
Можно ли сконфигурировать внутри плис процессор
Предисловие или немного лирики.
Современная электроника давно перешагнула тот рубеж, когда сложные схемы требовали усилий огромных коллективов и серьезных финансовых вложений. Сейчас, когда существуют программируемые логические интегральные схемы (ПЛИС), разработка стала настолько простой, что сложнейшие схемы можно создавать за считанные часы силами одного инженера.
Здесь я собираюсь представить одну из подобных разработок, которая покажет, как можно делать свои процессоры в ПЛИС. И покажет, насколько это просто на современном уровне развития цифровой электроники.
Целью данной статьи является не получение "минимального", "оптимального", "лучшего" или еще какого-либо иного экстра-свойства процессора, а представление принципа его построения и построение некой основы, которая может подойти для постройки иных процессоров и осуществления задумок программистов, которые раньше, быть может, просто боялись касаться такой сложнейшей сферы, как процессоростроение.
У процессоров есть много свойств, но одним из главнейших является способность процессора исполнять некую программу действий. И в этом смысле процессор является исполнительным устройством для выполнения программ. С точки зрения такого определения процессор может оказаться каким угодно. И механическим, и электрическим, и гидравлическим.
Тем не менее, в данном случае нас интересует только один тип процессоров. Это процессор цифровой электронный. Если разбираться в цифровых электронных процессорах и начать с самого начала, с истории их создания, то достаточно быстро станет ясно, что подобный процессор состоит из цифровых элементов определенных типов. А именно, из развесистых логических схем и множества регистров, которые в свою очередь состоят из триггеров (обычно D-типа). Пошагово разбирая подобные схемы можно придти к определенному выводу.
А именно: Процессор - это цифровая электронная схема, представляющая собой конечный автомат, предназначенный для исполнения программы, записанной цифровыми кодами.
Именно это определение и заложено в основу разработки, описываемой в данной статье.
2. Конечный автомат О том, что такое конечный автомат (КА) и теорию их построения можно достаточно легко прочитать в литературе и в интернете. Здесь ответам на эти вопросы нет места. Здесь важно только, что одним из видов электронного цифрового конечного автомата является схема следующего вида:
Рис.1.
Для стабильной работы КА необходимо, чтобы время отработки логической части схемы было меньше, чем период синхронизирующих импульсов, поступающих на вход CLK. Это замечание будет важно в дальнейшем.
3. Способ описания процессора Описание процессора представляет собой электрическую схему, которую можно представлять по-разному. Привычная для инженеров графическая схема для процессора мало подходит, так как любая ее правка при возникновении такой необходимости приводит к определенным сложностям. Чтобы обойти эти сложности были разработаны языки описания аппаратуры (HDL), которые позволяют не только достаточно наглядно описать схему процесора, но и легко ее исправлять, так как исправление текстового документа намного проще, чем графического.
В этой статье будет использоваться альтеровский HDL - AHDL, a проверяться в альтеровском САПР - Quartus II. При желании, код может быть легко переведен на VHDL ввиду своей прозрачности и простоты применяемых конструкций.
В соответствии с этими заявлениями, составим верхний иерархический элемент процессора на языке AHDL:
Это очень обобщенная схема процессора с обезличенными входами и выходами. В реальной схеме входы и выходы приобретут конкретные названия и параметры ширины шин. Заметим только, что входы и выходы цепей, соединенных с регистром в обоих модулях процессора названы одинаково, и входы предваряются символом 'i', а выходы символом 'o'. Для AHDL эти символы являются просто частями имен и ничего не значат. Можно, например, у регистра названия входов и выходов поменять местами, и тогда последние строчки описания будут соединять одноименные выводы логического ядра и большого регистра. В каких-то случаях это может оказаться удобно, но здесь применяется другая идея. Смысл которой в том, чтобы программисту было как можно удобнее понимать, что куда подключается. Все входы начинаются с символа 'i', а выходы с символа 'о'.
Теперь поговорим о конкретностях. Выбор, какие регистры и какие нужны входы/выходы делается из предыдущего опыта автора статьи и здесь не обсуждаются. Здесь показан только пример того, как это можно сделать, а добавить иные регистры или выкинуть лишние, читатель при желании сможет сам.
Набор регистров будет следующим:
Набор входов/выходов процессора:
Шины данных и адреса для устройств и памяти считаются совмещенными, хотя могут быть легко разделены при желании.
В соответствии с этими идеями, редактируем верхний файл проекта:
Теперь оформляем модули. Модуль "Большого Регистра" элементарно прост (помним, что два минуса это комментарий до конца строки, а так же коментарием является многострочный текст, ограниченный с двух сторон знаками процента):
Можно было бы и не оформлять большой регистр отдельным файлом, а вписать все его элементы в файл верхнего уровня, но так не сделано намеренно с учетом дальнейшей нацеленности на модификацию этого процессора от одноядерного к многоядерному варианту, в котором разделение регистров и логики имеет существенное значение.
Начало файла логического ядра:
5. Логическое ядро Логическое ядро процессора требует особого внимания, поэтому исходный текст логического ядра в предыдущем параграфе и был оборван "на самом интересном месте".
В первую очередь напомню, что у нас логическое ядро - это чисто комбинарторная схема, а значит, в секции элементов схемы нет никаких тригеров и защелок. Так же, исключены и все элементы, описывающие структурую ПЛИС. Вся реализация ядра отдается "на откуп компилятору", а элементами назначаются только некие шины, которые удобны для описания схемы и вовсе не обязаны присутствовать в ПЛИС явно. Да это и не нужно.
Секция элементов схемы логического ядра:
Выбор, какие шины именовать в этой секции, лежит полностью на разработчике, и не имеет особого значения для сути данной статьи, поэтому здесь приведен конкретный набор без объяснений, почему именно такие шины выбраны для описания.
Собственный софт-процессор на ПЛИС с компилятором языка высокого уровня или Песнь о МышЕ — опыт адаптации компилятора языка высокого уровня к стековому процессорному ядру.
Распространенной проблемой для софт-процессоров является отсутствие средств разработки для них, особенно, если их система команд не является подмножеством команд одного их популярных процессорных ядер. Разработчики в этом случае вынуждены будут решать эту проблему. Прямым её решением является создание компилятора языка ассемблера. Однако в современных реалиях не всегда удобно работать на Ассемблере, так как в процессе развития проекта может изменяться система команд в связи, например, с изменившимися требованиями. Поэтому задача легкой реализации компилятора языка высокого уровня (ЯВУ) для софт-процессора является актуальной.
Компилятор языка Python — Uzh представляется легким и удобным инструментарием для разработки программного обеспечения для софт-процессоров. Инструментарий определения примитивов и макросов как функций целевого языка позволяет критичные места реализовывать на ассемблере процессора. В данной работе рассмотрены основные моменты адаптации компилятора для процессоров стековой архитектуры.
Вместо эпиграфа:
Если взрослого мыша
Взять и, бережно держа,
Напихать в него иголок
Вы получите ежа.
Если этого ежа,
Нос заткнув, чтоб не дышал,
Где поглубже, бросить в речку
Вы получите ерша.
Если этого ерша,
Головой в тисках зажав,
Посильней тянуть за хвост
Вы получите ужа.
Если этого ужа,
Приготовив два ножа…
Впрочем, он наверно сдохнет,
Но идея хороша!
Введение
Во многих случаях при реализации измерительных приборов, научно-исследовательского оборудования в качестве основного ядра системы предпочтительнее применять реконфигурируемые решения на базе ПЛИС/FPGA. Данный подход имеет множество преимуществ, благодаря возможности легкого и быстрого внесения изменений в логику работы, а также за счет аппаратного ускорения операций обработки данных и сигналов управления.
Для широкого круга задач, таких, как цифровая обработка сигналов, встраиваемые системы управления, системы сбора и анализа данных, хорошо зарекомендовал себя подход, заключающийся в сочетании в одном решении блоков, реализуемых логикой ПЛИС для критических процессов, и элементов программного управления на основе одного или нескольких софт-процессоров для общего управления и координации, а также для реализации взаимодействия с пользователем или внешними устройствами/узлами. Применение софт-процессоров в данном случае позволяет несколько снизить временные затраты на отладку и верификацию алгоритмов управления системой или алгоритмов взаимодействия отдельных узлов.
2.2. SliceM
Второй, более функциональный вид секций SliceM (рисунок 5). Он очень похож на SliceL, но при этом его таблицы истинности могут иметь несколько воплощений в проектах. Они могут выступать:
- • В качестве обычных таблиц истинности
- • В качестве элемента распределённой памяти, для хранения небольшого объема информации
- • В качестве аппаратных сдвиговых регистров, позволяя заменить одним элементов цепочку из 32 триггеров
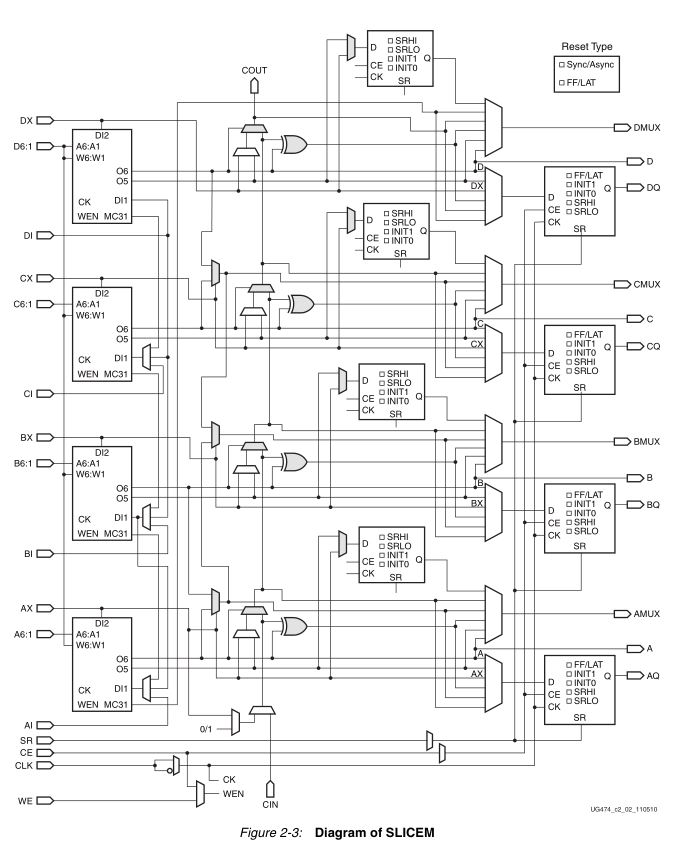
Рисунок 5. Структура SliceM
Думаю, вам было бы интересно узнать, как нужно писать код на VHDL или Verilog, чтобы задействовать все эти ресурсы, казалось бы, обычного CLB - но об этом в другой раз.
Как мы только что увидели, даже такая простая структура из таблицы истинности, мультиплексора и триггера, на практике может оказаться мощным и многофункциональным блоком. И это мы лишь рассмотрели всего один ресурс ПЛИС. Движемся далее
Исходные компоненты
Этим требованиям с большим процентом соответствия удовлетворяют стековые процессоры, т.к. нет необходимости адресовать регистры, разрядность команды может быть небольшой.
Разрядность данных для них может варьироваться и не привязана к разрядности системы команд. Являясь де-факто (пусть и с небольшими оговорками) аппаратной реализацией промежуточного представления программного кода при компиляции (виртуальная стековая машина, или в терминах контекстно-свободных грамматик – магазинный автомат) позволяют с низкими трудозатратами перевести грамматику любого языка в исполнимый код. Кроме того, для стековых процессоров практически «родным» языком является язык Форт. Трудозатраты на реализацию Форт-компилятора для стекового процессора сравнимы с затратами на Ассемблер, при гораздо большей гибкости и эффективности в реализации программ в дальнейшем.
Имея задачу на построение системы сбора данных с интеллектуальных датчиков в режиме, близком к режиму реального времени, в качестве опорного решения (т.н. Reference Design) софт-процессора был выбран Форт-процессор, описанный в работах [1] (в дальнейшем будет иногда называться как процессор whiteTiger по нику его автора).
Его основные особенности:
- раздельные стеки данных и возвратов;
- гарвардская архитектура организации памяти (раздельные памяти программ и данных, включая и адресное пространство);
- расширение периферийными устройствами при помощи простой параллельной шины.
- В процессоре не используется конвейер, выполнение команд двухтактное:
- выборка команды и операндов;
- исполнение команды и сохранение результата.
С оглядкой на конфигурацию блочной памяти в ПЛИС разрядность команд установлена равной 9 бит. Разрядность данных задана в 32 бита, но может быть в принципе любой.
Код процессора написан на VHDL без применения каких-либо специфических библиотек, что позволяет работать с данным проектом на ПЛИС от любого производителя.
Для относительно широкого применения, снижения «входного порога», а также для повторного использования кода и применения наработок кода, целесообразнее перейти на ЯВУ, отличный от Форта (отчасти это связано с суевериями и заблуждениями майн-стрим программистов относительно сложностей данного языка и читабельности его кода (к слову, один из авторов данной работы аналогичного мнения о С-подобных языках)).
Исходя из ряда факторов для эксперимента по «привязке» софт-процессора и ЯВУ был выбран язык Питон (Python). Это высокоуровневый язык программирования общего назначения, ориентированный на повышение производительности разработчика и читаемости кода, поддерживающий несколько парадигм программирования, в том числе структурное, объектно-ориентированное, функциональное, императивное и аспектно-ориентированное [2].
Для начинающих разработчиков интересно его расширение MyHDL [3, 4], позволяющее описывать аппаратные элементы и структуры на Python и транслировать их в код на VHDL или Verilog.
Некоторое время назад был анонсирован компилятор Uzh [5] — небольшой компилятор для программного процессора FPGA Zmey (32-битная стековая архитектура с поддержкой многопоточности – если проследить цепочку версий/модификаций/верификаций – Zmey – дальний потомок процессора whiteTiger).
Uzh – это также статически скомпилированное подмножество Python, основывается на перспективном инструментарии raddsl (набор инструментов для быстрого создания прототипов DSL-компиляторов) [6, 7].
Таким образом, факторы, повлиявшие на выбор направления работ можно сформулировать примерно так:
- интерес к средствам, понижающим «порог вхождения» для начинающих разработчиков устройств и систем на ПЛИС (синтаксически Python не такой «страшный» для начинающего, как VHDL);
- стремление к гармонии и единому стилю в проекте (теоретически возможно описать требуемые аппаратные блоки и программное обеспечение софт-процессора на Python);
- случайное стечение обстоятельств.
2.1. SliceL
Это наиболее «простая» из имеющихся в 7-ой серии ПЛИС Xilinx секций (рисунок 4). При этом она в своем составе содержит:
- • Таблицы истинности, которые могут быть как 5-ти, так и 6-ти входовыми и иметь 2 или 1 выход соответственно
- • Цепи переноса – используемые при реализации математических операций, имплементируемых в логике
- • Синхронные элементы – D-триггеры, которые можно сконфигурировать как обычные синхронные триггеры либо как защелки
- • Мультиплексоры, расширяющие функционал всего конфигурируемого логического блока

Рисунок 4. Структура SliceL
2.5. Сеть тактовой синхронизации
Зададимся вопросом: как нам синхронизировать ресурсы внутри ПЛИС? Для этого есть отдельный выделенный набор ресурсов (рисунок 12), которые включают в себя: ресурсы генерации сетки тактовых частот, построенные на базе фазовой или цифровой автоподстройки частоты – PLL / DLL, специализированных тактовых буферов и трассировочных ресурсов [4].
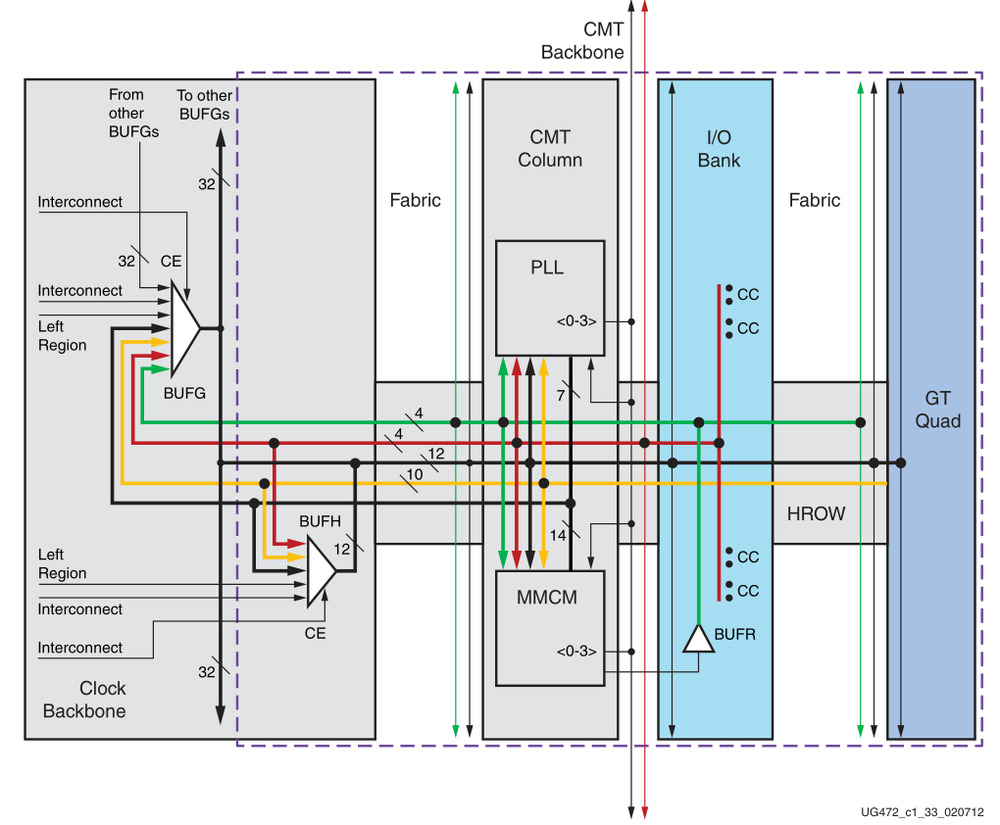
Рисунок 12. Пример ресурсов тактовой синхронизации в FPGA
Сведение таймингов внутри плис – это основная задача FPGA разработчика, помимо написания кода и его отладки. Понимание устройства тактовой сети и ресурсов, ее обеспечивающих очень важно, поскольку именно от этого зависит успех всего проекта.
Реализация интерфейса с помощью модуля EBI
Многие 32-разрядные МК оснащены модулем интерфейса внешней шины (EBI — External Bus Interface), предназначенным для передачи данных между внешними устройствами и контроллерами памяти ARM-устройств. Эти контроллеры способны управлять несколькими типами внешней памяти и периферийными устройствами, например SRAM, PROM, EPROM, EEPROM, флэш-памятью и SDRAM.
Модуль EBI можно также применять для подключения к ПЛИС, пока ПЛИС управляет встроенными интерфейсами памяти. Использование интерфейса статической памяти (SRAM) на модуле EBI является предпочтительным для установления связи с ПЛИС, поскольку он прост и хорошо известен большинству разработчиков. Как и в случае с интерфейсом PIO, ПЛИС должна включать модуль, который понимает синхронизацию SRAM и способен выдавать ответный сигнал микроконтроллеру (см. рис. 4).

На рисунке 5 показана стандартная синхронизация чтения данных для EBI-интерфейса с использованием интерфейса памяти SMC, а на рисунке 6 — стандартный цикл записи.


EBI-интерфейс работает быстрее, чем PIO, т.к. у EBI имеется собственная система ввода-вывода и большая часть сигналов параллельна. Однако если внешнее устройство работает медленно или входит в состояние ожидания, преимущества скорости EBI нивелируются.
Как и PIO-интерфейс, EBI-интерфейс управляется процессором или другим ведущим AHB-устройством. Таким образом, достижимая ширина полосы у EBI-интерфейса также зависит от программного обеспечения и от того, располагает ли процессор достаточным временем. Безусловно, имеется ограничение на ширину полосы, которое и в этом случае ограничивает возможности встраиваемого процессора при выполнении других системных функций, для чего он и предназначен.
PIO-интерфейс
Сопряжение МК с ПЛИС через PIO — относительно простая задача при передаче простых данных, состоящих из 32 бит адреса, 32 бит данных и нескольких сигналов управления. Для такой передачи требуется 32-разрядный PIO и дополнительно два бит для другого PIO (см. рис. 1).

Для передачи данных на ПЛИС направление двусторонних буферов в PIO устанавливается на выход. Чтение с ПЛИС выполняется схожим образом: направление буфера на PIO сначала устанавливается на выход, а затем направление изменяется на вход для чтения данных с ПЛИС.
Для установления требуемой связи между ARM-микроконтроллером и ПЛИС требуется более сложный алгоритм, чем для базовой передачи. Особое внимание при этом необходимо уделить подтверждению приема данных, например для того, чтобы данные не потерялись из-за недостаточной скорости или циклов ожидания с каждой стороны.
Время доступа рассчитывается следующим образом:
Тдост. PIO = t1 + адресная фаза + t2 +
+ информационная фаза
При использовании компилятора GCC с максимальной оптимизацией системе требуется около 55 циклов AHB для выполнения операции записи на ПЛИС (см. рис. 2).

Предполагая, что время t2 (ожидание отклика готовности от ПЛИС) занимает около 25 циклов AHB, системе требуется приблизительно 85 циклов AHB на выполнение операции чтения данных от ПЛИС (см. рис. 3).

Интерфейс со стороны МК устроен достаточно просто. Однако в ПЛИС должна быть реализована специальная логика для декодирования всего трафика, поступающего с PIO. В большинстве случаев трафик от микроконтроллера полностью асинхронный. По этой причине ПЛИС должна быть в состоянии выполнить передискретизацию сигналов управления от МК, иначе она пропустит временное окно, и данные не поступят адресату внутри ПЛИС.
Поскольку именно процессор отвечает за занятость PIO, время обработки используется нерационально. До тех пор пока центральный процессор занят передачей данных, он не может выполнять другие операции. Таким образом, это решение усложняет обработку данных в системе. Метод прямого доступа к памяти (ПДП) не имеет возможности использовать интерфейс PIO, поэтому разработчик ПО должен ограничить ширину полосы данных, чтобы учесть другую канал связи с МК. Например, если подпрограмма требует 100% циклов процессоров, выполняемых параллельно с последовательной передачей (SPI, USART или TWI) данных в или от ПЛИС, один из этих двух процессов должен находиться в состоянии ожидания. Если данные, поступающие в или от ПЛИС, не буферизуются вовремя, возникает переполнение к моменту поступления следующей порции байтов. По сути, встроенный процессор становится устройством по перемещению данных.
Заключение
В целом, компилятор Uzh представляется легким и удобным инструментарием для разработки программного обеспечения для софт-процессоров. Является прекрасной альтернативой ассемблеру, по крайней мере, в плане удобства работы программисту. Инструментарий определения примитивов и макросов как функций целевого языка позволяет критичные места реализовывать на ассемблере процессора. Для процессоров стековой архитектуры процедура адаптации компилятора не является слишком сложной и долгой. Можно сказать, что это как раз тот случай, когда наличие исходных текстов компилятора помогает – изменяются ключевые участки компилятора.
Результаты синтеза процессора (разрядность 32 бита, 4К-слов памяти программ и 1К ОЗУ) для FPGA Altera серии Cyclone V дает следующее:
Каким образом повысить количество российских инженеров, которые были бы знакомы и с разработкой хардвера, и с разработкой софтвера, и могли бы строить системы, в которых часть функциональности находится в специализированном железе, а часть — в программном обеспечении, с соблюдением баланса между ними?
Для этого вовсе не обязательно выбрасывать несуразные деньги а-ля сделка Сколкова и MIT.
Есть масса дешевых и эффективных мер по апгрейду российской образовательной системы. Одна из них — широко ввести практические классы ПЛИС / ППВМ / FPGA среди старших школьников и студентов. Это то, на чем учатся и инженеры, которые потом разрабатывают микросхемы внутри Apple iPhone в Купертино, Калифорния.
ПЛИС — Программируемая логическая интегральная схема
ППВМ — Программируемая пользователем вентильная матрица
FPGA — Field Programmable Gate Array

Так как ниже речь идет о платах, то у многих читателей тут же может возникнуть реакиция «а, это ардуино/raspberry pi/роботы — знаем!» Нет, это не ардуино, не имеет вообще никакого отношения к данному классу устройств. Еще раз повторяю: это не ардуино, потому что у ардуин стоит внутри основанный на микропроцессорном ядре микроконтроллер, а тут вообще никакого процессора нет — чистая матрица перепрограммируемых логических ячеек.
Пока американские школьники будут играться только с микроконтроллерами, российские школьники могут играться одновременно и с микроконтроллерами, и с FPGA, и тем самым получат технологическое преимущество за счет системного мышления — понимания и программирования, и принципов разработки хардверной логики одновременно.
Одной из проблем использования FPGA для образования российских тинейджеров является нехватка литературы на русском языке. Довольно скоро должен выйти русский перевод книжки Digital Design and Computer Architecture, Second Edition, by David Harris and Sarah Harris, и эта проблема будет частично решена. Но помимо литературы, описывающей схемотехнику и разработку хардвера на уровне регистровых обменов (Register Transfer Level — RTL) используя языки описания аппаратуры (Hardware Description Languages — HDL), есть и другая проблема — для новичка работа со студенческими платами нетривиальна, а программная среда для разработки — недружелюбна.
Поэтому я решил показать по шагам, как начать работать с одной из FPGA плат, которая удобна тем, что втыкается в макетную плату и может быть использована преподавателями кружков школьников наподобие тех, которые еще с 1970-х годов начинали введение в схемотехнику через микросхемы малой степени интеграции типа К155ЛА3 (TTL 7400, CMOS 4000). Втыкаемая в макетку FPGA плата является естественным продолжением таких курсов.
Вот так учили основам цифровой логики с начала 1970-х годов:
И вот к чему он может переходить после ознакомления школьников с базовыми понятиями логического элемента, триггера и сигнала тактовой частоты. Это то же самое, но на технологии 2010-х:

Дело в том, что внутри FPGA по сути находится конструктор из тысяч логических элементов наподобие элементов в K155ЛА3, но в FPGA их можно соединять не руками с помощью проводов, а меняя содержимое специальной памяти, биты которое соединены с мультиплексорами, которые меняют логические функции ячеек FPGA и соединения между ними:

Где достать платы, софтвер для разработки и необходимые плагины, я расскажу в конце, а сейчас погрузимся непосредственно в создание простой схемы с помощью бесплатной среды разработки Xilinx ISE WebPACK:

Важно выбрать отдельную директорию для проекта и не смешивать его с вашими исходными файлами, ибо синтезатор генерирует много всяких временных файлов и вы в них можете запутаться (все их можно удалить после использования):

Вводим имя проекта. Это имя совпадает с именем главного модуля на Verilog-е (языке описания железа):

Вводим параметры FPGA: Family, Device, Package, Speed. Их нужно взять из документации по плате.


Добавляем исходные файлы на языке описания аппаратуры Verilog.
Файл top.v содержит описание схемы:
Файл cmods6.ucf содержит информацию для среды разработки о том, как связаны логические вводы и выводы главного модуля (btn_0, led_2, . ) с местонахождением (location, LOC) физических ножек микросхемы FPGA, которые именуются P8, N4 и т.д. Этот файл — урезанная версия файла для данной платы, загруженная с сайта компании Digilent (производитель плат):







Теперь нажмем на кнопку «сгенерировать файл для программирования ПЛИС». Тут есть важный момент — «программирование» — это не софтверное софтверным программированием, которое сводится к созданию последовательности команд некоего процессора. Programming File в данном случае — это содержимое памяти в ПЛИС, которое определяет логические функции и соединения ячеек ПЛИС. Процессор в данной схеме не присутствует (хотя вы можете сами создать процессор, программируя (в вышеприведенном смысле) ячейки ПЛИС).

Теперь нажмем кнопку «посмотреть на абстрактную (не привязанную к конкретному FPGA) схему, описанную на верилоге и синтезированную софтвером):



Нажмем на мышкой чтобы посмотреть внутрь:

Нажмем на кнопку „Zoom to Full View“ чтобы увидеть всю схему:

А теперь посмотрим на переработанную схему, сгенерированную софтвером для конкретного FPGA (View Technology-Specific):


Мы видим слово LUT — это Look-Up Table — его нужно запомнить на будущее:

Теперь нажмем на кнопку „View/Edit Routed Design (FPGA Editor)“, чтобы посмотреть, как схема ляжет на ячейки FPGA:






Жмем кнопку чтобы сконфигурировать FPGA. Плата прицеплена микро-USB кабелем к компьютеру.
У Digilent-а есть еще софтвер под названием Digilent Adept, но он на моем компьютере с этой платой почему-то не работает, так что лучше использовать плагин и iMPACT. Последовательность действий ниже понимать не обязательно, это просто „магические заклинания“, чтобы перенести *.bit файл в конфигурационную память внутри FPGA:












Все, теперь плата должна работать — откликаться на нажатия кнопок и соответственно им мигать лампочками.
Теперь не будем закрывать iMPACT, вернемся к главному окну ISE и построим не комбинационную, а последовательностную схему — сдвиговый регистр. Используем генератор тактового сигнала низкой частоты 1 Hz, т.е. один раз в секунду. На плате еще есть генератор тактового сигнала на 8 MHz — это частоту с помощью PLL можно поднять до 200 MHz. Но высокая частота — это других дизайнов, а для наглядности 1 Hz — то что надо:

Засинтезируем ее, сгенерим bit-файл, вернемся в iMPACT и нажмем на кнопку Program. Оно скажет:

Нужно нажать Yes и в FPGA будет загружен новый дизайн. Кстати, теоретически повторная (после создания iMPACT project) загрузка должна происходить просто нажатием Configure Target Device в главном окне ISE, но реально у меня это не происходит — софтвер норовит создать новый iMPACT project. Поэтому и лучше использовать кнопку Program внутри окна iMPACT. Все претензии по этому поводу — в Digilent и Xilinx.
Приложение A. Два видео — как реализовать сдвиговый регистр и счетчик
Приложение B. Полный заголовок верхнего модуля на верилоге для данной платы
Со всеми соединениями и комментариями:
Приложение C. Где взять платы
Платы с Xilinx FPGA можно брать на сайте Digilent, сейчас это отделение National Instruments. Вот плата Digilent Cmod S6, которую я использовал в посте, с самым небольшим Xilinx Spartan-6 FPGA:

Для последующего обучения есть например платы Nexys 4 с более мощными FPGA Xilinx Artix-7. На них не нужно скручивать провода на макетной плате, так как эта стадия обучения уже пройдена:

Про платы с Altera FPGA я напишу другой пост.
Приложение D. Где взять софтвер Xilinx ISE
Его можно загрузить прямо с сайта Xilinx. Использовать можно бесплатную версию. Но для Spartan-6 нужно использовать не самую новую версию среды разработки Xilinx Vivado 2014.4, а Xilinx ISE 14.7 2013 года. Почему не Vivado? Маркетологи в Xilinx решили пересадить всех пользователей чипов Spartan на более новые FPGA Artix, и выключили поддержку для Spartan из нового софтвера. Вот только плат, которые можно вставлять в макетную плату, на Artix еще нет. Поэтому нужно использовать версию софтвера 2013 года:

А вот софтвер Xilinx Vivado который подерживает в частности плату Nexys 4 с Xilinx Artix-7 (для платы со Spartan-6 он не нужен):

Теперь важный момент. Для того, чтобы загружать .bit-файл в конфигурационную память FPGA на плате, необходимо скачать специальный плагин с сайта Digilent:


На сайте еще есть софтвер Digilent Adept, но я его не рекомендую для Spartan-6, у меня были с ним проблемы.
Приложение E. Немного табличек с параметрами FPGA



И в заключение еще одна фотка FPGA платы на макетной плате с кнопками, резисторами и семисегментным индикатором:
В половине всех разработок встраиваемых систем ПЛИС соседствует с микроконтроллером (МК). В таких схемах ПЛИС имеют различное функциональное назначение, начиная с интерфейсных логических схем и заканчивая заказными СФ-блоками и ускорителями для алгоритмов с большим объемом вычислений. Беря на себя некоторые задачи по обработке данных, ПЛИС повышают производительность системы, освобождая МК от работы с большим количеством циклов. ПЛИС также обеспечивают превосходные рабочие характеристики и гибкость, соответствуя изменяющимся стандартам.
Существуют две базовые реализации проектов МК+ПЛИС. В первой из них программное ядро МК помещается в логическую структуру ПЛИС, а во второй стандартный МК используется с дискретной ПЛИС. Применение программного ядра в ПЛИС может оказаться эффективным, но дорогостоящим и энергозатратным методом по сравнению с использованием стандартного МК, например, с 32-разрядным ARM-ядром. В результате только 1/3 проектов ПЛИС+МК осуществляется с установленным внутри логики ПЛИС ядром МК. Оставшиеся 2/3 разработок используют стандартный МК по соседству с дискретной ПЛИС.
Следует заметить, что ни стандартные МК, ни ПЛИС не создавались в расчете на эффективное взаимодействие друг с другом. Они даже используют разные языки. По этой причине вопрос обеспечения интерфейса между ними может оказаться непростым. ПЛИС не имеют специализированной логической схемы для установления связи с МК. Этот блок логики требуется создать с нуля. Во-вторых, связь между микроконтроллером и ПЛИС асинхронна. Особое внимание требуется уделить тому, чтобы повторно синхронизировать МК с тактовым генератором ПЛИС. Наконец, имеется проблема ограничений как на интерфейсной, так и на шине микроконтроллера. Передача информации между МК и ПЛИС обычно занимает несколько циклов МК и отнимает ресурс (PIO или EBI), используемый для эффективной передачи данных. При этом следует избегать ограничений со стороны внешней SRAM- или флэш-памяти, а также на шине МК.
Для обеспечения интерфейса между ПЛИС и МК используются три аппаратные опции: блок программируемого ввода-вывода (PIO); интерфейс внешней шины (EBI) и специализированный встроенный в МК интерфейс между расширенной высокоскоростной шиной (AHB — Advanced High-Speed Bus) и ПЛИС. Выбор того или иного метода зависит от конечного приложения и поставленной задачей.
Заключение
Мы рассмотрели лишь малую часть того, что есть в современных ПЛИС. Но даже после такого короткого обзора думаю вам стало интересно, что же еще есть внутри FPGA и как это применить в ваших проектах. Многое осталось за кадром, но если вам понравился такой формат, и вы хотите более детальные обзоры аппаратных ресурсов и может даже демонстрации примеров работы с ними, то оставляйте ваши пожелания в комментариях.
Логическая схема интерфейса ПЛИС
При реализации интерфейса ПЛИС с помощью EBI или PIO инженер должен записывать RTL-код, позволяющий ПЛИС сообщаться с МК. Поставщики МК с прямым интерфейсом ПЛИС обеспечивают все коды RTL для кодирования и декодирования связи с соответствующими ограничениями для каждой ПЛИС того или иного производителя. Этот блок логики производит возврат в исходное состояние и обеспечивает в нем требуемые режимы. RTL-коды поставщика позволяют выбрать определенную функциональность. По умолчанию все биты режима являются нулями (см. табл. 1).
ПЛИС – программируемые логические интегральные схемы.
Часто в роликах на ютубе или в различных статьях о том «Что же такое ПЛИС?» приводят одну и ту же концепцию ее построения, то есть ПЛИС изображают как набор конфигурируемых логических блоков, соединенных между собой матрицей соединений или интерконнектами.
С одной стороны это верно, именно так и устроены самые простые представители программируемых логических микросхем, но сегодня ПЛИС – это нечто более сложное и в рамках этой статьи мы разберемся из чего же на самом деле состоят современные FPGA.
Что возникает в Вашей голове, когда вам говорят про ПЛИС? Наиболее вероятно, что на ум приходит примерно вот такая картинка (рисунок 1), где схематично изображено упрощенное представление конфигурируемого логического блока: его комбинационной части, состоящей из N-входного Look Up Table или таблиц истинности и мультиплексора и синхронной части, в качестве которой обычно выступает D-триггер.
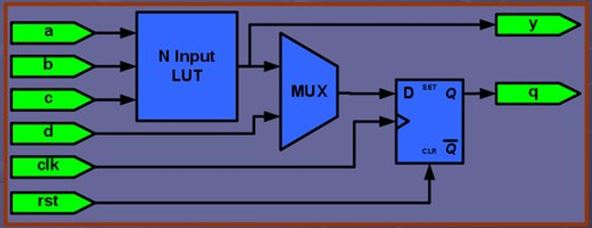
Рисунок 1. Типичное представление структуры логических блоков ПЛИС
Не исключено, что возникает и вот такое укрупненное представление (рисунок 2), на котором конфигурируемые логические блоки соединяются между собой с помощью интерконнектов и по краям находятся порты ввода-вывода нашей микросхемы.
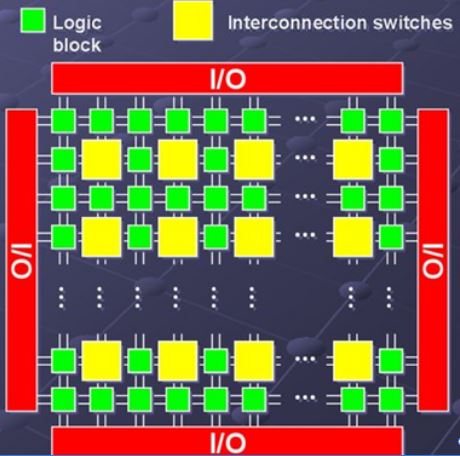
Рисунок 2. Типичное представление архитектуры ПЛИС
Небольшое лирическое отступление: конфигурируемый логический блок – это основной логический ресурс, предназначенный для реализации последовательных (синхронных), а также комбинаторных схем. Каждый конфигурируемый логический блок соединен с матрицей коммутаторов для доступа к общей матрице маршрутизации. Но об этом чуть позже.
Но на самом деле это лишь верхушка айсберга. Да, современные ПЛИС состоят из тысяч, сотен тысяч или даже миллионов конфигурируемых логических блоков, вот только выглядят они несколько сложнее, чем просто два квадратика одна трапеция.
Для примера построения современного конфигурируемого логического блока давайте обратимся к документации [1]. Например, для 7-го семейства ПЛИС компании Xilinx он состоит из двух секций, или slice и цепей переноса (рисунок 3). Пока как-то не впечатляет, да?
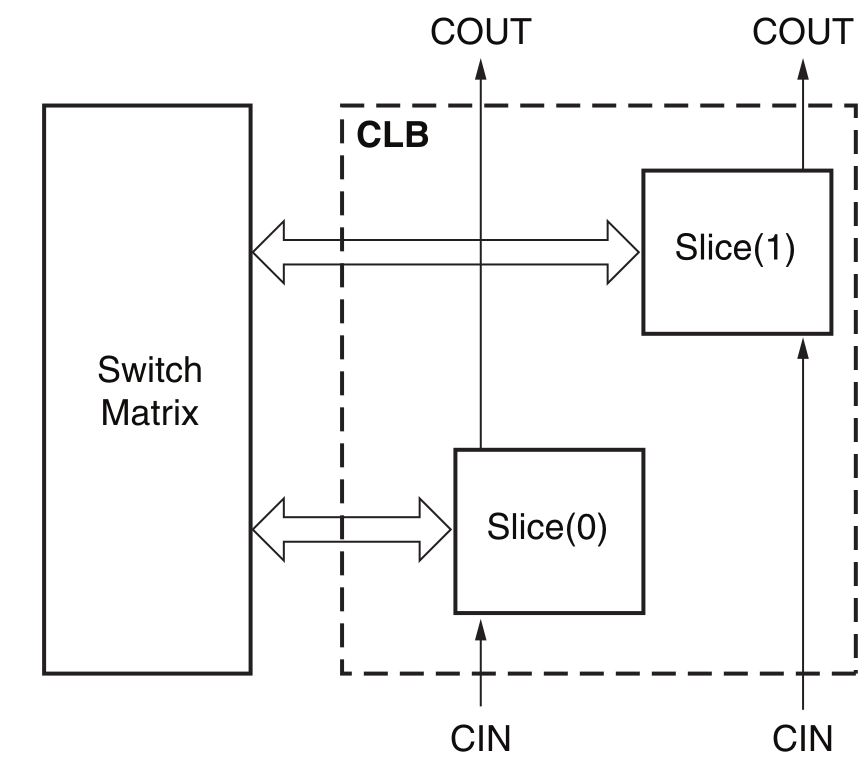
Рисунок 3. Укрупнённое представление конфигурируемого логического блока ПЛИС 7-го семейства компании Xilinx
Не спешите с выводами. Каждая из секций может быть одного из двух типов: либо SliceL либо SliceM и вот именно их архитектура для нас уже более интересна.
Типовые «хотелки»
Зачастую от софт-процессоров в данном случае не требуется сверхвысокая производительность (т.к. её проще добиться, использую логические и аппаратные ресурсы ПЛИС). Они могут быть достаточно простыми (а с точки зрения современных микроконтроллеров – почти примитивными), т.к. они могут обойтись без сложной системы прерываний, работать только с определенными узлами или интерфейсами, нет необходимости поддерживать ту или иную систему команд. Их может быть много, при этом каждый из них может выполнять только определенный набор алгоритмов или подпрограмм. Разрядность софт-процессоров также может быть любой, в том числе не кратной байту – в зависимости от требований текущей задачи.
Типовыми целевыми показателями для софт-процессоров являются:
- достаточная функциональность системы команд, возможно оптимизированная под задачу;
- высокая плотность программного кода, т.к. это позволит экономить ресурсы памяти ПЛИС;
- компактность – не хотелось бы, чтобы вспомогательные элементы занимали дефицитные ресурсы программируемой логики.
Небольшие, «почти» ничего не значащие нюансы
Исходный код процессора Zmey не является открытым, но доступно описание принципов его работы и некоторых особенностей архитектуры. Хотя он и является также стековым, есть ряд ключевых отличий от процессора whiteTiger:
- стеки являются программными – т.е. представлены указателями и размещаются в памяти данных по разным адресам;
- в систему команд введен ряд команд, оптимизирующих процессор для выполнения кода С-подобных ЯВУ;
- отличаются способы загрузки и представления чисел и констант в памяти программ;
- процессор является многопоточным, но в контексте данной работы это не является существенным.
Для установки компилятора Uzh достаточно скачать его архив и распаковать в любую удобную папку (лучше придерживаться общих рекомендаций для специализированного программного обеспечения – избегать путей, содержащих кириллицу и пробелы). Также необходимо скачать и распаковать в основную папку компилятора инструментарий raddsl.
Папка test компилятора содержит примеры программ для софт-процессора, папка src – исходные тексты элементов компилятора. Для удобства работы лучше создать небольшой командный файл (расширение .cmd) с содержимым: c.py C:\D\My_Docs\Documents\uzh-master\tests\abc.py , где abc.py – имя файла с программой для софт-процессора.
2.3. Ячейки памяти
Мы уже упоминали, что часть секций могут быть использованы для хранения информации и могут выступать в качестве распределенной памяти. Почему распределенной? Такая память привязана к расположению конфигурируемых логических блоков и как бы равномерно распределена по всему кристаллу (рисунок 6).
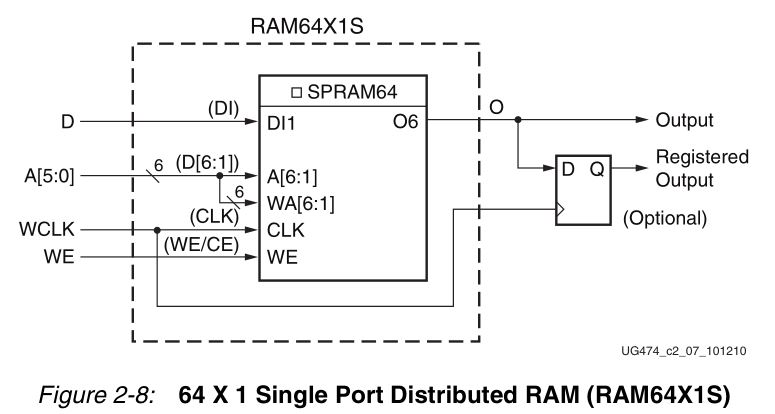
Рисунок 6. Ячейка распределенной памяти
К сожалению, хранить большой объем информации в такой памяти не представляется возможным. Для решения этой проблемы в ПЛИС имеется специальный ресурс – блочная память – которая представляет собой аппаратный блок [2], в котором можно хранить значительно больше информации, нежели в распределенной памяти.
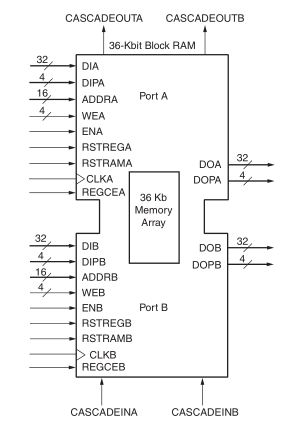
Рисунок 7. Ячейка блочной памяти
Объем блочной памяти, ее функциональность и количество доступных компонентов зависит как от производителя ПЛИС, так и от семейства ПЛИС. Блочная память может быть размером 9кб, 18кб, 36кб или даже 288кб.
Она может быть сконфигурирована различными способами, может быть каскадирована (рисунок 8, а), иметь различную разрядность для записи и чтения, иметь разные управляющие сигналы. Память может иметь один или два порта для выполнения независимых операций записи/чтения по обоим портам, т. н. true-dual port ram, использоваться в качестве FIFO (рисунок 8, б) - специального элемента для синхронизации тактовых доменов и многое другое.
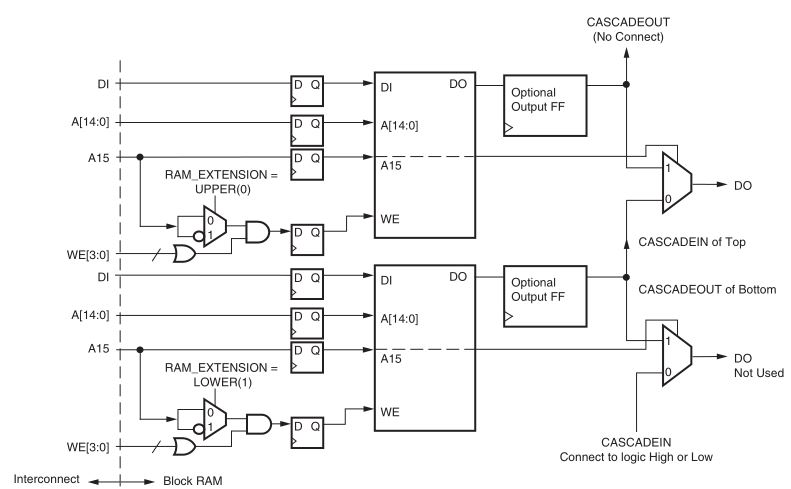 | 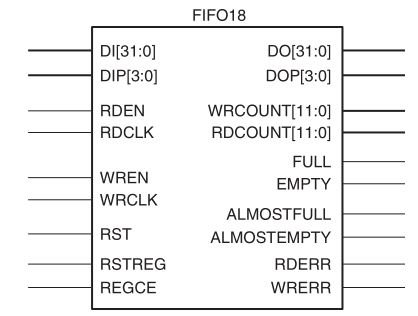 |
| а) | б) |
Рисунок 8. Использование блочной памяти: а – каскадирование, б - FIFO
Часто для настройки и управления режимами работы используются специальный мастер настроек или wizard (рисунок 9)– где с помощью графического интерфейса пользователь задает все необходимые параметр памяти.
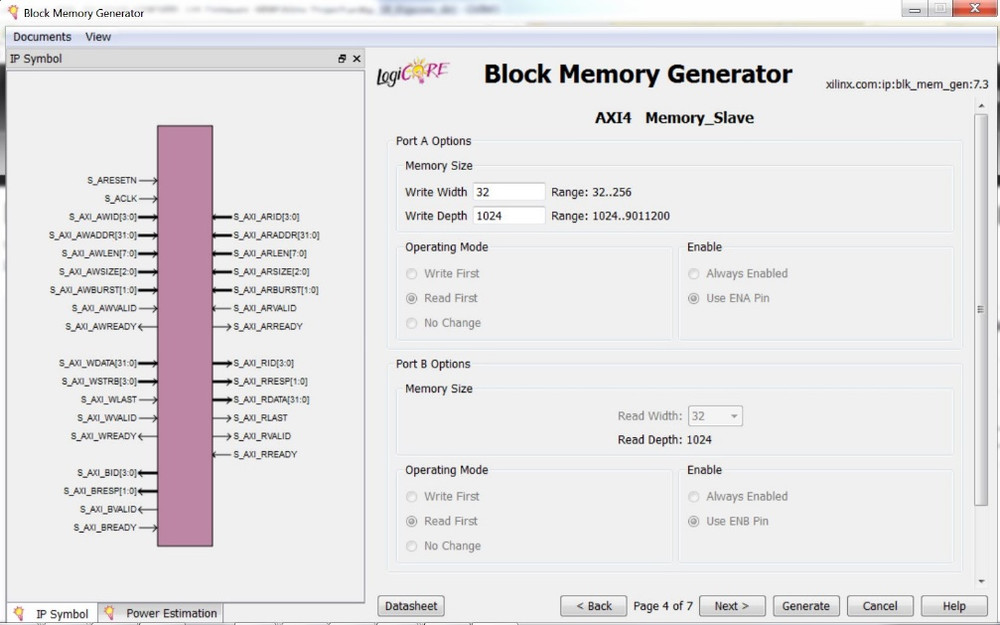
Рисунок 9. Пример мастера настройки (wizard) блочной памяти
Специализированный интерфейса ПЛИС на МК
Микроконтроллеры с ядром ARM7 имеют специализированный интерфейс, который позволяет ПЛИС получать прямой доступ к внутренней AHB-шине МК с ПДП через два ведущих AHB-устройства и четыре ведомых AHB-устройства. Одно дополнительное ведомое AHB-устройство можно использовать для перераспределения памяти ПЗУ с помощью технологии внешней памяти ZBT RAM (RAM с нулевым временем переключения) через ПЛИС с программируемой функцией перераспределения ПЗУ при запуске.
Этот интерфейс также обеспечивает ПЛИС доступ к 14 ведомым устройствам с шинами APB (Advanced Peripheral Bus), двум полнодуплексным каналам ПДП, а также обеспечивает до 13 кодированных прерываний с установкой приоритетов (IRQ), два некодируемых IRQ для передачи данных с ПДП и программируемые 32-бит вводы-выводы для совместного пользования. Интерфейс ПЛИС получает доступ к AHB-шине, предварительно установив МК в режим ведущего или ведомого устройства (см. рис. 7).

Интерфейс ПЛИС основан на нескольких параллельно-последовательных преобразователях, которые кодируют и декодируют весь трафик между МК и ПЛИС. Для того чтобы установить связь и синхронизацию между обоими устройствами, необходимо соблюсти следующие требования.
ПЛИС должна компенсировать рассогласование тактовых частот и устранять задержку. В семействах ПЛИС компании Xilinx использование менеджера DCM (Digital Clock Manager) обязательно, чтобы устранять задержку и управлять генерацией требуемых тактовых сигналов. Устройства компании Altera требуют ФАПЧ. ПЛИС должна также обеспечивать режимы конфигурирования и сброс встроенного интерфейса МК. ПЛИС должна также обеспечить тактовый сигнал последовательной связи с МК, частота которого может достигать 100 МГц для коммерческих устройств. Соотношение между внутренним тактовым сигналом и синхросигналом в линии синхронизации должно быть около 0,8 или ниже (ARM Clk/Serial Clk).
Основу интерфейса ПЛИС составляет ряд модулей, которые кодируют и декодируют внутренние AHB-транзакции. Кодированные и декодированные данные передаются через MPIO с помощью специализированных параллельно-последовательных преобразователей каждого ведущего и ведомого устройств. Из-за большого количества передаваемых бит на одну отправку данных требуется несколько циклов синхронизации AHB-шины. Количество этих циклов зависит от соотношения между частотами тактового сигнала AHB-шины в ARM7, синхросигнала в линии синхронизации и тактового сигнала AHB-шины в ПЛИС. Поскольку частота тактового сигнала AHB-шины микроконтроллера не зависит от частоты тактового сигнала AHB-шины в ПЛИС, МК и ПЛИС могут работать на разных частотах. Даже ведущие и ведомые устройства внутри ПЛИС могут работать на различных частотах.
Каждый блок параллельно-последовательного преобразователя на МК и ПЛИС имеет дополнительный конечный автомат, который сообщается с шиной AHB. Таким образом, этот интерфейс может управлять одновременными передачами с любой стороны, что устраняет ограничения, в отличие от использования таких топологий как EBI или PIO.
Микроконтроллеры с прямым интерфейсом ПЛИС также имеют каналы ПДП почти на каждом периферийном устройстве, причем несколько ПДП-каналов выделено под интерфейс ПЛИС. ПДП-каналы поддерживаются многоканальным периферийным ПДП-контроллером (Peripheral DMA Controller — PDC), который освобождает ЦП от передачи данных между ПЛИС, периферией и памятью, как и в предыдущих методах. Это позволяет избежать ограничений на ширину полосы стандартного ядра ARM7, которая в ряде случае полностью монополизируется передачей данных со скоростью всего 4 Мбит/c.
Разгружая ЦП, PDC-контроллер обеспечивает скорость передачи данных до 12 Мбит/с. При этом 85% циклов блока ЦП доступны для обработки. Несколько ПДП-каналов выделяются под интерфейс ПЛИС для связи периферийных устройств (в зависимости от приложения) и интерфейсов с PDC без вмешательства со стороны МК. Применение выделенных ПДП-каналов в PDC освобождает ARM-процессор для выполнения ресурсоемких задач и увеличивает общую производительность системы наряду с шириной полосы передачи данных (см. рис. 8).

Модуль параллельно-последовательного преобразователя управляет всеми шинами AHB и последовательными каналами связи. Он состоит из конечного автомата и сдвигового регистра. Конечный автомат распознает шину и устанавливает с ней связь. Если ведущее устройство начинает передачу данных (операции чтения/записи), конечный автомат входит в состояние ожидания с помощью HREADY в соответствии с протоколом AHB. Конечный автомат управляет количеством введенных циклов ожидания на основе соотношения между частотами тактовых сигналов AHB и синхросигнала в линии синхронизации. Чем меньше это соотношение, тем меньше количество вводимых циклов ожидания.
Конечный автомат управляет сдвиговым регистром, который управляет всеми перемещаемыми данными между МК и ПЛИС, передавая данные по два бита на цикл. Если скорость синхросигнала в линии синхронизации установлена равной 100 МГц, скорость передачи сдвигового регистра составляет 200 Мбит/с.
Модули параллельно-последовательного преобразователя, которые управляют ведущими устройствами A/B, ведомыми устройствами A/B и C/D, программируются при сбросе с помощью модуля режимов в ПЛИС, чтобы максимально увеличить количество доступных портов ввода-вывода. Разработчик может пользоваться всеми десятью линиями ввода-вывода в единичной последовательной конфигурации, при этом последовательный модуль станет управлять только одним AHB-интерфейсом. Например, если пользователю требуется только ведущее AHB-устройство А, последовательный модуль, управляющий ведущими устройствами, конфигурируется в единичной последовательной конфигурации. Она оптимизирует количество передаваемых бит между сдвиговыми регистрами, ускоряя посылку транзакций между МК и ПЛИС (см. рис. 9).

Другой возможностью является конфигурирование последовательного модуля для управления двумя AHB-интерфейсами в последовательной спаренной конфигурации, в которой 10 линий ввода-вывода коллективно используются между двумя AHB (ведущие/ведомые устройства). В этом случае скорость передачи данных между МК и ПЛИС ниже, но ширина полосы больше, т.к. задействованы два AHB-интерфейса. Спаренная конфигурация повторно использует половину выделенных портов ввода-вывода для другого AHB-интерфейса (см. рис. 10).

2.7. Что еще?
Помимо основных типов ресурсов: конфигурируемых логических блоков, блочной памяти, DSP секций, тактовой сети, портовой логики которые есть практически в любой ПЛИС в нее также могут быть интегрированы и специальные аппаратные блоки, например высокоскоростные трансиверы, PCIe блоки, контроллеры внешней памяти, аналогово-цифровые преобразователи и даже процессоры. Рекомендуем посмотреть заметку [6].
ПЛИС – это изначально универсальное устройство, на котором можно сделать абсолютно любые задачи: вы даже можете реализовать свой процессор на плис или развернуть готовый, запустить на нем линукс или другую ОС, обрабатывать 100/400/600Гбитные потоки данных, коммутировать десятки 10Гбитных каналов, выполнять обработку сигналов, видео, разворачивать нейронные сети, ускорять обработку баз данных, и многое многое другое, все что только можно себе вообразить.
2.6. Порты ввода вывода
Связать ядро ПЛИС с внешним миром мы можем с помощью портов ввода вывода, которые так же не просты, как и сама ПЛИС [5].
Порты ввода вывода современных плис поддерживают просто огромное количество стандартов напряжения.
Но помимо простых выходных буферов, дифференциальных буферов и буферов с третьим состоянием, в портах ввода – вывода плис есть еще очень много разнообразных ресурсов, таких как:
- • Серилайзеры и десерилайзеры, преобразующие вектор данных в поток данных и наоборот
- • Блоки цифрового контроля импеданса DCI для достижения хорошей целостности сигнала
- • SDR и DDR триггеры для работы с различными типами памяти и интерфейсами
- • Различные типы задержек для компенсации неодинаковости линий на печатной плате
- • Свои собственные PLL для более точной подстройки блоков данных, относительно стробирующих или тактовых сигналов, например при работе с высокосортной памятью или АЦП/ЦАП
- • Собственные FIFO для компенсаций разности фаз между внешними сигналами и внутренней логикой ПЛИС

Рисунок 13. Укрупнённое представление структуры портов ввода/вывода
Введение
Во многих случаях при реализации измерительных приборов, научно-исследовательского оборудования в качестве основного ядра системы предпочтительнее применять реконфигурируемые решения на базе ПЛИС/FPGA. Данный подход имеет множество преимуществ, благодаря возможности легкого и быстрого внесения изменений в логику работы, а также за счет аппаратного ускорения операций обработки данных и сигналов управления.
Для широкого круга задач, таких, как цифровая обработка сигналов, встраиваемые системы управления, системы сбора и анализа данных, хорошо зарекомендовал себя подход, заключающийся в сочетании в одном решении блоков, реализуемых логикой ПЛИС для критических процессов, и элементов программного управления на основе одного или нескольких софт-процессоров для общего управления и координации, а также для реализации взаимодействия с пользователем или внешними устройствами/узлами. Применение софт-процессоров в данном случае позволяет несколько снизить временные затраты на отладку и верификацию алгоритмов управления системой или алгоритмов взаимодействия отдельных узлов.
Тестирование
Небольшая тестовая высокоуровневая программа для нашего процессора содержит определение функции для вычисления факториала, и основную функцию, реализующую последовательный вывод значений факториала от 1 до 7 в порт в бесконечном цикле.
Запуск её на компиляцию можно произвести, например, простым скриптом или из командной строки последовательностью:
c.py C:\D\My_Docs\Documents\uzh-master\tests\fact2.py
В результате будет сформирован загрузочный файл stream.bin, который можно передавать процессорному ядру в ПЛИС через последовательный порт (в современных реалиях через любой виртуальный последовательный порт, который предоставляют преобразователи интерфейсов USB-UART). Программа в итоге занимает 146 слов (9-битных) памяти программ и 3 в памяти данных.
Змея, кусающая себя за хвост или притирка железа и софта
Для адаптации Uzh-а к процессору whiteTiger потребуются некоторые изменения, также как и немного придется подкорректировать и сам процессор.
К счастью, мест, подлежащих корректировке в компиляторе не много. Основные «аппаратно-зависимые» файлы:
- asm.py – ассемблер и формирование чисел (литералов);
- gen.py – низкоуровневые правила формирования кода (функции, переменные, переходы и условия);
- stream.py – формирование загрузочного потока;
- macro.py – макроопределения, по факту – расширения базового языка аппаратно-специфичными функциями.
- по приему определенного управляющего байта загрузчик выставляет активный уровень на внутренней линии сброса процессора;
- по второй байтовой команде сбрасывается счетчик адреса памяти;
- далее следует последовательность тетрад передаваемого слова, начиная с младшей, комбинированные с тетрадой-номером ;
- после каждого байта с упакованной тетрадой следует пара управляющих байт первый из которых устанавливает активный уровень на линии разрешения записи памяти, второй сбрасывает его;
- по завершении последовательности упакованных тетрад управляющим байтом снимается активный уровень на линии сброса.
Поскольку память данных задействована в логике работы процессорного ядра, необходимо мультиплексировать её линии данных и управления. Для этого вводятся дополнительные сигналы DataDinBtemp, LoaderAddrB, DataWeBtemp – данные, адрес и разрешение записи для порта В памяти.
Код загрузчика теперь выглядит так:
При активном уровне сброса сигналы DataDinBtemp, LoaderAddrB, DataWeBtemp подключаются к соответствующим портам памяти данных.
В соответствии с алгоритмом работы загрузчика необходимо модифицировать модуль stream.py. Сейчас в нем две функции. Первая функция — get_val() — разбивает входное слова на нужное количество тетрад. Так, для 9-битных команд процессора whiteTiger они будут транформированы в группы по три тетрады, а 32-битные данные – в последовательности из восьми тетрад. Вторая функция make() формирует непосредственно загрузочный поток.
Финальный вид модуля stream:
Следующие изменения в компиляторе коснутся модуля asm.py в котором описывается система команд процессора (прописываются мнемоники команд и опкоды команд) и способ представления/компиляции числовых значений – литералов.
Если старший (9-ый) бит слова равен 1, то опкод интерпретируется как число – так, к примеру, четыре идущих подряд опкода с признаком числа формируют в итоге 32-битной число. Признаком окончания числа является наличие опкода команды – для определенности и обеспечения единообразия окончанием определения числа служит опкод команды NOP («нет операций»).
В итоге модифицированная функция lit() выглядит так:
Основные и самые ответственные изменения/определения – в модуле gen.py. Данный модуль определяет основную логику работы/исполнения высокоуровневого кода на уровне ассемблера:
- условные и безусловные переходы;
- вызов функций и передача им аргументов;
- возврат из функций и возвращение результатов;
- подстройки под размеры памяти программ, памяти данных и стеков;
- последовательность действий при старте процессора.
В процессоре Zmey для работы с локальными переменными и аргументами функций используется стек возвратов – аргументы функции переносятся на него и при дальнейшей работе к ним идет обращение через регистр-указатель стека возвратов (чтение, модификация в сторону увеличения/уменьшения, чтение по адресу указателя). Поскольку стек физически располагается в памяти данных, то такие операции по сути просто сводятся к операциям с памятью, в пределах этой же памяти располагаются и глобальные переменные.
В whiteTiger стеки возвратов и данных являются выделенными аппаратными стеками со своим адресным пространством и не имеет команд работы с указателями стеков. Следовательно, операции с передачей аргументов функциям и работу с локальными переменными необходимо будет организовывать через память данных. Увеличивать объемы стеков данных и возвратов для возможного хранения в них относительно больших массивов данных не имеет большого смысла, логичнее иметь несколько большую память данных.
Для работы с локальными переменными был добавлен выделенный регистр LocalReg, задача которого – хранить указатель на область памяти, отведенную для локальных переменных (своего рода heap). Добавлены также операции для работы с ним (файл cpu.vhd – область определения команд):
LOCAL – возвращает на стек данных текущее значение указателя LocalReg;
SETLOCAL – устанавливает новое значение указателя, принятое со стека данных;
LOCALadd – оставляет на стеке данных текущее значение указателя и увеличивает его на 1;
LOCALsubb — оставляет на стеке данных текущее значение указателя и уменьшает его на 1.
LOCALadd и LOCALsubb добавлены для уменьшения количества тактов при операциях передачи параметров функции и наоборот.
В отличие от оригинального whiteTiger немного были изменены подключения памяти данных – теперь порт В памяти постоянно адресуется выходом первой ячейки стека данных, на его вход подается выход второй ячейки стека данных:
Логика выполнения команд STORE и FETCH также немного подкорректировалась – FETCH принимает на вершину стека данных выходное значение порта В памяти, а STORE просто управляет сигналом разрешения записи порта В:
В рамках тренировки, а также для некоторой аппаратной поддержки циклов на низком уровне (и на уровне компилятора языка Форт) к ядру whiteTiger был добавлен стек счетчиков циклов (действия аналогичные, как при объявлении стеков данных и возвратов):
Были добавлены команды организации циклов со счетчиком.
DO – перемещающая число итераций цикла со стека данных на стек счетчиков и помещающая на стек возвратов инкрементированное на единицу значение счетчика команд.
LOOP – проверяет обнуление счетчика, если не достигнуто, верхний элемент стека счетчиков декрементируется, осуществляется переход по адресу на вершине стека возвратов. Если вершина стека счетчиков равна нулю, верхний элемент сбрасывается, сбрасывается также адрес возврата на начало цикла с вершины стека возвратов.
Теперь можно приступить к модификации кода модуля gen.py.
Переменные *_SIZE в комментариях не нуждаются и требуют только подстановки значений, заданных в проекте процессорного ядра.
Список STUB – временная заглушка для формирования места для адресов переходов с последующим их заполнением компилятором (текущие значения соответствуют 24-битному адресному пространству памяти кода).
Список STARTUP – задает последовательность действий, выполняемых ядром после сброса – в данном случае будет задан начальный адрес памяти локальных переменных – 900, и переход на точку старта (если ничего не менять, точка старта/входа в приложение прописывается компиляторов в ячейку памяти данных с адресом 2):
Определение func() прописывает действия, производимые при вызове функции, а именно – перенос аргументов функции в область локальных переменных, выделение памяти для собственных локальных переменных функции.
Epilog() определяет действия при возвращении из функции – освобождение памяти временных переменных, возврат на точку вызова.
Работа с переменными идет посредством их адресов, ключевое определение для этого – push_local(), оставляющее на стеке данных адрес «высокоуровневой» переменной.
Следующие ключевые моменты – это условный и безусловный переходы. Условный переход в процессоре whiteTiger проверяет на 0 второй элемент стека данных и переходит по адресу на вершине стека, если условие выполняется. Безусловный переход просто устанавливает значение счетчика команд равному значению на вершине стека.
Следующие два определения задают операции битового сдвига – как раз на низком уровне применены циклы (даст некоторый выигрыш в размере кода – оригинале компилятор просто помещает подряд требуемое количество элементарных операций сдвига.
И основное определение компилятора на низком уровне – набор правил для операций языка и работы с памятью:
Модуль macro.py позволяет несколько «расширить» словарь целевого языка за счет макроопределений на ассемблере целевого процессора. Для компилятора ЯВУ определения в macro.py не будут отличаться от «родных» операторов и функций языка. Так, к примеру, в оригинальном компиляторе были определены функции ввода-вывода значения во внешний порт. Были добавлены тестовые последовательности операций с памятью и локальными переменными и операция временной задержки.
2.4. Математические и логические векторные операции
Вы наверняка слышали, что ПЛИС часто применяются в решении задач цифровой обработки сигналов.
Это стало возможным благодаря DSP ячейкам или DSP секциям – специализированным умножителям внутри ПЛИС [3]. Современные ПЛИС могут насчитывать несколько тысяч таких секций, которые могут выполнять операции как с фиксированной точкой, с плавающей точкой, операции с комплексными числами, логические операции с векторами данных и много многое другое: опять же, это зависит от производителя и семейства плис. Давайте посмотрим, как они устроены DSP секции на примере DSP48E1
Перед вами базовая функциональная диаграмма DSP секции (рисунок 10). Она включает в себя триггеры по входу, промежуточные триггеры, триггеры по выходу, блоки арифметических и логических операций.

Рисунок 10. Базовая функциональная диаграмма DSP секции
Наверняка у вас сразу появился вопрос, а зачем нам нужны такие блоки внутри ПЛИС, мы же можем использовать обычные логические ресурсы ПЛИС для реализации того же самого сложения двух векторов или выполнения операций сравнения. Да, вы можете это сделать, но, так же, как и в случае с распределенной памятью вы потратите большое количество ресурсов для выполнения этих операций, особенно если работаете с широкими данными. Например, умножаете два 16-битных числа. Не говоря уже о максимальной частоте работы такой схемы.
Чтобы не тратить логические ресурсы ПЛИС и иметь хорошую производительность разрабатываемой системы и были интегрированы DSP секции.
Если же мы проявим чуть большей интерес к секциям DSP, то мы увидим, что они также имеют сложную внутреннюю структуру, для настройки которой также зачастую используют специальные визарды.

Рисунок 11. Более детальное представление DSP секции
Комбинирование ячеек блочной памяти и DSP секций является большим преимуществом ПЛИС и такая конфигурация очень часто находит свое применение в решении задачи цифровой обработки сигналов, где сразу несколько тысяч брамок и dsp работают одновременно, например, выполняя фильтрацию сигнала, различные частотно-временные преобразования и анализ спектра.
Читайте также: