
Почему на рынке нет 128 битных процессоров
Будет ли он работать быстрее или что-то в этом роде? Попробуем поговорить про это простыми словами.
Этот монстр своего времени имел 16-bit:
Этот может иметь 640 kb оперативной памяти (чуть меньше 200 бит)
Но имел 16- bit'ный чип, вот этот:
Чтобы получить доступ к пространству памяти, большему, чем то, что может быть представлено регистрами ЦП (центрального процессора), вы должны просто использовать пейджинг (подкачка - схема управления памятью) , где вы будете использовать одну инструкцию, чтобы сообщить системе, какую страницу памяти вы хотели бы использовать, и другую инструкцию для доступа к данным в этой страницы
Итак, у нас есть пара чисел: размер в битах общего пространства памяти, размер в битах регистров ЦП и размер в битах шины памяти, которая загружает данные в ЦП. Они могут в принципе варьироваться независимо друг от друга.
Немного . 64-битные с трудом дают преимущества по сравнению с 32-битными. 64-битные программы дают программам прямой доступ к пространству памяти, которое примерно в миллиард раз больше, чем у ПК сегодня, но даже для специализированных суперкомпьютеров это ограничение может быть преодолено другими архитектурными изменениями, помимо простого увеличения количества бит.
В типичной компьютерной программе большинство чисел редко превышает несколько миллионов, что намного меньше 64-разрядных, что составляет миллиарды миллиардов (18 446 744 073 709 551 616). Компьютерные программы также обычно используют так называемые числа с плавающей запятой, которые представляют дробные числа. Здесь число битов повышает точность, а 32-разрядные - для младшего разряда для научных расчетов, а 64-разрядные числа обычно используются. Однако точность битов с плавающей запятой имеет мало общего с битами операционной системы или объемом памяти. На самом деле с плавающей запятой, как правило, обрабатываются специальным оборудованием, которое внутренне использует еще больше битов.
Эта вещь с 1980 года использовала до 80 бит внутри:

На текущий момент у производителей компьютерного и мобильного «железа» котируются лишь две архитектуры. Чем ARM отличается от x86 и почему один стандарт до сих пор не сумел вытеснить конкурента?
Кратко рассмотрим данный вопрос. Стандартизация x86-архитектуры появилась более 30 лет назад, больше подходит для громоздких систем, но встречается и на лэптопах.
С другой стороны, для смартфонов и планшетов оптимальным выбором остаются ARM-процессоры, поскольку они меньше выделяют и потребляют энергию, характеризуются уменьшенным техпроцессом и в ряде ситуаций проще в производстве.
Чем x86 отличается от ARM – основные параметры:
- ИнструкцииCPU. Поскольку x86-чипы развивались очень долго, в них есть не только стандартный набор, но и дополнительные команды. Улучшена виртуализация, предусмотрены разнообразные защитные методики. В случае с ARM-процессором, командный ассортимент скудней;
- Изготовление. В случае с x86-микропроцессорами рынок делят Intel и AMD, причём первая начала терять долю в последние годы (сейчас у неё ~70 %). В ARM-архитектуре на передний план выходит открытость, поэтому есть немало производителей, вносящих в стандарт нечто своё, изготавливающих необходимые чипы и модули;
- Энергопотребление. Для сравнения, Core i9-9900K потребляет до 190 Вт, а среднестатистический мобильный конкурент – около 2-3 Вт. Очевидно, что для первых потребуется мощный аккумулятор, либо стационарный источник питания. Вторые подходят для любых гаджетов, умещающихся в кармане и на ладони. Схожая ситуация наблюдается и в плане тепловыделения;
- Общая производительность. Из вышесказанного можно сделать логичный вывод, что x86-е остаются флагманским вариантом для стационарных систем. Но и ARM-чипы постепенно догоняют их, что обуславливается уменьшением техпроцесса и развитием производственных технологий.
Как считаете, появится ли в ближайшем будущем некая объединяющая стандартизация, которая окончательно смоет границы между ПК и портативными гаджетами? Напишите об этом в комментариях.
Это целая уйма вещей. Расширение набора инструкций для нового режима адресации (AMODE), вероятно, будет использовать более крупные инструкции. (за исключением случаев, когда длина инструкций постоянна, как архитектура IBM PowerPC). Также более крупные константы и указатели, что приводит к увеличению размера программ.
Что затем приводит к ухудшению производительности памяти, так как появляются более частые пропуски в кеше. И больше трансляций виртуальной памяти в физическую (TLB) … и так далее.
На самом деле, 64-битная производительность вызывает такое беспокойство, что в IBM Java у нас есть 64-битный режим. В котором 64-битные указатели сжимаются до 32-битных ( ). -Xcompressedrefs
Минусы ARM-чипов:
- Меньшая скорость обработки данных за счёт минимизации размеров и упора на обеспечение достаточной автономности.
Вопрос глобальной переработки всего кода…
И это только часть производительности. Вы должны заплатить большому количеству людей, чтобы переписать большую часть основных инструментов. (ОС, компиляторы, драйверы, библиотеки, …) и перекомпилировать все остальное.
«Остальные», скорее всего, не просто перекомпилируются, даже в идеальном случае. Так как у программистов есть привычка жестко кодировать константы, которые в один прекрасный день меняются.
Эти ошибки часто приводят к разочарованию, так как некоторые менее используемые программы просто переписываются с нуля! А в это мало кто поверит.
По сути, единственная причина увеличения AMODE — возможность доступа ко всей этой памяти в одном адресном пространстве. То есть, представьте, что вы пишете программу или алгоритм, который требует непрерывного доступа всего лишь к 4 ГБ (32-разрядным).
Какие недостатки есть у x86-процессоров:
- Сложные команды и инструкции;
- Повышенное потребление энергии ради достижения максимальной производительности.
А справится ли ядро?
Тогда возникает вопрос, может ли одно ядро процессора действительно обрабатывать все эти 128 разрядов байт данных. Сегодня много-поточных программ не так много, даже на 64 разряда. (Обратите внимание, что мы переходим к многоядерности, а однопоточная производительность в значительной степени остановилась).
С другой стороны, AMODE не имеет ничего общего с тем, какие операции можно выполнять или какие регистры размера можно использовать. Хотите сделать 64-битное умножение в 32-битном приложении? Конечно!
Благодаря поддержке ОС для переключения контекста все эти регистры могут быть доступны из 32-битного приложения.
В заключение. AMODE предназначен исключительно для адресации данных из единого адресного пространства. Так что .. Не просто автоматически компилируйте ваше приложение . Оно не будет быстрее! -m64

Altra Max совместим с другими моделями Altra и могут устанавливаться в серверы, где уже стоят процессоры компании той же линейки. Вся она базируется на дизайне ARM Neoverse N1, он же лежит в основе процессоров AWS Graviton2 от AWS. Компания Ampere заявила, что новые процессоры позволят повысить производительность оборудования, в чем заинтересованы поставщики облачных услуг.
Что касается характеристик, то новинка оснащена 128 физическими ядрами (без технологии многопоточности). Кэш L1 для инструкций и данных — 64 Кбайт, L2 — 1 МБ, L3 — 32 МБ для каждого из ядер. Тактовая частота ядер — 3.0 ГГц.

В зависимости от модели энергопотребление чипов составляет от 45 до 250 Вт. У 80-ядерного Ampere Altra показатель TDP — 210 Вт.
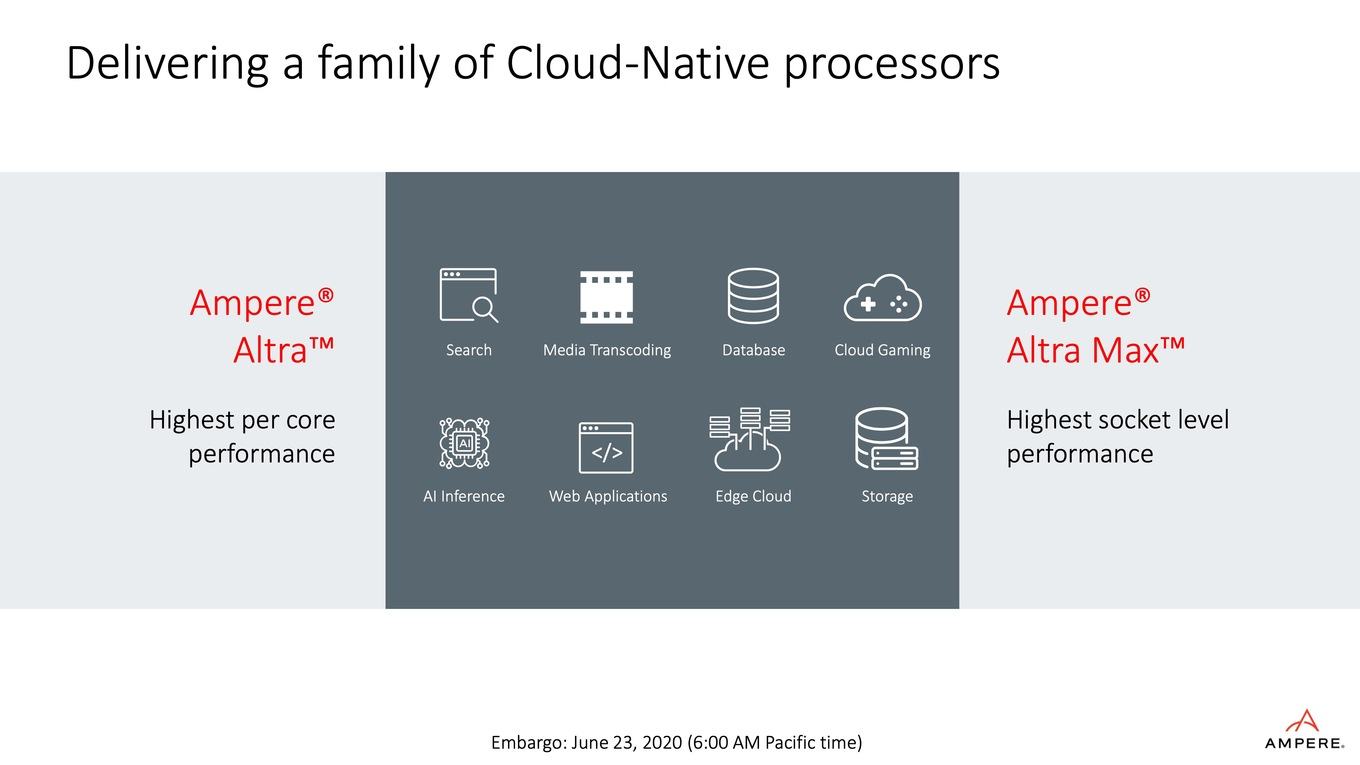
Разработчики предлагают использовать процессор для серверных приложений, включая аналитику данных, нейросети, базы данных, пограничные вычисления и облачные приложения. Специально для нужд машинного обучения Ampere реализовала на аппаратном уровне поддержку форматов данных FP16 (числа половинной точности) и INT8 (однобайтное представление целого числа). Предусмотрено аппаратное ускорение хэширования AES и SHA-256.

Бенчмарк для 80-ядерного ARM процессора Ampere Altra
По словам производителей, серверные ARM-процессоры эффективнее X86, во многом благодаря пониженному энергопотреблению. Поэтому можно повысить плотность размещения оборудования c этими процессорами в ЦОД, одновременно улучшив показатели удельной производительности, энергопотребления и тепловыделения.
Сейчас в линейку Altra входит 12 процессоров, в продажу уже поступили процессоры с количеством ядер от 32 до 80, частотами от 1,7 до 3,3 ГГц и теплопакетами от 45 до 250 Ватт. Цены пока не озвучены.
Известно, что новинкой заинтересовалось несколько партнеров, включая Gigabyte, Wiwynn, Cloudflare, Genymobile, NVIDIA, Equinix и менее крупные компании. Массовое производство новых процессоров начнется в 2021 году, так что и начало продаж можно ожидать примерно в это же время.
«Компания Cloudflare крайне заинтересована в процессоре Ampere и его инновационной архитектуре. Мы приятно удивлены результатами предварительных тестов производительности. Рады возможности поработать с Ampere Altra Max со 128 ядрами и с нетерпением ждем процессор для тестов», — заявили в Cloudflare.
Одновременно Ampere начала освоение 5-нм техпроцесса, именно эта технология будет использоваться при создании серверных процессоров следующего поколения. Они уже получили название Siryn и будут представлены через пару лет, ориентировочно в 2022 году. Насколько известно, они будут поддерживать PCI Express 5.0 и DDR5.

Кроме процессоров, компания поставляет и платформы для них. Платформы доступны двух типов: первая — однопроцессорная Mt. Snow, вторая — двухпроцессорная Mt. Jade.
А здесь можно почитать о том, как мы распаковывали, устанавливали и тестировали сервер с архитектурой arm64 — TaiShan 2280v2.

8 ноября 2021 года на виртуальном мероприятии Accelerated Data Center Premiere компания AMD представила серверные процессоры EPYC 4-го поколения, которые выпустит в 2022–2023 гг (ядра Zen 4 и Zen 4c). Кроме того, представлены улучшенные версии серверных процессоров текущего 3-го поколения EPYC и GPU-ускорители второй серии AMD Instinct MI200 для высокопроизводительных вычислений в дата-центрах (быстрее, чем Nvidia A100).
Сначала о процессорах EPYC.
Как показано на слайде из выступления исполнительного директора Лизы Су, после текущего поколения Milan будет выпущено «улучшенное» поколение Milan-X на том же ядре Zen 3 (16, 32 и 64 ядра) c топологией 7 нм. Выход Milan-X состоится в I кв. 2022 года, цены пока неизвестны.

Отличительной особенностью Milan-X является изготовление кэша L3 по инновационной технологии многослойной укладки транзисторов 3D V-Cache. В остальном это в точности такие же процессоры Milan на том же сокете SP3.
Раньше, до модификации, в каждом чиплете с 8 ядрами размещалось 32 МБ кэша L3, площадью 6×6 мм. Теперь на него сверху нанесут ещё один слой кэша 64 МБ, доведя общий объём до 96 МБ на один чиплет. Для восьми чиплетов (64 ядра) выходит 768 МБ кэша (всего 806 МБ кэша на сокет). То есть в двухпроцессорных серверах общий объём процессорного кэша L3 составит невероятные 1,5 ГБ.

Если технологию обкатают, её могут использовать для изготовления других компонентов CPU, в том числе в новых моделях десктопных процессоров Ryzen.
Трёхмерный стекинг более чем в 200 раз увеличивает плотность интерконнекта, по сравнению с двухмерной структурой. Это означает повышение энергоэффективности и возможность нарастить количество транзисторов на той же площади, но добавляет +10 % задержки при обращении к кэшу.
Компания AMD привела примеры некоторых задач, которые ускоряются до 66 % от апгрейда кэша:



По заверениям AMD, производительность 32-ядерного EPYC 75F3 даже текущего поколения без увеличенного кэша в задачах гидроаэродинамики (расчёт свойств жидкости), анализа методом конечных элементов (FEA) и структурного анализа на 33–40 % выше, чем у 32-ядерного Xeon 8362.
Microsoft опубликовала бенчмарки виртуальных машин HBv3 VM на новых процессорах Milan-X, которые тоже показывают большой рост производительности в некоторых задачах.
Кстати, во время январской презентации на CES 2021 чипы Ryzen с кэшем 3D V-Cache показывали прибавку производительности 15 % в играх. Игры — одна из задач, которая тоже выигрывает от более быстрого и объёмного кэша L3, поэтому все так ждут новых Ryzen в 2022 году.
По слухам, в будущем количество слоёв 3D V-Cache планируется увеличить до четырёх (есть такие настройки в BIOS).
| Процессор | Ядер/Потоков | Базовая частота | Турбо | TDP | Кэш L3 (L3 + 3D V-Cache) |
|---|---|---|---|---|---|
| EPYC 7773X | 64/128 | 2,2 ГГц | 3,5 ГГц | 280 Вт | 768 МБ |
| EPYC 7573X | 32/64 | 2,8 ГГц | 3,6 ГГц | 280 Вт | 768 МБ |
| EPYC 7473X | 24/48 | 2,8 ГГц | 3,7 ГГц | 240 Вт | 768 МБ |
| EPYC 7373X | 16/32 | 3,05 ГГц | 3,8 ГГц | 240 Вт | 768 МБ |
Следующими поколениями серверных процессоров станут Genoa (до 96 ядер, 2022 г) и Bergamo (до 128 ядер, 2023 г) на топологии TSMC 5 нм и новых ядрах Zen 4 и Zen 4c.
По сравнению с нынешним поколением 7 нм компания обещает двойное улучшение энергоэффективности, двойное повышение плотности размещения транзисторов и рост производительности более чем на 25 %

Высокопроизводительное ядро Zen 4 с поддержкой памяти DDR5 и шины PCIe Gen 5, возможно, будет без значительных изменений использоваться также и в десктопных процессорах.

Bergamo (128 ядер Zen 4c) — это вычислительный движок специально для облачных приложений (c — это 'cloud'), в том же сокете, что и Genoa на Zen 4, с межпроцессорной шиной CXL 1.1 (Compute Express Link).
Наконец, серия AMD Instinct MI200 — «самый продвинутый в мире ускоритель для дата-центров», как называет его компания AMD. Вторая серия включает две модели, которые слегка отличаются производительностью: AMD Instinct MI250 и AMD Instinct MI250X.

Эти устройства предназначены для научных расчётов в суперкомпьютерах и дата-центрах, рядом с процессорами EPYC. В частности, ускорители MI250X использовались в сборке суперкомпьютера Frontier, предполагаемого к запуску в Ок-Риджской национальной лаборатории. Он станет первым эксафлопсным компьютером США.
В будущем к ним добавится еще модель в другом форм-факторе AMD Instinct MI210 PCie.




В таблице ниже указаны предполагаемые спецификации новых моделей в сравнении с ускорителями текущего поколения AMD Radeon Instinct MI60 и AMD Instinct MI100.
| Предполагаемые спецификации ускорителей | ||||
|---|---|---|---|---|
| AMD Radeon Instinct MI60 | AMD Instinct MI100 | AMD Instinct MI250 | AMD Instinct MI250X | |
| Архитектура | 7 нм GCN5 (GFX906) | 7 нм CDNA1 (GFX908) | 6 нм CDNA2 (GFX90A) | 6 нм CDNA2 (GFX90A) |
| GPU | Vega 20 | Arcturus | Aldebaran (MCM) | Aldebaran (MCM) |
| Вычислительных модулей | 1 | 1 | 2 | 2 |
| Вычислительных юнитов | 64 | 120 | 208 | 220 |
| Тактовая частота GPU | 1800 МГц | ~1500 МГц | ~1700 МГц | ~1700 МГц |
| FP16 | 29,5 TFLOPS | 185 TFLOPS | 362 TFLOPS | 383 TFLOPS |
| FP32 | 14,7 TFLOPS | 23,1 TFLOPS | 45.3TFLOPS | 47,9 TFLOPS |
| FP64 | 7,4 TFLOPS | 11,5 TFLOPS | 47,9 TFLOPS | 47,9 TFLOPS |
| VRAM | 32 ГБ HBM2 | 32 ГБ HBM2 | 128 ГБ HBM2E | 128 ГБ HBM2E |
| Скорость памяти | 2,0 Гбит/с | 2,4 Гбит/с | 3,2 Гбит/с | 3,2 Гбит/с |
| Шина памяти | 4096-бит | 4096-бит | 8192-бит | 8192-бит |
| Полоса памяти | 1 TБ/с | 1,23 ТБ/с | 3,2 ТБ/с | 3,2 ТБ/с |
| Форм-фактор | Двойной слот, полная длина | Двойной слот, полная длина | OAM | OAM |
| Охлаждение | Пассивное | Пассивное | Пассивное | Пассивное |
| TDP | 300 Вт | 300 Вт | 560 Вт | 560 Вт |
AMD утверждает, что флагманский ускоритель Instinct MI200 значительно быстрее, чем Nvidia A100. В частности, он в несколько раз быстрее в различных научных вычислениях, от астрофизики до молекулярной динамики, и на 20% производительнее в задачах машинного обучения и ИИ, если сравнивать с 400-ваттной SXM-версией A100 с 80 ГБ памяти. Конкретно, Instinct MI200 в 2,4 раза быстрее в OpenMM, в 2,2 раза в LAMMPS, 1,9 раза в HACC и т. д.
Instinct MI250X GPU уже устанавливается в модульные суперкомпьютеры Cray EX от Hewlett Packard Enterprise.
Огромные объемы данных
4 ГБ — это МНОГО данных для доступа «одновременно». Теперь увеличьте это до 16 эксабайт (64-битных). Это просто невероятное количество данных, к которым нужно обращаться из одной программы. Возможно, какая-то «Распределенная ОС», которая имеет 2 в 128 степени байтов памяти сможет управлять всем этим и делиться?
Так много данных, это действительно трудно осознать. Более вероятно, что мы будем использовать подход «разделяй и властвуй», чтобы сделать это управляемым процессом. (Подумайте о модели быстрой сортировки.То есть рекурсивно обрабатывайте эти «простые для понимания» куски объемом 2 ГБ, а затем объединяйте их в виде потока. Другой пример — просмотр фильма. Каждый загружает несколько МБ данных из хранилища, распаковывает их, отправляет для отображения на экране, затем снова то-же самое).
Читайте также: