
Открытая архитектура процессора это
Существует общественное мнение, что процессор - мозг компьютера. Но как работает этот самый мозг, состоящий из миллиардов транзисторов? В этой небольшой серии статей (всего из четырех частей), портал Techspot решил тщательно разобраться в том, что же заставляет работать ваше "железо".
В статьях будут затронуты такие темы, как принцип работы компьютерной архитектуры, дизайн микросхем процессоров, сверхбольшая масштабная интеграция (VLSI), создание чипов и грядущие тренды. Если вам всегда было интересно, как работают процессоры, то присаживайтесь прямо сейчас и наслаждайтесь чтением, потому что именно с этого и начинается эта статья.
Для начала, нужно понять из чего состоит процессор и как блоки соединяются в функциональное целое. Также будет затронута тема ядер процессоров, иерархии памяти, прогнозирования ветвлений и многого другого. Для начала, стоит дать базовое определение тому, что именно делает процессор. Если говорить простым языком, то процессор проводит операции над введенными командами, следуя конкретным инструкциям. Такой операцией может быть считывание значений из памяти, сложение этих значений а затем сохранение их в другом отделе памяти. Или что-то более сложное, например - деление двух чисел, если результат предыдущего вычисления оказался выше нуля.
Любая программа, будь то операционная система или видеоигра, представляет собой набор инструкций, которые необходимо выполнить. Эти действия загружаются из памяти и запускаются по очереди, вплоть до окончания программы. Многие разработчики пишут программы на сложных языках программирования, например, C++ или Python, но стоит отметить, что процессор их попросту не понимает. Все, что он может - обработать нули и единицы, поэтому необходимо представить код в подобном формате.
Программы представляют собой набор низкоуровневых инструкций. Их называют языком ассемблера (assembly language) и они являются одной из частей архитектуры набора команд (ISA). Процессоры запрограммированы на распознавание и выполнение этих инструкций. Самыми распространенными архитектурами набора команд являются x86, MIPS, ARM, RISC-V и PowerPC. Каждая из них отличается друг от друга написанием кода, по аналогии с языками программирования.
Эти архитектуры можно разбить на две категории: архитектуры с фиксированной длиной и переменной длиной. RISC-V является архитектурой с фиксированной длиной, и это означает, что по количеству битов можно понять можно определить тип инструкции. Ее полная противоположность - это x86, архитектура с переменной длиной, в которой каждая инструкция может быть закодирована совершенно по-разному и с разным количеством битов в каждой части. Именно поэтому декодер инструкций на процессорах с архитектурой x86 является самой сложной деталью всего устройства.
Инструкции с фиксированной длиной декодируются легче и быстрее, но у таких архитектур существует лимит поддерживаемых инструкций. Так, самые распространенные процессоры на RISC-V с открытым доступом поддерживают около 100 инструкций, а x86 является закрытой архитектурой, поэтому никто не знает точного количества поддерживаемых инструкций. Многие считают, что это число достигает нескольких тысяч, но это лишь догадки. Тем не менее, несмотря на такую разницу, процессоры на обеих архитектурах выполняют одни и те же функции.
Примеры инструкций архитектуры RISC-V. Инструкция opcode справа занимает 7 бит, что, в свою очередь, определяет ее тип. Каждая инструкция состоит из битов, которые отвечают за то, какие регистры и функции будут выполняться. Так инструкции ассемблера превращаются в бинарный код, который процессор способен считывать.
Итак, теперь можно включить компьютер и запускать программы. Стоит отметить, что выполнение инструкции состоит из нескольких базовых шагов.
Первым таким шагом является перенос инструкции из памяти в сам процессор. На второй стадии инструкция декодируется, чтобы процессор смог понять, что это за инструкция. Типов инструкций много - от арифметических действий до инструкций памяти. После того, как процессор определил тип инструкции, он достает необходимые операнды из памяти или внутренних регистров. Объясняется это просто - вы не можете сложить числа A и B, если не знаете их значений. Стоит также упомянуть, что, так как многие современные процессоры - 64-битные, то размер значения данных тоже будет составлять 64 бита.
64 бита - это пропускная способность регистра процессора; пути данных и/или адреса памяти. Чем больше бит, тем больше информации компьютер может обрабатывать за раз. Проще говоря, 64-битный процессор может обрабатывать в два раза больше информации, чем 32-битный.
После того, как процессор получил необходимые операнды, начинается выполнение инструкции и операций над введенными данными. Это может быть добавление чисел, проведение логических манипуляций или даже отсутствие действий, когда значение просто отправляется дальше. После подсчета результата, процессор может снова обратиться к памяти, чтобы сохранить полученное значение там или же просто отложить полученное значение в одном из внутренних регистров. Только после того, как результат сохранен, процессор обновит состояние различных элементов и перейдет к выполнению следующей инструкции.
Следует отметить, что вся вышеперечисленная цепочка действий значительно упрощена, поскольку в реальных ситуациях большинство современных процессоров разделяют все эти действия на 20+ более мелких циклов, чтобы повысить эффективность. В профессиональной среде подобное называется пайплайном - чем-то вроде трубопровода, который постепенно заполняется жидкостью, но как только заполнится полностью - внутри создается постоянный поток.
Пример четырехступенчатого пайплайна. Цветные квадраты представляют собой независимые друг от друга инструкции.
Прохождение циклов - тщательно отлаженный процесс, но не все инструкции заканчиваются одновременно. Сложение, например, выполняется невероятно быстро, а вот делению или загрузке из памяти может потребоваться на выполнение несколько сотен циклов. Современные процессоры, вместо того, чтобы простаивать в ожидании завершения одной медленной инструкции, могут выполнять инструкции вне очереди. Процессор сам способен определить, какую инструкцию лучше выполнить в данный момент, а какие - после нее. Если выполняемая инструкция еще не готова, то система может забежать немного вперед, чтобы посмотреть, готово ли что-то другое.
Современные процессоры, кроме внеочередного выполнения инструкций, обладают также суперскалярной архитектурой. Это означает, что процессор может выполнять сразу несколько инструкций на каждом из этапов пайплайна. Для того, чтобы это было возможно, процессору необходимо иметь несколько копий каждого этапа пайплайна. Таким образом, если процессор видит две доступные для исполнения инструкции, между которыми нет никакой зависимости друг от друга, то он сможет одновременно выполнить обе. Такая технология называется одновременной многопотоковостью (SMT), более известной как гиперпотоковость (Hyper-Threading). Процессоры Intel и AMD поддерживают двухстороннюю одновременную многопотоковость, в то время как IBM разработала чипы, поддерживающие уже восьмистороннюю многопотоковость.
Для того, чтобы в точности прорабатывать подобную схему, процессору, помимо ядра, для работы необходимы и другие элементы. В каждом процессоре расположены сотни модулей, причем каждый предназначен для специфической задачи, но в этой статье будут затронуты лишь самые важные. Основные два - это кэш и блок предсказания ветвлений.
Неопытных пользователей кэш может сбить с толку, ведь его главная задача - хранить данные, прямо как оперативная память или любой другой накопитель. Главное отличие кэша заключается в его огромной скорости и низкой задержке при работе с данными. Несмотря на то, что оперативная память обладает высокой скоростью работы с данными, она все еще в разы медленней кэша и слишком медленная для работы процессора. Если говорить, о более точных цифрах, то кэш быстрее оперативной памяти в 100 раз и в 1000 раз быстрее любого SSD. Без кэша процессоры работали бы в разы медленней.
Почти в каждом процессоре есть три уровня кэша - это называется иерархией памяти. Кэш 1 уровня (L1) - самый быстрый и самый маленький, 3 уровня (L3) - наоборот, крупнейший и медленный, а кэш 2 уровня (L2) - "золотая середина" между ними. Выше кэша в иерархии памяти стоят маленькие регистры, в которых сохраняется одиночное значение данных во время работы процессора. Эти регистры по скорости даже опережают кэш. Регистры используются, когда компилятор переводит высокоуровневые программы в язык ассемблера.
Когда процессор запрашивает данные из памяти, то он сначала проверяет, находятся ли эти данные в кэше первого уровня. Если они там есть, то процессор получает доступ к ним всего за пару циклов. Однако, если данных нет в кэше первого уровня, то процессор поищет их в кэше второго, а затем третьего уровня. С каждым уровнем будет снижаться скорость и увеличиваться задержка. Наконец, если в кэше данных не было, процессор начнет искать их уже в основной памяти (RAM).
В большинстве процессоров каждое ядро оснащено двумя кэшами первого уровня - один предназначен для данных, а другой - для инструкций. Кэш первого уровня, зачастую, около 100 КБ в размере, хотя это число может отличаться в зависимости от процессора. Обычно на каждое ядро приходится по кэшу второго уровня, хотя в некоторых архитектурах процессоров может кэш может быть разделен между двумя ядрами. Размер этого кэша составляет уже несколько сотен килобайт. Самым большим (несколько десятков мегабайт) является кэш 3 уровня, который делится сразу между всеми ядрами процессора.
Во время обработки кода процессором, инструкции и значения данных в большинстве случаев направляются в кэш. Так значительно увеличивается скорость выполнения задачи, поскольку процессору не нужно обращаться к главной памяти. Более подробно работа систем памяти будет рассмотрена во второй и третьей части этой серии статей.
Вторым важнейшим элементом процессора является блок предсказания ветвлений. Разветвленные инструкции являются чем-то вроде команды “если”, только в контексте процессора. Одна часть инструкций будет выполняться, если условие верно, а другая - если условие ложно. Пример: необходимо сравнить два числа и, если числа равны, то выполнить одну функцию, а если нет - то другую. Ветвления довольно распространены и, зачастую, составляют около 20% всех инструкций программы.
На бумаге разветвленные инструкции звучат довольно просто, но для процессоров их выполнение может быть довольно проблематичным. Поскольку процессор может выполнять 10-20 инструкций одновременно, ему важно понимать, какие именно нужно обработать. Процессору может понадобиться 5 циклов, чтобы определить является ли инструкция разветвленной, а затем до 10 циклов для того, чтобы определить верна она или нет. В это же время, процессор может начать выполнять десятки дополнительных инструкций, даже не зная правильно ли их выполнение.
Для решения этой проблемы все современные высокопроизводительные процессоры используют технологию спекулятивного выполнения. Благодаря этой технологии процессор запоминает выполняемые разветвленные инструкции и автоматически угадывает, произойдет ли ветвление или нет. Если системе удалось угадать, то процессор будет заранее выполнять другие инструкции, что увеличивает производительность. Если же не удалось, то процессор остановит выполнение всех неподходящих инструкций и начнет выполнять задачи с правильной точки.
Блоки предсказания ветвлений - это нечто вроде ранней формы машинного обучения, поскольку блок будет постепенно заучивать принцип работы разветвленных инструкций. Благодаря тому, что блоки развивались и улучшались десятилетиями, точность прогнозов в современных процессорах превышает 90%.
Несмотря на то, что эти предсказания могут увеличить производительность процессора, они также образуют дыры в безопасности. Так, недавняя уязвимость Spectre позволяла злоумышленникам получить доступ к процессору именно через блок предсказания ветвлений. Из-за этого производители процессоров вынуждены были переписать алгоритмы работы, тем самым слегка снизив производительность.
В последние несколько десятилетий процессоры развились до невероятных высот. Благодаря умелому использованию многих элементов процессоров, производителям удалось поднять производительность на новый уровень. Увы, но эти самые производители держат все принципы работы своих технологий в строжайшем секрете, поэтому трудно понять, как работают мельчайшие детали. К счастью, большинство фундаментальных основ работы процессоров остаются неизменными, стандартизированным и общеизвестными. Если Intel вдруг внезапно решит каким-то волшебным образом увеличить скорость работы кэша, либо AMD добавит более продвинутый блок предсказания ветвлений, знайте - обе компании стараются добиться одной и той же цели.
На этом заканчивается небольшая экскурсия в мир основ работы процессоров. В следующей статье речь пойдет о том, как создаются различные компоненты процессора, о логических вентилях, частоте, энергопотреблении, печатных схемах и многом другом.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Зачем ещё один процессор?
Этим вопросом задаются многие. Но мне видится такое решение довольно логичным, хотя, признаюсь, неожиданным. Смотрите, какое дело.
Архитектура CISC (инструкции переменной длины), на которой строились первые процессоры x86, в один прекрасный момент упёрлась в свой предел производительности. Последним процессором архитектуры CISC стал Pentium, выжавший из неё максимум.
Начиная с Pentium Pro, процессоры стали получать RISC-ядра (короткие быстро выполняемые инструкции), хотя и сохранили совместимость со старой системой команд благодаря её декодированию на лету в короткие RISC-команды уже внутри процессора. Но такое декодирование вызывает накладные расходы, хотя их и постарались снизить всеми возможными способами. Полный же переход на RISC означал бы для Intel потерю всего парка ПО, поэтому он пока не может этого сделать.
Некоторое время такой подход оправдывал себя, но сегодня такая архитектура CISC-RISC тоже упирается в свой предел, а на арену выходят конкурирующие RISC-архитектуры, самой известной из которых, пожалуй, является ARM.
Если сегодня и создавать новый универсальный процессор, то на одной из RISC-архитектур. Так поступили, например, при создании российского процессора Байкал. Купили лицензию на ARM-ядра Cortex A57, и на их основе сконструировали процессор. Но такой процессор зависит от этой самой лицензии, которую, при желании, можно и отозвать. Кроме того, лицензия накладывает некоторые ограничения на полёт фантазии разработчиков на пути к повышению производительности. Замечу также, что цена этой лицензии зависит от степени изменений, которую разработчик намерен провести в архитектуре ядра.
Поэтому хорошо бы нам иметь альтернативный процессор на архитектуре, не требующей покупки лицензии и позволяющей самостоятельно вносить необходимые изменения в ядро и дополнять базовую систему команд при необходимости. И такая архитектура есть — это RISC-V.
Эльбрус
Для этих процессоров их разработчик, компания МЦСТ, разрабатывает ядра самостоятельно. С точки зрения безопасности и независимости это самый безопасный и самый независимый процессор. Но у него тоже есть минусы.
Во-первых, компания-разработчик МЦСТ, в отличие от Байкал Электроникс, по моим ощущениям, имеет серьёзные проблемы с желанием выйти на коммерческий рынок. Они не умеют жить в коммерческой среде и заточены на прямую работу с государством. Даже конференции они технически готовят плохо. Это касается и подготовки презентаций, и ведения интернет-трансляций. В общем, экономят на всём, видимо, не осознавая важности пиара в современной жизни. Впрочем, это не является недостатком самого процессора. Это недостаток разработчика. Возможно, это ещё связано с тем, что Эльбрус всё ещё представляет из себя довольно сырой продукт для широкого потребления, и разработчик опасается негативной реакции пользователей.
Во-вторых, своя система команд является тормозом экспортного потенциала процессора. С одной стороны, она обеспечивает полную независимость развития архитектуры набора команд, но, с другой стороны, ограничивает использование существующего ПО. Справедливости ради, стоит сказать, что положение смягчает возможность выделения двух ядер процессора под бинарную трансляцию команд, что позволяет выполнять на процессоре код x86, запуская на нём Windows и другие ОС, написанные для этой системы команд.
Кстати, это может стать мейнстримом в будущем. Заложенная в аппаратуру процессора бинарная трансляция наиболее распространённых наборов команд мне представляется более удобной вещью, чем необходимость компилировать исходный код под разные наборы команд, хотя мир сейчас движется в сторону второго пути.
В-третьих, архитектура процессора имеет ряд проблемных мест, которые нельзя решить простыми методами. Одно из них — долгое переключение контекста, которое решается только написанием специальной операционной системы, в которой переключения контекста нет, как такового. Такие системы есть, но в настоящее время они существуют только для специальных применений.
В общем, пока Эльбрус мне видится только как процессор для специальных применений. А на что он способен, более предметно можно будет говорить только после внедрения Эльбрус-16С и тестирования образцов Эльбрус-32С, а это произойдёт только через 3-5 лет.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Возможные архитектуры процессоров
Тут есть два постоянных приемлемых варианта и один временный. Начну с временного.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
RISC-V
А вот теперь мы подобрались к основной теме статьи. Что такое RISC-V? Прежде всего, это международный набор процессорных команд, лицензия на использование которого предоставляется бесплатно.
Какие риски появляются при использовании этой системы? Только один, и то слабенький и решаемый — теоретически, компания, юридически предоставляющая бесплатную лицензию, наверное, может её отозвать. Но это крайне маловероятно, поскольку юридический статус подобной лицензии — фактически «общественное достояние с сохранением авторских прав», но даже в этом случае можно сделать минимальные изменения в командах, назвать эту систему как-то иначе (RISC-RUS, например) , и организовать простейшую, а потому очень эффективную, бинарную трансляцию, чтобы то же самое ПО для RISC-V продолжало почти так же быстро работать на этом процессоре. Это один из вариантов обхода лицензии.
А вот плюсы этой системы команд очевидны. Недаром даже Китай в качестве системы команд для своих суверенных процессоров выбрал именно RISC-V, да и Европа широко использует эти ядра в своём процессоре.
Во-первых, благодаря общемировой системе команд сохраняется максимальный экспортный потенциал, который в ближайшем будущем не будет уступать потенциалу процессоров с системой команд x86.
Во-вторых, у нас в России уже есть компании, которые успешно сами разрабатывают ядра RISC-V. То есть, разработка ядер (а не только процессора) возможна полностью своя. Таким образом, по безопасности (отсутствию закладок) и независимости (лицензия подразумевает возможность писать собственные командные расширения) потенциальный процессор с архитектурой набора команд RISC-V мало чем будет отличаться от Эльбруса, а по экспортному потенциалу на порядки превосходить его.
В-третьих, для любителей полной свободы, на базе опыта разработки RISC-V можно легко пойти дальше и начать исследования альтернативной системы команд, добавляя и тестируя их в качестве нерегистрируемого в RISC-V расширения. Впоследствии, добившись более высокой производительности альтернативной системы команд, можно достаточно плавно мигрировать на неё, оставив чистый RISC-V для экспорта.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Прерывания
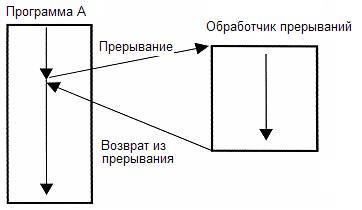
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
RISC-V
Архитектура эта новая, родилась в 2010-м году в отделении информатики Калифорнийского университета в Беркли.
RISC-V — открытая и свободная система команд и процессорная архитектура на основе концепции RISC для микропроцессоров и микроконтроллеров. Спецификация доступна для свободного и бесплатного использования, включая коммерческие реализации непосредственно в кремнии или конфигурировании ПЛИС. Имеет встроенные возможности для расширения списка команд и подходит для широкого круга применений.
Очень здорово, что эта архитектура проще, чем ARM. Поэтому с ней удобнее работать, легче реализовать в железе. В условиях российской действительности (дефицит высококвалифицированных специалистов с опытом работы) это особенно важно.
Простота архитектуры не влияет негативно на производительность процессора. Архитектура рождалась уже с учётом практических знаний о работе других уже имеющихся архитектур, и спроектирована таким образом, чтобы взять от них всё самое лучшее. В итоге эта архитектура выглядит наиболее перспективной из имеющихся, хотя и не такой изученной, как остальные.
Иллюстрацией перспективности архитектуры может быть опыт компании Micro Magic , которая в феврале этого года представила 64-разрядное процессорное ядро на RISC-V. С питанием напряжением 0,8 В ядро работало на частоте 4,25 ГГц и потребляло 200 мВт, а с питанием 1,1 В достигало тактовой частоты 5 ГГц.
Скажу сразу, что не собираюсь рекламировать тут конкретную российскую компанию, которая собирается разрабатывать у нас процессоры на этой архитектуре. Я сразу об этом предупреждаю, потому что как только я начинаю говорить о RISC-V, так тут же в головах некоторых моих читателей срабатывает триггер, и все начинают писать о принадлежности этой компании IBМ (а информацию об этом сами знаете, откуда берут, а именно, с известного Ютьюб-канала) . Надоело, чесслово! )))
Даже не буду снова тщетно спрашивать достоверные пруфы на реальные источники. Речь в статье пойдёт не об этом вообще.
Давайте договоримся, что будем рассматривать в качестве гипотетического разработчика таких процессоров, скажем, компанию МЦСТ. Пусть, предположим, она решила переориентировать своих разработчиков SPARC-линейки на RISC-V. Может, такая постановка вопроса хоть немного разбавит паразитные связи между архитектурой, компанией и её предполагаемой принадлежностью. Только не пишите теперь про Каймановы острова )))
Да, нелегко писать даже технические статьи в атмосфере слухов и фейков, приходится делать длительные вступления, хотя таковые тоже не избавят меня от соответствующих комментариев. Вдобавок, они могут породить массу вопросов у тех, кто не в теме проходящих сегодня жарких интернет-дискуссий, раздуваемых банальной конкурентной борьбой за государственные деньги. Для таковых скажу только одно — забудьте, это не имеет к статье никакого отношения. Информационный мусор.
Почему всем нужен свой процессор?
Итак, сегодня, в ужесточающейся борьбе за место под солнцем между США, Китаем и Россией, очень актуальным становится технологическая независимость в цифровой сфере, как в области, куда перемещаются все инфраструктурные связи государства, бизнеса и населения. Ещё недавно можно было бы выбрать путь глобализации и влиться в мировые технологические цепочки (к сожалению, в общей своей массе единичными и бессистемными звеньями, за исключением поставки полезных ископаемых, но влиться).
Но последние мировые тенденции говорят о том, что даже Европа начала наращивать свою субъектность в микроэлектронике, разрабатывая собственные европейские процессоры (а ей-то уж зачем, но всё равно разрабатывает), не говоря уже о переносе микроэлектронных производств из Тайваня в США и Японию и вложений Китая в создание собственного независимого процессора. В общем, мировая тенденция не оставляет выбора и нам. Необходимость создания собственного российского процессора, который решал бы этот вопрос — аксиома, вне зависимости от того, есть у России сегодня такие возможности, или нет.
Теперь о возможностях. Россия может и разрабатывает процессоры и микроконтроллеры нескольких архитектур разной степени независимости. Этот этап мы завершили. Производить на территории России мы можем только те микроконтроллеры, которые не требуют технологических норм выше 90 нм. Современные процессоры общего назначения мы производить у себя сейчас не можем, поскольку у нас нет соответствующего оборудования для современных технологических норм нижн 90 нм, да и те процессоры Эльбрус-2СМ, которые производились на заводе «Микрон» в Зеленограде по нормам 90 нм не показывали желаемой производительности, поскольку оборудование было ориентировано на производство по этим нормам других продуктов.
Теоретически, в Зеленограде можно произвести процессор и по нормам 65 нм, но для этого пришлось бы использовать слишком много циклов травления, и в результате получить очень невысокий процент годных чипов. Новую фабрику по технологии 28 и 16 нм ещё только начинают строить, а НИРы на разработку оборудования были профинансированы только в прошлом году. Поэтому в ближайшие 4-5 лет ожидать чего-то своего прорывного не стоит, а технологию 6 нм, для которой сейчас разрабатывается Эльбрус-32С и Байкал-S2, можно ожидать лишь к 2030-му году. Так что печатать их будем опять же в TSMC, если нам позволят это делать американские собственники этой условно тайваньской компании.
То есть, сейчас перед нами стоит несколько очень сложных задач, которые нельзя решить сразу. Потребуется действовать в течение какого-то времени, и поступательно делать то, что возможно в каждый конкретный момент. Давайте рассмотрим процесс повышения технической независимости именно с этих позиций.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )

Раскрытие уязвимостей Meltdown и Spectre снова привлекло внимание к багам на аппаратном уровне. Многое сделано для улучшения (всё ещё слабой) безопасности нашего программного обеспечения, но всё напрасно, если оборудование даёт сбой. Процессоры в наших системах по-прежнему, в основном, проприетарные и уже преподнесли ряд неприятных сюрпризов (например, в движке Intel Management Engine). Поэтому встаёт естественный вопрос о переходе на железо open-source, как мы сделали с нашим программным обеспечением. Такой переход вполне возможен и даёт ряд преимуществ, хотя и не является панацеей.
Учитывая сложность современных процессоров и свирепый рынок, где они продаются, их разработка по принципам open-source может показаться необычной идеей. Но в этой области уже есть серьёзные инициативы; так что идея свободного дизайна CPU — не просто фантазия. Небольшое исследование темы выявляет несколько проектов; хотя дальнейший список явно не полон.
Рассмотрим, например, проект OpenPOWER, основанный на архитектуре POWER. Это не полностью свободный проект, в отличие от некоторых других, но это хороший пример совместной разработки процессорной архитектуры. Процессоры на (относительно) открытой архитектуре уже продаются. OpenPOWER ориентируется на серверные CPU; они в ближайшее время вряд ли появятся в вашем компьютере или смартфоне.
Затем, есть OpenSPARC, где Sun Microsystems полностью открыла архитектуры процессоров SPARC T1 и T2. Несколько проектов пытались использовать эти архитектуры, но пока неясно, удалось ли кому-нибудь добиться успеха. На данный момент открытой архитектуре SPARC уже десять лет, а будущее SPARC в целом под сомнением. Что-нибудь интересное может получиться, если Oracle решит открыть архитектуры современных процессоров, но ожидать этого события, затаив дыхание — тоже не лучшая идея.
OpenRISC — полностью открытая архитектура процессора для встроенных приложений; у них полностью готов один процессор (OpenRISC 1000). Сделаны несколько коммерческих версий OpenRISC 1000, существуют и эталонные реализации (такие как mor1kx). Ядро Linux поддерживает OpenRISC с версии 3.1, которая вышла в 2011 году, а порт на Debian существует с 2014 года. Правда, работа в рамках дистрибутива Debian прекратилась в 2016-м. Работа над кодом OpenRISC для ядра тоже замедлилась, хотя в 2017 году появилась поддержка SMP. В целом, OpenRISC как будто потерял бóльшую часть динамики разработки, какая была раньше.
Сейчас максимальная активность вроде бы связана с архитектурой RISC-V. Этот проект ориентируется, в основном, на архитектуру набора команд (ISA), а не на конкретные реализации, но существуют и примеры дизайна свободного оборудования. Western Digital недавно анонсировала, что будет использовать процессоры RISC-V в своём оборудовании для хранения данных — это может привести к поставкам RISC-V в миллиардном масштабе. Есть набор средств разработки для тех, кто хочет поиграться с этим процессором, и доступны многие архитектуры ядра.
В отличие от OpenRISC, RISC-V нацелен на различные варианты использования. Есть надежда, что простая архитектура RISC позволит относительно легко сделать быстрый процессор. В то же время для низкопроизводительных устройств существует сокращённый формат потока команд, с помощью которого уменьшаются требования к памяти и сокращается энергопотребление. ISA предусматривает расширения для конкретных реализаций, что облегчает эксперименты и добавление техник аппаратного ускорения.
Поддержка RISC-V в Linux появилась совсем недавно; только в версии 4.15 (релиз состоялся 28 января 2018 года). Активность разработчиков кажется весьма бурной, а в соответствующих проектах также есть поддержка необходимых инструментальных средств и библиотеки. Судя по всему, у RISC-V имеется определённая поддержка в коммерческой индустрии — по крайней мере, в организацию RISC-V Foundation вступило много компаний. В ближайшее время эта архитектура должна продолжать развитие.
После появления информации о Meltdown и Spectre, организация RISC-V Foundation опубликовала пресс-релиз, продвигающий свою архитектуру процессоров как более безопасную альтернативу. Процессоры RISC-V действительно не подвержены этим уязвимостям, потому что они добропорядочно не допускают никакого спекулятивного доступа к памяти. Но в пресс-релизе говорится, что преимущества RISC-V распространяются за рамки этих конкретных уязвимостей. Сама открытость модели разработки позволяет быстро внедрять лучшие идеи безопасности от широкого круга разработчиков.
Становится всё более очевидным, что хотя Linux может и выиграл битву на уровне ядра, но есть целый слой проприетарного аппаратного и программного обеспечения, работающего ниже этого уровня — и мы не контролируем его. Поэтому открытая архитектура RISC-V выглядит очень привлекательно. Возможно, со временем мы сможем частично вернуть себе этот контроль. Это кажется желанной мечтой, но для её достижения требуется в первую очередь решить некоторые проблемы.
Первая из них, конечно, в том, что хотя компиляторы можно получить бесплатно, но это невозможно в отношении производственных мощностей, особенно дорогих фабрик по производству высокопроизводительных современных процессоров. Если на уровне производства микросхем прогресс замедлится — а некоторые говорят, что это уже происходит — и услуги по производству станут более доступны для малых заказчиков, то тогда эксперименты с архитектурами процессоров на практике станут доступнее для большего количества заказчиков. Впрочем, это никогда не будет настолько простым и дешёвым, как набрать make в консоли.
До тех пор мы останемся зависимыми от других в создании для нас процессоров. Это необязательно плохо; почти все мы точно так же зависим от других в создании для нас программного обеспечения. Но в железе нужно добиваться более высокого уровня доверия. Получение воспроизводимых сборок на уровне программного обеспечения — серьёзная и актуальная задача; на аппаратном уровне она станет ещё сложнее. Но если не добиться некоего способа проверки исходной архитектуры в реальном образце железа, то мы никогда не можем быть уверены, то конкретная микросхема имеет тот дизайн, как нам сказали.
В спецификациях RISC-V ничего не сказано, что конкретные варианты реализаций обязаны публично открывать свою архитектуру. Даже если RISC-V добьётся успеха на рынке, есть высокие шансы, что реальные процессоры не станут поставляться со свободно лицензируемым дизайном. Крупные заказчики (которые строят дата-центры по собственным проектам) могут настоять на получении дизайна микросхем — или просто создать собственный — но у остальных довольно слабая переговорная позиция.
Наконец, даже если мы получим полностью открытые и свободные процессоры, с уязвимостями на этом уровне не будет полностью покончено. У нас есть свободное ядро, но уязвимости в ядре тоже постоянно находят. Открытое железо может придать больше уверенности, что мы сохраним контроль над нашими системами в долговременной перспективе, но это не волшебная палочка для решения всех проблем.
Впрочем, ничего из этого не должно помешать нам добиваться большей открытости и свободы в части аппаратного обеспечения. Когда-то и создание свободной операционной системы казалось непреодолимо сложной задачей, но мы сделали, причём несколько раз. Отход от проприетарного дизайна аппаратного обеспечения может стать одним из лучших шансов сохранить нашу свободу; будет глупо не попытаться сделать это.
На днях пришла очень неожиданная новость из государственной корпорации «Ростех» , которой ещё в 2007 году была передана значительная часть промышленных активов России. Так вот, они уже к 2025-му году собираются разработать и выпустить собственный универсальный процессор с системой команд и архитектурой RISC-V. Основным партнёром в этой миссии является разработчик отечественных систем хранения данных и серверов Yadro .
Ростех выделяет на этот проект 18 миллиардов рублей. Ещё 9,8 миллиарда выделяется на этот проект напрямую из федерального бюджета. Итого 27,8 миллиардов рублей. Сумма, прямо скажем, впечатляющая.
Предположительно, чип будет выпускаться по 12-нм техпроцессу и получит 8 ядер частотой 2 ГГц. К 2025-му году собираются уже продать 60 тысяч компьютеров на базе этого чипа на сумму 7 миллиардов рублей. Конечно, эта информация ещё очень предварительная, и может существенно меняться (и по срокам, и по нанометрам, и по частоте, и по суммам, как мы привыкли).
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Заключение
В общем, я не вижу никаких серьёзных опасностей в использовании RISC-V в ситуации, когда свою архитектуру схожей простоты и производительности мы так и не придумали (хотя хотелось бы), а архитектура процессора Эльбрус в ближайшей перспективе не сулит особых успехов на рынке десктопов. Да, проблемы Эльбруса решаемы, но сопряжены с неудобными побочными эффектами, которые никуда не денутся, хотя их влияние, несомненно, будет нивелировано.
Оппоненты могут возразить, дескать RISC-V ещё слабо развита, применяется только в микроконтроллерах и не предназначена для рабочих станций и серверов, и ещё неизвестно, как она там себя поведёт. Но на это можно возразить, что RISC-V — всего лишь небольшая система команд, а предназначение процессора будет определяться набором расширений этой системы и её аппаратной реализацией. И то и то можно сделать какими угодно, в отличие от уже жёстких особенностей архитектуры Эльбруса, из которых проистекают не только преимущества в отдельных областях применений, но и основные проблемы с контекстом, объёмом кода, скоростью компиляции и т.п.
Резюмируя, я предлагаю огульно ничего не охаивать и не поддаваться на эмоциональный хайп и фейки по поводу той или иной архитектуры, а подходить к осмыслению нашего пути трезво. Думаю, что нужно сконцентрировать усилия на двух направлениях — это архитектура Эльбрус, потому что это, как минимум, интересно с научной точки зрения, и архитектура RISC-V, потому что в ней содержится больше актуальных для нас преимуществ, в том числе и потенциальных. Одновременно следует начать поиск других вариантов системы команд, которые лучше легли бы на аппаратные возможности транзисторной (а может и не только транзисторной) логики , что дало бы повышение эффективности вычислений.
Что касается Байкала, то он сам способен занять свою нишу благодаря простейшей модели бизнеса и хорошей бизнес-хватке его топ-менеджмента. Но и риски от использования лицензий ARM нужно всегда иметь ввиду.
На сегодня всё. Пишите свои соображения в комментариях, ставьте нравлики и не забудьте подписаться на мой канал, если вы этого ещё не сделали. Удачи!
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Байкал
Это процессоры Байкал с лицензией ARM . Компания Байкал Электроникс лицензирует целиком ядра ARM без изменений. Из своего — микроархитектура процессора, то есть то, как эти ядра и другие купленные блоки соединены в нём внутри. Кстати сказать, от этого тоже зависит немало.
С одной стороны, это самый простой и быстрый способ сделать свой процессор. Кроме того, система команд ARM получается универсальной для всего мира, и у процессора открывается простой путь для экспорта.
С другой стороны, лицензию на каждое новое ядро приходится покупать. А ведь могут и не продать. Кроме того, готовое купленное ядро может содержать закладки. Причём компания ARM может делать закладки только в те ядра, которые она предоставляет конкретной компании. То есть, теоретически, закладки могут оказаться только в ARM-процессорах, разрабатываемых в России.
С этой точки зрения, использование процессоров Байкал по безопасности мало чем отличается от использования процессоров Intel. Но ведь выше мы поняли, что к цели приходится идти поступательно, и если рассматривать этот процесс в динамике, то Байкалы стимулируют учиться разрабатывать собственную микроархитектуру, собственные материнские платы, помогают осваивать внедрение альтернативных процессоров, да и восполнять провалы поставок крупных партий более медлительными конкурентами.
То есть, Байкалы нужны на данном этапе. Но они не совсем безопасны, да и в дальнейшем они могут испытать проблемы с закупкой лицензий.
Читайте также: