
Какие субд полностью полагаются на оперативную память при хранении информации
Среди самых важных характеристик любой базы данных следует назвать производительность, надежность и простоту администрирования. Знание того, как большинство СУБД физически хранят данные во внешней памяти, представление о параметрах этого хранения и соответствующих методах доступа может очень помочь при проектировании баз данных, обладающих заданной производительностью.
Хранение данных во внешней памяти в известных СУБД (Oracle, IBM DB2, Microsoft SQL Server, CA-OpenIngres, решения от Sybase и Informix и др.) организовано очень похожим образом.
Что выведет в приведённой схеме TextViewer?
- (Правильный ответ) число
- обучающую выборку
- контрольную и обучающую выборку
- текст
Какая из NoSQL СУБД подходит для организации консистентного и распределённого хранилища?
- (Правильный ответ) Hbase
- Cassandra
- (Правильный ответ) Redis
- (Правильный ответ) BigTable
На каком из этапов процесса CRISP-DM происходит проверка гипотез?
- (Правильный ответ) моделирование (Modeling)
- понимание данных (Data Understanding)
- оценка (Evaluation)
- понимание бизнеса (Business understanding)
Можно ли с помощью приведённой схемы произвести оценку качества работы алгоритма J48 на загруженных данных?
- да, только после 100 запусков
- (Правильный ответ) да, достаточно одного прогона
- да, только после 10 запусков
- нет
Компания, проводящая социологические опросы, испытывает сложности с верификацией данных, поступающих от волонтеров непосредственно опрашивающих респондентов: многие анкеты заполнены не полностью; волонтеры фальсифицируют результаты опроса, самостоятельно заполняя часть анкет. К какому типу задач анализа данных здесь прибегать не придётся?
- классификация
- цензурирование
- (Правильный ответ) прогнозирование
- заполнение пробелов
Коммерческая клиника желает установить структуру своих клиентов с
точки зрения вклада в доход клиники. К какому типу относится эта задача анализа данных?
- прогнозирование
- (Правильный ответ) кластеризация
- цензурирование
- классификация
Компания, проводящая социологические опросы получает анкеты от волонтеров, непосредственно опрашивающих респондентов. При каких условиях разумна постановка задачи цензурирования?
- Часть анкет пришла в негодность, что не позволяет считать информацию с них со 100% уверенностью
- многие анкеты заполнены не полностью
- (Правильный ответ) стало известно, что волонтеры фальсифицируют результаты опроса, самостоятельно заполняя часть анкет
- от заказчика поступило требование уничтожить часть анкет, содержащих информацию о руководителях страны
Отметьте причины создания NoSQL баз данных:
- дороговизна лицензий RDBMS
- (Правильный ответ) высокая стоимость горизонтальной масштабируемости RDBMS при сохранении требования высокой доступности
- недостаточная гибкость языка запросов SQL
- невозможность хранить большие объёмы данных
Как правильно присвоить p значение типа данных, имеющих две координаты x=1 и y=2 ?
С некоторой периодичностью персонал предприятия списывает группы расходных материалов на различных участках учета. Для выявления ошибок, акты списания выборочно проверяются аудитором. Определены три категории: «ошибочные», «под сомнением», «безошибочные». К какому типу задач анализа данных относится задача о построении правила автоматического отнесения списаний к этим категориям.
- (Правильный ответ) классификация
- поиск информативных признаков
- кластеризация
- цензурирование
С некоторой периодичностью персонал предприятия списывает группы расходных материалов на различных участках учета. Для выявления ошибок, акты списания выборочно проверяются аудитором. Как бы в данном случае формулировалась задача классификации?
- (Правильный ответ) научиться автоматически выявлять ошибочные списания с ожидаемой ошибкой не ниже 97%
- классифицировать типичные ошибки и составить их список
- определить характерные признаки ошибочных списаний
- (Правильный ответ) определить три категории: «ошибочные», «под сомнением», «безошибочные» и найти правило отнесения к этим категориям
Что будет присвоено переменной res (Python) в следующем выражении res = [x for x in xrange(1,5, 2)]
- [1,5,2]
- (Правильный ответ) [1, 3]
- [1,2,3,4,5,1,2,3,4,5]
- [152]
Инвестиционный фонд интересуется тем, почему часть финансируемых им
проектов успешно переходят на второй год, а часть — нет. К какому типу относится эта задача анализа данных?
- построение решающего правила
- классификация
- (Правильный ответ) поиск информативных признаков
- цензурирование
Для каких аргументов функция is.finite вернет false ?
Какие вероятные разочарования тренда больших данных?
- из-за угрозы безопасности личной жизни (privacy) граждан будут упрощены процедуры сбора данных, что приведёт к падению ценности больших данных
- (Правильный ответ) из-за угрозы безопасности личной жизни (privacy) граждан будут усложнены процедуры сбора данных, что приведёт к падению ценности больших данных
- нет
Для каких аргументов функция is.finite вернет true ?
Оставить комментарий

Inna Petrova 18 минут назад
Нужно пройти преддипломную практику у нескольких предметов написать введение и отчет по практике так де сдать 4 экзамена после практики
Иван, помощь с обучением 25 минут назад
Коля 2 часа назад
Здравствуйте, сколько будет стоить данная работа и как заказать?
Иван, помощь с обучением 2 часа назад
Инкогнито 5 часов назад
Сделать презентацию и защитную речь к дипломной работе по теме: Источники права социального обеспечения. Сам диплом готов, пришлю его Вам по запросу!
Иван, помощь с обучением 6 часов назад
Василий 12 часов назад
Здравствуйте. ищу экзаменационные билеты с ответами для прохождения вступительного теста по теме Общая социальная психология на магистратуру в Московский институт психоанализа.
Иван, помощь с обучением 12 часов назад
Анна Михайловна 1 день назад
Нужно закрыть предмет «Микроэкономика» за сколько времени и за какую цену сделаете?
Иван, помощь с обучением 1 день назад
Сергей 1 день назад
Здравствуйте. Нужен отчёт о прохождении практики, специальность Государственное и муниципальное управление. Планирую пройти практику в школе там, где работаю.
Иван, помощь с обучением 1 день назад
Инна 1 день назад
Добрый день! Учусь на 2 курсе по специальности земельно-имущественные отношения. Нужен отчет по учебной практике. Подскажите, пожалуйста, стоимость и сроки выполнения?
Иван, помощь с обучением 1 день назад
Студент 2 дня назад
Здравствуйте, у меня сегодня начинается сессия, нужно будет ответить на вопросы по русскому и математике за определенное время онлайн. Сможете помочь? И сколько это будет стоить? Колледж КЭСИ, первый курс.
Иван, помощь с обучением 2 дня назад
Ольга 2 дня назад
Требуется сделать практические задания по математике 40.02.01 Право и организация социального обеспечения семестр 2
Иван, помощь с обучением 2 дня назад
Вика 3 дня назад
сдача сессии по следующим предметам: Этика деловых отношений - Калашников В.Г. Управление соц. развитием организации- Пересада А. В. Документационное обеспечение управления - Рафикова В.М. Управление производительностью труда- Фаизова Э. Ф. Кадровый аудит- Рафикова В. М. Персональный брендинг - Фаизова Э. Ф. Эргономика труда- Калашников В. Г.
Иван, помощь с обучением 3 дня назад
Игорь Валерьевич 3 дня назад
здравствуйте. помогите пройти итоговый тест по теме Обновление содержания образования: изменения организации и осуществления образовательной деятельности в соответствии с ФГОС НОО
Иван, помощь с обучением 3 дня назад
Вадим 4 дня назад
Пройти 7 тестов в личном кабинете. Сооружения и эксплуатация газонефтипровод и хранилищ
Иван, помощь с обучением 4 дня назад
Кирилл 4 дня назад
Здравствуйте! Нашел у вас на сайте задачу, какая мне необходима, можно узнать стоимость?
Иван, помощь с обучением 4 дня назад
Oleg 4 дня назад
Требуется пройти задания первый семестр Специальность: 10.02.01 Организация и технология защиты информации. Химия сдана, история тоже. Сколько это будет стоить в комплексе и попредметно и сколько на это понадобится времени?
Иван, помощь с обучением 4 дня назад
Валерия 5 дней назад
ЗДРАВСТВУЙТЕ. СКАЖИТЕ МОЖЕТЕ ЛИ ВЫ ПОМОЧЬ С ВЫПОЛНЕНИЕМ практики и ВКР по банку ВТБ. ответьте пожалуйста если можно побыстрее , а то просто уже вся на нервяке из-за этой учебы. и сколько это будет стоить?
Иван, помощь с обучением 5 дней назад
Инкогнито 5 дней назад
Здравствуйте. Нужны ответы на вопросы для экзамена. Направление - Пожарная безопасность.
Иван, помощь с обучением 5 дней назад
Иван неделю назад
Защита дипломной дистанционно, "Синергия", Направленность (профиль) Информационные системы и технологии, Бакалавр, тема: «Автоматизация приема и анализа заявок технической поддержки
Иван, помощь с обучением неделю назад
Дарья неделю назад
Иван, помощь с обучением неделю назад
Универсальные СУБД — фундамент ИТ-инфраструктуры современного предприятия — часто оказываются не в состоянии обеспечить операционные характеристики, требуемые для решения целого ряда задач оперативной обработки информации в распределенной вычислительной среде. Должную производительность, время отклика и пропускную способность могут гарантировать механизмы, обеспечивающие работу с базами в оперативной памяти компьютера.
Среди подобных решений особое место занимают реляционные системы управления базами данных в оперативной памяти (in-memory/main memory database, IMDB/MMDB). Благодаря стандартизованным интерфейсам они могут обслуживать множество программ, обеспечивая высокую реактивность и пропускную способность систем при пиковых нагрузках, позволяя тем самым решать задачи сбора, интеграции, обработки и анализа информации в близком к реальному масштабе времени, которые централизованные СУБД поддерживать просто не в состоянии. В традиционной трехзвенной архитектуре «клиент — сервер приложений — мощный сервер реляционных СУБД» приложение далеко не всегда в состоянии предоставить и обработать всю необходимую информацию тогда и там, где это необходимо: по мере роста систем централизованные сервисы доступа к информационным ресурсам оказываются чрезмерно ресурсоемкими и дефицитными, причем экстенсивное наращивание мощностей корпоративных серверов и систем хранения данных проблему не снимает.
Высокопроизводительные системы, поддерживающие базы данных в оперативной памяти, предлагают сегодня корпорации IBM (solidDB), Oracle (TimesTen) и Sun Microsystems (SQL Cluster), специализированные компании ENEA (Polyhedra), McObject (eXtremeDB), Birdstep Technology (Raima Data Manager), Altibase (Altibase), а также представители сообщества Open Source (в том числе CSQL, MonetDB, H2 DBMS и HSQLDB). Именно с помощью таких продуктов в информационных системах операторов связи, фондовых бирж и банков, авиакомпаний, торговых и транспортных сетей, промышленных предприятий, научно-исследовательских организаций, оборонных и специальных структур сегодня ежесекундно выявляются и регистрируются миллионы фактов, анализируются происходящие события, принимаются обоснованные решения и перераспределяются потоки данных и работ.
Освободиться от дисков
Как известно, общая производительность традиционных систем ограничена скоростью выполнения операции обмена с внешними устройствами, поэтому применяются механизмы управления буферами и кэширования, индексирования, оптимизации обработки запросов, распределение баз данных во внешней памяти, распараллеливание обработки запросов на мультипроцессорах, кластерные решения, сегментирование и даже специализированные аппаратно-программные решения.
Техника кэширования основана на временном хранении копии данных в буферной памяти. Например, процессорный кэш обеспечивает эффективный обмен между процессором и оперативной памятью, благодаря дисковому кэшу сокращается число обращений к внешней памяти, сетевой кэш за счет сохранения HTML-страниц и их фрагментов позволяет сократить сетевой трафик и нагрузку на Web-серверы и серверы приложений. Буферный кэш СУБД и механизм управления им обеспечивает своевременное считывание и возврат страниц баз данных во внешнюю память. Именно в этой области памяти прозрачно для прикладной программы осуществляются операции манипулирования данными: программа обращается к исполнительной системе СУБД, та, оптимизировав запрос, определяет адреса нужных страниц на диске, перемещает их целиком в кэш, выполняет необходимые преобразования и передает нужные данные программе. Измененные данные возвращаются на диск, и они проделывают обратный путь (рис. 1а).
Конечно, чем большую часть базы данных удастся разместить в буферном кэше, тем с большей скоростью будет происходить обработка. Однако, несмотря на то, что современные серверы, операционные системы и СУБД позволяют полностью кэшировать базы данных объемом в десятки и сотни гигабайт, предельная производительность системы по-прежнему определяется традиционной архитектурой механизма управления данными, нацеленного на минимизацию числа операций обмена данными между медленной внешней памятью и прикладными программами. До сих пор в кэше приходится держать полные образы страниц данных на диске, структура индексов соответствует страничной организации данных, а доступ осуществляется через менеджер буферного пула.
Радикально улучшить производительность можно, освободив СУБД на время исполнения программы от необходимости обращаться к внешним запоминающим устройствам (рис. 1б). В «бездисковой» СУБД все пользовательские и системные таблицы, каталоги, индексы, буферы системного журнала, таблицы блокировок, временные области и другие объекты эффективно располагаются в оперативной памяти, что позволяет существенно «облегчить» архитектуру. Структура индексов также претерпевает изменения — они становятся компактнее, поскольку при доступе к данным не требуется минимизация количества операций ввода-вывода. В алгоритмах обработки запросов главным критерием выбора оптимального плана становится не число обращений к внешней памяти, а вычислительная «стоимость» операции и эффективная загрузка процессора. Наконец, более эффективно решается ряд задач администрирования, например борьба с фрагментацией памяти. В результате по времени реакции и пропускной способности система, в которой работа базы данных происходит в оперативной памяти, значительно выигрывает даже по сравнению с решением с полностью кэшированной базой традиционной «дисковой» СУБД. Так, например, в тесте Telecom One, имитирующем рабочую нагрузку в телекоммуникационных приложениях при 100 тыс. мобильных абонентах, пропускная способность системы IBM solidDB оказалась в среднем в десять раз выше, чем у традиционных СУБД.
Долговременное хранение
Но как обеспечить физическую целостность базы данных, если оперативная память компьютера энергозависима, и при отключении или отказе сервера СУБД данные будут потеряны? Для этого применяются локальные или сетевые процедуры резервного копирования и восстановления, а в качестве оперативных механизмов — периодическое сохранение «моментальных снимков» состояния базы данных и ведение системных журналов изменений на диске, а также репликация и синхронизация баз данных. При открытии состояние базы данных восстанавливается по контрольной точке, и дальнейшая обработка в памяти поддерживается эффективными механизмами управления конкурентным доступом, обработки транзакций и блокирования ресурсов. При записи контрольной точки все зафиксированные транзакции сбрасываются из буфера журнала во внешнюю память, а между контрольными точками в журнал вносятся транзакции по мере фиксации, что обеспечивает возможность восстановления в случае системного отказа. Применение механизма контрольных точек без ведения системного журнала обеспечивает более высокую производительность, но в аварийной ситуации дает возможность вернуться только к предыдущему целостному состоянию. В зависимости от специфики приложения и требуемого баланса между производительностью и обеспечением сохранности данных в промежутках между контрольными точками запись изменений в журнал относительно момента фиксации транзакции может осуществляться синхронно или асинхронно. В системах Altibase и IBM solidDB реализовано гибридное решение — сервер СУБД содержит два механизма управления данными: один оптимизирован для доступа к диску, а другой ориентирован на хранение данных в оперативной памяти. Прикладная программа может обращаться и к тем, и к другим данным с помощью одного оператора SQL.
Уровень изоляции определяется спецификой прикладных задач: одни должны монопольно «захватывать» обрабатываемые данные, в других допускается определенная степень вмешательства со стороны выполняемых параллельно программ. В СУБД в оперативной памяти чтение результатов незафиксированных транзакций не предусмотрено, поэтому поддерживаются три уровня изоляции транзакций: Read Committed (чтение результатов только зафиксированных транзакций — это достаточный уровень изоляции для большинства приложений); Repeatable Read (чтение результатов только зафиксированных транзакций с гарантией того, что данные остаются неизменными до фиксации транзакции); Serializable (наивысший уровень изолированности — результат конкурирующих транзакций должен быть таким же, как после их последовательного выполнения).
В традиционной СУБД изоляция транзакций реализуется с помощью хэш-таблиц, указывающих на блокируемые объекты, а при хранении баз данных в оперативной памяти соответствующие признаки могут встраиваться непосредственно в объекты базы данных, и это дает возможность оптимизировать алгоритмы управления блокировками. В ряде систем, например в Oracle TimesTen, с целью поддержки распределенных транзакций предусмотрен интерфейс для программного мониторинга изменений, регистрируемых в журнале (Transaction Log API, XLA), и инициализации соответствующих действий (применения изменений к внешним базам данных, рассылки уведомлений и т.п.).
Архитектура передового развертывания
На рис. 2 представлена укрупненная схема взаимодействия компонентов системы баз данных, поддерживаемых в оперативной памяти.
СУБД в оперативной памяти могут применяться как в компактных решениях, встраиваемых в специализированные приложения и устройства, так и в крупных проектах масштаба предприятия, в которых множество приложений в сервис-ориентированной архитектуре (Service-Oriented Architecture, SOA) обеспечивают решение задач по периметру сетевой инфраструктуры компании. Сбор, обработка и предоставление данных в реальном масштабе времени нужны для поддержки персонализированных форм взаимодействия с пользователями, гармонизации бизнес-процессов и упрощения внутренних операций, обработки информационных потоков и доставки данных мультимедиа. Организациям практически любого масштаба и направления деятельности необходимы приложения, развертываемые как можно ближе к источникам и местам потребления информации, причем дополнительные выгоды для заказчиков могут обеспечить средства поддержки баз данных в оперативной памяти, интегрируемые с корпоративными СУБД.
В дополнение к основному уровню хранения данных (back-end) целесообразно, опираясь на совокупные ресурсы оперативной памяти распределенной серверной платформы, иметь облегченные и в то же время более производительные механизмы управления и среду хранения данных на «переднем плане» (front-end) непосредственно на серверах приложений и периферийных узлах. Для этого используются различные архитектурные схемы развертывания решения: библиотека функций СУБД, подключаемая непосредственно к прикладной программе, сервер IMDB, обслуживающий прикладные программы; дополнительно могут применяться функциональные компоненты, обеспечивающие кэширование основной базы данных, и отказоустойчивые конфигурации. Во всех этих схемах действует единый интерфейс прикладного программирования.
Такие решения могут быть относительно автономными, например, в телекоммуникационных приложениях реального времени и интеллектуальных устройствах для сбора и обмена данными о поступающих вызовах, состоянии сети, перемещении абонентов и т.п. В системах обработки потоков данных, поступающих по коммерческим, новостным и технологическим каналам, в интеграционных решениях и системах бизнес-аналитики усиленные с их помощью узлы хранения данных и управления транзакциями позволяют распределить нагрузку и разгрузить корпоративные серверы, а в системах резервирования билетов, мест в гостиницах, в электронной торговле и системах поддержки коллективной работы они могут обеспечить вертикальное или горизонтальное партиционирование баз данных и ускорение доступа к их интенсивно используемым подмножествам. Наконец, на их базе может быть развернут синхронизируемый с основной «дисковой» базой данных быстродействующий локальный или распределенный кэш основной базы данных, способный справляться с пиковыми нагрузками на корпоративные системы.
Отказоустойчивость
Системы управления базами данных в оперативной памяти позволяют реализовать отказоустойчивые конфигурации с основным и резервным узлами СУБД, в которых обеспечивается постоянная автоматическая синхронизация на уровне системы, сеанса или транзакции, что позволяет сбалансировать пропускную способность, сохранность данных и время восстановления системы, а при отказе практически мгновенно переключать ресурсы (рис. 3). К тому же наличие постоянно готовой копии системы позволяет, не отключая основной сервер, параллельно выполнять вспомогательные работы: формирование отчетности, резервное копирование, установку обновлений программного обеспечения и т.д.
Кэширование баз данных
Механизм управления данными в оперативной памяти позволяет поддерживать локальный или распределенный кэш основной базы данных в виде копий ее фрагментов, реплицируемых в памяти на серверах приложений, «приближенных» к месту создания или использования данных. Кэшируемые фрагменты основной базы данных, в качестве которых могут выступать одна или несколько таблиц, их «горизонтальные» проекции или «вертикальные» подмножества строк, определяются в рамках установленных структурных ограничений администратором баз данных с помощью операторов расширения SQL или дополнительных инструментов.
Прикладным программам доступны высокопроизводительные сервисы СУБД в оперативной памяти для хранения и обработки данных, управления конкурентным доступом и транзакциями и обеспечения отказоустойчивости, причем благодаря использованию аналогичных с основной СУБД интерфейсов, взаимодействие с кэшем и основной базой данных «прозрачно» для приложения. После загрузки из основной базы данные могут считываться или обновляться непосредственно в кэше подключенными к нему (локально или по сети) прикладными программами. Двусторонний трафик при загрузке, периодической подкачке, синхронизации данных (в синхронном или асинхронном режиме) обрабатывает специальный программный агент — коннектор кэша и основной базой данных. Управление осуществляется автоматически в соответствии с параметрами, установленными по умолчанию или задаваемыми администратором баз данных, а также на уровне прикладной программы, при этом обеспечивается восстановление системы в аварийных ситуациях.
Такое решение позволяет разгрузить корпоративные серверы хранения данных и обеспечить необходимые операционные характеристики для высоко реактивных масштабируемых приложений реального времени, обработки транзакций, а также ведения условно-постоянной, нормативно-справочной информации, профилей пользователей, данных о конфигурации и т.д.
Распределенные базы данных
Сервисы управления базами данных должны быть непрерывными, в особенности для критических задач. Благодаря возможности репликации баз данных непосредственно в оперативной памяти на узлах сети, данные можно расположить настолько «близко» к приложениям, насколько этого требует быстродействие, пропускная способность или доступность решения, например, в сетях доставки мультимедиа-контента, телекоммуникационных системах и устройствах и т.д.
Высокопроизводительные механизмы синхронной и асинхронной (на основе модели публикации и подписки) репликации и синхронизации баз данных встраиваются в СУБД в оперативной памяти и используют такие их возможности, как управление транзакциями и поддержка расширений SQL, позволяющих достаточно быстро разрабатывать распределенные приложения, максимально отражающие специфику реальной задачи, например, способность выявлять и разрешать конфликты, исходя из бизнес-правил и логики.
В распределенной системе основная база содержит «эталонные» данные, которые реплицируются на одну или несколько копий. Копия может иметь несколько таблиц, одни из которых содержат только копии эталонных данных, другие — только локальные значения, а третьи некоторую их смесь. Изменения, внесенные в какую-либо из копий передаются на главный сервер, который верифицирует их в соответствии с заданными правилами, и после проверки рассылаются на остальные копии (рис. 4). При этом в зависимости от требований решаемой задачи поддерживаются различные по производительности, организации взаимодействия и отказоустойчивости схемы репликации, разрешения конфликтов, восстановления баз данных и проводки изменений в реальном времени, в том числе ориентированные на решения, встраиваемые в устройства без дисков. Для управления репликацией применяются соответствующие операторы расширения SQL.
После приобретения в 2005 году «ветерана» СУБД в оперативной памяти компании TimesTen корпорацией Oracle последняя предлагает решение Oracle TimesTen, в состав которого входит сервер СУБД Oracle Timesten In-Memory Database и дополняющие его опции Replication — TimesTen to TimesTen для создания отказоустойчивых конфигураций и равномерного распределения нагрузки и Cache Connect to Oracle для кэширования баз данных Oracle на серверах приложений.
Объявленные в начале лета 2008 года три решения IBM SolidDB 6.1, работающие под управлением ОС Linux, HP/UX, AIX, Solaris и Z/OS — результат первого этапа интеграции технологий финской компании Solid Information Technology, приобретенной IBM годом ранее, в стек решений по управлению информацией по требованию. Два из них — IBM solidDB Cache для DB2 и IBM solidDB Cache для Informix Dynamic Server могут быть развернуты в дополнение к серверам СУБД для увеличения производительности за счет кэширования основной базы данных, а третье — IBM solidDB — благодаря сдвоенному гибридному механизму СУБД поддерживает базы данных в оперативной памяти и на дисках.
На рынке систем управления базами данных в оперативной памяти заметно присутствие не только лидеров, но и «чистых» игроков, таких как шведская компания ENEA, которая с 1993 года предлагает семейство реляционных СУБД в оперативной и флэш-памяти Polyhedra для мобильных устройств и клиент-серверных приложений, требующих максимальной производительности и надежности в системах с интенсивными информационными потоками, например в беспроводных сетях и промышленных системах управления. К таким игрокам относятся и южнокорейская компания Altibase с одноименной гибридной системой, и поставщики встраиваемых СУБД McObject с eXtremeDB и Birdstep Technology с Raima Data Manager (в эту группу следует включить и поставляемую Oracle систему Berkley DB), а также таких систем категории Open Source, как CSQL, FastDB, MonetDB, H2 и HSQLDB.
На системы управления базами данных в оперативной памяти приходится от 0,5 до 1% современного рынка СУБД, и этот сегмент, по мнению аналитиков IDC, еще только формируется. Решения этого класса не следует рассматривать как альтернативу корпоративным СУБД — их применение оправданно в особо ответственных ситуациях в качестве инструмента существенного повышения производительности, надежности и пропускной способности, дополняющего корпоративный портфель средств управления данными.
Рис. 1. Доступ приложения к базе данных: а) в традиционной системе; б) в СУБД в оперативной памяти (Oracle TimesTen)
Рис. 2. Схема взаимодействия компонентов системы баз данных, поддерживаемых в оперативной памяти с репликацией и кэшированием основной базы данных. Решение Oracle TimesTen
Рис. 3. Отказоустойчивые конфигурации: а) основной и резервный сервер: б) два активных сервера; в) активный и несколько резервных серверов IMDB. Решение Altibase
Рис. 4. Различные схемы репликации баз данных: односторонняя а) с одной копией, б) с несколькими копиями, в) двусторонняя, г) многосторонняя. Решение Oracle TimesTen Replication
Начиная с каких размеров данных обоснованно применение кластера Hadoop для хранения данных?
Проблемы управления внешней памятью
Распространенной проблемой для администраторов при управлении физическим хранением является фрагментация различных структур внешней памяти, которая чаще обусловлена операциями удаления. В отличие от преднамеренной фрагментации, такая «фрагментация» обычно ухудшает производительность. Встречается фрагментация на уровне блоков, когда в блоке остается свободное пространство после удаления строк из таблицы, на уровне экстентов, когда заполненные экстенты чередуются с незаполненными, появившимися после операций удаления таблиц, и т.п. Укажем лишь часть из проблем, которые могут быть обусловлены фрагментацией.
Фрагментация неизбежна и поэтому является нормальным явлением, и не всегда ухудшает характеристики базы данных. Индексы также подвержены проблемам фрагментации пространства, и могут стать несбалансированными, поэтому SQL-оператор ALTER INDEX обычно имеет опцию REBUILD, позволяющую перестроить индекс. Индекс также можно удалить и создать заново даже в работающей базе данных.
Какие из следующих технологий СУБД не используют принцип MapReduce
- Hadoop
- Cassandra
- (Правильный ответ) Redis
- HDInsight
В чём состоит свойство расширяемости записей СУБД?
- СУБД не имеет чёткой структуры, поэтому любую запись можно расширить
- повышение отказоустойчивости системы при добавлении новых записей в СУБД
- в любую таблицу СУБД можно добавить новую колонку, предварительно изменив структуру этой таблицы
- (Правильный ответ) СУБД имеет чёткую, но расширяемую структуру, в каждую запись можно добавить новую колонку, также как и узнать значение любой записи по добавленной колонке
Какие СУБД полностью полагаются на оперативную память при хранении информации:
- (Правильный ответ) SAP HANA
- HBase
- (Правильный ответ) Oracle Exalytics
- BigTable
В каких из перечисленных случаях требуется СУБД со свойством расширяемости записей?
Какие задачи решают графовые БД?
- (Правильный ответ) хранение информации о графах
- использование графа серверов для распределенного хранения больших данных
- встроенная обработка данных сетевыми методами
- (Правильный ответ) распределенное хранение с учетом минимизации передачи информации
Организация хранения
Основными единицами физического хранения являются блок данных, экстент, файл (либо раздел жесткого диска). Логический уровень представления информации включает пространства (либо табличные пространства). Блок данных (block) или страница (page) является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных (Oracle) или для ее различных структур (DB2, Informix, Sybase) и устанавливается при создании. Очень важно сразу правильно выбрать размер блока: в работающей базе изменить его практически невозможно (для этого часто проводят ряд испытаний базы данных-прототипа).
Администратор отводит пространство для базы данных на внешних устройствах большими фрагментами: файлами и разделами диска. В первом случае доступ к диску осуществляется операционной системой, что дает определенные преимущества, например, работа с файлами средствами ОС. Во втором случае с внешним устройством работает сам сервер. При этом достигается более высокая производительность; кроме того, использование дисков необходимо в случае, если кэш ОС не может работать в режиме сквозной (write-through) записи. Диски особенно эффективны для ускорения операций записи данных (подобный механизм поддерживается Oracle, DB2 и Informix; например, в DB2 данная единица размещения называется контейнером).
Пространством внешней памяти, отведенным ему администратором, сервер управляет с помощью экстентов (extent), т.е. непрерывных последовательностей блоков. Информация о наличии экстентов для объекта схемы данных находится в специальных управляющих структурах, реализация которых зависит от СУБД. На управление экстентами (выделение пространства, освобождение, слияние) тратятся определенные ресурсы, поэтому для достижения эффективности нужно правильно определять их параметры. СУБД от Oracle, IBM, Informix позволяют определять параметры этих структур, а в Sybase экстенты имеет постоянный размер, равный 8 страницам. Уменьшение размера экстента будет способствовать более эффективному использованию памяти, однако при этом возрастают накладные расходы на управление большим количеством экстентов, что может замедлить операции вставки большого количества строк в таблицу. Кроме того, сервер может иметь ограничение на максимальное количество экстентов для таблицы. При слишком большом размере экстентов могут возникнуть проблемы с выделением для них необходимого количества памяти. Обычно определяется размер начального экстента, размер второго и правило определения размеров следующих экстентов. На рис. 2 иллюстрируется взаимосвязь блоков, экстентов и файлов баз данных.
В Informix существует еще одна единица физического хранения, промежуточная между файлом (или разделом диска) и экстентом, — это «чанк» (от английского chunk, что дословно переводится как «емкость»). Чанк позволяет более гибко управлять очень большими массивами внешней памяти. В одном разделе диска или файле администратор может создать несколько чанков. Чанк также служит единицей зеркалирования.
Общим для СУБД Oracle, DB2 и Informix является понятие пространства (для Oracle и DB2 это табличное пространство). Различные логические структуры данных, такие как таблицы и индексы, временные таблицы и словарь данных размещены в табличных пространствах. В DB2 и Informix дополнительно можно устанавливать размер страницы отдельно для каждой из этих структур. Группировка хранимых данных по пространствам производится по ряду признаков: частота изменения данных, характер работы с данными (преимущественно чтение или запись и т.п.), скорость роста объема данных, важность и т.п. Таким образом, например, только читаемые таблицы помещаются в одно пространство, для которого установлены одни параметры хранения, таблицы транзакций размещаются в пространстве с другими параметрами и т.д. (рис. 3).
Одна логическая единица данных (таблица или индекс) размещается точно в одном пространстве, которое может быть отображено на несколько физических устройств или файлов. При этом физически разнесены (располагаться на разных дисках) могут не только логические единицы данных (таблицы отдельно от индексов), но и данные одной логической структуры (таблица на нескольких дисках). Такой способ хранения называется горизонтальной фрагментацией: таблица делится на фрагменты по строкам. В Oracle вместо термина «фрагментация» используется «секционирование» (partitioning). Фрагментация — один из способов повышения производительности.
Могут применяться различные схемы записи данных во фрагментированные таблицы. Одна из них — круговая (round-robin), когда некоторая часть вставляемых в таблицу строк записывается в первый фрагмент, другая часть — в следующий и так далее по кругу. В данном случае за счет распараллеливания может быть увеличена производительность операций модификации данных и запросов. Существует и другая схема, включающая логическое разделение строк таблицы по ключу («кластеризация»). Данная схема позволяет избежать перерасхода процессорного времени и уменьшить общий объем операций ввода/вывода. Ее суть в том, что при создании таблицы все пространство значений ключа таблицы разбивается на несколько интервалов, а строкам с ключами, принадлежащими разным интервалам, назначаются различные месторасположения. Впоследствии, при обработке запроса, данная информация учитывается оптимизатором. Если производится поиск по ключу, то оптимизатор может удалять из рассмотрения фрагменты таблицы, не удовлетворяющие условию выборки. Например, создание кластеризованной таблицы будет выглядеть следующим образом (этот и все остальные SQL-скрипты приведены для Oracle):
Здесь создаются два раздела part1 и part2, каждый из которых размещен в своем табличном пространстве (tblspace1 и tblspace2). Записи со значением поля num от 1 до 499 будут располагаться в первом разделе, а записи с номерами от 500 до 1000 — во втором (рис. 4).
Тогда при запросе:
оптимизатор будет производить поиск только в разделе part1, что может дать ощутимый выигрыш в производительности в таблице с десятками тысяч строк.
Подобные механизмы фрагментации данных поддерживают практически все современные СУБД, что часто используется при создании систем высокой производительности.
Отметьте те из вариантов, в которых данные структурированы:
- данные о продажах компании, представленные в виде помесячных отчётов в формате MS Word
- библиотека фильмов, представленных в формате mpeg4 на одном жестком диске
- (Правильный ответ) таблица с ежедневными показаниями температуры помещения за год в файле формата csv
- текст педагогической поэмы А.С. Макаренко, представленный в формате PDF
Каким образом можно описать вектор (1,2,3,4,5,6)?
К какому типу шкал относится шкала «очень плохо»-«плохо»-«средне»-«хорошо-«очень хорошо»?
- номинальная
- абсолютная
- (Правильный ответ) порядковая
- бинарная
Методы доступа
Современные СУБД предоставляют достаточно широкий набор различных методов доступа, которые чаще всего являются теми или иными видами индексирования — способа отображения ключа индексирования в адрес хранимой записи. Используются следующие типы индексных структур: на основе B-дерева (B-tree); на основе хэш-функции или хеширование (hashing); на базе битовых шкал или индексов (bitmap). Индекс может служить различным целям: для ускорения доступа к записям одной таблицы и для ускорения операций соединения, тогда он называется индексом соединения. Если в качестве ключа индексирования используется некоторая функция атрибутов таблицы, такой индекс называют «основанным на функции» (function-based). Скажем, можно создать такой индекс для ускорения поиска с учетом регистра символов для таблицы Famous (таблица 1):
Отличают также «кластеризованный» (clustered) индекс. При его использовании все записи таблицы упорядочиваются по его ключу; поэтому кластеризованный индекс более экономно расходует память и обычно быстрее опрашивается. Для таблицы, таким образом, можно создать лишь один такой индекс.
B-деревья универсальны и обеспечивают хорошую скорость доступа как при просмотрах по диапазонам, так и при выборке единичной записи по значению ключа, однако характеризуются относительно большим объемом памяти для хранения и затратами на поддержание в актуальном состоянии, включающими обычно балансировку дерева. Такой индекс имеет один существенный недостаток — он может быть использован только в запросах по ведущим столбцам. Например, если в таблице Famous создан составной индекс по столбцам fullname, birth и sex:
смогут использовать этот индекс, а в следующих запросах:
оптимизатор не сможет им воспользоваться, что связано с архитектурными особенностями данного типа индексирования. В данном примере индекс может быть использован при запросах по fullname, birth, sex либо fullname, birth либо только fullname. Несмотря на этот недостаток, индексы B-деревьев наиболее распространены и используются во всех рассматриваемых СУБД. Для B-дерева можно задать «степень использования страницы индекса» (fillfactor); так, в Oracle используются параметры PCTUSED и PCTFREE для блоков базы данных в том числе и индексных. При создании индекса его страницы заполняются только на указанный процент (рис. 5). При увеличении процента использования страницы увеличится скорость операций изменения индекса, однако возрастут также расходы на хранение и может увеличиться время выполнения запросов.
Каждая СУБД может иметь ряд дополнительных параметров, предоставляющих разработчику расширенные возможности конфигурирования В-деревьев.
Хэш-индекс имеет небольшие накладные расходы на хранение, однако требует, чтобы распределение значений ключа индексирования было относительно постоянно, в противном случае потребуется частая переделка индекса на основе новой хэш-функции. Индексы на основе хэш-функций хорошо подходят для различного рода справочных таблиц. При этом не требуется, чтобы индексируемый столбец имел много повторяющихся значений, как того требуют битовые индексы.
Битовые индексы также очень компактны и полезны для столбцов с большим процентом повторения значений ключа. Обычно используют следующее правило: если количество повторяющихся значений столбца более 99% от общего количества строк таблицы, тогда целесообразно рассмотреть использование битового индекса. Так, таблица Famous могла бы выиграть от использования двух битовых индексов — по столбцам SEX и MARRIED.
Битовые индексы обладают очень важным свойством: если производится запрос, включающий сложное условие выборки, которое составлено из предикатов OR, AND, NOT и «=», то оптимизатор может использовать имеющиеся по конкретным столбцам битовые индексы, объединяя их. B-деревья этого делать не позволяют (для этого потребовалось бы построить составной индекс по этим столбцам, специально для ускорения данного запроса). В рассматриваемом примере запрос вида:
может использовать оба битовых индекса emp_ind_02 и emp_ind_03. Однако тот же запрос не сможет использовать два отдельных индекса по этим же столбцам. Битовые карты полезны в хранилищах, где преобладают длинные транзакции и данные читаются чаще чем записываются, однако они неэффективны в приложениях с короткими транзакциями, характерными для OLTP-систем.
В DB2 используется оптимизированный вариант B-дерева с двунаправленными указателями и «упреждающей регистрацией обновлений» (write-ahead logging), что позволяет ускорить вставку данных. При создании индекса можно также использовать некоторые опции, например, указать серверу о необходимости хранить в структуре индекса дополнительные часто запрашиваемые значения атрибутов.
В СУБД Oracle помимо многочисленных индексов используются «индексно-упорядоченные» (index-organized) таблицы и кластеры. В первом случае вся таблица индексирована по первичному ключу и организована в виде B-дерева.
Подобный метод организации хранения хорошо подходит для часто опрашиваемых больших (более 5 тыс. строк) и очень больших таблиц с небольшим объемом операций, для которых критично время выполнения запроса на точное совпадение по первичному ключу, например:
Экономия времени при выполнении таких запросов может составлять от 15 до 400% в зависимости от длины строки [1].
Кластер Oracle — это структура для хранения одной или нескольких таблиц, главным образом служащая для ускорения операций их соединения, в которой строки таблиц, удовлетворяющие условию соединения, хранятся вместе. Столбцы, используемые для соединения, называются кластерным ключом. Значения кластерного ключа сохраняются один раз (дубликаты исключаются). Для доступа по кластерному ключу могут использоваться как B-деревья, так и хэш-структуры, в этом случае кластер является хэш-кластером. Стоит также упомянуть битовый индекс соединения (bitmap join), ускоряющий операции объединения таблиц. В Sybase используются B-деревья, а индекс может быть как кластеризованным так и обычным. В Informix можно применять кластеризованные, битовые и индексы, основанные на функции.
Можно ли с помощью приведённой схемы произвести оценку качества работы алгоритма J48 на загруженных данных?
- (Правильный ответ) да, достаточно одного прогона
- да, только после 100 запусков
- да, только после 10 запусков
- нет
укажите фактор, способствовавший появлению тренда больших данных
- появление новых технологий обработки потоковых данных
- выпуск баз данных с обработкой данных в памяти
- (Правильный ответ) маркетинговые кампании крупных корпораций
- (Правильный ответ) снижение издержек на хранение данных
Организация хранения
Основными единицами физического хранения являются блок данных, экстент, файл (либо раздел жесткого диска). Логический уровень представления информации включает пространства (либо табличные пространства). Блок данных (block) или страница (page) является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных (Oracle) или для ее различных структур (DB2, Informix, Sybase) и устанавливается при создании. Очень важно сразу правильно выбрать размер блока: в работающей базе изменить его практически невозможно (для этого часто проводят ряд испытаний базы данных-прототипа).
Администратор отводит пространство для базы данных на внешних устройствах большими фрагментами: файлами и разделами диска. В первом случае доступ к диску осуществляется операционной системой, что дает определенные преимущества, например, работа с файлами средствами ОС. Во втором случае с внешним устройством работает сам сервер. При этом достигается более высокая производительность; кроме того, использование дисков необходимо в случае, если кэш ОС не может работать в режиме сквозной (write-through) записи. Диски особенно эффективны для ускорения операций записи данных (подобный механизм поддерживается Oracle, DB2 и Informix; например, в DB2 данная единица размещения называется контейнером).
Пространством внешней памяти, отведенным ему администратором, сервер управляет с помощью экстентов (extent), т.е. непрерывных последовательностей блоков. Информация о наличии экстентов для объекта схемы данных находится в специальных управляющих структурах, реализация которых зависит от СУБД. На управление экстентами (выделение пространства, освобождение, слияние) тратятся определенные ресурсы, поэтому для достижения эффективности нужно правильно определять их параметры. СУБД от Oracle, IBM, Informix позволяют определять параметры этих структур, а в Sybase экстенты имеет постоянный размер, равный 8 страницам. Уменьшение размера экстента будет способствовать более эффективному использованию памяти, однако при этом возрастают накладные расходы на управление большим количеством экстентов, что может замедлить операции вставки большого количества строк в таблицу. Кроме того, сервер может иметь ограничение на максимальное количество экстентов для таблицы. При слишком большом размере экстентов могут возникнуть проблемы с выделением для них необходимого количества памяти. Обычно определяется размер начального экстента, размер второго и правило определения размеров следующих экстентов. На рис. 2 иллюстрируется взаимосвязь блоков, экстентов и файлов баз данных.
В Informix существует еще одна единица физического хранения, промежуточная между файлом (или разделом диска) и экстентом, — это «чанк» (от английского chunk, что дословно переводится как «емкость»). Чанк позволяет более гибко управлять очень большими массивами внешней памяти. В одном разделе диска или файле администратор может создать несколько чанков. Чанк также служит единицей зеркалирования.
Общим для СУБД Oracle, DB2 и Informix является понятие пространства (для Oracle и DB2 это табличное пространство). Различные логические структуры данных, такие как таблицы и индексы, временные таблицы и словарь данных размещены в табличных пространствах. В DB2 и Informix дополнительно можно устанавливать размер страницы отдельно для каждой из этих структур. Группировка хранимых данных по пространствам производится по ряду признаков: частота изменения данных, характер работы с данными (преимущественно чтение или запись и т.п.), скорость роста объема данных, важность и т.п. Таким образом, например, только читаемые таблицы помещаются в одно пространство, для которого установлены одни параметры хранения, таблицы транзакций размещаются в пространстве с другими параметрами и т.д. (рис. 3).
Одна логическая единица данных (таблица или индекс) размещается точно в одном пространстве, которое может быть отображено на несколько физических устройств или файлов. При этом физически разнесены (располагаться на разных дисках) могут не только логические единицы данных (таблицы отдельно от индексов), но и данные одной логической структуры (таблица на нескольких дисках). Такой способ хранения называется горизонтальной фрагментацией: таблица делится на фрагменты по строкам. В Oracle вместо термина «фрагментация» используется «секционирование» (partitioning). Фрагментация — один из способов повышения производительности.
Могут применяться различные схемы записи данных во фрагментированные таблицы. Одна из них — круговая (round-robin), когда некоторая часть вставляемых в таблицу строк записывается в первый фрагмент, другая часть — в следующий и так далее по кругу. В данном случае за счет распараллеливания может быть увеличена производительность операций модификации данных и запросов. Существует и другая схема, включающая логическое разделение строк таблицы по ключу («кластеризация»). Данная схема позволяет избежать перерасхода процессорного времени и уменьшить общий объем операций ввода/вывода. Ее суть в том, что при создании таблицы все пространство значений ключа таблицы разбивается на несколько интервалов, а строкам с ключами, принадлежащими разным интервалам, назначаются различные месторасположения. Впоследствии, при обработке запроса, данная информация учитывается оптимизатором. Если производится поиск по ключу, то оптимизатор может удалять из рассмотрения фрагменты таблицы, не удовлетворяющие условию выборки. Например, создание кластеризованной таблицы будет выглядеть следующим образом (этот и все остальные SQL-скрипты приведены для Oracle):
Здесь создаются два раздела part1 и part2, каждый из которых размещен в своем табличном пространстве (tblspace1 и tblspace2). Записи со значением поля num от 1 до 499 будут располагаться в первом разделе, а записи с номерами от 500 до 1000 — во втором (рис. 4).
Тогда при запросе:
оптимизатор будет производить поиск только в разделе part1, что может дать ощутимый выигрыш в производительности в таблице с десятками тысяч строк.
Подобные механизмы фрагментации данных поддерживают практически все современные СУБД, что часто используется при создании систем высокой производительности.
Имеет ли Python аналог Data Frame из R
- (Правильный ответ) да, библиотека Pandas
- да, библиотека SciPy
- нет
- да, библиотека NumPy
В каком случае применение Tableau наиболее оправдано
- необходимо реализовать гибкое интерактивное визуальное представление данных
- проведено исследование, результатом которого стала таблица объект-свойства, необходимо предоставить отчетность
- (Правильный ответ) имеются данные, необходимо более получить ясное понимание этих данных
- не оправдано
Заключение
Эффективность использования любых методов доступа зависит от распределения данных в запрашиваемых таблицах, от стратегии работы оптимизатора СУБД и от возможностей диалекта SQL. Поэтому приведенные рекомендации носят достаточно общий характер — все определяется конкретной ситуацией. Решения, принимаемые на этапах физического проектирования и настройки, чаще всего представляют собой компромисс между достижением требуемых характеристик, которые часто противоречат друг другу. За выигрыш в скорости обработки запросов, которую дает индекс, приходится платить дополнительными ресурсами памяти на его размещение и процессорным временем для его поддержки в актуальном состоянии. К сожалению, трудно привести конкретные оценки: многое зависит от конфигурации сервера, настройки ОС и СУБД и т.п.
Рассмотренный перечень методов доступа не является полным. Описаны лишь распространенные технологии, которые можно назвать традиционными. Например, за кадром остались возможности современных СУБД, связанные с реализацией расширяемой системы типов данных. Сюда относят технологии расширителей (Extender) IBM, DataBlade (Informix) и картриджей (Oracle). Тем не менее, перечисленный арсенал средств достаточно богат сам по себе. Адекватное представление об этих средствах позволяет сделать проектируемые базы данных и их приложения менее зависимыми от конкретной СУБД.
Литература

Всем привет. Кто-то из вас, возможно, уже знаком с СУБД для данных в оперативной памяти, но на всякий случай — по ссылке можно найти их общее описание. Если вкратце, такие СУБД хранят данные целиком в оперативной памяти. Что это означает? Каждый раз, отправляя запрос на поиск или обновление данных, вы обращаетесь только к оперативной памяти в обход жесткого диска — на нем никакие операции не производятся. И это хорошо, потому что оперативная память работает намного быстрее любого диска. Примером такой СУБД является Memcached.
Секундочку, скажете вы, а как же восстановить данные после перезагрузки или поломки машины с такой СУБД? Если на машине установлена СУБД для хранения данных только в оперативной памяти, о них можно забыть: при отключении питания данные бесследно исчезнут.
Можно ли объединить достоинства хранения данных в оперативной памяти с надежностью проверенных временем СУБД вроде MySQL или Postgres? Конечно! Повлияет ли это на производительность? Вы удивитесь, но нет!
Встречайте СУБД для данных в оперативной памяти, обеспечивающие их сохранность: Redis, Aerospike, Tarantool.
Вы можете спросить, как же эти СУБД обеспечивают сохранность данных? Фокус в том, что все данные по-прежнему хранятся в оперативной памяти, но каждая операция вдобавок записывается в расположенный на диске журнал транзакций. Посмотрите на изображение ниже:


Транзакции всегда записываются в самый конец журнала. В чем плюс такого подхода? Диск работает довольно быстро. Если говорить о классическом жестком диске (HDD), он может записывать данные в конец файла со скоростью до 100 Мбайт/с. Не верите? Запустите этот тест из командной строки в Unix/Linux/macOS:
И посмотрите, как быстро увеличивается размер some_file . Итак, жесткий диск весьма проворен при последовательной записи, однако его скорость резко падает при произвольной записи: обычно он способен выполнить около 100 таких операций.
При побайтовой записи, когда каждый байт записывается в произвольное место на жестком диске, вы можете увидеть, что реальная максимальная производительность диска составляет 100 байтов/с. Еще раз, всего-навсего 100 байтов/с! Разница в шесть порядков между пессимистичной (100 байтов/с) и оптимистичной (100 000 000 байтов/с) оценками скорости доступа к диску столь велика потому, что для поиска по произвольному сектору на диске требуется физическое движение головки диска, тогда как при последовательном доступе можно считывать данные по мере вращения диска; головка при этом остается неподвижной.
Если говорить о твердотельном накопителе (SSD), здесь ситуация лучше из-за отсутствия движущихся частей. Однако соотношение пессимистичной (1—10 тысяч операций в секунду) и оптимистичной (200—300 Мбайт/с) оценок остается практически неизменным: четыре-пять порядков. Подробнее с этими показателями можно ознакомиться по ссылке.
Таким образом, наша СУБД для данных в оперативной памяти, по сути, наводняет журнал транзакциями со скоростью до 100 Мбайт/с. Достаточно ли это быстро? Очень быстро. Предположим, размер транзакции составляет 100 байтов, тогда скорость будет равняться миллиону транзакций в секунду! Это настолько хороший показатель, что вам абсолютно точно не придется волноваться о производительности диска при использовании подобной СУБД. По ссылке ниже находится подробный тест производительности одной СУБД в оперативной памяти при обработке миллиона транзакций в секунду, где проблемным элементом является не диск, а процессор:
Подведем итог всему вышесказанному о дисках и СУБД в оперативной памяти:
- СУБД в оперативной памяти не обращаются к диску при обработке запросов, не изменяющих данные.
- СУБД в оперативной памяти все-таки обращаются к диску при обработке запросов, изменяющих данные, но работают с ним на максимальной скорости.
Во-вторых, дисковые СУБД должны сохранять данные таким образом, чтобы измененные данные можно было немедленно считать, в отличие от СУБД в оперативной памяти, которые не считывают с диска, за исключением случаев, когда при старте запускается восстановление. Именно поэтому для быстрого считывания дисковым СУБД нужны особые структуры данных, чтобы избежать полного сканирования журнала транзакций.
Одна из таких структур — B/B+-дерево, ускоряющее считывание данных. Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе, что может привести к падению производительности из-за произвольного доступа к диску. Довольно много движков СУБД основано на B/B+-деревьях, из популярных можно назвать InnoDB от MySQL и движок Postgres.
Существует другая структура, которая лучше справляется с записью данных, — LSM-дерево. Это относительно новый тип деревьев, который не решает проблему произвольного считывания, но помогает избавиться от части проблем, связанных с произвольной записью. Примерами движков, использующих такие деревья, могут служить RocksDB, LevelDB или Vinyl. На изображении ниже приведена сводная информация о типах СУБД и используемых ими деревьях:

Резюмируем вышесказанное: СУБД в оперативной памяти, обеспечивающие сохранность данных, как при считывании, так и при записи могут работать очень быстро, а точнее — так же быстро, как и СУБД в оперативной памяти, которые не сохраняют данные на диске: первые используют диск настолько эффективно, что он никогда не становится проблемным местом.
Последняя — по порядку, но не по значимости — тема, которую я хотел бы затронуть в статье, посвящена снимкам состояния. Снятие таких снимков необходимо для компактификации журналов транзакций. Снимок состояния базы данных — это копия всех имеющихся данных. Снимка и журналов с последними транзакциями достаточно для восстановления состояния вашей базы данных. Поэтому, имея свежий снимок состояния, можно удалять все старые журналы транзакций, предшествующие дате снимка.
Зачем компактифицировать журналы? Потому что чем больше журналов, тем дольше будет восстановление базы данных. И потом, вам ведь не хочется захламлять диск устаревшей и бесполезной информацией (ну хорошо, старые журналы иногда здорово выручают, но давайте поговорим об этом в отдельной статье).
По сути, периодически делая снимки состояния, вы целиком копируете базу данных из оперативной памяти на диск. Как только копирование закончилось, можно смело удалять все журналы, в которых нет транзакций, записанных позже последней транзакции в вашем снимке состояния. Довольно просто, не так ли? А все потому, что все транзакции начиная с самого первого дня попадают в снимок.
Вы могли задаться вопросом: как сохранить консистентное состояние базы данных на диск и как определить последнюю зафиксированную в снимке транзакцию при условии постоянного поступления новых транзакций? Об этом мы поговорим в следующей статье.

В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
Всё это время мы проводили масштабное тестирование нескольких in-memory СУБД. Любой разговор с администраторами DWH в это время можно было начать с фразы «Ну как, кто лидирует?», и не прогадать. В ответ люди получали длинную и очень эмоциональную тираду о сложностях тестирования, премудростях общения с доселе неизвестными вендорами и недостатках отдельных испытуемых.
Подробности, результаты и некое подобие выводов из тестирования — под катом.
Цель тестирования — присмотреть себе быструю аналитическую in-memory базу данных, отвечающую нашим требованиям, и оценить сложность её интеграции с остальными системами хранилища данных.
Также мы включили в тестирование две СУБД, не позиционирующиеся как in-memory решение. Мы рассчитывали на то, что имеющиеся в них механизмы кэширования, при условии примерного соответствия объёма данных объёму оперативной памяти серверов, позволят этим СУБД приблизиться в производительности к классическим in-memory решениям.
Описание кейса использования
Предполагается, что выбранная в результате тестирования СУБД будет работать в качестве front-end БД хранилища для выборочного набора данных (2-4 Тб, однако объём данных может расти со временем): принимать на себя запросы от BI-системы (SAP BusinessObjects) и часть ad-hoc запросов некоторых пользователей. Запросы, в 90% случаев, это SELECT'ы c от 1 до 10 join-ами по условиям равенства и, иногда, условиям вхождения дат в интервал.
Нам нужно, чтобы такие запросы работали значительно быстрее, чем они работают сейчас в основной БД хранилища — Greenplum.
Также важно, чтобы количество одновременно выполняемых запросов не сильно влияло на время выполнения каждого запроса — оно должно быть примерно постоянным.
На наш взгляд, целевая БД должна обладать следующей функциональностью:
- горизонтальная масштабируемость;
- возможность выполнять локальные join-ы — использовать «правильный» ключ распределения в таблицах
- поколоночное хранение данных;
- умение работать с кэшем и большим объёмом доступной памяти.
Также важна возможность интеграции с SAP BO. К счастью, с этой системой хорошо работает почти всё, что имеет стабильный ODBC-драйвер для Windows.
Из мелких, но весомых требований можно выделить оконные функции, резервирование (способность хранить несколько копий данных на разных нодах), простота дальнейшего расширения кластера, параллельная загрузка данных.
Стенд для тестирования
На каждую БД было выделено два физических сервера:
- 16 физических ядер (32 с HT)
- 128 Гб ОП
- 3.9 Тб дискового пространтства (RAID 5 из 8 дисков)
- Сервера связаны 10 Гбит-ой сетью.
- ОС для каждой БД была выбрана исходя из рекомендаций по установке этой самой БД. То же касается настроек ОС, ядра и прочего.
Критерии тестирования
- Скорость выполнения тестовых запросов
- Возможность интеграции с SAP BO
- Наличие быстрого и подходящего способа импорта данных
- Наличие стабильного ODBC-драйвера
- В случае, если продукт не распространяется свободно, удалось в адекватное время связаться с представителями компании производителя и получить инсталляцию (дистрибутив) БД, необходимую для тестирования
БД, вошедшие в тестирование

Greenplum
Старый, добрый, хорошо знакомый нам Greenplum. Про него у нас есть отдельная статья.
Строго говоря, Greenplum не является in-memory БД, однако экспериментально доказано, что за счёт свойств XFS, на которой он хранит данные, при определённых условиях он ведёт себя как таковая.
Так, например, при чтении, если количество памяти достаточно, а также если данные, запрашиваемые запросом, уже лежат в памяти (закэшированы), диски для получения данных затронуты не будут вообще — все данные Greenplum возьмёт из памяти. Надо понимать, что такой режим работы не свойственен для Greenplum, а потому специализированные in-memory DB должны (в теории) справляться с такой задачей лучше.
Для тестирования Greenplum был установлен по умолчанию, без зеркал (только primary-сегменты). Все настройки дефолтные, таблицы сжаты zlib.

Yandex Clickhouse
Колоночная СУБД для аналитики и отчётов в реальном времени от известного поискового гиганта.
СУБД установлена с учётом рекомендаций производителя, движок для локальных таблиц — MergeTree, поверх локальных таблиц были созданы Distributed-таблицы, которые и участвовали в запросах.
HANA (High performance ANalytics Appliance) позиционируется как универсальный инструмент для аналитической и транзакционной нагрузки. Умеет хранить данные поколоночно. Имеются нужные для продуктовой базы Disaster recovery, зеркалирование и репликация. HANA позволяет гибко настроить партиции (шарды) для таблиц: как по hash, так и по интервалу значений.
В наличии многоуровневое партиционирование, на разных уровнях можно применять различные типы партиций. В одну партицию можно записать до 2 миллиардов записей.
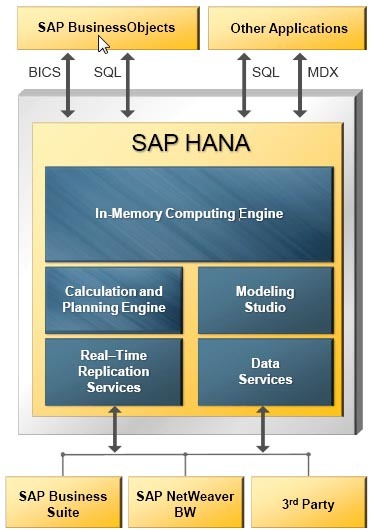
Архитектура решения на базе SAP HANA
Одна из интересных возможностей этой СУБД — потабличная настройка «unload priority» — приоритета выгрузки из памяти, от 1 до 10. Она позволяет гибко управлять ресурсами памяти и скоростью доступа к таблицам: если таблица используется редко, то ей устанавливается наименьший приоритет. В таком случае таблица будет редко загружаться в память и будет одной из первых выгружаться при нехватке ресурсов.
Продукт в России практически неизвестный, тёмная лошадка. Из крупных компаний с этой СУБД работают только Badoo (о чём на Хабре есть статья) и ещё пара не-IT компаний, чьё имя на слуху — полный список есть на официальном сайте.
Вендор обещает феерически быструю аналитику, стабильность камня в лесу и простоту администрирования на уровне кофемолки.
Работает Exasol на своей ОС — ExaOS (свой дистрибутив GNU/Linux на основе CentOS/RHEL). Установка СУБД как минимум необычна, так как это не установка отдельного куска ПО на готовую ОС, а установка ОС на отдельную лицензионную машину (в нашем случае виртуальную) из скачанного образа и минимальная настройка (разбиение дисков, сетевые интерфейсы, разрешить загрузку по PxE) рабочих нод.
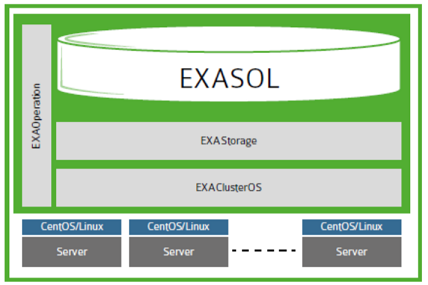
Упрощённая архитектура Exasol
Красота этой системы в том, что, так как на ноды ничего устанавливать не надо (ОС, параметры ядра и прочие радости), добавление новой ноды в кластер происходит очень быстро. С того момента, как сервер установлен и скоммутирован (bare-metal, без ОС), можно ввести ноду в кластер менее чем за полчаса. Все управление базой осуществляется через веб-консоль. Лишним функционалом она не перегружена, но и урезанной ее назвать нельзя.
Данные хранятся в памяти поколоночно и неплохо сжимаются (настроек сжатия при этом обнаружить не удалось).
Если при обработке запроса надо данных больше чем есть ОЗУ, база начнет использовать своп (спилл) на диски. Запрос не упадет (привет Hana и memSQL), просто будет работать медленней.
Exasol автоматически создает и удаляет индексы. Если вы делаете запрос впервые и СУБД решает, что с индексом запрос будет работать быстрее, то индекс будет создан в процессе отработки запроса. А если этот индекс 30 дней никому не был нужен, то база сама его удалит. Вот какая умная лошадка.
In-memory СУБД на основе mySQL. Кластерная, присутствуют аналитические функции. По умолчанию хранит данные построчно.
Чтобы сделать поколоночное хранение, нужно при создании таблицы добавить специальный индекс:
При этом rowstore-данные хранятся в памяти всегда, а вот columnstore-данные, в случае нехватки памяти, могут быть автоматически сброшены на диск.
Ключ дистрибуции называется SHARD KEY. Автоматически для каждого поля в shard key создается btree индекс.
Базовая версия — полностью бесплатная, без ограничений по объему данных и оперативной памяти. В платной версии есть high availability, онлайн бэкапы и ресторы, репликация между дата-центрами и управление правами пользователей.
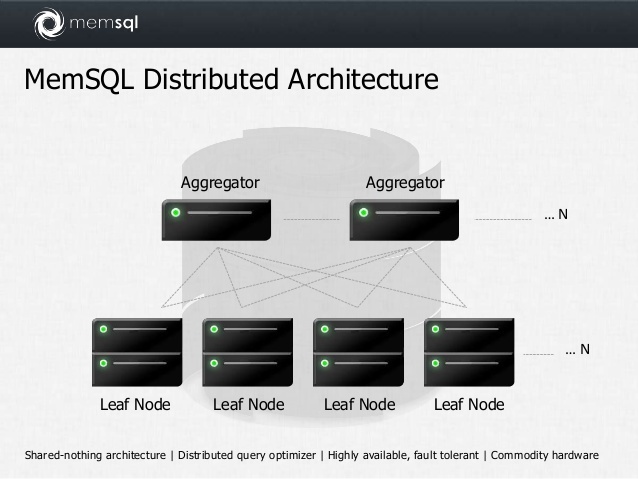
Упрощённая архитектура Memsql
Продукт Cloudera, SQL движок, разработанный на С++, входит в экосистему Apache Hadoop. Работает с данными, хранящимися в HDFS и HBase. В качестве хранилища метаданных использует HiveMetastore, входящий в состав СУБД Hive. В отличие от Hive, не использует MapReduce. Поддерживает кеширование часто используемых блоков данных.
Позиционируется как СУБД для обработки аналитических запросов, требующих быстрого ответа. Умеет работать с основными BI-инструментами. Полная поддержка ANSI SQL, присутствуют оконные функции.
Impala доступна в виде пакета и парцела в репозитории Cloudera. При проведении тестирования использовался дистрибутив Cloudera CDH 5.8.0. Для установки был выбран минимальный набор сервисов для работы Impala: Zookeeper, HDFS, Yarn, Hive. Большая часть настроек использовалась по умолчанию. Для Impala было выделено суммарно 160 Гб памяти с обоих серверов. Для контроля утилизации ресурсов серверов контейнерами использовались cgroups.
Были выполнены все оптимизации, рекомендованные в статье, а именно:
— в качестве формата хранения таблиц в HDFS был выбран Parquet;
— оптимизированы типы данных, где это можно было сделать;
— предварительно выполнялся сбор статистики для каждой таблицы (compute stats);
— данные всех таблиц были записаны в кэш HDFS (alter table … set cached in …);
— оптимизированы join’ы (насколько это было возможно).
На первоначальном этапе планирования тестирования и определения СУБД для участия Impala была отброшена, поскольку мы уже работали с ней несколько лет назад и на тот момент она не выглядела production-ready. Ещё раз посмотреть в сторону «Антилопы» нас убедили коллеги по отрасли, убеждая, что за прошедшее время она очень похорошела и научилась грамотно работать с памятью.
Состав:
Impala Daemon – основной сервис, который служит для принятия, обработки, координирования, распределения по кластеру и выполнения запроса. Поддерживает интерфейсы ODBC и JDBC. Также имеет CLI-интерфейс и интерфейс для работы с Hue (Web UI для анализа данных в Hadoop). Выполняется в качестве демона на каждом из воркеров кластера.
Impala Statestore – используется для проверки состояния инстансов Impala Daemon, работающих в кластере. Если на каком-либо воркере выходит из строя Impala Daemon, то Statestore уведомляет об этом инстансы на остальных воркерах, чтобы запросы к ушедшему в offline инстансу не передавались. Как правило, работает на мастер-ноде кластера, не является обязательным.
Impala Catalog Server – этот сервис служит для получения и агрегации метаданных из HiveMetastore, HDFS Namenode, HBase в виде структуры, поддерживаемой Impala Daemon. Также этот сервис используется для хранения метаданных, используемых исключительно самой Impala, таких, например, как пользовательские функции. Как правило, работает на мастер-ноде кластера.

Для смелых - эта же таблица в формате Хабра (острожно, редизайн хабра сделал мало-мальски широкие таблицы нечитаемыми)
| Greenplum | Exasol | Clickhouse | Memsql | SAP Hana | Impala | |
| Вендор | EMC | Exasol | Yandex | Memsql | SAP | Apache / Cloudera |
| Используемая версия | 4.3.8.1 | 5.0.15 | 1.1.53988 | 5.1.0 | 1.00.121.00.1466466057 | 2.6.0 |
| Мастер-ноды | Мастер-сегмент. Резервируется. | Точка входа — любая нода. Есть license-нода, резервируется. | Точка входа — любая нода | Точка входа — любая нода | Есть мастер-нода. Резервируется. | Точка входа — любая нода. Однако, нужен Hive metastore server. |
| Используемая ОС | RHEL 6.7 | EXA OS (проприетарная) | Ubuntu 14.04.4 | RHEL 6.7 | RHEL 6.7 | RHEL 6.7 |
| Возможное железо | Любое | Любое с поддержкой PXE Boot | Любое | Любое | Только из списка SAP | Любое |
| Импорт из Greenplum | External http tablesPipes | External http tablesJDBC import | External http tables | CSV с локального сервераSPARK | CSV с локального сервера | External GPHDFS tables |
| Интеграция с SAP BO(источник для юниверсов) | Да, ODBC | Да, ODBC | Нет данных | Нет данных | Да | Да, ODBCSIMBA |
| Интеграция с SAS | Да, SAS ACCESS | Да, ODBC | Нет данных | Нет данных | Нет данных | Да, SAS ACCESS |
| Оконные функции | Есть | Есть | Нет | Есть | Есть | Есть |
| Дистрибуция по нодам | По полю/полям | По полю/полям | По полю/полям | По полю/полям | По полю/полямШарды раскидываютсяпо нодам вручную | Рандомно |
| Колоночное хранение | Есть | Есть | Есть | Есть на дискеНет в пямяти | Есть | Есть (Parquet) |
| При нехватке памяти при выполнении запроса | Данные спилятся на диск | Данные спилятся на диск | Запрос падает | Запрос падает | Запрос падает | Данные спилятся на диск |
| Отказоустойчивость | Есть, механизм зеркал | Есть, механизм зеркал | Есть, на уровне таблиц | Есть | Есть | Есть, силами HDFS |
| Способ распространения | Open source, APACHE-2 | Закрытый код, платная | Open source, APACHE-2 | Закрытый код, бесплатная | Закрытый код, платная | Open source, APACHE-2 |
Результаты тестирования

Для тестирования были подобраны запросы с d_financial_account_not_additive. d_financial_account_not_additive — это представление (view) с данными по каждому счету на каждый день. View сделано на основе трех таблиц с целью оптимизации места на диске, и, соответственно, чтения с диска. Для тестирования была выбрана часть данных по первому миллиону счетов с начала 2015 года. Это чуть больше 522 миллионов строк. К not_additive мы присоединяем данные по счетам (financial_account) и по заявкам (financial_account_application и application_calling_channel). В Greenplum (для примера) для таблиц заданы ключи распределения по сегментам: для счетов это account_rk, для заявок – financial_application_rk. В запросах join-ы между основными таблицами происходят по равенству, поэтому мы можем ожидать hash join, без nested loop, когда нужно сравнить построчно большое количество строк из разных таблиц.
Общий объём данных составил около 200 Гб в несжатом виде (рассчитываем, что весь этот объём с небольшим запасом влезает в память).
Число строк в используемых таблицах:
Какие из перечисленных признаков таблицы представлены в абсолютной шкале?
- (Правильный ответ) никакие
- Temperature, Humidity
- Temperature
- Humidity
Читайте также: