
Какую структуру имеет дескриптор сегмента оперативной памяти
Дескриптор сегмента (в архитектуре x86) — служебная структура в памяти, которая определяет сегмент. Длина дескриптора равна 8 байт .
- База (жёлтые поля, 32 бита) — начало сегмента в линейной памяти
- Лимит (красные поля, 20 бит) — (размер сегмента в байтах)-1 (База+Лимит = линейный адрес последнего байта)
- Права доступа (синие поля, 12 бит) — флаги, определяющие наличие сегмента в памяти, уровень защиты, тип, разрядность + один пользовательский флаг [1]
Младший бит байта AR пользовательских сегментов (A, англ. Accessed , бит 8 на рисунке) можно использовать для сбора статистики о сегменте. При первом же обращении к сегменту (чтение, запись, выполнение) он устанавливается процессором в 1.
- Флаг гранулярности G определяет лимит сегмента: при G=0 лимит равен значению соответствующего поля в дескрипторе, а при G=1 лимит равен полю дескриптора, умноженному на (2 12 = 4096). Таким образом при G=0 максимальный размер сегмента 1 МБайт, а при G=1 4 ГБайт.
- Флаг разрядности DB (бит 22 на рисунке) актуален для пользовательских сегментов кода и стека. Определяет разрядность в 16 бит при нулевом и 32 бит при единичном значении.
- Зарезервированный флаг (серое поле) должен всегда равняться нулю.
- Пользовательский флаг AVL (A, бит 20 на рисунке) отдан операционной системе. Его состояние никак не влияет на работу с сегментом.
Примечания
- ↑ Разорванность полей дескриптора объясняется эволюционированием процессоров.
Логическое адресное пространство
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Логическое адресное пространство
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Ссылки
- Программирование x86
- Виртуальная память
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое "Дескриптор сегмента" в других словарях:
дескриптор сегмента — — [Е.С.Алексеев, А.А.Мячев. Англо русский толковый словарь по системотехнике ЭВМ. Москва 1993] Тематики информационные технологии в целом EN segment descriptor … Справочник технического переводчика
Дескриптор шлюза — Дескриптор шлюза служебная структура данных, служащая для различных переходов. Используется только в защищённом режиме. В реальном режиме некоторым аналогом может служить дальний адрес. Длина дескриптора стандартна и равна восьми байтам.… … Википедия
Дескриптор — (англ. Descriptor): Дескриптор HTML элемент языка разметки гипертекста HTML. В разговорной речи дескрипторы называют тегами. Дескриптор развертывания XML файлы, которые описывают, как развернуть модули. Файловый дескриптор число… … Википедия
Сегментная защита памяти — В этой статье отсутствует вступление. Пожалуйста, допишите вводную секцию, кратко раскрывающую тему статьи. Сегментная защита памяти один из вариантов реализации защиты памяти в процессорах архитектуры x86. Может применяться в защищенном… … Википедия
Регистр процессора — Эта статья включает описание термина «IP»; см. также другие значения. Регистр процессора блок ячеек памяти, образующий сверхбыструю оперативную память (СОЗУ) внутри процессора; используется самим процессором и большой частью недоступен… … Википедия
Сегментная адресация памяти — Эта статья или раздел описывает ситуацию применительно лишь к частным случаям. Необходимо переработать изложение или добавить информацию, чтобы статья описывала более общий случай … Википедия
Program Segment Prefix — (рус. Префикс программного сегмента, PSP) структура данных, которая используется в операционных системах семейства DOS и CP/M для сохранения состояния компьютерных программ. PSP в DOS имеет следующую структуру: Offset (Смещение) Size (Размер)… … Википедия
TSS — (англ. Task State Segment сегмент состояния задачи) специальная структура в архитектуре x86, содержащая информацию о задаче (процессе). Используется ОС для диспетчеризации задач. В TSS содержится информация о: Состоянии регистров… … Википедия
Intel 80286 — > Центральный процессор Микропроцессор Intel 80286 (8 МГц) Производство: с 1 февраля 1 … Википедия
80286 — > Центральный процессор Микропроцесс … Википедия
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Ранее мы увидели как организована виртуальная память процесса. Теперь рассмотрим механизмы, благодаря которым ядро управляет памятью. Обратимся к нашей программе:
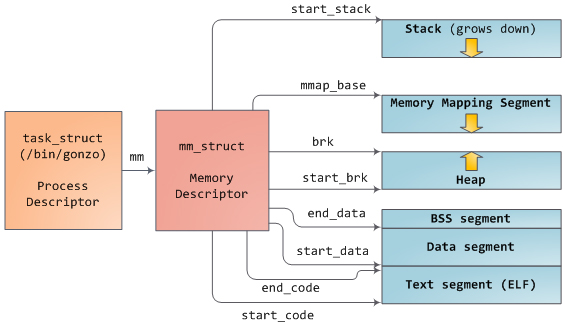
В Linux, процессы реализованы в виде struct-объекта task_struct, который по сути является дескриптором процесса. В поле mm объекта task_struct содержится указатель на т.н. «дескриптор памяти процесса» — struct-объект mm_struct — который содержит исчерпывающую информацию об использовании памяти данным процессом. В дескрипторе памяти процесса хранится информация о начальном и конечном адресе сегментов процесса, как показано на рисунке вверху, число page-фреймов (физических страниц в оперативной памяти), используемых процессом (это RSS или т.н. «резидентный набор страниц»), количество виртуальной памяти, выделенной процессу, и другая мелочь. Дескриптор памяти процесса также указывает на местонахождение дескрипторов VMA (virtual memory area или «область виртуальной памяти») и набора page-таблиц для процесса. Последние две структуры данных — это своего рода «рабочие лошадки», т.к. они задействуются при большинстве операций управления памятью. Области виртуальной памяти для нашей программы указаны на рисунке:

Область виртуальной памяти (VMA) представляет собой непрерывный диапазон виртуальных адресов; области никогда не перекрывают друг друга. Экземпляр struct-объекта vm_area_struct исчерпывающе описывает одну VMA, включая начальный и конечный виртуальный адрес области, флаги, определяющие права и другие особенности доступа к области, поле vm_file с информацией о файле, отображенном в данную область (если таковой файл имеется). Область виртуальной памяти, которая не сопоставлена ни с каким файлом, называется анонимной. Каждому из сегментов программы на вышеприведенном рисунке (куча, стек и т.д.) соответствует своя VMA; исключение в этом отношении состовляет только т.н. «сегмент для мэппирования» (memory mapping segment). Данное положение вещей не является каким-то требованием или чем-то предопределенным, но в случае с платформой x86 это в большинстве случаев именно так. Области виртуальной памяти все равно какому сегменту соответствовать.
Набор VMA для данного процесса описан сразу двумя способами. Во-первых, в дескрипторе памяти процесса (struct-объект mm_struct) имеется указатель mmap на связный список дескрипторов VMA (порядок дескрипторов в списке соответствует порядку следования VMA в виртуальном адресном пространстве). Во-вторых, все в том же дескрипторе памяти имеется указатель mm_rb на структуру, которая представляет собой red-black tree. RB-дерево позволяет ядру быстро устанавливать факт нахождения некоторого виртуального адреса в пределах той или иной виртуальной области. Если посмотреть содержимое файла /proc/pid_of_process/maps в файловой системе proc, то это будет не что иное как информация, полученная ядром в результате «прохода» по связному списку дескрипторов VMA.
В Windows, блок EPROCESS – это, грубо говоря, что-то среднее между структурами task_struct и mm_struct. Аналогом дескриптора области виртуальной памяти является Virtual Address Descriptor или VAD. Информация о VAD дескрипторах храниться в AVL-дереве. Знаете, что самое смешное при сравнении Windows и Linux? Это то, что отличий как раз не так уж и много.

Процессор консультируется с page-таблицами для того, чтобы осуществить преобразование виртуального адреса в физический. У каждого процесса есть свой набор таких page-таблиц; как только происходит переключение процесса (context switch), меняются и page-таблицы для user space-части виртуального адресного пространства. В Linux, указатель на page-таблицы процесса хранится в поле pgd дескриптора памяти процесса. Каждой виртуальной странице соответствует одна запись в page-таблице, и, в случае с классическим x86-пейджингом, это простая 4-байтовая запись, показанная на следующем рисунке:

В ядре Linux есть функции, которые позволяют взвести или обнулить любой флаг в page table записи. Флаг «P» говорит о том, находится ли страница в оперативной памяти или нет. Когда данный флаг установлен в 0, доступ к соответствующей странице вызовет page fault. Нужно учесть, что если данный флаг установлен в 0, то ядро может как угодно использовать оставшиеся биты в page table записи. Флаг «R/W» означает «запись/чтение»; если флаг не установлен, то к странице возможен доступ только на чтение. Флаг «U/S» означает «пользователь/супервайзер»; если флаг не установлен, только код выполняющийся с уровнем привилегий 0 (т.е. ядро) может обратиться к данной странице. Таким образом, данные флаги используются для того, чтобы реализовать концепцию адресного пространства доступного только на запись и пространства, которое доступно только для ядра.
Флаги «D» и «A» означают «dirty» и «accessed». «Dirty-страница» – эта та, в которую была недавно проведена запись, а «accessed»-страница – это страница, к которой было осуществлено обращение (чтение или запись). Оба флага являются «липкими», процессор может их установить, но не будет обнулять – делать это должно ядро. Наконец, page table запись хранит начальный физический адрес страницы в памяти; адрес всегда будет кратным 4 КБ. Это казалось бы безобидное поле является причиной многих проблем, т.к. оно фактически ограничивает размер адресуемой физической памяти 4 гигабайтами. Другие поля page table записи рассмотрим как-нибудь в другой раз, так же как и механизм Physical Address Extension.
Защита памяти осуществляется на постраничной основе, поскольку страница – это самый маленький «кусочек» памяти, для которого можно выставить флаги «U/S» и «R/W». Стоит однако учитывать, что теоретически, две разные виртуальные страницы, имеющие отличающийся набор флагов, могут соответствовать одной и той же физической странице. Заметьте, в формате page table записи не предусмотрены флаги, связанные с запретом на выполнение кода. Иными словами, классический x86-пейджинг никак не препятствует выполнению кода в стеке. Именно поэтому возможно эксплуатирование уязвимостей, в основе которых переполнение буфера в стеке (неисполняемые стеки все равно подвержены уязвимостям; в таком случае используется техника return-to-libc и другие приемы). Отсутсвие no-execute флага также свидетельствует о другом важном аспекте: флаги доступа, содержащиеся в дескрипторе VMA, не всегда имеют прямые соответствия в системе защиты, реализуемой процессором, и соответствуют этой системе лишь в большей или меньшей степени. Образно говоря, ядро делает все, что в его силах, но в конечном счете архитектура процессора накладывает свои ограничения на то, что возможно реализовать.
Конечно же виртуальная память сама по себе ничего не хранит. Виртуальное адресное пространство — это просто абстракция, но оно определенным образом поставлено в соответствие физической памяти. То, как работает адресная шина процессора, вообще говоря, вещь достаточно нетривиальная, но мы сейчас можем от этого абстрагироваться. Будем считать, что процессор работает с диапазоном последовательных адресов от нуля до максимально доступного в системе адреса (в зависимости от количества оперативной памяти) и может при необходимости обратиться к любому байту в этом диапазоне. Физическое адресное пространство рассматривается процессором как последовательность физических страниц (их еще называют page-фреймами). Процессору мало дела до page-фреймов, а вот для ядра они очень важны, т.к. page-фрейм – единица учета и управления физической памятью, которое и осуществляется ядром. 32-битные версии Linux и Windows используют 4-килобайтные page-фреймы; вот пример машины с 2 ГБ оперативной памяти:

Ядро Linux ведет учет каждому page-фрейму с помощью специального дескриптора и нескольких флагов. Взятые вместе, эти дескрипторы описывают всю оперативную память компьютера; в каждый момент времени известно точное состояние любого page-фрейма. В основе управления физической памятью лежит алгоритм Buddy memory allocation. Таким образом, page-фрейм считается свободным, если он доступен для выделения с точки зрения Buddy-алгоритма. Выделенный под использование page-фрейм может быть «анонимным» (в таком случае он содержит данные программы) или он может находиться в т.н. «страничном кэше» (page cache) и хранить порцию данных из некоторого файла или блочного устройства. Существуют и другие, более экзотичные варианты использования page-фреймов, но давайте не будем их сейчас трогать. В Windows также имеется аналогичная структура для учета page-фреймов, и называется она — база данных Page Frame Number.
А теперь, давайте соберем воедино все эти концепции – области виртуальной памяти (VMA), page table-записи и page-фреймы – и посмотрим как это все вместе работает. Далее идет пример кучи в user space области программы:

Прямоугольники с голубым фоном обозначают виртуальные страницы, находящиеся в пределах VMA. Стрелки обозначают page table-записи, с помощью которых виртуальные страницы «мэппируются» в page-фремы (физические страницы). У некоторых виртуальных страниц нет стрелок; это означает, что в соответствующих им page table записях флаг присутствия установлен в 0. Причиной тому может быть то, что данные виртуальные страницы возможно не разу еще не использовались или же потому, что соответствующие им физические страницы были выгружены в своп. В любом случае, попытка доступа к этим страницам приведет к page fault, даже несмотря на то, что виртуальные страницы находятся в пределах некоторой VMA. Может показаться странным, что существует подобного рода разночтение – страницы в пределах VMA и тем не менее доступ к ним является невалидным – но так действительно часто происходит.
VMA представляет собой своего рода «контракт» между программой и ядром. Вы просите ядро выполнить какое-нибудь действие (например, выделить память или замэппировать файл), ядро говорит «без проблем» и создает новую или обновляет существующую VMA. Но ядро при этом не спешит выполнять сами эти действия; вместо этого оно отложит непосредственное выполнение запрошенного действия до того момента, пока не случится page fault. Получается, что ядро – это этакий «ленивый обманщик», и это является основополагающим принципом управления виртуальной памятью. Данный принцип применяется в большинстве ситуаций – некоторые из них могут быть вполне знакомыми, некоторые — неожиданными, но общее правило таково, что VMA лишь фиксирует, то о чем было договорено, в то время как page table-записи отражают то, что непосредственно было сделано ленивым ядром. Эти две структуры вместе учавствуют в управлении памятью программы; обе структуры играют определенную роль при обработке page fault, высвобождении памяти, выгрузке страниц в своп и т.д. Рассмотрим простой случай выделения памяти:

Когда программа запрашивает выделение дополнительной памяти посредством системного вызова brk(), ядро просто напросто обновляет информацию в дескрипторе VMA и на этом считает свою задачу выполненной. В данный момент времени не происходит ни выделение новых page-фреймов, ни размещение их в оперативной памяти. Однако, как только программа попытается обратиться к виртуальной странице, процессор отловит page fault и будет вызван обработчик do_page_fault(). Данная функция осуществит поиск VMA, в пределах которой находится адрес, обращение к которому вызвало page fault. Если такая VMA существует, то дальше прозводится проверка на соответствие между правами доступа к VMA и типом производимого доступа (доступ на чтение или запись). Если же подходящей VMA нет, тогда нет и «контракта», который предусматривал бы возможность обращения к памяти. В последнем случае, процессу посылается сигнал Segmentation Fault, и он завершается.
Допустим, VMA все-таки нашлась. Дальнейшая обработка page fault такая – ядро смотрит на содержимое page table записи и тип VMA. В нашем примере, page table запись свидетельствует о том, что страницы в памяти нет. Более того, наша запись совершенно пустая (состоит из одних нулей), и в Linux это означает, что соответствующая виртуальная страница вообще еще ни разу не была замэппирована. Поскольку мы имеем дело с «анонимной» VMA, то все дальнейшие действия будут связаны только с оперативной памятью, и для обработки данной ситуации вызывается функция do_anonymous_page(). Данная функция производит выделение page-фрейма и мэппирует в него виртуальную страницу путем внесения нужных данных в page table запись.
Дело могли обстоять и иначе. Page table запись для выгруженной в своп страницы, к примеру, имеет флаг присутствия установленный в 0, но остальная часть записи непустая. Остальные биты хранят информацию о нахождении страницы в свопе. Функция do_swap_page() считывает содержимое этой страницы с диска и загружает страницу в оперативную память. Подобного рода page fault называют major fault.
На этом завершим первую часть нашего экскурса в то, как ядро управляет памятью. В следующей статье мы усложним картину, дополнив её работой с файлами — таким образом получим более полное представление об основных концепциях управления памятью, включая и некоторые аспекты производительности.
Аннотация: Изучение механизмов формирования физического адреса при различной организации логического адресного пространства. Организация памяти микропроцессорной системы один из важнейших компонентов, влияющий на многие параметры ее работы: защиту данных, мультипрограммирование, работу кэш-памяти и т. д. Поэтому изучение принципов построения памяти как на логическом, так и на физическом уровне является одним из ключевых моментов данного курса, и данному вопросу будет уделено достаточно много внимания.
См. также
Формирование физического адреса в универсальном микропроцессоре при различных режимах работы
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 2 16 байт .
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
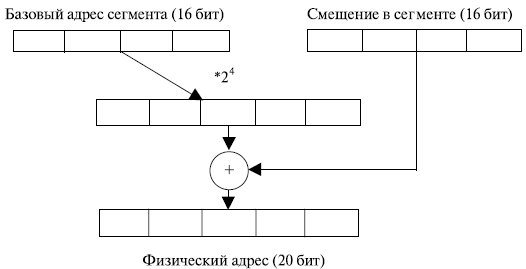
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
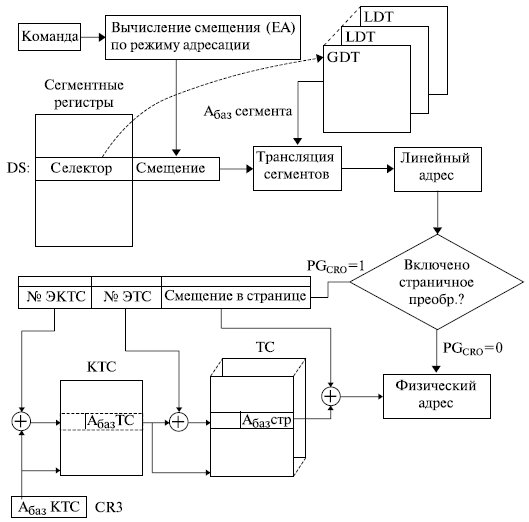
Общая схема формирования физического адреса микропроцессором , работающим в защищенном режиме, представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес . Он состоит из двух частей: селектора и смещения в сегменте.
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной ( GDT ) и локальных ( LDT ) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора , от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора , работающего в защищенном режиме, характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в
Структура дескриптора сегмента представлена на рис. 3.3.
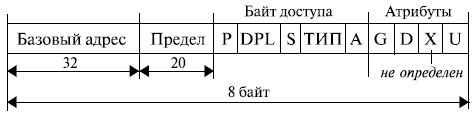
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G ( Granularity - гранулярность , или дробность):

Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0 ). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (при G = l ):

Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности ( Default size ) определяет длину адресов и операндов, используемых в команде по умолчанию:

Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память , как временно отсутствующий, устанавливая в его дескрипторе P = 0 . При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL ( Descriptor Privilege Level ) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора, определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты , к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S ( System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0 , то этот дескриптор описывает специальный системный объект , который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT . Назначение битов байта доступа определяется типом сегмента (рис. 3.4).
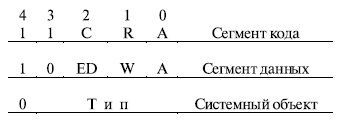
В сегменте кода: бит подчинения, или согласования, C ( Conforming ) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R ( Readable ) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание .
В сегменте данных:
- ED ( Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable) . При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание .
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP .
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти , то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы , а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
Аннотация: Изучение механизмов формирования физического адреса при различной организации логического адресного пространства. Организация памяти микропроцессорной системы один из важнейших компонентов, влияющий на многие параметры ее работы: защиту данных, мультипрограммирование, работу кэш-памяти и т. д. Поэтому изучение принципов построения памяти как на логическом, так и на физическом уровне является одним из ключевых моментов данного курса, и данному вопросу будет уделено достаточно много внимания.
Формирование физического адреса в универсальном микропроцессоре при различных режимах работы
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 2 16 байт .
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
Общая схема формирования физического адреса микропроцессором , работающим в защищенном режиме, представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес . Он состоит из двух частей: селектора и смещения в сегменте.
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной ( GDT ) и локальных ( LDT ) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора , от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора , работающего в защищенном режиме, характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в
Структура дескриптора сегмента представлена на рис. 3.3.
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G ( Granularity - гранулярность , или дробность):
Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0 ). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (при G = l ):
Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности ( Default size ) определяет длину адресов и операндов, используемых в команде по умолчанию:
Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память , как временно отсутствующий, устанавливая в его дескрипторе P = 0 . При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL ( Descriptor Privilege Level ) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора, определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты , к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S ( System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0 , то этот дескриптор описывает специальный системный объект , который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT . Назначение битов байта доступа определяется типом сегмента (рис. 3.4).
В сегменте кода: бит подчинения, или согласования, C ( Conforming ) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R ( Readable ) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание .
В сегменте данных:
- ED ( Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable) . При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание .
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP .
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти , то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы , а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
Читайте также: