
На сколько банков разбита оперативная память в пэвм реализованных на базе процессора 8086
Intel 8086 — первый 16-битный процессор компании Intel, выпущенный 8 июня 1978 года. Процессор имел набор команд, который применяется и в современных процессорах, именно от этого процессора берёт своё начало известная на сегодня архитектура x86.
Конкурентами микропроцессора i8086 являются такие разработки, как NEC V30, который был на 5% производительнее i8086, но при этом был полностью с ним совместим. Отечественным аналогом является микропроцессор К1810ВМ86, входивший в серию микросхем К1810.
Оглавление документа
Микрокомпьютеры на основе i8086
Но всё же в некоторых микрокомпьютерах применялся и i8086, одним из таких является Mycron 2000 — первый коммерческий микрокомпьютер на базе i8086. Машина для обработки текстов IBM Displaywriter, Compaq DeskPro и Wang Professional Computer также использовали i8086.

Сегодня, в 2018 году, мы отмечаем сорокалетие, пожалуй, ключевого в истории персональных компьютеров процессора, а именно – Intel 8086.
Именно с него началась эпоха архитектуры x86, заложившей основы развития процессоров на многие годы и десятилетия вперед, именно ему мы обязаны взлету популярности компьютера как индивидуальной единицы, доступной каждому пользователю. В честь 40-летнего юбилея процессора, с которого началось превращение Intel в многомиллиардную корпорацию, компания представила небольшой символический подарок своим поклонникам — им стал юбилейный i7-8086K, первым процессором в истории Intel, способным работать на частоте 5 ГГц прямо из коробки.

Но сегодня мы не будем петь дифирамбы инженерам современных процессоров-лидеров, а вернемся в далекое прошлое, в 1976 год, где и началась история Intel 8086. И началась она с совершенно другого процессора.
Но как оказалось позже, они были крайне полезными – уже в июле 1976 года небольшая компания Zilog, основанная изобретателем Intel 4004 и Intel 8008 Федерико Фаджином, а также менеджером Intel Ральфом Унгерманном и еще одним разработчиком 4004, японцем Масатоси Сима, представила на рынке свой процессор Z-80, ставший фактической работой над ошибками на базе Intel 8080.

Усовершенствовав архитектуру оригинального процессора Intel, команда Zilog предложила недорогой и производительный процессор, сразу же полюбившийся многим производителям техники и ведущих платформ того времени. Именно Z-80 лег в основу легендарного ZX Spectrum, а также был установлен в не менее известный Commodore 128 в качестве сопроцессора. Z-80 стал невероятно успешным во многих уголках мира, и этот успех не мог остаться незамеченным – в Intel срочно решили, что Z-80 нужен достойный конкурент.
Именно здесь руководители компании вспомнили о замечаниях Стивена Морса, и предложили тому возглавить создание принципиально нового процессора, призванного составить конкуренцию новинке от Zilog. Intel не видели особенных причин задавать рамки в этом проекте – тогда всем казалось, что новый процессор будет быстрым ответом на Z-80, и забудется в течение следующих лет, поэтому Морс получил зеленый свет на любые эксперименты. Именно навязчивая мысль о том, что процессор должен строиться вокруг эффективности работы с ПО, как выяснилось позже, стала ключевой для развития всей индустрии.
Морсу приходилось отталкиваться от проекта 8080, в соответствии с которым процессор назначал «адрес» каждому месту, где хранились числа, подобно ярлыкам классификатора. Адреса представляли собой 16-битные двоичные числа, что позволяло обозначить 65536 различных адресов. Этот потолок был приемлем, когда разработчикам требовалось экономно использовать память. Однако теперь потребителям понадобился больший объем, они настаивали на преодолении барьера в 64 Кбайт.
В июле 1978 года новый процессор, получивший название Intel 8086, появился на рынке.

Его выход не стал фурором или невероятным успехом. Впервые процессор попал на прилавки в составе нескольких бюджетных компьютеров, не пользующихся популярностью, а также использовался в различных терминалах. Чуть позже он лег в основу микроконтроллера NASA, где использовался для контроля над диагностическими системами ракетного пуска вплоть до начала 2000-х годов.
Легендарный статус 8088 получил позже, когда в 1980 году IBM впервые задумалась о покорении рынка персональных компьютеров и создании компьютера, который был бы достаточно недорогим, и включал в себя комплектующие среднего класса. Именно IBM 5150, более известный под брендом IBM PC, и получил в основу процессор 8088 (по сути, все тот же 8086), благодаря чему Intel стала широко известной даже в кругах рядовых пользователей. А ведь на место 8088 претендовала и Motorola 68000 (основа первого Apple Macintosh), но руководство IBM отдала предпочтение Intel.

IBM PC быстро превратился в главную силу на рынке компьютерных систем, и Intel, следуя логике «дальше-лучше», продолжила выпускать процессоры – 80186, 80286, 80386, 80486, Pentium и так далее – на базе все той же основы Стивена Морса, заложенной им еще в 8086. Именно благодаря двум последним цифрам архитектура стала известна как «х86», а невероятная популярность компьютеров IBM обеспечила Intel огромные прибыли и узнаваемость в качестве бренда.
Как регистры реализуются в кремнии
Начну с описания того, как 8086 создаётся из N-МОП транзисторов. Затем объясню, как делается инвертор, как при помощи инверторов хранятся одиночные биты, и как делается регистр.
8086, как и другие чипы той эпохи, создавались на основе транзисторов типа N-МОП. Эти чипы состояли из кремниевой подложки, в которую при помощи диффузии внедряли примеси из мышьяка или бора, формировавшие транзисторы. Находящиеся над кремнием проводники из поликремния формировали вентили транзисторов и соединяли все компоненты друг с другом. Находившийся ещё выше металлический слой содержал дополнительные проводники. Для сравнения, современные процессоры используют технологию КМОП, комбинирующую N-МОП и P-МОП транзисторы, и содержат множество металлических слоёв.
На схеме ниже показан инвертор, состоящий из N-МОП транзистора и резистора. При низком входном напряжении транзистор выключен, поэтому подтягивающий резистор подтягивает выход вверх. При высоком входном напряжении транзистор включается, соединяет землю и выход, подтягивая выход вниз. Таким образом входящий сигнал инвертируется.
На самом деле, подтягивающий резистор в вентиле N-МОП представляет собой транзистор особого рода. Работающий в режиме обеднения транзистор ведёт себя, как резистор, будучи при этом более компактным и эффективным.

На схеме показано, как из транзистора и резистора получается инвертор. На фото показана реализация на чипе. Металлический слой удалён, чтобы было видно кремний и поликремний.
На фото выше видно, как физически сделан инвертор у 8086. Розоватые участки – это кремний с примесями, делающими его токопроводящим, а линии медного цвета – это поликремний сверху. Транзистор появляется там, где поликремний пересекается с кремнием. Поликремний формирует вентиль транзистора, а участки кремния с двух сторон дают исток и сток. Большой прямоугольник поликремния формирует подтягивающий резистор между +5 В и выходом. Таким образом, схема чипа совпадает со схемой инвертора. Подобные цепи можно рассмотреть под микроскопом и подвергнуть реверс-инжинирингу.
Строительный блок регистра – два инвертора в цепи обратной связи, хранящих один бит (см. ниже). Если на верхнем проводнике 0, правый инвертор выдаст 1 на нижний проводник. Затем левый инвертор выдаст 0 на верхний проводник, завершая цикл. Таким образом цепь оказывается стабильной и «помнит» 0. И наоборот, если на верхнем проводнике 1, она превратится в 0 на нижнем проводнике, и обратно в 1 на верхнем. В итоге цепь может хранить 0 или 1, формируя однобитную память.

У 8086 два спаренных инвертора хранят в регистре один бит. Схема стабильно находится в состоянии 0 или 1.
К паре инверторов добавляются три транзистора, чтобы получилась пригодная для использования ячейка регистра. Один транзистор выбирает ячейку для чтения, второй выбирает ячейку для записи, третий усиливает сигнал при чтении. В центре схемы ниже два инвертора хранят бит. Для чтения бита ток подаётся на красную шину. Это соединяет выход инвертора с разрядной шиной через усиливающий транзистор. Для записи бита ток подаётся на красную шину, соединяющую разрядную шину с инверторами. Подавая высокотоковые сигналы 0 или 1 на разрядную шину (и, соответственно, на хранящийся бит), мы заставляем инверторы переключаться на нужное значение. Отметьте, что разрядная шина используется и для чтения, и для записи.
В других процессорах используются несколько другие ячейки для хранения регистров. 6502 использует дополнительный транзистор в цепи обратной связи инвертора, чтобы разбивать цепь при записи нового значения. Z80 пишет одновременно в оба инвертора, что «облегчает» изменение, однако требует наличия двух проводников для записи. У 8086 есть усиливающий транзистор в каждой ячейке регистра для чтения, а другие процессоры считывают выходной сигнал с обоих инверторов и используют внешний дифференциальный усилитель для усиления сигнала. Базовая ячейка регистра 8086 состоит из 7 транзисторов (7Т), что больше, чем в типичной статичной ячейке RAM, использующей 6 или 4 транзистора, однако она использует только одну разрядную шину, а не две разных. Динамическая память (DRAM) работает гораздо эффективнее, и использует один транзистор и конденсатор, однако без обновления данных они будут утеряны.

Принципиальная схема хранящей бит ячейки регистра. Регистровый файл делается из массива таких ячеек.
Регистровый файл состоит из матрицы ячеек регистров, подобных описанному выше. Ширина матрицы составляет 16 ячеек, поскольку в регистрах хранятся 16-битные значения. Каждый регистр расположен по горизонтали, поэтому шина чтения или записи выбирает все ячейки определённого регистра. 16 вертикальных разрядных шин формируют единую шину, поэтому все 16 битов в выбранном регистре читаются и записываются параллельно.
На фото ниже показан увеличенный регистровый файл 8086 общего назначения, и видна матрица регистровых ячеек: 16 столбцов и 8 строк, 8 16-битных регистров. Затем дано увеличение одной регистровой ячейки в файле. Объясню, как реализована эта ячейка.

Фото кристалла 8086 с увеличением нижнего регистрового файла (восьми 16-битовых регистров), а потом и отдельной регистровой ячейки. Чтобы было видно кремниевые структуры, металлический и поликремниевый слои удалены.
8086 делается из кремния с примесями и поликремниевых проводников с металлическими проводниками сверху. На левом фото ниже показаны вертикальные металлические проводники регистровой ячейки. Отмечены земля, питание и проводники разрядной шины (оставшийся проводник пересекает регистровый файл, но не контачит с ним). На фото справа металлический слой растворён, чтобы было видно поликремний и кремний. Шины чтения и записи – это горизонтальные поликремниевые проводники. Поскольку у чипа только один металлический слой, в регистрах для вертикальных шин используется металл, а для горизонтальных – поликремний, чтобы они не пересекались друг с другом). Сквозные соединения металла и кремния видны как более яркие круги на фото с металлом и как кружки на фото с кремнием.

Ячейка хранения регистра. На фото слева показан металлический слой, а справа – соответствующие слои поликремния и кремния.
На диаграмме ниже показано соответствие физической схемы регистровой ячейки с принципиальной. Инверторы состоят из транзистора А и В и регистров. Транзисторы C, D и E формируются отмеченными кусочками поликремния. Разрядная шина не видна, поскольку располагается в металлическом слое. Отметьте, что схема ячейки памяти сильно оптимизирована для минимизации размера. Также отметьте, что транзистор А гораздо меньше других. У инвертора А довольно слабый выходной ток, поэтому разрядная шина может преодолеть его при записи.
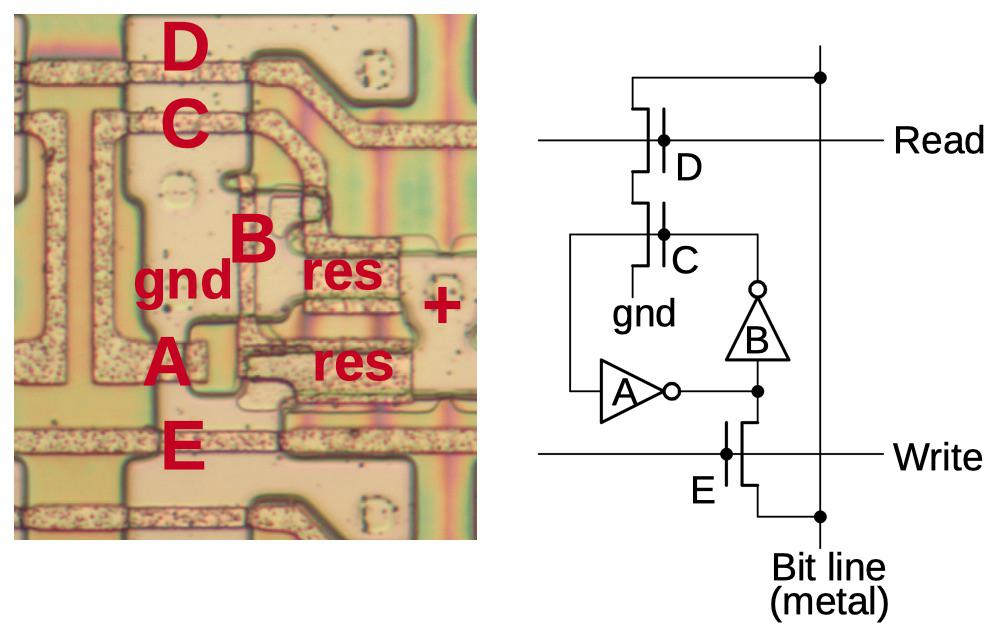
Регистровая ячейка от 8086 с соответствующей схемой
Регистровая ячейка на кристалле повторяются не единообразно – каждая вторая ячейка является зеркальным отражением предыдущей. Это увеличивает плотность регистровой ячейки – шина питания, идущая между двумя зеркальными ячейками, может питать их обе (то же касается и земли). Зеркальные повторения уменьшают количество требуемых шин питания и земли в два раза.
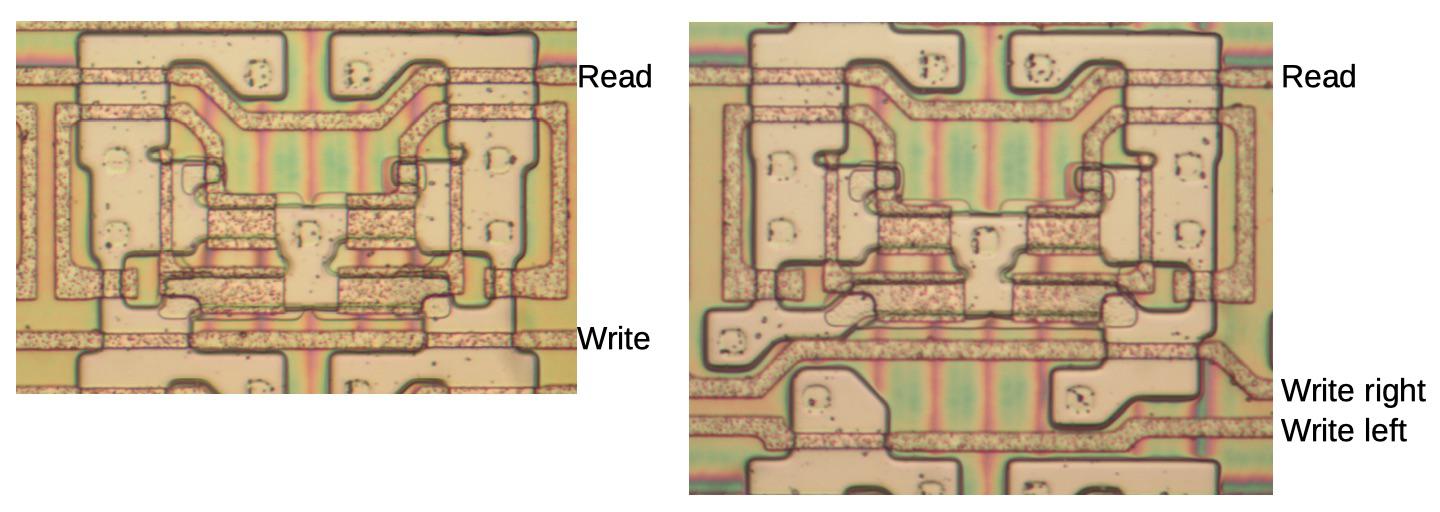
Две пары ячеек памяти с разными цепями. У ячеек слева одна шина записи, а справа – отдельные шины записи для левых и правых битов.
Влияние и наследие
Стивен Морс, создавая концепцию небольшого «дочернего» процессора в стенах Intel, едва ли мог предположить, что находится на пороге создания исторического микропроцессора. Выход Intel 8086 был скромным и неоднозначным, однако его младший брат 8088 обрел славу в составе IBM PC/XT, позволив компании Intel обрести известность и получить колоссальную прибыль.
Архитектура х86 легла в основу всех дальнейших процессоров Intel, осознавшей удобство и универсальность концепции Морса «сначала ПО — потом начинка». Каждый следующий процессор строился на фундаменте предыдущего, обрастая новыми технологиями, инструкциями и блоками, но по своей сути немногим отличался от 8086.

И даже сегодня, глядя на i7 8086K, нужно понимать, что где-то глубоко внутри него еще находятся корни того самого процессора, увидевшего свет 40 лет назад, ознаменовавшего открытие эпохи х86.
Intel 8086 – один из самых влиятельных из когда-либо созданных компьютерных чипов. Он создал архитектуру x86, доминирующую в современных настольных и серверных компьютерах. Я занимался реверс-инжинирингом 8086 на основе фотографий кристаллов, и в данной статье я опишу реализацию регистрового файла (набора регистров).

Кристалл 8086. Отмечено место хранения регистров. Верхние регистры используются блоком интерфейса шины для доступа к памяти, а нижние регистры общего назначения используются исполнительным блоком. Буфер команд – это 6-байтная очередь, состоящая из заранее запрошенных команд.
На фото дано изображение процессора 8086 под микроскопом. Виден металлический слой сверху чипа, под которым прячется кремний. Расположенные по внешнему краю соединительные провода соединяют площадки на кристалле с 40 внешними контактами чипа.
Рамкой обведены пятнадцать 16-битовых регистров 8086 и шесть байтов очереди предварительного запроса команд (предвыборки кода). Регистры занимают значительную часть кристалла, хотя в сумме их наберётся всего на 36 байт. Из-за ограничений по площади у первых микропроцессоров было относительно небольшое количество регистров. Для сравнения, у современных чипов процессоров есть килобайты регистров и мегабайты кэшей.
8086 был одним из самых ранних микропроцессоров, реализовавших предвыборку кода, однако у Motorola 68000 (1979) немного раньше появился буфер предвыборки на 4 байта. В мейнфреймах предвыборка существовала у IBM Stretch (1961), CDC 6600 (1964) и IBM System/360 Model 91 (1966).
Количество регистров у современного процессора подсчитать сложно. Единственное точное число, найденное мною, содержалось в книге "Анатомия высокоскоростного микропроцессора" (1997), подробно описывающей процессор AMD K6. Из-за переименования регистров у современных процессоров физических регистров гораздо больше, чем архитектурных (тех, что видны программисту), а количество физических регистров в документации не указывается. У K6, кроме восьми регистров х86 общего назначения, было 16 микроархитектурных рабочих регистров для переименования.
У процессоров с поддержкой AVX-512 есть 32 512-битовых регистра, то есть для одной этой функции зарезервировано 2 кБ регистров. В таких случаях размер регистров подсчитать ещё сложнее. Что до размера кэша, то у передовых процессоров его объём доходит до 77 МБ.
Заключение
Хотя 8086 процессору уже 42 года, он до сих пор оказывает значительное влияние на современные компьютеры, поскольку архитектура х86 до сих пор очень часто используется. Регистры 8086 до сих пор существуют в современных компьютерах х86, хотя сегодня они уже имеют длину в 64 бита, а кроме этих регистров существует и множество других.
Кристалл 8086-го очень интересно изучать, поскольку его транзисторы можно рассмотреть под микроскопом. В своё время это был сложный процессор, поскольку на нём расположено 29 000 транзисторов, однако достаточно простой для того, чтобы отследить все цепи и понять, как они работают.
Обязательное условие — сегментация
Сегментация — это процесс, в котором основная память компьютера логически разделяется на разные сегменты, и каждый сегмент имеет свой собственный базовый адрес. Он в основном используется для повышения скорости выполнения компьютерной системы, так что процессор может легко и быстро извлекать и выполнять данные из памяти.
Потребность в сегментации —
Шинный интерфейсный блок (BIU) содержит четыре 16-битных регистра специального назначения (упомянутых ниже), называемых сегментными регистрами.
- Регистр сегмента кода (CS): используется для адресации области памяти в сегменте кода памяти, где хранится исполняемая программа.
- Регистр сегмента данных (DS): указывает на сегмент данных памяти, где хранятся данные.
- Дополнительный регистр сегмента (ES): также относится к сегменту в памяти, который является другим сегментом данных в памяти.
- Регистр сегмента стека (SS): используется для адресации сегмента стека памяти. Сегмент стека — это тот сегмент памяти, который используется для хранения данных стека.
Количество строк адреса в 8086 равно 20, 8086 BIU отправит 20-битный адрес, чтобы получить доступ к одному из ячеек памяти объемом 1 МБ. Четыре сегментных регистра фактически содержат старшие 16 бит начальных адресов четырех сегментов памяти по 64 КБ каждый, с которыми 8086 работает в данный момент времени. Сегмент — это логическая единица памяти, длина которой может достигать 64 килобайт. Каждый сегмент состоит из смежных областей памяти. Это независимая, отдельно адресуемая единица. Начальный адрес всегда будет меняться. Это не будет исправлено.
Обратите внимание, что 8086 не работает всю 1 МБ памяти в любой момент времени. Однако он работает только с четырьмя сегментами по 64 КБ в пределах всей 1 МБ памяти.
Ниже представлен один из способов размещения четырех сегментов по 64 килобайта в 1 Мбайт памяти 8086.

Типы сегментации —
- Перекрывающийся сегмент — сегмент начинается с определенного адреса, и его максимальный размер может достигать 64 килобайт. Но если другой сегмент начинается вместе с этим 64-килобайтным местоположением первого сегмента, то эти два, как говорят, являются перекрывающимися сегментами .
- Неперекрывающийся сегмент — сегмент начинается с определенного адреса, и его максимальный размер может достигать 64 килобайт. Но если другой сегмент начинается до этого 64-килобайтного местоположения первого сегмента, то эти два сегмента называются неперекрывающимися сегментами .
Правила сегментации Процесс сегментации следует следующим правилам:
- Начальный адрес сегмента должен быть таким, чтобы его можно было равномерно разделить на 16.
- Минимальный размер сегмента может составлять 16 байтов, а максимальный — 64 КБ.

Преимущества сегментации Основными преимуществами сегментации являются следующие:
Аннотация: На лекции рассматривается упрощенная модель процессора, составляющие его компоненты. Рассматривается многоуровневая модель памяти, использование регистров и оперативной памяти, механизм упреждающей выборки, предсказание переходов. Конвейер. Векторные инструкции. Многоядерность и параллельное выполнение инструкций. Место и роль компилятора в процессе создания эффективного приложения.
Презентацию к лекции Вы можете скачать здесь.
Упрощенная модель процессора

Дополнительная информация:
Прототипом схемы служит отчасти описание архитектуры фон Неймана, которая имеет следующие принципы:
- Принцип двоичности
- Принцип программного управления
- Принцип однородности памяти
- Принцип адресуемости памяти
- Принцип последовательного программного управления
- Принцип условного перехода
Чтобы легче было понять, что из себя представляет современная вычислительная система , надо рассматривать ее в развитии. Поэтому я здесь привел самую простую схему, которая приходит в голову. По сути дела, эта упрощенная модель. У нас существует некое устройство управления внутри процессора, арифметико-логическое устройство , системные регистры, системная шина , которая позволяет вести обмен между устройством управления и другими устройствами, память и периферийные устройства. Устройство управления получает инструкции, делает их дешифрацию, управляет арифметико-логическим устройством, осуществляет пересылку данных между регистрами процессора, памятью , периферийными устройствами.
Упрощенная модель процессора
- устройство управления ( Control Unit , CU)
- арифметико-логическое устройство ( Arithmetic and Logic Unit , ALU )
- системные регистры
- системная шина (Front Side Bus, FSB )
- память
- периферийные устройства
Устройство управления (CU):
- выполняет дешифрацию инструкций, поступающих из памяти компьютера.
- управляет ALU .
- осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
- позволяет производить арифметические и логические операции над системными регистрами.
- определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
- используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами.
Арифметико-логическое устройство состоит из различных электронных компонент , позволяющих производить операции над системными регистрами. Системные регистры – это некие участки в памяти, внутри центрального процессора, используемые для хранения промежуточных результатов, обрабатываемых процессором. Системная шина используется для пересылки данных между центральным процессором и памятью, а также между центральным процессором и периферийными устройствами.
Высокая производительность МП (микропроцессора)– один из ключевых факторов в конкурентной борьбе производителей процессоров.
Производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Производительность = Кол-во инструкций / Время
Мы будем рассматривать производительность процессоров на базе архитектур IA32 и IA32e. (IA32 with EM64T ).
Факторы влияющие на производительность процессора:
- Тактовая частота процессора.
- Объем адресуемой памяти и скорость доступа к внешней памяти.
- Скорость выполнения и набор инструкций.
- Использование внутренней памяти, регистров.
- Качество конвейеризации .
- Качество предсказания переходов.
- Качество упреждающей выборки.
- Суперскалярность .
- Наличие векторных инструкций.
- Многоядерность.
Что такое производительность ? Сложно дать однозначное определение производительности. Можно формально привязать его к процессору – сколько, инструкций за единицу времени может выполнять тот или иной процессор . Но проще дать сравнительное определение – взять два процессора и тот, который выполняет некий набор инструкций быстрее, тот более производительный. То есть, очень условно, можно сказать, что производительность – это количество инструкций на время выполнения . Мы здесь в основном будем исследовать те микропроцессорные архитектуры, которые выпускает Intel, то есть архитектуры IA32, которые сейчас называются Intel 64. Это архитектуры, которые с одной стороны поддерживает старые инструкции из набора IA32, с другой стороны имеют EM64T – это некое расширение, которое позволяет использовать 64 битные адреса, т.е. адресовать большие размеры памяти , а также включает в себя какие-то полезные дополнения, типа увеличенного количества системных регистров, увеличенное количество векторных регистров.
Какие факторы влияют на производительность ? Перечислим все, которые приходят в голову. Это:
- Скорость выполнения инструкций, полнота базового набора инструкций.
- Использование внутренней памяти регистров.
- Качество конвейеризации .
- Качество предсказания переходов.
- Качество упреждающей выборки.
- Суперскалярность .
- Векторизация , использование векторных инструкций.
- Параллелизация и многоядерность.
Тактовая частота
Процессор состоит из компонент, срабатывающих в разное время и в нем существует таймер, который обеспечивает синхронизацию, посылая периодические импульсы. Его частота и называется тактовой частотой процессора.
Объем адресуемой памяти
| 8086 – 1МБ. |
| 80286 – 16МБ (новые системные регистры и новый режим работы с памятью). |
| 80386 – 4ГБ (первый 32-битный процессор технология EM64T – ~2 64 ГБ) |
Тактовая частота.
Поскольку процессор имеет много различных электронных компонент , которые работают независимо, то для того, чтобы синхронизировать их работу, чтобы они знали, в какой момент надо начать работать, когда нужно выполнить свою работу и ждать, существует таймер , который посылает синхроимпульс. Частота, с которой посылается синхроимпульс – и есть тактовая частота процессора. Есть устройства, которые успевают две операции выполнить за это время, тем не менее, к этому синхроимпульсу работа процессора привязана, и, можно сказать, что если мы эту частоту увеличим, то мы заставим все эти микросхемы работать с большим напряжением сил и меньше простаивать.
Объем адресуемой памяти и скорость доступа к памяти.
Объем памяти - необходимо, чтобы памяти хватало для нашей программы и наших данных. То есть, технология EM64T позволяет адресовать огромное количество памяти и на данный момент вопрос с тем, что нам не хватает адресуемой памяти не стоит.
Поскольку на эти факторы разработчики в общем случае не имеют возможности влиять, то я только упоминаю о них.
Скорость выполнения и набор инструкций
Производительность зависит от того, насколько качественно реализованы инструкции, насколько полно базовый набор инструкций покрывает все возможные задачи.
CISC,RISC (complex, reduced instruction set computing)
Современные процессоры Intel® представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.
Скорость выполнения инструкций и полнота базового набора инструкций.
По сути дела, когда архитекторы проектируют процессоры, они постоянно работают с целью улучшить его производительность . Одной из их задач является сбор статистики, для определения , какие инструкции или последовательности инструкций являются ключевыми с точки зрения производительности. Пытаясь улучшить производительность , архитекторы пытаются самые горячие инструкции сделать быстрее, для каких-то наборов инструкций сделать специальную инструкцию, которая заменит этот набор и будет работать эффективнее. От архитектуры к архитектуре изменяются характеристики инструкций, появляются новые инструкции, которые позволяют добиться лучшей производительности. Т.е. можно считать что от архитектуры к архитектуре базовый набор инструкций постоянно совершенствуется и расширяется. Но если вы не указываете на каких архитектурах будет выполняться ваша программа , то в вашем приложении будет задействован некий умолчательный набор инструкций, который поддерживают все последние микропроцессоры. Т.е. наилучшей производительности мы можем добиться только если будем четко специфицировать тот микропроцессор , на котором будет выполняться задача.
Использование регистров и оперативной памяти
Время доступа к регистрам наименьшее, поэтому кол-во доступных регистров влияет на производительность микропроцессора.
Вытеснение регистров ( register spilling ) – из-за недостаточного кол-ва регистров велик обмен между регистрами и стеком приложения.
| Ia32 |
| Технология EM64T – добавлены дополнительные системные регистры |
С ростом производительности процессоров возникла проблема, связанная с тем, что скорость доступа к внешней памяти стала ниже скорости вычислений.
Существуют две характеристики для описания свойств памяти:
- Время отклика ( latency ) – число циклов процессора необходимых для передачи единицы данных из памяти.
- Пропускная способность ( bandwidth ) – количество элементов данных которые могут быть отправлены процессору из памяти за один цикл.
Две возможные стратегии для ускорения быстродействия– уменьшение времени отклика или упреждающий запрос нужной памяти.
Использование регистров и оперативной памяти.
Регистры – самые быстрые элементы памяти, они находятся непосредственно на ядре, и доступ к ним практически мгновенный. Если ваша программа делает какие-то вычисления, хотелось бы, чтобы все промежуточные данные хранились на регистрах. Понятно, что это невозможно. Одна из возможных проблем производительности– это проблема вытеснения регистров. Когда вы под каким-нибудь анализатором производительности смотрите на ассемблерный код, вы видите, что у вас очень много движения со стека в регистры и обратно выгрузка регистров на стек . Стоит вопрос – как оптимизировать код так, чтобы самые горячие адреса, самые горячие промежуточные данные, лежали именно на системных регистрах.
Следующая часть памяти – это обычная оперативная память . С ростом производительности процессоров стало ясно, что самым узким местом производительности является доступ к оперативной памяти. Для того, чтобы добраться до оперативной памяти, нужны сотня, а то и две сотни тактов процессора. То есть, запросив какую-то ячейку памяти в оперативной памяти, мы будем ждать двести тактов, а процессор будет простаивать.
Существует две характеристики для описания свойств памяти – это время отклика, то есть число циклов процессора, необходимое для передачи единицы данных из памяти, и пропускная способность — сколько элементов данных могут быть отправлены процессором из памяти за один цикл. Встретившись с проблемой, что у нас узким местом является доступ к памяти, мы можем решать эту проблему двумя путями – либо уменьшением времени отклика, либо делать упреждающие запросы нужной памяти. То есть, в данный момент нам значение какой-то переменной неинтересно, но мы знаем, что оно скоро нам понадобится, и мы его уже запрашиваем.
Кэширование
Кэш-память служит для уменьшения времени доступа к данным.
Для этого блоки оперативной памяти отображаются в более быструю кэш-память.
Если адрес памяти находится в кэше – происходит "попадание" и скорость получения данных значительно увеличивается.
В противном случае – "промах" (cache miss)
В этом случае блок оперативной памяти считывается в кэш-память за один или несколько циклов шины, называемых заполнением строки кэш-памяти.
Можно выделить следующие виды кэш-памяти:
- полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
- память с прямым отображением (каждый блок может отображаться в одно место)
- гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, куда может отображаться данная память, но в этой строке может находиться только несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Качество использования кэша – ключевое условие быстродействия.
Уменьшение времени доступа было достигнуто введением кэш -памяти. Кэш - память – это буферная память , находящаяся между оперативной памятью и микропроцессором. Она реализована на ядре, то есть доступ к ней гораздо быстрее чем к обычной памяти, но она намного дороже, поэтому при разработке микроархитектуры нужно найти точный баланс между ценой и производительностью. Если вы посмотрите на описания предлагаемых в продаже процессоров, вы увидите, что всегда в описании пишется, сколько кэша памяти того или иного уровня на данном процессоре есть. Эта цифра серьезно влияет на цену данного изделия. Кэш - память устроена так, что обычная память отображается на кэш - память , отображение идет блоками. Вы, запрашивая в оперативной памяти какой-то адрес , делаете проверку, отображен ли этот адрес в кэш -памяти. Если этот адрес уже есть в кэш -памяти, то вы экономите время на обращение к памяти. Вы считываете эту информацию из быстрой памяти, и у вас время отклика существенно уменьшается, если же этого адреса в кэш -памяти нет, то мы должны обратиться к обычной памяти, чтобы этот необходимый нам адрес вместе с каким-то блоком, в котором он находится, отобразился в эту кэш - память .
Существуют разные реализации кэш -памяти. Бывает полностью ассоциативная кэш - память , когда каждый блок может отображаться в любое место кэша. Существует память с прямым отображением, когда каждый блок может отображаться в одно место , также существуют различные гибридные варианты – например кэш с множественно-ассоциативным доступом. В чем разница? Разница во времени и сложности проверки на наличие нужного адреса в кэш -памяти. Предположим, что нам нужен определенный адрес . В случае с ассоциативной памятью нам нужно проверить весь кэш – убедиться, что этого адреса в кэше нет. В случае с прямым отображением нам нужно проверить только одну ячейку. В случае с гибридными вариантами, например, когда используется кэш с множественно-ассоциативным доступом, нам нужно проверить, к примеру, четыре или восемь ячеек. То есть, задача определить есть ли адрес кэша – тоже важна. Качество использования кэша – важное условие быстродействия. Если нам удастся написать программу так, чтобы как можно чаще те данные, с которыми мы собирались работать, находились в кэше, то такая программа будет работать гораздо быстрее.
Характерные времена отклика при обращении к кэш памяти для Nehalem i7:
- L1 - latency 4
- L2 - latency 11
- L3 - latency 38
Время отклика для оперативной памяти > 100
Упреждающий механизм доступа к памяти реализован при помощи механизма упреждающей выборки (hardware prefetching ).
Есть специальный набор инструкций, позволяющий побудить процессор загрузить в кэш память расположенную по определенному адресу (software prefetching ).
Для примера возьмем наш последний процессор Nehalem: i7.
Здесь мы имеем не просто кэш , а некий иерархический кэш . Долгое время он был двухуровневый, в современной системе Nehalem он трехуровневый – совсем немного очень быстрого кэша, чуть побольше кэша второго уровня и достаточно большое количество кэша третьего уровня. При этом, эта система построена так, что если какой-то адрес находится в кэше первого уровня, он автоматически находится во втором и в третьем уровнях. Это и есть иерархическая система. Для кэша первого уровня задержка – 4 такта, для второго – 11, третьего – 38 и время отклика оперативной памяти – больше 100 тактов процессора.
Принцип локальности. Качество упреждающей выборки.
Локальность ссылки (locality of reference) – повторное использование переменных или взаимосвязанных данных. Различают временную локальность ( temporal locality ) – когда речь идет об одних и тех же данных и пространственную локальность ( spatial locality ) – использование различных данных, имеющих относительно близкие области хранения.
Механизм кэширования использует принцип временной локальности. (Стремится сохранять в кэше наиболее часто используемые данные).
Механизм упреждающей выборки использует принцип пространственной локальности. (Стремится определить закономерность в доступе к памяти, чтобы заранее подгружать в кэш необходимую память). При этом, чем выше пространственная локальность (элементы расположены ближе в памяти), тем меньше данных требуется загружать в кэш и меньше нагрузка на системную шину.
Кэш aliasing – из-за неудачного расположения в памяти различных объектов, участвующих в вычислении, происходит вытеснению из кэш памяти одних адресов другими.
Второй вариант улучшения быстродействия и работы с памятью, про который мы упомянули – это подкладывать в кэш заранее необходимые адреса – упреждающий механизм доступа к памяти ( Hardware Prefetching ). Этот механизм выявляет закономерности, с которыми вы обращаетесь к памяти, и заранее закачивает в кэш адреса, которые могут вам понадобиться. Если вы обрабатываете несколько массивов, движетесь по ним последовательно или с каким-то постоянным шагом, то, скорее всего, этот механизм начнет эти адреса заранее подгружать. Есть специальный набор инструкций, позволяющий загрузить в кэш память , расположенную по определенному адресу. ( Software Prefetching )
Кэш имеет внутренние алгоритмы работы. Введем несколько понятий.
Локальность ссылки – переиспользование переменных или взаимосвязанных данных. Различают временную локальность – переиспользование определенных данных и ресурсов и пространственную локальность - использование данных, имеющих относительно близкие области хранения.
Механизм кэширования использует механизм временной локальности. Он пытается отследить те адреса, которые чаще всего используются, и сохранять их в кэше, а те, которые больше не используются – из кэша удалять. То есть каждый раз, когда вы запрашиваете из памяти какой-то новый адрес , механизм кэширования оценивает, какие блоки у него есть, какой из имеющихся у него блоков давно не использовался, и удаляет этот блок, заменяя его на новый. Этот механизм пытается сохранять только те данные, с которыми ведется активная работа.
Механизм упреждающей выборки использует принцип пространственной локальности, то есть подгружает соседние элементы.
При работе механизма кэширования могут происходить неприятные моменты. Например, вы работаете с двумя массивами, но они расположены в памяти так, что взяв адреса одного массива, которые вам нужны, вы вытесняете из кэша адреса другого массива, которые будут вам нужны. Формально, ничего не мешает расположить эти массивы в памяти по -другому и избежать этой проблемы.
Архитектурные особенности 8086
В плане архитектурных особенностей Intel 8086 во многом опирался на опыт разработки процессора 8080, и его усовершенствованного собрата 8085, вышедшего на рынок летом 1976 года. Несмотря на некоторые параллели, 8086 стал первым 16-битным процессором компании, располагавшим 16 каналами данных и 20 адресными каналами, способными обрабатывать до 1 Мб данных, а также имел широкий набор инструкций, позволявших, среди всего прочего, проводить операции деления/умножения. Особенностью работы 8086 было наличие двух режимов – Минимального и Максимального, последний из которых предполагал использование процессора в системе с несколькими процессорами, а первый – в классических системах с одним процессором.
В Intel 8086 впервые появилась очередь инструкций, позволяющая хранить до шести байт инструкций напрямую из памяти, значительно сокращая время на их обработку. 16-битная природа процессора не была основана лишь на нескольких компонентах, ведь 8086 составляли 16-битный ALU, 16-битные регистры, а также внутренняя и внешняя шина данных, обрабатывающие данные по 16-битным инструкциям, благодаря чему система работала значительно быстрее, чем с более ранними процессорами Intel.
Конечно, из-за такого масштабного набора инноваций 8086 был значительно дороже предшественника, но и в подобном ключе у потребителя был выбор — Intel предлагала купить новинку в нескольких вариантах, зависевших от частот процессора – они варьировались от 5 до 10 МГц.
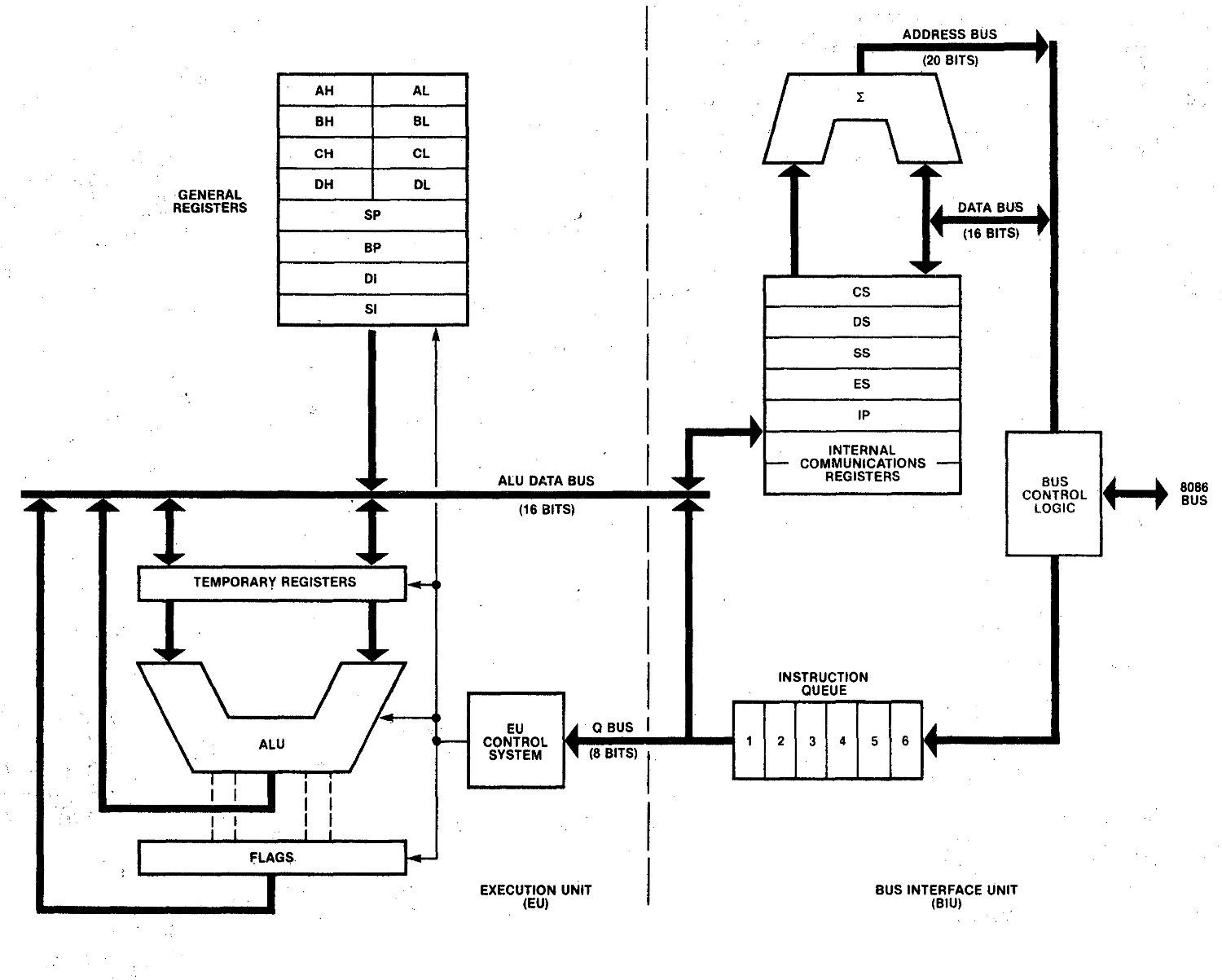
С точки зрения архитектуры микропроцессор Intel 8086 состоял из двух аппаратных модулей – модуля выполнения и модуля интерфейса шины. Модуль выполнения указывал модулю интерфейса шины, откуда получать данные инструкций, а после этого приступал к их подготовке и выполнению. Его суть сводилась к управлению данными с помощью декодера инструкций и блока ALU, при этом сам модуль не имел прямого соединения с шинами данных, и работал исключительно через модуль интерфейса шины.
Модуль выполнения содержал блок АЛУ, предназначенный для выполнения логических и арифметических операций, таких как умножение, деление, сложение, вычитание или операции по типу OR, AND и NOT. Также здесь был 16-битный регистр флагов, хранивший различные состояния операций в аккумуляторе – всего их было 9, 6 из которых были флагами состояния, а 3 являлись системными флагами, отражающими статус работы устройства.
К первым относились: флаг переноса, флаг четности, вспомогательный флаг переноса, флаг нуля, флаг знака и флаг переполнения. К системным флагам относились: флаг трассировки, флаг разрешения прерываний, а также флаг направления.
Наконец, последним из регистров в модуле стал 16-битный указательный регистр, который сохранял адрес сегмента данных в буфере памяти, необходимый для выполнения операции. Остальные функциональные части относились к соседнему модулю интерфейса шины.
Модуль интерфейса шины содержал в себе значительно больше функциональных компонентов – он отвечал на обработку всех данных и отправку инструкций в модуль выполнения, считывание адресов из памяти компьютера и информации со всех доступных портов ввода-вывода, а также за запись данных в доступную память и через вышеуказанные порты. Из-за того, что модуль выполнения не имел прямого соединения с модулем интерфейса шины, взаимодействие блоков происходило посредством внутренней шины данных.
В данном модуле содержится одна из ключевых архитектурных особенностей процессора 8086 – очередь инструкций. Модуль интерфейса шины включает очередь инструкций, способную хранить до 6 байт инструкций в буфере, отсылая новые инструкции по конвейеру после того, как от модуля выполнения поступит соответствующий запрос. Термин pipelining появился именно с выходом на рынок процессора 8086, так как он означает подготовку следующей инструкции в момент, когда предыдущая находится в процессе выполнения.
Здесь же располагается 4 сегментных регистра, отвечающих за буферизацию адресов инструкций и сопутствующих им данных в памяти компьютера, и тем самым обеспечивающих доступ к нужным сегментам центральному процессору. В регистре также содержится указатель команды (IP), содержащий адрес следующей инструкции, предназначенной для модуля выполнения.
Наконец, последним из регистров является 16-битный указатель команды, содержащий адрес следующей для выполнения инструкции.
Intel 8086 стал первым 16-битным процессором компании, доступном в 40-контактном DIP (ди ай пи) корпусе, который наряду со множеством прочих особенностей, стал одним из стандартов в микроэлектронике последующих лет.
Описание
Работа с памятью
Для того чтобы адресовать больший, чем i8080, объём памяти, потребовалось изменить способ адресации памяти. Ведь если использовать старые методы, когда адрес к ячейке памяти содержался в указательных регистрах, то пришлось бы увеличивать размер этих самых регистров, чтобы иметь возможность обращаться к большему объёму памяти. Поэтому для адресации 1 Мбайт памяти применили следующую схему. На шину адреса подавался физический адрес размером 20 бит, который формировался путём сложения содержимого одного из сегментных регистров (16 бит), умноженного на 16, с содержимым указательного регистра: таким образом, адресация ячейки памяти производилась по номеру сегмента и эффективному адресу ячейки в сегменте (называемому также смещением). Если результат сложения оказывался больше, чем 2 20 -1, то 21-й бит отбрасывался; такая процедура называется «заворачиванием» адреса (англ. address wraparound). Этот метод назвали реальным режимом адресации процессора, такой режим позволяет адресовать до 1 Мбайт памяти.

Таким образом, память разделяется на сегменты, размером 64 Кбайт каждый и начинающиеся с адреса, кратного 16 (граница параграфа); память в 1 Мбайт разделялась, таким образом, на 16 сегментов. Эти 16 сегментов называют страницами памяти. В компьютере, подобном IBM PC, последние 6 страниц (A, B, C, D, E, F) памяти (т.н. верхняя память – англ. upper memory) использовались для видеопамяти и BIOS-а, это ограничивало память, доступную пользователю, объёмом в 640 Кбайт (т.н. обычная память – англ. conventional memory; страницы 09).
На то время такой режим адресации обеспечивал множество преимуществ: ёмкость памяти могла составлять до 1 Мбайт, хотя команды оперировали 16-битными адресами; упрощалось использование отдельных областей памяти для программы, её данных и стека; упрощалась разработка устройств, совместимых друг с другом.
Многопортовые регистры
Пока что мы рассмотрели восемь «нижних регистров» общего назначения. У 8086 есть также семь «верхних регистров», используемых для доступа к памяти, включая печально известные сегментные регистры. У этих регистров схема работы более сложная, многопортовая, позволяющая одновременно вести несколько процессов чтения и записи. К примеру, многопортовый регистровый файл позволяет прочесть счётчик программы, сегментный регистр и записать другой сегментный регистр – и всё это одновременно.
Приведённая ниже блок-схема отличается от большинства блок-схем для 8086, поскольку показывает реальную физическую реализацию процессора, а не ту, что представляет себе программист. В частности, на диаграмме показано два «регистра внутренних коммуникаций» среди регистров модуля интерфейса шины (справа) вместе с сегментными регистрами, совпадающими с 7 регистрами, которые можно рассмотреть на кристалле. Временные регистры, показанные ниже, физически являются частью АЛУ, поэтому в данной статье я их не рассматриваю.
В книжке "Разработка современных процессоров" обсуждаются сложные системы регистров в процессоре, начиная с 2000-х годов. Там написано, что сложность цепей быстро выходит за рамки трёх портов, а в некоторых передовых процессорах существуют регистровые файлы с 20 или более портами.
Многопортовая регистровая ячейка ниже создана на основе той же схемы из двух инверторов, однако у неё есть три разрядных шины (а не одна, как в предыдущем случае) и пять управляющих шин (вместо двух). Три шины чтения позволяют читать содержимое регистровой ячейки по любой из трёх разрядных шин, а две шины записи позволяют разрядной шине А или С вести запись в регистровую ячейку.
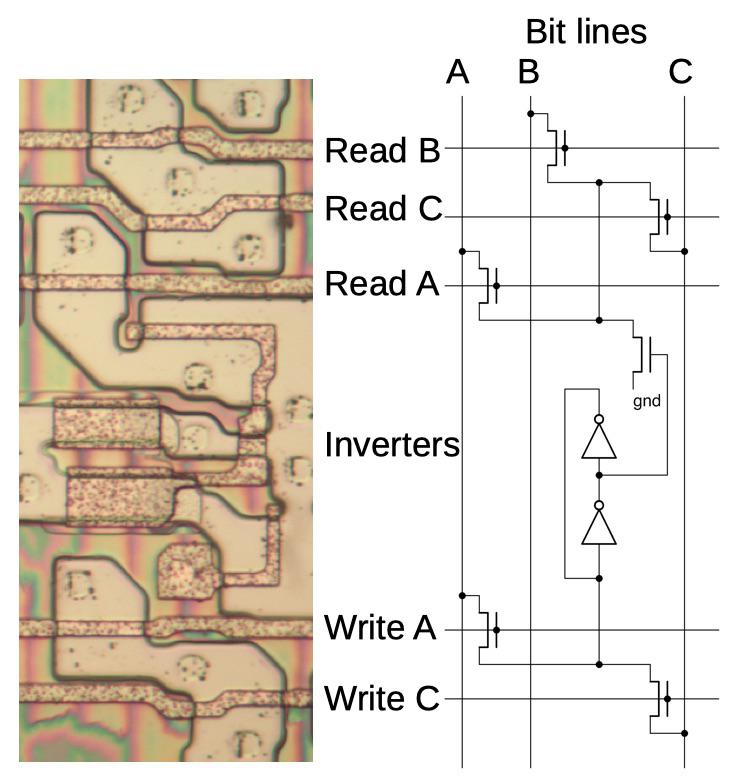
Многопортовая регистровая ячейка в процессоре 8086
У верхних регистров есть разное количество портов для чтения и записи: два регистра с 3 шинами чтения и 2 шинами записи, один регистр с 2 шинами чтения и 2 шинами записи, четыре регистра с 2 шинами чтения и 1 шиной записи. Три первых регистра – это, вероятно, счётчик программы, непрямой временный регистр и временный регистр операнда. Последние четыре – вероятно, сегментные регистры SS, DS, SS и ES. Также там есть три регистра буфера предварительной выборки команд, каждый с одной шиной для чтения и одной для записи.

Файл верхних регистров, состоящий из десяти 16-битных регистров. На фото видно кремний и поликремний. Вертикальные красные линии – остатки удалённого металлического слоя. Кликабельно.
Система команд
Система команд процессора i8086 состоит из 98 команд (и более 3800 их вариаций): 19 команд передачи данных, 38 команд их обработки, 24 команд перехода и 17 команд управления процессором. Микропроцессор не содержал команды для работы с числами с плавающей запятой. Данная возможность реализовывалась отдельной микросхемой, называемой математический сопроцессор, который устанавливался на материнской плате. Сопроцессор, вовсе не обязательно должен был произвёден Intel (модель i8087), к примеру, некоторые производители микросхем, такие, как Weitek, выпускали более производительные сопроцессоры, чем Intel.
В микропроцессоре i8086 была использована примитивная форма конвейерной обработки. Блок интерфейса с шиной подавал поток команд к исполнительному устройству через 6-байтовую очередь команд. Таким образом, выборка и выполнение новых команд могли происходить одновременно. Это значительно увеличивало пропускную способность процессора и лишало необходимости считывать команды из медленной памяти.
Регистры
Всего в процессоре i8086 было 14 16-разрядных регистров: 4 регистра общего назначения (AX, BX, CX, DX), 2 индексных регистра (SI, DI), 2 указательных (BP, SP), 4 сегментных регистра (CS, SS, DS, ES), программный счётчик или указатель команды (IP) и регистр флагов (FLAGS, включает в себя 9 флагов). При этом регистры данных (AX, BX, CX, DX) допускали адресацию не только целых регистров, но и их младшей половины (регистры AL, BL, CL, DL) и старшей половины (регистры AH, BH, CH, DH), что позволяло использовать не только новое 16-разрядное ПО, но сохраняло совместимость и со старыми программами (правда, их необходимо было, по крайней мере, перекомпилировать).
Размер шины адреса был увеличен с 16 бит до 20 бит, что позволило адресовать 1 Мбайт (2 20 байт) памяти. Шина данных была 16-разрядной. Однако в микропроцессоре шина данных и шина адреса использовали одни и те же контакты на корпусе. Это привело к тому, что нельзя одновременно подавать на системную шину адреса и данные. Мультиплексирование адресов и данных во времени сокращает число контактов корпуса до 40, но и замедляет скорость передачи данных.
Читайте также: