
Процессоры с расширенной системой команд это
В зависимости от набора и порядка выполнения команд ЦП делятся на 4 класса, что также отражает историю развития ЭВМ.
Ранее других появились процессоры CISC (complex instruction set computer). Здесь для увеличения производительности используется расширение числа аппаратно и микропрограммно реализуемых команд. Но анализ работы ЦП показал, что в течение 80% времени выполняется только 20% всего набора команд. При этом введение таких команд, которые выполняются за несколько тактов ЦП (10 и более), имеют различную длину и используют различные способы адресации существенно усложняют логику управления и весь ЦП в целом и создают трудности на пути повышения производительности.
RISC(reduced instruction set computer) – 1974г. Джон Кок – процессоры с сокращённым набором команд одинаковой длины, включают только наиболее часто используемые команды. Большинство команд выполняются за 1 такт. В связи со своей простотой такие процессоры не патентуются, что способствует быстрой их разработке. В них используется конвейерная обработка команд, позволяющая обрабатывать несколько команд одновременно. Новый подход позволил сократить потребность в площади на кристалле интегральной схемы, что дало возможность резко увеличить число регистров. Однако процессоры RISCбыли несовместимы с CISC,что затрудняло их распространение.Но прогрессивная идеология RISCстала использоваться в архитектуре CISC и в настоящее время такие процессоры получили широкое распространение. Начиная с процессора Pentium, корпорация Intel начала внедрять технологии RISC в свои изделия (есть ядро, выполняющее самые простые и распространённые команды за 1 цикл, а по обычной технологии CISCинтерпретируются только более сложные команды. Такая гибридная архитектура позволяет повысить скорость выполнения программ и обеспечить совместимость со старым СПО.
MISC (minimum instruction set computer) – процессор, работающий с минимальным набором длинных команд. Увеличение разрядности ЦП позволило укладывать несколько команд в одно слово размером в 128 бит. Выбрав из памяти одно слово, ЦП может обрабатывать сразу несколько команд, т.е. за 1 цикл работы. . В этих процессорах, как и в RISC, используется небольшой набор часто используемых команд.
VLIW(verylarge instruction word) – процессоры, работающие с системой команд сверхбольшой разрядности. Идея технологии – создаётся специальный компилятор планирования, который проводит анализ ПП перед выполнением, группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора.
Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то компилятор может «уложить» в один пакет эти четыре разнотипные операции. Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими. Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
(При суперскалярной технологии отбор групп одновременно выполняемых команд выполняется непосредственно в ходе выполнения ПП, а в VLIW это делается заранее, что упрощает структуру ЦП.)
Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC. Известны также архитектуры MISC и VLIW
Лидером в разработке микропроцессоров с полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров.
Архитектура процессоров компании Intel основана на системе команд CISC (Complex Instruction Set Computer) – полной системе команд переменной длины. Команды процессора могут иметь длину от 8 до 108 бит, и процессор должен последовательно декодировать инструкцию после определения её границ. Первые процессоры для персональных компьютеров были скалярными устройствами ( то есть могли в каждый момент времени выполнять только одну команду), конвейерная обработка ( то есть одновременное выполнение нескольких команд на разных стадиях конвейера применялась лишь в больших ЭВМ).
Для CISC-процессоров характерно:
Ø сравнительно небольшое число регистров общего назначения;
Ø большое количество машинных команд, некоторые, из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов;
Ø большое количество методов адресации;
Ø большое количество форматов команд различной разрядности;
Ø преобладание двухадресного формата команд;
Ø наличие команд обработки типа регистр-память.
Позже появились процессоры, основанные на архитектуре RISC (Reduced Instruction Set Computer) – сокращённом наборе команд компьютера фиксированной длины, которая была оптимизирована для суперскалярных (с возможностью выполнения нескольких команд одновременно) конвейерных вычислений.
Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research.
Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Для RISC-процессоров характерно:
Ø архитектура, отделяющая команды обработки от команд работы с памятью;
Ø эффективная конвейерная обработка;
Ø система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт);
Ø логика выполнения команд, с целью повышения производительности, ориентировалась на аппаратную, а не на микропрограммную реализацию (чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата);
Ø наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные;
Ø для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983-1984 гг.) обозначился также прорыв в технологии изготовления сверхбольших интегральных схем. Простота архитектуры и ее эффективность, подтвержденная этими проектами, вызвали большой интерес в компьютерной индустрии и с 1986 года началась, активная промышленная реализация архитектуры RISC. К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих программаторов (компиляторов). Именно современная техника программирования позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд. Архитектуры процессоров CISC и RISC развивались практически независимо, однако в отдельных модификациях процессоров AMD удалось совместить обе архитектуры. То есть микроядро процессора работает на основе инструкций RISC, а специальный блок интерпретирует команды CISC для обеспечения совместимости с программами для процессоров х86.

Minimum instruction set computer — вычисления с минимальным набором команд. Дальнейшее развитие идей команды Чака Мура, который полагает, что принцип простоты, изначальный для RISC-процессоров, слишком быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие, RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC строится на стековой вычислительной модели с ограниченным числом команд (примерно 20-30 команд).
Very long instruction word — сверхдлинное командное слово. Архитектура процессоров с явно выраженным параллелизмом вычислений, заложенным в систему команд процессора. Являются основой для архитектуры EPIC. Ключевым отличием от суперскалярных CISC-процессоров является то, что для них загрузкой исполнительных устройств занимается часть процессора (планировщик), на что отводится достаточно малое время, в то время как загрузкой вычислительных устройств для VLIW-процессора занимается компилятор, на что отводится существенно больше времени (качество загрузки и, соответственно, производительность теоретически должны быть выше). Примером VLIW-процессора является Intel Itanium.
Центральный процессор в персональных компьютерах представляет собой микропроцессор, то есть, построен на одной микросхеме. В его состав входят:
•Центральное устройство управления - комплекс средств автоматического управления процессами передачи и обработки информации;
•Арифметико-логическое устройство - устройство, осуществляющее обработку информации и выработку признаков управляющих сигналов.
•Внутренняя память процессора:
-Постоянная память устройства управления.
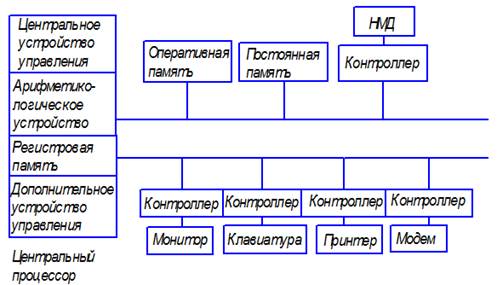
Рис. 1 Обобщенная структурная схема ПК
Модули оперативной и постоянной памяти, связаны с микропроцессором напрямую. Остальные устройства (монитор, клавиатура, накопители на магнитных носителях и т.д.) связаны с микропроцессором через контроллеры ввода-вывода, которые, в свою очередь, связаны с микропроцессором через системную шину.
Микропроцессор является ядром ЭВМ. Он осуществляет обработку данных и функции управления системой. К функциям управления системой относятся:
•инициирование операций ввода-вывода;
•управление доступом к основной памяти;
•обработка системных событий – прерываний;
•организация многозадачных режимов работы.
Организация центрального процессора определяется архитектурой и принципами работы ЭВМ ( состав и форматы команд, организация памяти). Логическая структура включает ряд функциональных средств:
•средства обработки информации;
•средства управления системой и программами;
•управление интерфейсом и каналами.
Структурно эти средства разбиваются на центральное устройство управления, АЛУ, внутреннюю память и управляющие устройства, связанные с конкретными устройствами вычислительной машины.
Центральное устройство управления принимает и расшифровывает команды, формирует адреса команд и операндов, формирует последовательности управляющих сигналов и обеспечивает координацию работы всех функциональных узлов, посредством выработки синхронизирующих сигналов.
Внутренняя память входит в состав первого уровня и связана с АЛУ и другими блоками центрального процессора непосредственно и имеет скорость работы соизмеримую со скоростью работы блоков процессора.
•Управляющая память входит в состав центрального устройства управления и относится к классу постоянной памяти. Этот вид памяти используется для хранения микропрограмм. Ее отличает очень высокое быстродействие и небольшая емкость, определяющаяся количеством команд в системе команд центрального процессора.
•Регистровая память выполнена на триггерных элементах и входит в состав центрального процессора. Емкость ее невысока, скорость высокая, но меньше, чем у управляющей памяти. Основной характеристикой данного типа памяти является разрядность.
Вы наверняка знаете, что мир процессоров разбит на два лагеря. Если вы смотрите это видео со смартфона, то для вас работает процессор на архитектуре ARM, а если с ноутбука, для вас трудится чип на архитектуре x86.
А теперь еще и Apple объявила, что переводит свои Mac на собственные процессоры Apple Silicon на архитектуре ARM. Мы уже рассказывали, почему так происходит. А сегодня давайте подробно разберемся, в чем принципиальные отличия x86 и ARM. И зачем Apple в это все вписалась?
Итак, большинство мобильных устройств, iPhone и Android'ы работают на ARM'е. Qualcomm, HUAWEI Kirin, Samsung Exynos и Apple A13/A14 Bionic — это все ARM-процессоры.
А вот на компьютере не так — там доминирует x86 под крылом Intel и AMD. Именно поэтому на телефоне мы не можем запустить Word с компьютера.
x86 — так называется по последним цифрам семейства классических процессоров Intel 70-80х годов.

Чем же они отличаются?
Есть два ключевых отличия.
Первое — это набор инструкций, то есть язык который понимает процессор
x86 процессоры используют сложный набор инструкций, который называется CISC - Complex Instruction Set Computing.
ARM процессоры наоборот используют упрощенный набор инструкций — RISC - Reduced Instruction Set Computing.
Кстати ARM расшифровывается как Продвинутые RISC машины - Advanced RISC Machines.
Наборы инструкций ещё принято назвать архитектурой или ISA - Instruction Set Architecture.
Второе отличие — это микроархитектура. Что это такое?
От того на каком языке говорят процессоры, зависит и то, как они проектируются. Потому как для выполнения каждой инструкции на процессоре нужно расположить свой логический блок. Соответственно, разные инструкции — разный дизайн процессора. А дизайн — это и есть микроархитектура.
Но как так произошло, что процессоры стали говорить на разных языках?
История CISC
Памятка программиста, 1960-е годы. Цифровой (машинный) код «Минск-22».
Всё началось в 1960-х. Поначалу программисты работали с машинным кодом, то есть реально писали нолики и единички. Это быстро всех достало и появился Assembler. Низкоуровневый язык программирования, который позволял писать простые команды типа сложить, скопировать и прочее. Но программировать на Assembler'е тоже было несладко. Потому как приходилось буквально “за ручку” поэтапно описывать процессору каждое его действие.
Поэтому, если бы вы ужинали с процессором, и попросили передать его вам соль, это выглядело бы так:
- Эй процессор, посмотри в центр стола.
- Видишь соль? Возьми её.
- Теперь посмотри на меня.
- Отдай мне соль. — Ага, спасибо!
- А теперь снова возьми у меня соль.
- Поставь её откуда взял
- Спасибо большое! Продолжай свои дела.
- Кхм… Процессор, видишь перец?
- И так далее.
Этот подход стал настоящим спасением как для разработчиков, так и для бизнеса. Захотел клиент новую инструкцию — не проблема, были бы деньги — мы сделаем. А деньги у клиентов были.
Недостатки CISC
Но был ли такой подход оптимальным. С точки зрения разработчиков — да. Но вот микроархитектура страдала.
Представьте, вы купили квартиру и теперь вам нужно обставить её мебелью. Площади мало, каждый квадратный метр на счету. И вот представьте, если бы CISC-процессор обставил мебелью вам гостиную, он бы с одной стороны позаботился о комфорте каждого потенциального гостя и выделил бы для него своё персональное место.
С другой стороны, он бы не щадил бюджет. Диван для одного человека, пуф для другого, кушетка для третьего, трон из Игры Престолов для вашей Дейенерис. В этом случае площадь комнаты бы очень быстро закончилась. Чтобы разместить всех вам бы пришлось увеличивать бюджет и расширять зал. Это не рационально. Но самое главное, CISC-архитектура существует очень давно и те инструкции, которые были написаны в 60-х годах сейчас уже вообще не актуальны. Поэтому часть мебели, а точнее исполнительных блоков, просто не будут использоваться. Но многие из них там остаются. Поэтому появился RISC…
Преимущества RISC
С одной стороны писать на Assembler'е под RISC процессоры не очень-то удобно. Если в лоб сравнивать код, написанный под CISC и RISC процессоры, очевидно преимущество первого.
Так выглядит код одной и той же операции для x86 и ARM.
x86
Представьте, что вы проектируете процессор. Расположение блоков на х86 выглядело бы так.
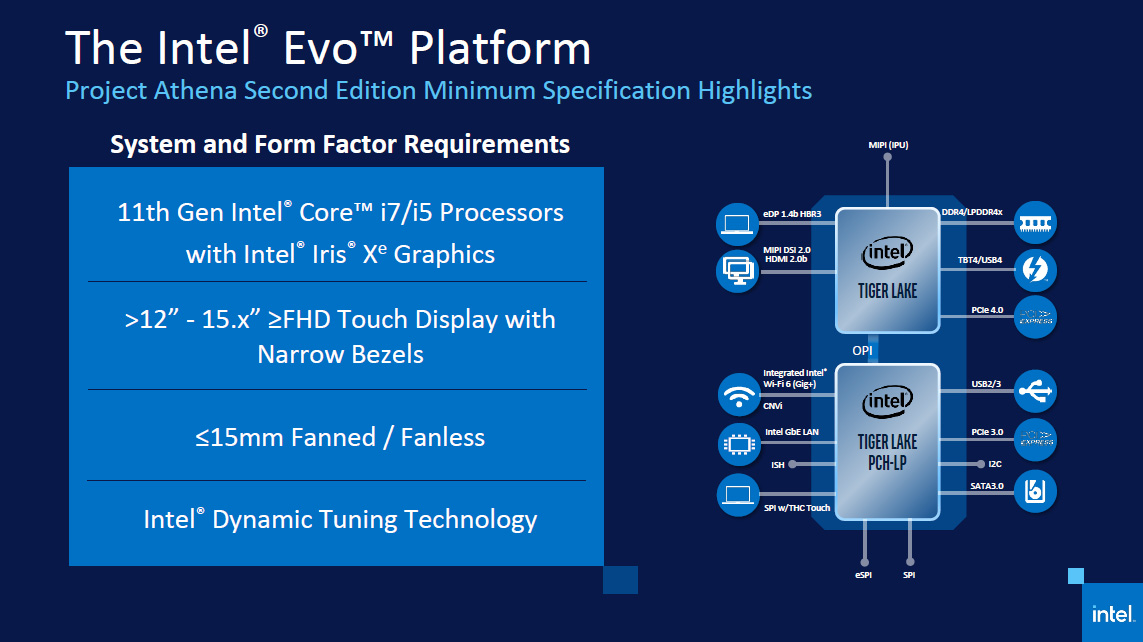
Каждый цветной квадрат — это отдельные команды. Их много и они разные. Как вы поняли, здесь мы уже говорим про микроархитектуру, которая вытекает из набора команд. А вот ARM-процессор скорее выглядит так.

Ему не нужны блоки, созданные для функций, написанных 50 лет назад.
По сути, тут блоки только для самых востребованных команд. Зато таких блоков много. А это значит, что можно одновременно выполнять больше базовых команд. А раритетные не занимают место.
Еще один бонус сокращенного набора RISC: меньше места на чипе занимает блок по декодированию команд. Да, для этого тоже нужно место. Архитектура RISC проще и удобнее, загибайте пальцы:
- проще работа с памятью,
- более богатая регистровая архитектура,
- легче делать 32/64/128 разряды,
- легче оптимизировать,
- меньше энергопотребление,
- проще масштабировать и делать отладку.
Поэтому наши смартфоны, которые работают на ARM процессорах с архитектурой RISC, долго живут, не требуют активного охлаждения и такие быстрые.
Лицензирование
Но это все отличия технические. Есть отличия и организационные. Вы не задумывались почему для смартфонов так много производителей процессоров, а в мире ПК на x86 только AMD и Intel? Все просто — ARM это компания которая занимается лицензированием, а не производством.
Даже Apple приложила руку к развитию ARM. Вместе с Acorn Computers и VLSI Technology. Apple присоединился к альянсу из-за их грядущего устройства — Newton. Устройства, главной функцией которого было распознавание текста.
Даже вы можете начать производить свои процессоры, купив лицензию. А вот производить процессоры на x86 не может никто кроме синей и красной компании. А это значит что? Правильно, меньше конкуренции, медленнее развитие. Как же так произошло?

Ну окей. Допустим ARM прекрасно справляется со смартфонами и планшетами, но как насчет компьютеров и серверов, где вся поляна исторически поделена? И зачем Apple вообще ломанулась туда со своим Apple Silicon.
Что сейчас?
Допустим мы решили, что архитектура ARM более эффективная и универсальная. Что теперь? x86 похоронен?
На самом деле, в Intel и AMD не дураки сидят. И сейчас под капотом современные CISC-процессоры очень похожи на RISC. Постепенно разработчики CISC-процессоров все-таки пришли к этому и начали делать гибридные процессоры, но старый хвост так просто нельзя сбросить.

Но уже достаточно давно процессоры Intel и AMD разбивают входные инструкции на более мелкие микро инструкции (micro-ops), которые в дальнейшем — сейчас вы удивитесь — исполняются RISC ядром.
Да-да, ребята! Те самые 4-8 ядер в вашем ПК — это тоже RISC-ядра!
Надеюсь, тут вы окончательно запутались. Но суть в том, что разница между RISC и CISC-дизайнами уже сейчас минимальна.
А что остается важным — так это микроархитектура. То есть то, насколько эффективно все организовано на самом камне.
Ну вы уже наверное знаете, что Современные iPad практически не уступают 15-дюймовым MacBook Pro с процессорами Core i7 и Core i9.

А что с компьютерами?
Недавно компания Ampere представила свой 80-ядерный ARM процессор. По заявлению производителя в тестах процессор Ampere показывает результат на 4% лучше, чем самый быстрый процессор EPYC от AMD и потребляет на 14% меньше энергии.

Компания Ampere лезет в сегменты Cloud и Workstation, и показывает там отличные цифры. Самый быстрый суперкомпьютер в мире сегодня работает на ARM ISA. С обратной стороны, Intel пытается все таки влезть в сегмент low power и для этого выпускает новый интересный процессор на микроархитектуре lakefield.
Пока у ноутбуков и процессоров от Intel есть одно неоспоримое достоинство - (охлаждение и) единство архитектуры. Пока на рынке ARM-процессоров существуют Qualcomm, Samsung, MediaTek, в мире x86 творится монополия и разработчикам сильно легче делать софт и игры под “взрослые” процессоры.
И Apple та компания, которая способна мотивировать достаточное количество разработчиков пилить под свой ARM. Но суть этого перехода скорее не в противостоянии CISC и RISC. Поскольку оба подхода сближаются, акцент смещается на микроархитектуру, которую делает Apple для своих мобильных устройств. И судя по всему микроархитектура у них крута. И они хотели бы ее использовать в своих компьютерах.
И если бы Intel лицензировал x86 за деньги другим людям, то вероятно Apple просто адаптировали свою текущую микроархитектуру под x86. Но так как они не могут этого сделать, они решили просто перейти на ARM. Проблема для нас с микроархитектурой в том, что она коммерческая тайна. И мы про нее ничего не знаем.
Итоги

Спрос на ARM в итоге вырастет. Для индустрии это не просто важный шаг, а архиважный. Линус Торвальдс говорил, что пока рабочие станции не станут работать на ARM — на рынке серверов будут использовать x86.
И вот это случилось — в перспективе это миллионы долларов, вложенных в серверные решения. Что, конечно, хорошо и для потребителей. Нас ждет светлое будущее и Apple, действительно, совершила революцию!
Редактор материала: Антон Евстратенко. Этот материал помогли подготовить наши зрители Никита Куликов и Григорий Чирков. Спасибо ребята!
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Многие знают, что в России производятся процессоры «Эльбрус» и, исходя из мнений «диванных экспертов» делают ошибочные выводы о полной их непригодности. А между тем у «Эльбрусов» есть важнейшие критерии, по которым они превосходят процессоры AMD и Intel.
В России есть компания МЦСТ (Московский Центр Спарк Технологий), которая занимается разработкой отечественных процессоров «Эльбрус». Их архитектура и система команд является полностью отечественной разработкой.
реклама

Многие в кавычках технические эксперты, с просторов интернета преподносят нам информацию о полной никчемности и бесполезности этих процессоров. Подходят к этому вопросу однобоко, оценивают только их производительность, и совершенно не рассматривают другие важные критерии. Ссылаясь на проведенные сравнительные тесты с устаревшими процессорами, например с одним из таких как Intel Core i7 2600, в которых «Эльбрусы» в несколько раз уступают ему по производительности, ставят крест на «Эльбрусах».

При этом абсолютно не задумываясь, что у них совершенно другое назначение, и разрабатывались они не для игры в World of Tanks. Или аргументируют свои выводы тем, что даже Сбербанк отказался от использования серверов на базе «Эльбрусов» по причине их недостаточной производительности.
реклама
И да, бесспорно, производительность у «Эльбрусов» крайне низкая, даже по сравнению с устаревшим Intel Core i7 2600. Так в чем же «Эльбрусы», учитывая, что они направлены на государственный и оборонный сектор, могут превосходить подобных монстров, как AMD и Intel?
Чтобы ответить на этот вопрос, нужно вспомнить, какое главное требование предъявляется к вычислительным системам, которые обслуживают государственный и оборонный сектор. Этим требованием будет информационная безопасность.
Дыры в безопасности процессоров AMD и Intel
А какая может быть информационная безопасность у вычислительных систем на процессорах AMD и Intel? Правильно, никакая. Если на этапе их проектирования и производства, компании могут беспрепятственно вносить в них аппаратные закладки любого назначения. А после распространения этих процессоров по всему миру, скрытно собирать необходимые данные. Закладка – это скрытно встроенный в процессор аппаратный инструмент, при помощи которого заинтересованные лица могут получить доступ к конфиденциальным данным или к дистанционному управлению компьютером.
реклама
Кроме того у процессоров AMD и Intel имеется еще и большое количество аппаратных уязвимостей внесенных непреднамеренно, они в этом плане дырявые как решето.

Компания AMD и Intel признают наличие в своих процессорах непреднамеренных уязвимостей, и постоянно публикуют об этом отчеты.
реклама
А ведь это серверный сегмент, где безопасность информации святая святых. А насколько безопасно их можно использовать в оборонной сфере? А ведь это безопасность нашего государства.
Преимущества процессоров Эльбрус
В процессорах «Эльбрус», несмотря на то, что они производятся на производственных мощностях другого государства, Тайваньской компанией TSMC, вероятность внедрения «закладок» стремится к нулю. Поскольку компании TSMC не предоставляется вся документация на процессор, предоставляется только на фотошаблон. А определить по фотошаблону и по документации на него, как взаимодействуют миллиарды транзисторов между собой невозможно. А без понимания этого, не удастся разработать и внедрить в процессор какую-либо закладку. Кроме того в «Эльбрусах» используется технология «безопасных вычислений» позволяющая выявлять ошибки в ПО, которые могут использоваться как уязвимости. Аппаратная защита процессора обнаруживает подобные ошибки и блокирует возможность их исполнения. Так же высокую информационную безопасность обеспечивает и используемая для работы с «Эльбрусами» защищенная отечественная операционная система «Альт 8СП» и архитектура процессоров E2K, корни которой идут еще из СССР.

Основным отличием архитектуры E2K от других, является то, что распараллеливание потоков в ней осуществляется программным компилятором, который делает это значительно эффективнее, чем аппаратные компиляторы других архитектур. Поддерживает эта архитектура и ОС Windows, правда только в режиме эмуляции, преобразовывая коды «на лету» и теряя при этом до 30% производительности.
Таким образом, вычислительные системы, построенные на процессорах «Эльбрус» имеют все законные основания стать самыми надежными системами по обеспечению безопасности информации. И решение о выборе систем на «Эльбрусах» или на AMD и Intel, должно зависеть от того, какие критерии у пользователя в приоритете, общая производительность или информационная безопасность.
Многие скажут, что и в технологическом плане они значительно уступают другим процессорам.

Да, в некотором роде это так, техпроцесс, по которому будет производиться перспективный процессор «Эльбрус-16С» составит только 16 нм, а техпроцесс предыдущей версии «Эльбрус-8С» составляет 28 нм, что как в первом, так и во втором случае далеко до 7 нм процессоров AMD Ryzen. Но и этот недостаток, при некоторых обстоятельствах, например как при работе процессора в условиях ионизирующего излучения, вполне свойственного для оборонной сферы, оказывается преимуществом. Дело в том, что чем меньше физические размеры транзисторов процессора, тем меньше в них атомов вещества, и тем быстрее происходит разрушение их атомарной решетки под воздействием радиации. И напротив, более крупные транзисторы будут разрушаться медленнее, и работа процессора в целом под воздействием радиации будет более длительной.
Выводы
Таким образом, результатом всего вышесказанного является вывод, что процессоры «Эльбрус» предназначены для потребителя, у которого главным приоритетом является безопасность информации. К этой категории потребителей в первую очередь можно отнести государственный и оборонный сектор. И не корректно сравнивать «Эльбрусы» с процессорами AMD, Intel и другими. Это равносильно сравнению скоростей экскаватора и легковой машины, движущихся по дороге, и то и другое движется, но решаемые задачи абсолютно разные.
Надеюсь, моя статья была для вас интересна. Пишите в комментариях, что думаете вы о целесообразности существования и дальнейшего развития процессоров «Эльбрус».
Подпишитесь на наш канал в Яндекс.Дзен или telegram-канал @overclockers_news - это удобные способы следить за новыми материалами на сайте. С картинками, расширенными описаниями и без рекламы.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Прерывания
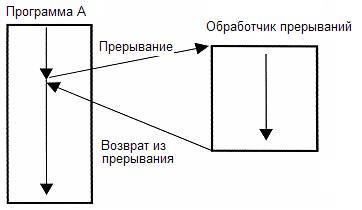
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Читайте также: