
Контекст процесса может быть перемещен из оперативной памяти
Как уже отмечалось в главе 2, время жизни процесса можно теоретически разбить на несколько состояний, описывающих процесс. Полный набор состояний процесса содержится в следующем перечне:
1. Процесс выполняется в режиме задачи.
2. Процесс выполняется в режиме ядра.
3. Процесс не выполняется, но готов к запуску под управлением ядра.
4. Процесс приостановлен и находится в оперативной памяти.
5. Процесс готов к запуску, но программа подкачки (нулевой процесс) должна еще загрузить процесс в оперативную память, прежде чем он будет запущен под управлением ядра. Это состояние будет предметом обсуждения в главе 9 при рассмотрении системы подкачки.
6. Процесс приостановлен и программа подкачки выгрузила его во внешнюю память, чтобы в оперативной памяти освободить место для других процессов.
7. Процесс возвращен из привилегированного режима (режима ядра) в непривилегированный (режим задачи), ядро резервирует его и переключает контекст на другой процесс. Об отличии этого состояния от состояния 3 (готовность к запуску) пойдет речь ниже.
8. Процесс вновь создан и находится в переходном состоянии; процесс существует, но не готов к выполнению, хотя и не приостановлен. Это состояние является начальным состоянием всех процессов, кроме нулевого.
9. Процесс вызывает системную функцию exit и прекращает существование. Однако, после него осталась запись, содержащая код выхода, и некоторая хронометрическая статистика, собираемая родительским процессом. Это состояние является последним состоянием процесса.
Рисунок 6.1 представляет собой полную диаграмму переходов процесса из состояния в состояние. Рассмотрим с помощью модели переходов типичное поведение процесса. Ситуации, которые будут обсуждаться, несколько искусственны и процессы не всегда имеют дело с ними, но эти ситуации вполне применимы для иллюстрации различных переходов. Начальным состоянием модели является создание процесса родительским процессом с помощью системной функции fork; из этого состояния процесс неминуемо переходит в состояние готовности к запуску (3 или 5). Для простоты предположим, что процесс перешел в состояние «готовности к запуску в памяти» (3). Планировщик процессов в конечном счете выберет процесс для выполнения и процесс перейдет в состояние «выполнения в режиме ядра», где доиграет до конца роль, отведенную ему функцией fork.

Рисунок 6.1. Диаграмма переходов процесса из состояния в состояние
После всего этого процесс может перейти в состояние «выполнения в режиме задачи». По прохождении определенного периода времени может произойти прерывание работы процессора по таймеру и процесс снова перейдет в состояние «выполнения в режиме ядра». Как только программа обработки прерывания закончит работу, ядру может понадобиться подготовить к запуску другой процесс, поэтому первый процесс перейдет в состояние «резервирования», уступив дорогу второму процессу. Состояние «резервирования» в действительности не отличается от состояния «готовности к запуску в памяти» (пунктирная линия на рисунке, соединяющая между собой оба состояния, подчеркивает их эквивалентность), но они выделяются в отдельные состояния, чтобы подчеркнуть, что процесс, выполняющийся в режиме ядра, может быть зарезервирован только в том случае, если он собирается вернуться в режим задачи. Следовательно, ядро может при необходимости подкачивать процесс из состояния «резервирования». При известных условиях планировщик выберет процесс для исполнения и тот снова вернется в состояние «выполнения в режиме задачи».
Когда процесс выполняет вызов системной функции, он из состояния «выполнения в режиме задачи» переходит в состояние «выполнения в режиме ядра». Предположим, что системной функции требуется ввод-вывод с диска и поэтому процесс вынужден дожидаться завершения ввода-вывода. Он переходит в состояние «приостанова в памяти», в котором будет находиться до тех пор, пока не получит извещения об окончании ввода-вывода. Когда ввод-вывод завершится, произойдет аппаратное прерывание работы центрального процессора и программа обработки прерывания возобновит выполнение процесса, в результате чего он перейдет в состояние «готовности к запуску в памяти».
Предположим, что система выполняет множество процессов, которые одновременно никак не могут поместиться в оперативной памяти, и программа подкачки (нулевой процесс) выгружает один процесс, чтобы освободить место для другого процесса, находящегося в состоянии «готов к запуску, но выгружен». Первый процесс, выгруженный из оперативной памяти, переходит в то же состояние. Когда программа подкачки выбирает наиболее подходящий процесс для загрузки в оперативную память, этот процесс переходит в состояние «готовности к запуску в памяти». Планировщик выбирает процесс для исполнения и он переходит в состояние «выполнения в режиме ядра». Когда процесс завершается, он исполняет системную функцию exit, последовательно переходя в состояния «выполнения в режиме ядра» и, наконец, в состояние «прекращения существования».
Процесс может управлять некоторыми из переходов на уровне задачи. Во-первых, один процесс может создать другой процесс. Тем не менее, в какое из состояний процесс перейдет после создания (т. е. в состояние «готов к выполнению, находясь в памяти» или в состояние «готов к выполнению, но выгружен») зависит уже от ядра. Процессу эти состояния не подконтрольны. Во-вторых, процесс может обратиться к различным системным функциям, чтобы перейти из состояния «выполнения в режиме задачи» в состояние «выполнения в режиме ядра», а также перейти в режим ядра по своей собственной воле. Тем не менее, момент возвращения из режима ядра от процесса уже не зависит; в результате каких-то событий он может никогда не вернуться из этого режима и из него перейдет в состояние «прекращения существования» (см. раздел 7.2, где говорится о сигналах). Наконец, процесс может завершиться с помощью функции exit по своей собственной воле, но как указывалось ранее, внешние события могут потребовать завершения процесса без явного обращения к функции exit. Все остальные переходы относятся к жестко закрепленной части модели, закодированной в ядре, и являются результатом определенных событий, реагируя на них в соответствии с правилами, сформулированными в этой и последующих главах. Некоторые из правил уже упоминались: например, то, что процесс может выгрузить другой процесс, выполняющийся в ядре.
Две принадлежащие ядру структуры данных описывают процесс: запись в таблице процессов и пространство процесса. Таблица процессов содержит поля, которые должны быть всегда доступны ядру, а пространство процесса — поля, необходимость в которых возникает только у выполняющегося процесса. Поэтому ядро выделяет место для пространства процесса только при создании процесса: в нем нет необходимости, если записи в таблице процессов не соответствует конкретный процесс.
Запись в таблице процессов состоит из следующих полей:
• Поле состояния, которое идентифицирует состояние процесса.
• Поля, используемые ядром при размещении процесса и его пространства в основной или внешней памяти. Ядро использует информацию этих полей для переключения контекста на процесс, когда процесс переходит из состояния «готов к выполнению, находясь в памяти» в состояние «выполнения в режиме ядра» или из состояния «резервирования» в состояние «выполнения в режиме задачи». Кроме того, ядро использует эту информацию при перекачки процессов из и в оперативную память (между двумя состояниями «в памяти» и двумя состояниями «выгружен»). Запись в таблице процессов содержит также поле, описывающее размер процесса и позволяющее ядру планировать выделение пространства для процесса.
• Несколько пользовательских идентификаторов (UID), устанавливающих различные привилегии процесса. Поля UID, например, описывают совокупность процессов, могущих обмениваться сигналами (см. следующую главу).
• Идентификаторы процесса (PID), указывающие взаимосвязь между процессами. Значения полей PID задаются при переходе процесса в состояние «создан» во время выполнения функции fork.
• Дескриптор события (устанавливается тогда, когда процесс приостановлен). В данной главе будет рассмотрено использование дескриптора события в алгоритмах функций sleep и wakeup.
• Параметры планирования, позволяющие ядру устанавливать порядок перехода процессов из состояния «выполнения в режиме ядра» в состояние «выполнения в режиме задачи».
• Поле сигналов, в котором перечисляются сигналы, посланные процессу, но еще не обработанные (раздел 7.2).
• Различные таймеры, описывающие время выполнения процесса и использование ресурсов ядра и позволяющие осуществлять слежение за выполнением и вычислять приоритет планирования процесса. Одно из полей является таймером, который устанавливает пользователь и который необходим для посылки процессу сигнала тревоги (раздел 8.3). Пространство процесса содержит поля, дополнительно характеризующие состояния процесса. В предыдущих главах были рассмотрены последние семь из приводимых ниже полей пространства процесса, которые мы для полноты вновь кратко перечислим:
• Указатель на таблицу процессов, который идентифицирует запись, соответствующую процессу.
• Пользовательские идентификаторы, устанавливающие различные привилегии процесса, в частности, права доступа к файлу (см. раздел 7.6).
• Поля таймеров, хранящие время выполнения процесса (и его потомков) в режиме задачи и в режиме ядра.
• Вектор, описывающий реакцию процесса на сигналы.
• Поле операторского терминала, идентифицирующее «регистрационный терминал», который связан с процессом.
• Поле ошибок, в которое записываются ошибки, имевшие место при выполнении системной функции.
• Поле возвращенного значения, хранящее результат выполнения системной функции.
• Параметры ввода-вывода: объем передаваемых данных, адрес источника (или приемника) данных в пространстве задачи, смещения в файле (которыми пользуются операции ввода-вывода) и т. д.
• Имена текущего каталога и текущего корня, описывающие файловую систему, в которой выполняется процесс.
• Таблица пользовательских дескрипторов файла, которая описывает файлы, открытые процессом.
• Поля границ, накладывающие ограничения на размерные характеристики процесса и на размер файла, в который процесс может вести запись.
• Поле прав доступа, хранящее двоичную маску установок прав доступа к файлам, которые создаются процессом. Пространство состояний процесса и переходов между ними рассматривалось в данном разделе на логическом уровне. Каждое состояние имеет также физические характеристики, управляемые ядром, в частности, виртуальное адресное пространство процесса. Следующий раздел посвящен описанию модели распределения памяти; в остальных разделах состояния процесса и переходы между ними рассматриваются на физическом уровне, особое внимание при этом уделяется состояниям «выполнения в режиме задачи», «выполнения в режиме ядра», «резервирования» и «приостанова (в памяти)». В следующей главе затрагиваются состояния «создания» и «прекращения существования», а в главе 8 — состояние «готовности к запуску в памяти». В главе 9 обсуждаются два состояния выгруженного процесса и организация подкачки по обращению.
2. Переходы в CSS
2. Переходы в CSS Шел 1997 год; я сидел в плохонькой квартирке в красивом Оллстоне, в Массачусетсе. Обычная ночь просмотра исходников и изучения HTML, которой предшествовал день упаковывания компакт-дисков на местной звукозаписывающей студии, – практически бесплатно
Переходы между параллельными состояниями
Переходы между параллельными состояниями В отдельных случаях переход может иметь несколько состояний-источников и несколько целевых состояний. Такой переход получил специальное название – параллельный переход. Введение в рассмотрение параллельного перехода
Переходы между составными состояниями
Переходы между составными состояниями Переход, стрелка которого соединена с границей некоторого составного состояния, обозначает переход в составное состояние (переход b на рис. 6.12). Он эквивалентен переходу в начальное состояние каждого из подавтоматов (возможно,
10.1. Ограничения доступа к файлам и борьба с ними
10.1. Ограничения доступа к файлам и борьба с ними Разрешения NTFSВ Windows Vista можно управлять правами доступа к файлам и папкам для различных пользователей. Эта возможность реализована в самой файловой системе NTFS в виде разрешений, которые хранятся для каждого файла или папки
Состояния процесса
Состояния процесса Жизненный цикл процесса может быть разбит на несколько состояний. Переход процесса из одного состояния в другое происходит в зависимости от наступления тех или иных событий в системе. На рис. 3.3 показаны состояния, в которых процесс может находиться с
2.2.2.2 Состояния процесса
2.2.2.2 Состояния процесса Время жизни процесса можно разделить на несколько состояний, каждое из которых имеет определенные характеристики, описывающие процесс. Все состояния процесса рассматриваются в главе 6, однако представляется существенным для понимания
2.2.2.3 Переходы из состояния в состояние
2.2.2.3 Переходы из состояния в состояние Состояния процесса, перечисленные выше, дают статическое представление о процессе, однако процессы непрерывно переходят из состояния в состояние в соответствии с определенными правилами. Диаграмма переходов представляет собой
4.2.2. Запуск программ и переключение между ними
4.2.2. Запуск программ и переключение между ними В общем случае запустить программу или приложение на выполнение можно несколькими способами:? Щелкнуть мышкой по значку программы на панели (если таковой имеется).? Щелкнуть мышкой по соответствующему значку рабочего стола
4.2. Различия между внутренними и внешними оценками производственного процесса
4.2. Различия между внутренними и внешними оценками производственного процесса Несмотря на эти сходства, результаты внутренней и внешней оценки могут расходиться даже в случае успешного применения одного и того же метода. Одной из причин этого является то, что объем
Создание снимков отчета и работа с ними
Создание снимков отчета и работа с ними Уже созданный и отредактированный отчет можно экспортировать в формат снимка, в таком случае конечный файл будет являться файлом формата SNP. Снимок отчета представляет собой файл, в котором содержатся копии всех страниц отчета,
Глава 5 Агрессивные формы кода и борьба с ними
Глава 5 Агрессивные формы кода и борьба с ними ? Все гениальное – просто. Пишем вирус одной строкой!? Веб-страница в обличии Фредди Крюгера – "потрошит" ваш винчестер!? Антология сокрытия вирусного кода? Как работает эвристический анализатор кода и почему даже два
Не думать, что такое не может случиться с ними
Не думать, что такое не может случиться с ними Во многих компаниях взлом компьютеров считают игрой в лотерею. Они уверены в своем иммунитете от вторжения хакера и пренебрегают даже основными мерами предосторожности. Это никогда не может с ними произойти, поэтому они не
Текстовые блоки и работа с ними
Текстовые блоки и работа с ними Любой текст, который мы поместим на рабочий лист, будет заключен в так называемый текстовый блок. Это особый примитив, мало чем отличающийся от уже знакомых нам "графических" примитивов — линий и заливок. О работе с текстовыми блоками мы
Создание массивов и работа с ними
Создание массивов и работа с ними Массив — это пронумерованный набор переменных одного типа, называемых элементами массива. Доступ к нужному элементу массива выполняется по его порядковому номеру, называемому индексом. А общее число элементов массива называется его
5.3 Мониторинг состояния системы, устранение ошибок, восстановление утерянных файлов и защита данных Анализ состояния аппаратной части системы
Введение Как и всякая техника, персональный компьютер нуждается в техническом обслуживании, настройке и наладке. Небрежное отношение к своей машине приводит к тому, что работа компьютера становится нестабильной и не эффективной. А потом происходит сбой, и компьютер
Файлы и операции с ними
Файлы и операции с ними Итак, что такое файл, мы уже себе можем представить (одна программа, один документ, один рисунок и т. д.). Каждый файл обязательно имеет имя, адрес, размер.Начнем с «прописки» файла. Здесь, слава богу, только два варианта – внутри компьютера (на жестком
Рисунок 6.1 представляет собой полную диаграмму переходов процесса из состояния в состояние. Рассмотрим с помощью модели переходов типичное поведение процесса. Ситуации, которые будут обсуждаться, несколько искусственны и процессы не всегда имеют дело с ними, но эти ситуации вполне применимы для иллюстрации различных переходов. Начальным состоянием модели является создание процесса родительским процессом с помощью системной функции fork; из этого состояния процесс неминуемо переходит в состояние готовности к запуску (3 или 5). Для простоты предположим, что процесс перешел в состояние "готовности к запуску в памяти" (3). Планировщик процессов в конечном счете выберет процесс для выполнения и процесс перейдет в состояние "выполнения в режиме ядра", где доиграет до конца роль, отведенную ему функцией fork.
Рисунок 6.1. Диаграмма переходов процесса из состояния в состояние
После всего этого процесс может перейти в состояние "выполнения в режиме задачи". По прохождении определенного периода времени может произойти прерывание работы процессора по таймеру и процесс снова перейдет в состояние "выполнения в режиме ядра". Как только программа обработки прерывания закончит работу, ядру может понадобиться подготовить к запуску другой процесс, поэтому первый процесс перейдет в состояние "резервирования", уступив дорогу второму процессу. Состояние "резервирования" в действительности не отличается от состояния "готовности к запуску в памяти" (пунктирная линия на рисунке, соединяющая между собой оба состояния, подчеркивает их эквивалентность), но они выделяются в отдельные состояния, чтобы подчеркнуть, что процесс, выполняющийся в режиме ядра, может быть зарезервирован только в том случае, если он собирается вернуться в режим задачи. Следовательно, ядро может при необходимости подкачивать процесс из состояния "резервирования". При известных условиях планировщик выберет процесс для исполнения и тот снова вернется в состояние "выполнения в режиме задачи".
Когда процесс выполняет вызов системной функции, он из состояния "выполнения в режиме задачи" переходит в состояние "выполнения в режиме ядра". Предположим, что системной функции требуется ввод-вывод с диска и поэтому процесс вынужден дожидаться завершения ввода-вывода. Он переходит в состояние "приостанова в памяти", в котором будет находиться до тех пор, пока не получит извещения об окончании ввода-вывода. Когда ввод-вывод завершится, произойдет аппаратное прерывание работы центрального процессора и программа обработки прерывания возобновит выполнение процесса, в результате чего он перейдет в состояние "готовности к запуску в памяти".
Предположим, что система выполняет множество процессов, которые одновременно никак не могут поместиться в оперативной памяти, и программа подкачки (нулевой процесс) выгружает один процесс, чтобы освободить место для другого процесса, находящегося в состоянии "готов к запуску, но выгружен". Первый процесс, выгруженный из оперативной памяти, переходит в то же состояние. Когда программа подкачки выбирает наиболее подходящий процесс для загрузки в оперативную память, этот процесс переходит в состояние "готовности к запуску в памяти". Планировщик выбирает процесс для исполнения и он переходит в состояние "выполнения в режиме ядра". Когда процесс завершается, он исполняет системную функцию exit, последовательно переходя в состояния "выполнения в режиме ядра" и, наконец, в состояние "прекращения существования".
Процесс может управлять некоторыми из переходов на уровне задачи. Во-первых, один процесс может создать другой процесс. Тем не менее, в какое из состояний процесс перейдет после создания (т.е. в состояние "готов к выполнению, находясь в памяти" или в состояние "готов к выполнению, но выгружен") зависит уже от ядра. Процессу эти состояния не подконтрольны. Во-вторых, процесс может обратиться к различным системным функциям, чтобы перейти из состояния "выполнения в режиме задачи" в состояние "выполнения в режиме ядра", а также перейти в режим ядра по своей собственной воле. Тем не менее, момент возвращения из режима ядра от процесса уже не зависит; в результате каких-то событий он может никогда не вернуться из этого режима и из него перейдет в состояние "прекращения существования" (см. раздел 7.2, где говорится о сигналах). Наконец, процесс может завершиться с помощью функции exit по своей собственной воле, но как указывалось ранее, внешние события могут потребовать завершения процесса без явного обращения к функции exit. Все остальные переходы относятся к жестко закрепленной части модели, закодированной в ядре, и являются результатом определенных событий, реагируя на них в соответствии с правилами, сформулированными в этой и последующих главах. Некоторые из правил уже упоминались: например, то, что процесс может выгрузить другой процесс, выполняющийся в ядре.
Две принадлежащие ядру структуры данных описывают процесс: запись в таблице процессов и пространство процесса. Таблица процессов содержит поля, которые должны быть всегда доступны ядру, а пространство процесса - поля, необходимость в которых возникает только у выполняющегося процесса. Поэтому ядро выделяет место для пространства процесса только при создании процесса: в нем нет необходимости, если записи в таблице процессов не соответствует конкретный процесс.
6.3 КОНТЕКСТ ПРОЦЕССА
Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательский контекст, регистровый контекст и системный контекст (*). Пользовательский контекст состоит из команд и данных процесса, стека задачи и содержимого совместно используемого пространства памяти в виртуальных адресах процесса. Те части виртуального адресного пространства процесса, которые периодически отсутствуют в оперативной памяти вследствие выгрузки или замещения страниц, также включаются в пользовательский контекст.
- Счетчика команд, указывающего адрес следующей команды, которую будет выполнять центральный процессор; этот адрес является виртуальным адресом внутри пространства ядра или пространства задачи.
- Регистра состояния процессора (PS), который указывает аппаратный статус машины по отношению к процессу. Регистр PS, например, обычно содержит подполя, которые указывают, является ли результат последних вычислений нулевым, положительным или отрицательным, переполнен ли регистр с установкой бита переноса и т.д. Операции, влияющие на установку регистра PS, выполняются для отдельного процесса, потому-то в регистре PS и содержится аппаратный статус машины по отношению к процессу. В других имеющих важное значение подполях регистра PS указывается текущий уровень прерывания процессора, а также текущий и предыдущий режимы выполнения процесса (режим ядра/задачи). По значению подполя текущего режима выполнения процесса устанавливается, может ли процесс выполнять привилегированные команды и обращаться к адресному пространству ядра.
- Указателя вершины стека, в котором содержится адрес следующего элемента стека ядра или стека задачи, в соответствии с режимом выполнения процесса. В зависимости от архитектуры машины указатель вершины стека показывает на следующий свободный элемент стека или на последний используемый элемент. От архитектуры машины также зависит направление увеличения стека (к старшим или младшим адресам), но для нас сейчас эти вопросы несущественны.
- Регистров общего назначения, в которых содержится информация, сгенерированная процессом во время его выполнения. Чтобы облегчить последующие объяснения, выделим среди них два регистра - регистр 0 и регистр 1 - для дополнительного использования при передаче информации между процессами и ядром.
- Запись в таблице процессов, описывающая состояние процесса (раздел 6.1) и содержащая различную управляющую информацию, к которой ядро всегда может обратиться.
- Часть адресного пространства задачи, выделенная процессу, где хранится управляющая информация о процессе, доступная только в контексте процесса. Общие управляющие параметры, такие как приоритет процесса, хранятся в таблице процессов, поскольку обращение к ним должно производиться за пределами контекста процесса.
- Записи частной таблицы областей процесса, общие таблицы областей и таблицы страниц, необходимые для преобразования виртуальных адресов в физические, в связи с чем в них описываются области команд, данных, стека и другие области, принадлежащие процессу. Если несколько процессов совместно используют общие области, эти области входят составной частью в контекст каждого процесса, поскольку каждый процесс работает с этими областями независимо от других процессов. В задачи управления памятью входит идентификация участков виртуального адресного пространства процесса, не являющихся резидентными в памяти.
- Стек ядра, в котором хранятся записи процедур ядра, если процесс выполняется в режиме ядра. Несмотря на то, что все процессы пользуются одними и теми же программами ядра, каждый из них имеет свою собственную копию стека ядра для хранения индивидуальных обращений к функциям ядра. Пусть, например, один процесс вызывает функцию creat и приостанавливается в ожидании назначения нового индекса, а другой процесс вызывает функцию read и приостанавливается в ожидании завершения передачи данных с диска в память. Оба процесса обращаются к функциям ядра и у каждого из них имеется в наличии отдельный стек, в котором хранится последовательность выполненных обращений. Ядро должно иметь возможность восстанавливать содержимое стека ядра и положение указателя вершины стека для того, чтобы возобновлять выполнение процесса в режиме ядра. В различных системах стек ядра часто располагается в пространстве процесса, однако этот стек является логически-независимым и, таким образом, может помещаться в самостоятельной области памяти. Когда процесс выполняется в режиме задачи, соответствующий ему стек ядра пуст.
- Динамическая часть системного контекста процесса, состоящая из нескольких уровней и имеющая вид стека, который освобождается от элементов в порядке, обратном порядку их поступления. На каждом уровне системного контекста содержится информация, необходимая для восстановления предыдущего уровня и включающая в себя регистровый контекст предыдущего уровня.
(*) Используемые в данном разделе термины "пользовательский контекст" (user-level context), "регистровый контекст" (register context), "системный контекст" (system-level context) и "контекстные уровни" (context layers) введены автором.
Ядро помещает контекстный уровень в стек при возникновении прерывания, при обращении к системной функции или при переключении контекста процесса. Контекстный уровень выталкивается из стека после завершения обработки прерывания, при возврате процесса в режим задачи после выполнения системной функции, или при переключении контекста. Таким образом, переключение контекста влечет за собой как помещение контекстного уровня в стек, так и извлечение уровня из стека: ядро помещает в стек контекстный уровень старого процесса, а извлекает из стека контекстный уровень нового процесса. Информация, необходимая для восстановления текущего контекстного уровня, хранится в записи таблицы процессов.
На Рисунке 6.8 изображены компоненты контекста процесса. Слева на рисунке изображена статическая часть контекста. В нее входят: пользовательский контекст, состоящий из программ процесса (машинных инструкций), данных, стека и разделяемой памяти (если она имеется), а также статическая часть системного контекста, состоящая из записи таблицы процессов, пространства процесса и записей частной таблицы областей (информации, необходимой для трансляции виртуальных адресов пользовательского контекста). Справа на рисунке изображена динамическая часть контекста. Она имеет вид стека и включает в себя несколько элементов, хранящих регистровый контекст предыдущего уровня и стек ядра для текущего уровня. Нулевой контекстный уровень представляет собой пустой уровень, относящийся к пользовательскому контексту; увеличение стека здесь идет в адресном пространстве задачи, стек ядра недействителен. Стрелка, соединяющая между собой статическую часть системного контекста и верхний уровень динамической части контекста, означает то, что в таблице процессов хранится информация, позволяющая ядру восстанавливать текущий контекстный уровень процесса.
Рисунок 6.8. Компоненты контекста процесса
Процесс выполняется в рамках своего контекста или, если говорить более точно, в рамках своего текущего контекстного уровня. Количество контекстных уровней ограничивается числом поддерживаемых в машине уровней прерывания. Например, если в машине поддерживаются разные уровни прерываний для программ, терминалов, дисков, всех остальных периферийных устройств и таймера, то есть 5 уровней прерывания, то, следовательно, у процесса может быть не более 7 контекстных уровней: по одному на каждый уровень прерывания, 1 для системных функций и 1 для пользовательского контекста. 7 уровней будет достаточно, даже если прерывания будут поступать в "наихудшем" из возможных порядков, поскольку прерывание данного уровня блокируется (то есть его обработка откладывается центральным процессором) до тех пор, пока ядро не обработает все прерывания этого и более высоких уровней.
Несмотря на то, что ядро всегда исполняет контекст какого-нибудь процесса, логическая функция, которую ядро реализует в каждый момент, не всегда имеет отношение к данному процессу. Например, если возвращая данные, дисковое запоминающее устройство посылает прерывание, то прерывается выполнение текущего процесса и ядро обрабатывает прерывание на новом контекстном уровне этого процесса, даже если данные относятся к другому процессу. Программы обработки прерываний обычно не обращаются к статическим составляющим контекста процесса и не видоизменяют их, так как эти части не связаны с прерываниями.
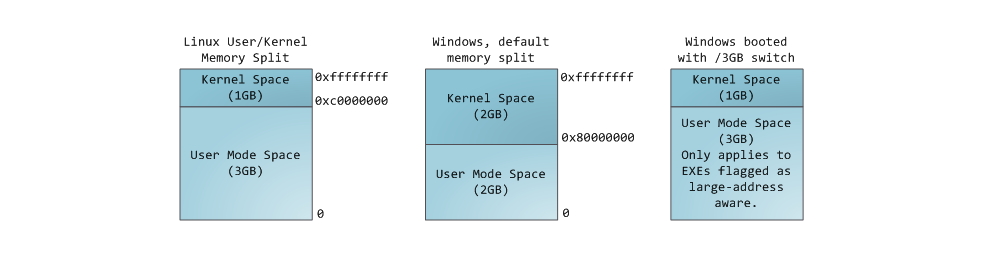
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент. Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
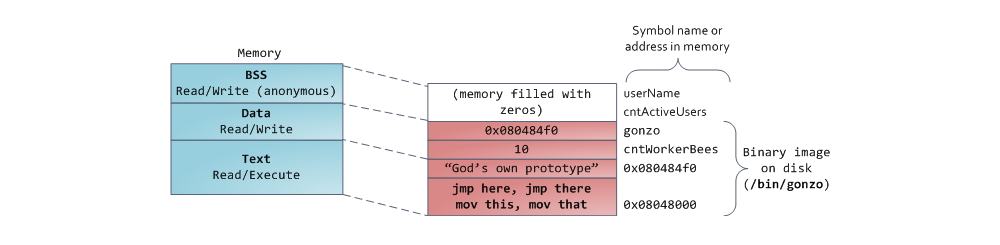
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:
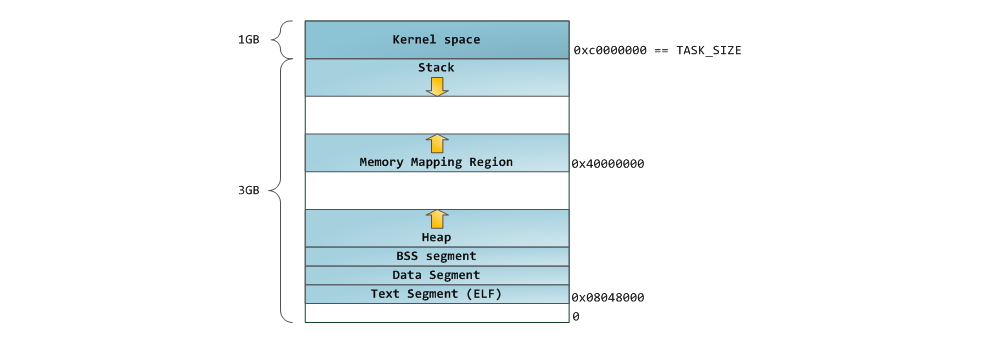
Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.
Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательский контекст, регистровый контекст и системный контекст[17]. Пользовательский контекст состоит из команд и данных процесса, стека задачи и содержимого совместно используемого пространства памяти в виртуальных адресах процесса. Те части виртуального адресного пространства процесса, которые периодически отсутствуют в оперативной памяти вследствие выгрузки или замещения страниц, также включаются в пользовательский контекст.
Регистровый контекст состоит из следующих компонент:
• Счетчика команд, указывающего адрес следующей команды, которую будет выполнять центральный процессор; этот адрес является виртуальным адресом внутри пространства ядра или пространства задачи.
• Регистра состояния процессора (PS), который указывает аппаратный статус машины по отношению к процессу. Регистр PS, например, обычно содержит подполя, которые указывают, является ли результат последних вычислений нулевым, положительным или отрицательным, переполнен ли регистр с установкой бита переноса и т. д. Операции, влияющие на установку регистра PS, выполняются для отдельного процесса, потому-то в регистре PS и содержится аппаратный статус машины по отношению к процессу. В других имеющих важное значение подполях регистра PS указывается текущий уровень прерывания процессора, а также текущий и предыдущий режимы выполнения процесса (режим ядра/задачи). По значению подполя текущего режима выполнения процесса устанавливается, может ли процесс выполнять привилегированные команды и обращаться к адресному пространству ядра.
• Указателя вершины стека, в котором содержится адрес следующего элемента стека ядра или стека задачи, в соответствии с режимом выполнения процесса. В зависимости от архитектуры машины указатель вершины стека показывает на следующий свободный элемент стека или на последний используемый элемент. От архитектуры машины также зависит направление увеличения стека (к старшим или младшим адресам), но для нас сейчас эти вопросы несущественны.
• Регистров общего назначения, в которых содержится информация, сгенерированная процессом во время его выполнения. Чтобы облегчить последующие объяснения, выделим среди них два регистра — регистр 0 и регистр 1 — для дополнительного использования при передаче информации между процессами и ядром.
Системный контекст процесса имеет «статическую часть» (первые три элемента в нижеследующем списке) и «динамическую часть» (последние два элемента). На протяжении всего времени выполнения процесс постоянно располагает одной статической частью системного контекста, но может иметь переменное число динамических частей. Динамическую часть системного контекста можно представить в виде стека, элементами которого являются контекстные уровни, которые помещаются в стек ядром или выталкиваются из стека при наступлении различных событий. Системный контекст включает в себя следующие компоненты:
• Запись в таблице процессов, описывающая состояние процесса (раздел 6.1) и содержащая различную управляющую информацию, к которой ядро всегда может обратиться.
• Часть адресного пространства задачи, выделенная процессу, где хранится управляющая информация о процессе, доступная только в контексте процесса. Общие управляющие параметры, такие как приоритет процесса, хранятся в таблице процессов, поскольку обращение к ним должно производиться за пределами контекста процесса.
• Записи частной таблицы областей процесса, общие таблицы областей и таблицы страниц, необходимые для преобразования виртуальных адресов в физические, в связи с чем в них описываются области команд, данных, стека и другие области, принадлежащие процессу. Если несколько процессов совместно используют общие области, эти области входят составной частью в контекст каждого процесса, поскольку каждый процесс работает с этими областями независимо от других процессов. В задачи управления памятью входит идентификация участков виртуального адресного пространства процесса, не являющихся резидентными в памяти.
• Стек ядра, в котором хранятся записи процедур ядра, если процесс выполняется в режиме ядра. Несмотря на то, что все процессы пользуются одними и теми же программами ядра, каждый из них имеет свою собственную копию стека ядра для хранения индивидуальных обращений к функциям ядра. Пусть, например, один процесс вызывает функцию creat и приостанавливается в ожидании назначения нового индекса, а другой процесс вызывает функцию read и приостанавливается в ожидании завершения передачи данных с диска в память. Оба процесса обращаются к функциям ядра и у каждого из них имеется в наличии отдельный стек, в котором хранится последовательность выполненных обращений. Ядро должно иметь возможность восстанавливать содержимое стека ядра и положение указателя вершины стека для того, чтобы возобновлять выполнение процесса в режиме ядра. В различных системах стек ядра часто располагается в пространстве процесса, однако этот стек является логически-независимым и, таким образом, может помещаться в самостоятельной области памяти. Когда процесс выполняется в режиме задачи, соответствующий ему стек ядра пуст.
• Динамическая часть системного контекста процесса, состоящая из нескольких уровней и имеющая вид стека, который освобождается от элементов в порядке, обратном порядку их поступления. На каждом уровне системного контекста содержится информация, необходимая для восстановления предыдущего уровня и включающая в себя регистровый контекст предыдущего уровня.
Ядро помещает контекстный уровень в стек при возникновении прерывания, при обращении к системной функции или при переключении контекста процесса. Контекстный уровень выталкивается из стека после завершения обработки прерывания, при возврате процесса в режим задачи после выполнения системной функции, или при переключении контекста. Таким образом, переключение контекста влечет за собой как помещение контекстного уровня в стек, так и извлечение уровня из стека: ядро помещает в стек контекстный уровень старого процесса, а извлекает из стека контекстный уровень нового процесса. Информация, необходимая для восстановления текущего контекстного уровня, хранится в записи таблицы процессов.
На Рисунке 6.8 изображены компоненты контекста процесса. Слева на рисунке изображена статическая часть контекста. В нее входят: пользовательский контекст, состоящий из программ процесса (машинных инструкций), данных, стека и разделяемой памяти (если она имеется), а также статическая часть системного контекста, состоящая из записи таблицы процессов, пространства процесса и записей частной таблицы областей (информации, необходимой для трансляции виртуальных адресов пользовательского контекста). Справа на рисунке изображена динамическая часть контекста. Она имеет вид стека и включает в себя несколько элементов, хранящих регистровый контекст предыдущего уровня и стек ядра для текущего уровня. Нулевой контекстный уровень представляет собой пустой уровень, относящийся к пользовательскому контексту; увеличение стека здесь идет в адресном пространстве задачи, стек ядра недействителен. Стрелка, соединяющая между собой статическую часть системного контекста и верхний уровень динамической части контекста, означает то, что в таблице процессов хранится информация, позволяющая ядру восстанавливать текущий контекстный уровень процесса.

Рисунок 6.8. Компоненты контекста процесса
Процесс выполняется в рамках своего контекста или, если говорить более точно, в рамках своего текущего контекстного уровня. Количество контекстных уровней ограничивается числом поддерживаемых в машине уровней прерывания. Например, если в машине поддерживаются разные уровни прерываний для программ, терминалов, дисков, всех остальных периферийных устройств и таймера, то есть 5 уровней прерывания, то, следовательно, у процесса может быть не более 7 контекстных уровней: по одному на каждый уровень прерывания, 1 для системных функций и 1 для пользовательского контекста. 7 уровней будет достаточно, даже если прерывания будут поступать в «наихудшем» из возможных порядков, поскольку прерывание данного уровня блокируется (то есть его обработка откладывается центральным процессором) до тех пор, пока ядро не обработает все прерывания этого и более высоких уровней.
Несмотря на то, что ядро всегда исполняет контекст какого-нибудь процесса, логическая функция, которую ядро реализует в каждый момент, не всегда имеет отношение к данному процессу. Например, если возвращая данные, дисковое запоминающее устройство посылает прерывание, то прерывается выполнение текущего процесса и ядро обрабатывает прерывание на новом контекстном уровне этого процесса, даже если данные относятся к другому процессу. Программы обработки прерываний обычно не обращаются к статическим составляющим контекста процесса и не видоизменяют их, так как эти части не связаны с прерываниями.
Контекст процесса
Контекст процесса Одна из наиболее важных частей процесса— это исполняемый программный код. Этот код считывается из выполняемого файла (executable) и выполняется в адресном пространстве процесса. Обычно выполнение программы осуществляется в пространстве пользователя.
Контекст прерывания
Контекст прерывания При выполнении обработчика прерывания или обработчика нижней половины, ядро находится в контексте прерывания. Вспомним, что контекст процесса — это режим, в котором работает ядро, выполняя работу от имени процесса, например выполнение системного
Контекст рисования
Контекст рисования Рисование на канве выполняется с помощью особых свойств и методов объекта… нет, не HTMLCanvasElement, а CanvasRenderingContext2D. Этот объект представляет так называемый контекст рисования, который можно рассматривать как набор инструментов, используемый для рисования
2.2.2.1 Контекст процесса
2.2.2.1 Контекст процесса Контекстом процесса является его состояние, определяемое текстом, значениями глобальных переменных пользователя и информационными структурами, значениями используемых машинных регистров, значениями, хранимыми в позиции таблицы процессов и в
6.3 КОНТЕКСТ ПРОЦЕССА
6.3 КОНТЕКСТ ПРОЦЕССА Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе
Поисковый контекст
Поисковый контекст В случае с запросами из нескольких слов «Яндекс» умеет определять, каким должно быть максимальное расстояние между словами, чтобы страница наиболее точно отвечала запросу. Вы можете задать расстояние явным образом.Слова идут подрядТакой порядок слов
Контекст рисования
Контекст рисования Рисование на канве выполняется с помощью особых свойств и методов объекта… нет, не HTMLCanvasElement, а CanvasRenderingContext2D. Этот объект представляет так называемый контекст рисования, который можно рассматривать как набор инструментов, используемый для рисования
1.2 Процесс, контекст процесса и потоки
1.2 Процесс, контекст процесса и потоки Процесс – это образ выполняемой программы в памяти. Процессу назначается область памяти до окончания его работы. Процесс может совместно использовать код (динамически подключаемые библиотеки) или данные (области совместно
Контекст откровения
Контекст откровения Главное событие, решившее судьбу проекта, случилось 31 июля 2001 г., когда «Яндекс» запустил «Яндекс. Директ» — систему автоматического (в режиме онлайн) размещения контекстной рекламы с оплатой по кликам. Контекстная реклама по сей день остается
Контекст устройства
Контекст устройства CancelDC Функция CancelDC отменяет любую незаконченную операцию на указанном контексте устройства. BOOL CancelDC ( HDC hdc // дескриптор контекста устройства ); Параметры hdc - идентифицирует контекст устройства. Возвращаемые значения В случае успеха возвращается
Контекст транзакции
Контекст транзакции Завершенное общение между клиентом и сервером называется транзакцией. Каждая транзакция имеет уникальный контекст, что приводит к тому, что транзакция будет изолирована от всех других транзакций указанным способом. Правила для контекста транзакции
6.3. Контекст устройства
6.3. Контекст устройства Контекст устройства – структура, определяющая набор графических объектов и связанных с ними атрибутов и графических режимов, которые воздействуют на вывод. Графические объекты включают карандаши для рисования линий, кисти для закрашивания и
1.2.1 Графический контекст
1.2.1 Графический контекст Прежде чем начать работу с графикой, программа должна выделить себе специальную структуру данных и получить указатель на нее. Эта структура называется графическим контекстом (Graphic Context (GC)). Указатель на GC используется в качестве одного из
Контекст преобразования
Контекст преобразования При выполнении преобразования каждая из его инструкций, каждый из элементов обрабатывается в некотором контексте. Контекст преобразования состоит из двух частей: из текущего множества узлов и из текущего узла, которые показывают, что именно
Читайте также: