
Проверка sas дисков в raid
Тестирование «настоящих» аппаратных RAID-контроллеров является очень непростым занятием. Основных причин тому несколько. Первая – сложность сбора тестового стенда соответствующего уровня. Если делать все «правильно», то потребуется много жестких дисков, соответствующий корпус и достаточно мощная серверная платформа, в некоторых случаях – еще и быстрая сеть и клиенты. Вторая проблема заключается в том, что в большинстве случаев подбор конфигурации СХД – задача под конкретного заказчика и конкретные приложения. При этом вариантов существует слишком много, что бы можно было за разумное время охватить их все. Третий вопрос касается выбора тестовых приложений и сценариев. На практике потребителя интересуют именно его задачи с определенной нагрузкой, тогда как в лаборатории в данном случае обычно удобнее использовать синтетику.
Тем не менее, когда появилась возможность в некотором приближении разобраться с первой проблемой, захотелось вернуться к этому вопросу и попробовать провести для начала несколько тестов. Безусловно, выбранные конфигурации и бенчмарки, вызовут множество вопросов у читателей, особенно если они являются профессионалами в данной области. Но просьба отнестись к этому материалу как попытке возрождения обсуждения темы и в комментариях предложить идеи (желательно конструктивные), как, что и почему было бы интересно исследовать в рамках данного направления. Двигаться есть куда, но направлений слишком много и выбрать интересные можно только с вашей помощью.
Напомним, как и для чего используются RAID-массивы и контроллеры на традиционных винчестерах. Ключевых причин три. Первая – необходимость создания дисковых томов большого объема. Одиночные диски сейчас есть на 12 ТБ, так что если нужно больше – придется использовать несколько дисков. Вторая – требование высокой скорости чтения и записи. Один винчестер способен показать максимально около 200 МБ/с, так что если нужно больше – тоже требуется подключить несколько дисков и обеспечить возможность одновременной работы с ними. Третий момент, непосредственно связанный с первыми двумя, – реализация отказоустойчивого массива. Обратите внимание, что речь идет исключительно о сохранении данных при выходе из строя диска (или дисков), что конечно связано с общим понятием «надежность хранения», но не заменяет такой операции, как создание резервных копий. Именно последняя позволяет обеспечить восстановление в случае таких неприятностей, как удаление или изменение файлов.
Данное тестирование проводилось на сервере с платформой Supermicro X8SIL, процессором Intel Xeon X3430 и 8 ГБ оперативной памяти. Ему уже около десяти лет и конечно он как минимум морально устарел. Но, пожалуй, единственной серьезной претензией здесь может быть отсутствие поддержки PCIe 3.0. С другой стороны, 8 линий PCIe 2.0 – это тоже неплохо для массива из нескольких жестких дисков.
Конфигурация массива – RAID6, размер блока 256 КБ. Все кэши для тома на контроллерах включены, остальные параметры по умолчанию, все контроллеры использовали батареи для резервного питания. Напомним, что для данных поколений адаптеров Adaptec можно переносить массивы без потери конфигурации и данных (причем не только «вверх», но и «вниз»), что, безусловно, очень удобно.
Для операционной системы в сервере был выбран Debian 9. Как обычно, со всеми обновлениями на момент проведения тестирования. Драйвера для контроллеров из состава дистрибутива, BIOS обновлены, для удобства управления установлен последний MaxView Storage Manager.
Тесты проводились на «сыром» томе, что еще больше уводит нас в сторону синтетики, однако позволяет более точно оценить возможности аппаратной конфигурации. В реальности же приложения и пользователи обычно работают с файлами, которые размещены на какой-то файловой системе, а доступ к ним может осуществляться не только локально, но и по сети с использованием определенных протоколов. И конечно все это заслуживает отдельного изучения.
В роли тестового пакета выступала утилита fio, в некоторой степени аналогичная известному пакету iometer. В отличие от него, она корректно работает в современных Linux и позволяет оценить сразу несколько параметров.
Файлы конфигурации утилиты имели следующий вид:
[test]
blocksize=256k | 4k
filename=/dev/sda
rw=read | write | randread | randwrite
direct=1
ioengine=libaio
iodepth=1 | 2 | 4 | 8 | 16 | 32 | 64
runtime=180
Где «|» подразумевает выбор одного из значений. Таким образом, исследовались операции последовательного чтения и записи с блоками размером 256 КБ и случайного чтения и записи с блоками по 4 КБ. Все тесты прогонялись с глубиной очереди от 1 до 64 и каждый занимал три минуты. По результатам смотрим на скорости в МБ/с, IOPS и задержки (clat avg в мс). При повторении обязательно перепроверьте имя устройства (filename=/dev/sda). Неверное указание этого параметра на тестах записи может привести к потере данных.
Как мы видим, опций у теста много. Кроме того, можно запустить и одновременно несколько операций. Так что все сочетания проверить просто невозможно и при выборе параметров стоит ориентироваться на характерные для требуемого варианта использования схемы. Ну и не будем забывать, что при особом старании (или везении) можно «положить» любую систему
Учитывая, что в массиве только восемь дисков, скорее всего, некоторые из характеристик будут ограничиваться именно возможностями диска, а не использованного контроллера. Последние, напомним, отличаются производительностью процессора, объемом памяти и некоторыми другими характеристиками.
Сначала стоит сделать замечание об использованном формате диаграмм. На каждом графике приводятся сразу два показателя – производительности и средней задержки в зависимости от параметра iodepth теста. При этом для последовательных операций мы выбрали более привычный показатель в мегабайтах в секунду, а для случайных – iops. В данном конкретном случае с фиксированным размером блока они прямо пропорциональны и равноценны с точки зрения оценки результата.
Начнем с наименее быстрого контроллера Adaptec ASR-6805, который появился на рынке более семи лет назад. Интересно, что, несмотря на его возраст, данная линейка все еще востребована потребителями, как бы странно это не звучало.
Кстати, заодно опишем схему именований – первая цифра показывает поколение, вторая (точнее одна или две – встречается и вариант 16) – число внутренних физических портов (объединенных по четыре в разъёмы SAS различных форматов), третья – число внешних портов, пятая указывает на тип шины (5 – это PCI Express). Дополнительно могут присутствовать суффиксы, указывающие на тип разъемов, сокращенный объем кэшпамяти, наличие дополнительных функций.
Итак, последовательные операции.
На чтении с нашего массива контроллер может обеспечить до 900 МБ/с. Судя по близости последней пары показателей и резкому росту задержек в последней точке, дальнейшего увеличения скорости можно не ждать. Очевидно, что при повышении глубины очереди будут только повышаться задержки, при этом общая скорость останется на указанном уровне.
На операциях записи картина немного иная – максимальное значение в 500 МБ/с достигается сразу на минимальной нагрузке. В дальнейшем мы видим только рост задержек при увеличении глубины очереди.
Таким образом, поставив целью допустимое время отклика массива, вы можете оценить возможную нагрузку по максимальному числу обращений.
Безусловно, если задача требует исключительно случайных операций доступа к данным, то сразу на ум приходит использование SSD, обеспечивающих просто совершенно другой уровень производительности. И проводимые на массиве тесты этого сценария являются в скорее иллюстрацией «самой плохой ситуации», чем отражением реального положения дел на практических задачах.
На чтении массив не вносит никаких «скрытых» расходов и мы видим рост IOPS при увеличении глубины очереди с одновременным ростом задержек. С этим контроллером я не проверял следующие значения iodepth, но как будет показано далее, IOPS имеют свой предел, после которого будет только расти время отклика с сохранением общей скорости. На график записи лучше не смотреть. Все очень и очень грустно. Накладные расходы RAID6 на операциях записи часто оцениваются как число дисков*IOPS одного диска/6. То есть на одну операцию записи контроллеру требуется по факту провести шесть операций (не считая математических расчетов) – чтение исходного блока, чтение двух блоков четности, пересчет, запись трех измененных блоков.
При случайной записи при любой глубине очереди производительность ограничена на уровне 300 IOPS (примерно 1 МБ/с) и сделать здесь почти ничего нельзя. К счастью, в реальной жизни ситуация необходимости 100% случайного доступа к десяткам терабайт данных случается редко, а кроме того, на помощь приходит кэш операционной системы.
Итак, для ASR-6805 на наших шаблонах мы получили – последовательное чтение и запись на уровне 900 и 500 МБ/с соответственно, случайное чтение и запись – примерно 1000 и 300 IOPS.
Переходим к следующему участнику. Модели ASR-7805 около четырех лет. Ключевые отличия этого поколения от прошлого – увеличение производительности процессора, в два раза больше объем кэшпамяти, шина PCIe 3.0, поддержка режима HBA, работа с ленточными библиотеками.
В целом, зависимость производительности от нагрузки сохраняется, но есть и некоторые отличия. На последовательном чтении можно получить более 900 МБ/с, но только при относительно небольшой глубине очереди, тогда как значения для последних строк существенно ниже. Аналогичная ситуация и с последовательной записью – если нагрузка невелика, то скорость близка к 700 МБ/с, но при росте глубины очереди она падает до 630 МБ/с.
На случайном чтении мы видим те же 1000 IOPS, а вот с записью данный контроллер справляется лучше – он способен обеспечить почти 400 IOPS.
Дополнительно с этим контроллером я протестировал случайное чтение с существенным увеличением глубины очереди.

Как и говорилось выше, на этом шаблоне можно получить и более высокие значения производительности, но цена (рост задержек) все-таки слишком высока. Итого для этой модели максимальные показатели составили – 960 и 680 МБ/с на последовательном чтении и записи, 1100 и 400 IOPS на случайном чтении и записи.
Последняя протестированная модель контроллера – ASR-81605ZQ. В данном материале ее дополнительные возможности (в частности, MaxCache) не использовались, так что результаты будут применимы и к «обычному» представителю серии. Эта линейка является последней актуальной из традиционных продуктов со стеком Adaptec. Более новые решения серии SmartRAID – это уже совершенно другая история. В восьмой серии появилась поддержка 12 Гбит/с SAS, накопителей с секторами 4kn, UEFI BIOS. Все это для данного теста не актуально.
На последовательном чтении уже нет такого эффекта, как у седьмой серии и при любой нагрузке можно получить около 1000 МБ/с. Запись также дает более стабильные результаты на уровне 700 МБ/с. Обратим также внимание на то, что задержки при той же нагрузке меньше, чем у прошлой модели.
На операциях случайного чтения все упирается в диски и мы снова видим те же 1100 IOPS в сочетании с 60 мс откликом. Да и запись тоже мало отличается от прошлой модели – около 400 IOPS.
По итогам тестирования можно сделать несколько выводов. Прежде всего, напомним, что касаются они исключительно протестированной конфигурации дискового массива. Во-первых, 6-я серия все еще может быть интересна для реальной работы. Во-вторых, более современные поколения хотя и показывают результаты выше, говорить о каком-то существенном их превосходстве пожалуй не стоит. Особенно это заметно на сравнении серий 7 и 8. Так что если в вашем сервере или СХД применяются массивы из относительно небольшого количества SATA винчестеров, можно обеспечить их эффективное (насколько это возможно) использование на любом из данных контроллеров. Но если встают вопросы производительности на случайных операциях в сочетании с томом большого объема, то к ним нужно подходить более внимательно. Привычный RAID6 на базе жестких дисков не способен здесь показать высокие результаты даже на современных аппаратных контроллерах. Да и случайное чтение тоже является непростой задачей для такой конфигурации.
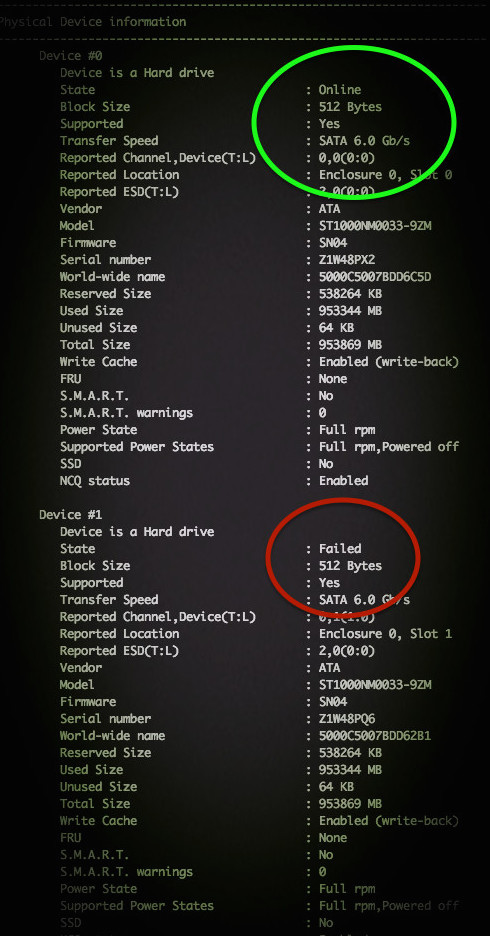
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
Или (более поздняя версия):
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Имею в серверном парке SAS диски Seagate и Hitachi. В боевую они работают через RAID контроллеры Adaptec или LSI.
Бывает такое, что появляется на диске на media error.
Если провести медиа сканирование с помощью, например, Adaptec Storage Manager, то эта media error в свойствах диска исчезает.
В smart-е показывает, что все ок - одной строчкой.
Маловато информации показывает этот софт.
Хотелось бы внимательно посмотреть на smart диска и провести дополнительное сканирование поверхности, перепрошить прошивку
Оставляю один Seagate диск на контроллере LSI 92618i, не конфигурирую его никак.
Seatool for DOS видит other контроллер, из пераметром диска только обьем, на диске можно сделать только диагностическое сканирование.
Seatool for windows видит диск MR9261-81, на диске можно сделать только диагностическое сканирование, прошивка обламывается
Seatool Enterprise не видит контроллер.
Пытался запустить DFT for dos c драйвером LSI 320x - не видит контроллер.
Поделитесь, пожалуйста, рабочими вариантами сочетания ПО и контроллеров.
С уважением,
Александр
shab2 писал(а): Запустил. Диск видится как LSI. Smart не показывает. Тестирование выполняет.
А как у тебя?
Здесь принято общаться на вы. Скачайте утилиты тестирования от производителей дисков, подключите их к обычному САС ХБА и протестируйте.
shab2 писал(а): Запустил. Диск видится как LSI. Smart не показывает. Тестирование выполняет.
А как у тебя?
Здесь принято общаться на вы. Скачайте утилиты тестирования от производителей дисков, подключите их к обычному САС ХБА и протестируйте.
Ответ на ты адресовался не Вам. Если Вы модератор, прошу дать ссылку на пункт правил, где запрещается обращение на ты.
По существу темы: Все использованные утилиты упомянуты. Если Вы знаете о других, скажите. Кроме контроллера LSI SAS 9261 использовался LSI SAS 8208XLP. Однако разницы в поведении программ не было. "Взять любой SAS HBA" - это платить деньги. Хотелось бы заранее знать модель с которой утилиты производителей умеют работать.
С уважением, Александр
И уберите из подписи - "С уважением"
Helium писал(а): Hd sentinel попробуйте.
Она видит смарт дисков (в т.ч. САС), подключенных к hardware контроллерам.
Не вводите людей в заблуждение, через рейд контроллер ни одна утилита ничего не увидит. imho
Как проверить и чем, уже давно написали, без хост контроллера никак.
Геннадий, а Вы точно не перегибаете палку?
Да, по поводу подписи у shab2 вышло резко, возможно даже неуважительно резко - но всё же до хамства, на мой взгляд, никак не дотягивает (кстати, как давний и регулярный посетитель и участник данного форума я неоднократно замечал за Вами не менее резкие ответы, однако Вас никто не одёргивал и не банил).
Другое дело, что Вы, как мне кажется, вольно или невольно форсировали развитие довольно таки безобидной ситуации, доведя её до модераториала.
Ув.Лис обратился к ув.shab2 на "ты". Ув.shab2 мог проигнорировать (ответив на "Вы"), мог возмутиться (мол, я с Вами , сударь, на брудершафт не пил"). Однако он ответил в том же ключе (на "ты"), не заморачиваясь формой. Ситуация замкнулась "сам на сам".
Вы же не преминули сделать замечание (почему-то топикстартеру, а не первому "тыкнувшему"), притом что никто из них не возражал против такого обращения; ну а кроме того "принято"(на "Вы") <> "обязательно"(на "Вы") - в правилах форума нигде ничего такого действительно не регламентировано.
В этой связи непонятны причины, побудившие Вас сделать ув.shab2 замечание и пригрозить баном - его (развёрнутый) ответ Вам не выходит, как мне кажется, за рамки приличий. Да, без расшаркиваний, но по-большому счёту всё правильно - нет запрета, нет и повода для одёргиваний.
Ув.shab2 мне, конечно, не сват, не брат, однако не хотелось бы создания грустного прецедента типа "попала шлея под мантию" (никогда не знаешь, что и в какой момент придётся Вам не по вкусу).
Плюс к тому подобное реагирование с Вашей стороны может изрядно подпортить Ваше реноме. В конце концов, Ваши ответы по техническим вопросам неплохо характеризуют Вас как специалиста, тогда как подобные эксцессы могут создать о Вас впечатление уже как о человеке - и не самое благоприятное.
Про то, что кто-то может просто не захотеть лишний раз иметь дело с фирмой, сотрудники которой ведут себя как высокомерные снобы и самодуры, уж и упоминать-то неудобно.
С уважением,
Umlyaut.
P.S. Полагаю, просить о пересмотре решения о бане ув.shab2 будет уместно.
Сейчас диски стоят через рейд-контроллер HP P410, через ПО котроллера ничего информативного кроме названия, серийника и скорости вращения подключенных дисков не видно. Если подключить диск/диски с интерфесом SAS к контроллеру который может работать как HBA (IT-mode, JBOD) будет ли виден полноценный СМАРТ (битые сектора, время нароботки и прочую полезную информацию)?

Подлючил к HBA, вид Смарта не поменялся, вывод - SATA-подобного вида SMART не посмотреть на SAS-дисках (меня лично интересовали больше всего часы наработки и бэд блоки)

Самая "пробивная" утилита для просмотра состояния дисков - smartmontools. Наиболее полные возможности у неё в Linux, но и в Windows частично что-то она может.
про AIDA64 и CrystalDiskInfo не уверен, но полагаю, что у них способностей поменьше будет
Пробовал, не показывает нормальный смарт тоже, максимум ошибок скоректированных. В SAS-дисках есть вообще смарт такого вида как у саташных (релокейты, часы наработки и пр.) просто его не так просто посмотреть или его вообще как такового нет?
ChikiHh, если вообще хоть что-то показывает конкретно по вашему диску, то вот оно и есть.
обычно проблема до диска достучаться, RAID контроллеры их закрывают и даже модель сторонними утилитами не видно.
наибольшее количество данных по SAS диску разве что спецутилита от вендора самого диска покажет.

smartmontools в режиме cciss впролне пробивается сквозь HPE-шные рейды, в том числе не в режиме HBA.
На SATA-дисках выводит обычный SMART, даже если диск в рейде.
Показывает даже больше, чем родная HPE-шная тулза
Но выдрать SATA-подобные счетчики с SAS-диска мне не удалось.
Спасибо за подробный комментарий, проделал тоже что и вы и именно поэтому задал вопрос, так как интересует именно есть ли вообще SATA-подобные счетчики на SAS-дисках (в частности часы наработки, нестабильные секторы и т.п.) и можно ли их посмотреть или в SAS-дисках они просто отсутствуют как таковые.
P.S. через несолько дней будет на руках HBA, подключу напрамую, гляну смарт и уже можно будет ответить на вопрос
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
Расшифрую эту команду:
- -LdPdInfo — получить информацию(Info) по логическим (Ld) и физическим(Pd) устройствам …
- -aALL — … на всех адаптерах
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
-
Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с Drive: 1 == /dev/sdb и в него входит 2 физических диска с Drive: 2 == /dev/sdc и в него входит 6 физических дисков с >Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
К примеру возьмем первый диск.
- write error counters — ошибки записи
- read error counters — ошибки считывания
- verify error counters (отображаются только когда не нулевое значение) — ошибки выполнения
- non-medium error counter (определенное число) — число восстанавливаемых ошибок отличных от ошибок записи/считывания/выполнения
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Errors Corrected by ECC, fast [Errors corrected without substantial delay: 00h]. An error correction was applied to get perfect data (a.k.a. ECC on-the-fly). «Without substantial delay» means the correction did not postpone reading of later sectors (e.g. a revolution was not lost). The counter is incremented once for each logical block that requires correction. Two different blocks corrected during the same command are counted as two events.
Errors Corrected by ECC: delayed [Errors corrected with possible delays: 01h]. An error code or algorithm (e.g. ECC, checksum) is applied in order to get perfect data with substantial delay. «With possible delay» means the correction took longer than a sector time so that reading/writing of subsequent sectors was delayed (e.g. a lost revolution). The counter is incremented once for each logical block that requires correction. A block with a double error that is correctable counts as one event and two different blocks corrected during the same command count as two events.
Error corrected by rereads/rewrites [Total (e.g. rewrites and rereads): 02h]. This parameter code specifies the counter counting the number of errors that are corrected by applying retries. This counts errors recovered, not the number of retries. If five retries were required to recover one block of data, the counter increments by one, not five. The counter is incremented once for each logical block that is recovered using retries. If an error is not recoverable while applying retries and is recovered by ECC, it isn’t counted by this counter; it will be counted by the counter specified by parameter code 01h — Errors Corrected With Possible Delays.
Total errors corrected [Total errors corrected: 03h]. This counter counts the total of parameter code errors 00h, 01h and 02h (i.e. error corrected by ECC: fast and delayed plus errors corrected by rereads and rewrites). There is no «double counting» of data errors among these three counters. The sum of all correctable errors can be reached by adding parameter code 01h and 02h errors, not by using this total. [The author does not understand the previous sentence from the Seagate manual.]
Correction algorithm invocations [Total times correction algorithm processed: 04h]. This parameter code specifies the counter that counts the total number of retries, or «times the retry algorithm is invoked». If after five attempts a counter 02h type error is recovered, then five is added to this counter. If three retries are required to get stable ECC syndrome before a counter 01h type error is corrected, then those three retries are also counted here. The number of retries applied to unsuccessfully recover an error (counter 06h type error) are also counted by this counter.
Gigabytes processed [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь
Для начала добавим демон в автозагрузку.
Так же было добавлено интервал запуска проверок. Далее нам нужно добавить диски на мониторинг, для чего служит файл smartd.conf.
Немного о HDD интерфейсах
Аббревиатуры:
SCSI— Small Computer System Interface
SAS— Serial Attached SCSI
SATA — Serial ATA
ATA — AT Attachment
Чтобы визуально понять как выглядят те, или иные интерфейсы навожу картинки.


С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
SMC2108 — означает, что у нас Supermicro MC2108 контроллер. Так же можно убедиться, что у нас Megaraid контроллер используя эту команду.
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
Как видим, на первом физическом диске есть «Media Error Count: 38». Это означает, что запасные(зарезервированные) сектора для remap(замены) битых секторов диска — закончились. И нужно проводить замену диска.
Так же нужно мониторить следующие параметры используя команду:
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
Данный скрипт проверяет все диски на наличие проблем с прошивкой,состояние рейда,ошибки физических дисков и состояние батареи. Если есть проблема с батареей — код выхода скрипта будет больше 250, если проблемы с остальными устройствами, то будет выведено только количество ошибок. Скрипт запускается без аргументов. Если добавить аргумент log, будет выведено текст с указанием проблемного элемента. Проверяем работу скрипта:
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
Читайте также: