
Подсистема памяти процессора это
Развитие обрабатывающей подсистемы заключается в разделения функций и повышения специализации составляющих ее устройств. Создаются специальные средства, которые осуществляют функции управления системой, освобождая от этих функций средства обработки. Такое распределение функций сокращает эффективное время обработки информации и повышает производительность ЭВМ.
Устройство управления памятью реализует эффективные методы передачи данных между средствами обработки и подсистемой памяти. Меняются функции центрального устройства управления. С одной стороны, ряд функций передается в другие подсистемы (например, функции ввода-вывода), с другой - развиваются средства организации параллельной обработки нескольких команд (суперскалярная обработка) с одновременным повышением темпа исполнения последовательности команд. Для повышения темпа выполнения последовательности команд применяются методы конвейерной обработки наряду с совершенствованием алгоритмов диспетчеризации и исполнения команд. Бурно развивается управление межпроцессорным обменом как эффективное средство передачи информации между несколькими центральными процессорами, входящими в состав вычислительной системы.Операционные устройства (АЛУ) обрабатывающей подсистемы, кроме традиционных средств скалярной и логической обработки, все шире стали включать специальныесредства векторной обработки. При этом время выполнения операций можно резко сократить как за счет использования арифметического конвейера (одного или нескольких), так и за счет сокращения такта работы конвейера. Возможности задач к распараллеливанию алгоритма счета снимают принципиальные ограничения к организации параллельной обработки информации и использованию структур с глубокой конвейеризацией. В устройствах скалярной обработки все шире появляются специальные операционные блоки, оптимизированные на эффективное выполнение отдельных операций.
Процессор ЭВМ: его определение, основные задачи
Центральным блоком, занимающимся обработкой информации в компьютере, является процессор.
Процессор - это главная микросхема компьютера, его "мозг". Он разрешает выполнять программный код, находящийся в памяти и руководит работой всех устройств компьютера. Работа процессора состоит в выборе из памяти в определенной последовательности команд и данных и их выполнении. На этом и базируется выполнение программ.
В области вычислительной техники различают процессоры:
Центральный процессор (ЦП) – также осуществляет обработку данных и выполняющее функции управления системой (инициирование ввода/вывода, управление доступом к основной памяти, обработку сигналов, поступающих от различных внешних устройств и от внутренних устройств ЭВМ).
Он выполняет операции над данными – операндами. Возможности использования ЭВМ определяются набором операций, которые может выполнять процессор. Этот набор операций называется системой команд. Ее объем является одной из главных характеристик ЭВМ. Для микроЭВМ система команд может содержать около сотни и более различных команд.
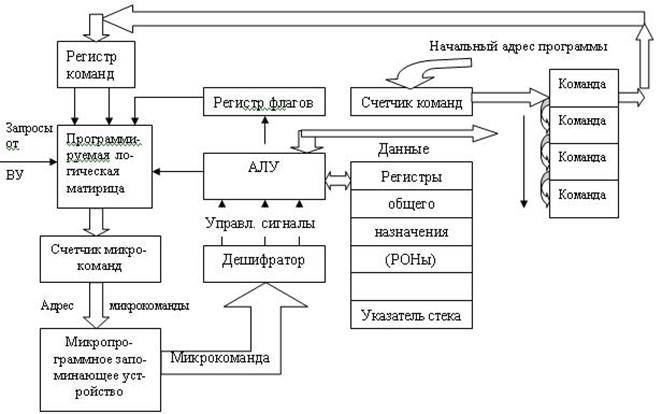
Помимо чисто арифметических и логических операций, процессор должен анализировать еще некоторые признаки (знак результата, переполнение разрядной сетки ЭВМ, нулевой результат ) и принимать соответствующие решения о дальнейших действиях. Возможный вариант структуры процессора представлен на рисунке:
Процессор - самостоятельное или входящее в состав ЭВМ
устройство, осуществляющее обработку информации и управляющее этим
процессом, выполненное в виде одной или нескольких БИС (большая интегральная схема)
Характеристики процессора
Говоря о внутренней архитектуре процессора, не следует забывать и о его характеристиках, главная из которых – производительность, то есть число итераций, выполняемых за одну секунду. Производительность, в свою очередь, характеризуется радом параметров:
¨ внутренней и внешней разрядностью обработки данных;
¨ памятью, к которой может адресоваться процессор;
¨ объемом и устройством кэш-памяти.
Степень интеграции процессора – число транзисторов, которые могут уместиться на микросхеме.
| Например, | для | - | 0,029 | млн. |
| для | i486DX | - | 1,2 | млн. |
| для | Pentium MMX | - | 4,5 | млн. |
| для | Pentium III MMX2 | - | 9,5 | млн. |
Внутренняя разрядность данных – количество бит, которое процессор может обрабатывать одновременно. Особенно важна эта характеристика для арифметических команд, выполняемых внутри ЦП.
Внешняя разрядность данных – разрядность системной шины. Тактовая частота современных процессоров превышает 300 МГц, тактовая частота системной шины составляет лишь 66 МГц. В самых последних моделях материнских плат – порядка 100 и 133 МГц, поэтому разрядность системной шины важна для эффективной работы ЦП.
Тактовая частота – количество циклов (или машинных тактов) в секунду, вырабатываемых генератором тактовых сигналов. Современные персональные компьютеры имеют несколько тактовых генераторов, работающих синхронно на различных частотах. Говоря о тактовой частоте системы, имеют в виду тактовую частоту системной шины.
Характеристики различных процессоров
| Тип процессора | Тактовая частота, МГц | Внешняя разрядность данных, бит | Внутренняя разрядность данных, бит |
| 5, 8, 10 | |||
| 80486 DX | 25, 33, 50 | ||
| 80486 DX4 | 75, 100 | ||
| Pentium MMX | 166, 200, 233, 266 | ||
| Pentium II/III | 400 - 500, 533 и более |
Ширина ША,или количество ячеек памяти, к которым может адресоваться процессор.
Ширина ШД,или количество бит данных, которые могут быть одновременно переданы по ШД.
Принципы организации памяти. Связь между устройствами на материнской плате. Современные DDR, DDR2, DDR3. Отображение бита информации через величину заряда на плавающем затворе в ячейках MLC и SLC. Организация записи информации на полевом транзисторе.
| Рубрика | Коммуникации, связь, цифровые приборы и радиоэлектроника |
| Вид | доклад |
| Язык | русский |
| Дата добавления | 12.03.2015 |
| Размер файла | 900,0 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное образовательное учреждение
высшего профессионального образования
ТОМСКИЙ ПОЛИТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра: Электроника и автоматика физических установок
«Подсистема памяти микропроцессорной системы: процессор - материнская плата - память, flash-память»
Введение
Запоминающие устройства используют ля хранения информации в микропроцессорных системах. Данные устройства сделаны на основе полупроводников. Также существуют магнитные и оптические носители для хранения информации. Совокупность интегральных микросхем памяти образуют внутреннюю компьютерную память и не только. Из данных интегральных микросхем состоят различные виды памяти как внешние, так и внутренние. [1]
Компьютерная память представляет собой определенную часть ЭВМ и представляет собой физическое устройство, среду или место для хранения данных, которые могут использоваться для различных вычислительных операций, в течение долгого промежутка времени.
Основными характеристиками запоминающих устройств (ЗУ) являются:
информационная емкость - максимальный объем хранимой информации;
быстродействие - время обращения к ЗУ с различным видом доступа;
энергопотребление - электрическая мощность, которую потребляет ЗУ.
Также память микропроцессорных систем разделяют на внутреннюю и внешнюю:
внутренняя память - электронная память, которая установлена на системной плате;
внешняя память - память, которая реализована в виде устройств.
Непосредственно доступной памятью для процессора является внутренняя (оперативная) память, которая используется для обмена информацией между процессором внешней памятью и периферийными подсистемами. Произвольность доступа подразумевает возможность операций записи/чтения любой ячейкой ОЗУ в произвольном порядке.
Основными параметрами оперативной памяти являются: [2]
время доступа - задержка появления действительных данных на выходе памяти относительно начала цикла чтения;
длительность цикла - минимальный период следующих друг за другом обращений к памяти;
производительность памяти - скорость потока записываемых или считываемых данных;
разрядность шины памяти - это количество бит или байт, с которыми операция чтения или записи может быть выполнена одновременно;
банк памяти - комплекс модулей, обеспечивающих требуемую для данной системы разрядность хранимых данных.
1. Основные принципы организации памяти
Если судить с точки зрения системы команд, то память - это набор слов, каждое из которых представляет собой уникальный адрес, который показывает расположение слов в памяти. Каждый адрес данной ячейки определяет модуль памяти, а также расположение самой ячейки в модуле. [2]
Каждое слово памяти содержит один или более адресуемых байт, который процессор может обработать за одно обращение. Таким образом в зависимости от разрядности процессора возможность обрабатывать большую информацию возрастает с увеличением разрядов. Например, 16-разрядные микропроцессоры за одно обращение могут обратиться к одному или двум байтам одновременно. Также количество адресуемых ячеек памяти зависит от количества бит шины адреса процессора.
Вычислительные системы чаще всего используют целую иерар-хическую структуру систем памяти как это показано на рисунке 1.
В различных вычислительных системах память можно разделить на внутреннюю и внешнюю. Внутренняя память используется для тесной связи с микропроцессором. Прямо или произвольно адресуемая память представляет собой последовательность нумерованных ячеек, доступ к которым осуществляется с помощью адресных сигналов, определяющих номер ячейки, и специальных стробирующих сигналов, определяющих момент чтения или записи. Внешняя память используется для хранения больших объемов информации.
2. Связь между устройствами на материнской плате
Чипсет материнской платы состоит из двух мостов, северного и южного (рисунок 2), которые, в свою очередь, осуществляют взаимодействия с различными разделами, расположенными на материнской плате. [1]
Рис. 2 - Принципиальная упрощенная схема материнской платы компьютера
Таким образом, северного моста предназначен для осуществления взаимодействия между процессором, оперативной памятью, видеокартой, а южным мостом - с остальными устройствами. Ещё северный мост могут называть системным контроллером. В состав данного моста входят такие важные компоненты:
контроллер оперативной памяти;
контроллеры шин для управления потоками информации между процессором и остальными устройствами;
встроенный графический контроллер.
Процессор, оперативная память, видеокарта являются в компьютере самыми быстрыми устройствами, поэтому они подключены к северному мосту для быстрого обмена данными. Южный мост, который зачастую называют мостом ввода-вывода, объединяет более медленные устройства, например:
различные устройства PCI-шин;
часы реального времени;
различные периферийные устройства.
Также, северный и южный мосты соединяются индивидуальной шиной обмена, по которой передаются данные, сигналы управления и контроля в обоих направлениях.
Материнскую плату можно представить как некий город, в котором есть своя инфраструктура. Северный и южный мосты в данном городе представляются некоторые железнодорожные станции, объединённые между собой широкой высокоскоростной магистралью -- шиной, по которой в обоих направлениях движутся составы -- информационные потоки. На самих станциях-мостах происходит дальнейшее распределение и доставка информации конечному электронному компоненту. Таким же образом происходит связь процессора с различными видами памяти: с постоянной и оперативной. [3]
Для примера, необходимо процессору передать данные в большом количестве и с высокой скоростью в оперативную память. Данной проблемой займётся контроллер прямого доступа в память. Он организует возможность занять беспрепятственно шину и передавать данные непосредственно в память, минуя процессор. Оперативная память также в это время будет занята только приёмом данных от винчестера. Этим повысится быстродействие системы.
На данный момент чипсет системной платы -- это объединение двух, а иногда и одна, СБИС (Сверхбольшая интегральная схема).
3. Современные типы памяти DDR, DDR2, DDR3
DDR SDRAM представляет собой синхронную динамическую память с произвольным доступом и удвоенной скоростью передачи данных. Модули DDR SDRAM выполнены в форм-факторе DIMM, у которого контакты, расположенные на разных сторонах модуля, являются независимыми и передают разные сигналы. На каждом отдельном модуле несколько одинаковых чипов и конфигурационный чип SPD. На модулях регистровой памяти располагаются регистровые чипы, буферизующие и усиливающие сигнал на шине.
Далее рассмотрим 3 вида современной оперативной памяти:
DDR - является одной из первых видов данной оперативной памяти, для которой рабочее напряжение составляет 2.5 В. DDR является наибольшим потребителем электроэнергии из всех рассматриваемых видов памяти.
DDR2 - данный вид памяти работает быстрее, чем DDR. Данная память имеет рабочее напряжение 1.8 В.
DDR3 - быстрый и новый тип памяти. DDR3 обладает скоростью большей, чем у DDR2 и потребляет электроэнергию меньше других видов оперативной памяти - 1.5 В. Основные характеристики данных видов оперативной памяти представлены в таблице 1.
Таблица 1 - Технические характеристики оперативной памяти
Самокалибровка с ZQ
Одной из самых важных характеристик оперативной памяти является ее пропускная способность, то есть произведение частоты системной шины на объем данных, передаваемых за один такт. От данной пропускной способности зависит производительность памяти. Таким образом, можно рассчитать пропускную способность оперативной памяти, частота которой составляет 400 МГц, а объем данных 8 байт. Путем нехитрых вычислений получим, что 400 МГц х 8 Байт = 3200 Мбайт в секунду (или 3.2 Гбайт/с).
Также на производительность оперативной памяти также влияют и такие параметры как «тайминги памяти». Так как логическая структура банка памяти представляет собой двухмерный массив, то есть каждая ячейка памяти имеет свой адрес - номер строки и номер столбца. Для считывания контроллер памяти задает номер строки и столбца для обращения к ячейке по данному адресу. Между подачей команды и ее выполнением всегда будет присутствовать какая-нибудь задержка, которая и будет характеризовать «тайминги». Наиболее известными параметрами оперативной памяти, которые определяют «тайминги», являются следующие:
CAS - задержка между подачей сигнала и вызовом данных из соответствующей ячейки;
RAS to CAS - количество тактов шины памяти, которые должны пройти после подачи сигнала RAS до того, как можно будет подать сигнал CAS;
ROW Precharge - время закрытия страницы памяти в пределах одного банка, которое тратится на перезарядку самого этого банка;
Activate to Precharge - минимальное количество циклов между командой активации RAS и командой подзарядки Precharge, после которой заканчивается работа с данной строкой, или закрытия одного и того же банка.
4. Flash-память
Флэш-память (flash memory) - относится к полупроводникам электрически перепрограммируемой памяти (EEPROM). Благодаря техническим решениям, не высокой стоимости, большому объему, низкому энергопотреблению, высокой скорости работы, компактности и механической прочности, флэш-память встраивают в цифровые портативные устройства и носители информации. Основное достоинство этого устройства в том, что оно энергонезависимое и ему не нужно электричество для хранения данных. Всю хранящуюся информацию во флэш-памяти можно считать бесконечное количество раз, а вот количество полных циклов записи к сожалению ограничено. [5]
Принцип работы флеш-памяти основан на изменении и регистрации электрического заряда в изолированной области полупроводниковой структуры. Элементарной ячейка хранения данных флэш-памяти представляет из себя транзистор с плавающим затвором. Особенность такого транзистора в том, что он умеет удерживать электроны (заряд). Таким образом на его основе и разработаны основные типы флэш-памяти NAND и NOR. Во флэш-памяти производители используют два типа ячеек памяти MLC и SLC (рисунок 3).
Рис. 3 - Отображение бита информации через величину заряда на плавающем затворе в ячейках MLC и SLC
Флэш-память с MLC ячейки более емкие и дешевые, но они с большим временем доступа и меньшим количеством циклов записи/стирания (около 10000).
Флэш-память, которая содержит в себе SLC ячейки имеет максимальное количество циклов записи/стирания (100000) и обладают меньшим временем доступа.
Благодаря подачи между затвором и истоком большого потенциала происходит изменение заряда (запись/стирание) (рисунок 4). Таким образом, напряженность электрического поля в тонком диэлектрике между каналом транзистора и карманом становится достаточной для возникновения туннельного эффекта. Для усиления эффекта туннеллирования электронов в карман при записи применяется небольшое ускорение электронов путем пропускания тока через канал полевого транзистора.[4]
Рис. 4 - Организация записи/стирания информации на полевом транзисторе с плавающим затвором
память материнский плата транзистор
Чтение выполняется полевым транзистором, для которого карман выполняет роль затвора. Потенциал плавающего затвора изменяет пороговые характеристики транзистора, что и регистрируется цепями чтения. Эта конструкция снабжается элементами, которые позволяют ей работать в большом массиве таких же ячеек.
На данный момент существует различные виды запоминающих устройств, которые применяются в огромном количестве электронных устройств. Объемы памяти уже давно зашли за сотни гигабайт, а в некоторых - даже терабайт. С каждым годом объем памяти на запоминающих устройствах увеличивается в огромных масштабах, однако сами устройства при этом уменьшаются. Также обеспечиваются огромные скорости передачи данных, что способствует сокращению необходимого времени.
Как мы знаем данные устройства основываются на кремневых транзисторах, и с каждым годом величины данных транзистором уменьшаются до микроскопических размеров, что способствует расположению большого их числа на кристалле. Однако, если смотреть в будущее, основой компьютеров будущего станут не кремниевые транзисторы, где передача информации осуществляется электронами, а оптические системы. Носителем информации станут фотоны, так как они легче и быстрее электронов. В результате компьютер станет более дешевым и значительно компактным. Но самое главное, что оптоэлектронное счисление гораздо быстрее, чем то, что применяется сегодня, поэтому компьютер будет намного производительнее. Компьютер будущего будет практически независим от источников электропитания. Одно из самых больших преимуществ фотонных цепей -- крайне малое энергопотребление.
Список литературы
2. Непомнящий О.В., Вейсов Е.А., Скотников Г.А., Савицкая М.В. Микропроцессорные системы. - Красноярск: ИПК СФУ, 2009.
3. Костров Б. В., Ручкин В. Н.. Архитектура микропроцессорных систем. / Пер. с англ. - М.: Диалог-МИФИ, 2007. - 304 с.
5. Шишков А. Н.. Микропроцессоры // МАИ, каф. 404. - 2007 - с. 25 - 34.
13.2. Отображение в памяти
13.2. Отображение в памяти Операционная система Linux позволяет процессу отображать файлы в их адресное пространство. Такое отображение создает взаимно однозначное соответствие между данными в файле и в отображаемой области памяти. Отображение в памяти обладает рядом
Глава 5 Подсистема ввода/вывода
Глава 5 Подсистема ввода/вывода Фактическая архитектура ввода/вывода скрыта от прикладного процесса несколькими интерфейсами. Один из них — интерфейс файловой системы был рассмотрен в предыдущей главе. Взаимодействие с удаленными ресурсами обеспечивается сетевыми
Файловая подсистема
Файловая подсистема Файловая подсистема обеспечивает унифицированный интерфейс доступа к данным, расположенным на дисковых накопителях, и к периферийным устройствам. Одни и те же функции open(2), read(2), write(2) могут использоваться как при чтении или записи данных на диск, так
Подсистема управления процессами
Подсистема управления процессами Запущенная на выполнение программа порождает в системе один или более процессов (или задач). Подсистема управления процессами контролирует:? Создание и удаление процессов? Распределение системных ресурсов (памяти, вычислительных
Глава 4 Файловая подсистема
Глава 4 Файловая подсистема Большинство данных в операционной системе UNIX хранится в файлах, организованных в виде дерева и расположенных на некотором носителе данных. Обычно это локальный (т. е. расположенный на том же компьютере, что и сама операционная система) жесткий
Подсистема ввода/вывода
Подсистема ввода/вывода Подсистема ввода/вывода выполняет запросы файловой подсистемы и подсистемы управления процессами для доступа к периферийным устройствам (дискам, магнитным лентам, терминалам и т.д.). Она обеспечивает необходимую буферизацию данных и
Подобные документы
Разработка модулей памяти микропроцессорной системы, в частности оперативного и постоянного запоминающих устройств. Расчет необходимого объема памяти и количества микросхем для реализации данного объема. Исследование структуры каждого из блоков памяти.
контрольная работа [1,3 M], добавлен 07.07.2013
Критерии эффективности и обоснование выбора базисных элементов для записи отсчетов от 16 аналоговых датчиков в область памяти. Функциональная схема компьютерной системы управления железнодорожным переездом. Алгоритм работы микропроцессорной системы.
курсовая работа [1,4 M], добавлен 14.06.2016
Разработка интерфейса и уточнённой структурной схемы, процессорного модуля, подсистем памяти и ввода/вывода, алгоритма программного обеспечения. Оценка памяти программ и данных. Структура адресного пространства. Организация клавиатуры и индикации.
курсовая работа [2,4 M], добавлен 09.08.2015
Рассмотрение аппаратных принципов построения устройств микропроцессорной техники и их программного обеспечения. Структурная схема микропроцессора К1821ВМ85А. Карта распределения адресного пространства памяти. Расчет потребляемой устройством мощности.
курсовая работа [2,4 M], добавлен 26.11.2012
Изучение устройства связи с датчиком и исполнительными механизмами, разработка блока памяти объёмом 80 кб. Характеристика программ, обеспечивающих выполнение заданного алгоритма и алгоритма обмена. Оценка микропроцессорной системы по аппаратным затратам.
практическая работа [154,1 K], добавлен 14.11.2011
курсовая работа [422,5 K], добавлен 10.03.2015
Схема записи и считывания из оперативной памяти. Основные элементы двунаправленного регистра. Схемотехническое моделирование MC-9 GUAP Edition. Применение макроопределений (макросов) в процессе моделирования. Обеспечение помехоустойчивости плат.
Подсистема памяти современных компьютеров имеет иерархическую структуру, состоящую из нескольких уровней:
¨ сверхоперативный уровень (локальная память процессора, кэш-память первого и второго уровня);
¨ оперативный уровень (оперативная память, дисковый кэш);
¨ внешний уровень (внешние ЗУ на дисках, лентах и т.д.).
Каждый уровень состоит из запоминающих устройств, обладающих различным быстродействием и емкостью. Чем выше уровень, тем выше быстродействие соответствующей памяти, но меньше её емкость.
Эффективными методами повышения производительности ЭВМ являются увеличение количества регистров общего назначения процессора, использование многоуровневой кэш-памяти, увеличение объема и пропускной способности оперативной памяти, буферизация передачи информации между ОП и внешней памятью. Увеличение пропускной способности оперативной памяти достигается за счет увеличения их расслоения и секционирования.
Память – один из блоков ЭВМ, состоящий из ЗУ и предназначенный для запоминания, хранения и выдачи информации (алгоритма обработки данных и самих данных).
Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита).
Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Требования к увеличению емкости и быстродействия памяти, а также к снижению ее стоимости являются противоречивыми.Чем больше быстродействие, тем технически труднее достигается и дороже обходится увеличение емкости памяти. Стоимость памяти составляет значительную часть общей стоимости ЭВМ.
Как и большинство устройств ЭВМ, память имеет иерархическую структуру. Обобщённая модель такой структуры, отражающая многообразие ЗУ и их взаимодействие, представлена на рисунке 8.1. Все запоминающие устройства обладают различным быстродействием и емкостью. Чем выше уровень иерархии, тем выше быстродействие соответствующей памяти, но меньше её емкость.

Рис. 8.1. Иерархическая структура памяти
К самому высокому уровню - сверхоперативному - относятся регистры управляющих и операционных блоков процессора, сверхоперативная память, управляющая память, буферная память (кэш-память).
На втором оперативном уровне, более низком, находится оперативная память (ОП), служащая для хранения активных программ и данных, то есть тех программ и данных, с которыми работает ЭВМ.
На следующем более низком внешнем уровне размещается внешняя память.
Сверхоперативная память. Иногда в архитектуре ЭВМ регистровая память организуется в виде сверхоперативного ЗУ с прямой адресацией. Такая память имеет то же назначение как и РОН, служит для хранения операндов, данных и служебной информации, необходимой процессору.
Управляющая память предназначена для хранения управляющих микропрограмм процессора (см. раздел Устройство управления микропрограммного типа). Выполнена в виде постоянного ЗУ (ПЗУ) или программируемого постоянного ЗУ (ППЗУ). В системах с микропрограммным способом обработки информации УП применяется для хранения однажды записанных микропрограмм, управляющих программ, констант и т.п.
Буферная память.В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти. Кэш – память от английского cashe – тайник. Она не является программно доступной. Поэтому она оказывает влияние на производительность ЭВМ, но не влияет на программирование прикладных задач. В современных ЭВМ различают кэш первого и второго уровней. Кэш первого уровня интегрирована с блоком предварительной выборки команд и данных ЦП и служит, как правило, для хранения наиболее часто используемых команд. Кэш второго уровня служит буфером между ОП и процессором. В некоторых ЭВМ существует кэш память отдельно для команд и отдельно для данных.
ОП (ОЗУ)служит для хранения информации, непосредственно участвующей в вычислительном процессе (происходящем в операционном устройстве - АЛУ). Из ОЗУ в процессор поступают коды и операнды, над которыми производятся предусмотренные программой операции, из процессора в ОЗУ направляются для хранения промежуточные и конечные результаты обработки информации. ОЗУ имеет сравнительно большую ёмкость и высокое быстродействие, однако меньшее, чем ЗУ сверхоперативного уровня.
Внешняя память (ВнП) используется для хранения больших массивов информации в течении продолжительного времени. Обычно ВнП не имеет непосредственной связи с процессором. Обмен информацией носит групповой характер, что значительно сокращает время обмена. ВнП обладает сравнительно низким быстродействием (поиск информации). В качестве носителя используются магнитные диски (гибкие и жёсткие), лазерные диски(CD-room) и др.
Сравнительно небольшая емкость оперативной памяти (8 - 64 Мбайта) компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства сравнительно медленные - время обращения за данными для магнитных дисков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет 50 нс. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти.
Рост производительности ЭВМ проявляется в первую очередь в увеличении скорости работы процессора. Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора потому, что одновременно происходит опережающий рост ее емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Проявляется это в несоответствии пропускных способностей процессора и памяти. Для выравнивания их пропускных способностей и предназначена сверхоперативная буферная память небольшой емкости (как правило, не более 512 Кбайт) и повышенного быстродействия.
При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память. Последующие обращения к этому блоку данных производится к буферной памяти. Поскольку время выборки из СОЗУ tСОЗУ много меньше времени выборки из оперативной памяти tОП, введение в структуру ЭВМ СОЗУ приводит к уменьшению эквивалентного времени обращения tэ по сравнению с временем обращения к оперативной памяти tОП:
а q – вероятность попадания, т. е. вероятность того, что блок данных, к которому производится обращение, находится в СОЗУ.

После ознакомления с теоретической частью самое время перейти, так сказать, к "практической теории". В данной статье мы поговорим о том необходимом багаже знаний, которым надо владеть для успешной и грамотной настройки подсистемы памяти. Поскольку понятие "подсистема памяти" имеет достаточно широкий диапазон значений и трактовок, придется сделать соответствующие уточнения — мы рассмотрим работу "стандартной" системной памяти на примере наиболее популярных современных платформ, а отдельный материал будет целиком посвящен тестированию модулей.
Обращение от редакции: Нашим защитникам из 3-го отдельного батальона УДА, которые находятся в Запорожской области, нужны вещи, чтобы противостоять врагу: квадрокоптеры и смартфоны для управления ими, прицелы ночного видения. Реквизиты для перевода средств на карту monobank – Колонович Катерина, номер карты 5375411505235312. Просим приобщиться к сбору средств. Слава Украине!
Память до сих пор остается одним из самых "таинственных инструментов" современного компьютера, и для пользователя сложность управления и организации работы этой неотъемлемой составляющей любого компьютера растет в геометрической прогрессии. Во времена 386-х и 486-х основные трудности и премудрости заключались лишь в правильном выборе модулей FPM. Затем были выпущены более совершенные модули EDO, а BIOS Setup стали "обзаводиться" настройками, позволяющими хоть как-то управлять режимами работы памяти. С появлением модулей SDRAM организация подсистемы памяти лишь с небольшими изменениями (и постоянными усложнениями) дошла до наших дней. Поэтому опорным пунктом предлагаемой нами "практической теории" будет память PC100, продержавшаяся достаточно долго, да и сейчас нередко встречающаяся. Но сначала поговорим немного об общепринятых методах определения производительности подсистемы памяти.
Собственно говоря, сама методика включает всего три способа, которые для простоты понимания условно назовем так: прямые (низкоуровневые), синтетические и относительные. Первые включают в себя вычисление скорости записи в память, чтения из памяти, иногда еще копирования данных специализированными программами. Наиболее известные и часто применяемые — CacheMem, Cache Burst 32, причем производительность именно памяти определяется при размере блока данных, обязательно превосходящем объем процессорных кэшей всех уровней. Обе эти программы являются достаточно гибкими инструментами, кроме скорости и латентности памяти, с их помощью можно найти значения этих же параметров для кэшей CPU. Немаловажен и тот факт, что продемонстрированные ими результаты не противоречат друг другу. Однако Cache Burst 32 все же имеет ряд преимуществ в плане функциональности по сравнению с CacheMem, поэтому в большинстве случаев мы оперируем именно его показаниями.
Вторая (синтетическая) группа тестов представляет собой подтесты из популярных пакетов, определяющие производительность подсистемы памяти. Наиболее распространенные — PCMark, AIDA, SiSoft Sandra. Хотя последние два пакета отличаются от PCMark тем, что отображают свои результаты не в "марках", а, подобно "низкоуровневым" тестам, в "мегабайтах в секунду", но нам неизвестны алгоритмы определения производительности. Кроме того, полученная с их помощью информация иногда, мягко говоря, далека от реальности. Однако с точки зрения обычного пользователя ценность информации, выдаваемой этими пакетами, достаточно велика, а встроенную систему "бенчмарков" можно рассматривать как "приятную добавку". Тест PCMark сложно назвать информативным в отношении производительности подсистемы памяти, да и вообще он в этом амплуа уже давно не используется. Скорее, это "мерило крутизны", но ведь именно к этому и стремились разработчики, так что все честно.
Третий, наиболее интересный и профессиональный метод определения производительности подсистемы памяти — сравнительный. Что имеется в виду? Когда для тестирования применяются реальные задачи, нагружающие память, а заключения делаются исходя из сравнительных показателей быстродействия нескольких систем, отличающихся организацией подсистемы памяти. Как правило, это комплекс тестов, включающий в себя игровые пакеты, работу архиваторов, сложную обработку растровых изображений, иногда медиакодирование. Данный список можно расширять, но на практике даже этот набор уже считается достаточно серьезным.
К примеру, есть необходимость определить, насколько один чипсет "быстрее" другого (относящегося к той же платформе). По показаниям "прямых" тестов можно сделать некоторые предположения, посредством сопоставления производительности в реальных задачах с низкоуровневыми набросками находятся отличия в быстродействии, и главное — их причина! Затем с помощью имеющихся данных можно выполнять синтетические тесты — тестировать не ими, а именно их, для определения достоверности результатов. Хотя это похоже на шутку, но для многих подобная деятельность (т. е. разоблачение "продажных" изготовителей тестов производительности) действительно становится неким хобби.
Также одним из наиболее важных параметров является латентность — время реакции памяти, иными словами, наблюдаемая инерционность при изменении режимов ее работы. Или упрощенно: латентность — это, по сути, значение задержки между посылкой команды на чтение (запись) некой ячейки (блока ячеек) памяти и выполнением этой команды. Вообще, по поводу терминов и определений латентности существует достаточно много теорий. Попробуем высказать нашу точку зрения в отношении данного параметра. Латентность — это мера неэффективности (поскольку большее значение является худшим показателем) использования подсистемы памяти. Более детально и наглядно со всеми этими параметрами и значениями нам поможет разобраться табл. 1.
Наверное, даже искушенный в этой области читатель не сразу поймет, что стоит за обилием приведенных цифр и столбцов. С первыми двумя колонками все должно быть понятно — это частота работы шины памяти и соответствующая теоретическая пропускная способность контроллера памяти. Следующие три колонки — реальные значения, полученные для применяемых платформ с помощью пакета Cache Burst 32 при использовании MMX-команд (скорость при 64-битной передаче данных условно можно считать усредненным показателем производительности памяти). Затем две колонки, отображающие латентность в тактах процессора и ее же в перерасчете на время. А дальше начинается самое интересное — собственно наши расчеты, позволяющие распознать закономерности в поведении тех или иных современных платформ, и главное — сравнить эффективность различных контроллеров памяти и посмотреть, насколько эти устройства "ушли вперед" от своих предков в лице 440BX и i815. Средневзвешенный показатель быстродействия подсистемы памяти высчитывался с весовыми коэффициентами, определенными эмпирическим путем: 0,6 для скорости чтения и 0,4 для записи. Разобраться, как вычислялись соответствующие коэффициенты, поможет табл. 2, а мы переходим к рассмотрению результатов (см. табл. 1). Собственно платформы выбраны неслучайно, на основании приведенных данных можно спрогнозировать поведение практически любого современного чипсета от Intel, VIA, SiS, зная разницу в спецификациях.
Наиболее интересными и показательными являются два последних столбца. Безусловно, полученные значения — это некоторые условные коэффициенты, однако с их помощью очень удобно объяснить поведение той или иной платформы в плане работы с памятью. Показатель "полезной" производительности подсистемы памяти является неким нашим "марком", характеризующим общее быстродействие системы с учетом основных параметров памяти: скорости записи/чтения и латентности. Ударение следует сделать именно на слово "полезной", если взять два любых значения из этого столбца и найти их частное, можно узнать, насколько будет отличаться "повседневная" производительность подсистем памяти.
Но вернемся к участникам нашего тестирования и рассмотрим предпоследний столбец. Как можно заметить, двухканальный контроллер в чипсете i875P условно оказался в 10 раз быстрее своего знаменитого предка 440ВХ, а как мы уже упоминали, теоретическая производительность даже в самом идеальном случае должна была увеличиться всего в 8 раз. Следовательно, можно говорить о реально возросшей эффективности подсистемы памяти в целом. Значит, нам нужен еще один показатель (коэффициент), с помощью которого мы сумеем вычислить сравнительную эффективность той или иной подсистемы памяти. Цифры, приведенные в последнем столбце таблицы, как раз и показывают тот самый Сравнительный коэффициент эффективности контроллера памяти с учетом КПД шины (для удобства показатели чипсета 440ВХ в своем максимальном режиме 100 MHz приняты за единицу).
Если читатель разобрался с нашими математическими выкладками, то рассмотреть и понять имеющиеся в таблице закономерности особого труда не составит. Но основные моменты мы все же прокомментируем.
Для проверки того, насколько полученные данные являются масштабируемыми (т. е. в каких случаях подобные закономерности сохранятся), было проведено несколько экспериментов. Вместо основного Pentium 4 3,2 GHz мы решили посмотреть, какую скорость покажет идентичная система с чипсетом i875P, но с процессором Pentium 4 2,4 GHz (шина 800 MHz). Как выяснилось, они оказались практически одинаковыми. То же самое можно сказать и о Athlon XP, в котором мы понизили множитель с 11 до 8, сравнительные показатели быстродействия подсистемы памяти остались теми же. Отсюда вывод: производительность подсистем памяти на платформах с однотипными процессорами, имеющими одинаковые частоты FSB, будет почти равной. Заметьте, мы сейчас говорим исключительно о памяти, а не о системе в целом.
Итак, основных таймингов собственно пять, и это вторая по значимости (после частоты) характеристика модулей памяти, прошитая в SPD. Прежде чем их перечислить, нужно разобраться с некоторыми понятиями:
Собственно, на этом основная часть заканчивается. Однако на многих материнских платах BIOS Setup позволяет менять еще несколько "второстепенных" типов таймингов и параметров регенерации, которые также могут помочь с получением несколько бoльшей производительности при довольно продолжительном времени, затрачиваемом на манипулирование ими.
Хотя мы и не приводим отдельных результатов по влиянию того или иного тайминга на быстродействие, скажем следующее: наиболее важные параметры — CAS Latency и RAS to CAS (впрочем, как и наиболее проблематичные). Если есть возможность изменять DRAM Command Rate, то переключение с 2Т на 1Т также значительно поднимет производительность. В некоторых BIOS Setup можно устанавливать тайминги, выходящие за общепринятые нормы, к примеру доступны значения 1,5 для CAS Latency или 4 для RAS Active Time. Кроме того, во многих случаях эти значения даже удастся выставить и запустить систему, но на самом деле никаких 1,5 вы не получите. Вот тут мы подошли к еще одному очень важному вопросу о соответствии настроек BIOS Setup и реальных показателей. Проверить существующие установки можно с помощью информационных пакетов — тех же Sandra и AIDA, но лучшей и самой достоверной утилитой является, пожалуй, свободно распространяемая программа CPU Z, которая, помимо таймингов, показывает и содержимое SPD. Также далеко не все материнские платы корректно устанавливают напряжения и тайминги в режиме "By SPD". К примеру, наши модули Corsair PC3200, стандартно имеющие тайминги 6-2-2-2 и вольтаж 2,6 В, в некоторых случаях определялись как 7-3-3-2,5 с напряжением 2,5 В. Были и "обратные" варианты — например, установка режимов 5-2-2-2 по умолчанию. Так что настоятельно рекомендуем проверять соответствие, это поможет избежать недоразумений в работе.
Как мы смогли убедиться, частоты, двухканальность, тайминги — все это понятия достаточно условные и относительные, сами по себе еще ничего не определяющие. Например, одноканальный контроллер памяти у Athlon 64 оказался на сегодняшний день самым эффективным, в то время как в более серьезном по спецификациям чипсете nForce2 наличие второго канала — лишь дань моде. Если вспомнить неоднократно рассматриваемый нами чипсет ATI 9100IGP, то даже в случае использования с ним самого мощного процессора Intel Pentium 4 3,2 GHz (шина 800 MHz) практически не будет иметь значения ни количество каналов, ни установленные тайминги, ни применение встроенного или внешнего видео — и при всем при этом чипсет действительно хороший.
При изменении таймингов на разных платформах под Pentium 4 и Athlon XP реакция подсистемы памяти весьма различается. В первом случае повышаются пропускная способность и скорость чтения/записи, во втором — значительно уменьшается латентность при сохранении других параметров, но прирост реальной производительности при этом практически одинаков. Системы, чипсеты которых умеют работать с регистровой памятью с возможностью коррекции ошибок, считаются самыми надежными, однако существуют серверные решения, где память вообще организована наподобие RAID-массива уровня 5 и поддерживает горячую замену модулей. Следовательно, для того чтобы уверенно говорить о чем-либо, касающемся подсистемы памяти, нужно учитывать огромное количество факторов.
Исходя из всего этого мы не можем однозначно ответить на один из наиболее часто задаваемых вопросов, к примеру, в каком случае система будет работать быстрее: с процессором Pentium 4 (FSB 533 MHz) — с памятью DDR333 и "плохими" таймингами либо с DDR266, но с "хорошими"? Чтобы дать ответ, нужно рассмотреть как минимум пару десятков типичных случаев (о нюансах мы даже не говорим), да и то полученная информация будет лишь первым приближением к истине, не более того.
При поиске ответа на один вопрос, касающийся работы современных подсистем памяти, возникает еще два, для тех двух — еще по два и т. д. Если мы попробуем "копнуть" затронутые в данной статье проблемы еще чуточку глубже, то размер ее тут же возрастет многократно. Мы же пытались больше изложить методику по работе с памятью и дать информацию для собственного "полета мысли" и возможного проведения самостоятельных исследований.

О Подсистема памяти
Одна из самых больших проблем любого процессора — обеспечение его загрузки. За последние несколько лет производительность процессоров необычайно выросла, в среднем удваиваясь каждые два года. Производительность памяти и ввода-вывода не успевает за этими темпами.
В 1991 году я купил новую IBM PC для домашних нужд. В ней был установлен процессор Intel 386 20 МГц, 70-наносекундная память и жесткий диск с временем доступа 16 миллисекунд. Маломощный процессор 386 не долго меня устраивал; поэтому я, как и многие другие, начал бесконечную гонку за новейшей аппаратурой, приобретая последовательно системы с процессорами 486 и Pentium. В последнем купленном мною компьютере (который уже тоже устарел) установлены процессоры Pentium Pro 200 МГц, 60-наносекундная память и жесткие диски со временем доступа 8,5 миллисекунд.
Да, за последние несколько лет разрыв в скорости между процессором и памятью-вводом/выводом вырос невероятно. Теперь вполне возможна ситуация, когда память и ввод-вывод не смогут поставлять достаточно информации для поддержания загрузки процессора, и последний будет проводить множество своих высокоскоростных циклов в ожидании выборки команд или данных.
Универсальный прием для компенсации разницы в производительности между процессором и основной памятью — применение кэшей. Как мы уже говорили, кэш — это быстродействующая память, используемая для хранения блоков команд и данных, к которым процессор недавно обращался. При этом предполагается, что в ближайшем будущем процессор будет обращаться к тем же самым блокам.
Кэши эффективны благодаря тому, что большинство программ обладают так называемыми пространственной и временной локализацией. Это означает, что программа, скорее всего, обратится к команде или элементу данных, расположенным в памяти недалеко от места последнего обращения (пространственная локализация); а также что такой доступ произойдет через короткий отрезок времени (временная локализация). Нетрудно предположить, некоторые программы обладают большей степенью локализации, чем другие. Программа, предполагающая выполнение многих циклов или большой объем повторной обработки одних и тех же данных, имеет очень высокую степень локализации. Приложения для коммерческих расчетов, наоборот, выполняют мало обработки такого сорта, и имеют несколько меньшую степень локализации. Большие кэши и иерархия кэшей могут обеспечить загрузку процессора данными и командами даже при низких уровнях локализации.
При использовании иерархии кэшей происходит следующее: если нужная процессору информация отсутствует в кэше L1, процессор обращается к кэшу L2. Если информация не найдена и там, то происходит обращение к основной памяти. Пока идет поиск информации и выборка ее в регистр, процессор простаивает. Обычно это называют циклами простоя (stall cycles) процессора. В том случае, если информации нет даже в основной памяти и система должна обратиться к диску, процессор не ждет, а переключается на выполнение другой задачи в системе. Такую ситуацию обычно называют страничной ошибкой (page fault). Подробней мы поговорим об этом в главе 8.
Несмотря на использование больших кэшей и иерархии кэшей, большинство процессоров все равно тратят много циклов простоя, ожидая выборки из памяти. Проблема заключается в шине между процессором и основной памятью. Большая часть систем, включая ранние AS/400, имеют одну такую шину, обычно высокоскоростную, но все равно работающую медленнее самого процессора. Например, мой Intel Pentium Pro 200 МГц работает с шиной памяти 66 МГц. Это означает, что при обращении к памяти процессор простаивает по три цикла на каждый цикл шины. Легко понять, что таких циклов простоя может быть много.
В конфигурации SMP ситуация может значительно ухудшиться. Теперь одну шину памяти и одну основную память пытаются задействовать несколько процессоров. Так как в данный момент времени шина может использоваться только одним процессором, то все остальные процессоры, которым она понадобилась в этот момент, обречены ждать. А если та же шина памяти используется еще и для ввода-вывода, положение еще более усугубляется.
Эта борьба за шину памяти приводит к уменьшению производительности при добавлении к системе SMP каждого нового процессора. Например, добавление второго процессора не позволит увеличить общую производительность на 100 процентов; фактическое увеличение будет несколько меньшим из-за борьбы за память. Добавление третьего и четвертого процессора еще сильнее сократит прирост производительности на один процессор. А когда дело дойдет до восьми и более процессоров, рост производительности системы SMP может и вовсе прекратиться.
Подсистема STREAMS
Подсистема STREAMS Архитектура подсистемы потокового ввода/вывода STREAMS впервые была описана в статье Ритчи "Потоковая система ввода/вывода" (Ritchie, D.M., "A Stream Input-Output System", AT&T Bell Laboratories Technical Journal, Vol. 63, No. 8, Oct. 1984) в 1984 году. Двумя годами позднее эта система была реализована в
2.6. Тип памяти FEDERATED
2.6. Тип памяти FEDERATED Тип памяти FEDERATED обращается к данным в таблицах удаленных баз данных, а не в локальных таблицах.Тип памяти FEDERATED включен в двоичные дистрибутивы MySQL-Max. Чтобы его включить, если Вы формируете MySQL из исходного текста, вызовите configure с опцией
Глава 3 Подсистема управления процессами
Глава 3 Подсистема управления процессами Сердцем операционной системы UNIX является подсистема управления процессами. Практически все действия ядра имеют отношение к процессам, будь то обслуживание системного вызова, генерация сигнала, размещение памяти, обработка
3.1. Требования к памяти
ГЛАВА 10. ПОДСИСТЕМА УПРАВЛЕНИЯ ВВОДОМ-ВЫВОДОМ
ГЛАВА 10. ПОДСИСТЕМА УПРАВЛЕНИЯ ВВОДОМ-ВЫВОДОМ Подсистема управления вводом-выводом позволяет процессам поддерживать связь с периферийными устройствами, такими как накопители на магнитных дисках и лентах, терминалы, принтеры и сети, с одной стороны, и с модулями ядра,
Читайте также: