
Как рассчитать тактовую частоту процессора
правильно ли говорить, например, что процессор с четырьмя ядрами, каждый из которых работает на 3 ГГц, на самом деле является процессором, работающим на 12 ГГц?
Я однажды попал в аргумент" Mac против ПК " (который, кстати, не находится в центре внимания этой темы. это было еще в средней школе) со знакомым, который настаивал на том, что маки рекламировались только как машины 1 ГГц, потому что они были двухпроцессорными G4, каждый из которых работал на 500 МГц.
в то время я знал, что это фигня по причинам, которые я think очевидны для большинства людей, но я только что видел комментарий на этом сайте к эффекту "6 ядер x 0,2 ГГц = 1,2 ГГц", и это заставило меня снова задуматься о том, есть ли реальный ответ на это.
Итак, это более или менее философский / глубокий технический вопрос о семантике вычисления тактовой частоты. Я вижу две возможности:
- каждое ядро на самом деле делает x вычислений в секунду, таким образом, общее количество вычислений x (ядра).
- тактовая частота, а количество циклов процессора проходит в течение секунды, так как все ядра работают с одинаковой скоростью, скорость каждого тактового цикла остается неизменным независимо от того, сколько ядер существует. Другими словами, Hz = (core1Hz+core2Hz+. )/начинка.
основная причина, почему четырехъядерный процессор 3 ГГц никогда не так быстро, как 12 ГГц одноядерный делать с тем, как работает задача на этом процессоре, т. е. однопоточный или многопоточный. закон Амдала важно при рассмотрении типов выполняемых задач.
если у вас есть задача, которая по своей сути линейна и должна быть выполнена точно шаг за шагом, например (очень простая программа)
тогда задача сильно зависит от результат предыдущего прохода и не может запустить несколько копий себя без повреждения значения 'a' как каждая копия будет получать значение 'a' в разное время и писать обратно по-разному. Это ограничивает задачу одним потоком, и, таким образом, задача может выполняться только на одном ядре в любой момент времени, если бы она выполнялась на нескольких ядрах, то произошло бы повреждение синхронизации. Это ограничивает в 1/2 мощности процессора двухъядерный системе, или 1/4 в четырехъядерная система.
теперь возьмем задачу типа:
все эти линии независимы и могут быть разделены на 4 отдельные программы, как первый и работать в то же время, каждый из которых способен эффективно использовать полную мощность одного из ядер без каких-либо проблем синхронизации, это где закон Амдала заходит в него.
так что если у вас есть однопоточного приложения делают грубую силу расчетам один 12ггц процессор выиграли бы руки, если бы вы могли как-то разделить задачу на отдельные части и многопоточные, тогда 4 ядра могли бы приблизиться, но не совсем достичь той же производительности, что и по закону Амдала.
главное, что дает система с несколькими процессорами, - это отзывчивость. На одном ядре машины, которая работает трудно система может показаться вялым, как большую часть времени может использоваться одной задачей, а другие задачи выполняются только в короткие очереди между более крупной задачи, в результате чего в системе, которая кажется вялой или вялой. На многоядерной системе тяжелая задача получает одно ядро, а все остальные задачи играют на других ядрах, выполняя свою работу быстро и эффективно.
аргумент "6 ядер x 0,2 ГГц = 1,2 ГГц" является мусором в любой ситуации, за исключением случаев, когда задачи совершенно параллельны и независимы. Есть большое количество задач, которые очень параллельны, но они все еще требуют некоторой формы синхронизации. ручной тормоз видео trancoder это очень хорошо при использовании всех доступных процессоров, но для этого требуется основной процесс, чтобы другие потоки заполнялись данными и собирали данные, с которыми они выполняются.
- каждое ядро фактически выполняет x вычислений в секунду, таким образом, общее количество вычислений равно x(ядер).
каждое ядро способно выполнять x вычислений в секунду, предполагая, что рабочая нагрузка подходит параллельно, в линейной программе все, что у вас есть, это 1 сердечник.
- тактовая частота, а количество циклов процессора проходит в течение секунды, так как все ядра работают с одинаковой скоростью, скорость каждого тактового цикла остается неизменным независимо от того, сколько ядер существует. Другими словами, Hz = (core1Hz+core2Hz+. )/начинка.
Я думаю, что ошибочно думать, что 4 x 3GHz = 12GHz, предоставленный математике, но вы сравниваете яблоки с апельсинами и суммы просто не правы, ГГц не могут быть просто сложены вместе для каждой ситуации. Я бы изменил его на 4 x 3GHz = 4 x 3GHz.

Многие, наверное, помнят, какими темпами увеличивалась тактовая частота микропроцессора в 90-х и начале 2000-х годов. Десятки мегагерц стремительно переросли в сотни, сотни мегагерц почти мгновенно сменились цельным гигагерцем, затем гигагерцем с долями, двумя гигагерцами и т.д.
Но последние несколько лет частота уже не растет так быстро. От десятка гигагерц мы сейчас почти так же далеки, как и 5 лет назад. Так куда же исчез прежний темп? Что препятствует, как и раньше, «задирать» частоту вверх?
Текст ниже ориентирован на людей, не знакомых или слабо знакомых с архитектурой микропроцессора. Для подкованных читателей рекомендуются соответствующие посты yurav
«Горячие» гигагерцы
Бытует мнение, что дальнейший рост тактовой частоты непременно связан с увеличением тепловыделения. То есть, вроде как, ничего не мешает просто повернуть в нужную сторону некоторый «рубильник», отвечающий за увеличение частоты, – и частота пойдет вверх. Но процессор при этом нагреется настолько, что расплавится.
Это мнение поддерживается множеством людей, имеющих какое-то отношение к компьютерной технике. К тому же подтверждается успехами оверклокеров, разгоняющих процессоры в два и более раз. Главное – поставить систему охлаждения помощнее.
Хотя упомянутый «рубильник» и связанная с ним проблема тепловыделения действительно существуют, — это только часть битвы за гигагерцы…
Главный тормоз
У различных микропроцессорных архитектур могут быть различные сложности с «разгоном». Для определенности, мы здесь будем говорить о суперскалярных архитектурах. К таковым относится, например, архитектура x86 – самая популярная среди разработок компании Интел.
Чтобы понять проблемы, связанные с подъемом тактовой частоты, необходимо сначала определить, во что упирается ее рост. На разных уровнях рассмотрения архитектуры можно выделить различные наборы параметров, ограничивающих частоту. Однако оказывается, что существует такой уровень, на котором есть только один такой параметр. То есть можно выделить всего один тормоз, который надо дополнительно приотпускать каждый раз, когда охота разогнаться.
Конвейер
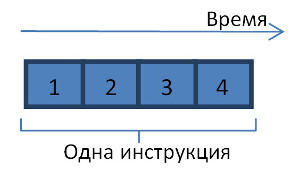
Главный тормоз лежит на уровне конвейера. Конвейер – это сердце суперскалярной архитектуры. Его суть состоит в том, что исполнение каждой инструкции микропроцессора разбивается на стадии (см. рисунок).
Стадии следуют друг за другом во времени, причем каждая из них исполняется на отдельном вычислительном устройстве.
Как только исполнение некоторой стадии завершается, освободившееся вычислительное устройство может быть задействовано для исполнения аналогичной стадии, но уже другой инструкции.
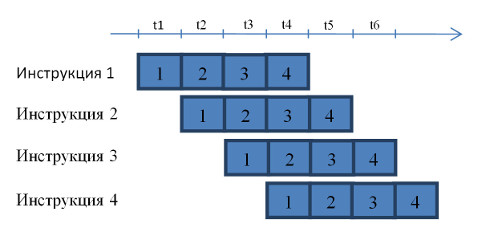
На рисунке показано, как в период времени t1 на первом вычислительном устройстве исполняется первая стадия первой инструкции. К началу периода t2 первая стадия уже выполнена, и поэтому можно переходить к исполнению второй стадии на втором устройстве. Первое устройство при этом освобождается, и его можно отдать под первую стадию уже другой инструкции. И так далее. В период времени t4 на конвейере одновременно будут исполняться различные стадии четырех инструкций.
Но какое отношение все это имеет к частоте? Оказывается, что самое непосредственное. В действительности различные стадии могут отличаться по длительности исполнения. При этом разные стадии одной и той же инструкции исполняются в отдельных тактах. Продолжительность такта (а с ней и частота) микропроцессора должна быть такой, чтобы в него уместилась самая длинная стадия. На рисунке, приведенном ниже, самой длинной изображена стадия 3.
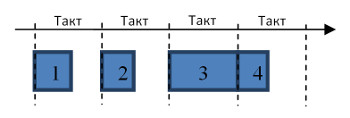
Делать такт короче самой долгой стадии не имеет смысла. Технически это возможно, однако не приведет к реальному ускорению работы микропроцессора.
Предположим, что самая длинная стадия требует для исполнения 500пс (пикосекунд) времени. Это длительность такта в машине с частотой 2ГГц. Допустим теперь, что мы хотим сделать такт в два раза короче – 250пс. Просто так… Ничего, кроме частоты, менять не собираемся. Такой ход приведет только к тому, что проблемная стадия будет исполняться два такта, но по времени это будут все те же 500пс. К тому же значительно возрастут сложности проектирования и увеличится тепловыделение процессора.
Можно было бы возразить, что благодаря более короткому такту, быстрее начнут «пролетать» короткие стадии, и значит, возрастет средняя скорость вычислений. Однако это не так (см. рисунок).

Поначалу вычисления действительно пойдут быстрее. Но уже с четвертого такта третья стадия и любые следующие за ней (в нашем примере – только четвертая) начнут задерживаться. Это произойдет из-за того, что третье вычислительное устройство будет освобождаться не каждый такт, а каждые два такта. Пока оно занято третьей стадией одной инструкции, аналогичная стадия другой инструкции не может быть исполнена. Таким образом, наш гипотетичский процессор с длиной такта в 250пс эффективно будет работать как процессор с тактом в 500пс, хотя формально его частота будет в два раза выше.
Чем мельче, тем лучше
Итак, с точки зрения конвейера, тактовая частота может быть повышена только одним способом – за счет уменьшения длительности самой долгой стадии. Если удается сократить самую долгую стадию, появляется возможность уменьшить такт до размера той стадии, которая станет самой длинной после проведенного сокращения. А чем короче такт, тем выше частота.
В рамках современных технологий, существует не так много способов, которыми можно воздействовать на размер стадии.
Один из таких способов – переход к более совершенному технологическому процессу. Грубо говоря, очередное уменьшение количества нанометров. Чем мельче составные части процессора, тем быстрее он работает. Происходит это за счет того, что сокращаются расстояния, которые необходимо преодолевать электрическим импульсам, сокращается время переключения транзисторов и пр. Упрощенно можно считать, что всё равномерно ускоряется. Примерно равномерно сокращаются длительности всех стадий, в том числе и самой долгой. Частоту после этого можно поднять.
Звучит довольно просто, однако продвижение вниз по шкале нанометров – процесс очень непростой. Он очень сильно зависит от современного уровня технологий, и дальше, чем позволяет этот уровень, шагнуть нельзя. Тем не менее, производители микропроцессоров постоянно совершенствуют технологический процесс, и частота за счет этого постепенно ползет вверх.
Порезать пациента
Другой способ поднять частоту – это «порезать» самую проблемную стадию на более мелкие. Ведь когда-то инструкции уже удавалось мельчить на стадии. И удавалось многократно. Почему бы не продолжить нарезку? Процессор после этого будет работать только быстрее!
Будет. Однако резать очень сложно.
Приведем аналогию со строительством домов. Дома строятся этаж за этажом. Пусть этаж будет аналогией инструкции. Мы хотим разбить строительство этажа на стадии. Для начала, пусть это будут две стадии: собственно строительство и отделка. Пока происходит отделка на последнем построенном этаже, ничто не мешает приступить к строительству нового этажа. Главное, чтобы строительством и отделкой занимались две разные бригады. Вроде, все хорошо.
Теперь мы хотим пойти дальше и помельчить уже имеющиеся две стадии. Отделку, допустим, можно разбить на поклейку обоев и покраску потолков. С таким разделением нет никаких проблем. После того, как маляры покрасили один этаж, они могут идти на следующий, даже если на предыдущем все еще идет поклейка обоев.
Та же самая проблема имеется и в микропроцессорах. Существуют стадии, которые цепляют инструкции друг за друга. Дробить такие стадии на более мелкие очень тяжело. Для этого нужны очень серьезные изменения в архитектуре процессора. Точно так же, как серьезные изменения нужны в строительстве для того, чтобы одновременно строить несколько этажей одного дома.
Повернуть рубильник
Вот мы и добрались до того, чем занимаются оверклокеры. Они поднимают напряжение, под которым работает процессор. За счет этого быстрее начинают переключаться транзисторы (основные элементы, из которых состоит процессор), и длины всех стадий более-менее равномерно сокращаются. Появляется возможность поднять частоту.
Очень просто! Но есть большие проблемы с тепловыделением. Упрощенно, выделяемая процессором мощность описывается следующим образом:
P ~ Cdyn*V 2 *f
Здесь Cdyn – динамическая емкость, V – напряжение, f – частота процессора.
Неважно, если вы не знаете, что такое динамическая емкость. Главное здесь – напряжение. Оно в квадрате! Выглядит ужасно…
На самом деле, все еще хуже. Как я уже сказал, напряжение нужно, чтобы заставить быстрее работать транзисторы. Транзистор – это своеобразный переключатель. Для того, чтобы переключиться, ему необходимо накопить достаточный заряд. Время такого накопления пропорционально току: чем он больше, тем быстрее на транзистор приходит заряд. Ток, в свою очередь, пропорционален напряжению. Таким образом, скорость срабатывания транзистора пропорциональна напряжению. Теперь обратим внимание на то, что частоту процессора мы можем увеличить лишь пропорционально увеличению скорости срабатывания транзисторов. Суммируя сказанное, имеем:
f ~ V и P ~ Cdyn*V 3
С линейным ростом частоты тепловыделение будет увеличиваться по кубическому закону! При увеличении частоты в 2 раза, необходимо будет отвести от процессора в 8 раз больше тепла. Иначе он расплавится.
Очевидно, такой способ увеличения частоты не очень подходит для производителей процессоров из-за низкой энергоэффективности, хотя и используется разгонщиками-экстремалами.
И это все?
И это все. Ну или почти все. Кто-то мог бы вспомнить, что ему удавалось слегка увеличить тактовую частоту микропроцессора даже без поднятия напряжения.
Такое тоже возможно, однако в очень ограниченных пределах. Процессоры рассчитаны производителем на то, чтобы эксплуатироваться в широком диапазоне внешних условий (которые влияют на длину стадии), поэтому производятся с некоторым запасом по частоте. Например, самая длинная стадия может занимать не целый такт работы процессора, а скажем, 95% такта. Отсюда и возможность незначительно повысить частоту.
Кстати, я ни в коем случае не призываю никого заниматься самостоятельным разгоном процессоров. Все, кто им занимается, делают это на свой страх и риск. Неправильно проводимый разгон опасен не только для ваших процессоров, но и для вас лично!
Отмечу также, что помимо описанных, существуют и другие способы воздействовать на длину стадии. Но они гораздо менее существенны, чем представленные здесь. Например, изменение температуры влияет на работу электроники в целом. Однако серьезные эффекты достигаются только при очень низких температурах.
В общем и целом, получается, что за повышение частоты бороться очень тяжело… Тем не менее, эта битва постепенно ведется, и частота потихонечку ползет вверх. При этом грустить из-за того, что процесс замедлился, не приходится. Ведь появилась такая штука как многоядерность. И какая, в сущности, нам разница, стал наш компьютер работать быстрее из-за того, что поднялась его частота, или потому, что задачи стали исполняться в параллель? Тем более что во втором случае мы получаем дополнительные возможности и бОльшую гибкость…

Сегодня мы разберемся с двумя важными вопросами: как писать более эффективный код с CMSIS и как правильно рассчитывать скорость работы процессора. Начнем мы со второй части и изучим процессы, которые происходят в LPC1114 для генерации тактовой частоты.
Тактовая частота – основной источник «рабочей силы» в процессоре, ее генератор можно сравнить с сердцем у человека. В разных компонентах процессора может использоваться разная частота, которая, тем не менее, зарождается обычно в одном и том же кристалле (или резонаторе).
Большинство процессоров имеют встроенный резонатор и возможность подключить внешний резонатор или кристалл. Зачем это сделано? В основном, для удешевления процессора. Встроенный резонатор типично имеет погрешность около 1%, чего может хватить для многих задач, но есть еще больше задач, для которых такая точность неприемлема. В самом деле, если мы будем, например, считать время на встроенном резонаторе, то погрешность за сутки может достигнуть 14 минут. Если вы передаете пакет по сети где-то раз в полчаса – это совершенно не критичная погрешность. Другое дело, если вы делаете будильник.

(изображение из LPC111x User Manual)
Выше представлена обзорная схема генератора тактовой частоты, разбитая на компоненты. Сейчас мы займемся каждым из них по отдельности.
⓵ Основная частота
MAINCLKSEL задает основную частоту, от которой зависят почти все остальные. Она может быть основана на одном из нескольких источников.
Во-первых, это IRC – внутренний резонатор. Рабочая частота – 12 МГц (на самом деле, можно тюнинговать в небольших пределах), погрешность — около 1%. Именно отсюда генерируется тактовая частота процессора в момент старта, так что весь загрузочный код выполняется при тактовой частоте в 12 МГц. Вариант максимально простой (вам вообще ничего не надо делать, чтобы он работал), не требует дополнительных внешних компонентов. К сожалению, имеет свои проблемы: резонатор, как я уже упоминал, несколько неточен, кроме того, нам не особенно интересно гонять ядро на 12 МГц, когда оно отлично работает на 50 МГц.
Во-вторых, основную частоту можно задать еще с одного внутреннего генератора – watchdog oscillator, который обычно используется для работы watchdog. Этот осциллятор работает на скоростях (программно настраиваемо) от 9,4 кГц до 2,3 МГц с погрешностью ±40%, — казалось бы, не лучшее решение для основной частоты. С другой стороны – это именно то замечательное и энергоэффективное решение, если вам нужно перевести ядро в спящий режим, при этом оставив какую-то часть периферии рабочей.
В-третьих, мы можем получить основную частоту из системного осциллятора до или после ФАПЧ. Не будем сейчас вникать в специфику работы ФАПЧ, так как это достаточно объемная тема. Интересующимся советую изучить раздел «3.11 System PLL functional description».
⓶ Системный осциллятор
Системный осциллятор – это та часть процессора, которая не будет работать без аппаратных модификаций, в нем отсутствует основная рабочая сила осциллятора – кристалл (или кварцевый резонатор), который необходимо подключить снаружи, для чего на любом современном процессоре есть пины XTALIN/XTALOUT.
Конкретно LPC1114 (впрочем, как и остальные процессоры линейки LPC111x) поддерживает кристаллы с частотой осцилляции от 1 МГц до 25 МГц. Помимо самого кристалла, вам также понадобятся два конденсатора, значения которых зависят от параметров выбранного кристалла. Тут я отсылаю вас к datasheet, где в разделе 12.3 (XTAL input) есть и схема подключения, и таблица с рекомендованными емкостями конденсаторов. В тестовой схеме я пробовал использовать кристалл с частотой 12 МГц, емкостью нагрузки 20 пФ и двумя конденсаторами на 39 пФ, но этот режим работы далее рассматриваться не будет.
Если у вас есть надежный внешний источник тактовой частоты, то можно пропустить системный осциллятор, тогда тактовая частота берется с пина XTALIN.
Системный осциллятор можно использовать непосредственно как генератор основной частоты, или же предварительно пропустить его через ФАПЧ.
Не вдаваясь в электромеханику, ФАПЧ – это устройство, которое сначала умножает, а потом делит входную тактовую частоту. На входе ФАПЧ может принять частоту от IRC или системного осциллятора, а выход будет использован для основной частоты.
Настройка параметров ФАПЧ потенциально опасна для внутренностей процессора, потому я рекомендую NXP-шную утилиту (успешно конвертируется и работает в Google Drive) для подбора необходимых параметров, просто задайте частоту осциллятора на входе и итоговую частоту, которую хотите получить, и она рассчитает возможные варианты.
В сети есть интересная заметка о том, как поднять частоту IRC для генерации 50 МГц на выходе ФАПЧ, но для отладки этого результата вам понадобится осциллоскоп.
⓸ Системная частота
Обычно ядро (то, что Cortex-M0) работает на основной частоте, но, при необходимости, основную частоту можно разделить (на значение вплоть до 255), получив в итоге системную частоту. Помимо непосредственно ядра, на этой частоте будут работать флеш-память, RAM и вся периферия, за исключением SPI и UART. Имейте в виду, что максимальная частота тут – это 50 МГц.
⓹ А что же со SPI и UART?
Из-за специфики этих интерфейсов у них есть свои выделенные делители частоты, например, у UART он позволяет выбрать необходимый битрейт.
Несмотря на некоторую неочевидность схемы, на вход делителя попадает не основная, а системная частота.
Расчет делителя для битрейта – достаточно сложная задача, потому в очередной раз отправляю вас в инструкцию – «13.5.15 UART Fractional Divider Register (U0FDR — 0x4000 8028)». Там есть и формула расчета, и объяснение дополнительного дробного аргумента, а также блок-схема для поиска нужных параметров для заданного битрейта и пара примеров.
У SPI все как-то существенно проще, скорее всего потому, что мастер на шине задает частоту, и остальные устройства работают на ней – заочной синхронизации не требуется. Так что единственное, что мы можем сделать – это задать делитель. Важный момент – когда процессор работает в мастер-режиме, то минимальный делитель – 2, т.е., при частоте системной частоты в 48 МГц скорость передачи данных на SPI будет 24 МГц.
UPD: как верно заметил valeriyk, этот делитель не единственное, что влияет на выходную частоту. У SPI, например, несущая частота расчитывается по формуле: PCLK / (CPSDVSR * (SCR + 1)) , где PCLK — это частота периферии; CPSDVSR — «предделитель»; SCR — количество тактов предделителя на один бит вывода.
⓺ Watchdog на страже жизнедеятельности
Watchdog по своей специфике — компонент изолированный. Поэтому, в качестве ведущей частоты можно использовать системную, IRC или отдельный осциллятор. Точно так же, у watchdog есть свой выделенный делитель.
Зачем для watchdog нужен отдельный тактовый генератор? Если программа случайно поломает основной генератор, конечно же! Тогда у нее все еще будет шанс быть перезагруженной по таймеру watchdog.
⓻ На выход
Наконец, процессор может генерировать выходной сигнал тактовой частоты на пине CLKOUT (одна из альтернативных функций у GPIO 0.1). В качестве ведущей частоты мы можем использовать любую из доступных нам: из осцилляторов (IRC, системного или watchdog) или системную частоту (после ФАПЧ, если он включен). Ну и, конечно, свой делитель.
Немного о mbed
Мы детально рассмотрели процесс генерации тактовой частоты в LPC1114, но что же с LPC1768? На самом деле, у каждой линейки процессоров может быть (и скорее всего будет свой особый подход, потому инструкцию по этой теме надо изучить предельно внимательно. В LPC1768 также есть внутренний осциллятор – IRC, но работает он на частоте 12 МГц. Помимо него есть основной (main) осциллятор, идентичный системному осциллятору. На mbed к нему подключен кристалл на 12 МГц. Наконец, есть осциллятор часов реального времени (RTC), но кристалл к нему не подключен.
Также, помимо основного ФАПЧ, есть дополнительный, который используется для генерации рабочей частоты USB. Все компоненты периферии имеют независимые настраиваемые делители относительно рабочей частоты.
Практические нюансы изменения частоты
Изменение рабочей тактовой частоты влечет за собой несколько последствий. Самое очевидное — необходимость перенастраивать таймеры. Также, потребуется переинициализация периферии, работающей с протоколами где важно зафиксировать несущую частоту (UART, USB). Наконец, количество тактов для доступа к флеш-памяти тоже играет важную роль. У LPC1114 значение по умолчанию — 3 такта (рабочая частота до 50 МГц, см. документацию по регистру FLASHCFG), чего вполне хватает для наших задач. Но у LPC1768 значение по умолчанию — 4 такта, с рабочей частотой до 80 МГц, чего нам будет недостаточно.
Тем не менее, работать на более высокой частоте, скорее всего, будет выгодно. Встраиваемые процессоры большую часть времени проводят в режиме сна, так что чем быстрее они отработают цикл бодрствования — тем меньше энергии они затратят в итоге.
За работу!
Теперь у нас есть необходимый теоретический багаж, и мы готовы применить полученные знания на практике – заставить светодиод мигать детерминировано, 1 раз в секунду.
Как вы видели раньше, очень много задач выполняются однотипно – записью и чтением регистров (вообще, все задачи выполняются именно так). ARM позаботилась о том, чтобы задачи, не привязанные к конкретному процессору, можно было выполнять одним и тем же кодом на C, для этого и существует CMSIS – набор драйверов для ядра процессора. Вендоры обычно расширяют его драйверами для всей остальной периферии.
Сложный момент с CMSIS состоит в том, что иногда не совсем понятно, где найти актуальную версию. Базовый набор файлов можно скачать непосредственно у ARM, на момент написания там доступна версия 3.01. Помимо заголовочных файлов, ARM предоставляет библиотеку для разноплановых сложных расчетов на DSP (которого в нашем железе все равно нет). Хуже обстоит дело с драйверами от конкретных производителей. У NXP, например, CMSIS для LPC1114 основан на CMSIS 1.30, а для LPC1768 – на 2.10. Более того, в наборе драйверов периферии есть явные ошибки в коде. А уж драйверы для чипов TI приходится основательно искать в гугле.
Из этого можно сделать два важных вывода: во-первых, код драйверов почти весь открыт, так что «доверяй, но проверяй»: инструкция и даташит — это ваша основная литература по работе с периферией. Во-вторых, в драйверах нет почти ничего, что нельзя было бы написать самому, т.е., это отличный и, зачастую, рабочий справочный материал. Главное – не забывать относиться к нему критически, если что-то выглядит странно – раскуривайте инструкцию по процессору.
Исходный код теперь несколько более структурирован. Хотя в результате он существенно вырос в количестве фалов, теперь намного проще поддерживать несколько разных платформ. Исходники для сегодняшнего примера доступны на GitHub: farcaller/arm-demos (pull-реквесты для новых архитектур приветствуются!).
Дерево исходников еще не до конца причесано, в частности, я не избавился от примитивных boot.s и memmap.ld . Следующая часть будет целиком посвящена вопросам компоновщика (включая сборку мусора и правильную инициализацию .data и .bss), где мы займемся добиванием до конца всех спорных моментов. Весь код разбит на три категории: в app/ находятся файлы «приложения» – непосредственно рабочий код примера. Он оформлен в стиле arduino, через функции setup() и loop() . В platform/ хранятся описания разных платформ и платформозависимые функции (кроме platform/common , файлы которого линкуются во все платформы). Наконец, в cpu/ находятся CMSIS для конкретных процессоров.
Весь этот комбайн собирается маленьким забавным Rakefile. Наверное, можно было бы обойтись и make, но хотелось все аккуратно собрать в одном файле, так что для сборки примеров вам пригодится руби не старше версии 1.9.
Работа по часам
Для реализации нашей задачи (напомню, нам надо мигать светодиодом ровно раз в секунду) нам пригодился бы какой-то таймер. К счастью, таймеров в LPC-шных процессорах сразу несколько, мы будем работать с самым унифицированным – SysTick. Этот таймер описан непосредственно в CMSIS, т.е., есть большая вероятность того, что он будет и в любом другом процессоре. Его предполагается использовать для измерения квантов времени при переключении задач в ОС, но ничего не мешает использовать его для простых задач.
SysTick – это простой таймер, который считает от заданного значения вниз до нуля, где он устанавливает бит переполнения, дергает прерывание и начинает считать сначала.
Для начала о синтаксисе. Эти замечательные структуры доступны нам из CMSIS, больше не надо запоминать, где находятся регистры, да и доступ к полям реализуется существенно нагляднее.
Для инициализации таймера мы записываем 4 в регистр контроля. Это выключает таймер, если он был включен, выключает прерывание и переводит SysTick на использование частоты процессора (напоминаю, что по умолчанию — это 12 МГц). Далее мы загружаем стартовую точку отсчета в регистр SYST_RVR, ограничивая максимум — 16777215, сбрасываем текущее значение регистра в ноль и запускаем таймер.
Теперь о том, как нам подождать одну секунду:
Мы считываем значение COUNTFLAG из регистра SYST_CSR. COUNTFLAG выставляется в единицу, когда счетчик идет на новый круг, и сбрасывается в ноль при чтении. Таким образом, мы будем в цикле, пока счетчик не переполнится.
Заглянем в другие файлы нашего проекта. app/systick-blink.c :
Тут все достаточно наглядно. Инициализируем «драйвер» светодиода и таймера, и в цикле включаем-выключаем светодиод с задержкой. В зависимости от платформы, используем разное стартовое значение таймера (IRC на mbed и protoboard у нас работают на разных частотах). А как же работает код самого светодиода?
Как видите, с CMSIS все стало действительно читабельнее. Единственный интересный момент — это то, что вместо общего регистра GPIO мы сейчас используем регистр с маской. Он позволяет устанавливать биты GPIO для конкретных пинов с маской, т.е., можно просто писать нужное значение, не думая о том, что надо сохранять состояние соседних пинов. Детальнее (и в картинках) об этом можно прочитать в инструкции: «12.4.1 Write/read data operation».
Для сравнения вот код для mbed. platform/mbed/led.c :
Как видите, он весьма схож. У LPC1768 нет возможности задавать маску прямо в адресе указателя, но зато есть побайтовый доступ к регистрам, что генерирует немного более эффективный ассемблерный листинг.
Собрать проект можно командой rake build_protoboard или rake build_mbed . Можно даже сразу прошить устройство: rake upload_protoboard TTY=/dev/ftdi/tty/device или rake upload_mbed MOUNT=/Volumes/MBED соответственно. Сейчас светодиоды мигают идентично на обоих устройствах.
Поиграем частотой?
Вроде бы мы и решили поставленную задачу — светодиод мигает с корректным интервалом, но что-то еще осталось за кадром. Максимальная рабочая частота LPC1114 — 50 МГц, а у LPC1768 и того больше — 100 МГц, получается, мы гоняем их едва ли в треть силы!
Настало время заняться правильной инициализацией платформы. platform/protoboard/init.c :
В исходном коде доступны три шаблона для LPC1114: стандартные 12 МГц от IRC, 48 МГц от IRC, пропущенного через ФАПЧ, и 48 МГц от системного осциллятора, пропущенного через ФАПЧ. Последний вариант требует дополнительной аппаратной поддержки, но мы рассматриваем его, так как это очень актуальный режим использования.
Если мы работаем от системного осциллятора, его необходимо корректно инициализировать, а в первую очередь — включить. Как мы обсуждали ранее, осциллятор можно пропустить, если на входе XTALIN присутствует уже сформированный сигнал тактовой частоты.
После первичной инициализации следует сделать небольшую задержку. Далее мы переводим ФАПЧ на работу от системного осциллятора (вместо IRC), для этого существует интересный механизм: пишем 0, пишем 1, ждем — регистр начнет возвращать 1.
Вторая часть инициализирует ФАПЧ, который на данном этапе получает на входе сигнал или от IRC, или от системного осциллятора. Настраиваем делители по формуле из инструкции, включаем ФАПЧ и ждем, пока он заблокируется. Основная частота после загрузки работает от IRC, переводим ее на работу от выхода ФАПЧ и ждем, пока это изменение «устаканится».
На 48 МГц для SysTick нам понадобится 48000000 циклов, но это больше его максимального значения. Один из вариантов решения — ждать несколько циклов таймера, что реализовано в функции platform_systick_wait_loop (другим вариантом было бы использовать 32-разрядный таймер CT32B0).
У LPC1768 код, опять же, в целом похожий. Тут важный момент в том, что на выходе из PLL должно быть не менее 275 МГц, когда на входе в процессор — не более 100 МГц. В общем, внимательно проверяем делители. Также важно отметить, что мы повышаем количество тактов, необходимых для доступа к флеш-памяти, потому что мы будем работать на частоте выче чем значение по умолчанию.
Код, приведенный в примере, актуален только для LPC1768 на mbed, так как привязан к конкретной частоте кристалла. Более того, если вы работаете с LPC1768 «напрямую», то его загрузчик стартует с IRC с включенным ФАПЧ, так что в своем инициализаторе его перед настройкой необходимо выключить.
Подводя итоги
Еще хотел сегодня рассказать про CLKOUT и о том, как можно контролировать частоту анализатором логики или осциллографом, но так статья получилась бы слишком большой. CLKOUT, 32-разрядные таймеры, прерывания и спящий режим — все это будет в следующих выпусках.
До меня доехала коробка со Stellaris LaunchPad, я подумаю над тем, как лучше всего будет добавить еще одну архитектуру, не раздувая повествование. В любом случае, LPC1114 становится основным целевым процессором, все примеры мы сначала будем обкатывать на нем.
Приношу свои извинения за «многобукаф», далее постараюсь писать более содержательно.
P.S. Как всегда, большое спасибо pfactum за вычитку текста и бесценные комментарии по электромеханике. И за то, что объяснил про ФАПЧ :-).
Любая программа, которую выполняет компьютер, сводится к математическим операциям процессора: сложению, умножению, вычитания (операция деления - сводится к тому же вычитанию) , а кроме того и передачи данных между отдельными элементами архитектуры ЭВМ. Для осуществления обычной математической операции - требуется до девяти элементарных тактов микросхемы процессора. Частота процессора показывает сколько таких элементарных тактов в секунду было реализовано на данном чипсете. Тактовая частота процессора задается в герцах: в современных процессорах эта величина достигает значения нескольких миллиардов в секунду и даже выше.
1 Ггц = 1 миллиард эл. опер. в секунду.
Итак, частота - основная характеристика быстродействия (скорости) процессора: однако, не единственная - важна и архитектура чипсета. Важной величиной, характеризующей производительность компьютера в целом, является еще и размер оперативной памяти.
Чем больше частота тем лучше идёт обработка информации.. .
Т. е это то что обрабатывает информацию на компе
Понизили частоту процессора, значит, уменьшили количество энергии им потребляемое. Поэтому нечего удивляться, что частота вашего процессора окажется меньше, чем заявлено, просто максимальная частота будет выдаваться при питании ноутбука от сети.
Частота процессора - это частота в частотозадающих цепях процессора. Сказать что на этой частоте работает поцессор как бы правильно. Однако реальная частота процессора обычно меньше, однако частоту поцессора стали постоянно использовать как рекламную величину . А в общем быстродействие компа определяется не столько частотой процессора, сколько косвенными величинами. Как то - частота шины, рабочая часточа ОЗУ, скорость обращения к харду и остальной обвязке.
Частота процессора измеряется в мегагерцах. Если часто процессора 3000 мегагерц, это значит, что его частота в гигагерцах всего 3. Пот тому как 1 килогерц =1000 Герц, 1 мегагерц= 1000 килогерц, 1 гигагерц = 1000 мегагерц. Значит если процессор имеет частоту к примеру 2 Гигагерца это значит, что за один рабочий такт в секунду он может отработать 2000000 раз. Но это в общем не говорит о мощности процессора, о мощности свидетельствует его реальноя производительность, частота решающей роли не играет. Частота процессора определяется задающим тактовым генератором либо на мат. плате, либо еще где.
С выходом многоядерных процессоров в сети стали появляться различные способы вычисления суммарной тактовой частоты процессора. Многие наивно полагают, что четырехядерный процессор с частотой ядер 2,6ГГц в итоге работает как одноядерный процессор с частотой 4*2,6=10.4ГГц. А ведь это совсем не так.

Тактовая частота процессора определяет количество операций, которое может выполнить центральный процессор за единицу времени. Вычисляется тактовая частота процессора за счет перемножения базовой частоты (частоты шины) на множитель. На примере процессора Intel i7 5600U с множителем 20 и базовой частотой шины 133МГц получим тактовую частоту процессора 133*20=2,66ГГц. Тактовую частоту процессора можно повысить методом разгона, для этого можно поднять множитель или базовую частоту. В большинстве случаев повышают множитель в тех процессорах, в которых он разблокирован (серия с индексом «U» для процессоров Intel (например, 5557U) и процессоры серии FX unlocked от AMD).
Как же теперь определить общую производительность многоядерного (на примере 4-х ядерного) процессора, например, с тактовой частотой в 3ГГц? В 4-х ядерном процессоре каждое ядро работает с тактовой частотой 3ГГц. То есть каждое ядро может выполнить равное количество вычислений в единицу времени при условии, что все ядра будут загружены процессом вычисления. За загрузку ядер «работой» отвечает приложение, которое запущено на компьютере пользователя (будь то игра, или архиватор).
Нельзя сказать, что 4-х ядерный процессор с частотой 3ГГц будет иметь производительность на уровне одноядерного с частотой 12ГГц. Это совсем не так. Суть производительности многоядерных процессоров сводится к тому, что вычислительный процесс должен быть разбит на параллельные потоки, которые могут быть выполнены в одно и то же время различными ядрами процессора. У Intel параллельные потоки или многопоточность называется Hyper-Threading.
Если представить себе четыре ручья шириной и глубиной в один метр, скорость течения воды, в каждом из которых составляет 3 м/сек. Понятно, что скорость четырех ручьев не будет составлять 12 м/сек, а вот суммарная производительность всех четырех ручьев составит 12 куб. м. за секунду. То же самое можно отметить и в процессорах, при этом скорость потока воды – это тактовая частота, которая не умножается и не суммируется при увеличении количества ядер.
Преимущество многоядерных процессоров перед одноядерными заметно лишь в тех приложениях и играх, которые используют технологию разбивки процесса вычислений на несколько параллельных потоков. В таких приложениях скорость работы приложений значительно выше одноядерных. В то же время при работе старых приложений, использующих всего лишь один поток, производительность вычислений будет отграничена возможностью одного ядра. Читайте о том, как узнать количество ядер и частоту процессора.
Также некорректно сравнивать производительность двухядерного процессора с тактовой частотой 3ГГц и четырехядерного с тактовой частотой 2,1ГГц. Производительность во многом зависит от используемого приложения и способности этого приложения разделить вычисления на несколько потоков. При прочих равных условиях, когда приложение поддерживает многопоточность, производительность 4-х ядерного процессора с меньшей тактовой частотой будет выше производительности 2-х ядерного процессора с большей частотой. Однако, если приложение не способно разделять потоки, то двухядерный процессор будет более эффективным, так как имеет большую частоту.
Таким образом, производительность современных процессоров в большинстве случаев определяется программным обеспечением, которое способно загрузить все ядра процессора. Также следует понимать, что многопоточность все же предпочтительней одноядерных процессоров, так как все больше производителей ПО выпускают программные продукты, ориентированные именно на многоядерные процессоры. В этом направлении двигаются и разработчики компьютерных игр.
Читайте также: