
Какой рекомендуемый трансфер жесткого диска
Гибридные тесты
самая вкусная часть:
(внимание! Ошибётесь буквой диска — останетесь без данных)
Во время теста мы видим что-то вроде такого:
В квадратных скобках — цифры IOPS'ов. Но радоваться рано — ведь нас интересует latency.
На выходе (по Ctrl-C, либо по окончании) мы получим примерно вот такое:
^C
fio: terminating on signal 2
Нас из этого интересует (в минимальном случае) следующее:
read: iops=3526 clat=9063.18 (usec), то есть 9мс.
write: iops=2657 clat=12028.23
Не путайте slat и clat. slat — это время отправки запроса (т.е. производительность дискового стека линукса), а clat — это complete latency, то есть та latency, о которой мы говорили. Легко видеть, что чтение явно производительнее записи, да и глубину я указал чрезмерную.
В том же самом примере я снижаю iodepth до 16/16 и получаю:
read 6548 iops, 2432.79usec = 2.4ms
write 5301 iops, 3005.13usec = 3ms
Очевидно, что глубина в 64 (32+32) оказалась перебором, да таким, что итоговая производительность даже упала. Глубина 32 куда более подходящий вариант для теста.

IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
По сути, IOPS это количество блоков, которое успевает считаться или записаться на носитель. Чем больше размер блока, тем меньше кусков, из которых состоит файл, и тем меньше будет IOPS, так как на чтение куска большего размера будет затрачиваться больше времени.
Значит, для определения IOPS надо знать скорость и размер блока при операции чтения / записи. Параметр IOPS равен скорости, деленной на размер блока при выполнении операции.
Характеристики производительности
Основными измеряемыми величинами являются операции линейного (последовательного) и произвольного (случайного) доступа.

Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К). При произвольных операциях данные читаются случайно из разных областей носителя, обычно они ассоциируются с размером блока 4 Кбайт.
Ниже приведены основные характеристики:
| Параметр | Описание |
| Всего IOPS (Total IOPS) | Суммарное число операций ввода/вывода в секунду (при выполнении как чтения, так и записи) |
| IOPS произвольного чтения (Random Read) | Среднее число операций произвольного чтения в секунду |
| IOPS произвольной записи (Random Write) | Среднее число операций произвольной записи в секунду |
| IOPS последовательного чтения (Sequential Read) | Среднее число операций линейного чтения в секунду |
| IOPS последовательной записи (Sequential Write) | Среднее число операций линейной записи в секунду |
Приблизительные значения IOPS
Приблизительные значения IOPS для жестких дисков.
| Устройство | Тип | IOPS | Интерфейс |
| 7,200 об/мин SATA-диски | HDD | ~75-100 IOPS | SATA 3 Гбит/с |
| 10,000 об/мин SATA-диски | HDD | ~125-150 IOPS | SATA 3 Гбит/с |
| 10,000 об/мин SAS-диски | HDD | ~140 IOPS | SAS |
| 15,000 об/мин SAS-диски | HDD | ~175-210 IOPS | SAS |
Приблизительные значения IOPS для SSD.
| Устройство | Тип | IOPS | Интерфейс |
| Intel X25-M G2 MLC | SSD | ~8 600 IOPS | SATA 3 Гбит/с |
| OCZ Vertex 3 | SSD | ~60 000 IOPS (Произвольная запись 4K) | SATA 6 Гбит/с |
| OCZ RevoDrive 3 X2 | SSD | ~200 000 IOPS (Произвольная запись 4K) | PCIe |
| OCZ Z-Drive R4 CloudServ | SSD | ~1 400 000 IOPS | PCIe |
RAID пенальти
Любые операции чтения, которые выполняются на дисках, не подвергаются никакому пенальти, поскольку все диски могут использоваться для операций чтения. Но всё на оборот с операциями на запись. Количество пенальти на запись зависят от типа выбранного RAID-а, например.
В RAID 1 чтобы данные записались на диск, происходит две операции на запись (по одной записи на каждый диск), и следовательно RAID 1 имеет два пенальти.
В RAID 5 чтобы записать данные происходит 4 операции (Чтение существующих данных, четность RAID, Запись новых данных, Запись новой четности) тем самым пенальти в RAID 5 составляет 4.
В этой таблице приведено значение пенальти для более часто используемых RAID конфигурации.
| RAID | I/O Пенальти |
| RAID 0 | 1 (Edited by Reader) |
| RAID 1 | 2 |
| RAID 5 | 4 |
| RAID 6 | 6 |
| RAID 10 | 2 |
Характеристика рабочих нагрузок
Характеристика рабочей нагрузки в основном рассматривается как процент операции чтений и записей, которые вырабатывает или требует приложение. Например, в среде VDI процентное соотношение IOPS рассматривается как 80-90% на запись и 10-20% на чтение. Понимание характеристики рабочей нагрузки является наиболее критическим фактором, поскольку от этого и зависит выбор оптимального RAID для среды. Приложения которые интенсивно используют операции на запись являются хорошими кандидатами для RAID 10, тогда как приложения которые интенсивно используют операции на чтение могут быть размещены на RAID 5.
Вычисление IOPS
Есть два сценария вычисления IOPS-ов.
Один из сценариев это когда есть определенное число дисков, и мы хотим знать, сколько IOPS эти диски выдадут?
Второй сценарий, когда мы знаем сколько нам IOPS-ов надо, и хотим вычислить нужное количество дисков?
Сценарий 1: Вычисление IOPS исходя из определенного кол-ва дисков
Представим что у нас есть 20 450GB 15к RPM дисков. Рассмотрим два сценария Рабочей нагрузки 80%Write-20%Read и другой сценарий с 20%Write-80%Read. Также мы вычислим количество IOPS как для RAID5 и RAID 10.
Формула для расчета IOPS:
Total Raw IOPS = Disk Speed IOPS * Number of disks
Functional IOPS =(((Total Raw IOPS×Write %))/(RAID Penalty))+(Total Raw IOPS×Read %)
Есть определение Raw IOPS и Functional IOPS, как раз токи Functional IOPS-ы и есть те IOPS-ы которые включают в себя RAID пенальти, и это и есть “настоявшие” IOPS-ы.
А теперь подставим цифры и посмотрим что получится.
Total Raw IOPS = 170*20 = 3400 IOPS (один 15K RPM диск может выдать в среднем 170 IOPS)
Для RAID-5
Вариант 1 (80%Write 20%Read) Functional IOPS = (((3400*0.8))/(4))+(3400*0.2) = 1360 IOPS
Вариант 2 (20%Write 80%Read) Functional IOPS = (((3400*0.2))/(4))+(3400*0.8) = 2890 IOPS
Для RAID-1
Вариант 1 (80%Write 20%Read) Functional IOPS = (((3400*0.8))/(2))+(3400*0.2) = 2040 IOPS
Вариант 2 (20%Write 80%Read) Functional IOPS = (((3400*0.2))/(2))+(3400*0.8) = 3100 IOPS
Сценарий 2: Подсчет кол-ва дисков для достижения определенного кол-ва IOPS
Рассмотрим ситуацию где нам надо определить тип RAID-а и количества дисков для достижения определенного количества IOPS-ов 5000 и с определенными рабочими нагрузками, например 80%Write20%Read и 20%Write80% Read.
Опять же для начала формула по которой и будем считать:
Total number of Disks required = ((Total Read IOPS + (Total Write IOPS*RAID Penalty))/Disk Speed IOPS)
Total IOPS = 5000
Теперь подставим цифры.
Заметка: 80% от 5000 IOPS = 4000 IOPS и 20% от 5000 IOPS = 1000 IOPS с этими цифрами и будем оперировать.
Для RAID-5
Вариант 1 (80%Write20%Read) – Total Number of disks required = ((1000+(4000*4))/170) = 100 дисков.
Вариант 2 (20%Write80%Read) – Total Number of disks required = ((4000+(1000*4))/170) = 47 дисков приблизительно.
Для RAID-1
Вариант 1 (80%Write20%Read) – Total Number of disks required = ((1000+(4000*2))/170) = 53 диска приблизительно.
Вариант 2 (20%Write80%Read) – Total Number of disks required = ((4000+(1000*2))/170) = 35 дисков приблизительно.
Понимание и подсчет IOPS, RAID пенальти, и характеристик рабочих нагрузок очень критичны аспект при планировании. Когда нагрузка более интенсивна на запись луче выбирать RAID 10 и наоборот при нагрузках на чтение RAID 5.
Программы для измерения IOPS
IOmeter — тест IOPS
IOzone — тест IOPS
FIO — тест IOPS
CrystalDiskMark — тест IOPS
SQLIO — набор тестов для расчета производительности (IOPS, MB, Latency) под сервера БД
wmarow — калькулятор RAID групп по производительности IOPS
Производительность жестких дисков при подключении по USB.
В последнее время все большую популярность приобретают различные USB аксессуары к жестким дискам: внешние боксы, док-станции. Не меньшей популярностью пользуются портативные жесткие диски. Самое время задуматься: а как обстоят дела с производительностью у подобных решений?
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Вполне очевидно, что производительность подобных устройств будет ниже, чем у классического жесткого диска, гораздо более важно - насколько.
Если не считать использования USB дисков в качестве "большой флешки", то наиболее часто их применяют в качестве рабочего диска для хранения и работы с документами, базами данных, в том числе совместного, в этом случае к диску открывается общий доступ по сети.
Обычно такой подход практикуется в небольших организациях, где сотрудников немного и они могут работать как в офисе, так и дома, а также в домашних сетях, где на первый план выходит возможность оперативно снять диск и пойти с ним, скажем, в гости.
Перед тем, как переходить к тестированию, стоит навести порядок в значениях скоростей интерфейсов, так как неправильное толкование этих значений способно привести к неправильным выводам, а различные маркетинговые уловки этому только способствуют.
Во первых нужно раз и навсегда запомнить, что для измерения скорости передачи данных могут использоваться две единицы бит в секунду (бит/с) и байт в секунду (Б/с). Так как в одном байте 8 бит, то скорость выраженная в Б/с будет в восемь раз меньше скорости в бит/с.
Скорость интерфейсов как правило выражается в бит/с: Ethernet 100 Мбит/с, SATA 6 Гбит/с и т.п., в то время как скорость передачи данных в Б/с.
Классический пример непонимания разницы: подключив интернет со скоростью тарифа, скажем 8 Мбит/с пользователь совершенно искренне недоумевает, почему скорость скачки не превышает 1 МБ/с. Поэтому сделаем небольшую памятку, чтобы в будущем не возникало вопросов:
Стоит обратить внимание, что для SATA указана реальная пропускная способность, с учетом накладных расходов (10b/8b кодирование).
Тесты на запись
(внимание! Ошибётесь буквой диска — останетесь без данных)
Тестовый стенд
Для тестирования мы использовали два ПК, один основной, к которому подключались тестируемые диски, и второй, дополнительный, в качестве клиента при тестировании скорости передачи по сети.
Основной ПК
- Материнская плата: ASUS P8P67 LE rev3.0 LGA1155
- Процессор: Intel Core i5-2500 3.3 ГГц
- Оперативная память: 8 Гб, 2 х Kingston ValueRAM DDR-III DIMM 4Gb
- Дисковая система: RAID0 2 х 1 Tb SATA 6Gb/s Western Digital Caviar Black 7200rpm 64Mb
- Операционная система: Windows 7 Professional 64-bit
Дополнительный ПК
- Материнская плата: ASUS P8H61-M EVO rev3.0 LGA1155
- Процессор: Intel Pentium G620 2.6 ГГц
- Оперативная память: 2 Гб, 2 х Kingston ValueRAM DDR-III DIMM 1Gb
- Дисковая система: 500 Gb SATA-II 300 Western Digital Caviar Blue 7200rpm 16Mb
- Операционная система: Windows 7 Professional 32-bit
В качестве тестируемого диска мы использовали еще один 1 Tb SATA 6Gb/s Western Digital Caviar Black 7200rpm 64Mb и внешний бокс AgeStar .
Производительность дисковой подсистемы - краткий ликбез.
Когда заходит речь о производительности в первую очередь обращают внимание на частоту процессора, скорость памяти, чипсет и т.д. и т.п., про дисковую подсистему если и вспоминают, то мимоходом, чаще всего обращая внимание только на один параметр - скорость линейного чтения. В тоже время именно дисковая подсистема чаще всего становится узким местом в системе. Почему так происходит и как этого избежать мы расскажем в данной статье.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Прежде чем говорить о производительности вспомним как устроен жесткий диск, так как многие особенности и ограничения HDD заложены именно на физическом уровне. Не вдаваясь в подробности, можно сказать что диск состоит из одной или нескольких магнитных пластин над которыми расположен блок магнитных головок, пластины в свою очередь содержат намагниченные концентрические окружности - цилиндры (дорожки), которые в свою очередь состоят из небольших фрагментов - секторов. Сектор - минимальное адресуемое пространство диска, его размер традиционно составляет 512 байт, хотя некоторые современные диски имеют более крупный сектор размером в 4 Кбайт.
Во время вращения диска сектора проходят мимо блока магнитных головок, которые осуществляют запись или чтение информации. Скорость вращения (угловая скорость) диска в конечный момент времени величина постоянная, однако линейная скорость различных участков диска различна. У внешнего края диска она максимальна, у внутреннего - минимальна. Рассмотрим следующий рисунок:
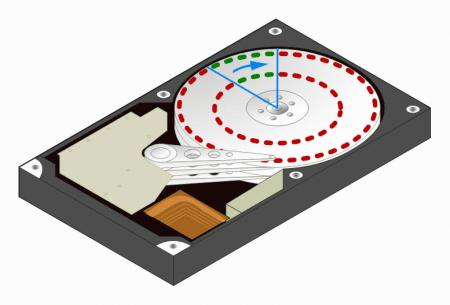
Как видим за один и тот же промежуток времени определенная область диска сделает поворот на один и тот же угол, если мы обозначим эту область в виде сектора, то окажется что в него попадет пять секторов с внешней дорожки и только три с внутренней. Следовательно за данный промежуток времени магнитная головка считает с внешнего цилиндра большее количество информации, чем с внутреннего. На практике это проявляется в том, что график скорости чтения любого диска представляет собой снижающуюся кривую.
Начальные сектора и цилиндры всегда располагаются с внешней стороны, обеспечивая максимальную скорость обмена данными, поэтому рекомендуется размещать системный раздел именно в начале диска.
Теперь перейдем на более высокий уровень - уровень файловой системы. Файловая система оперирует более крупными блоками данных - кластерами. Типичный размер кластера NTFS - 4 Кб или 8 секторов. Получив указание считать определенный кластер диск произведет чтение 8 последовательных секторов, при последовательном расположении данных операционная система даст указание считать данные начиная с кластера 100 и заканчивая кластером 107. Данное действие будет представлять собой одну операцию ввода-вывода (IO), максимальное количество таких операций в секунду (IOPS) конечно и зависит от того, сколько секторов пройдут мимо головки за единицу времени (а также от времени позиционирования головки). Скорость обмена данными измеряется в МБ/с (MBPS) и зависит от того, какое количество данных будет считано за одну операцию ввода-вывода. При последовательном расположении данных скорость обмена будет максимальной, а количество операций ввода-вывода минимально.

Здесь будет не лишним вспомнить о таком параметре как плотность записи, которая выражается в площади необходимой для записи 1 бита данных. Чем выше этот параметр, тем больше данных может вместить одна пластина и тем выше скорость линейного обмена данными. Этим объясняются более высокие скоростные характеристики современных винчестеров, хотя технически они могут ничем не отличаться от более старых моделей. Рисунок ниже иллюстрирует данную ситуацию. Как несложно заметить, при более высокой плотности записи за один и тот-же промежуток времени, при той же самой скорости вращения будет считано/записано большее количество данных
Теперь разберем прямо противоположную ситуацию, нам требуется считать большое количество небольших файлов случайным образом разбросанных по всему диску. В этом случае количество операций ввода-вывода будет велико, а скорость обмена данными низка. Основное время будет занимать ожидание доступа к следующему блоку данных, которое зависит от времени позиционирования головки и задержки из-за вращения диска. Простой пример: если после 100 сектора поступит команда прочитать 98, то придется ждать полный оборот диска, пока появится возможность прочитать данный сектор. Сюда же следует добавить время, которое требуется чтобы физически прочитать нужное количество секторов. Совокупность этих параметров составит время случайного доступа, которое имеет очень большое влияние на производительность винчестера.

Следует отметить, что для ОС и многих серверных задач (СУБД, виртуализация и т.п.) характерен именно случайный доступ с размером блока в 4 Кб (размер кластера), при этом основным показателем производительности будет не скорость линейного обмена данными (MBPS), а максимальное количество операций ввода-вывода в секунду (IOPS). Чем выше этот параметр, тем большее количество данных может быть считано в единицу времени.
Однако количество операций ввода-вывода не может расти бесконечно, это значение очень жестко ограничено сверху физическими показателями винчестера, а именно временем случайного доступа.
А теперь поговорим о фрагментации, суть этого явления общеизвестна, мы же посмотрим на него сквозь призму производительности. Для крупных файлов и линейных нагрузок фрагментация способна значительно снизить производительность, так как последовательный доступ превратится в случайный, что вызовет резкое снижение скорости доступа и также резко увеличит количество операций ввода-вывода.
При случайном характере доступа фрагментация не играет особой роли, так как нет никакой разницы в каком именно месте диска находится тот или иной блок данных.
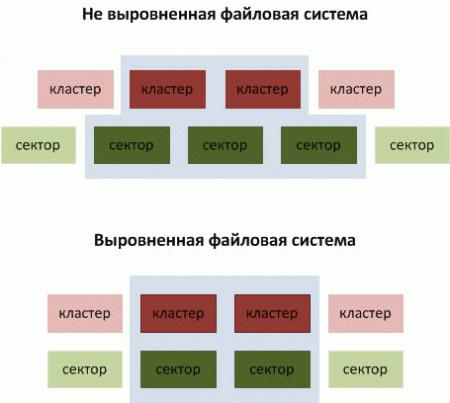
Появление дисков с более крупным 4 Кб сектором стало причиной появления еще одной проблемы: выравнивания файловой системы относительно секторов диска. Здесь возможны два варианта: если файловая система выровнена, то каждому кластеру соответствует сектор, если не выровнена, то каждому кластеру соответствует два смежных сектора. А так как сектор это минимальная адресуемая единица, то для считывания одного кластера потребуется считать не один, а два сектора, что негативно скажется на производительности, особенно при случайном доступе.
Реальная производительность жесткого диска - это всегда баланс между скоростью обмена данными и количеством операций ввода вывода. Для последовательного чтения характерен большой размер пакета данных, который считывается за одну операцию ввода вывода. Максимальная скорость (MBPS) будет достижима при последовательном чтении секторов с внешнего края диска, количество операций ввода-вывода (IOPS) будет при этом минимально - дорожки длинные, позиционировать головку нужно реже, данных при этом считывается больше. На внутренних дорожках линейная скорость будет ниже, количество IO - выше, дорожки короткие, позиционировать головку нужно чаще, данных считывается меньше.
При случайном доступе скорость будет минимальна, так как размер пакета данных очень мал (в худшем случае кластер) и производительность упрется в максимально доступное количество IOPS. Для современных массовых дисков это значение равно около 70 IOPS, нетрудно посчитать, что при случайном доступе с размером пакета в 4 Кб мы получим максимальную скорость не более 0,28 MBPS.
Непонимание этого момента часто приводит к тому, что дисковая подсистема оказывается бутылочным горлышком, которое тормозит работу всей системы. Так, выбирая между двумя дисками с максимальной линейной скоростью в 120 и 150 MBPS, многие не задумываясь выберут второй, не посмотрев на то, что первый диск обеспечивает 70 IOPS, а второй всего 50 IOPS (вполне характерная ситуация для экономичных серий), а потом будут сильно удивляться тому, почему "более быстрый" диск сильно тормозит.
Что будет, если количества IOPS диска окажется недостаточно чтобы обработать все запросы? Возникнет очередь дисковых запросов. На практике все несколько сложнее и очередь диска будет возникать даже в том случае, когда IOPS достаточно. Это связано с тем, что различные процессы, обращающиеся к диску, имеют разный приоритет, а также то, что операции записи всегда имеют приоритет над операциями чтения. Для оценки ситуации существует параметр длина очереди диска, значение которого не должно превышать (по рекомендациям Microsoft)
В любом случае постоянная большая длина очереди говорит о том, что системе недостаточно текущего значения IOPS. Увеличение очереди диска на уже работающих системах говорит либо о увеличении нагрузки, либо о выходе из строя или износе жестких дисков. В любом случае следует задуматься об апгрейде дисковой подсистемы.
На этом мы закончим наш сегодняшний материал, приведенной информации должно быть достаточно для понимания физических процессов, происходящих при работе жесткого диска и того, как они влияют на производительность. В следующих статьях мы рассмотрим, как правильно определить, какое количество IOPS нужно в зависимости от характера нагрузки и как правильно спроектировать дисковую подсистему, чтобы она удовлетворяла предъявляемым требованиям.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Несмотря на то, что стоимость 1 гигабайта на твердотельных накопителях стремительно дешевеет в последние годы, жесткие диски всё ещё остаются в несколько раз более дешёвым способом хранения информации. Там, где не нужна высокая скорость чтения и записи, HDD до сих пор остаются актуальными.
Выбор внешнего HDD несколько сложнее, чем выбор обычного жесткого диска. Ассортимент внешних накопителей довольно большой, однако производители очень редко указывают полный перечень характеристик, как в случае с «внутренними» HDD. Из-за этого некоторые пользователи предпочитают отдельно приобретать жесткий диск и «коробку» со встроенным переходником Sata-USB для самостоятельной сборки внешнего HDD.

Такой подход в случае дисков с большим объёмом памяти выходит слишком накладным, ведь внешние HDD очень часто стоят дешевле внутренних такого же объема. О причинах этого явления (с примерами) я рассказывал в этом материале. И раз уж внешние жесткие диски до сих пор актуальны, то предлагаю рассмотреть ключевые моменты при выборе данного типа накопителей.
Содержание
Форм-фактор

Все современные внешние HDD содержат в себе один или несколько жестких дисков форм-фактора 2.5 или 3.5 дюйма. Объем памяти современных внешних HDD 2.5" может составлять от 500 Гб до 5 Тб. В случае 3.5-дюймовых решений — от 4 Тб до 28 Тб.
Преимущества накопителей 2.5"
- компактность;
- низкий вес;
- повышенная ударостойкость;
- работа без дополнительного питания;
- низкий уровень шума.
Таким образом, если внешний жесткий диск планируется использовать в том числе вне дома, то выбирать нужно среди 2.5-дюймовых внешних HDD. Если нужен недорогой накопитель с объемом менее 4 Тб, то это только 2.5".
Преимущества накопителей 3.5"
- более низкая цена в пересчете на 1 Гб памяти;
- более высокая скорость чтения и записи файлов.
Размеры и вес перестают играть решающую роль в случае «стационарного» использования накопителя дома или в офисе, поэтому для таких сценариев внешние HDD на 3.5 дюйма более уместны.
Скоростные показатели HDD 2.5"

Большинство современных внешних HDD 2.5" демонстрируют скорость линейных записи и чтения на уровне 120 — 140 МБ/с. Отличия между конкретными экземплярами довольно незначительны из-за того, что все внешние жесткие диски в этом форм-факторе предлагают скорость вращения шпинделя только в 5400 об/мин. Да и технология записи в них — исключительно SMR.
В продаже можно найти немногочисленные внутренние HDD 2.5" на 7200 об/мин с технологией записи CMR, и они куда более шустрые. Однако внутрь внешних HDD в данный момент такие модели не ставят.
Отличия методов записи CMR и SMR неплохо описаны в Википедии. Если вкратце: метод SMR позволяет снизить цену накопителей в пересчете за 1 Гб, а также увеличить емкость HDD. Одновременно с этим он приводит к снижению скорости записи и перезаписи.
Подытоживая: какой бы внешний HDD 2.5" вы ни выбрали, его скорость будет мало отличаться от конкурентов.
Скоростные показатели HDD 3.5"
А вот с жесткими дисками 3.5" ситуация сложнее. Скорость вращения шпинделя может быть как 5400, так и 7200 об/мин, а метод записи — как CMR, так и SMR. Производители на официальных сайтах практически никогда не озвучивают эти параметры для своих внешних накопителей, поэтому пользователям приходится разбираться самостоятельно. К счастью, в интернете немало информации о «начинке» различных внешних HDD.

Как видно из таблички выше, в случае с внешними накопителями Seagate всё просто: экземпляры с объемом в 10 Тб и более содержат в себе шустрые диски с технологией записи CMR и со скоростью вращения в 7200 об/мин. Что касается вариантов от 4 до 8 Тб, то они довольствуются SMR и 5400 об/мин. Ситуация несколько сложнее с решениями от Western Digital:

У WD всё сильно зависит от модели. Более того, для каждой модели существует несколько вариантов «начинки». Например, в случае WD Black D10 внутри коробки может скрываться как WD Black, так и Ultrastar DC HC320 или HC520. Однако в любом случае скорость вращения составит 7200 об/мин, а технология записи — исключительно CMR.
Это позволяет накопителям WD D10 достигать скорости чтения и записи в ~ 260 МБ/с. Диски на 5400 об/мин с CMR способны обеспечить скорость в ~ 210 МБ/с. Экземпляры на 5400 об/мин с SMR демонстрируют в среднем ~ 180 МБ/с. Приведенные выше цифры характеры для пустых накопителей. Быстродействие будет ухудшаться по мере заполнения, скорость линейного чтения и записи может снижаться примерно вдвое.
Бренды

Когда-то обычные «внутренние» жесткие диски производила целая дюжина компаний. После ряда банкротств, слияний и поглощений осталось всего 3 производителя: Seagate, WD и Toshiba. Однако внешние накопители производит не только эта троица. На базе их жестких дисков собирает внешние HDD целый ряд сторонних производителей, таких как Transcend и Adata.
Последние могут предлагать фирменный софт разной степени полезности, создавать усиленные противоударные и водонепроницаемые корпуса, при этом внутри будет та же самая «начинка», что и у большой тройки.
При выборе бренда следует учитывать один нюанс. Внешние винчестеры 2.5" от сторонних производителей всегда можно разобрать, снять переходник USB-Sata, и установить жесткий диск внутрь ПК или ноутбука, подключив его к интерфейсу Sata. А вот с изделиями от Western Digital и Toshiba такой трюк зачастую не пройдет, так как разъём USB в их случае впаян на сам жесткий диск. Внешние HDD от Seagate пока что не последовали примеру WD и Toshiba, но в будущем это может измениться.
Надёжность

Если говорить о надёжности накопителей, то здесь сложно определить однозначного победителя. Более-менее подробную статистику отказоустойчивости HDD регулярно публикует компания Backblaze, но у них в основном данные по серверным накопителям 3.5" и вообще нет данных по дискам 2.5".
Что касается условий гарантии, то большинство моделей внешних HDD от большой тройки вне зависимости от форм-фактора поставляется с 2-летней гарантией. Несколько реже встречается гарантия на 3 года. Среди 2.5-дюймовых дисков этим могут похвастаться Toshiba Canvio Flex, Canvio Slim и WD Black P10. Среди моделей на 3.5 дюйма 3-летняя гарантия встречается у WD Black D10.
А вот у сторонних производителей 3-летняя гарантия — это скорее стандарт: все внешние HDD от Transcend, Adata и Silicon Power независимо от форм-фактора поставляются с гарантией на 3 года. Продолжительность гарантии для огромного множества моделей внешних (и не только) HDD удобно смотреть вот тут.
Выводы
Выбор портативного HDD в форм-факторе 2.5" — дело нехитрое. Следует обращать внимание на продолжительность гарантии, особенности корпуса (водонепроницаемость / ударостойкость) и цену.
Выбирать стационарный внешний HDD 3.5" нужно более осознанно, так как характеристики «начинки» могут сильно повлиять на опыт использования. Внутри таких накопителей могут располагаться как тихие и медленные винчестеры из пользовательского сегмента, так и быстрые, но шумные серверные HDD.
Выводы
Какие выводы можно сделать из полученных нами результатов? Сегодня все довольно очевидно: если у вас нет особых требований к производительности дисковой системы и на первый план выходит удобство и мобильность, то внешние диски с подключением через USB 2.0, это то, что вам нужно.
Подобный диск вполне справится с ролью сетевого накопителя в 100 Мбит/с сети или домашнего файлового сервера. Однако для производительных решений стоит выбрать подключение дисков посредством SATA интерфейса.
Также нет никакого смысла в приобретении высокопроизводительных дисков для внешних боксов, лучше обратите внимание на другие характеристики, такие как: энергопотребление, нагрев, уровень шума и вибрации.
Надеемся, что результаты нашего исследования помогут вам сделать правильный выбор и получить оптимальное решение при минимальных затратах.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
bonnie++ и iozone меряют скорость файловой системы. Которая зависит от кеша, задумчивости ядра, удачности расположения FS на диске и т.д. Косвенно можно сказать, что если в iozone получились хорошие результаты, то это либо хороший кеш, либо дурацкий набор параметров, либо действительно быстрый диск (угадайте, какой из вариантов достался вам). bonnie++ вообще сфокусирована на операциях открытия/закрытия файлов. т.е. производительность диска она особо не тестирует.
dd без опции direct показывает лишь скорость кеша — не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
С опцией же direct (iflag=direct для чтения, oflag=direct для записи) dd проверяет лишь линейную скорость. Которая совершенно не равна ни максимальной скорости (если мы про рейд на много дисков, то рейд в несколько потоков может отдавать большую скорость, чем в один), ни реальной производительности.
IOmeter — лучше всего перечисленного, но у него есть проблемы при работе в linux. 64-битная версия неправильно рассчитывает тип нагрузки и показывает заниженные результаты (для тех, кто не верит — запустите его на ramdisk).
Спойлер: правильная утилита для linux — fio. Но она требует очень вдумчивого составления теста и ещё более вдумчивого анализа результатов. Всё, что ниже — как раз подготовка теории и практические замечания по работе с fio.
(текущая VS максимальная производительность)
Сейчас будет ещё больше скучных букв. Если кого-то интересует количество попугаев на его любимой SSD'шке, ноутбучном винте и т.д. — см рецепты в конце статьи.
Все современные носители, кроме ramdisk'ов, крайне негативно относятся к случайным операциям записи. Для HDD нет разницы запись или чтение, важно, что головки гонять по диску. Для SSD же случайная операция чтения ерунда, а вот запись малым блоком приводит к copy-on-write. Минимальный размер записи — 1-2 Мб, пишут 4кб. Нужно прочитать 2Мб, заменить в них 4кб и записать обратно. В результате в SSD'шку уходит, например, 400 запросов в секундну на запись 4кб которые превращаются в чтение 800 Мб/с (. ) и записи их обратно. (Для ramdisk'а такая проблема могла бы быть тоже, но интрига в том, что размер «минимального блока» для DDR составляет около 128 байт, а блоки в тестах обычно 4кб, так что гранулярность DDR в тестах дисковой производительности оперативной памяти не важна).
Этот пост не про специфику разных носителей, так что возвращаемся к общей проблеме.
Мы не можем мерять запись в Мб/с. Важным является сколько перемещений головки было, и сколько случайных блоков мы потревожили на SSD. Т.е. счёт идёт на количество IO operation, а величина IO/s называется IOPS. Таким образом, когда мы меряем случайную нагрузку, мы говорим про IOPS (иногда wIOPS, rIOPS, на запись и чтение соотв.). В крупных системах используют величину kIOPS, (внимание, всегда и везде, никаких 1024) 1kIOPS = 1000 IOPS.
И вот тут многие попадают в ловушку первого рода. Они хотят знать, «сколько IOPS'ов» выдаёт диск. Или полка дисков. Или 200 серверных шкафов, набитые дисками под самые крышки.
Тут важно различать число выполненных операций (зафиксировано, что с 12:00:15 до 12:00:16 было выполнено 245790 дисковых операций — т.е. нагрузка составила 245kIOPS) и то, сколько система может выполнить операций максимум.
Число выполненых операций всегда известно и легко измерить. Но когда мы говорим про дисковую операцию, мы говорим про неё в будущем времени. «сколько операций может выполнить система?» — «каких операций?». Разные операции дают разную нагрузку на СХД. Например, если кто-то пишет случайными блоками по 1Мб, то он получит много меньше iops, чем если он будет читать последовательно блоками по 4кб.
И если в случае пришедшей нагрузки мы говорим о том, сколько было обслужено запросов «какие пришли, такие и обслужили», то в случае планирования, мы хотим знать, какие именно iops'ы будут.
Драма состоит в том, что никто не знает, какие именно запросы придут. Маленькие? Большие? Подряд? В разнобой? Будут они прочитаны из кеша или придётся идти на самое медленное место и выковыривать байтики с разных половинок диска?
- Тест диска (СХД/массива) на best case (попадание в кеш, последовательные операции)
- Тест диска на worst case. Чаще всего такие тесты планируются с знанием устройства диска. «У него кеш 64Мб? А если я сделаю размер области тестирования в 2Гб?». Жёсткий диск быстрее читает с внешней стороны диска? А если я размещу тестовую область на внутренней (ближшей к шпинделю) области, да так, чтобы проходимый головками путь был поболе? У него есть read ahead предсказание? А если я буду читать в обратном порядке? И т.д.
В результате мы получаем цифры, каждая из которых неправильная. Например: 15kIOPS и 150 IOPS.
Какая будет реальная производительность системы? Это определяется только тем, как близко будет нагрузка к хорошему и плохому концу. (Т.е. банальное «жизнь покажет»).
- Что best case всё-таки best. Потому что можно дооптимизироваться до такого, что best case от worst будет отличаться едва-едва. Это плохо (ну или у нас такой офигенный worst).
- На worst. Имея его мы можем сказать, что СХД будет работать быстрее, чем полученный показатель. Т.е. если мы получили 3000 IOPS, то мы можем смело использовать систему/диск в нагрузке «до 2000».
Ну и про размер блока. Традиционно тест идёт с размером блока в 4к. Почему? Потому что это стандартный размер блока, которым оперируют ОС при сохранении файла. Это размер страницы памяти и вообще, Очень Круглое Компьютерное Число.
Нужно понимать, что если система обрабатывает 100 IOPS с 4к блоком (worst), то она будет обрабатывать меньше при 8к блоке (не менее 50 IOPS, вероятнее всего, в районе 70-80). Ну и на 1Мб блоке мы увидим совсем другие цифры.
Всё? Нет, это было только вступление. Всё, что написано выше, более-менее общеизвестно. Нетривиальные вещи начинаются ниже.
- прочитать запись
- поменять запись
- записать запись обратно
Для удобства будем полагать, что время обработки нулевое. Если каждый запрос на чтение и запись будет обслуживаться 1мс, сколько записей в секунду сможет обработать приложение? Правильно, 500. А если мы запустим рядом вторую копию приложения? На любой приличной системе мы получим 1000. Если мы получим значительно меньше 1000, значит мы достигли предела производительности системы. Если нет — значит, что производительность приложения с зависимыми IOPS'ами ограничивается не производительностью СХД, а двумя параметрами: latency и уровнем зависимости IOPS'ов.
Начнём с latency. Latency — время выполнения запроса, задержка перед ответом. Обычно используют величину, «средняя задержка». Более продвинутые используют медиану среди всех операций за некоторый интервал (чаще всего за 1с). Latency очень сложная для измерения величина. Связано это с тем, что на любой СХД часть запросов выполняется быстро, часть медленно, а часть может попасть в крайне неприятную ситуацию и обслуживаться в десятки раз дольше остальных.
Интригу усиливает наличие очереди запросов, в рамках которой может осуществляться переупорядочивание запросов и параллельное их исполнение. У обычного SATA'шного диска глубина очереди (NCQ) — 31, у мощных систем хранения данных может достигать нескольких тысяч. (заметим, что реальная длина очереди (число ожидающих выполнения запросов) — это параметр скорее негативный, если в очереди много запросов, то они дольше ждут, т.е. тормозят. Любой человек, стоявший в час пик в супермаркете согласится, что чем длиннее очередь, тем фиговее обслуживание.
Latency напрямую влияет на производительность последовательного приложения, пример которого приведён выше. Выше latency — ниже производительность. При 5мс максимальное число запросов — 200 шт/с, при 20мс — 50. При этом если у нас 100 запросов будут обработаны за 1мс, а 9 запросов — за 100мс, то за секунду мы получим всего 109 IOPS, при медиане в 1мс и avg (среднем) в 10мс.
Отсюда довольно трудный для понимания вывод: тип нагрузки на производительность влияет не только тем, «последовательный» он или «случайный», но и тем, как устроены приложения, использующие диск.
Пример: запуск приложения (типовая десктопная задача) практически на 100% последовательный. Прочитали приложение, прочитали список нужных библиотек, по-очереди прочитали каждую библиотеку… Именно потому на десктопах так пламенно любят SSD — у них микроскопическая задержка (микросекундная) на чтение — разумеется, любимый фотошоп или блендер запускается в десятые доли секунды.
Трешинг. Я думаю, с этим явлением пользователи десктопов знакомы даже больше, чем сисадмины. Жуткий хруст жёсткого диска, невыразимые тормоза, «ничего не работает и всё тормозит».
По мере того, как мы начинаем забивать очередь диска (или хранилища, повторю, в контексте статьи между ними нет никакой разницы), у нас начинает резко вырастать latency. Диск работает на пределе возможностей, но входящих обращений больше, чем скорость их обслуживания. Latency начинает стремительно расти, достигая ужасающих цифр в единицы секунд (и это при том, что приложению, например, для завершения работы нужно сделать 100 операций, которые при latency в 5 мс означали полусекундную задержку. ). Это состояние называется thrashing.
Вы будете удивлены, но любой диск или хранилище способны показывать БОЛЬШЕ IOPS'ов в состоянии thrashing, чем в нормальной загрузке. Причина проста: если в нормальном режиме очередь чаще всего пустая и кассир скучает, ожидая клиентов, то в условии трешинга идёт постоянное обслуживание. (Кстати, вот вам и объяснение, почему в супермаркетах любят устраивать очереди — в этом случае производительность кассиров максимальная). Правда, это сильно не нравится клиентам. И в хороших супермаркетах хранилищах такого режима стараются избегать. Если дальше начинать поднимать глубину очереди, то производительность начнёт падать из-за того, что переполняется очередь и запросы стоят в очереди чтобы встать в очередь (да-да, и порядковый номер шариковой ручкой на на руке).
И тут нас ждёт следующая частая (и очень трудно опровергаемая) ошибка тех, кто меряет производительность диска.
Они говорят «у меня диск выдаёт 180 IOPS, так что если взять 10 дисков, то это будет аж 1800 IOPS». (Именно так думают плохие супермаркеты, сажая меньше кассиров, чем нужно). При этом latency оказывается запредельной — и «так жить нельзя».
Реальный тест производительности требует контроля latency, то есть подбора таких параметров тестирования, чтобы latency оставалась ниже оговоренного лимита.
И вот тут вот мы сталкиваемся со второй проблемой: а какого лимита? Ответить на этот вопрос теория не может — этот показатель является показателем качества обслуживания. Другими словами, каждый выбирает для себя сам.
Лично я для себя провожу тесты так, чтобы latency оставалась не более 10мс. Этот показатель я для себя считаю потолком производительности хранилища. (при этом в уме я для себя считаю, что предельный показатель, после которого начинают ощущаться лаги — это 20мс, но помните, про пример выше с 900 по 1мс и 10 по 100мс, у которого avg стала 10мс? Вот для этого я и резервирую себе +10мс на случайные всплески).
Выше мы уже рассмотрели вопрос с зависимыми и независимыми IOPS'ами. Производительность зависимых Iops'ов точно контролируется latency, и этот вопрос мы уже обсудили. А вот производительность в независимых iops'ах (т.е. при параллельной нагрузке), от чего она зависит?
Отдельно нужно говорить про ситуацию, когда хранилище подключено к хосту через сеть с использованием TCP. О TCP нужно писать, писать, писать и ещё раз писать. Достаточно сказать, что в линуксе существует 12 разных алгоритмов контроля заторов в сети (congestion), которые предназначены для разных ситуаций. И есть около 20 параметров ядра, каждый из которых может радикальным образом повлиять на попугаи на выходе (пардон, результаты теста).
С точки зрения оценки производительности мы должны просто принять такое правило: для сетевых хранилищ тест должен осуществляться с нескольких хостов (серверов) параллельно. Тесты с одного сервера не будут тестом хранилища, а будут интегрированным тестом сети, хранилища и правильности настройки самого сервера.
Последний вопрос — это вопрос затенения шины. О чём речь? Если у нас ssd способна выдать 400 МБ/с, а мы её подключаем по SATA/300, то очевидно, что мы не увидим всю производительность. Причём с точки зрения latency проблема начнёт проявляться задолго до приближения к 300МБ/с, ведь каждому запросу (и ответу на него) придётся ждать своей очереди, чтобы проскочить через бутылочное горлышко SATA-кабеля.
Но бывают ситуации более забавные. Например, если у вас есть полка дисков, подключенных по SAS/300x4 (т.е. 4 линии SAS по 300МБ каждая). Вроде бы много. А если в полке 24 диска? 24*100=2400 МБ/с, а у нас есть всего 1200 (300х4).
Более того, тесты на некоторых (серверных!) материнских платах показали, что встроенные SATA-контроллеры часто бывают подключены через PCIx4, что не даёт максимально возможной скорости всех 6 SATA-разъёмов.
Повторю, главной проблемой в bus saturation является не выедание «под потолок» полосы, а увеличение latency по мере загрузки шины.
Ну и перед практическими советами, скажу про известные трюки, которые можно встретить в индустриальных хранилищах. Во-первых, если вы будете читать пустой диск, вы будете читать его из «ниоткуда». Системы достаточно умны, чтобы кормить вас нулями из тех областей диска, куда вы никогда не писали.
Во-вторых, во многих системах первая запись хуже последующих из-за всяких механизмов снапшотов, thin provision'а, дедупликации, компрессии, late allocation, sparse placement и т.д. Другими словами, тестировать следует после первичной записи.
В третьих — кеш. Если мы тестируем worst case, то нам нужно знать, как будет вести себя система когда кеш не помогает. Для этого нужно брать такой размер теста, чтобы мы гарантированно читали/писали «мимо кеша», то есть выбивались за объёмы кеша.
Кеш на запись — особая история. Он может копить все запросы на запись (последовательные и случайные) и писать их в комфортном режиме. Единственным методом worst case является «трешинг кеша», то есть посыл запросов на запись в таком объёме и так долго, чтобы write cache перестал стправляться и был вынужден писать данные не в комфортном режиме (объединяя смежные области), а скидывать случайные данные, осуществляя random writing. Добиться этого можно только с помощью многократного превышения области теста над размером кеша.
Вердикт — минимум x10 кеш (откровенно, число взято с потолка, механизма точного расчёта у меня нет).
Разумеется, тест должен быть без участия локального кеша ОС, то есть нам надо запускать тест в режиме, который бы не использовал кеширование. В линуксе это опция O_DIRECT при открытии файла (или диска).
Итого:
1) Мы тестируем worst case — 100% размера диска, который в несколько раз больше предположительного размера кеша на хранилище. Для десктопа это всего лишь «весь диск», для индустриальных хранилищ — LUN или диск виртуальной машины размером от 1Тб и больше. (Хехе, если вы думаете, что 64Гб RAM-кеша это много. ).
2) Мы ведём тест блоком в 4кб размером.
3) Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.
На выходе нас интересуют параметры: число IOPS, latency, глубина очереди. Если тест запускался на нескольких хостах, то показатели суммируются (iops и глубина очереди), а для latency берётся либо avg, либо max от показателей по всем хостам.
Тут мы переходим к практической части. Есть утилита fio которая позволяет добиться нужного нам результата.
Нормальный режим fio подразумевает использование т.н. job-файла, т.е. конфига, который описывает как именно выглядит тест. Примеры job-файлов приведены ниже, а пока что обсудим принцип работы fio.
fio выполняет операции над указанным файлом/файлами. Вместо файла может быть указано устройство, т.е. мы можем исключить файловую систему из рассмотрения. Существует несколько режимов тестирования. Нас интересует randwrite, randread и randrw. К сожалению, randrw даёт нам зависимые iops'ы (чтение идёт после записи), так что для получения полностью независимого теста нам придётся делать две параллельные задачи — одна на чтение, вторая на запись (randread, randwrite).
И нам придётся сказать fio делать «preallocation». (см выше про трюки производителей). Дальше мы фиксируем размер блока (4к).
Ещё один параметр — метод доступа к диску. Наиболее быстрым является libaio, именно его мы и будем использовать.
При тесте диска запускать её надо от root'а.
тесты на чтение
Запуск: fio read.ini
Содержимое read.ini
Задача подобрать такой iodepth, чтобы avg.latency была меньше 10мс.
Результаты тестов
Выбранный нами жесткий диск относится к производительной "черной" серии винчестеров WD и имеет весьма неплохие скоростные характеристики:

Посмотрим, какие результаты он покажет при подключении через USB:

Да, мягко говоря, результат не очень. Хотя он вполне закономерен, на практике максимальная пропускная способность USB 2.0 составляет около 40 МБ/с (не будем забывать про накладные расходы), поэтому данные результаты можно считать вполне неплохими.
Но это был высокопроизводительный диск, а какие результаты покажут более медленные диски или SSD? Поэтому мы расширили наше тестирование и включили в него жесткий диск 320 Gb SATA-II 300 Fujitsu 2.5" 5400 rpm 8Mb, входящий в состав внешнего диска Prestigio Data Safe II USB2.0 Portable HQ Leather HDD 320Gb и уже знакомый по предыдущим тестам твердотельный накопитель OCZ Agility 2 .
Мы не стали разбирать внешний HDD, и так понятно, что 2,5" ноутбучный диск значительно уступает по производительности "черному" WD. Нас больше интересовали его результаты применительно к USB подключению:

А также результаты при подключении через USB твердотельного накопителя:

Как видим, результат практически ровный, из чего можно сделать вывод, что "узким горлышком" в данном случае является пропускная способность шины USB 2.0 и скорость диска не оказывает практически никакого влияния на результат.
Поэтому, если вы выбираете диск для внешнего бокса нет смысла тратить деньги на высокопроизводительный винчестер, лучше обратите внимание на экономичные, бесшумные и с малым нагревом диски "зеленой" серии WD или аналогичные решения от других производителей.
Этим вы сэкономите определенную сумму денег и снимете ряд проблем связанных с температурным режимом и энергопотреблением диска. Покупка для этих целей SSD иначе как "деньги на ветер" назвать нельзя.
Вторым, интересовавшим нас вопросом, было использование USB дисков в качестве общего сетевого ресурса. Как правило подобный подход практикуется в небольших фирмах с небольшим числом сетевых клиентов и сетью 100 Мбит/с.
Мы провели несколько тестов на копирование файлов и папок из пакета Intel® NAS Performance Toolkit. Для сравнения мы использовали общий сетевой ресурс на том же диске (1 Tb SATA 6Gb/s Western Digital Caviar Black), только подключенном через SATA.

Как видим, большой разницы нет. Основным сдерживающим фактором в данном случае является пропускная способность сети (12,5 МБ/с), поэтому нет никаких причин отказываться от удобства USB дисков в пользу предполагаемой производительности.
Также нет смысла пытаться увеличить производительность покупкой более быстрого диска, даже самый медленный современный диск даст вам возможность по максимуму использовать все возможности сети 100 Мбит/с.
Теперь посмотрим, что изменится при переходе к гигабитной сети, хотя использование внешних дисков в качестве общих ресурсов в таких сетях как раз таки является скорее исключением, чем правилом.

А вот здесь уже проявляются ограничения USB подключения, максимально доступная скорость передачи данных уперлась в значение 40 МБ/с, что лишает практического смысла использование внешних дисков в качестве сетевых ресурсов в гигабитных сетях.
Читайте также: