
Как парсить гугл диск
Я все еще занимаюсь электронными таблицами Google, недавно понял, как отформатировать .txt , чтобы иметь возможность использовать =ImportData должным образом благодаря помощи Танаике, теперь я решаю - немного - более сложную задачу.
Цель:
Автоматическое извлечение определенных данных из файлов .pdf, размещенных в папке диска Google, и размещение информации в определенных ячейках.
Проблемы:
- Возможность декодировать информационные блоки, поскольку только необработанные данные, полученный с помощью =ImportData , бесполезна.
- Истинно учусь использовать google-apps-script для чего-то полезного (это я сам)
- Указание однократного извлечения информации, а не постоянного онлайн-статуса, как в =ImportData
- [Второй приоритет] Остановить в зависимости от надстройки ( Drive Direct Links ) для получения URL-адресов файлов
Насколько я понимаю, мне нужно будет выполнить синтаксический анализ. Я знаю, что .pdf не всегда прямолинейный, все файлы будут исходить из одного места и иметь один и тот же формат, поэтому достаточно понять, как это сделать один раз. Я уже знаю, как автоматически получить настоящую / постоянную ссылку на файлы и как организовать информацию, разделенную на ячейки, с помощью =Index , =Extract и других.
Надеюсь, я достаточно ясен. Заранее большое спасибо.
С наилучшими пожеланиями,
Хотя я не уверен насчет specific data , если вы хотите получить текст строки из PDF, например, как насчет их получения путем преобразования PDF в текстовые данные с помощью OCR? Что касается OCR, вы можете использовать Drive API Google и API других сайтов. Если вы хотите получить метаданные PDF, простые данные можно получить с помощью Drive API. Но если вы хотите получить подробную информацию, вам необходимо использовать API другого сайта или прямой синтаксический анализ. Для всех методов требуется использование скрипта Google Apps. Если это не то, что вам нужно, извините.
Я только что сделал несколько проб. Если я загружаю .PDF с диска Google как .TXT и снова загружаю их на диск Google, я могу использовать =Importdata для получения необходимой информации аналогично тому, что я делал с другим .TXT недавно (разделение на ячейки и еще много чего). Это сработает, но мне нужно делать это автоматически с .PDF , чтобы сократить время и рабочую нагрузку. Мне все еще нужно, чтобы скрипт заработал.
Вы хотите получать значения из файла PDF без использования OCR. Но вы хотите получить текстовый файл из файла PDF. Если я правильно понимаю, вам необходимо напрямую проанализировать файл PDF. Я не уверен насчет метода.
Но если вы используете OCR, вы можете добиться этого с помощью Files: create Drive API. Документ - здесь. Связанный поток - здесь и здесь.
Решил написать достаточно подробную инструкцию о том как работать с API Google Drive v3 с помощью клиентской библиотеки Google API для Python. Статья будет полезна тем, кому приходится часто работать с документами в Google Drive: скачивать и загружать новые документы, удалять файлы, создавать папки.
Также я покажу пример того как можно с помощью API скачивать файлы Google Sheets в формате Excel, или наоборот: заливать в Google Drive файл Excel в виде документа Google Sheets.
Использование API Google Drive может быть полезным для автоматизации различной рутины, связанной с отчетностью. Например, я использую его для того, чтобы по расписанию загружать заранее подготовленные отчеты в папку Google Drive, к которой есть доступ у конечных потребителей отчетов.
Все примеры на Python 3.
Загрузка файлов и удаление в Google Drive
Рассмотрим простой пример загрузки файла в папку. Во-первых, нужно указать folder_id — id папки (его можно получить в адресной строке браузера, зайдя в папку, либо получив все файлы и папки методом list). Также нужно указать название name, с которым файл загрузится на Google Drive. Это название может быть отличным от исходного названия файла. Параметры folder_id и name передаем в словарь file_metadata, в котором задаются метаданные загружаемого файла. В переменной file_path указываем путь к файлу. Создаем объект media, в котором будет указание по какому пути находится загружаемый файл, а также указание, что мы будем использовать возобновляемую загрузку, что позволит нам загружать большие файлы. Google рекомендует использовать этот тип загрузки для файлов больше 5 мегабайт. Затем выполняем функцию create, которая позволит загрузить файл на Google Drive.

Как видно выше, при вызове функции create возвращается id созданного файла. Можно удалить файл, вызвав функцию delete. Но мы этого делать не будет так как файл понадобится в следующем примере
Сервисный аккаунт может удалить ли те файлы, которые были с помощью него созданы. Таким образом, даже если у сервисного аккаунта есть доступ на редактирование папки, то он не может удалить файлы, созданные другими пользователями. Понять что файл был создан помощью сервисного аккаунта можно задав поисковое условие с указанием email нашего сервисного аккаунта. Узнать email сервисного аккаунта можно вызвав атрибут signer_email у объекта credentials


Дальше — больше. С помощью API Google Drive мы можем загрузить файл с определенным mimeType, чтобы Drive понял к какому типу относится файл и предложил соответствующее приложение для его открытия.

Но ещё более классная возможность — это загрузить файл одного типа с конвертацией в другой тип. Таким образом, мы можем залить csv файл из примера выше, указав для него тип Google Sheets. Это позволит сразу же конвертировать файл для открытия в Гугл Таблицах. Для этого надо в словаре file_metadata указать mimeType «application/vnd.google-apps.spreadsheet».

Таким образом, загруженный нами CSV-файл будет доступен как Гугл Таблица:

Ещё одна часто необходимая функция — это создание папок. Тут всё просто, создание папки также делается с помощью метода create, надо только в file_metadata указать mimeType «application/vnd.google-apps.folder»

Заключение
Все содержимое этой статьи также представлено в виде ноутбука для Jupyter Notebook.
В этой статье мы рассмотрели лишь немногие возможности API Google Drive, но одни из самых необходимых:
- Просмотр списка файлов
- Скачивание документов из Google Drive (в том числе, скачивание с конвертацией, например, документов Google Sheets в формате Excel)
- Загрузка документов в Google Drive (также как и в случае со скачиванием, с возможностью конвертации в нативные форматы Google Drive)
- Удаление файлов
- Создание папок
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Часто бывает нужно скопировать с какого-либо сайта большой объем данных, и поддерживать эти данные в актуальном состоянии. Делюсь пошаговой инструкцией, как это сделать!
Какое-то время назад я уже публиковал статью о том, как можно парсить данные с помощью гугл таблиц: вот эта статья , и мне теперь приходят вопросы, как это правильно делать. Сложность заключается в подборе правильных параметров для аргумента xpath в формуле importxml.
Вот и недавно пришел еще один вопрос:
Поэтому, давайте сегодня разберем еще раз, и в деталях, как парсить сайты с помощью google sheets.
Смотрите видео или читайте текст ниже, как вам удобнее!
С чего начнем? Давайте я коротко расскажу о том, что такое XPath.
1. XPath - что это?
XPath расшифровывается как XML Path Language - язык пути для XML, и служет для идентификации узлов и навигации по XML документу (Обычная веб-страница - это входит в подмножество документов XML). Это один из основных стандартов для интернета: с 16 ноября 1999 XPath стал получил рекомендацию W3C (World Wide Web Consortium) - главной организации, занимающейся стандартами в интернет.
Выражения XPath используется во многих языках программирования, включая JavaScript, Java, PHP, Python, С/С++ и многие другие.
Подробно про XPath можно прочитать на этом сайте (Жмите кнопку Next/Следующий вверху). Кстати, сайт можно перевести с помощью гугл-переводчика, и качество перевода отличное.
Доступна отличная шпаргалка по XPath: здесь .
Создание сервисного аккаунта и получение ключа
Прежде всего создаем сервисный аккаунт в консоли Google Cloud и для email сервисного аккаунта открываем доступ на редактирование необходимых папок. Не забудьте добавить в папку файлы, если их там нет, потому что файл нам понадобится, когда мы будем выполнять первый пример — скачивание файлов из Google Drive.
Я записал небольшой скринкаст, чтобы показать как получить ключ для сервисного аккаунта в формате JSON.
Установка клиентской библиотеки Google API и получение доступа к API
Сначала устанавливаем клиентскую библиотеку Google API для Python
Дальше импортируем нужные модули или отдельные функции из библиотек.
Ниже будет небольшое описание импортируемых модулей. Это для тех кто хочет понимать, что импортирует, но большинство просто может скопировать импорты и вставить в ноутбук :)
Указываем Scopes. Scopes — это перечень возможностей, которыми будет обладать сервис, созданный в скрипте. Ниже приведены Scopes, которые относятся к API Google Drive (из официальной документации):
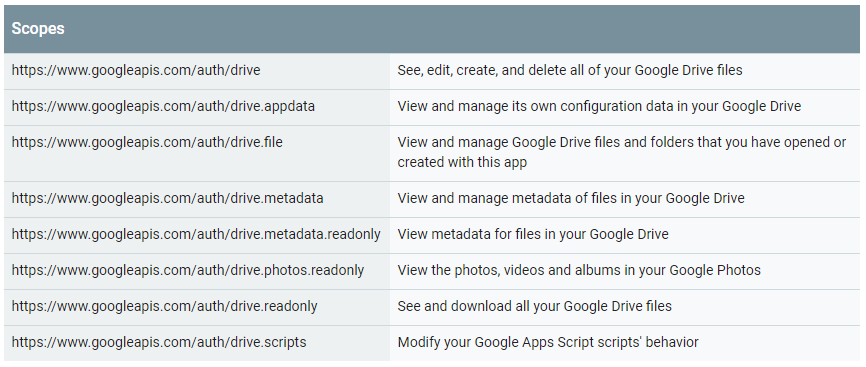
Также указываем в переменной SERVICE_ACCOUNT_FILE путь к файлу с ключами сервисного аккаунта.
Создаем Credentials (учетные данные), указав путь к сервисному аккаунту, а также заданные Scopes. А затем создаем сервис, который будет использовать 3ю версию REST API Google Drive, отправляя запросы из-под учетных данных credentials.
2. Смотрим исходный код веб-страницы
Следующий шаг - нам нужно посмотреть код веб-страницы. Но не весь, от начала и до конца, а то, что касается элементов, которые мы хотим импортировать в таблицу. Жмем правой кнопкой мыши на интересующем элементе и выбираем "Просмотр кода элемента" ("Inspect") (в разных браузерах название этого пункта меню может немного отличаться).
После этого в правой панели текущего окна или в новом окне откроется консоль разработчика, в которой отображено дерево элементов веб-страницы. Водя мышкой над этими элементами можно заметить, как на веб-странице подсвечиваются те или иные области:

Пытаюсь спарсить url на самую первую картинку с помощью =IMPORTXML(A1;"//*[@id='J_Tb-Viewer-Original-0']") - где A1 это ссылка на страницу, но всегда получаю ошибку об отсутствии данных для импорта.

Таких страниц у меня около полутысячи, вручную это делать слишком долго. Вроде ничего сложного, но чувство что бьюсь в закрытую дверь, информации в интернете на эту тему крайне мало.
Xpath в гуглотаблицах это не про динамически добавляемый html. Это про то, что отдаёт сервер при запросе.

Как тогда вытащить оттуда URL картинок в хорошем качестве? Пока что начала делать вручную, очень долго
Столбец B
=IMPORTXML(A1;"//ul[@class = 'tb-thumb tb-clearfix']/li[position() = 1]/div/a/img/@data-src")
Отдаёт //gd1.alicdn.com/imgextra/i4/1124265575/O1CN01ru2kOr1r3Om5rCAEZ_!!1124265575.jpg_50x50.jpg
Картинка 50 на 50.
НО . Адрес большой картинки содержится в этом урле. Надо только удалить из конца строки "_50x50.jpg". Тогда получим адрес большой картинки
Столбец С
=REGEXREPLACE(B1; "_50x50\.jpg$"; "")

Roman Fov, спасибо огромное, всё поняла. Теперь почему-то пишет что нет данных для импорта. Не знаете с чем может быть связано?
Т.к. это первый пост про гугл таблички, то кроме разбора конкретной функции расскажу в целом чем же они так хороши.
Гугл таблички (далее ГТ) просчитываются на бекенде, т.е. на серверах гугла и продолжают работать даже если они закрыты физически у вас в браузере. Это значит, что сложные вычисления, справочники, доки со скриптами и т.д. продолжают работать в фоне. Это позволяет из ГТ делать настоящую информационную экосистему в компании. Если добавить сюда бесчисленные интеграции - то ГТ могут собрать всё инфо в вашем бизнесе и в автоматическом режиме с ней работать.
Что касается персонального использования - то тут плюсом будут в основном интеграции и скрипты, которые оч просто использовать и обращаться к ним с телефона или вообще из телеграмма.
С прелюдией всё, переходим к мясу.
У ГТ есть замечательнейшая функция =importxml(), которая позволяет забирать данные с сайтов, т.е. парсить эти самые сайты. Функционал её ограничен и полноценного парсера в ГТ не сделать по двум причинам:
1. Оно не может парсить данные с сайтов, где необходима авторизация.
2. Оно имеет техническое ограничение на кол-во попыток парсинга, т.к. вход на сайт парсер осуществляет с одного и того же IP. Если на сайте установлено ограничение на кол-во заходов в минуту (а его специально ставят против парсеров), то работать он будет, но будет это крайне медленно.
Итак, к самой функции.
Покажу на двух примерах - КиноПоиск и Авито.
Я очень люблю ужастики, поэтому работать будем с ними :3
Заходим на кинопоиск и исследуем конкретный элемент:



На сайтах похожие элементы чаще всего имеют одинаковый класс внутри тега div, span или a. Технически грузить не буду, достаточно навести мышкой на кусок когда и нужный элемент будет подсвечен. Нам нужен тег и его класс. Т.е. div и 'info'.
Дальше заходим в ГТ и пишем следующее:
Первый аргумент функции - ссылка на сайт. Второй - запрос на языке Xpath, который ведет к заветному div с классом 'info'. На выходе получаем:

Аналогично для авито:




Вот и все на сегодня) Пост первый, так что жду критики и советов, чтобы следующий контент материал был более читабельным и полезным)
Скачивание файлов из Google Drive
Теперь рассмотрим как скачивать файлы из Google Drive. Для этого нам понадобится создать запрос request для получения файла. После этого задаем интерфейс fh для записи в файл с помощью библиотеки io, указав в filename название файла (таким образом, можно сохранять файлы из Google Drive сразу с другим названием). Затем создаем экземпляр класса MediaIoBaseDownload, передав наш интерфейс для записи файла fh и запрос для скачивания файла request. Следующим шагом скачиваем файл по небольшим кусочкам (чанкам) с помощью метода next_chunk.
Если из предыдущего описания вам мало что понятно, не запаривайтесь, просто укажите свой file_id и filename, и всё у вас будет в порядке.
Файлы Google Sheets или Google Docs можно конвертировать в другие форматы, указав параметр mimeType в функции export_media (обратите внимание, что в предыдущем примере скачивания файла мы использоали другую функцию get_media). Например, файл Google Sheets можно конвертировать и скачать в виде файла Excel.
Затем скачанный файл можно загнать в датафрейм. Это достаточно простой способ получить данные из Google Sheet в pandas-dataframe, но есть и другие способы, например, воспользоваться библиотекой gspread.

Получение списка файлов
Теперь можно получить список файлов и папок, к которым имеет доступ сервис. Для этого выполним запрос list, выдающий список файлов, со следующими параметрами:
Получили вот такие результаты:

Получив из результатов nextPageToken мы можем передать его в следущий запрос в параметре pageToken, чтобы получить результаты следующей страницы. Если в результатах будет nextPageToken, это значит, что есть ещё одна или несколько страниц с результатами

Таким образом, мы можем сделать цикл, который будет выполняться до тех пор, пока в результатах ответа есть nextPageToken. Внутри цикла будем выполнять запрос для получения результатов страницы и сохранять результаты к первым полученным результатам
Дальше давайте рассмотрим какие ещё поля можно использовать для списка возвращаемых файлов. Как я уже писал выше, со всеми полями можно ознакомиться по ссылке. Давайте рассмотрим самые полезные из них:
- parents — ID папки, в которой расположен файл/подпапка
- createdTime — дата создания файла/папки
- permissions — перечень прав доступа к файлу
- quotaBytesUsed — сколько места от квоты хранилища занимает файл (в байтах)
Отобразим один файл из результатов с расширенным списком полей. Как видно permissions содержит информацию о двух юзерах, один из которых имеет role = owner, то есть владелец файла, а другой с role = writer, то есть имеет право записи.

Очень удобная штука, позволяющая сократить количество результатов в запросе, чтобы получать только то, что действительно нужно — это возможность задать параметры поиска для файлов. Например, мы можем задать в какой папке искать файлы, зная её id:

С синтаксисом поисковых запросов можно ознакомиться в документации. Ещё один удобный способ поиска нужных файлов — по имени. Вот пример запроса, где мы ищем все файлы, содержащие в названии «data»:

Условия поиска можно комбинировать. Возьмем условие поиска в папке и совместим с условием поиска по названию:

Читайте также: