
Предсказатель переходов процессора это
Давно уже был тот момент, когда увидели свет предыдущие части цикла статей, которые рассказывали об устройстве процессора, о том, как он выполняет команды, и о том, что такое конвейер и для чего он нужен. Теперь мы познакомимся еще с одним компонентом процессора: предсказателем переходов.
Многие полагают, что в работе вычислительной техники нет места неопределенности и элементам теории вероятности. А уж угадываниям и «вангованию» - так и подавно. Оказывается, что это далеко не так. И если до сих пор считаете так, то мы в данной статье переубедим вас.
Давайте вспомним: среди команд, выполняемых процессором, есть команды перехода. Они бывают двух типов: условные и безусловные. Команды выполняются последовательно, одна за другой, а когда встречается команда перехода, происходит «прыжок» на другой адрес. Если команда безусловная, то этот «прыжок» происходит в любом случае. А если команда условная, то надо еще решить, нужно ли нам прыгать.
Когда проводятся какие-либо вычисления, следующим шагом мы проверяем, получился ли результат нулевой. И в зависимости от этого выполняем разные действия. В коде это будет выглядеть примерно так:
result = a * b – с / d;
// набор команд при нулевом результате (ветвь 1)
// набор команд при ненулевом результате (ветвь 2)
Кажется, что всё хорошо: сначала посчитали результат, а потом проверили, нулевой ли он. Загрузили новый адрес и продолжили выполнение. Так-то оно так, но давайте вспомним, что у нас есть конвейер! Пока будет считаться результат, конвейер уже может успеть запустить на выполнение несколько новых команд. Но как? Ведь он же не знает, по какой ветви двигаться, пока не рассчитает предыдущее значение.
Как выйти из создавшейся ситуации? Подождать, пока результат будет рассчитан, а потом продолжить выполнение? Пожалуй, это простейшее, однако не самое лучшее решение, поскольку это сводит на нет все преимущества конвейера в плане ускорения вычислений.
Ещё один способ. Создать в процессоре возможность выполнять обе ветви одновременно, а в конце выбрать необходимый результат. Но тут свои проблемы: а как быть, если у нас в ветви встретится еще одно условие? А если ещё большей вложенности условий? Вернуться к первому варианту в таком случае? Не выход. К тому же, это существенно удорожает процессор.
Решение было найдено достаточно изящное: установить предсказатель переходов. Такое устройство, которое будет угадывать, по какой ветви нам придется идти. Кажется странным, не правда ли? Но все на самом деле ещё более странно выглядит, когда начинаешь разбираться в том, как же предсказатель угадывает ветвь, по которой пойдет вычисление.
Давайте посмотрим на простейшие предсказатели переходов. Конечно, такие предсказатели не используются в реальной технике, однако некоторые из них (а может и все) когда-то давно применялись.
- Переход происходит всегда. Один из простейших вариантов, который в любом случае осуществляет переход. В процессоре не требуется никаких дополнительных компонентов. Вероятность угадывания таким предсказателем около 50%.
- Переход не происходит никогда. Ещё один простейший вариант. Полностью аналогичен предыдущему, за исключением того, что всегда выбирается иная ветвь. Вероятность угадывания те же 50% (та половина, которая не угадывается первым вариантом).
- Переход происходит всегда, когда назад. Если адрес перехода меньше текущего адреса, то переход будет, а если больше, то не будет. Вероятность угадывания таким предсказателем около 70%. Повышение вероятности связано с тем, что в большинстве случаев переход назад – это переход на очередной шаг цикла. Если цикл должен выполниться 50 раз, то 49 переходов будет назад и лишь один будет вперед.
Рассмотренные выше предсказатели называются статическими, поскольку их предсказания не зависят ни от чего, что происходит во время выполнения. Как видно, их эффективность не особо высокая. Другая разновидность предсказателей – это динамические предсказатели. Их существует достаточно много видов, каждый из которых работает по-своему.
Основная идея динамических переходов – это анализ истории прошлых переходов. Существует история глобальных переходов, куда записываются все переходы, а также история локальных переходов, куда по раздельности записываются переходы каждого типа (ассемблерные команды je, jne, jg, jz и так далее). Алгоритм работы таких предсказателей бывает весьма интересным, и создается впечатление, что предсказатель просто магическим образом угадывает ветвь. Например, выбирается несколько значений из истории локальных переходов, на основе этих значений выбираются некоторые значения из истории глобальных переходов, а затем вновь выбранные значения отправляются в конечный автомат, который по результатам работы выдает на выход информацию о том, будет ли переход или нет. И что самое интересное, что при отсутствии, казалось бы, логики в работе этих предсказателей, вероятность угадывания ими достаточно высокая: 96-98%!
Но все же, что будет, если предсказатель переходов не угадал направление, и произошло выполнение не той ветви? В таком случае осуществляется сброс конвейера, полная его очистка, и загрузка заново. Конечно, теряется время, но все же намного меньше (в целом при выполнении всей программы), чем в случае остановки конвейера до того момента, пока не станет точно известен результат.
И еще небольшой момент: что делать процессору, если у него история переходов пуста? В таком случае динамические предсказатели перехода не могут ничего предположить, да и угадать у них тоже вряд ли получится. В этом случае процессор прибегает к помощи статического предсказателя (как правило, к варианту «Переход происходит всегда, когда назад»). И когда заполнятся истории динамического предсказателя, произойдёт переход к нему.
Как говорится, удивительное рядом. Тяжело было бы предположить вообще, что при работе компьютера находится место реализации теории вероятности и угадываниям. Но, как оказывается, без этого не удается обойтись. И предсказатель переходов – очередное тому подтверждение. Выдавая достаточно высокий процент точности предсказаний, он становится незаменимым ускорителем конвейеризации вычислений.
Эта заметка написана по мотивам одного любопытного поста, краткий коммент её же автора к которому сподвиг меня разобраться в происходящем поподробнее. Предлагается сравнить две вариации алгоритма сортировки пузырьком. Первая из них – обычный пузырёк, с небольшой оптимизацией — внутренний цикл можно закончить немного раньше, зная, что оставшаяся часть массива уже отсортирована:
for (i=0; i for (j=0; j if (a[j] > a[j+1])
swap(a[j], a[j+1]);
Во втором варианте внутренний цикл проходит по другой части массива, однако алгоритмически этот вариант эквивалентен первому (подробности ниже):
for (i=0; i for (j=i; j>=0; j--)
if (a[j] > a[j+1])
swap(a[j], a[j+1]);
Запускаем (код), например, для N=100 000 на массиве int'ов, и получаем около 30 секунд в первом случае, и меньше 10 секунд — во втором, то есть отличие в 3 раза! Откуда же тогда берётся такая разница?
Для начала проверяем, что дело не в оптимизациях компилятора. В этом легко убедиться, сгенерировав и сравнив ассемблерные коды в обоих случаях. Либо можно отключить оптимизацию. Или же можно переписать код на ассемблере (например, используя ассемблерные вставки). В любом случае эффект сохраняется.
Далее, как проверить, что оба варианта эквиваленты? Например, можно вывести в строку сравниваемые значения a[j], a[j+1] и соответствующее значение j, отсортировать получившийся список, а затем сравнить их построчно (конечно же, разумно это делать для небольших N). Оказывается, что списки совпадают, а значит в обоих случаях выполняются одни и те же сравнения и одни и те же присваивания, и разница заключается только в порядке выполнения этих операций.
Ага, скажут некоторые, но мы ведь знаем другие примеры, когда в зависимости от порядка выполнения операций зависит время их выполнения. Например, есть же разница между последовательным и случайным доступом к памяти, даже если мы будем считывать одни и те же данные. В этом случае дело в том, что обращение к памяти – достаточно долгий процесс, и процессор практически простаивает в то время, когда он мог выполнять сотни инструкций. Однако при последовательном доступе эти задержки амортизируются за счёт процессорных кэшей, куда копируется сразу большое количество данных, и доступ к которым осуществляется существенно быстрее.
Но заметим, что в нашем случае объём данных не такой и большой – 100’000 int’ов это всего лишь 400Кб, в то время как современные процессоры обладают кэшами L2 от мегабайта и больше. Кроме того, в обоих случаях мы последовательно обращаемся к элементам массива, поэтому задержки обращения к памяти опять же амортизируются. Наконец, если уменьшать N, то всё равно наблюдается то же самое отличие в 3 раза. Поэтому, здесь кэши хоть и играют свою роль, но не являются основной причиной наблюдаемого эффекта.
Чтобы разобраться в происходящем и проверить предыдущее утверждение, проанализируем оба варианта при помощи процессорных счётчиков. Эти счётчики подсчитывают число выполненных инструкций, обращений к кэшам, количество произошедших ветвлений, и многие другие параметры. Для снятия показаний я использовал интеловскую (пробную версию — да-да, не ждите халявы, тут вам не гугл!) VTune Performance Analyzer, но существуют и другие способы. Запускаем, выполняется анализ, и получаем на выходе (P4 Prescott, L1 16Кб, L2 2Мб, первый вариант vs. второй):
Выполненных инструкций: 40 vs. 35 (·10 9 )
Промахов кэша L2: 1.1 vs. 1.8 (·10 9 )
Промахов кэша L1: 1.6 vs. 0.4 (·10 6 )
Итак, что отсюда следует? Во-первых, промахов кэша первого уровня в расчёте на инструкцию приходится очень мало, а поэтому и соответствующие задержки не так значительны. Во-вторых, промахов кэша второго уровня всё же достаточно много, но оказывается, что во втором варианте промахи случаются даже чаще, чем в первом! Результаты на других процессорах могут быть немного другие (в частности, может быть ещё кэш L3, которого нет на моём процессоре), но думаю, что общая картина останется примерно такой же.
Итак, дело не в кэшах. Но посмотрим на дополнительные результаты анализа:
Количество переходов (ветвлений, branches): 1.0 vs. 1.0 (·10 10 )
Ошибок предсказателя переходов (mispredicted branches): 0.16 vs. 0.00009 (·10 10 )
Небольшое отступление для тех, кто, как и я был до недавнего времени, не знаком с такой интересной вещью, как предсказатель переходов (branch predictor) — как ни странно, я не нашёл топиков о нём на хабре.
Вы наверняка знаете, что современные процессоры за счёт конвейера инструкций (instruction pipeline) выполняют не одну инструкцию за другой последовательно, а сразу несколько инструкций параллельно, и затем объединяют результаты. Однако последовательность инструкций может зависеть от результатов условных переходов, как в нашем примере — в случае, если a[j]>a[j+1], то выполняется перестановка элементов, а в противном случае — нет. Тут на помощь приходит предсказатель переходов, который пытается догадаться, будет ли выполнент переход или нет, и в соответствии с этим выбираются инструкции для конвейера.
Предсказатель переходов может быть статическим и динамическим. Динамический пытается предсказать переход, основываясь на истории предыдущих переходов. В случае, если эта история ещё не набрана, применяется статический предсказатель, но он в нашем случае не важен. На тему статических и динамических предсказателей мне понравилась эта статья (англ.), хотя в реальности всё, конечно, сложнее.
Насколько же важен предсказатель переходов и его ошибки? Википедия сообщает, что на современных процессорах задержка составляет десятки тактов, что не так уж и много само по себе много (leotsarev). Однако, кроме того, отсутствие таких ошибок может означать очень хорошую выгоду, поскольку за счёт большой длины конвейера процессор может «заглянуть» на много инструкций вперёд. В этом можно убедиться при помощи следующего кода:
Здесь p[] – массив, определяющий, нужно ли выполнять условный переход, или нет, а счётчик служит просто для различения этих двух событий. В случае, если все значения p[j] одинаковы, то через несколько итераций переход уже хорошо предсказуем. Если же p[j] сгенерировано некоторым, например, периодическим образом, то предсказуемость перехода будет зависеть от реализации предсказателя. Но при случайном заполнении массива предсказать следующий переход, при определённых ограничениях, нельзя. Нужно отметить, что размер массива M важен – если массив будет слишком большим, то он может плохо кэшироваться, а если слишком маленьким – то переход можно будет предсказать.
На моём компьютере время выполнения этого кода различается в 4-6 раз в зависимости от степени случайности заполнения массива. В случае, если выполнять более сложную операцию, чем увеличение счётчика, например, перестановку элементов массива, то различие уменьшается, но не намного. Таким образом, наличие или отсутствие ошибок предсказателя переходов могут привести к разнице во времени выполнения в несколько раз, что и наблюдается в нашей исходной задаче.
Согласно приведённым выше результатам анализа, в первом варианте сортировки ошибки предсказателя происходят в 16% случаях, а во втором – в 1000 раз реже. Почему так получается? Это можно понять, рассмотрев, как происходит сортировка в обоих случаях.
В первом случае, при небольших i внутренний цикл по j пробегает почти до конца массива, не трогая лишь отсортированный «хвост». Изначально данные в этой части массива неупорядочены, и поэтому условие a[j]>a[j+1] выполняется практически случайно. При увеличении i происходит некоторое упорядочивание элементов за счёт перестановок, но всё равно остаётся большая доля случайности (анимация). Поэтому предсказать переход достаточно сложно, что и приводит к большому числу ошибок предсказателя.
Во втором случае, при i=0 внутренний цикл лишь сортирует a[0] и a[1], при i=1 он добавляет a[2], и так далее. Фактически, это сортировка вставками (но не бинарными) — на i-ом шаге происходит вставка элемента a[i+1] в уже отсортированный подмассив a[0..i] (анимация). Поскольку элемент вставляется с конца подмассива, то в большинстве случаев будет выполняться последовательное перемещение этого элемента до необходимой позиции в массиве, и значение условия p[j]>p[j+1] будет одинаковым до того, как он её достигнет. Таким образом, после нескольких итераций переход легко предсказать, чему предсказатель переходов, похоже, несказанно рад.
Модуль предсказания условных переходов (англ. Branch Prediction Unit ) — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как он будет выполнен. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора. [1]
Существует два основных метода предсказания переходов: статический и динамический.
Статическое предсказание
Статические методы предсказания ветвлений являются наиболее простыми. Суть этих методов состоит в том, что различные типы переходов либо выполняются всегда, либо не выполняются никогда. В современных процессорах статические методы используются лишь в том случае, когда невозможно использование динамического предсказания.
Примерами статического предсказания могут служить тривиальное предсказание переходов, применявшееся в ранних процессорах архитектуры MIPS (предполагается, что условные переходы никогда не выполняются), а также статическое предсказание, использующееся в современных процессорах в качестве «подстраховки» (предполагается, что любой обратный переход является циклом и выполняется, а любой прямой переход не выполняется).
Содержание
Статическое предсказание
Статические методы предсказания ветвлений являются наиболее простыми. Суть этих методов состоит в том, что различные типы переходов либо выполняются всегда, либо не выполняются никогда. В современных процессорах статические методы используются лишь в том случае, когда невозможно использование динамического предсказания.
Примерами статического предсказания могут служить тривиальное предсказание переходов, применявшееся в ранних процессорах архитектуры SPARC и MIPS (предполагается, что условные переходы никогда не выполняются), а также статическое предсказание, использующееся в современных процессорах в качестве «подстраховки» (предполагается, что любой обратный переход, т.е. переход на более младшие адреса, является циклом и выполняется, а любой прямой переход, т.е. на более старшие адреса, не выполняется).
Динамическое предсказание
Динамические методы, широко используемые в современных процессорах, подразумевают анализ истории ветвлений. Примером динамического предсказания может служить двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction ), использовавшийся процессорами архитектуры P6 (анализируется таблица истории переходов, содержащая младшие значимые биты адреса инструкции и соответствующую им вероятность условного перехода: «скорее всего, будет выполнен», «возможно, будет выполнен», «возможно, не будет выполнен», «скорее всего, не будет выполнен» и обновляемая после каждого перехода).
Рассмотрим понятие модуля предсказания переходов - устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, предсказывающее, будет ли выполнен условный переходов исполняемой программе.
Для предсказания переходов процессор использует расширенный алгоритм Yeh'а, позволяющий с большой достоверностью спрогнозировать, будет ли выполняться переход. Если предсказание окажется верным, то исполнение продолжится с малой задержкой или совсем без задержки. Если же предположение ошибочно, то частично выполненные команды придется удалять из конвейера, а новые команды выбирать из области памяти с правильным адресом, декодировать и выполнять их. Это повлечет за собой существенное снижение производительности, напрямую зависящее от глубины конвейера — для архитектуры P6 в случае ошибочного предсказания перехода потери составят от 4 до 15 тактов.
Алгоритм предсказания ветвлений является динамическим двухуровневым и основывается на поведении команд перехода за предшествующий период, а также на поведении конкретных групп команд, для которых с большой вероятностью можно предсказать конкретный переход. Точность предсказания данного алгоритма составляет порядка 90 процентов.
Предположим, что ничего исключительного не происходит и что буфер переходов в своих предсказаниях оказался прав (в P6 предусмотрены эффективные действия в случае неправильного предсказания перехода).
Кэш команд выбирает строку кэша, соответствующую индексу в указателе на следующую команду, и следующую за ней строку, после чего передает 16 выровненных байтов декодеру. Две строки считываются из-за того, что команды в архитектуре Intel выровнены по границе байта, и поэтому может происходить передача управления на середину или конец строки кэша. Выполнение этой ступени конвейера занимает три такта, включая время, необходимое для вращения предвыбранных байтов и их подачи на декодеры команд. Начало и конец команд помечаются.
Три параллельных декодера принимают поток отмеченных байтов и обрабатывают их, отыскивая и декодируя содержащиеся в потоке команды. Декодер преобразует команды архитектуры Intel в микрокоманды-триады (два операнда, один результат). Большинство команд архитектуры Intel преобразуются в одну микрокоманду, некоторые требуют четырех микрокоманд, а сложные команды требуют обращения к микрокоду, представляющему из себя набор заранее составленных последовательностей микрокоманд. Некоторые команды, так называемые байт-префиксы, модифицируют следующую за ними команду, что также усложняет работу декодера. Микрокоманды ставятся в очередь, посылаются в таблицу псевдонимов регистров, где ссылки на логические регистры преобразуются в ссылки на физические регистры P6, после чего каждая из микрокоманд вместе с дополнительной информацией о ее состоянии (статусе) посылается в пул команд. Пул команд реализован в виде массива контекстно-адресуемой памяти, называемого также буфером переупорядочивания.
Пул команд – это буфер переупорядочения.
Прежде чем попасть в пул команд (известный формально, как буфер переупорядочения) поток микроинструкций имеет тот порядок, который определяется потоком команд процессора, посылаемым в дешифратор команд. Никакого переупорядочения команд нет.
Буфер переупорядочения представляет собой массив ассоциативной памяти, состоящей из 40 регистров микроинструкций. Он содержит микроинструкции, ожидающие исполнения, а также выполненные микроинструкции, результаты которых еще не зафиксированы в состоянии процессора. Блок диспетчирования/исполнения может выполнить микроинструкции из этого буфера в любом порядке.
Более подробно об алгоритме yeh-а.
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 52б
Принципы организации шин расширения. ISA, VLB, PCI как последовательные этапы перехода к централизации вычислительной системы относительно магистрали. Сопроцессоры, влияние сопроцессоров на принципы Фон-Неймана. Архитектура систем реального времени (СРВ). Базовые модули. Выполняемые функции.

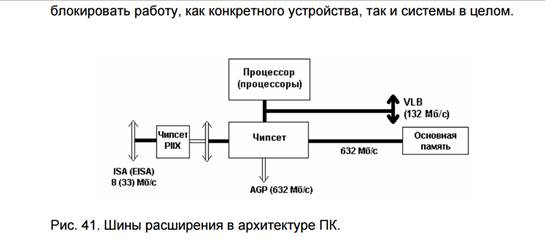
Шина ISA (Industry Standard Architecture)
В усовершенствованной версии шины ISA используется 16-разрядная шина данных и 24-разрядные адреса. Конструктивно расширение было сделано за счет установки второго 36-контактного разъема, правда в дальнейшем оба разъема шины ISA объединили в один.
Кроме линий адреса и данных, на шине ISA имеются сигналы управления, с помощью которых производится запись/чтение данных и разрешение конфликтов между устройствами, вставленными в слоты ISA.
Платы расширения с восьмибитной шиной могут вставляться в 16-битный слот без каких-либо проблем.
Для увеличения производительности шины ISA одно время совместно с ней использовалась шина VLB (VESA [4] Local BUS). При этом питание и ряд сигналов управления плата расширения получала через шину ISA, а обмен данными происходил через шину VLB, которая непосредственно подключалась к системной шине процессора.
Шины PCI (Peripheral Component Interconnect ) local bus.
Шина для соединения периферийных компонентов. Является мостом между системной шиной процессора и шиной ввода/вывода ISA и EISA. Эта шина была разработана в расчете на Pentium системы, однако хорошо совместима и не с процессорами Intel. PCI является стандартизированной, высокопроизводительной шиной расширения ввода/вывода.
Шина PCI является независимой от других шин и позволяет осуществлять связь между любыми узлами.
Наиболее интересной особенностью шины PCI является принцип Bus Mastering, когда внешнее устройство без помощи центрального процессора может управлять шиной, становясь главным устройством при передаче данных. То есть в компьютере может одновременно (без временного разделения) выполняться, например, две задачи — процессор занимается одной задачей, а контроллер винчестера загружает данные в память через шину PCI.
Шины VLB (VESA Local Bus)
Появление локальной шины было первым шагом к формированию архитектуры ПК с несколькими шинами, имеющими разную пропускную способность. Локальная шина не заменяла собой ISA или EISA, а дополняла их за счет нескольких (не более трех) разъемов локальной шины. Первоначально эти шины использовались для обмена процессора с видеоадаптером, для которого уже не хватало скорости работы ISA.
Шина VL-bus позволяет таким периферийным устройствам, как видеоадаптеры и контроллеры накопителей, работать с тактовой частотой до 66 МГц. Она представляет собой двунаправленную 32-разрядную шину данных с теоретической пропускной способностью 160 Мбайт/с (при частоте шины 50 МГц) и 107 Мбайт/с при частоте 33 МГц.
В качестве устройств, подключаемых к VL-bus, выступают контроллеры накопителей, видеоадаптеры и сетевые платы. Конструктивно VL-bus представляет собой короткий разъем типа MCA (112 контактов), установленный позади разъемов расширения ISA или EISA. При этом 32 линии используются для передачи данных и 30 - для передачи адреса.
Принципы Фон - Неймана
1. Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
2. Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом.
3. Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т.е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
4. Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
5. Возможность условного перехода в процессе выполнения программы. Не смотря на то, что команды выполняются последовательно, в программах можно реализовать возможность перехода к любому участку кода.
Самым главным следствием этих принципов можно назвать то, что теперь программа уже не была постоянной частью машины (как например, у калькулятора). Программу стало возможно легко изменить. А вот аппаратура, конечно же, остается неизменной, и очень простой.
СОПРОЦЕССОР. В тех случаях, когда на компьютере приходится выполнять много математических вычислений (например, в инженерных расчетах), к основному микропроцессору добавляют математический сопроцессор. Он помогает основному микропроцессору выполнять математические операции над вещественными числами. Новейшие микропроцессоры фирмы Intel (80486 и Pentium) сами умеют выполнять операции над вещественными числами, так что для них сопроцессоры не требуются.
Динамическое предсказание
Динамические методы, широко используемые в современных процессорах, подразумевают анализ истории ветвлений. Примером динамического предсказания может служить двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction ), использовавшийся процессорами архитектуры P6 (анализируется таблица истории переходов, содержащая младшие значимые биты адреса инструкции и соответствующую им вероятность условного перехода: «скорее всего, будет выполнен», «возможно, будет выполнен», «возможно, не будет выполнен», «скорее всего, не будет выполнен» и обновляемая после каждого перехода).
Модуль предсказания условных переходов (англ. Branch Prediction Unit ) — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход, или нет) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как будет определено его направление. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора. [1]
Существует два основных метода предсказания переходов: статический и динамический.
Читайте также: