
Память предназначенная для того чтобы уменьшить количество обращений к оперативной памяти называется
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная память
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти ( ассоциативная память ) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
ПЗУ - быстрая, энергонезависимая память, которая, предназначенная только для чтения. Информация заносится в нее один раз (обычно в заводских условиях) и сохраняется постоянно (при включенном и выключенном компьютере). В ПЗУ хранится информация, присутствие которой постоянно необходимо в компьютере. Комплект программ, находящийся в ПЗУ образовывает базовую систему ввода/вывода BIOS (Basic Input Output System). BIOS (Basic Input Output System — базовая система ввода-вывода) — совокупность программ, предназначенных для автоматического тестирования устройств после включения питания компьютера и загрузки операционной системы в оперативную память.
В ПЗУ находятся:
- тестовые программы, проверяющие при каждом включении компьютера правильность работы его блоков;
- информация о том, где на диске расположена операционная система.
Типы ПЗУ:
ПЗУ с масочным программированием это память, в которую информация записана раз и навсегда в процессе изготовления полупроводниковых интегральных схем. Постоянные запоминающие устройства применяются только в тех случаях, когда речь идет о массовом производстве, т.к. изготовление масок для интегральных схем частного применения обходится весьма недешево.
Программирование ПЗУ – это однократно выполняемая операция, т.е. информация, когда-то записанная в ППЗУ, впоследствии изменена быть не может.
СППЗУ (стираемое программируемое постоянное запоминающее устройство). При работе с ним, пользователь может запрограммировать его, а затем стереть записанную информацию.
ЭИПЗУ (электрически изменяемое постоянное запоминающее устройство). Его программирование и изменение осуществляются с помощью электрических средств. В отличии от СППЗУ для стирания информации, хранимой в ЭИПЗУ, не требуется специальных внешних устройств.
Наглядно ОЗУ и ПЗУ можно представить себе в виде массива ячеек, в которые записаны отдельные байты информации. Каждая ячейка имеет свой номер, причем нумерация начинается с нуля. Номер ячейки является адресом байта.
Центральный процессор при работе с ОЗУ должен указать адрес байта, который он желает прочитать из памяти или записать в память. Разумеется, из ПЗУ можно только читать данные. Прочитанные из ОЗУ или ПЗУ данные процессор записывает в свою внутреннюю память, устроенную аналогично ОЗУ, но работающую значительно быстрее и имеющую емкость не более десятков байт.
Процессор может обрабатывать только те данные, которые находятся в его внутренней памяти, в ОЗУ или в ПЗУ. Все эти виды устройства памяти называются устройствами внутренней памяти, они обычно располагаются непосредственно на материнской плате компьютера (внутренняя память процессора находится в самом процессоре).
Кэш-память. Обмен данными внутри процессора происходит намного быстрее, чем обмен данными между процессором и оперативной памятью. Поэтому, для того чтобы уменьшить количество обращений к оперативной памяти, внутри процессора создают так называемую сверхоперативную или кэш-память. Когда процессору нужны данные, он сначала обращается к кэш-памяти, и только тогда, когда там отсутствуют нужные данные, происходит обращение к оперативной памяти. Чем больше размер кэш-памяти, тем большая вероятность, что необходимые данные находятся там. Поэтому высокопроизводительные процессоры имеют повышенные объемы кэш-памяти.
Различают кэш-память первого уровня (выполняется на одном кристалле с процессором и имеет объем порядка несколько десятков Кбайт), второго уровня (выполняется на отдельном кристалле, но в границах процессора, с объемом в сто и более Кбайт) и третьего уровня (выполняется на отдельных быстродействующих микросхемах с расположением на материнской плате и имеет объем один и больше Мбайт).
В процессе работы процессор обрабатывает данные, находящиеся в его регистрах, оперативной памяти и внешних портах процессора. Часть данных интерпретируется как собственно данные, часть данных - как адресные данные, а часть - как команды. Совокупность разнообразных команд, которые может выполнить процессор над данными, образовывает систему команд процессора. Чем больше набор команд процессора, тем сложнее его архитектура, тем длиннее запись команд в байтах и тем дольше средняя продолжительность выполнения команд.
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
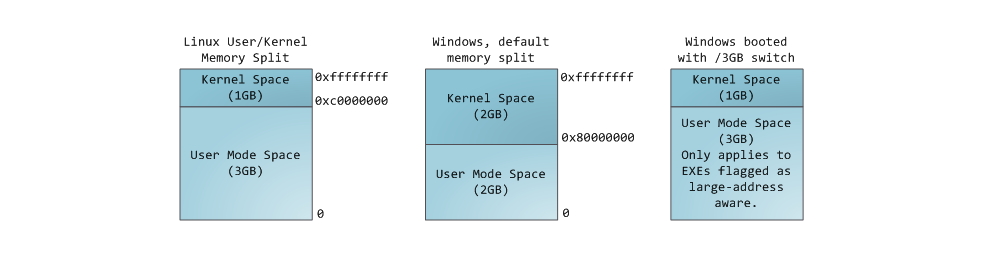
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

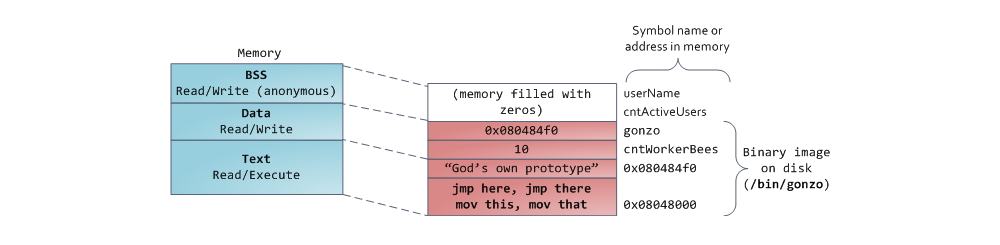
Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент. Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:
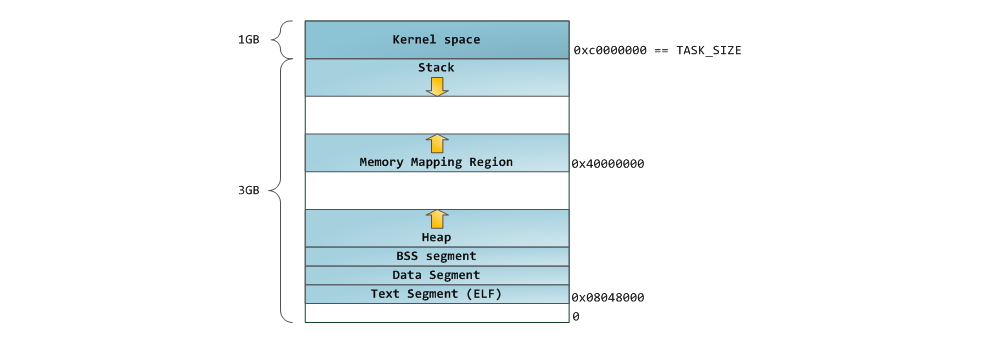
Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.
Память это один из самих важных элементов персонального компьютера (ПК).Память ПК – это совокупность отдельных устройств которые запоминают, хранят, выдают информацию.Основные характеристики памяти – это емкость (объем) и быстродействие.
Быстродействие памяти – время обращения к ячейкам памяти, определяемое временем считывания и (или) временем записи информации. Измеряется в наносекундах.
Емкость памяти – это максимальное количество адресуемых ячеек, выраженное в байтах. Однако часто байт оказывается слишком малой, поэтому существуют более крупные единицы измерения:
Мегабайт -1024 кб
Терабайт – 1024 мб
Перабайт – 1024 тб
Эксабайт – 1024 пб
Зетабайт – 1024 эб
Иоттабайт – 1024 зб
Кроме устройств ввода/вывода информации компьютер также имеет внутреннюю и внешнюю память.
Внутренняя память — это электронное устройство, которое хранит информацию, пока питается электроэнергией, находится внутри материнской платы. Программа во время выполнения хранится в памяти компьютера.
Внешняя память — это различные магнитные носители (ленты, диски), оптические диски, флеш-накопители и др вне материнской платы. Сохранённая информация на них не требует постоянного электропитания.
Единицей хранения информации во внешней памяти является файл – последовательность байтов, записанная в устройство внешней памяти и имеющая имя. Обмен информации между оперативной памятью и внешней осуществляется файлами.
Жесткий диск (HDD) – устройство памяти (физический диск) или раздел винчестера (логический диск). Диск имеет имя и таблицу размещения файлов.
Внутренняя память компьютера делится на:
1. Оперативная память (ОП, ОЗУ) – это быстрое запоминающее устройство не очень большого объема, непосредственно связанное с процессором и предназначенное для записи, считывания и хранения выполняемых программ и данных, обрабатываемых этими программами.
2. Постоянная память (ПЗУ). ПЗУ содержат программы и данные, определяющие работу ПК после его включения. Содержимое ПЗУ изменить нельзя. Программы, находящиеся в ПЗУ, называют «зашитыми» - их записывают туда на этапе изготовления микросхемы. Наряду с ПЗУ используются полупостоянная энергонезависимая память, называемая ППЗУ, хранящая параметры конфигурации системы, она может быть изменена.
3. Кэш-память. Обмен данными внутри процессора происходит в несколько раз быстрее, чем обмен с другими устройствами, например с ОП. Для того чтобы уменьшить количество обращений к оперативной памяти, внутри процессора создают буферную область – так называемую кэш-память. Это как бы «сверхоперативная память».
Классификация запоминающих устройств и систем памяти позволяет выделить общие и характерные особенности их организации, систематизировать базовые принципы и методы, положенные в основу их реализации и использования.
Устройства памяти подразделяются по двум основным критериям: по функциональному назначению (роли или месту в иерархии памяти) и принципу организации.
Классификация ЗУ по функциональному назначению (иерархия запоминающих устройств)
Память ЭВМ почти всегда является "узким местом", ограничивающим производительность компьютера. Поэтому в ее организации используется ряд приемов, улучшающих временные характеристики памяти и, следовательно, повышающих производительность ЭВМ в целом.
Память вычислительной машины представляет собой иерархию запоминающих устройств (внутренние регистры процессора, различные типы сверхоперативной и оперативной памяти, диски, ленты), отличающихся средним временем доступа и стоимостью хранения данных в расчете на один бит. Пользователю хотелось бы иметь и недорогую и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы.
Кэш-память - это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в "быстрое" ЗУ наиболее часто используемой информации из медленного ЗУ.
Кэш-памятью часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств - "быстрое" ЗУ. Оно стоит дороже и, как правило, имеет сравнительно небольшой объем.
Верхнее место в иерархии памяти занимают регистровые ЗУ, которые входят в состав процессора и часто рассматриваются не как самостоятельный блок ЗУ, а просто как набор регистров процессора. Такие ЗУ в большинстве случаев реализованы на том же кристалле, что и процессор, и предназначены для хранения небольшого количества информации (до нескольких десятков слов, а в RISC-архитектурах – до сотни), которая обрабатывается в текущий момент времени или часто используется процессором. Это позволяет сократить время выполнения программы за счет использования команд типа регистр-регистр и уменьшить частоту обменов информацией с более медленными ЗУ ЭВМ. Обращение к этим ЗУ производится непосредственно по командам процессора.
Следующую позицию в иерархии занимают буферные ЗУ (кэш-память). Их назначение состоит в сокращении времени передачи информации между процессором и более медленными уровнями памяти компьютера. Буферная память может устанавливаться на различных уровнях, но здесь речь идет именно об указанном ее местоположении.
Еще одним (внутренним) уровнем памяти являются служебные ЗУ. Они могут иметь различное назначение. Одним из примеров таких устройств являются ЗУ микропрограмм выполнения команд процессора, а также различных служебных операций (например, хранение таблиц адресов данных в кэше процессора). Специфика назначения предполагает недоступность их командам процессора.
Следующим уровнем иерархии памяти является оперативная память. Оперативное ЗУ (ОЗУ) является основным запоминающим устройством ЭВМ, в котором хранятся выполняемые в настоящий момент процессором программы и обрабатываемые данные, резидентные программы, модули операционной системы и т.п. Информация, находящаяся в ОЗУ, непосредственно доступна командам процессора, при условии соблюдения требований защиты.
Еще одним уровнем иерархии ЗУ может являться дополнительная память, которую иногда называли расширенной или массовой. Эта ступень использовалась для наращивания емкости оперативной памяти до величины, соответствующей адресному пространству с помощью подключения более дешевого и емкого, чем ОЗУ, но более медленного запоминающего устройства.
В состав памяти ЭВМ входят также ЗУ, принадлежащие отдельным функциональным блокам компьютера. Формально эти устройства непосредственно не обслуживают основные потоки данных и команд, проходящие через процессор. Их назначение обычно сводится к буферизации данных, извлекаемых из каких-либо устройств и поступающих в них. Типичные примеры такой памяти – видеопамять графического адаптера и буферная память контроллеров жестких дисков и других внешних запоминающих устройств. Емкости и быстродействие этих видов памяти зависят от конкретного функционального назначения обслуживаемых ими устройств. Для видеопамяти, например, объем может достигать величин, сравнимых с оперативными ЗУ, а быстродействие – даже превосходить быстродействие последних.
Следующей ступенью памяти, являются жесткие диски. В этих ЗУ хранится практически вся информация, начиная от операционной системы и основных прикладных программ и кончая редко используемыми пакетами и справочными данными. Эти ЗУ обладают большей емкостью, чем остальные виды памяти и используются для постоянного хранения данных.
Все остальные запоминающие устройства можно объединить с точки зрения функционального назначения в одну общую группу, охарактеризовав ее как группу внешних ЗУ. Под словом “внешние” следует подразумевать то, что информация, хранимая в этих ЗУ, в общем случае расположена на носителях не являющихся частью собственно ЭВМ. Это дискеты, флеш-накопители, CD, DVD, BD-диски и др.
Особенности организации ЗУ определяются, в первую очередь, используемыми технологиями, логикой их функционирования, а также некоторыми другими факторами. Эти особенности и соответствующие разновидности ЗУ перечисляются ниже.
По функциональным возможностям ЗУ можно разделять:
простые, допускающие только хранение информации;
многофункциональные, которые позволяют не только хранить, но и перерабатывать хранимую информацию без участия процессора непосредственно в самих ЗУ.
По возможности изменения информации различают ЗУ:
постоянные (или с однократной записью – CD-ROM, ПЗУ);
односторонние (с перезаписью или перепрограммируемые – CD-RW);
двусторонние (имеют близкие значения времен чтения и записи – HDD).
По способу доступа различают ЗУ:
с адресным доступом (произвольный, последовательный);
с ассоциативным доступом (по ключу).
По организации носителя различают ЗУ:
с неподвижным носителем (SDD, flash);
с подвижным носителем (HDD).
По способу подключения к системе ЗУ делятся на:
По количеству блоков, образующих модуль или ступень памяти, можно различать:
многоблочные ЗУ (позволяют обрабатывать данные параллельно).
Интерфейсы
Архитектура ЭВМ
Архитектура ЭВМ
Мини блог
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
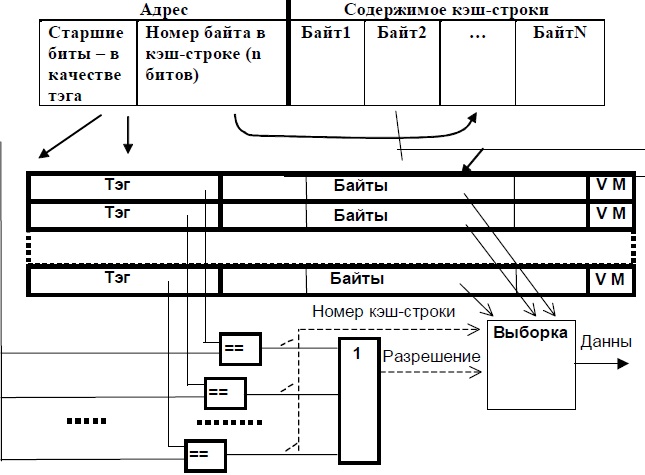
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования ( LRU — Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" ( FIFO — First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Состав, устройство и принцип действия основной памяти
Комплекс технических средств, реализующих функцию памяти, называется запоминающим устройством (ЗУ). ЗУ необходимы для размещения в них команд и данных. Они обеспечивают центральному процессору доступ к программам и информации.
Запоминающие устройства делятся на:
основную память (ОП),
сверхоперативную память (СОЗУ) – устаревшее название кэш и/или регистровой памяти
внешние запоминающие устройства (ВЗУ).
Основная память включает в себя два типа устройств: оперативное запоминающее устройство (ОЗУ или RAM - Random Access Memory) и постоянное запоминающее устройство (ПЗУ или ROM - Read Only Memory).
ОЗУ предназначено для хранения переменной информации. Оно допускает изменение своего содержимого в ходе выполнения процессором вычислительных операций с данными и может работать в режимах записи, чтения, хранения.
ПЗУ содержит информацию, которая не должна изменяться в ходе выполнения процессором вычислительных операций, например стандартные программы и константы. Эта информация заносится в ПЗУ перед установкой микросхемы в ЭВМ. Основными операциями, которые может выполнять ПЗУ, являются чтение и хранение.
Функциональные возможности ОЗУ шире, чем ПЗУ Но ПЗУ сохраняет информацию при отключении питания (т.е. является энергонезависимой памятью) и может иметь более высокое быстродействие, так как ограниченность функциональных возможностей ПЗУ и его специализация на чтении и хранении позволяют сократить время выполнения реализуемых им операций считывания.
В современных ЭВМ микросхемы памяти (ОП и СОЗУ) изготавливают из кремния по полупроводниковой технологии с высокой степенью интеграции элементов на кристалле (микросхемы памяти относятся к так называемым “регулярным” схемам, что позволяет сделать установку элементов памяти в кристалле (чипе) настолько плотной, что размеры элементов памяти становятся сопоставимыми с размерами отдельных атомов).
Основной составной частью микросхемы является массив элементов памяти (ЭП), объединенных в матрицу накопителя.
Каждый элемент памяти может хранить 1 бит информации и имеет свой адрес. ЗУ, позволяющие обращаться по адресу к любому ЭП в произвольном порядке, называются запоминающими устройствами с произвольным доступом.
При матричной организации памяти реализуется координатный принцип адресации ЭП, в связи с чем адрес делится на две части (две координаты) - Х и Y. На пересечении этих координат находится элемент памяти, чья информация должна быть прочитана или изменена.
ОЗУ связано с остальным микропроцессорным комплектом ЭВМ через системную магистраль (рис.1).
Рис. 1. Структурная схема ОЗУ
По шине управления передается сигнал, определяющий, какую операцию необходимо выполнить.
По шине данных передается информация, записываемая в память или считываемая из нее.
По шине адреса передается адрес участвующих в обмене элементов памяти (поскольку данные передаются машинными словами, а один ЭП может воспринять только один бит информации, блок элементов памяти состоит из n матриц ЭП, где n -количество разрядов в машинном слове). Максимальная емкость памяти определяется количеством линий в шине адреса системной магистрали.
Микросхемы памяти могут строиться на статических (SRAM) и динамических (DRAM) ЭП. В качестве статического ЭП чаще всего выступает статический триггер. В качестве динамического ЭП может использоваться электрический конденсатор, сформированный внутри кремниевого кристалла.
Статические ЭП способны сохранять свое состояние (0 или 1) неограниченно долго (при включенном питании). Динамические ЭП с течением времени записанную в них информацию теряют (например, из-за саморазряда конденсатора), поэтому они нуждаются в периодическом восстановлении записанной в них информации - в регенерации.
Микросхемы элементов памяти динамических ОЗУ отличаются от аналогичных ЭП статических ОЗУ меньшим числом компонентов в одном элементе памяти, в связи с чем имеют меньшие размеры и могут быть более плотно упакованы в кристалле. Однако из-за необходимости регенерации информации динамические ОЗУ имеют более сложные схемы управления.
Основными характеристиками ОЗУ являются объем и быстродействие.
На производительность ЭВМ влияет не только время доступа, но и такие параметры (связанные с ОЗУ), как тактовая частота и разрядность шины данных системной магистрали. Если тактовая частота недостаточно высока, то ОЗУ простаивает в ожидании обращения. При тактовой частоте, превышающей возможности ОЗУ, в ожидании будет находиться системная магистраль, через которую поступил запрос в ОЗУ.
ПЗУ (энергонезависимая память)
Микросхемы ПЗУ также построены по принципу матричной структуры накопителя. Функции элементов памяти в них выполняют перемычки в виде проводников, полупроводниковых диодов или транзисторов. В такой матрице наличие перемычки может означать “1”, а ее отсутствие - “О”. Занесение формации в микросхему ПЗУ называется еепрограммированием, а устройство, с помощью которого заносится информация, - программатором. Программирование ПЗУ заключается в устранении (прожигании) перемычек по тем адресам, где должен храниться “О”. Обычно схемы ПЗУ допускают только одно программирование, но специальные микросхемы - репрограммируемые ПЗУ (РПЗУ) - допускают их многократное стирание и занесение новой информации. Этот вид микросхем также относится к энергонезависимым, т.е. может длительное время сохранять информацию при выключенном питании (стирание микросхемы происходит либо за счет подачи специального стирающего напряжения, либо за счет воздействия на кристалл ультрафиолетового излучения, для этого в корпусе микросхемы оставляется прозрачное окно).
Сверхоперативные ЗУ(в настоящее время это кэш-память) используются для хранения небольших объемов информации и имеют значительно меньшее время (в 2 - 10 раз) считывания/записи, чем основная память. СОЗУ (или кэш) обычно строятся на регистрах и регистровых структурах.
Регистр представляет собой электронное устройство, способное хранить занесенное в него число неограниченно долго (при включенном питании). Наибольшее распространение получили регистры на статических триггерах.
По назначению регистры делятся на регистры хранения и регистры сдвига. Информация в регистры может заноситься и считываться либо параллельно, сразу всеми разрядами, либо последовательно, через один из крайних разрядов с последующим сдвигом занесенной информации.
Сдвиг записанной в регистр информации может производиться вправо или влево. Если регистр допускает сдвиг информации в любом направлении, он называется реверсивным.
Регистры могут быть объединены в единую структуру. Возможности такой структуры определяются способом доступа и адресации регистров.
Если к любому регистру можно обратиться для записи/чтения по его адресу, такая регистровая структура образует СОЗУ с произвольным доступом.
Безадресные регистровые структуры могут образовывать два вида устройств памяти: магазинного типа и память с выборкой по содержанию (ассоциативные ЗУ).
Память магазинного типа образуется из последовательно соединенных регистров (рис. 2).
Если запись в регистровую структуру (рис.2,а) производится через один регистр, а считывание - через другой, то такая память является аналогом магазинной памяти и работает по принципу “первым вошел - первым вышел” (FIFO - first input, first output).
Если же запись и чтение осуществляются через один и тот же регистр (рис. 2,б), такое устройство называется стековой памятью, работающей по принципу “первым вошел — последним вышел” (FILO - first input, last output). При записи числа в стековую память сначала содержимое стека сдвигается в сторону последнего, К-го регистра (если стек был полностью заполнен, то число из К-го регистра теряется), а затем число заносится в вершину стека -регистр 1. Чтение осуществляется тоже через вершину стека, после того как число из вершины прочитано, стек сдвигается в сторону регистра 1.
Рис.2. Регистровая структура магазинного типа: а - типа FIFO; б - типа FILO
Стековая память получила широкое распространение. Для ее реализации в ЭВМ разработаны специальные микросхемы. Но часто работа стековой памяти эмулируется в основной памяти ЭВМ: с помощью программ операционной системы выделяется часть памяти под стек (в IBM PC для этой цели выделяется 64 Кбайта). Специальный регистр микропроцессора (указатель стека) постоянно хранит адрес ячейки ОП, выполняющей функции вершины стека. Чтение числа всегда производится из вершины стека, после чего указатель стека изменяется и указывает на очередную ячейку стековой памяти (т.е. фактически стек остается неподвижным, а перемещается вершина стека). При записи числа в стек сначала номер ячейки в указателе стека модифицируется так, чтобы он указывал на очередную свободную ячейку, после чего производится запись числа по этому адресу. Такая работа указателя стека позволяет реализовать принцип “первым вошел - последним вышел”. В стек может быть загружен в определенной последовательности ряд данных, которые впоследствии считываются из стека уже в обратном порядке, на этом свойстве построена система арифметических преобразований информации, известная под названием “логика Лукашевича”.
Память с выборкой по содержанию является безадресной. Обращение к ней осуществляется по специальной маске, которая содержит поисковый образ. Информация считывается из памяти, если часть ее соответствует поисковому образу, зафиксированному в маске. Например, если в такую память записана информация, содержащая данные о месте жительства (включая город), и необходимо найти сведения о жителях определенного города, то название этого города помещается в маску и дается команда чтение - из памяти выбираются все записи, относящиеся к заданному городу.
В микропроцессорах ассоциативные ЗУ используются в составе кэш-памяти для хранения адресной части команд и операндов исполняемой программы. При этом нет необходимости обращаться к ОП за следующей командой или требуемым операндом: достаточно поместить в маску необходимый адрес, если искомая информация имеется в СОЗУ, то она будет сразу выдана. Обращение к ОП будет необходимо лишь при отсутствии требуемой информации в СОЗУ. За счет такого использования СОЗУ сокращается число обращений к ОП, а это позволяет экономить время, так как обращение к СОЗУ требует в 2 - 10 раз меньше времени, чем обращение к ОП.
Рис. 3. Возможный состав системы памяти ЭВМ
Кэш 1-го уровня – 8 Кслов, ( не более 128 Кб ) 1-2 такта
Кэш 2-го уровня – 256 Кслов, (от 128 Кбайт до 1−12 Мбайт) 3-5 тактов
Кэш 3-го уровня – 1 Мслов, (более 24 Мбайт) 6-11 тактов
Основная память – 4 Гслов, 12-55 тактов
Внешняя память – к*Тслов, от 10 6 слов
Буферные ЗУ:Их назначение состоит в сокращении времени передачи информации между процессором и более медленными уровнями памяти компьютера. Буферная память может устанавливаться на различных уровнях. Ранее такие буферные ЗУ в отечественной литературе называлисверхоперативными (СОЗУ), сейчас это название практически полностью вытеснил термин "кэш-память" или простокэш.
Принцип использования буферной памяти во всех случаях сводится к одному и тому же. Буфер представляет собой более быстрое (а значит, и более дорогое), но менее емкое ЗУ, чем то, для ускорения работы которого он предназначен. При этом в буфере размещается только та часть информации из более медленного ЗУ, которая используется в настоящий момент.
Конструктивно кэш уровня L1 входит в состав процессора (поэтому его иногда называют внутренним). Кэш уровня L2 либо также входит в микросхему процессора, либо может быть реализован в виде отдельной памяти. Как правило, на параметры быстродействия процессора большее влияние оказывают характеристики кэш-памяти первого уровня.
Время обращения к кэш-памяти, которая обычно работает на частоте процессора, составляет от десятых долей до единиц наносекунд, т.е. не превышает длительности одного цикла процессора.
Обмен информацией между кэш-памятью и более медленными ЗУ для улучшения временных характеристик выполняется блоками, а не байтами или словами.Управляют этим обменом аппаратные средства процессора и операционная система, и вмешательство прикладной программы не требуется. Причем непосредственно командам процессора кэш-память недоступна, т.е. программа не может явно указать чтение или запись в кэш-памяти, которая является для нее, как иногда говорят, “прозрачной” (прямой перевод используемого в англоязычной литературе словаtransparent).
Кэш (cache) - это память быстрого доступа, расположенная непосредственно в процессоре (в старых ЦП в виде микросхемы). Эта характеристика не так важна, как тактовая частота, но все же будет не приятно если кэш будет маленьким. В нем храниться информация с наибольшей вероятностью запроса. Доступ к этой информации будет воспроизведен мгновенно, этим cache отличается от оперативной памяти.
Компоненты ПК
Ассоциативная память
Читайте также: