
Megaraid storage manager замена диска raid 5
Довелось понастраивать сервер DELL T610 с рейд контроллером PERC H700 на борту. Все как обычно, кроме одного нюанса. Решил проверить, как оперативно выполнить замену сбойного диска. На сервер была установлена стандартная утилита mеgacli для управления всеми контроллерами с драйвером MegaRAID, к коим относится и упомянутый выше. Такая тривиальная задача оказалась не совсем тривиальной и пришлось поковыряться с документацией.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужно пройти вступительный теcт.
У меня был сервер на Debian 8 с 3 рейдами, raid1, raid1, raid10. Я вытаскивал диск из raid10 и заменял его новым.
Обращаю внимание, это важно. Я вставлял обратно не тот же самый диск, как часто делают, а другой. Это принципиально разные события. Если вынуть диск, а потом его же поставить на место, то ребилд пойдет автоматом и делать ничего дополнительно не надо. Если же вы другой физический диск ставите, то нужно будет проделать все то, что я сейчас опишу.
Сначала проверим состояние наших массивов:
Чувствуете хардкор? Еще нет? Тогда поехали дальше. Обращаю внимание, что последний массив помечен как Degraded, из него вынут диск. Это raid10. К сожалению, я так и не понял, как через megacli посмотреть тип массива. Где тут указано, что в массиве raid10, я не понял. Теперь посмотрим на список дисков:
Нас интересует последний диск. В Firmware state указано Unconfigured(good). Это я уже воткнул новый пустой диск, вместо старого. Если с диском будут какие-то проблемы, то его состояние будет Failed. Дальше вам важно запомнить следующие значения этого диска:
- Enclosure Device ID: 32
- Slot Number: 7
- DiskGroup: 2
Первые два - ID и номер слота жесткого диска. Они нам нужны в дальнейших командах для обозначения диска. Последнее, судя по всему, принадлежность к номеру DiskGroup в описании массива. Я не уверен в этом на 100%, но в моем случае эти данные для всех дисков и массивов показывали полное совпадение. Скорее всего это так. Проверьте по этой цифре, точно ли сбойный диск принадлежит к тому массиву, о котором вы думаете.
Я немного забежал вперед и поторопился с заменой диска. Я вытащил диск, загрузил сервер, убедился, что он работает без диска и что массив понимает, что он находится в состоянии Degraded. После этого мне нужно было бы выполнить следующие команды.
Отключить сбойный диск:
Пометить его как отключенный:
Я это не сделал, а просто выключил сервер и установил новый диск. После включения убедился, что новый диск присутствует в списке дисков и его статус Unconfigured(good). После этого я указываю контроллеру, что диск заменен:
Над этой командой я долго ломал голову. Расскажу по порядку, что тут к чему.
Array3. Откуда взялась цифра 3? Вот описание:
"The number N of the Array parameter is from the "Span Reference:" line you get using MegaCli -CfgDsply -aALL, minus the 0x0 part."
Выполняем команду просмотра конфигурации:
Получается такая простыня, которую очень трудно читать и анализировать. Грепаю вывод, чтобы разобраться, что тут вообще выходит:
Вижу, что у меня 4 конфигурации, хотя массива только 3. Рассуждаю логически. Так как последний массив это RAID10, то наверно он отображается как 2 RAID1. Проверил внимательно вывод конфигурации, убедился, что так оно и есть. Первые 2 рейда обозначены как DISK GROUP: 0 и 1, а raid10 как SPANNED DISK GROUP: 0, в котором соответственно SPAN: 0 и 1. Один из SPAN имеет статус Degraded и параметр Span Reference: 0x03. Судя по документации, мне надо взять это число 0x03 и отбросить 0x0. Получается цифра 3 и параметр Array3 в команде.
Дальше следует параметр row. Я очень старался понять что это такое :) Описание:
"The number N of the row parameter is the Physical Disk in that span or array starting with zero (it can be but is not always the physical disk’s slot!)".
Только сейчас, когда пишу статью, легко понимаю, откуда берется эта цифра. А когда тестировал сильно тупил и никак не мог сообразить. Сильно мешает очень объемный вывод команд. Я устал глазами бегать по простыням. В общем, это номер диска в сбойном SPAN. В моем случае это второй диск в SPAN, то есть цифра 1, так как отсчет идет с нуля. Таким образом получился параметр row1. Еще раз напоминаю команду замены сбойного диска:
Пока мы только указали, что заменили диск. Теперь нам надо запустить его ребил:
Статус ребилда смотрим командой:
После окончания ребилда снова смотрим вывод информации по массивам и дискам. Массив должен стать Optimal, а диск Online, Spun Up. На этом забываем про megacli как страшный сон и вспоминаем про приятный и удобный mdadm.
Я всегда тестирую выход из строя жесткого диска и его замену. Делаю на всех массивах, железных и софтовых. На железных, чтобы вот таких сюрпризов не было, а была рабочая инструкция. А в софтовых, в основном, чтобы убедиться, что загрузчик стоит на всех нужных дисках и система поднимется в случае чего. По надежности и замене дисков у меня к mdadm вопросов нет. Там все понятно и просто.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу ссылке.

Всем привет сегодня расскажу ККак добавить диск в существующий RAID на контроллере LSI. Ранее я рассказывал Как создать RAID на контроллере LSI MegaRAID через утилиту MegaRAID Storage Manager, а теперь представим ситуацию, что вы хотите расширить ваш RAID, более подробно про типы рейдов в посте Виды RAID и их характеристики.
Открываем ваш MSM, как его установить описано тут. Видим у меня есть RAID5 из трех дисков, я хочу добавить к нему еще 5 дисков.

Как изменить тип рейда с RAID5 на RAID6 в контроллерах LSI-01
Щелкаем по RAID правым кликом и выбираем Modify Drive Group

Как изменить тип рейда с RAID5 на RAID6 в контроллерах LSI-02
Вас предупредят, что мол вы реально это хотите сделать ставим галку и жмем ок

Как изменить тип рейда с RAID5 на RAID6 в контроллерах LSI-03
В выпадающем списке выбираем RAID5 и жмем next

Как изменить тип рейда с RAID5 на RAID6 в контроллерах LSI-04
Выбираем диск или диски

Видим сводную информацию и жмем Finish

Как добавить диск в существующий RAID на контроллере LSI-01
На дашборде появится процесс выполнения задачи

Как изменить тип рейда с RAID5 на RAID6 в контроллерах LSI-07
Время выполнения на прямую зависит от объема RAID. У меня это время растянулось на 3 дня.

Как добавить диск в существующий RAID на контроллере LSI-02
Хочу предупредить, что во время расширения RAID контроллер будет испытывать не хилые нагрузки и может вообще встать, так что у вас затормозит диким образом все то что на нем находится Отменить данную процедуру без потери данных уже не получится
Если у вас все затормозило и работать невозможно, то расширение стоит перенести на другое время. Если все же хотите отменить расширение то придется разваливать RAID. Для этого выполните. Правым кликом по каждому из винтов в рейде и выбираем Make Drive Offline.

Как добавить диск в существующий RAID на контроллере LSI-03
Вас предупредят, что это может привести к потере данных, жмем да

Как добавить диск в существующий RAID на контроллере LSI-04
Еще раз подтверждаем

Как добавить диск в существующий RAID на контроллере LSI-05
и далее снова правым кликом выбираем Make Drive as Missing

Как добавить диск в существующий RAID на контроллере LSI-06
Подтверждаем и выводим диск из RAID.

Как добавить диск в существующий RAID на контроллере LSI-07
Вот так вот просто добавить диск в существующий RAID на контроллере LSI.
Популярные Похожие записи:
Восстановление lsi raid
Раз уж так произошло, то не спешите паниковать все еще можно восстановить. Первым делом когда вы вернули не правильно вытащенный диск обратно и он получил статус foreign, на нем осталась конфигурация и ее следует обратно импортировать. Делается это следующим образом. Вы должны были заранее установить утилиту MegaRAID Storage Manager (MSM), в моем случае она стоит на Vmware ESXI 5.5, но может быть и на Windows платформе. Заходим в нее и выбираем пункт Physical и выбираете raid контроллер.
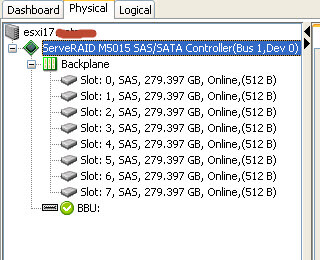
Теперь открываем пункт Go to > Scan Foreign Configuration. Выполняем сканирование имеющихся конфигураций.
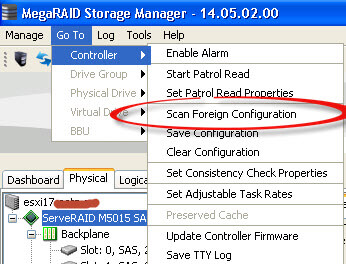
У вас появится окно с импортированием конфигурации.
ни в коем случае не выбирайте Clear: Remove logical configuration, если только не решили затереть диск
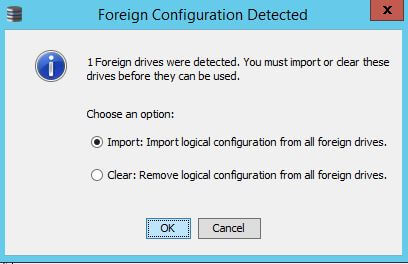
Вас спросят действительно ли вы хотите это сделать жмем yes.
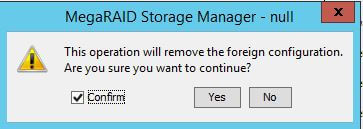
Если у вас не стоит MSM то вам придется перезагрузить хост и зайти в bios подобное меню. В котором будет приблизительно вот такое окно, где нужно так же импортировать конфигурацию.

После данной манипуляции ваши локальные lun перейдут в режим online и если вы до этого заменили сбойный диск на новый, то пойдет процедура rebuild. После чего raid перестроится и начнет нормальное функционирование.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

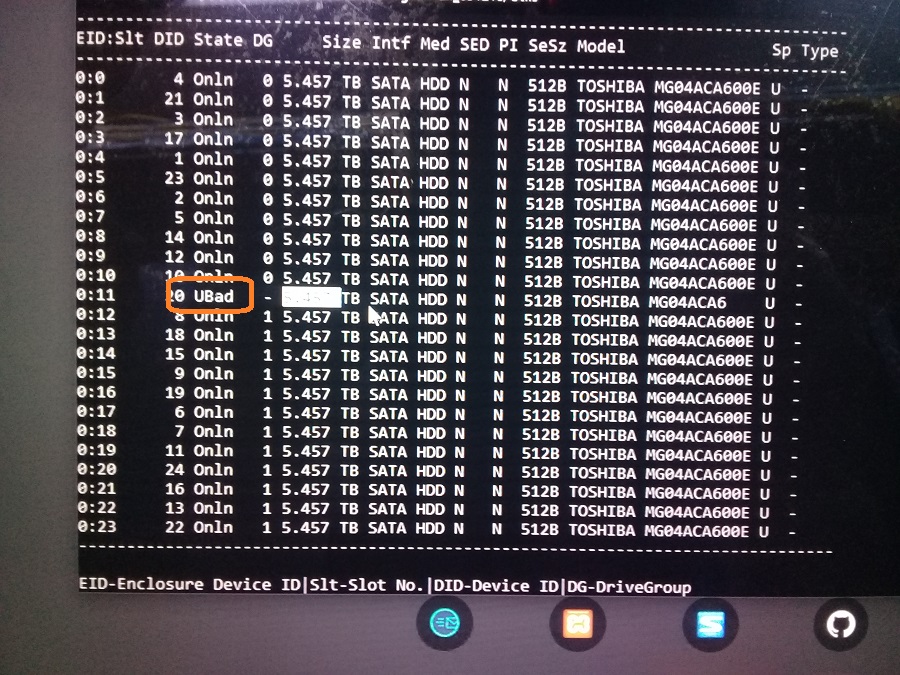
Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
13 Responses to Как добавить диск в существующий RAID на контроллере LSI
Добрый день, а какая у вас версия MegaRAID? На моей 13.04.03.01(от 2013г.) нет возможности нажать ПКМ на Drive Group, и соответственно зайти в Modify Drive Group(искал в других подменю тоже не нашел). На более старой версии 2.63.00 тоже нет. Пробовал версию 2015 года, она не увидела мой контроллер. Контроллер кстати LSI Logic MegaRAID SAS 8204ELP, может он не умеет на лету пересобирать рейд? Заранее спасибо за ответ.
Добрый день, я пользовался на тот момент 14 версией MSM, но у меня есть подозрения в 99 процентов, что это функционал рейд контроллера, у каких то есть у каких то нет.

Всем привет, очень рад, что вы снова зашли на мой IT блог. Сегодня я хочу рассказать поучительную историю, о том, как из-за невнимательности можно сильно попасть в не хорошую ситуацию из которой будет, очень сложно выйти без надлежащего опыта. Будет некий такой траблшутинг по восстановлению lsi raid массивов при замене вышедшего из строя диска. Думаю, что для людей, кто только знакомиться с избыточными массивами данных, будет очень полезно поучиться на чужом опыте.
13 Responses to Как добавить диск в существующий RAID на контроллере LSI
Добрый день, а какая у вас версия MegaRAID? На моей 13.04.03.01(от 2013г.) нет возможности нажать ПКМ на Drive Group, и соответственно зайти в Modify Drive Group(искал в других подменю тоже не нашел). На более старой версии 2.63.00 тоже нет. Пробовал версию 2015 года, она не увидела мой контроллер. Контроллер кстати LSI Logic MegaRAID SAS 8204ELP, может он не умеет на лету пересобирать рейд? Заранее спасибо за ответ.
Добрый день, я пользовался на тот момент 14 версией MSM, но у меня есть подозрения в 99 процентов, что это функционал рейд контроллера, у каких то есть у каких то нет.
Всем привет, очень рад, что вы снова зашли на мой IT блог. Сегодня я хочу рассказать поучительную историю, о том, как из-за невнимательности можно сильно попасть в не хорошую ситуацию из которой будет, очень сложно выйти без надлежащего опыта. Будет некий такой траблшутинг по восстановлению lsi raid массивов при замене вышедшего из строя диска. Думаю, что для людей, кто только знакомиться с избыточными массивами данных, будет очень полезно поучиться на чужом опыте.
40 Responses to Как запросить замену диска в сервере у IBM
Добрый день. Подскажите пож-та, сейчас у меня рейд в статусе разрушен, один диск вылетел, установил новый (той же серии) но ни чего не происходит. Желтая лампочка при этом не горит и не горела, ни на самом диске ни на панели. Может быть надо где настроить, что бы горела желтая лампочка? Server X3300 M4, диски не родные (не IBM). Спасибо
Спасибо за скорый ответ. Модель контроллера M1115. В моем случае меня интересует почему не горят желтые лампочки на самом диске и на панели сверху? Спасибо еще раз
а в каком статусе у вас видится в MSM ваш новый диск и какой статус RAID?
MSM пока не установил еще, в Megaraide диск был красным цветом, а рейд кажется в статусе разрушен (вроде бы так)
Нужно посмотреть с помощью MSM, статусы и логи так быстрее можно понять проблему, либо можно логи снять утилитой MEGACLI, но MSM нагляднее все показывает
проблем после установки MSM не было? у меня сейчас сервер работает, 200 чел онлайн
установил, один диск — Uncofig good, Virtual drive — degraded.
Хотел ссылку на скрин скинуть суда, не получается
Сделайте его правым кликом Online если такого нет то попробуйте его сделать как Assign Global Hot Spare
И покажите ещ пож скрин с dashboard
Я произвел на тестовом, после Assign Global Hot Spare должен начаться ребилд
Если вы его не сделаете то потеряете, ребилд это стандартная операция восстановления RAID, которая перекидывает дублирующая информацию на hdd дублер.
ночью на всякий случай сделаю бэкап, а после все что Вы писали! Спасибо! А на счет желтых индикаторов не подскажите почему не горят?
индикатор загорится как только начнется ребилд, сейчас диск находится в подвешенном состоянии ни туда ни сюда, отпишитесь пож как у вас все пройдет
пока еще не делал, в это воскресенье буду делать. Просьба не удалять статью и комментарии. спасибо
Добрый день. Сделал как Вы писали Asifn Global Hot Spare, начался ребилд. Сейчас работает как надо, спасибо большое за помощь.
рад что мой опыт вам помог и вы научились чему то новому
Иван, помогите советом, если есть возможность ответить.
У нас на сервере IBM System x3400 M3 Server -7379ZLP полетел один жёсткий диск. Проверили документы, оказалось, что уже не гарантийный. Сервер вообще не загружался (даже БИОС не грузил), просто чёрный экран. Вытащили все три диска, поставили три новых диска, но не фирмы IBM, БИОС загрузился. Стали думать как был сконфигурирован RAID, контроллер LSI, поддерживающий только RAID 0,1, и 10, а диска всего три. Стали звонить в техподдержку фирмы, где приобретали, они посоветовали позвонить всё же в IBM и уточнить на счёт гарантии, позвонили, оказывается наш сервер ещё гарантийный, вытащили новые диски, вставили старые, БИОС сервера загрузился, собрали логи для IBM, они обещали выслать один новый жёсткий диск, но по срокам пока не понятно, когда придёт. БИОС загрузился, но винда не загружается. Наш RAID получается развалился после замены дисков? Похоже что на двух дисках был собран RAID 1, а третий был для бэкапов. Как думаете есть возможность запустить винду с одного диска? Я его подключал отдельно к компу, он живой на нём системные файлы и пакпи.
Добрый день, при загрузке можно попасть в bios подобное меню LSI и посмотреть какой рейд у вас был.
Вероятнее всего был RAID0, так как RAID-1 это зеркало и при выходе одного диска остался бы жить. Третий диск видимо забыли использовать, хотя могли сделать как hot swap.
Срок поставки зависит от уровня поддержки, мне в среднем за 3-4 дня рабочих приходят.
А при загрузке W ошибки какие на экране появляются?
Зашёл в биос, действительно RAID0 был. Значит придётся винду переустанавливать. Не понимаю для чего на сервере RAID0 делать.
Видимо, человек создававший его не знал принципов его работы и какой он отказоустойчивый:)
Сегодня из IBM привезли жёсткий диск, буду восстанавливать работоспособность сервера. Сделаю RAID1 вместо RAID0.
Мудрое решение, успехов.
Добрый день!
контроллер LSI 5110e. RAID10 на 6 дисках.
Намедни получил почтой предупреждение о «Predictive Failure Count»
Посмотрел в MSM а также поэкспериментировал с CLI
Drive /c0/e252/s0 State :
Shield Counter = 0
Media Error Count = 11
Other Error Count = 0
Drive Temperature = 33C (91.40 F)
Predictive Failure Count = 5
S.M.A.R.T alert flagged by drive = Yes
SN = 6XR3H3PF0000M228GXJ5
Model Number = ST9600205SS
Хотя состояние RAID все еще optimal.
Естественно такая модель уже не продается, можно ли закупить аналогичный по характеристикам винт на замену сбойному?
поидее можно, но там должно быть одинаковое количество байт в диске
Да, поставил аналогичный. все прошло нормально. Ребилд автоматически запустился и отработал за полтора часа.
Ларчик как говорится просто открывался, видимо он FRU как то использует.
Добрый день!
Планируется лиликбез по замене BBU на Raid ?
Добрый, а что у вас за рейд и контроллер и что именно интересует?
IBM System x3630 M3 с контроллером ServeRAID M5015, как физически установить разобрался. Больше интересует какие могут быть подводные камни. На что перед заменой надо обратить внимание.
Да по идее их нет, создаете рейд и мониторите потом его на ошибки, если что меняете диски, все как то так.
Наверно имели ввиду батарею на рейде менять в случае ошибок. Спасибо!
Приветствую! Имеется сервер IBM X3650 M4, контроллер M5110e. Вышел из строя один диск в raid1. Поставщики нашли такой же и доставили. Старый диск я извлёк из корзины при работающем сервере, новый установил. В программу MSM этот диск отобразился со статусом Unconfigured good. Но ребилд не начинался автоматом.
После этого в контекстном меню нового диска выбрал «Assign Global Hot Spare», но и после этого ребилд не начался.
Сейчас ситуация как на скриншоте, новый диск постоянно мигает оранжевым светодиодом (уже 14 часов). Если это идёт ребилд, то почему в MSM на вкладке Dashboard в Background operations пусто?
Не пойму, что я сделал не так и что мне делать дальше? Как запустить ребилд из под винды, чтобы не тормозить работу?
Добрый вечер, есть сервер IBM X3500 M4, RAID 50 из 6 Sas дисков, контроллер М5110. Сегодня на сервере загорелась желтая лампочка с восклицательным знаком и с картинкой БД. Сразу стал смотреть, все диски мигают только зеленой лампочкой. Зашел в MegaRaid Storage Manager на одном диске Media Error Count = 1. На втором Media Error Count = 809, Pred Fail Count = 1. Также в Megaraid все диски на данный момент в нормальном состоянии, как лучше поступить? Есть запасной не родной диск. Стоит ли его вставлять на замену диску с ошибками?
Если запасной подходит по разметки (Размеру), то можете попробовать, если есть сервисный контракт, то пишите в саппорт.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Дополнение относительно SSD
Относительно SSD дисков, будьте осторожны, особенно если они в RAID-1, из практики могу привести случай, когда вылетевший диск, при возвращении его в строй, убил RAID массив и перезаписал рабочий SSD. В таких случаях, за место возвращения пропавшей конфигурации, по возможности вынимайте SSD и полностью с него удаляйте все разделы, проверяйте его на предмет ошибок и здоровья, и после этого возвращайте в RAID, чтобы начался автоматический ребилд.


Как запросить замену диска в сервере у IBM-011Она сигнализирует, что диск в данном RAID массиве вышел из строя. В некоторых случаях он еще не умер, а просто валился из RAID, для начала просто его вытащите и снова воткните, если через некоторое время лампочка продолжает гореть то приступаем к следующему шагу. Да еще хотел отметить, что посмотреть статус RAID в сервере IBM, можно утилитой MSM.
Заходим в нее и видим, что на вкладке Physical у нас один из винтов красного цвета, это значит что он все вышел из строя, намертво.

Как запросить замену диска в сервере у IBM-Сломанный диск
После, этого нам нужно обратиться в тех поддержку компании IBM, и собрать для них логи. Как собрать логи утилитой DSA читайте тут. Так же на каждом сервере вам нужно записать его MTM, SN и Product ID, найти их можно слева от винтов, еще техническая поддержка может вас попросить выслать ibm fru номер жесткого диска.

Как запросить замену диска в сервере у IBM-12
После сбора логов отправляем письмо в техническую поддержу, по адресу
Далее ждем когда приедет курьер и привезет диски. Заменяем их на убитые HDD и начинается процесс Rebild в RAID.

Как запросить замену диска в сервере у IBM-13
Наблюдать его статус можно через MSM утилиту.

Как запросить замену диска в сервере у IBM-Rebuil RAID
и также можно посмотреть сколько по времени это займет, на главной странице утилиты вы увидите ползунок

Как запросить замену диска в сервере у IBM-03
Нажав More details вы увидите более подробную информацию

Как запросить замену диска в сервере у IBM-04
Популярные Похожие записи:
Предыстория
В любом сервере рано или поздно начинают выходить из строя жесткие диски или ssd и преждевременная замена спасает вас от потери данных. Но при замене бывает такая вещь как человеческий фактор, который может все погубить.
И так есть сервер IBM с raid контроллером M5015 что в градации LSI 9260-8i. В lsi raid контроллере если диск начинает выходить из строя, то начинает срабатывать счетчик Pred Fail Count и диск следует менять. Как заказать замену диска у IBM я уже рассказывал, останавливать на этом не буду. Допустим диск вы получили и вам осталось его заменить, вы меняете его и обнаруживаете что вытащили не тот диск, что будет дальше.
А дальше все зависит от вида raid собранного у вас. У меня на lsi raid контроллере был raid 10. И когда мой коллега вытащил не тот диск, то с ним ничего не случилось, но если вы засуните на его место новый диск или опять тот же что вытащили, то рейд не восстановится. Новый диск будет видится как unconfigured good а старый как foreign, то есть потерянный.
Тут после возврата старого диска сразу нужно было выполнить процедуру описанную ниже и все бы восстановилось, но бывает что приходит мысль, поменять еще в данной ситуации выходящий из строя диск на новый, и вот тут LSi контроллер, дабы не потерять данные переводит локальные луны в offline, что выражается в остановке сервисов или частичной остановки, на данных дисках.
Читайте также: