
Как изобразить двоичное дерево в текстовом процессоре
B-дерево (читается как Би-дерево) — это особый тип сбалансированного дерева поиска, в котором каждый узел может содержать более одного ключа и иметь более двух дочерних элементов. Из-за этого свойства B-дерево называют сильноветвящимся.
Зачем нужно
Вторичные запоминающие устройства (жесткие диски, SSD) медленно работают с большим объемом данных. Людям захотелось сократить время доступа к физическим носителям информации, поэтому возникла потребность в таких структурах данных, которые способны это сделать.
Двоичное дерево поиска, АВЛ-дерево, красно-черное дерево и т. д. могут хранить только один ключ в одном узле. Если нужно хранить больше, высота деревьев резко начинает расти, из-за этого время доступа сильно увеличивается.
С B-деревом все не так. Оно позволяет хранить много ключей в одном узле и при этом может ссылаться на несколько дочерних узлов. Это значительно уменьшает высоту дерева и, соответственно, обеспечивает более быстрый доступ к диску.
Свойства
- Ключи в каждом узле x упорядочены по неубыванию.
- В каждом узле есть логическое значение x.leaf . Оно истинно, если x — лист.
- Каждый узел, кроме корня, содержит не менее t-1 ключей, а каждый внутренний узел имеет как минимум t дочерних узлов, где t — минимальная степень B-дерева.
- Все листья находятся на одном уровне, т. е. обладают одинаковой глубиной, равной высоте дерева.
- Корень имеет не менее 2 дочерних элементов и содержит не менее 1 ключа.
Операции с B-деревом
Удаление элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: O(n)
Всего может быть три случая при удаление элемента из дерева двоичного поиска. Давайте рассмотрим каждый.
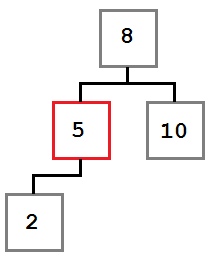
Случай I: лист
Первый случай — когда нужно удалить листовой элемент. Просто удаляем узел из дерева.
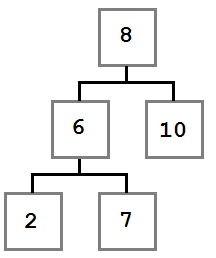
• Нужно удалить 4.
• Просто удалили узел.
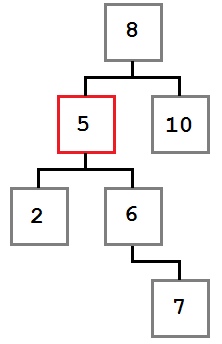
Случай II: есть дочерний элемент
Во втором случае у узла, который мы хотим удалить, есть один дочерний узел. В этом случае действуем так:
До сих пор мы рассматривали структуры данных, данные в которых располагаются линейно. В связном списке — от первого узла к единственному последнему. В динамическом массиве — в виде непрерывного блока.
В этой части мы рассмотрим совершенно новую структуру данных — дерево. А точнее, двоичное (бинарное) дерево поиска (binary search tree). Бинарное дерево поиска имеет структуру дерева, но элементы в нем расположены по определенным правилам.
Для начала мы рассмотрим обычное дерево.
Метод Remove
- Поведение: Удаляет первый узел с заданным значением.
- Сложность: O(log n) в среднем; O(n) в худшем случае.
Удаление узла из дерева — одна из тех операций, которые кажутся простыми, но на самом деле таят в себе немало подводных камней.
В целом, алгоритм удаления элемента выглядит так:
- Найти узел, который надо удалить.
- Удалить его.
Первый шаг достаточно простой. Мы рассмотрим поиск узла в методе Contains ниже. После того, как мы нашли узел, который необходимо удалить, у нас возможны три случая.
Случай 1: У удаляемого узла нет правого ребенка.
В этом случае мы просто перемещаем левого ребенка (при его наличии) на место удаляемого узла. В результате дерево будет выглядеть так:
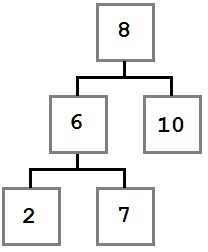
Случай 2: У удаляемого узла есть только правый ребенок, у которого, в свою очередь нет левого ребенка.
В этом случае нам надо переместить правого ребенка удаляемого узла (6) на его место. После удаления дерево будет выглядеть так:
Случай 3: У удаляемого узла есть первый ребенок, у которого есть левый ребенок.
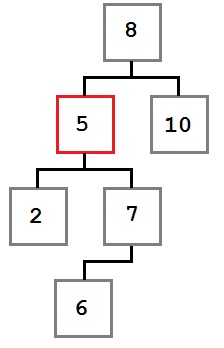
В этом случае место удаляемого узла занимает крайний левый ребенок правого ребенка удаляемого узла.
Давайте посмотрим, почему это так. Мы знаем о поддереве, начинающемся с удаляемого узла следующее:
- Все значения справа от него больше или равны значению самого узла.
- Наименьшее значение правого поддерева — крайнее левое.
Мы дожны поместить на место удаляемого узел со значением, меньшим или равным любому узлу справа от него. Для этого нам необходимо найти наименьшее значение в правом поддереве. Поэтому мы берем крайний левый узел правого поддерева.
После удаления узла дерево будет выглядеть так:
Теперь, когда мы знаем, как удалять узлы, посмотрим на код, который реализует этот алгоритм.
Отметим, что метод FindWithParent (см. метод Contains ) возвращает найденный узел и его родителя, поскольку мы должны заменить левого или правого ребенка родителя удаляемого узла.
Мы, конечно, можем избежать этого, если будем хранить ссылку на родителя в каждом узле, но это увеличит расход памяти и сложность всех алгоритмов, несмотря на то, что ссылка на родительский узел используется только в одном.
Метод Preorder (или префиксный обход)
- Поведение: Обходит дерево в префиксном порядке, выполняя указанное действие над каждым узлом.
- Сложность: O(n)
- Порядок обхода: 4, 2, 1, 3, 5, 7, 6, 8
При префиксном обходе алгоритм получает значение текущего узла перед тем, как перейти сначала в левое поддерево, а затем в правое. Начиная от корня, сначала мы получим значение 4. Затем таким же образом обходятся левый ребенок и его дети, затем правый ребенок и все его дети.
Префиксный обход обычно применяется для копирования дерева с сохранением его структуры.
Вставка элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: ΘO(n)
Операция вставки значения похожа на поиск элемента. Мы также придерживаемся правила: левое поддерево меньше корня, правое поддерево — больше.
Мы продолжаем переходить либо к правому поддереву, либо к левому поддереву в зависимости от значения узла, и когда достигаем точки, в которой левое или правое поддерево имеет значение NULL, помещаем туда новый узел.
Алгоритм:
Алгоритм не такой простой, как может показаться на первый взгляд. Давайте визуализируем процесс.
• 4 > 3 → идем через правого «ребенка» 3.
• Левого «ребенка» у 6 нет → вставляем 4 как левый дочерний элемент 6.
Мы вставили узел в нужное место, но нам всё еще нужно выйти из функции, не повредив при этом остальную часть дерева. Здесь пригодится return node; . В случае с NULL , вновь созданный узел возвращается и присоединяется к родительскому узлу, иначе тот же узел возвращается без каких-либо изменений по мере продвижения вверх, пока мы не вернемся к корню.
Таким образом, когда мы будем двигаться обратно вверх по дереву, связи других узлов не изменятся.
Корень возвращаем в конце — так ничего не сломается.
Метод Clear
- Поведение: Удаляет все узлы дерева.
- Сложность: O(1)
Двоичное дерево поиска
Двоичное дерево поиска похоже на дерево из примера выше, но строится по определенным правилам:
- У каждого узла не более двух детей.
- Любое значение меньше значения узла становится левым ребенком или ребенком левого ребенка.
- Любое значение больше или равное значению узла становится правым ребенком или ребенком правого ребенка.
Давайте посмотрим на дерево, построенное по этим правилам:
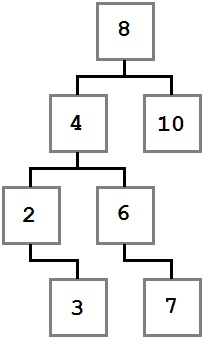
Двоичное дерево поиска
Обратите внимание, как указанные ограничения влияют на структуру дерева. Каждое значение слева от корня (8) меньше восьми, каждое значение справа — больше либо равно корню. Это правило применимо к любому узлу дерева.
Учитывая это, давайте представим, как можно построить такое дерево. Поскольку вначале дерево было пустым, первое добавленное значение — восьмерка — стало его корнем.
Мы не знаем точно, в каком порядке добавлялись остальные значения, но можем представить один из возможных путей. Узлы добавляются методом Add , который принимает добавляемое значение.
Рассмотрим подробнее первые шаги.
В первую очередь добавляется 8. Это значение становится корнем дерева. Затем мы добавляем 4. Поскольку 4 меньше 8, мы кладем ее в левого ребенка, согласно правилу 2. Поскольку у узла с восьмеркой нет детей слева, 4 становится единственным левым ребенком.
После этого мы добавляем 2. 2 меньше 8, поэтому идем налево. Так как слева уже есть значение, сравниваем его со вставляемым. 2 меньше 4, а у четверки нет детей слева, поэтому 2 становится левым ребенком 4.
Затем мы добавляем тройку. Она идет левее 8 и 4. Но так как 3 больше, чем 2, она становится правым ребенком 2, согласно третьему правилу.
Последовательное сравнение вставляемого значения с потенциальным родителем продолжается до тех пор, пока не будет найдено место для вставки, и повторяется для каждого вставляемого значения до тех пор, пока не будет построено все дерево целиком.
Класс BinaryTreeNode
Обход
Рассмотрим несколько алгоритмов обхода/поиска элементов в двоичном дереве.
Мы можем спускаться по дереву, в каждом из узлов есть выбор куда можем пойти в первую очередь и какой из элементов обработать сначала: левое поддерево, корень или право поддерево. Такие варианты обхода называются обходы в глубину (depth first).
Какие возможны варианты обхода (слово поддерево опустим):
- корень, левое, правое (preorder, прямой);
- корень, правое, левое;
- левое, корень, правое (inorder, симметричный, центрированный);
- левое, правое, корень (postorder, обратный);
- правое, корень, левое;
- правое, левое, корень.
Также используется вариант для обхода деревьев по уровням. Уровень в дереве — его удалённость от корня. Сначала обходится корень, после этого узлы первого уровня и так далее. Называется обход в ширину, по уровням, breadth first, BFS — breadth first search или level order traversal.
Выбирается один из этих вариантов, и делается обход, в каждом из узлов применяя выбранную стратегию.
Обычно для обходов в глубину применяется рекурсия. Реализуем один из вариантов, например симметричный: левое поддерево, корень, правое поддерево.
При этом мы обработаем первым самый левый узел, где левое поддерево окажется пустым, но правое может присутствовать. То есть в каждом из узлов будем спускаться ниже и ниже, пока левое поддерево не окажется пустым.
Для реализации других вариантов обхода просто меняем порядок вызова функций в функции _inorderInternal . И нужно не забыть переименовать функцию, чтобы название соответствовало содержимому.
Рассмотрим inorder алгоритм обхода на примере дерева, созданного в предыдущем блоке кода.
Сначала мы спустимся в самое левое поддерево — узел -1. Зайдем в его левое поддерево, которого нет, первая конструкция выполнится, ничего не сделав внутри функции. Вызовется обработчик handlerFunction , на узле -1. После этого произойдёт попытка войти в правое поддерево, которого нет. Работа функции для узла -1 завершится.
В вызов для узла -1 мы пришли через вызов функции _inorderInternal для левого поддерева узла 1. Вызов для левого поддерева -1 завершился, вызовется обработчик для значения узла 1, после этого — для правого поддерева. Правого поддерева нет, функция для узла 1 заканчивает работу. Выходим в обработчик для корня дерева.
Для корня дерева левое поддерево полностью отработало, происходит переход ко второй строке процедуры обхода — вызов обработчика значения узла. После чего вызов функции для обработчика правого поддерева.
Аналогично продолжая рассуждения, и запоминая на какой строке для определенного узла мы вошли в рекурсивный вызов, можем пройти алгоритм «руками», лучше понимая его работу.
Для обходов в ширину используется дополнительный массив.
Метод Postorder (или постфиксный обход)
- Поведение: Обходит дерево в постфиксном порядке, выполняя указанное действие над каждым узлом.
- Сложность: O(n)
- Порядок обхода: 1, 3, 2, 6, 8, 7, 5, 4
При постфиксном обходе мы посещаем левое поддерево, правое поддерево, а потом, после обхода всех детей, переходим к самому узлу.
Постфиксный обход часто используется для полного удаления дерева, так как в некоторых языках программирования необходимо убирать из памяти все узлы явно, или для удаления поддерева. Поскольку корень в данном случае обрабатывается последним, мы, таким образом, уменьшаем работу, необходимую для удаления узлов.
Заключение
Мы познакомились с концепцией двоичных деревьев и операциями для создания такого типа дерева. Эти операции интуитивно понятны, в следующей статье рассмотрим процедуру удаления и скорость работы двоичного дерева.
Метод Count
- Поведение: Возвращает количество узлов дерева или 0, если дерево пустое.
- Сложность: O(1)
Это поле инкрементируется методом Add и декрементируется методом Remove .
Метод GetEnumerator
- Поведение: Возвращает итератор для обхода дерева инфиксным способом.
- Сложность: Получение итератора — O(1). Обход дерева — O(n).
Деревья
Дерево — это структура, в которой у каждого узла может быть ноль или более подузлов — «детей». Например, дерево может выглядеть так:

Это дерево показывает структуру компании. Узлы представляют людей или подразделения, линии — связи и отношения. Дерево — это самый эффективный способ представления и хранения такой информации.
Дерево на картинке выше очень простое. Оно отражает только отношение родства категорий, но не накладывает никаких ограничений на свою структуру. У генерального директора может быть как один непосредственный подчиненный, так и несколько или ни одного. На рисунке отдел продаж находится левее отдела маркетинга, но порядок на самом деле не имеет значения. Единственное ограничение дерева — каждый узел может иметь не более одного родителя. Самый верхний узел (совет директоров, в нашем случае) родителя не имеет. Этот узел называется «корневым», или «корнем».
Вопросы о деревьях задают даже на собеседовании в Apple.
Поиск элемента
Средняя временная сложность: Θ(log n)
Худшая временная сложность: Θ(log n)
Поиск ключа в B-дереве работает так же, как и в двоичном дереве поиска.
- Сравниваем k с первым ключом узла, начиная с корня. Если k = первый ключ узла , возвращаем узел и индекс.
- Если k.leaf = true , возвращаем NULL . Элемент не найден.
- Если k < первый ключ корня , рекурсивно ищем левый дочерний элемент этого ключа.
- Если в текущем узле более одного ключа и k > первый ключ , сравниваем k со следующим ключом в узле.
Если k < следующий ключ , ищем левый дочерний элемент этого ключа (k находится между первым и вторым ключами).
Иначе иначе ищем правый дочерний элемент ключа. - Повторяем шаги с 1 по 4, пока не дойдем до листа.
Алгоритм:
Применим на примере
• Хотим найти ключ k = 17 в этом дереве.
• k нет в корне → сравниваем k с ключом корня.
• k > 11 → идем через правого «ребенка».
• Сравниваем k с первым ключом узла: k > 16 → сравниваем k со вторым ключом узла.
• k > 18 → k лежит между 16 и 18. Ищем либо в правом «ребенке» 16, либо в левом «ребенке» 18.
Двоичное дерево — древовидная структура данных, в которой у родительских узлов не может быть больше двух детей.
Создание дерева, вставка
Рассмотрим существующее двоичное дерево. Корень содержит число 3, все узлы в левом поддереве меньше текущего, в правом — больше. Такие же правила действуют для любого рассматриваемого узла и его поддеревьев.

Попробуем вставить в это дерево элемент -1.

Из корня идем в левое поддерево, так как -1 меньше 3. Из узла со значением 1 также идём в левое поддерево. Но в этом узле левое поддерево отсутствует, вставляем в эту позицию элемент, создавая новый узел дерева.
Вставим в получившееся дерево элемент 3.5.

Проходим по дереву, сравнивая на каждом из этапов вставляемое значение с элементом в узле, пока не дойдем до узла, в котором следующий узел для сравнения отсутствует, в эту позицию и вставляем новый узел.
Если дерево не существует, то есть root равен null, то элемент вставляется в корень, после этого проводится вставка по описанному выше алгоритму.
Напишем класс для создания двоичного дерева:
На скриншоте ниже то, какую информацию хранит в себе binaryTree :

Типы двоичных деревьев
Полное двоичное дерево
Полное двоичное дерево — особый тип бинарных деревьев, в котором у каждого узла либо 0 потомков, либо 2.
Совершенное двоичное дерево
Совершенное двоичное дерево — особый тип бинарного дерева, в котором у каждого внутреннего узла по два ребенка, а листовые вершины находятся на одном уровне.
Законченное двоичное дерево
Законченное двоичное дерево похоже на совершенное, но есть три большие отличия.
- Все уровни должны быть заполнены.
- Все листовые вершины склоняются влево.
- У последней листовой вершины может не быть правого собрата. Это значит, что завершенное дерево необязательно полное.
Вырожденное двоичное дерево
Вырожденное двоичное дерево — дерево, в котором на каждый уровень приходится по одной вершине.
Скошенное вырожденное дерево
Скошенное вырожденное дерево — вырожденное дерево, в котором есть либо только левые, либо только правые узлы. Таким образом, есть два типа скошенных деревьев — скошенные влево вырожденные деревья и скошенные вправо вырожденные деревья.
Сбалансированное двоичное дерево
Сбалансированное двоичное дерево — тип бинарного дерева, в котором у каждой вершины количество вершин в левом и правом поддереве различаются либо на 0, либо на 1.
.jpg)
Продолжение следует
На этом мы заканчивает пятую часть руководства по алгоритмам и структурам данных. В следующей статье мы рассмотрим множества (Set).
В этой статье рассмотрим двоичное дерево, как оно строится и варианты обходов.
Двоичное дерево в первую очередь дерево. В программировании – структура данных, которая имеет корень и дочерние узлы, без циклических связей. Если рассмотреть отдельно любой узел с дочерними элементами, то получится тоже дерево. Узел называется внутренним, если имеет хотя бы одно поддерево. Cамые нижние элементы, которые не имеют дочерних элементов, называются листами или листовыми узлами.
Дерево обычно рисуется сверху вниз.

В узлах может храниться любая информация, от примитивных типов до объектов. В этой статье, мы рассмотрим реализацию, когда в узле также хранятся ссылки на дочерние элементы. Кроме такого подхода, возможен альтернативный подход для двоичного дерева — хранение в массиве.
Первая особенность двоичного дерева, что любой узел не может иметь более двух детей. Их называют просто — левый и правый потомок, или левое и правое поддерево.
Вторая особенность двоичного дерева, и основное правило его построения, заключается в том что левый потомок меньше текущего узла, а правый потомок больше. Отношение больше/меньше имеет смысл для сравниваемых объектов, например числа, строки, если в дереве содержатся сложные объекты, то для них берётся какая-нибудь процедура сравнения, и она будет отрабатывать при всех операциях работы с деревом.
Представление двоичного дерева
Узел двоичного дерева можно представить структурой, содержащей данные и два указателя на другие структуры того же типа.
Дерево двоичного поиска — это структура данных, которая позволяет быстро работать с отсортированном списком чисел.
- Дерево двоичное, потому что у каждого узла не более двух дочерних элементов.
- Дерево поиска, потому что его можно использовать для проверки вхождения числа — за время O(log(n)) .
Чем отличается от обычного двоичного дерева
- Все узлы левого поддерева меньше корневого узла.
- Все узлы правого поддерева больше корневого узла.
- Оба поддерева каждого узла тоже являются деревьями двоичного поиска, т. е. также обладают первыми двумя свойствами.

У правого дерева есть поддерево со значением 2, которое меньше, чем корень 3 — таким дерево двоичного поиска быть не может.
Метод Inorder (или инфиксный обход)
- Поведение: Обходит дерево в инфиксном порядке, выполняя указанное действие над каждым узлом.
- Сложность: O(n)
- Порядок обхода: 1, 2, 3, 4, 5, 6, 7, 8
Инфиксный обход используется тогда, когда нам надо обойти дерево в порядке, соответствующем значениям узлов. В примере выше в дереве находятся числовые значения, поэтому мы обходим их от самого маленького до самого большого. То есть от левых поддеревьев к правым через корень.
В примере ниже показаны два способа инфиксного обхода. Первый — рекурсивный. Он выполняет указанное действие с каждым узлом. Второй использует стек и возвращает итератор для непосредственного перебора.
Поиск
Операция поиска — вернуть true или false, в зависимости от того, содержится элемент в дереве или нет. Может быть реализована на основе поиска в глубину или ширину, посмотрим на реализацию на основе алгоритма обхода в глубину.
Метод Contains
- Поведение: Возвращает true если значение содержится в дереве. В противном случает возвращает false .
- Сложность: O(log n) в среднем; O(n) в худшем случае.
Метод Contains выполняется с помощью метода FindWithParent , который проходит по дереву, выполняя в каждом узле следующие шаги:
- Если текущий узел null , вернуть null .
- Если значение текущего узла равно искомому, вернуть текущий узел.
- Если искомое значение меньше значения текущего узла, установить левого ребенка текущим узлом и перейти к шагу 1.
- В противном случае, установить правого ребенка текущим узлом и перейти к шагу 1.
Поскольку Contains возвращает булево значение, оно определяется сравнением результата выполнения FindWithParent с null . Если FindWithParent вернул непустой узел, Contains возвращает true .
Метод FindWithParent также используется в методе Remove .
Операции с двоичным деревом поиска
Функция сравнения или получение ключа
До этого мы рассматривали простые данные, для которых определена операция сравнения между ключами. Не всегда возможно реализовать сравнение таким простым образом.
Можно сделать функцию, которая будет получать ключ из данных, которые хранятся в узле.
Можно передать в конструктор специальную функцию сравнения. Эту функцию можно сделать как обычно делают функции сравнения в программировании, возвращать 0, если ключи равны. Значение больше нуля, если первый переданный объект больше второго, и меньше нуля если меньше. Важно не перепутать когда что возвращается и правильно передать параметры. Например, текущий узел, уже существующий в дереве, первым параметром, а тот, с которым производится текущая операция — вторым.
Для реализации такой возможности потребуется во всех местах сравнения использовать эту функцию
Класс BinaryTree
Класс BinaryTree предоставляет основные методы для манипуляций с данными: вставка элемента ( Add ), удаление ( Remove ), метод Contains для проверки, есть ли такое значение в дереве, несколько методов для обхода дерева различными способами, метод Count и Clear .
Кроме того, в классе есть ссылка на корневой узел дерева и поле с общим количеством узлов.
Обход деревьев
Обходы дерева — это семейство алгоритмов, которые позволяют обработать каждый узел в определенном порядке. Для всех алгоритмов обхода ниже в качестве примера будет использоваться следующее дерево:
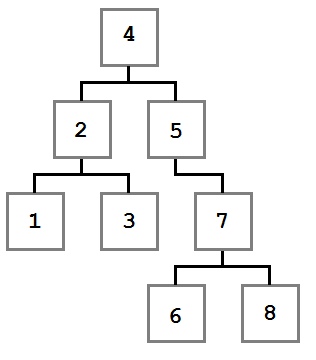
Пример дерева для обхода
Методы обхода в примерах будут принимать параметр Action , который определяет действие, поизводимое над каждым узлом.
Также, кроме описания поведения и алгоритмической сложности метода будет указываться порядок значений, полученный при обходе.
Метод Add
- Поведение: Добавляет элемент в дерево на корректную позицию.
- Сложность: O(log n) в среднем; O(n) в худшем случае.
Добавление узла не представляет особой сложности. Оно становится еще проще, если решать эту задачу рекурсивно. Есть всего два случая, которые надо учесть:
Если дерево пустое, мы просто создаем новый узел и добавляем его в дерево. Во втором случае мы сравниваем переданное значение со значением в узле, начиная от корня. Если добавляемое значение меньше значения рассматриваемого узла, повторяем ту же процедуру для левого поддерева. В противном случае — для правого.
Поиск элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: O(n)
Алгоритм зависит от свойств дерева: у каждого левого поддерева есть значения, которые ниже корня или у каждого правого поддерева есть значения, которые выше корня.
Если значение ниже корня, мы можем точно сказать, что оно находится не в правильном поддереве. Тогда нам нужно искать только в левом поддереве. А если значение выше корня, можно точно сказать, что значения нет в левом поддереве. Тогда ищем только в правом поддереве.
Алгоритм:
Изобразим это на диаграмме.
• Не нашли 4 → идем по левому поддереву корня 8
• Не нашли 4 → идем по левому поддереву корня 3
• Не нашли 4 → идем по левому поддереву корня 6
Если мы нашли значение, мы возвращаем его так, чтобы оно распространялось на каждом шаге рекурсии — рассмотрите рисунок ниже.
Как вы могли заметить, мы четыре раза вызывали search(struct node*) . Когда мы возвращаем новый узел или NULL , значение возвращается снова и снова, пока search(root) не вернет окончательный результат.
Если мы не нашли значение, значит, мы достигли левого или правого дочернего элемента листового узла, который имеет значение NULL — это значение также рекурсивно распространяется и возвращается.
Читайте также: