
Как работает декодер в процессоре
Вы когда-нибудь задумывались, в чем причина того, что программа, скомпилированная для работы на процессорах x86 для ПК, не работает на ARM ЦП например? Что делает программу совместимой с конкретным семейством процессоров, а не с другими? Что такое регистры и каковы их функции? В этой статье мы объясняем, что регистры и инструкции в А ЦП чтобы вы могли это понять.
Мы много раз говорили о процессорах, имеющих определенный набор инструкций, или о том, что набор инструкций был добавлен к новому процессору. Посмотрим, что это значит.
Регистры процессора
Регистры - это память, ближайшая к существующему процессору и, следовательно, самая быстрая; Это очень маленькие блоки памяти, которыми можно управлять напрямую с помощью блока управления процессора. Они используются для выполнения всех видов общих задач, а не только для выполнения арифметических операций.
- Регистры типа аккумулятора : используется для арифметических операций. Каждое семейство имеет разное количество записей типа аккумулятора.
- Регистры доступа к памяти : содержат адрес памяти данных, к которым мы хотим получить доступ из ОЗУ.
- Регистры данных в или из памяти : Содержат данные, скопированные из памяти (чтение) или для записи по определенному адресу памяти (запись).
- Регистры общего назначения : это регистры памяти без специальной утилиты, которые служат для хранения данных, которые должны быть вызваны как можно быстрее.
- Счетчик команд : указывает следующую инструкцию для выполнения; Команды перехода изменяют их, когда вы хотите получить доступ не к следующей инструкции, а к другой части программы. В каждом полном командном цикле адрес памяти увеличивается на 1 и связывается с адресной шиной процессора.
Некоторые из регистров ЦП, такие как регистр счетчика программ, который указывает, на какой следующий адрес памяти указывает процессор, находятся во всех ЦП и других типах процессоров с возможностью выполнения программ, в то время как другие записи уникальны для каждого набор записей и инструкций, делающий корреляцию 1: 1 между различными ISA практически невозможной.
Даже если бы у нас был преобразователь кода инструкции 1: 1, у нас все равно были бы проблемы, потому что, хотя два процессора могут иметь одну и ту же инструкцию сложения, мы можем обнаружить, что способ использования регистров и регистров, которые они используют, различны и что есть даже регистры, которые есть в одной семье, а в других нет. Примером этих трудностей столкнулись оба Microsoft и Qualcomm при адаптации Windows 10 в ARM, чтобы все приложения x86 без проблем работали на процессоре ARM.
Однако есть решения, такие как использование программного обеспечения для перевода инструкций. Указанное программное обеспечение переводит двоичный код в промежуточный код, а затем передает его в двоичный код целевого процессора, в котором мы хотим запустить приложение. Очевидно, что этот процесс намного медленнее, и рекомендуется запускать только очень старое программное обеспечение из семейств процессоров, которые не существуют на рынке.

Привет, %username%!
Декодирование IA-32 кода — задача архисложная. Чтобы в этом убедиться, можете обратиться к Intel Software Development Manual или к статьям, ранее написанным на хабре: Префиксы в системе команд IA-32, Правильно ли работает ваш дизассемблер?. Давайте посмотрим, как с этой задачей борется функционально точный полноплатформенный симулятор Wind River Simics, позволяющий создать высокопроизводительное виртуальное окружение, в котором любая электронная система, начиная с одной платы и заканчивая целыми многопроцессорными, многоядерными и даже многомашинными системами, может быть определена, разработана и запущена.
Большинство библиотек для декодирования IA-32 инструкций генерируют или используют таблицы соответствия между кодами операций и инструкциями. Пример использования данного подхода описан в статье Дизассемблер своими руками. Однако декодирование префиксов и аргументов обычно написано руками: libopcodes, metasm, beaengine, distorm. Данный подход обладает существенным недостатком — добавление поддержки новых наборов команд потребует большого количества ручной работы.
Существуют и другие способы создания декодеров, например с помощью языка GDSL. Данный подход является универсальным и позволяет создавать декодеры для любых архитектур.
Simics же использует совершенно другой не менее универсальный подход для работы с IA-32 инструкциями, названный раздельным декодированием. Также Simics имеет возможность использования внешних декодеров, но об этом немного позже.
Ввод и вывод процедуры декодера
В реальном процессоре за задачу декодирования отвечает отдельный блок логических элементов микросхемы. В симуляторе же ему соответствует некоторая процедура, написанная на языке программирования. Рассмотрим, что подаётся на её вход и какие результаты следует от нее ожидать.
Очевидно, что на вход декодера подаётся массив байт известной длины, полученный на фазе выборки команд (англ. fetch). Кроме того, ему должен быть известен текущий режим процессора (см. Префиксы в системе команд IA-32).
В результате работы декодер должен вернуть код ошибки и результаты анализа последовательности в виде списка полей результата. При этом возможны следующие значения для кода ошибки:
- Декодирование успешно (код возврата равен длине инструкции > 0). Массив байт был распознан как допустимая инструкция, и список полей содержит информацию о коде операции и её аргументах.
- Декодирование не успешно (код 0). Ни одна инструкция, определённая в архитектуре, не соответствует входному массиву байт. При этом содержимое полей результата не несёт смысла. Что происходит в этой ситуации дальше на этапе исполнения? Это зависит от архитектуры. Чаще всего невозможность декодировать ведёт к генерации исключения, а в некоторых случаях некорректная инструкция может быть воспринята как NOP — отсутствие операции.
- Для ISA с переменной длиной инструкций возможна третья ситуация — входных данных недостаточно для принятия однозначного решения (код < 0). Другими словами, на вход декодера передали только часть инструкции, и он, не имея информации о том, какие байты идут в памяти дальше, сообщает об этом.

Раздельное декодирование
- Декодирование префиксов. В эту стадию входит как декодирование всех префиксов, так и проверка конфликтов между ними.
- Декодирование кодов операции и операндов. Данная стадия подразумевает вызов декодера, генерированного с помощью SimGen.
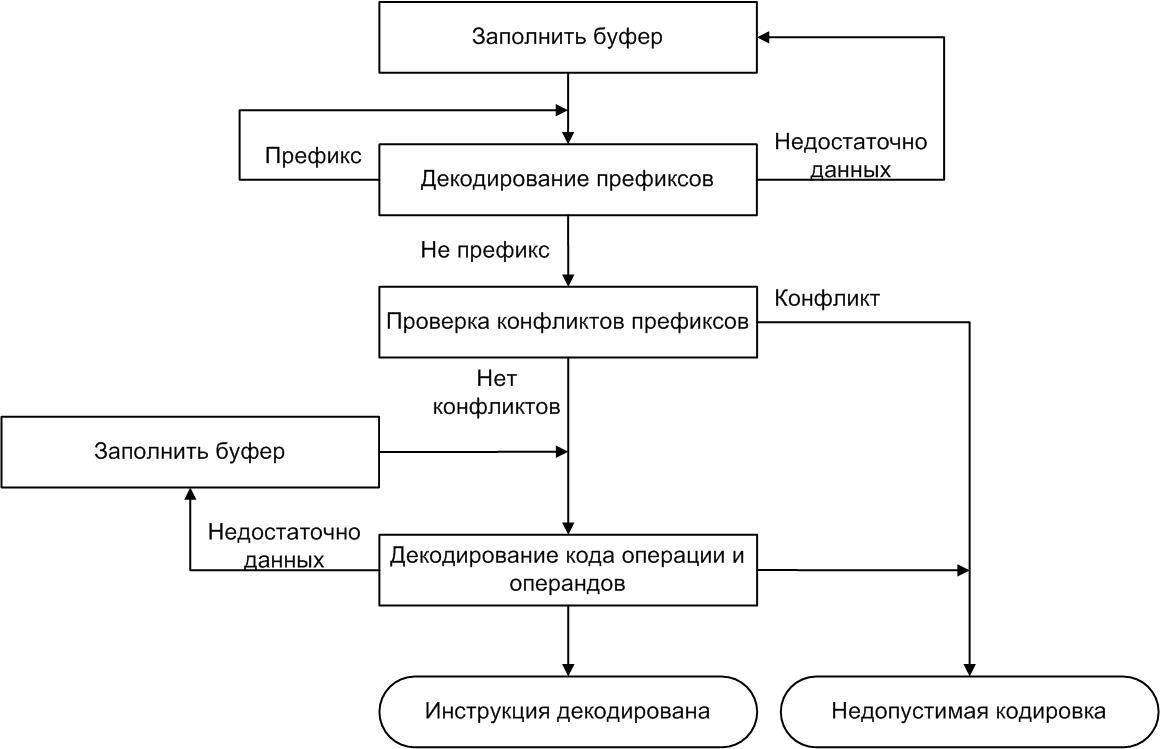
Само собой разумеется, что вторая фаза зависит от результата, так как в системе команд IA-32 существует такое понятие, как обязательные префиксы, которые фактически являются частью кода операции (см. Префиксы в системе команд IA-32).
Использование внешних декодеров
Simics позволяет подключать дополнительные декодеры с помощью внешних интерфейсов, описанных в Model Builder User's Guide, который поставляется вместе с симулятором. Таким образом, можно подключить множество внешних декодеров и вызывать их по очереди до тех пор, пока какой-нибудь декодер не даст положительного результата или список декодеров не кончится. В этом случае можно будет сделать вывод, что в данной модели данный код операции считается недопустимым.

Для обеспечения гибкости внешние декодеры в Simics делятся на два типа:
- Пользовательские декодеры (англ. user decoders) — декодеры, который могут переопределить любой существующий код операции, а также, разумеется, могут добавить возможность декодирования новых инструкций.
- Расширяющие декодеры (англ. extension decoders) — декодеры, предназначенные для расширения способностей встроенного декодера, то есть для декодирования не поддерживаемых им инструкций.
Разница между предложенными типами декодеров заключается в том, что пользовательские декодеры запускаются первыми — еще до вызова встроенного, что позволяет переопределять результаты декодирования, зашитые в исходную модель. Расширяющие запускаются только в том случае, когда ни пользовательские, ни встроенный декодеры не смогли распознать инструкцию.
Пользовательские декодеры определяет пользователь, тогда как расширяющие декодеры «зашиты» в модель им не могут быть изменены.
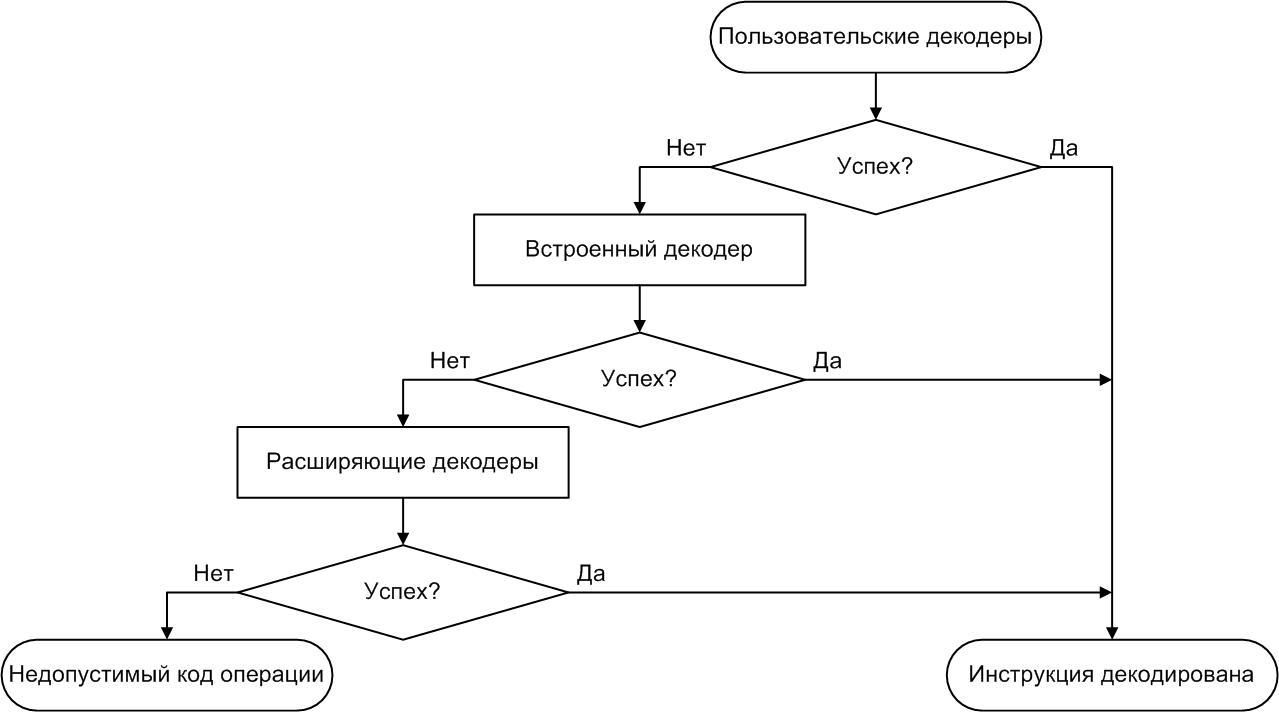
То есть пользователь, занимаясь разработкой какого-либо ISA, может просто подсунуть свой декодер и посмотреть что изменится, не меняя исходной модели процессора.
Вам вдруг захотелось поменять местами инструкции NOP и HLT и посмотреть заработает ли ваша система. Для этого Вы просто пишите маленький декодер, который декодирует 0x90 как HLT, а 0xF4 как NOP, прикрепляете его к Simics и пытаетесь запустить систему.
Кроме того, данный подход позволяет переиспользовать уже существующие декодеры вместо написания их с нуля, что значительно сокращает время разработки модели.
Если вы когда-нибудь задумывались, что это за процесс, за которым следует процессор и Оперативная память что он назначил для получения данных и инструкций, которые он должен выполнить, то вам повезло, потому что в этой статье мы собираемся объяснить, что это за процесс связи между двумя наиболее важными элементами ПК, с которыми общаются разное.
В этой статье мы не будем объяснять, какой тип оперативной памяти лучше or спецификации каждого , но процессор связывается с ним, чтобы иметь возможность выполнять программы.
Причина почему мы используем внешнюю память потому, что количество транзисторов, необходимых для хранения информации, не поместится в пространстве процессора , поэтому необходимо использовать память RAM, внешнюю по отношению к процессору, для хранения инструкций и данных, которые они будут выполнять.
RISC против CISC против Post-RISC
У процессоров RISC мало инструкций, поэтому им нужно восполнить нехватку инструкций более сложными, но взамен они получают более высокую скорость при их выполнении из-за их легкости. С другой стороны, процессоры CISC имеют гораздо более сложные наборы инструкций, которые требуют более сложной конструкции оборудования, но вместо этого выполняют эти инструкции за меньшее количество циклов.
Это различие, хотя и спорным в день, больше не так из-за того, что с момента появления из Pentium Pro на ПК мы пошли в эпоху пост-RISC, в котором, несмотря на то, что программы используют набор регистров и инструкций , они преобразуются в микрокод более простых инструкций в процессе, позволяя архитектурам CISC вести себя как архитектуры RISC и достигать высоких тактовых частот с использованием сложных инструкций.
Как ЦП читает инструкции в двоичном коде
Независимо от того, какой процессор использует наша система, все они читают двоичный код определенным образом, соответствующим своему семейству. Что они делают, так это берут определенное количество бит двоичного кода, который они выполняют, и интерпретируют их значение в соответствии с его расположением. Каждая инструкция кодируется следующим образом: первые цифры соответствуют коду инструкции и способу его выполнения, а последние биты - это сами данные или место, где находятся данные, на которых мы хотим выполнить инструкцию.
Наборы регистров и инструкций ЦП называются ISA (Архитектура набора инструкций), и все в рамках одного ISA используют одинаковую кодировку инструкций и, следовательно, один и тот же двоичный код для них.
Контакты для связи с RAM

- адресация штифты : Обычно обозначается от A0 до AN, где N - количество контактов и равно количеству бит адресации, которое всегда равно 2 ^ N.
- Контакты данных : Здесь данные передаются в оперативную память и из нее.
- Запись разрешена: Если вывод активен, передача данных осуществляется в память, запись, с другой стороны, если она не активна, то в сторону процессора, чтение.
Если наша система имеет несколько микросхем памяти RAM, то первые биты адресации используются для выбора, к какой из микросхем памяти мы хотим получить доступ в модуле памяти DIMM. Также были случаи, когда адрес и контакты данных совпадали. Это связано с тем, что адресация и доступ к данным не выполняются одновременно.
Но чтобы понять, как работает адресация, мы должны рассмотреть основную часть электроники - двоичный декодер.
Визуализация цикла обучения
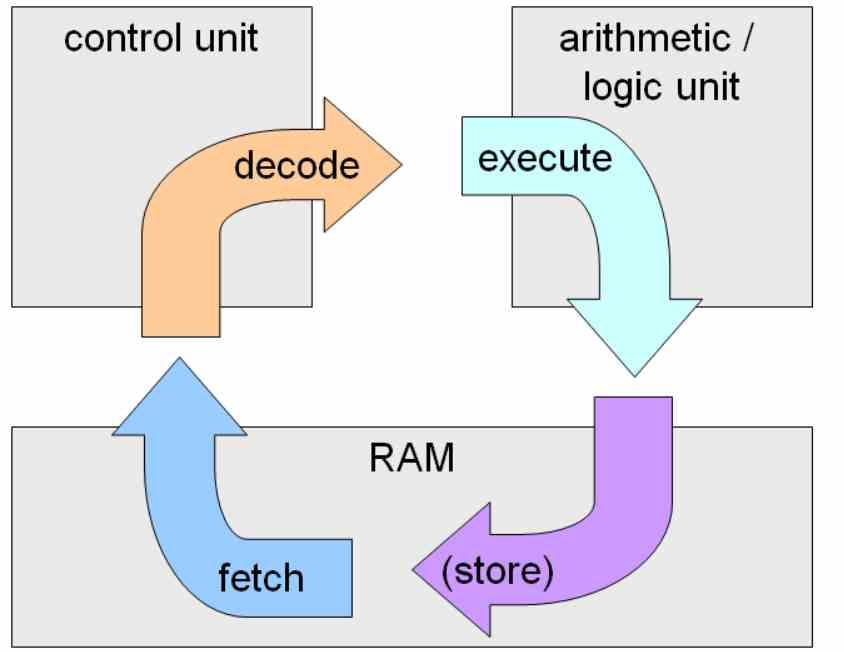
- Получить или захватить: В котором инструкция захватывается из ОЗУ и копируется в процессор.
- Декодирование или декодирование: В котором ранее захваченная инструкция декодируется и отправляется исполнительным блокам.
- Выполнили: Если инструкция разрешена, а результат записан во внутренние регистры процессора или в адрес памяти RAM
Эти три этапа выполняются в каждом процессоре. Существует четвертый этап, который является обратной записью, когда исполнительные блоки записывают результат, но это обычно учитывается на этапе выполнения цикла команд.
Первый этап цикла обучения: выборка
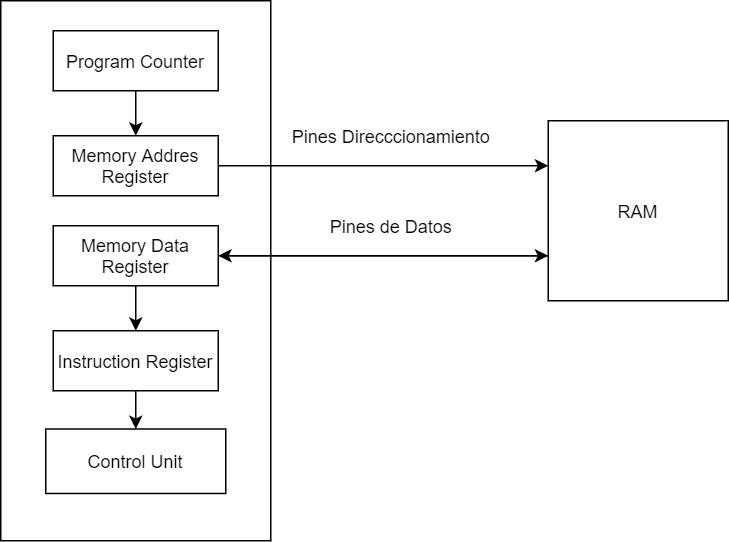
- Программный счетчик или Программный счетчик: Что указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в ОЗУ через адресационные контакты ЦП, которые соединены с адресными контактами самого ОЗУ.
- Регистр данных памяти или регистр данных памяти : В случае, если ЦП должен выполнить чтение памяти, MDR копирует содержимое этого адреса памяти во внутренний регистр ЦП, который является временным регистром передачи, прежде чем его содержимое будет скопировано в регистр команд. MDR, в отличие от MAR, подключается к выводам данных RAM, а не к контактам адресации, и в случае инструкции записи содержимое того, что вы хотите записать в RAM, также записывается в MDR.
- Реестр инструкций: Заключительной частью этапа выборки является запись инструкции в регистр инструкций, из которого блок управления процессором копирует ее содержимое для второго этапа цикла инструкций.
Эти 4 подэтапа происходят во всех процессорах, независимо от их полезности, архитектуры и двоичной совместимости или того, что мы называем ISA.
Связь набора инструкций с языком ассемблера
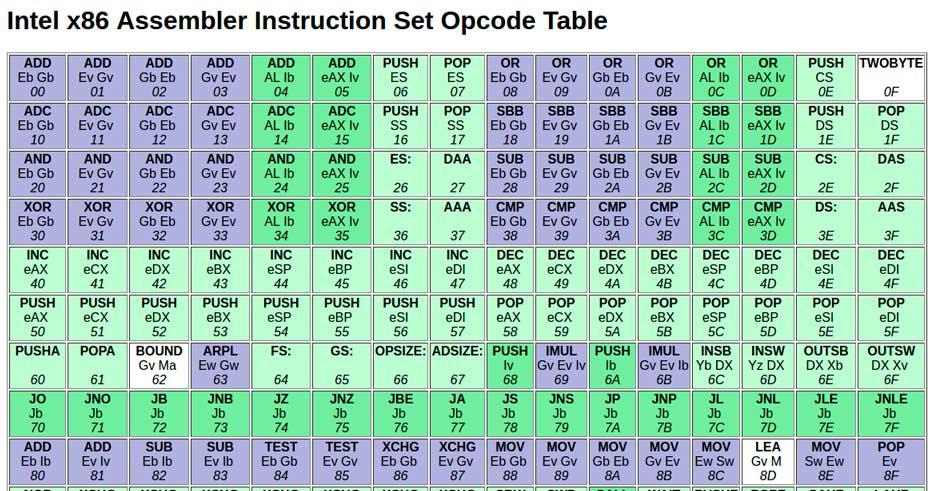
Все семейства процессоров имеют общий язык ассемблера, инструкции которого имеют соотношение 1: 1 с набором регистров и инструкций этого семейства процессоров. В приведенной выше таблице вы можете увидеть взаимосвязь между различными инструкциями языка ассемблера x86 и их кодом инструкций, который в таблице выражен в шестнадцатеричном формате.
Имейте в виду, что в ISA постоянно добавляются новые инструкции, что приводит к появлению очень новых программ, которые явно используют эти новые инструкции, работают только на процессорах, которые их поддерживают. В общем, наборы инструкций стабильны во времени с небольшими изменениями, но время от времени вводятся инструкции для конкретных рынков, которые либо становятся частью стандарта, либо позже отбрасываются.
Также есть случай, когда новые инструкции более эффективны, чем существующие, но в которых эти инструкции не исключаются из набора, потому что на рынке существует большое количество программного обеспечения, которое зависит от них.
устройство управления
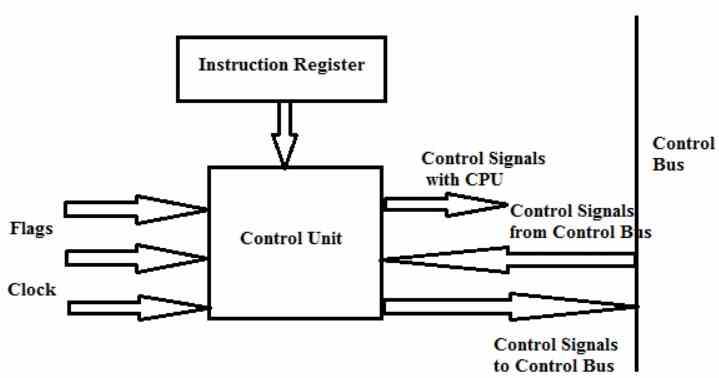
- Они отвечают за координацию движения и порядок, в котором данные перемещаются внутри и вне процессора, а также за различные подблоки, которые за это отвечают.
- В общем, считается, что блоки этапа захвата или Fetch являются частью оборудования, которое мы называем блоком управления, и это оборудование также называется Front-End процессора.
- Он интерпретирует инструкции и отправляет их различным исполнительным устройствам, к которым он подключен.
- Он передается различным ALU и исполнительным блокам процессора, которые действуют
- Он отвечает за захват и декодирование инструкций, а также за запись результатов в регистры, кеши или в соответствующий адрес ОЗУ.

Блок управления декодирует инструкции, и он делает это, потому что каждая инструкция на самом деле является своего рода предложением, в котором сначала идет глагол, а затем прямой объект или объект, на котором выполняется действие. Субъект в конечном итоге исключается на этом внутреннем языке компьютеров, поскольку понимается, что это сам компьютер выполняет его, поэтому каждое число битов представляет собой предложение, в котором первые 1 и 0 соответствуют действию, а единицы Далее идут данные или расположение данных, которыми нужно управлять.
Зачем процессору связь с ОЗУ?
Стадия, на которой ЦП берет следующую инструкцию для выполнения из ОЗУ, называется «выборкой» и является одним из трех этапов, составляющих цикл команд: Fetch-Decode-Execute, о котором мы поговорим только в этой статье о первой, а о второй два будут оставлены на другой раз, так как оперативная память не вмешивается в них, кроме как для записи результата обратно.
- Счетчик команд: ПК указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в RAM через адресные контакты ЦП, которые соединены с адресными контактами RAM.
- Регистр данных памяти : Если инструкция прочитана, то ОЗУ будет передавать через свою шину данных содержимое адреса памяти, на который указывал MAR.
- Реестр инструкций: Инструкция копируется в регистр инструкций, откуда блок управления расшифровывает ее, чтобы знать, как выполнить инструкцию.
Второй этап: декодирование
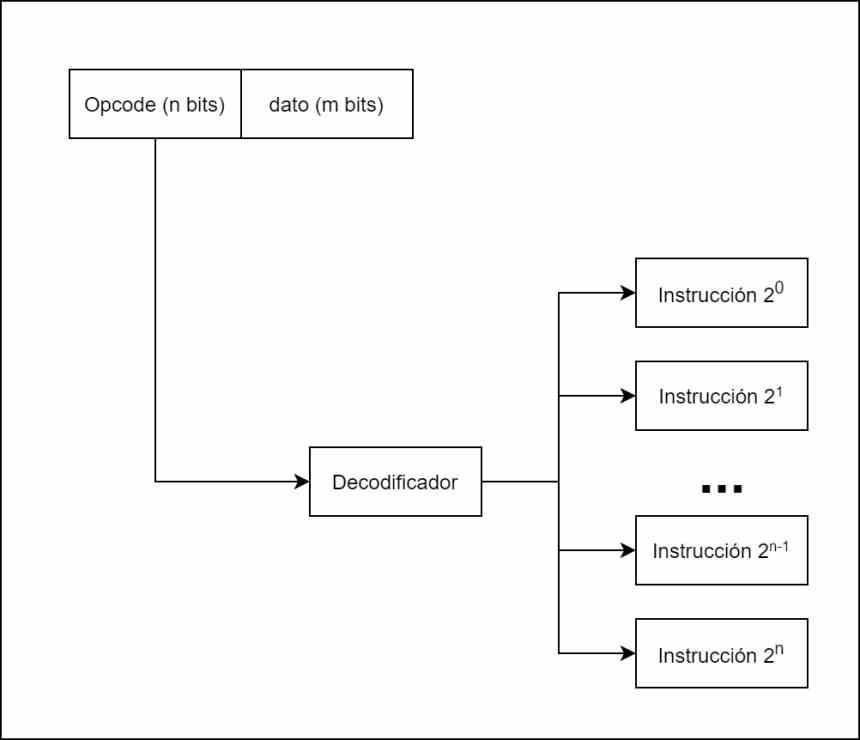
Существуют разные типы инструкций, и не все они делают одно и то же, поэтому в зависимости от типа инструкции нам нужно знать, в какие исполнительные единицы будут отправляться, и самый классический способ сделать это - использовать то, что мы называем декодером. , который принимает каждую инструкцию, делит ее внутри в соответствии с кодом операции или инструкцией и данными или адресом памяти, где она расположена.
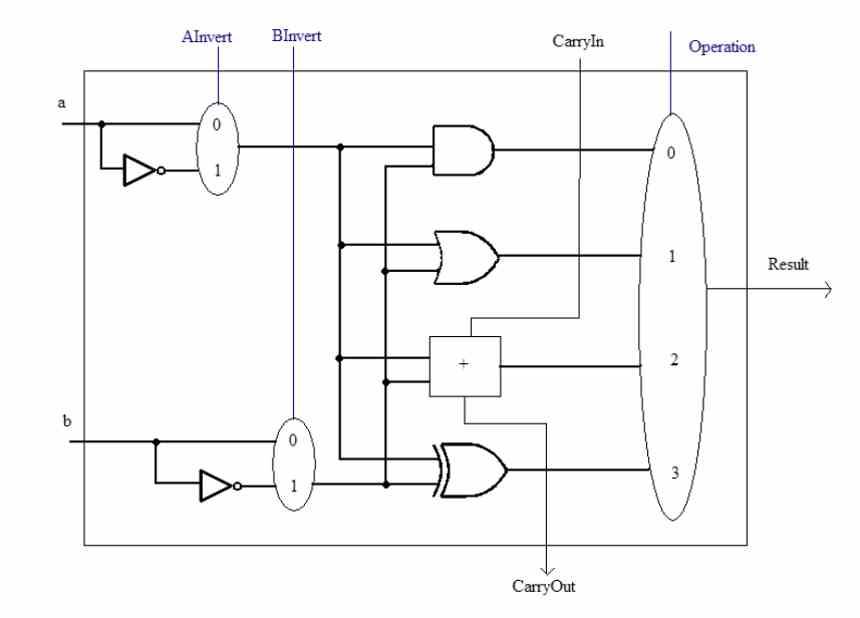
Например, на диаграмме выше у нас есть диаграмма процессора всего с 8 инструкциями, которые могут быть закодированы только 3 битами. Каждая из инструкций после декодирования отправляется различным исполнительным блокам, которые их разрешат.
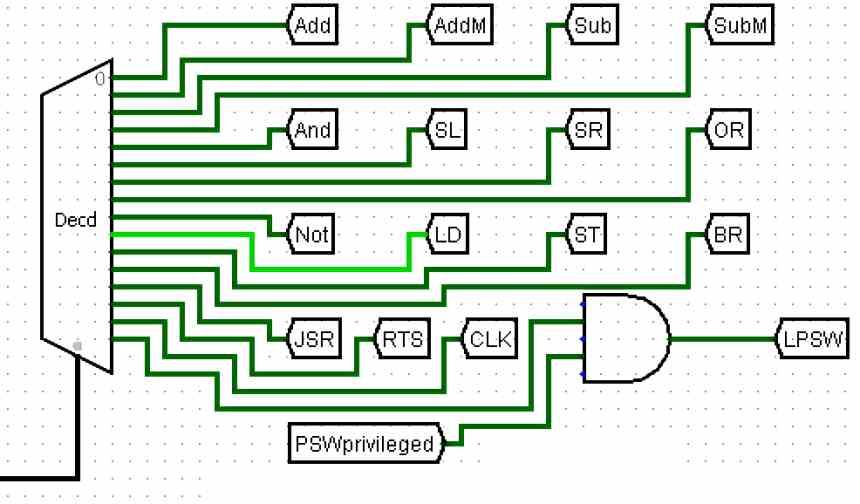

Этот цикл команд является самым сложным из всех и определяет тип архитектуры. В зависимости от того, есть ли у нас сокращенный или сложный набор инструкций, это повлияет на характер блока управления, в зависимости от формата инструкции или от того, сколько одновременно обрабатывается на этапе декодирования, и, следовательно, блок управления будет иметь разная природа. Другой.
Самый простой способ визуализировать происходящее - представить инструкции как поезда, движущиеся по сложной железнодорожной сети, и блок управления, направляющий их к конечной станции, которая является исполнительным блоком, который будет отвечать за выполнение инструкции.
Третий этап: Выполнить
- Инструкции по перемещению долота: В котором осуществляется управление порядком битов, содержащих данные.
- Арифметические инструкции: Там, где выполняются математические и логические операции, они решаются в так называемых ALU или арифметико-логических устройствах.
- Инструкции по прыжкам: В котором изменяется следующее значение программного счетчика, что позволяет использовать код рекурсивно.
- Инструкция к памяти: Они используются процессором для чтения и записи информации из системной памяти.
Другой момент - это форматы инструкций, поскольку инструкция может применяться к данным, скаляру или нескольким данным одновременно, что мы знаем как SIMD. В заключение и в зависимости от формата данных существуют разные типы ALU для выполнения арифметических инструкций, например, сегодня у нас есть целые числа и блоки с плавающей запятой как дифференцированные блоки.
После того, как инструкция завершена, результат записывается в определенный адрес памяти, и выполняется следующий. Некоторые инструкции управляют не значениями памяти, а определенными регистрами. Таким образом, регистр программного счетчика модифицируется инструкциями перехода, если мы хотим читать или записывать данные, то управляются регистры MAR и MDR.

При присвоении набору инструкций нам предлагается написать последовательность инструкций для арифметических операций, необходимых в различных моделях архитектуры: аккумулятор, стек, загрузка / сохранение, память / память.
- Код операции - 8 бит
- Адреса памяти - 16 бит
- Все регистры закодированы 4 битами
- Все операнды данных - 32 бита
- Все инструкции должны иметь четное число байтов, то есть 8 x N бит, где N - натуральное число.
А ТАКЖЕ! Адреса регистров могут быть упакованы вместе
Вопрос 1: Когда мы собираем два регистра вместе? Как система узнает, что это не один регистр, закодированный в 4 бита? Не могли бы вы привести мне пример?
Скажем, нам дано A = B + C. Инструкции, необходимые в модели загрузки / сохранения для этой операции:
Первая инструкция имеет длину 28 бит, поэтому нам нужны дополнительные 4 бита.
вопрос 2: Имеет ли значение, где поместить 4 бита в виде 0000? Как бы вы составили инструкцию из целого числа байтов?
Буду очень признателен за вашу помощь.
- Это зависит от вас, как вы создадите свой набор инструкций. Возможно вам понадобится NOP Оператор, который представляет собой бездействующие 4-битные инструкции, которые вы можете использовать везде, где в конечном итоге окажетесь с размером, отличным от 32 бит.
- Спасибо за ваш ответ. Подскажите, пожалуйста, когда мы хотим упаковать два регистра в один? Например, я использую регистры r1 и r2 и в кодировке они выглядят как 0001 и 0010. Могу ли я записать их оба только с 4 битами? Как бы они выглядели? Что-то вроде 0110? Я совершенно запуталась.
- Как я уже сказал, решать вам. это ваш набор инструкций, и вам решать, как его представить.
Хотя вопрос кажется немного расплывчатым, я рискну ответить и, возможно, проведу полезное обсуждение.
Вопрос 1: Когда мы собираем два регистра вместе? Как система узнает, что это не один регистр, закодированный в 4 бита? Не могли бы вы привести мне пример?
В МНЕ БЫ (Декодер инструкций) в ЦП сначала прочитает код операции. Это означает, что как только он узнает инструкцию, которую нужно декодировать, он знает, как интерпретировать следующие биты. Вы можете кодировать свои регистры на 4 бита, что означает, что у вас есть 16 регистров. Но представьте, что у вас есть инструкция, которая может работать только с 2 регистрами из подмножества из 4 регистров.. В этом случае вы можете использовать только 4 бита для идентификации 2 регистров. Таким образом вы упаковали в 4 бита "идентификаторы" из 2-х регистров.
вопрос 2: Имеет ли значение, где поместить 4 бита в виде 0000? Как бы вы составили инструкцию из целого числа байтов?
Он считает, где вы поместите 4 бита. В зависимости от каждого кода операции декодер команд знает, где получить адрес регистра, который он использует. Например, для грузить инструкция, если вы разработали инструкцию, чтобы она имела 4 бита сразу после кода операции, когда декодер определяет грузить, if интерпретирует следующие 4 бита как идентификаторы регистров.
Я не верю, что вы обязаны использовать целое количество байтов в том смысле, что каждый бит в инструкции имеет значение. Инструкция может состоять из целого числа байтов, просто содержащего неиспользуемые биты (обычно в конце).
Что такое инструкция?
Инструкция - это не что иное, как действие, которое мы отправляем процессору. Инструкции могут быть арифметическими операциями с различными типами данных, такими как с плавающей запятой, целыми числами, вектором, скаляром, логическими операциями, операциями перемещения данных, операциями перемещения битов (где бит изменяет положение), операциями перехода и т. Д.
Эти же инструкции делятся на другие подтипы в зависимости от того, где находятся данные. Например, некоторые инструкции позволяют работать с данными, находящимися в регистрах в этот момент, в то время как в других случаях мы должны отметить адрес памяти, в котором находятся данные (прямой режим), или адрес адреса памяти (косвенный режим ).
Что такое память DRAM?
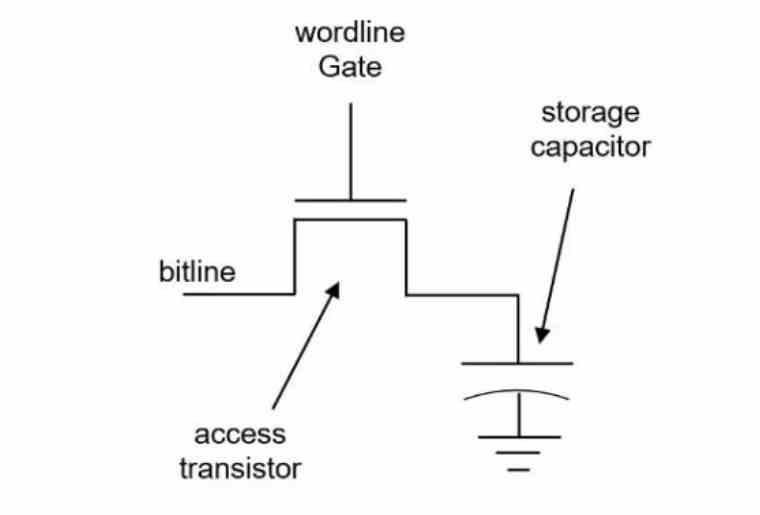
тип памяти, используемой для RAM как системное ОЗУ, так и видеопамять или видеопамять. Память DRAM или 1T-DRAM . В этом типе памяти каждый бит хранится в комбинация конденсатора и транзистора , а не в нескольких транзисторах, таких как SRAM, отсюда и название 1T-DRAM.
Вся память RAM, используемая в настоящее время в ПК: DDR4, GDDR6, HBM2e, LPDDR4 и т. Д., Является памятью типа DRAM, в то время как внутренняя память процессоров, кеши регистров и блокноты относятся к типу SRAM.
Указанная комбинация конденсатора и транзистора называется Bitcell , когда конденсатор битовой ячейки заряжен, интерпретируется, что информация, содержащаяся в этой битовой ячейке, равна 1, когда она не заряжена, она интерпретируется как 0.
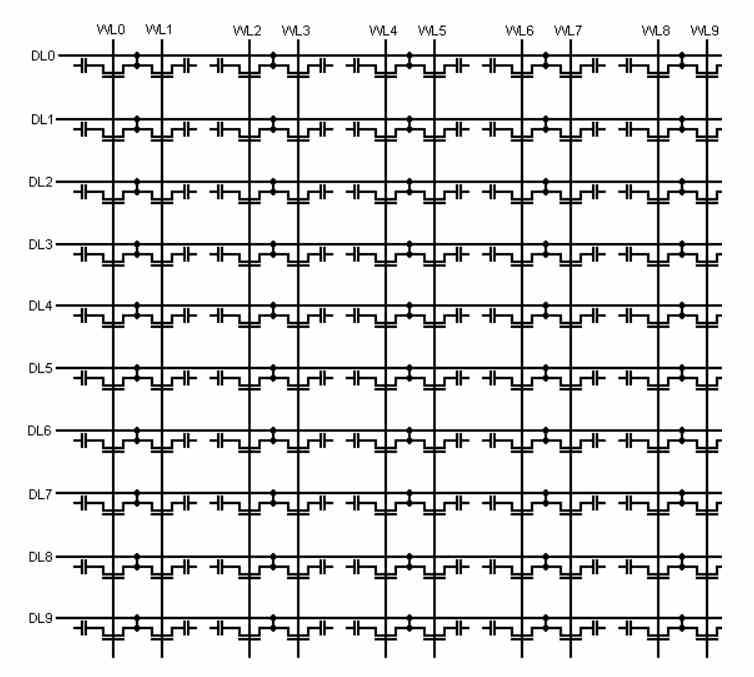
Битовые ячейки организованы в матрицу, в которой контакты адресации используются для доступа к ним следующим образом:
- Первая половина битов выбирает строку, к которой мы хотим получить доступ
- Вторая половина битов адресации содержит столбец, к которому мы хотим получить доступ,
Для этого между матрицей битовых ячеек и шиной адресации существует двоичный декодер, который позволяет выбрать соответствующую битовую ячейку.
Двоичный декодер и его роль в связи с RAM
В оперативной памяти адресация передается в двух циклах: сначала отправляется строка, к которой необходимо получить доступ, а затем столбец, а не одновременно.
По этой причине обращение к оперативной памяти происходит в два этапа.
Банки памяти
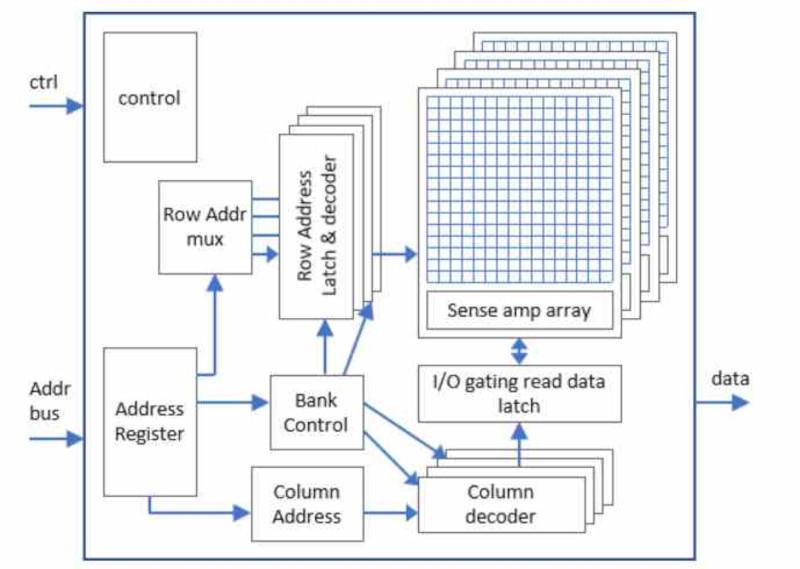
Данные в ОЗУ не хранятся последовательно , но в разных банках на одном чипе, каждый из банков содержит массив битовых ячеек , но если мы хотим передать, например, n битов данных, нам понадобится n массивов битовых ячеек, каждый из которых подключен к выводу шины данных.
Использование несколько банков , в той же микросхеме памяти, позволяет выбрать несколько бит одновременно с одним доступом к памяти , поскольку все банки разделяют адресацию . Таким образом, если у нас есть 8 банков памяти, выбор конкретной битовой ячейки приведет к одновременной передаче данных в 8 банков памяти и из них.
Стандартный размер банков в памяти RAM составляет 8 бит, поэтому максимальный объем памяти при адресации всегда считается как 2 ^ n байтов. Фактически, это 16-, 32-, 64-битные шины и т. Д. Они передают данные нескольких последовательных адресов памяти, начиная с первого.
Связь между RAM и CPU

- Выберите столбец (Адресация)
- Выберите строку (Адресация)
- Передача данных.
Для этого используется ряд специальных контактов, один из которых мы уже видели, и это запись Enable, а два других следующие:
- Строб доступа к колонке: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем столбец, к которому хотим получить доступ.
- Строб доступа к строке :: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем строку, к которой хотим получить доступ.
Обе операции можно резюмировать следующим образом:
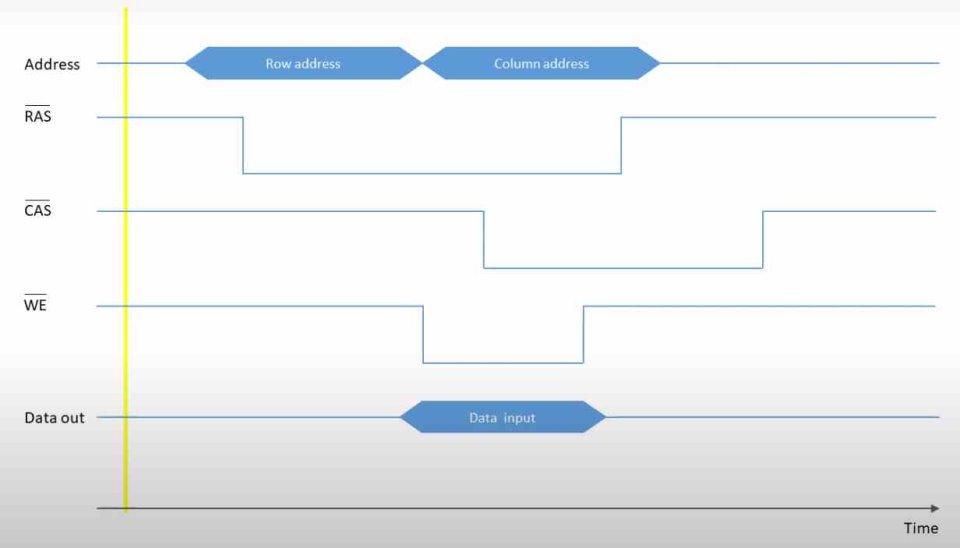
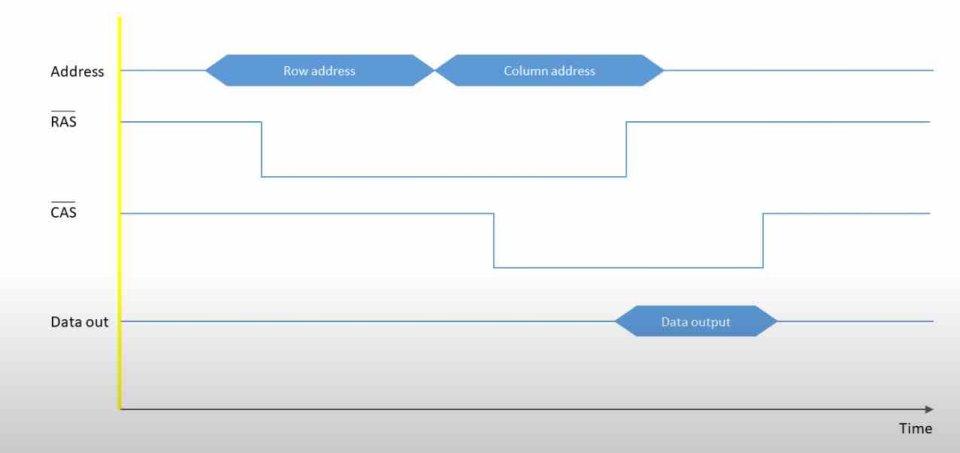
- Операция чтения очень проста, для этого у вас должен быть неактивен вывод WE, чтобы указать, что данные идут из ОЗУ в процессор, указать строку, а затем столбец, чтобы информация поступала к процессору из ОЗУ памяти. .
- Операция записи несколько отличается, для этого вывод WE должен быть активен, но данные передаются не после выбора столбца данных, а после выбора строки и одновременно с выбором столбца, в котором находятся данные.
Благодаря этому вы уже можете получить приблизительное представление о том, как работает связь между процессором и его оперативной памятью.
Что ЦП выполняет инструкции программы, находящейся в памяти. Но знаете ли вы, что все они следуют одним и тем же общим правилам? Все они следуют одному и тому же командному циклу, который разделен на три отдельных этапа, называемых «выборка», «декодирование» и «выполнение», которые переводятся как выборка, декодирование и выполнение. Мы объясняем, как работают эти этапы и как они организованы.
Читайте также: