной стойки, то есть можно размещать по три таких компьютера в одной стойке! А сам чип, по своей сути и предназначению, напоминает серверные GPU от NVIDIA, так что давайте их и сравним. Возьмем Nvidia Tesla V100.


Цифр много, приготовьтесь! Кроме размеров самого кристалла, процессор Церебро обладает четырьмя сотнями тысяч ядер, что в 78 раз больше, чем число ядер на NVIDIA Tesla V100! Количество транзисторов взрывает мозг — 1,2 триллиона, против 21 миллиарда у NVIDIA.
А сколько там памяти? 18 гигабайт l2 cache memory прямо на чипе! Это в три тысячи раз больше, чем у V100. Кстати у 3090 от той же NVIDIA, памяти на чипе тоже 6 мегабайт, прямо как у V100. Ну а про ширину полосы пропускания даже говорить страшно — у V100 это 300 Гигабит в секунду, а у Церебро — 100 ПЕТАбит в секунду. То есть разница в 33 тысячи раз!

А чтобы достичь схожей вычислительной мощности они заявляют, что нужна тысяча карт NVIDIA V100, что суммарно будет потреблять в 50 раз больше мощности и занимать в 40 раз больше места — это очень значительная экономия электроэнергии и свободного пространства.


Это конечно прекрасно — цифры поражают. Но как удалось их достичь?
Суть в размере. Чип — большой, нет, даже огромный. Именно это позволяет разместить столько всего на одном кристалле. И главное, что связь между элементами мгновенная, потому что не нужно заниматься сбором данных с разных чипов.
Однако, размер — это одновременно и главный недостаток Церебро.
Давайте по-порядку. Первое и главное — нагрев. Разработчики этого монстра прекрасно понимали, что они создают и какая система охлаждения нужна, поэтому она, как и сам процессор, были разработаны с нуля. Она представляет из себя комбинацию жидкостного охлаждения, которое направляется к охлаждаемым медным блокам! Охлаждающая жидкость, проходя через мощный насос, попадает в радиатор, где с помощью вентилятора происходит ее охлаждение, а горячий воздух уже выдувается наружу четырьмя дополнительными вентиляторами.




При потреблении 20 кВт, которые подаются через двенадцать разъемов питания, четыре уходит только на питание вентиляторов и насосов для системы охлаждения. Но в результате они достигли того, что чип работает при вдвое меньших температурах, чем стандартные GPU, что в конце концов повышает надежность всей системы.
Ну и конечно отдельно хочется сказать, что инженеры создали систему так, что она позволяет быстро менять почти любой компонент, что очень круто, так как в случае поломки — это уменьшает время возможного простоя.
Сам же чип собирает TSMC по, вы не поверите, 16 нанометровому техпроцессу. И тут вы можете справедливо возмутится. Как же так? Все уже делают чипы на 5 нм, какой смысл делать на древних 16 нм?
Тут то и скрывается вторая проблема. При производстве классических чипов неизбежно бывает брак, который приводит к тому, что несколько чипов оказываются негодными и выкидываются или используются для других задач, и чем мельче техпроцесс, тем выше процент брака. Но когда у тебя вся кремниевая подложка — это один чип, то любая ошибка в производстве приводит к тому, что всю пластину можно выкидывать. А при условии, что одна пластина может изготавливаться несколько месяцев и стоит около миллиона долларов, что ж….
Суть в том, что ребята решили, как бы подстраховаться. Ведь 16 нм техпроцессу уже почти семь лет: детали и тонкости при его производстве отлично изучены. Так сказать — уменьшают риски! Но стоит сказать, что уже ведется разработка и тестирование такого чипа на 7 нм, но его выход конечно будет зависеть от спроса на первое поколение! И там цифры просто огромные, только посмотрите на таблицу.


И тут вы можете справедливо заметить, что мы пока что ни слова не сказали о результатах, которых можно достичь с помощью этого монстра. Тут сложно, так как информация, в основном, закрытая, однако какие-то детали все равно просачиваются в медийное пространство.
Национальная лаборатория энергетических технологий Министерства энергетики США заявила, что CS-1 — первая система, которая смоделировала работу более миллиона топливных ячеек быстрее, чем в режиме реального времени.
Это означает, что когда CS-1 используется для моделирования, например, электростанции на основе данных о ее текущем состоянии, она может сказать, что произойдет в будущем быстрее, чем законы физики дадут такой же результат. Вы поняли? С помощью этого ПК можно заглянуть в будущее с высокой точностью, и если нужно подкорректировать и изменить его. И еще, например, в симуляции с 500 миллионами переменных Cerebras CS-1 уже обогнал суперкомпьютер Joule, занимающий 69-е место в рейтинге самых мощных суперкомпьютеров мира. Так что похоже со спросом проблем не ожидается.

Церебро планируется использовать для прогнозирования погоды или температуры внутри ядерного реактора или, например, проектирования крыльев самолета. Несомненно, лаборатории и различные исследовательские центры по всему миру найдут для Церебро области применения. Как вы понимаете, компьютер будет дорогим, но точная цена неизвестна.
Из открытых источников мы нашли только что в 2020 году в суперкомпьютерном центре Питтсбурга было куплено 2 компьютера Cerebras CS-1 за 5 миллионов долларов. Но система делается только под заказ и под каждого конкретного клиента, так что цена может варьироваться.
Выводы

Это явно уникальная система. И такого раньше никто не делал! Большинство производителей считают, что гораздо выгоднее и эффективнее наштамповать кучу маленьких процессоров, так как вероятность брака или поломки сильно падает и каждая ошибка сильно дешевле. Разработчики Церебро же решили пойти рискованным путем и, судя по тому, что процессор Cerebras CS-2 уже тестируют, их путь успешен.
И если все что они заявили — сбудется, то нас ждет абсолютно новая эра серверных вычислений, невероятные возможности для создания компьютерных моделей, новые мощности искусственного интеллекта. Нет сомнений, что и гиганты рынка, такие как Nvidia, Intel, Google, посмотрев на удачный опыт Церебро займутся разработкой своих огромных однокристальных систем. А вы только представьте, что будет если совместить это с квантовыми вычислениями, о которых мы недавно делали разбор? Ух!
Будем следить за развитием технологий, и продолжим дальше делать для вас такие интересные обзорные материалы про самые современные достижения!

PS. Кстати, лайк если поняли пасхалку в Церебро — ведь решетка радиатора выполнена в форме специальной сетки, которая используется в компьютерном моделировании для расчетов. Отсылка к предназначению Церебро!

Компания Cerebras Systems выпустила самую большую микросхему в истории компьютерной техники. С площадью 46 225 мм² и 1,2 трлн транзисторов она примерно в 56,7 раз больше, чем самый большой GPU (21,1 млрд транзисторов, 815 мм²). Фото: Jessica Chou / The New York Times
Самые большие компьютерные чипы обычно помещаются в ладони. Некоторые могут уместиться на кончике пальца. Известно, что увеличение физических размеров вызывает массу проблем. Однако стартап из Кремниевой долины бросает вызов этой идее. Сегодня на конференции Hot Chips в Пало-Альто компания Cerebras Systems и её производственный партнер TSMC представили «крупнейшую микросхему в истории компьютерной техники» размером примерно с обеденную тарелку, пишет NY Times.
Процессор предназначен для дата-центров по обработке вычислений в области машинного обучения и искусственного интеллекта (AI).
Инженеры Cerebras Systems считают, что микросхему под названием WSE можно использовать для облачных вычислений в разных приложениях машинного обучения: от беспилотных автомобилей до цифровых ассистентов с распознаванием речи, таких как Alexa от Amazon.
Разработкой чипов для AI занимаются многие компании, в том числе традиционные представители индустрии, такие как Intel, Qualcomm, а также различные стартапы в США, Великобритании и Китае. Некоторые эксперты считают, что эти чипы будут играть ключевую роль в гонке за создание искусственного интеллекта, потенциально влияя на баланс сил между технологическими компаниями и даже странами. Теоретически, они могут дать преимущество в работе коммерческих продуктов и государственных технологий, включая системы наблюдения и автономное оружие.
Google уже разработала собственный AI-ускоритель, используя его в широком спектре проектов AI, включая Google Assistant, который распознаёт голосовые команды на телефонах Android, и Google Translate для перевода текстов: «В этой области наблюдается чудовищный рост, — говорит основатель и исполнительный директор Cerebras Эндрю Фельдман (Andrew Feldman), ветеран полупроводниковой индустрии, который продал свой предыдущий стартап AMD.
Новые системы AI полагаются на нейронные сети и требует специфических вычислителей. Сегодня большинство компаний обрабатывает данные на GPU. Хотя графические процессоры изначально предназначены для других задач, но хорошо подходят для обсчёта математики нейросетей.
Около шести лет назад, когда технологические гиганты Google, Facebook и Microsoft сосредоточились на технологиях AI, они начали покупать огромное количество GPU у Nvidia. За год компания продала графических процессоров на $143 млн, удвоив продажи по сравнению с предыдущим годом.
Но компаниям требовалось ещё больше вычислительной мощности, поэтому Google разработала чип специально для нейронных сетей — тензорный процессор, или TPU. Несколько других производителей последовали её примеру.
Системы AI работают в многопоточном режиме, а узким местом становится перемещение данных между чипами: «Соединение этих чипов на самом деле замедляет их — и требует много энергии, — объясняет Субраманьян Айер (Subramanian Iyer), профессор Калифорнийского университета в Лос-Анджелесе, который специализируется на разработке чипов для искусственного интеллекта.
Производители оборудования изучают множество различных вариантов. Некоторые пытаются расширить межпроцессорные соединения. Трёхлетний стартап Cerebras, который получил более $200 млн венчурного финансирования, предлагает новый подход. Идея в том, чтобы сохранить все данные на гигантском чипе — и тем самым ускорить вычисления.
Работать с одним большим чипом очень сложно. Обычно микросхемы создаются на круглых кремниевых пластинах диаметром около 12 дюймов (30,5 см). Каждая из них обычно содержит около 100 чипов.

Пример кремниевой пластины. Фото: ARM
Многие из этих микросхем после снятия с пластины выбрасываются и никогда не используются. Травление цепей в кремнии — такой сложный процесс, что производители не могут полностью устранить дефекты. Некоторые цепи просто не работают. Это одна из причин, почему производители предпочитают сохранять маленький размер микросхем — так остаётся меньше места для ошибок. А вот Cerebras Systems уверяет, что создала одну микросхему размером с целую пластину. Технологический партнёр TSMC производит эти чипы по техпроцессу 16 нм.
Некоторые стартапы раньше пробовали такой подход, но безуспешно. Пожалуй, самым известным является стартап под названием Trilogy, который основал в 1980 году известный инженер из компании IBM Джин Амдал (Gene Amdahl). Несмотря на более $230 млн финансирования, Trilogy в конечном итоге сочла задачу слишком трудной и спустя пять лет свернула деятельность.
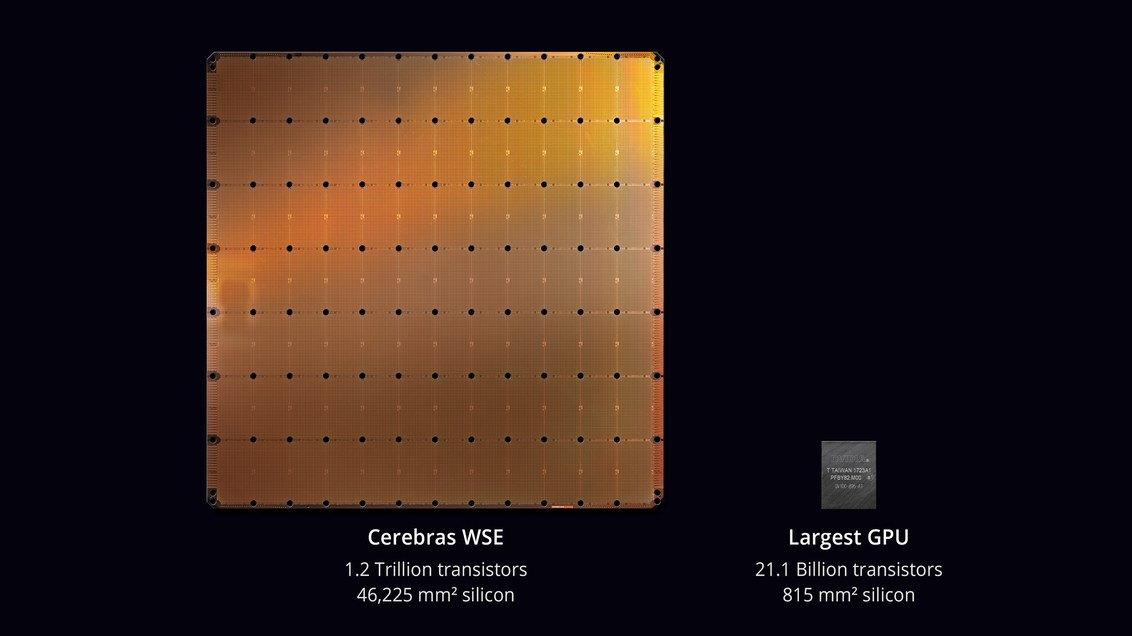
Фото: Cerebras Systems
18 гигабайт быстрой локальной SRAM — единственный уровень иерархии оперативной памяти. Скорость обмена данных с памятью — 9 петабайт в секунду, пишет VentureBeat.
Гигантская микросхема разделена на более мелкие секции (ядра), с учётом того, что некоторые из них не будут работать. Общее количество ядер — 400 000. Чип разработан с возможностью маршрутизации вокруг дефектных областей. Программируемые ядра SLAC (Sparse Linear Algebra Cores) оптимизированы для линейной алгебры, то есть для вычислений в векторном пространстве. Компания также разработала технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение. Векторы и матрицы в векторном пространстве обычно содержат множество нулевых элементов (от 50% до 98%), поэтому на традиционных GPU большая часть вычислений уходит впустую. В отличие от них, ядра SLAC предварительно отфильтровывают нулевые данные.
Коммуникации между ядрами обеспечивает система Swarm с пропускной способностью 100 петабит в секунду. Маршрутизация аппаратная, задержки измеряются в наносекундах.
NY Times отмечает, что заявления Cerebras Systems не подтверждены независимыми экспертами. Достоверно не известно, какова производительность микросхемы и сколько ядер работоспособны в реальных образцах.
Цена микросхемы будет зависеть и от процента брака. Разработка и производство таких изделий является «намного более трудоёмким процессом», признаёт Брэд Полсен (Brad Paulsen), старший вице-президент TSMC. Чип такого размера также потребляет большое количество энергии: значит, и охлаждать его будет сложно и дорого. Другими словами, создание чипа — только часть задачи.
Cerebras планирует продавать чип в составе гораздо более крупной машины, которая включает сложное оборудование для жидкостного охлаждения. Это не совсем то, с чем привыкли работать крупные технологические компании и государственные учреждения: «Дело не в том, что люди не могли создать такой чип, — говорит Ракеш Кумар (Rakesh Kumar), профессор университета Иллинойса, который также изучает большие чипы для AI. — Проблема в том, что никто не мог сделать это коммерчески осуществимым».
Таким образом, основной вопрос — сколько будет стоить эта система с жидкостным охлаждением и микросхемой Cerebras внутри.
Почти два года назад компания Cerebras представила огромный процессор масштаба кремниевой пластины. На производство одного такого чипа действительно уходила целая 300-мм кремниевая пластина. Выпуском Cerebras WSE занялась тайваньская TSMC. Чип производился по нормам 16-нм техпроцесса. Теперь Cerebras представила процессор WSE второго поколения — WSE-2.

Новый чип выполнен по нормам 7-нм техпроцесса, благодаря чему при неизменной площади в 46 255 квадратных миллиметров он вмещает 2,6 триллиона транзисторов против 1,2 триллиона у модели первого поколения. Количество ядер выросло больше чем в два раза. Теперь их 850 тысяч против 400 тысяч у предшественника. Чип содержит 40 Гбайт встроенной памяти SRAM, что на 22 Гбайт больше чем у оригинальной модели. Её пропускная способность выросла с впечатляющих 9 Петабайт в секунду до фантастических 20 Петабайт в секунду. Энергопотребление чипа осталось на прежнем уровне и составляет 15 кВт.

Компания добивается высочайшей производительности, сшивая штампы на кремниевой пластине с помощью коммуникационной сети. Эта матрица обеспечивает пропускную способность 220 Петабит в секунду, что существенно выше чем 100 Петабит в секунду у модели первого поколения. Cerebras заявила, что частота ядер WSE-2 соответствует показателям WSE первого поколения, который работал в диапазоне от 2,5 до 3 ГГц. Компания говорит, что производительность чипа выросла в два раза.

Как и раньше, чип поставляется в составе специальной системы 15U, разработанной с учётом его уникальных технических характеристик. Сообщается, что внешние отличия от системы первого поколения минимальны. Cerebras не указала цены на новый продукт, однако вполне очевидно, что он не предназначен для рядовых пользователей. Его целевой аудиторией являются крупные научные центры. Одним из покупателей чипа первого поколения стала Аргоннская национальная лаборатория, которая использует системы на его основе для исследования рака и чёрных дыр.

Cerebras заявляет, что у неё уже есть готовые системы второго поколения, а широкая доступность WSE-2 намечена на третий квартал 2021 года.
В эру завершения закона Мура известная шутка про самые большие в мире советские микросхемы перестала быть шуткой. Новым чудом микроэлектроники стал процессор Cerebras WSE со сторонами кристалла 21,5 × 21,5 см. Первая практика применения серверов на базе Cerebras WSE показала, что в ряде задач он обеспечивает подавляющее превосходство, и ещё долго не будет иметь равных.

Процессор Cerebras WSE
Системы CS-1 на базе процессора Cerebras WSE (Wafer Scale Engine) — компактные блоки высотой 26 дюймов (66 см) — были представлены примерно год назад. Эти блоки занимают 1/3 стандартной серверной стойки, но их производительность колоссальна. Причём вся эта производительность — результат работы одного-единственного процессора. Проектировщики компании SeaMicro рискнули разработать процессор размером с целую кремниевую пластину и не прогадали. На выходе получился продукт, который в вычислительных задачах в 10 тыс. раз быстрее самых производительных графических процессоров.
На днях о практических испытаниях CS-1 сообщила Национальная лаборатория энергетических технологий Министерства энергетики США (NETL). Она стала одним из немногих обладателей системы CS-1 и получила возможность сравнить её с классическими суперкомпьютерами на базе x86-процессоров с GPU NVIDIA. В частности, CS-1 сравнивали с одним из последних полученных лабораторией суперкомпьютеров Joule.

Система CS-1. Источник изображения: LLNL
Система Joule занимает 82 место в списке 500 мощнейших систем на Земле. Она опирается на 84 тыс. вычислительных ядер, распределённых по десяткам стоек, оценивается в десятки млн долларов США и потребляет 450 кВт. Система Cerebras CS-1 занимает треть стойки, стоит несколько млн долларов и потребляет всего 20 кВт. При этом в задаче, которая нагружает 16 384 ядер Joule, система на Cerebras оказалась в 200 раз быстрее.
Следует сказать, что Cerebras подходит не для всех вычислительных нагрузок. Этот процессор разрабатывался с упором на ускорение вычислений нейронных сетей и идеально подходит для ИИ и машинного обучения. Но даже в таком случае ему требуется мощнейший внешний сервер для подготовки и последующей обработки полученных данных. «Сырые» данные ему не подходят, либо они не позволяют загрузить такого монстра оптимальным образом.
И всё же для моделирования, например, гидродинамических задач ему нет равных, что показало сравнение с системой Joule, которая как раз призвана решать подобные задачи. Более того, Cerebras CS-1 настолько быстр, что может решать сложнейшие задачи быстрее, чем моделируемые процессы протекают в реальном времени. К примеру, он заканчивает расчёт ядерной реакции задолго до её прекращения в реальном реакторе. А вместо месяцев обучения той или иной модели ML система CS-1 способна обучиться за считаные минуты.

Подробнее о процессоре Cerebras можно прочесть в нашем архиве новостей. Вкратце напомним, что он состоит из 1,2 трлн транзисторов, часть которых сконфигурирована в 400 тыс. вычислительных ядер.
Читайте также: