
Какие приложения используют многопоточность процессора
Когда мы говорим о процессоры для ПК , очень часто говорят о количестве ядер и потоках обработки или исполнения, которые обычно вдвое превышают количество ядер, потому что Hyper Threading технологии в случае Intel и SMT в корпусе of AMD они делают то, что каждое ядро может выполнять две одновременные задачи. Однако это довольно простой способ объяснить, как многопоточность на процессоре, и в этой статье мы собираемся объяснить его вам более подробно, чтобы вы могли понять все его входы и выходы.
Тем не менее, все мы знаем, что процессор, у которого больше потоков, чем ядер, способен выполнять больше задач одновременно, и на самом деле операционная система определяет процессор, как если бы у него на самом деле было столько ядер, сколько потоков. Например, Intel Core i7-8700K имеет 6 ядер и 12 потоков благодаря технологии HyperThreading, и Windows 10 распознает его как 12-ядерный процессор как есть (правда, он называет их «логическими процессорами»), потому что для операционной системы его работа полностью прозрачна.

Типы многопоточной обработки
Как мы уже говорили в начале, у всех нас есть концепция, что многопоточная обработка - это просто распараллеливание процессов (то есть выполнение нескольких задач одновременно), но на самом деле все немного сложнее, и существуют разные типы. многопоточная обработка.
Процессы в Java: определение и функции
Процесс состоит из кода и данных. Он создается операционной системой при запуске приложения, является достаточно ресурсоемким и обладает собственным виртуальным адресным пространством.
Процессы работают независимо друг от друга. Они не имеют прямого доступа к общим данным в других процессах.
Операционная система выделяет ресурсы для процесса — память и время на выполнение.
Если один из процессов заблокирован, то ни один другой процесс не может выполняться, пока он не будет разблокирован.
Для создания нового процесса обычно дублируется родительский процесс.
Процесс может контролировать дочерние процессы, но не процессы того же уровня.
Основные средства синхронизации
Взаимоисключение (mutual exclusion, сокращённо — mutex) — «флажок», переходящий к потоку, который в данный момент имеет право работать с общими ресурсами. Исключает доступ остальных потоков к занятому участку памяти. Мьютексов в приложении может быть несколько, и они могут разделяться между процессами. Есть подвох: mutex заставляет приложение каждый раз обращаться к ядру операционной системы, что накладно.
Семафор — позволяет вам ограничить число потоков, имеющих доступ к ресурсу в конкретный момент. Так вы снизите нагрузку на процессор при выполнении кода, где есть узкие места. Проблема в том, что оптимальное число потоков зависит от машины пользователя.
Событие — вы определяете условие, при наступлении которого управление передаётся нужному потоку. Данными о событиях потоки обмениваются, чтобы развивать и логически продолжать действия друг друга. Один получил данные, другой проверил их корректность, третий — сохранил на жёсткий диск. События различаются по способу отмены сигнала о них. Если нужно уведомить о событии несколько потоков, для остановки сигнала придётся вручную ставить функцию отмены. Если же целевой поток только один, можно создать событие с автоматическим сбросом. Оно само остановит сигнал, после того как он дойдёт до потока. Для гибкого управления потоками события можно выстраивать в очередь.
Критическая секция — более сложный механизм, который объединяет в себе счётчик цикла и семафор. Счётчик позволяет отложить запуск семафора на нужное время. Преимущество в том, что ядро задействуется лишь в случае, если секция занята и нужно включать семафор. В остальное время поток выполняется в пользовательском режиме. Увы, секцию можно использовать только внутри одного процесса.
Разница между потоками и процессами
Потоки используют память, выделенную под процесс, а процессы требуют себе отдельное место в памяти. Поэтому потоки создаются и завершаются быстрее: системе не нужно каждый раз выделять им новое адресное пространство, а потом высвобождать его.
Процессы работают каждый со своими данными — обмениваться чем-то они могут только через механизм межпроцессного взаимодействия. Потоки обращаются к данным и ресурсам друг друга напрямую: что изменил один — сразу доступно всем. Поток может контролировать «собратьев» по процессу, в то время как процесс контролирует исключительно своих «дочек». Поэтому переключаться между потоками быстрее и коммуникация между ними организована проще.
Какой отсюда вывод? Если вам нужно как можно быстрее обработать большой объём данных, разбейте его на куски, которые можно обрабатывать отдельными потоками, а затем соберите результат воедино. Это лучше, чем плодить жадные до ресурсов процессы.
Но почему такое популярное приложение как Firefox идёт по пути создания нескольких процессов? Потому что именно для браузера изолированная работа вкладок — это надёжно и гибко. Если с одним процессом что-то не так, не обязательно завершать программу целиком — есть возможность сохранить хотя бы часть данных.
О потоках и их истоках
Чтобы понять многопоточность, сначала вникнем, что такое процесс. Процесс – это часть виртуальной памяти и ресурсов, которую ОС выделяет для выполнения программы. Если открыть несколько экземпляров одного приложения, под каждый система выделит по процессу. В современных браузерах за каждую вкладку может отвечать отдельный процесс.
Вы наверняка сталкивались с «Диспетчером задач» Windows (в Linux это — «Системный монитор») и знаете, что лишние запущенные процессы грузят систему, а самые «тяжёлые» из них часто зависают, так что их приходится завершать принудительно.
Но пользователи любят многозадачность: хлебом не корми — дай открыть с десяток окон и попрыгать туда-сюда. Налицо дилемма: нужно обеспечить одновременную работу приложений и при этом снизить нагрузку на систему, чтобы она не тормозила. Допустим, «железу» не угнаться за потребностями владельцев — нужно решать вопрос на программном уровне.
Мы хотим, чтобы в единицу времени процессор успевал выполнить больше команд и обработать больше данных. То есть нам надо уместить в каждом кванте времени больше выполненного кода. Представьте единицу выполнения кода в виде объекта — это и есть поток.
К сложному делу легче подступиться, если разбить его на несколько простых. Так и при работе с памятью: «тяжёлый» процесс делят на потоки, которые занимают меньше ресурсов и скорее доносят код до вычислителя (как именно — см. ниже).
У каждого приложения есть как минимум один процесс, а у каждого процесса — минимум один поток, который называют главным и из которого при необходимости запускают новые.
Что такое многопоточная обработка?
В компьютерной архитектуре многопоточная обработка - это способность центрального процессора (ЦП), чтобы обеспечить одновременное выполнение нескольких потоков, поддерживаемых операционной системой. Этот подход отличается от многопроцессорности, и его не следует путать; В многопоточном приложении потоки совместно используют ресурсы одного или нескольких ядер процессора, включая вычислительные блоки, кэш и буфер поиска трансляции (TLBL).
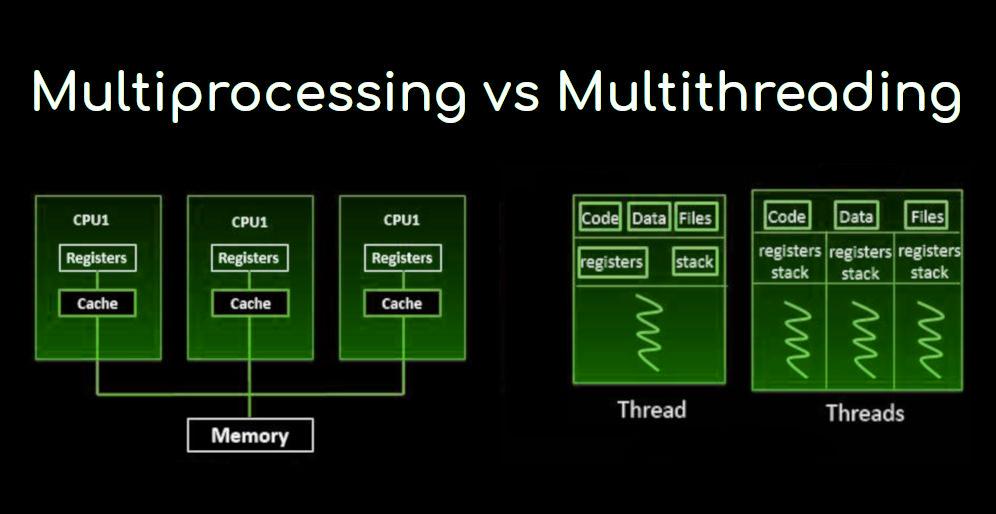
Когда многопроцессорные системы включают в себя несколько полных процессоров на одном или нескольких ядрах, многопроцессорность направлена на увеличение использования одного ядра за счет использования параллелизма на уровне потоков, а также параллелизма на уровне команд. Поскольку эти два метода дополняют друг друга, они объединены почти во всех современных системных архитектурах с несколькими многопоточными ЦП и с многоядерными ЦП, способными работать с несколькими потоками.
Многопоточная парадигма стала более популярной, поскольку попытки использовать параллелизм на уровне инструкций (то есть возможность выполнять несколько инструкций параллельно) застопорились в конце 1990-х годов. Это позволило концепции высокопроизводительных вычислений выйти из более специализированной области обработки транзакций.
Хотя дальнейшее ускорение отдельного потока или программы очень сложно, большинство компьютерных систем фактически выполняют многозадачность между несколькими потоками или программами, и поэтому методы, улучшающие производительность всех задач, приводят к увеличению производительности. Генеральная. Другими словами, чем больше инструкций может обрабатывать ЦП одновременно, тем выше общая производительность всей системы.
Что такое потоки
Поток — наименьшее составляющее процесса. Потоки могут выполняться параллельно друг с другом. Их также часто называют легковесными процессами. Они используют адресное пространство процесса и делят его с другими потоками.
Потоки могут контролироваться друг друга и общаться посредством методов wait(), notify(), notifyAll().
Параллельная многопоточность
Самый продвинутый тип многопоточности применяется к процессорам, известным как суперскаляры. В то время как типичный суперскалярный ЦП выдает несколько инструкций из одного потока в каждом цикле ЦП, при одновременной многопоточной обработке (SMT) суперскалярный процессор может выдавать инструкции из нескольких потоков в каждом цикле. Признавая, что любой поток имеет ограниченный уровень параллелизма на уровне инструкций, эта многопоточность пытается использовать параллелизм, доступный для нескольких потоков, для уменьшения потерь, связанных с неиспользуемыми пространствами.
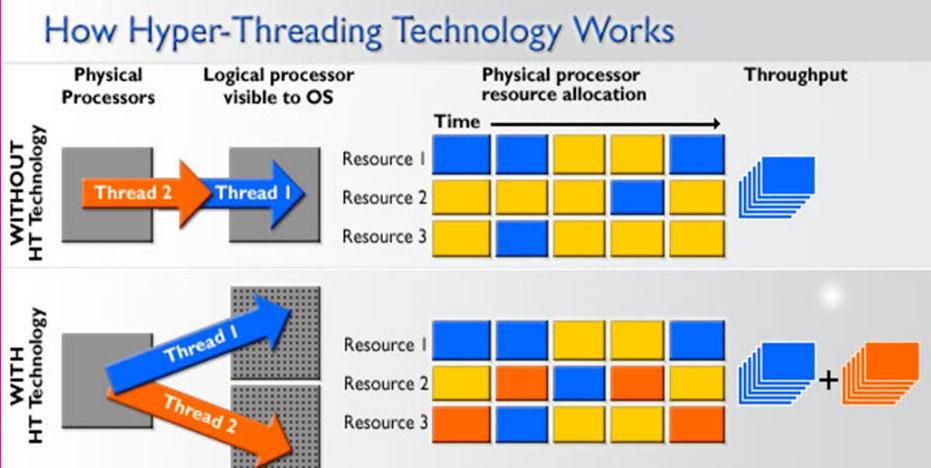
Чтобы различать другие типы многопоточной обработки SMT, часто используется термин «временная многопоточная», чтобы указать, когда однопоточные инструкции могут выполняться одновременно. Реализации этого типа включают DEC, EV8, Intel HyperThreading Technology, IBM Power5, Sun Mycrosystems UltraSPARC T2, Cray XMT, а также микроархитектуры Bulldozer и Zen от AMD.
Многопоточность в Java — это одновременное выполнение двух или более потоков для максимального использования центрального процессора (CPU — central processing unit). Каждый поток работает параллельно и не требует отдельной области памяти. К тому же, переключение контекста между потоками занимает меньше времени.
Лучшее использование одного центрального процессора: если поток ожидает ответ на запрос, отправленный по сети, другой поток в это время может использовать CPU для выполнения других задач. Кроме того, если у компьютера несколько CPU или у CPU несколько исполнительных ядер, многопоточность позволяет приложению использовать эти дополнительные ядра.
Оптимальное использование нескольких центральных процессоров или их ядер: необходимо использовать несколько потоков в приложении, чтобы задействовать все CPU или ядра CPU. Один поток может использовать максимум один CPU, иногда даже не полностью.
Улучшенный user experience в плане скорости ответа на запрос: например, если нажать на кнопку в графическом интерфейсе, то это действие отправит запрос по сети: здесь важно, какой поток выполняет этот запрос. Если используется тот же поток, который обновляет/уведомляет графический интерфейс, тогда пользователь может столкнуться с зависанием интерфейса, ожидающего ответа на запрос. Но этот запрос может выполнить фоновый поток, чтобы поток в графическом интерфейсе мог в это время реагировать на другие запросы пользователя.
Улучшенный user experience в плане справедливости распределения ресурсов: многопоточность позволяет справедливо распределять ресурсы компьютера между пользователями. Представьте сервер, который принимает запросы от клиентов и у него есть только один поток для выполнения этих запросов. Если клиент отправляет запрос, для обработки которого нужно много времени, все остальные запросы вынуждены ждать до тех пор, пока он завершится. Когда каждый клиентский запрос выполняется собственным потоком, ни одна задача не сможет полностью захватить CPU.
Многопоточность с чередованием
Целью этого типа многопоточной обработки является снятие всех блокировок зависимостей данных с конвейера выполнения. Поскольку один поток относительно независим от других, меньше шансов, что инструкции на стадии конвейера потребуется вывод предыдущей инструкции в том же канале; Концептуально это похоже на превентивную многозадачность, используемую в операционной системе, и аналогией может быть то, что временной интервал, предоставляемый каждому активному потоку, составляет один цикл ЦП.
Конечно, этот тип многопоточной обработки имеет главный недостаток, заключающийся в том, что каждый этап конвейера должен отслеживать идентификатор потока инструкции, которую он обрабатывает, что снижает его производительность. Кроме того, поскольку в конвейере одновременно выполняется больше потоков, общие ресурсы, такие как кеш, должны быть больше, чтобы избежать ошибок.
Жди сигнала: синхронизация в многопоточных приложениях
Представьте, что несколько потоков пытаются одновременно изменить одну и ту же область данных. Чьи изменения будут в итоге приняты, а чьи — отменены? Чтобы работа с общими ресурсами не приводила к путанице, потокам нужно координировать свои действия. Для этого они обмениваются информацией с помощью сигналов. Каждый поток сообщает другим, что он сейчас делает и каких изменений ждать. Так данные всех потоков о текущем состоянии ресурсов синхронизируются.
В категориях объектно-ориентированного программирования сигналы — это объекты синхронизации. У каждого из них — своя роль во взаимодействии.
Способы запуска потоков
Приложение, создающее экземпляр класса Thread, должно предоставить код, который будет работать в этом потоке. Существует два способа, чтобы добиться этого:
Предоставить реализацию объекта Runnable. Интерфейс Runnable определяет единственный метод — run, который должен содержать код, выполняющийся в потоке. Объект Runnable передается конструктору Thread. Например:
Использовать подкласс Thread. Класс Thread сам реализует Runnable, хотя его метод run не делает ничего. Можно объявить класс Thread подклассом, предоставляя собственную реализацию метода run, как в примере:
Обратите внимание, что оба примера вызывают Thread.start, чтобы запустить новый поток.
Какой из способов выбрать? Первый — с использованием объекта Runnable — более общий, потому что этот объект может превратить отличный от Thread класс в подкласс. Этот способ более гибкий и может использоваться для высокоуровневых API управления потоками.
Второй способ больше подходит для простых приложений, но есть условие: класс задачи должен быть потомком Thread.
Как реализовать многопоточность в Java
За работу с потоками в Java отвечает класс Thread. Создать новый поток для выполнения задачи — значит создать экземпляр класса Thread и связать его с нужным кодом. Сделать это можно двумя путями:
образовать от Thread подкласс;
имплементировать в своём классе интерфейс Runnable, после чего передавать экземпляры класса в конструктор Thread.
Пока мы не будем затрагивать тему тупиковых ситуаций (deadlock'ов), когда потоки блокируют работу друг друга и зависают — оставим это для следующей статьи. А сейчас перейдём к практике.
Что такое многопоточность
Вот мы и подошли к главному. Многопоточность — это когда процесс приложения разбит на потоки, которые параллельно — в одну единицу времени — обрабатываются процессором.
Вычислительная нагрузка распределяется между двумя или более ядрами, так что интерфейс и другие компоненты программы не замедляют работу друг друга.
Многопоточные приложения можно запускать и на одноядерных процессорах, но тогда потоки выполняются по очереди: первый поработал, его состояние сохранили — дали поработать второму, сохранили — вернулись к первому или запустили третий, и т.д.

Занятые люди жалуются, что у них всего две руки. Процессы и программы могут иметь столько рук, сколько нужно для скорейшего выполнения задачи.
Состояния потоков
Потоки могут пребывать в нескольких состояниях:
New – когда создается экземпляр класса Thread, поток находится в состоянии new. Он пока еще не работает.
Running — поток запущен и процессор начинает его выполнение. Во время выполнения состояние потока также может измениться на Runnable, Dead или Blocked.
Suspended — запущенный поток приостанавливает свою работу, затем можно возобновить его выполнение. Поток начнет работать с того места, где его остановили.
Blocked — поток ожидает высвобождения ресурсов или завершение операции ввода-вывода. Находясь в этом состоянии поток не потребляет процессорное время.
Terminated — поток немедленно завершает свое выполнение. Его работу нельзя возобновить. Причинами завершения потока могут быть ситуации, когда код потока полностью выполнен или во время выполнения потока произошла ошибка (например, ошибка сегментации или необработанного исключения).
Dead — после того, как поток завершил свое выполнение, его состояние меняется на dead, то есть он завершает свой жизненный цикл.
Даже многопоточная обработка имеет недостатки
Помимо повышения производительности, одним из преимуществ многопоточной обработки является то, что если один поток имеет много ошибок кеша, другие потоки могут продолжать использовать неиспользуемые ресурсы ЦП, что может привести к более быстрому общему выполнению. поскольку эти ресурсы бездействовали бы, если бы работал только один поток. Кроме того, если один поток не может использовать все ресурсы ЦП (например, потому что операторы зависят от результата предыдущего), запуск другого потока может предотвратить бездействие этих ресурсов.

Однако у всего есть и отрицательная сторона. Несколько потоков могут мешать друг другу, разделяя аппаратные ресурсы, такие как кэш или буферы поиска перевода. В результате время однопоточного выполнения не улучшается и может ухудшаться, даже когда выполняется только один поток, из-за более низких частот или дополнительных этапов конвейера, которые требуются для размещения оборудования переключения процессов.
Общая эффективность варьируется; Intel заявляет, что ее технология HyperThreading улучшает ее на 30%, тогда как синтетическая программа, которая выполняет только один цикл неоптимизированных зависимых операций с плавающей запятой, фактически получает 100% улучшение при параллельном запуске. С другой стороны, настроенные вручную программы на языке ассемблера, использующие расширения MMX или AltiVec и предварительный поиск данных (например, видеокодер), не страдают от утечек кеша или бездействующих ресурсов, поэтому они вообще не получают выгоды от запуска. . многопоточными, и их производительность может снизиться из-за конкуренции за общий доступ.
С точки зрения программного обеспечения поддержка многопоточного оборудования полностью видна, что требует дальнейших изменений как в прикладных программах, так и в самой операционной системе. Аппаратные методы, используемые для поддержки многопоточной обработки, часто параллельны программным методам, используемым для многозадачности; Планирование потоковой передачи также является серьезной проблемой в многопоточности.
Множественные «крупнозернистые» нити

Простейший тип многопоточности возникает, когда поток выполняется до тех пор, пока он не будет заблокирован событием, которое обычно создает блокировку с большой задержкой. Такой сбой может быть вызван нехваткой кеша, который должен обращаться к памяти вне кристалла, что может занять сотни циклов процессора для возврата данных. Вместо того, чтобы ждать разрешения сбоя, процессор переключит выполнение на другой поток, который уже был готов к запуску, и только когда данные из предыдущего потока будут получены, они будут возвращены в список готовых к запуску потоков.
Концептуально это похоже на совместную многозадачность, используемую в операционных системах реального времени, в которой задачи добровольно отказываются от времени выполнения процессора, когда им нужно дождаться какого-либо события. Этот тип многопоточности известен как «блочная» или «крупнозернистая».
Завершение процесса и потоки-демоны
В Java процесс завершается тогда, когда завершаются все его основные и дочерние потоки.
Потоки-демоны — это низкоприоритетные потоки, работающие в фоновом режиме для выполнения таких задач, как сбор «мусора»: они освобождают память неиспользованных объектов и очищают кэш. Большинство потоков JVM (Java Virtual Machine) являются потоками-демонами.
Свойства потоков-демонов:
Не влияют на закрытие JVM, когда все пользовательские потоки завершили свое исполнение;
JVM сама закрывается, когда все пользовательские потоки перестают выполняться;
Если JVM обнаружит работающий поток-демон, она завершит его, после чего закроется. JVM не учитывает, работает поток или нет.
Чтобы установить, является ли поток демоном, используется метод boolean isDaemon(). Если да, то он возвращает значение true, если нет, то — то значение false.
Завершение потоков
Завершение потока Java требует подготовки кода реализации потока. Класс Java Thread содержит метод stop(), но он помечен как deprecated. Оригинальный метод stop() не дает никаких гарантий относительно состояния, в котором поток остановили. То есть, все объекты Java, к которым у потока был доступ во время выполнения, останутся в неизвестном состоянии. Если другие потоки в приложении имели доступ к тем же объектам, то они могут неожиданно «сломаться».
Вместо вызова метода stop() нужно реализовать код потока, чтобы его остановить. Приведем пример класса с реализацией Runnable, который содержит дополнительный метод doStop(), посылающий Runnable сигнал остановиться. Runnable проверит его и остановит, когда будет готов.
Обратите внимание на методы doStop() и keepRunning(). Вызов doStop() происходит не из потока, выполняющего метод run() в MyRunnable.
Метод keepRunning() вызывается внутренней потоком, выполняющим метод run() MyRunnable. Поскольку метод doStop() не вызван, метод keepRunning() возвратит значение true, то есть поток, выполняющий метод run(), продолжит работать.
В примере сначала создается MyRunnable, а затем передается потоку и запускает его. Поток, выполняющий метод main() (главный поток), засыпает на 10 секунд и потом вызывает метод doStop() экземпляра класса MyRunnable. Впоследствии поток, выполняющий метод MyRunnable, остановится, потому что после того, как вызван doStop(), keepRunning() возвратит false.
Обратите внимание, если для реализация Runnable нужен не только метод run() (а например, еще метод stop() или pause()), реализацию Runnable больше нельзя будет создать с помощью лямбда-выражений. Понадобится кастомный класс или интерфейс, расширяющий Runnable, который содержит дополнительные методы и реализуется анонимным классом.
Метод Thread.sleep()
Поток может остановиться сам, вызвав статический метод Thread.sleep(). Thread.sleep() принимает в качестве параметра количество миллисекунд. Метод sleep() попытается заснуть на это количество времени перед возобновлениям выполнения. Thread sleep() не гарантирует абсолютной точности.
Приведем пример остановки потока Java на 10 секунд (10 тысяч миллисекунд) с помощью вызова метода Thread sleep():
Поток, выполняющий код, уснет примерно на 10 секунд.
Метод join()
Метод join() экземпляра класса Thread используется для объединения начала выполнения одного потока с завершением выполнения другого потока. Это необходимо, чтобы один поток не начал выполняться до того, как завершится другой поток. Если метод join() вызывается на Thread, то выполняющийся в этот момент поток блокируется до момента, пока Thread не закончит выполнение.
Метод join() ждет не более указанного количества миллисекунд, пока поток умрет. Тайм-аут 0 (ноль) означает «ждать вечно».
Синтаксис:
Например:
Результат:
Из примера видно, что как только поток t1 завершает выполнение задачи, потоки t2 и t3 начинают выполнять свои задачи.
каковы некоторые конкретные примеры приложений, которые должны быть многопоточными или не должны быть, но намного лучше?
ответы были бы лучше, если в виде одного приложения на пост таким образом, наиболее применимые будут плавать к вершине.
нет жесткого и быстрого ответа, но большую часть времени вы не увидите никаких преимуществ для систем, где процесс расчета состоит в последовательном. Если, однако, проблема может быть разбита на задачи, которые могут выполняться параллельно (или сама проблема массово параллельна [как некоторые математические или аналитические задачи]), вы можете увидеть большие улучшения.
Если ваше целевое оборудование-один процессор / ядро, вы вряд ли увидите какие-либо улучшения с многопоточным решения (так как в любом случае есть только один поток за раз!)
писать многопоточный код часто сложнее, так как вам может потребоваться инвестировать время в создание логики управления потоками.
сервера обычно многопоточны (веб-серверы, серверы radius, серверы электронной почты, любой сервер): вы обычно хотите иметь возможность обрабатывать несколько запросов одновременно. Если вы не хотите ждать окончания запроса, прежде чем начать обрабатывать новый запрос, то у вас в основном есть два варианта:
- запустить процесс с несколькими потоками
- запустить несколько процессов
запуск процесса обычно более ресурсоемкий чем lauching поток (или выбор одного в пуле потоков), поэтому серверы обычно многопоточны. Кроме того, потоки могут взаимодействовать напрямую, поскольку они имеют одинаковое пространство памяти.
проблема с несколькими потоками заключается в том, что их обычно сложнее правильно кодировать, чем несколько процессов.
есть действительно три класса причин, по которым будет применяться многопоточность:
- параллелизм выполнения для повышения производительности вычислений: если у вас есть проблема, которая может быть разбита на части, и у вас также есть более одного блока выполнения (ядро процессора), то отправка частей в отдельные потоки-это путь к возможности одновременного использования двух или более ядер одновременно.
- параллелизм CPU и IO Операции: это похоже на мышление первого, но в этом случае цель состоит в том, чтобы держать процессор занят, а также операции ввода-вывода (т. е. дисковый ввод-вывод), движущиеся параллельно, а не чередующиеся между ними.
- дизайн программы и отзывчивость: многие типы программ могут воспользоваться преимуществами потоковой обработки в качестве преимущества дизайна программы, чтобы сделать программу более отзывчивой к пользователю. Например, программа может взаимодействовать через GUI, а также делать что-то в фон.
- Microsoft Word: редактирование документа в то время как фон грамматики и проверки орфографии работает, чтобы добавить все зеленые и красные подчеркивания закорючки.
- Microsoft Excel: автоматические перерасчеты фона после редактирования ячейки
- Браузер: отправка нескольких потоков для загрузки каждой из нескольких ссылок HTML параллельно во время загрузки одной страницы. Ускоряет загрузку страниц и максимизирует пропускную способность данных TCP/IP.
в эти дни, ответ должен быть любое приложение, которое может быть.
скорость выполнения для одного потока в значительной степени достигла пика много лет назад - процессоры становятся быстрее, добавляя ядра, а не увеличивая тактовую частоту. Были некоторые архитектурные улучшения, которые лучше используют доступные тактовые циклы, но на самом деле будущее использует преимущества резьбы.
существует тонна исследований, направленных на поиск путей распараллеливание действий, которые мы традиционно не думали бы распараллеливать. Даже такая простая вещь, как поиск подстроки внутри строки, может быть распараллелена.
в основном есть две причины для многопоточности:
чтобы иметь возможность выполнять задачи обработки параллельно. Это применимо только в том случае, если у вас несколько ядер/процессоров, иначе на одном компьютере с ядром/процессором вы замедлите задачу по сравнению с версией без потоков.
I/O будь то сетевой ввод-вывод или файловый ввод-вывод.обычно, если вы вызываете блокировку вызова ввода-вывода, процесс должен ждать завершения вызова. Поскольку процессор / память на несколько порядков быстрее, чем дисковод (а сеть еще медленнее), это означает, что процессор будет ждать долгое время. Компьютер будет работать над другими вещами, но ваше приложение не будет делать никакого прогресса. Однако, если у вас несколько потоков, компьютер будет планировать ваше приложение, а другие потоки могут выполняться. Одним из распространенных применений является приложение GUI. Затем, пока приложение выполняет ввод-вывод, поток GUI может продолжать обновлять экран, не глядя, как приложение заморожено или не отвечает. Даже на одном процессоре ввод/вывод в другой поток будет способствовать ускорению работы приложения.
однопоточная Альтернатива 2 - использовать асинхронные вызовы, когда они возвращаются немедленно, и вы продолжаете контролировать свою программу. Затем вы должны увидеть, когда ввод-вывод завершается и управлять его использованием. Часто проще просто использовать поток для ввода-вывода, используя синхронные вызовы, как они имеют тенденцию быть легче.
причина использования потоков вместо отдельных процессов заключается в том, что потоки должны иметь возможность обмениваться данными проще, чем несколько процессов. И иногда переключение между потоками дешевле, чем переключение между процессами.
многие рамки GUI многопоточны. Это позволяет вам иметь более отзывчивый интерфейс. Например, вы можете нажать на кнопку "Отмена" в любое время, пока выполняется длинный расчет.
обратите внимание, что есть и другие решения для этого (например, программа может приостанавливать расчет каждые полсекунды, чтобы проверить, нажали ли вы на кнопку отмены или нет), но они не предлагают тот же уровень отзывчивости (GUI может показаться, замерзнуть на несколько секунд во время чтения файла или выполнения вычисления).
все ответы до сих пор сосредоточены на том, что многопоточность или многопоточность необходимы для оптимального использования современного оборудования.
существует, однако, и тот факт, что многопоточность может сделать жизнь намного проще для программиста. На работе я программирую программное обеспечение для управления производственным и испытательным оборудованием, где одна машина часто состоит из нескольких параллельно работающих позиций. Использование нескольких потоков для такого программного обеспечения является естественным, поскольку параллельные нити довольно хорошо моделируют физическую реальность. Потокам в основном не нужно обмениваться данными, поэтому необходимость синхронизации потоков встречается редко, и поэтому многие из причин сложности многопоточности не применяются.
Edit:
на самом деле речь идет не об улучшении производительности, поскольку (возможно, 5, Возможно, 10) потоки в основном спят. Однако это огромное улучшение для структуры программы, когда различные параллельные процессы могут быть закодированы как последовательности действий, которые не знают друг друга. У меня очень плохие воспоминания со времен 16-битных окон, когда я создавал государственную машину для каждой позиции машины, убеждался, что ничего не займет больше нескольких миллисекунд, и постоянно передавал управление следующей государственной машине. Когда были аппаратные события, которые нужно было обслуживать вовремя, а также вычисления, которые заняли некоторое время (например, FFT), тогда все будет очень быстро.
не отвечая непосредственно на ваш вопрос, я считаю, что в ближайшем будущем почти каждое приложение должно быть многопоточным. Производительность процессора не растет так быстро в эти дни, что компенсируется увеличение количества ядер. Таким образом, если мы хотим, чтобы наши приложения оставались на вершине производительности, нам нужно найти способы использовать все процессоры вашего компьютера и держать их занятыми, что довольно сложная работа.
пожалуйста, примите это как дополнительную информацию для размышления, а не как попытку ответить на ваш вопрос.
вид приложений, которые нужно быть продетым нитку одни где вы хотите делать больше чем одну вещь сразу. Кроме этого, ни одно приложение не должно быть многопоточным.
применения с большой рабочей нагрузкой которую можно легко сделать параллельной. Трудность принятия Вашего заявления и делать это не следует недооценивать. Легко, когда ваши данные, которыми вы манипулируете, не зависят от других данных, но v. трудно запланировать работу перекрестного потока, когда есть зависимость.
некоторые примеры, которые я сделал, которые являются хорошими кандидатами многопоточный..
- запущенные сценарии (например, цены на производные акции, статистика)
- массовое обновление файлов данных (например, добавление значения / записи в 10 000 записей)
- другие математические процессы
например, вы хотите, чтобы ваши программы были многопоточными, когда вы хотите использовать несколько ядер и/или процессоров, даже если программы не обязательно сделайте много вещей в то же время.
EDIT: использование нескольких процессов-одно и то же. Какой метод использовать, зависит от платформы и того, как вы собираетесь делать коммуникации в рамках своей программы и т. д.
хотя фривольные, игры, в общем, становятся все более и более резьбовыми с каждым годом. На работе наша игра использует около 10 потоков, занимающихся физикой, AI, анимацией, Редингом, сетью и IO.
просто хочу добавить, что необходимо соблюдать осторожность с протекторами, если ваш общий доступ к каким-либо ресурсам может привести к очень странному поведению, и ваш код работает неправильно или даже потоки, блокирующие друг друга.
мьютекс поможет вам там, поскольку вы можете использовать блокировки мьютекса для защищенных областей кода, примером защищенных областей кода будет чтение или запись в общую память между потоками.
только мои 2 цента стоит.
основная цель многопоточность для разделения временных доменов. Таким образом, использование везде, где вы хотите, чтобы несколько вещей произошли в их собственных отчетливо отдельных временных областях.
Как я прочитал, что для многопроцессорного приложения один процессор может обрабатывать только одну задачу за раз, переключая контексты между двумя процессами. В многопоточном приложении один процессор может обрабатывать несколько потоков. Я этого не понимаю. Обрабатывает ли процессор один поток за раз, если есть только один процессор? Если да, то в чем преимущество многопоточного приложения против многопроцессорного приложения, если CPU может обрабатывать одну вещь за раз.
TL; DR
Multithreading на одиночном ядре может быстро пройти вверх по применению путем использование параллелизма потока и уровня инструкции.
если один процессор имеет несколько ядер, она будет запускать процесс на каждом из ядер. Если это не так, ему нужно будет переключаться между процессами на одном ядре.
Multithreading и multiprocessing можно совместить для более лучших результатов.
Полное Описание
где многопроцессорные системы включают в себя несколько полных блоков обработки, многопоточность направлена на увеличение использования одного ядра с помощью уровня потока, а также параллелизма на уровне инструкций. Поскольку эти два метода являются взаимодополняющими, они иногда объединяются в системах с несколькими многопоточными процессорами и в процессорах с несколькими многопоточными ядрами. Многопоточность | Википедия
пример
один процессор обрабатывает многопоточность таким образом.
предположим, что у нас есть два процесса A и B которые необходимо выполнить набор команд. После каждой команды потокам нужен результат. Вот темы и команды, которые им нужно выполнить.
теперь давайте посмотрим, как CPU будет выполнять эти (теоретически)
CPU начинается с thread A
вот как это будет выглядеть без multi нарезка резьбы.
таким образом, с многопоточностью потоки будут завершены после 17 временные шаги, без него бы 24 .
ваш основной вопрос таков:"[W] вот преимущество многопоточного приложения против многопроцессорного приложения, если CPU может обрабатывать одну вещь за раз?"
простой ответ таков : потоки автоматически разделяют все дескрипторы памяти и файлов. Если вы используете многопроцессное приложение, вам нужно вручную организовать общий доступ к памяти или передать файловые дескрипторы, где это необходимо. Относительные преимущества и недостатки многопоточности по сравнению с мульти-процесс распараллеливания почти так же, независимо от количества ядер присутствует.
преимущество мультипроцесса заключается в том, что эта же разница аргументируется наоборот. Поскольку процессы не обмениваются памятью и файловыми дескрипторами автоматически, проще держать вещи изолированными, когда вы не хотите их совместного использования.
с практической точки зрения ответ обычно заключается в том, что программное обеспечение, необходимое для эффективного создания многопроцессорных приложений, просто не существует. В то время как программное обеспечение, необходимое для создания многопоточных приложений делает. Нет хороших библиотек, которые позволяют вам иметь пул процессов и отправлять задачи в первый доступный процесс. Нет хорошего способа иметь коллекции в памяти различных типов, которые совместно используются между процессами. В отличие от этого, эти инструменты широко доступны для потоков.
да один процессор может обрабатывать многие процессы или потоки. Он может сделать это, остановив один поток, приостановив его и запустив другой. Есть несколько причин, по которым вы, возможно, захотите это сделать. Прежде всего, многие процессы будут тратить некоторое время на ожидание внешних событий (таких как диск или база данных), пока он ждет, тогда процессор может работать над чем-то другим.
также в те дни, когда компьютеры были намного дороже, это позволило многим людям разделить использование одного компьютера. Когда Я начал свою степень CS, у отдела был один сервер HP Unix, который все использовали. Таким образом, я мог редактировать и компилировать код, в то время как другой пользователь проверял свою электронную почту и 20 других людей работали над тем или иным.

Какая тема вызывает больше всего вопросов и затруднений у начинающих? Когда я спросила об этом преподавателя и Java-программиста Александра Пряхина, он сразу ответил: «Многопоточность». Спасибо ему за идею и помощь в подготовке этой статьи!
Мы заглянем во внутренний мир приложения и его процессов, разберёмся, в чём суть многопоточности, когда она полезна и как её реализовать — на примере Java. Если учите другой язык ООП, не огорчайтесь: базовые принципы одни и те же.
Пример многопоточности в Java: пинг-понг мьютексами
Если вы думаете, что сейчас будет что-то страшное — выдохните. Работу с объектами синхронизации мы рассмотрим почти в игровой форме: два потока будут перебрасываться mutex'ом. Но по сути вы увидите реальное приложение, где в один момент времени только один поток может обрабатывать общедоступные данные.
Сначала создадим класс, наследующий свойства уже известного нам Thread, и напишем метод «удара по мячу» (kickBall):
Теперь позаботимся о мячике. Будет он у нас не простой, а памятливый: чтоб мог рассказать, кто по нему ударил, с какой стороны и сколько раз. Для этого используем mutex: он будет собирать информацию о работе каждого из потоков — это позволит изолированным потокам общаться друг с другом. После 15-го удара выведем мяч из игры, чтоб его сильно не травмировать.
А теперь на сцену выходят два потока-игрока. Назовём их, не мудрствуя лукаво, Пинг и Понг:
«Полный стадион народа — время начинать матч». Объявим об открытии встречи официально — в главном классе приложения:
Как видите, ничего зубодробительного здесь нет. Это пока только введение в многопоточность, но вы уже представляете, как это работает, и можете экспериментировать — ограничивать длительность игры не числом ударов, а по времени, например. Мы ещё вернёмся к теме многопоточности — рассмотрим пакет java.util.concurrent, библиотеку Akka и механизм volatile. А еще поговорим о реализации многопоточности на Python.
Читайте также: