
Как измерить ipc процессора
Увеличение IPC или инструкций за цикл - одна из проблем для любого ЦП производитель при разработке все более мощных архитектур. В этой статье мы расскажем вам, какие новейшие методы используются инженерами, работающими над разработкой новейших процессоров для повышения IPC и, соответственно, производительности процессоров.
В истории архитектур процессоров мы видели, как были реализованы различные концепции для повышения их производительности. Такие подходы, как сегментация, суперскалярные процессоры, выполнение вне очереди и т. Д. Все они служат для получения все более быстрых процессоров и с более высокой производительностью за такт.
Концепция гибридных ядер - это еще один шаг к достижению более высокой производительности, она основана на сочетании в одном ядре двух типов ядер, одно из которых оптимизировано для сложных инструкций, а другое - для более простых инструкций, но таким образом, что они разделяют аппаратное обеспечение совместно и работают вместе, как если бы они были одним ядром ЦП.
CPI или количество циклов на инструкцию, истинная мера производительности

Реальность в процессорах такова, что не все инструкции занимают одинаковое количество циклов для разрешения , То есть Цикл каждой инструкции зависит от ее сложности и количества шагов, которые она должна пройти.
Один из способов, которым архитекторы могут улучшить производительность процессоров, - это уменьшить количество шагов, необходимых ЦП для выполнения определенных конкретных инструкций, таким образом, чтобы в зависимости от производительности при выполнении потока или программы вы в конечном итоге увеличивали скорость выполнение программы за счет ускорения выполнения этих инструкций.
Это явление происходит как в процессорах, так и в графических процессорах, и это наиболее распространенный способ повышения производительности процессора, поскольку набор регистров и инструкций - это то, что делает инструкция, адресная память, которую она использует, и записи, но не указывают как.

Например. В этой сравнительной таблице вы можете увидеть эволюцию архитектуры графических процессоров GCN от AMD к RDNA от той же компании, поскольку вы можете видеть, что одна и та же программа шейдера занимает меньше циклов в архитектуре RDNA, поскольку значительная часть ее инструкций имеет более низкий CPI.
Что инструменты мониторинга производительности на самом деле должны показывать
Я считаю, что каждый инструмент мониторинга производительности должен показывать значение IPC рядом с загрузкой процессора. Это сделано, например, в инструменте tiptop под Linux:
Определение понятий
Следует начать с определений.
IPC (instructions per clock) – количество инструкций на такт; число операций, выполняемых процессором за один процессорный такт.
Одноядерная производительность / производительность на ядро – число операций, выполняемых одним ядром процессора за единицу времени.
реклама
Как видно из определений, в случае IPC однозначно определена единица времени – один процессорный такт. В случае же производительности на ядро может использоваться любая другая единица времени. Это первое отличие.
Второе отличие, отношение к многоядерности, в текущем контексте не особо интересно. Можно ограничиться отметкой, что IPC отражает производительность всего процессора в целом, а одноядерная производительность – производительность одного отдельно взятого ядра. Вместо одноядерной производительности в тексте можно подставить многоядерную – смысл от этого никак не поменяется.
IPC как составляющая производительности на ядро
IPC одна из составляющих производительности на ядро. Чем выше IPC, тем выше одноядерная производительность при прочих равных.
Одинаковой производительности на ядро при разной IPC можно добиться изменением других характеристик. Возьмем 2 процессора X и Y. Пусть IPC процессора X равно Z, а IPC процессора Y – 0.8 Z. Т.е. IPC процессора Y ниже на 20%. Добиться одинаковой производительности на ядро в этом случае можно снижением тактовой частоты процессора X на 20%. Действительно, 1 Z * 0.8 = 0.8 Z * 1. В итоге получается, что IPC процессоров отличается на 20%, а производительность на ядро идентична.
Концепция гибридных ядер для увеличения CPI

В ЦП не все инструкции одинаково сложны, для выполнения некоторых из них требуется большее количество тактовых циклов, а для других требуется очень мало тактовых циклов, потому что они намного проще. При разработке новых процессоров до сих пор существовала тенденция оптимизации самых сложных инструкций с точки зрения количества циклов.
Но независимо от типа инструкции, выполняемой ядрами нашего ЦП, все они используют одни и те же компоненты в течение цикла команд, а это означает, что на уровне энергопотребления простейшие инструкции не могут быть оптимизированы. который не будет иметь более низкой производительности в двоично-совместимом процессоре, но с меньшим потреблением.
Идея сводится к тому, что ЦП имеет два типа исполнительных блоков, некоторые из которых оптимизированы для выполнения самых сложных инструкций, а другие - для простейших, что позволяет оптимизировать потребление различных инструкций.
Архитектура против архитектуры, когда речь идет о CPI и IPC

Одно из самых распространенных заблуждений - это сравнение двух архитектур под одним и тем же ISA, но от разных производителей. , что является неверным сравнением, если оно проводится без учета ряда условий.
Поскольку нам совершенно неизвестны исторические изменения, которые каждый производитель вносил в CPI и IPC инструкций, при измерении программы даже под тем же ISA мы обнаружим несопоставимые результаты, если сравним производительность с производительностью другой программы. Причина? Оба они используют одни и те же инструкции, но время выполнения каждой инструкции разное.
Но если мы говорим о реализациях одного и того же производителя, то мы обнаруживаем, что и ЦП, и ГП развиваются постепенно, от одной итерации к другой сохраняется значительная часть инструкций предыдущей и CPI нескольких выбранных в конструкции процессора. период.
Контрольные показатели рассказывают только часть истории
Один из способов измерить производительность процессора - это тесты, которые представляют собой не что иное, как программы, выполняющие серию инструкций, и именно в выборе используемых инструкций является ключ ко всему. Производители в значительной степени полагаются на тесты производительности при продаже продукта, и им необходимо знать, какие инструкции в их новых версиях будут использоваться больше всего.
Вот почему есть тесты, которые больше ориентированы на использование инструкций, чей CPI был улучшен в процессоре, или на предоставление преимущества определенной марке над другими, в то же время производители также отдают предпочтение улучшению CPI. и IPC наиболее часто используемых инструкций для тестов производительности.
Интерпретация данных и реагирование
Если у вас IPC > 1.0, то ваше приложение страдает не столько от ожидания данных, сколько от чрезмерного количества выполняемых инструкций. Ищите более эффективные алгоритмы, не делайте ненужной работы, кэшируйте результаты повторяемых операций. Применение инструментов построения и анализа Flame Graphs может быть отличным способом разобраться в ситуации. С аппаратной точки зрения вы можете использовать более быстрые процессоры и увеличить количество ядер.
Как вы видите, я провёл черту по значению IPC равному 1.0. Откуда я взял это число? Я рассчитал его для своей платформы, а вы, если не доверяете моей оценке, можете рассчитать его для своей. Для этого напишите два приложения: одно должно загружать процессор на 100% потоком выполнения инструкций (без активного обращения к большим блокам оперативной памяти), а второе должно наоборот активно манипулировать данным в ОЗУ, избегая тяжелых вычислений. Замерьте IPC для каждого из них и возьмите среднее. Это и будет примерная переломная точка для вашей архитектуры.
Концепция гибридных ядер для увеличения CPI
В ЦП не все инструкции одинаково сложны, для выполнения некоторых из них требуется большее количество тактовых циклов, а для других требуется очень мало тактовых циклов, потому что они намного проще. При разработке новых процессоров до сих пор существовала тенденция оптимизации самых сложных инструкций с точки зрения количества циклов.
Но независимо от типа инструкции, выполняемой ядрами нашего ЦП, все они используют одни и те же компоненты в течение цикла команд, а это означает, что на уровне энергопотребления простейшие инструкции не могут быть оптимизированы. который не будет иметь более низкой производительности в двоично-совместимом процессоре, но с меньшим потреблением.
Идея сводится к тому, что ЦП имеет два типа исполнительных блоков, некоторые из которых оптимизированы для выполнения самых сложных инструкций, а другие - для простейших, что позволяет оптимизировать потребление различных инструкций.
Идея из мира графических процессоров
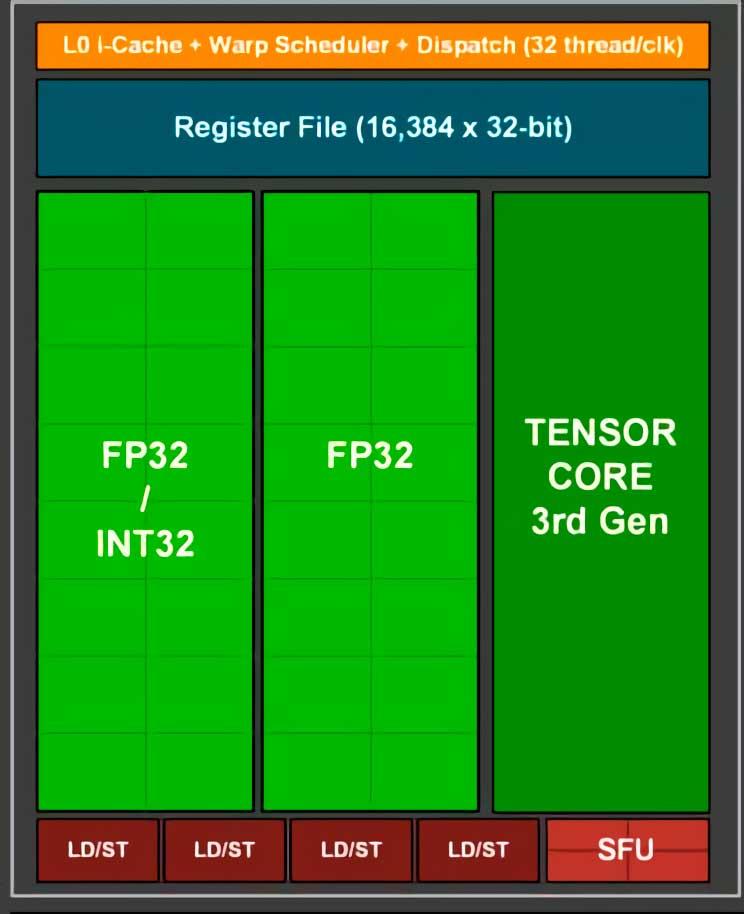
Субъядро RTX 3000 SM
В графических процессорах у нас есть два разных типа ALU, с одной стороны, у нас есть блоки SIMD, такие как ядра CUDA, которые производители обычно продвигают, говоря о скорости TFLOPS, эти блоки отвечают за этап выполнения чрезвычайно простых инструкций. , но, с другой стороны, у нас есть SFU, которые являются ALU с более низкой скоростью вычислений, поскольку они оптимизированы для более сложных инструкций
Что ж, SFU потребляли бы гораздо больше энергии для выполнения простых инструкций, чем модули SIMD, отсюда и разделение, которое было сделано много лет назад в обоих NVIDIA и AMD GPU. Когда блок управления или планировщик C0mpute Unit обнаруживает команду, которую могут выполнять SFU, он просто копирует эту строку команд и отправляет ее непосредственно в один из SFU, который свободен для выполнения.
Выводы
Загрузка процессора стала сегодня существенно недопонимаемой метрикой: она включает в себя время ожидания данных от ОЗУ, что может занимать даже больше времени, чем выполнение реальных команд. Вы можете определить реальную загрузку процессора с помощью дополнительных метрик, таких, как количество инструкций на такт (IPC). Значения меньшие, чем 1.0 говорят о том, что вы упираетесь в скорость обмена данными с памятью, а большие — свидетельствуют о большой загруженности процессора потоком инструкций. Инструменты замера производительности должны быть улучшены для отображения IPC (или чего-то аналогичного) непосредственно рядом с загрузкой процессора, что даст пользователю полное понимание ситуации. Имея все эти данные, разработчики могут предпринять некоторые меры по оптимизации своего кода именно в тех аспектах, где это принесёт наибольшую пользу.
Понятия IPC и одноядерной производительности путают между собой. Они описывают родственные, но тем не менее разные явления, поэтому их необходимо различать.
реклама

Внедрение гибридных ядер для увеличения IPC

Концепция ЦП не отличается, фаза выборки инструкций будет почти одинаковой в обоих процессорах, поэтому оба процессора будут совместно использовать счетчик программ, указывающий на следующую инструкцию, это будет в конце фазы выборки, где чтение регистра инструкций, в котором инструкция будет отправлена тому или иному типу ядра для выполнения.
Это означает, что оба ядра на самом деле будут похожи на сиамских близнецов, которые разделяют часть оборудования, разделяя один из этапов цикла команд, но поскольку инструкции будут декодироваться и выполняться в отдельной части обоих ядер, не только IPC увеличение количества одновременных инструкций за такт, но это также предотвращает конфликт определенных инструкций при использовании ресурсов.
Еще одна вещь, которую позволяет сделать это изменение, связана с управлением инструкциями, которые достигают процессора, которые представляют собой запросы, сделанные периферийными устройствами, которые останавливают выполнение кода. Вы можете сделать ядро оптимизированным для выполнения простых инструкций без остановки других команд.
IPC или инструкций на цикл

В компьютерной архитектуре , концепция инструкций за цикл относится к количеству инструкций, которые процессор выполняет одновременно, поэтому она в основном ограничена количеством исполнительных блоков в процессоре, но это не единственный ограничивающий фактор. поскольку могут быть инструкции, которые используют общие элементы процессора и вместе дают худшую производительность.
Но у этого термина есть сбивающий с толку вариант, основанный на том, чтобы взять время, которое два процессора требуется для выполнения одной и той же программы, а затем измерить разницу во времени, передать ее тактовым циклам и измерить разницу между ними. В результате получается среднее количество инструкций за цикл, но это не то, что в компьютерной архитектуре обычно называют IPC.
IPC, как мы сказали в начале, - это количество одновременных инструкций, которые процессор выполняет, и когда мы говорим «выполнение», мы имеем в виду то, что он решает в данный момент. Это не количество разрешенных инструкций, поскольку очень мало инструкций, если не сказать почти ни одной, решаются сегодня за один такт.
Его влияние на конвейер ЦП
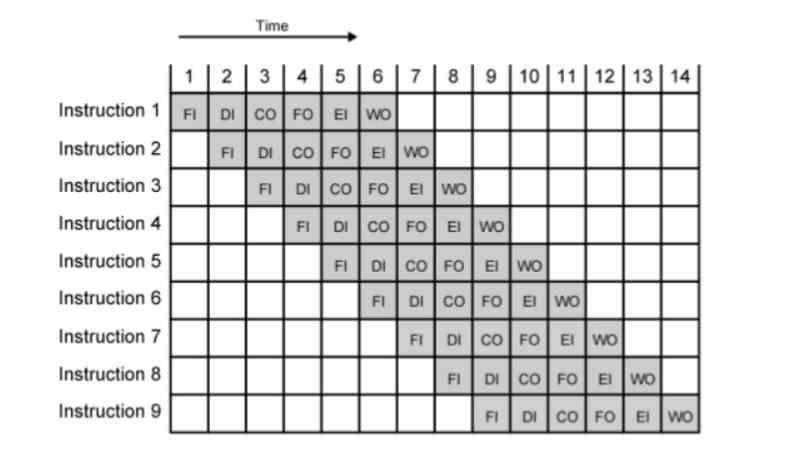
Мы должны понимать, что в настоящее время все процессоры сегментированы на несколько этапов таким образом, что если у нас есть инструкция n на определенном этапе, то инструкция n + 1 будет на предыдущем этапе, а n-1 - на следующем. .
Обратное время - это всегда частота (1 / время = частота), поэтому трюк с увеличением тактовой частоты состоит в том, чтобы уменьшить продолжительность каждого из этапов, поэтому обычно вы увеличиваете количество этапов с целью каждый новый этап длится меньше, а частота или тактовые импульсы выше.
Очевидно, что разделение сложной инструкции на большее количество командных циклов идеально подходит для достижения высоких тактовых частот. А как насчет таких же простых? Для архитекторов головная боль - разбивать даже более простые инструкции, чем они есть сегодня.
Отличия гибридных ядер с big.LITTLE

В процессоре big.LITTLE «большие» ядра отделены от ядер «LITTLE» в том смысле, что они работают коммутируемым образом по отношению друг к другу, поэтому именно приложение делает запрос к операционной системе. включается та или иная группа ядер.
Операция для этого типа ядра заключается в том, что, когда они получают конкретное прерывание, они завершают текущее и передают свидетель другому типу. Это происходит, когда рабочая нагрузка на систему очень высока или выполняются определенные условия. В любом случае необходимо учитывать, что в подходе big.LITTLE каждый набор ядер является полным и полностью независимым.
В концепции гибридных ALU у нас нет полностью отдельных ядер, а скорее они разделяют фазу захвата, а также имеют доступ как к иерархии кеша, так и к памяти. Вдобавок один не деактивируется, когда другой работает, именно потому, что они совместно используют оборудование для доступа к памяти, и мы не можем забыть, что big.LITTLE не увеличивает IPC ядер.
CPU-Z, лучший инструмент для мониторинга процессора, материнской платы и оперативной памяти
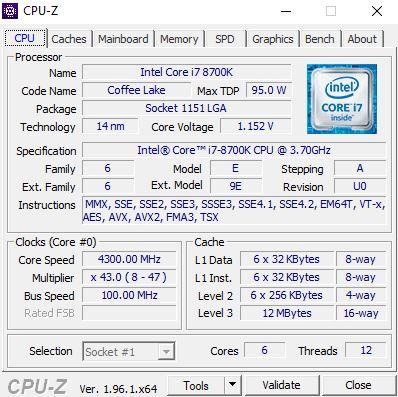
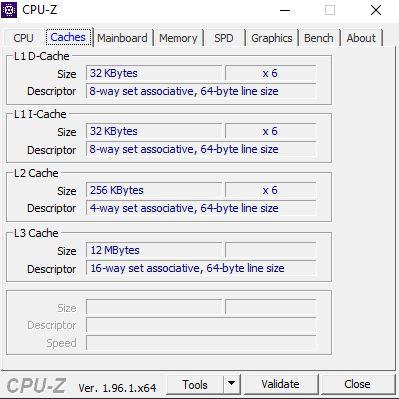
Во второй вкладке, называемой «Кэши», у нас есть информация о кеш-памяти процессора, с указанием отдельно размера и формата кешей L1, L2, L3 и L4 в случае их наличия.
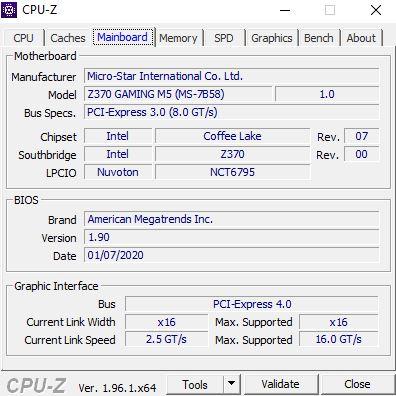
- ПРОИЗВОДИТЕЛЬ : производитель материнской платы.
- Модель : конкретная модель, включая ее ревизию, в поле справа.
- Технические характеристики автобуса - Отображает спецификации шины PCI-Express.
- Набор микросхем : показывает производителя, поколение и версию чипсета.
- Southbridge : в данном случае также говорится о чипсете и уже указывается модель.
- LPCIO - Отображает информацию о марке и модели основного контроллера ввода / вывода на плате.
- BIOS : здесь отображается информация о BIOS, такая как марка, версия и дата выпуска.
- Графический интерфейс : здесь у нас есть кое-что любопытное, потому что оно показывает нам информацию об интерфейсе видеокарты. Как видите, графический процессор поддерживает PCI-Express 4.0, а на плате - PCI-Express 3.0; Он также подтверждает, работает ли графический процессор на x16 (это полезно во многих случаях, чтобы иметь возможность знать наверняка, особенно если у нас есть проблемы с производительностью), а также его текущую скорость и максимальную поддерживаемую.
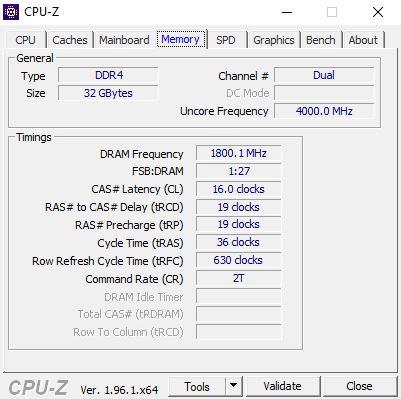
Четвертая вкладка называется Память, и, как очевидно, она дает нам информацию о Оперативная память установленная в системе память. В разделе General у нас есть тип (DDR4), размер (32 ГБ), если он работает в одно-, двух- или четырехканальном режиме (в данном случае в Dual). У нас также есть параметр под названием Uncore Частота которая, как видите, отличается от частоты оперативной памяти; Uncore - это термин, который был введен с первыми процессорами Core i7, который состоит из расчета с учетом встроенного контроллера памяти и кеш-памяти L3, что означает, более или менее, максимальную скорость ОЗУ, поддерживаемую ЦП.
Внизу у нас есть тайминги, которые представляют собой не что иное, как задержки памяти (в дополнение к частоте DRAM, которая является первым параметром). Если вы посмотрите на это, в нашем примере это 1,800 МГц, но на самом деле он работает на эффективной частоте 3,600 МГц (DDR, удвоенная скорость передачи данных, помните).
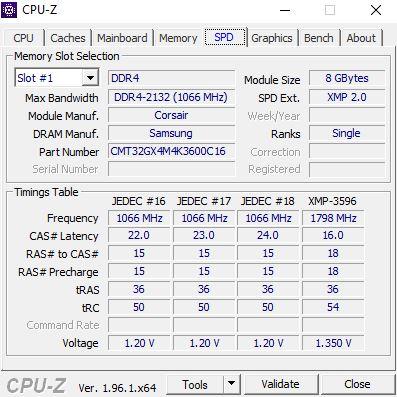
На вкладке SPD мы можем увидеть более конкретную информацию об установленных модулях памяти, и фактически в первом разделе (Выбор слота памяти) у нас есть раскрывающееся меню, в котором мы можем выбрать, какие из установленных модулей RAM мы хотим видеть. . Здесь мы находим интересные факты:
- Первоначально он сообщает нам, что это память DDR4, а под Размер модуля сообщает нам плотность выбранного модуля, в данном случае 8 ГБ.
- Макс. Пропускная способность : Несмотря на название, это стандартная частота работы памяти, в данном случае 2133 МГц. Низкие ранги говорят нам, что каждый отдельный модуль работает в одном канале, что совершенно не имеет значения. Также здесь, под SPD Ext. , Он указывает профиль XMP.
- Module Manuf, DRAM Manuf. y Номер детали : здесь говорится, что производитель модуля - Corsair, но, что немаловажно, микросхемы памяти производит Samsung. Он также сообщает нам конкретный номер модели.
- В разделе ниже Таблица синхронизации , он снова показывает нам задержки, но как в режимах JEDEC, так и в профиле XMP.
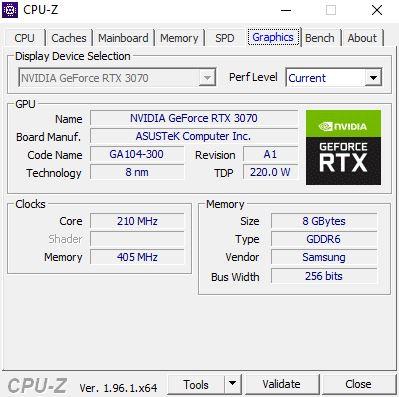
Переходим на вкладку Графика, где CPU-Z также показывает нам информацию о видеокарте. В этом случае у нас есть раскрывающийся список, который позволяет нам выбирать между несколькими, если они есть, в то время как раскрывающийся список «Уровень производительности» позволяет нам видеть текущий профиль, игру и повышение в случае, если GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР есть их.
Далее в GPU мы видим марку, модель, кодовое название, литографию и TDP графика, в то время как в разделе часов мы видим скорость работы в реальном времени GPU и памяти, а в разделе Memory мы видим информацию о VRAM. Также интересно, что здесь мы видим, что GDDR6 Asus RTX 3070, который мы использовали в примере, был произведен Samsung.
CPU-Z также имеет собственный встроенный тест, и мы можем получить к нему доступ из вкладки Bench. Здесь мы можем выполнить как тест производительности (нажав кнопку Bench CPU), так и стресс-тест (Stress CPU), выбрав, нужен ли нам эталонный процессор внизу для сравнения, и даже выбрав количество потоков процесса, которое мы хотим использовать.
Та метрика, которую мы называем «загрузкой процессора» на самом деле многими людьми понимается не совсем верно. Что же такое «загрузка процессора»? Это то, насколько занят наш процессор? Нет, это не так. Да-да, я говорю о той самой классической загрузке CPU, которую показывают все утилиты анализа производительности — от диспетчера задач Windows до команды top в Linux.
Вот что может означать «процессор загружен сейчас на 90%»? Возможно, вы думаете, что это выглядит как-то так:

А на самом деле это выглядит вот так:

«Работа вхолостую» означает, что процессор способен выполнить некоторые инструкции, но не делает этого, поскольку ожидает чего-то — например, ввода-вывода данных из оперативной памяти. Процентное соотношение реальной и «холостой» работы на рисунке выше — это то, что я вижу изо дня в день в работе реальных приложений на реальных серверах. Есть существенная вероятность, что и ваша программа проводит своё время примерно так же, а вы об этом и не знаете.
Что это означает для вас? Понимание того, какое количество времени процессор действительно выполняет некоторые операции, а какое — лишь ожидает данные, иногда даёт возможность изменить ваш код, уменьшив обмен данных с оперативной памятью. Это особенно актуально в нынешних реалиях облачных платформ, где политики автоматического масштабирования иногда напрямую завязаны на загрузку CPU, а значит каждый лишний такт «холостой» работы стоит нам вполне реальных денег.
Какая связь между FLOPS и CPI и CPI?

FLOPS - это количество операций в запятых или с плавающей запятой, которые может выполнять единица выполнения, операция длится только один цикл, и ее не следует путать с инструкцией. Они также используются в маркетинге вместо CPI и IPC, особенно когда речь идет о графических процессорах.
Например, у нас может быть процессор, который имеет гораздо более низкую скорость FLOPS, чем другой, и получит лучшую производительность из-за того, что количество циклов на инструкцию меньше в одной архитектуре, чем в другой . Когда дело доходит до измерения производительности в FLOPS, отделы маркетинга следуют инструкциям с самым низким CPI из всех, если они представляют очень высокие числа. Но на самом деле все мы знаем, что программа состоит из множества разрозненных инструкций.
Точно так же, как ошибочно сравнивать разные архитектуры с разными CPI, еще более ошибочно сравнивать разные архитектуры с точки зрения скорости FLOPS.

Если вы энтузиаст аппаратного обеспечения, вы наверняка хорошо знакомы с ЦП-Z Мониторинг и диагностическое программное обеспечение, одно из наиболее часто используемых для получения информации о аппаратное обеспечение ПК и особенно процессор. Однако вы можете не знать всего, что это программное обеспечение может для вас сделать, поэтому в этой статье мы расскажем вам все его плюсы и минусы, чтобы вы могли получить максимум от этого .
CPU-Z - один из основных инструментов, которые используют энтузиасты аппаратного обеспечения, чтобы узнать статус и информацию о нашем ПК, и он был с нами в течение многих лет (и то, что осталось). бесплатно . Однако это инструмент, который может быть гораздо более полезным, чем просто предоставление нам информации об оборудовании, которое мы установили на ПК, поэтому мы рассмотрим все аспекты приложения шаг за шагом.
Какой текущий процессор использует гибридные ядра для увеличения IPC?

Прямой ответ - решительное НЕТ, ни один из процессоров, которые сейчас присутствуют на рынке или выйдут в ближайшее время, не будет использовать гибридные ядра, но они будут больше основаны на концепции big.LITTLE. в котором будут использоваться ядра, в зависимости от ситуации, что особенно важно в IntelGen 12, который выйдет через несколько месяцев.
Тот, о котором мы знаем, благодаря подсказкам в различных патентах, опубликованных в прошлом году, что он выберет подход с гибридным ядром, - это AMD, мы не знаем, столкнется ли с ней Zen 4 или Zen 5. Это не означает, что Intel и даже другие разработчики ЦП, такие как Apple эти решения еще не реализованы.
Причина этого? Увеличение CPI не может происходить вечно, и его выполнение становится все более и более сложным, поэтому для его увеличения необходимо использовать такие методы, как гибридные ядра.
Когда мы говорим, что один процессор имеет лучшую производительность, чем другой, что мы имеем в виду? Что ж, процессор выполняет программу с большей скоростью, чем другой, но какие параметры и условия используются для улучшения производительности процессора по сравнению с его преемником?
Маркетинговые отделы, когда речь идет о продаже такой сложной технологии, как ЦП или GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР придется упростить производительность, поскольку они становятся все более сложными, и именно одним из созданных ими заблуждений стал термин IPC как термин для измерения производительности процессора.
Что же такое загрузка процессора на самом деле?
Та метрика, которую мы называем «загрузкой процессора» на самом деле означает нечто вроде «время не-простоя»: то есть это то количество времени, которое процессор провёл во всех потоках кроме специального «Idle»-потока. Ядро вашей операционной системы (какой бы она ни была) измеряет это количество времени при переключениях контекста между потоками исполнения. Если произошло переключение потока выполнения команд на не-idle поток, который проработал 100 милисекунд, то ядро операционки считает это время, как время, потраченное CPU на выполнение реальной работы в данном потоке.
Эта метрика впервые появилась в таком виде одновременно с появлением операционных систем с разделением времени. Руководство программиста для компьютера в лунном модуле корабля «Апполон» (передовая на тот момент система с разделением времени) называла свой idle-поток специальным именем «DUMMY JOB» и инженеры сравнивали количество команд, выполняемых этим потоком с количеством команд, выполняемых рабочими потоками — это давало им понимание загрузки процессора.
Так что в этом подходе плохого?
Сегодня процессоры стали значительно быстрее, чем оперативная память, а ожидание данных стало занимать львиную долю того времени, которое мы привыкли называть «временем работы CPU». Когда вы видите высокий процент использования CPU в выводе команды top, то можете решить, что узким местом является процессор (железка на материнской плате под радиатором и кулером), хотя на самом деле это будет совсем другое устройство — банки оперативной памяти.
Ситуация даже ухудшается со временем. Долгое время производителям процессоров удавалось наращивать скорость их ядер быстрее, чем производители памяти увеличивали скорость доступа к ней и уменьшали задержки. Где-то в 2005-ом году на рынке появились процессоры с частотой 3 Гц и производители сконцентрировались на увеличении количества ядер, гипертрейдинге, много-сокетных конфигурациях — и всё это поставило ещё большие требования по скорости обмена данных! Производители процессоров попробовали как-то решить проблему увеличением размера процессорных кэшей, более быстрыми шинами и т.д. Это, конечно, немного помогло, но не переломило ситуацию кардинально. Мы уже ждём память большую часть времени «загрузки процессора» и ситуация лишь ухудшается.
Программное обеспечение - это то, что командует в конце дня

Процессор выполняет программу, и важно то, что наиболее часто используемые программы на рынке в конечном итоге получают все большую и большую производительность, поэтому не только инструкции процессоров оптимизированы для повышения производительности в тестах, но также к тому, что в наиболее часто используемых программах и функциях есть разница.
В некоторых случаях создаются новые варианты наборов команд и исполнительных блоков, как это произошло с появлением модулей SIMD в конце 1990-х годов для мультимедийного контента или это происходит с инструкциями по ускорению алгоритмов искусственного интеллекта.
Повышение производительности не всегда должно сопровождаться сокращением количества циклов на инструкцию, оно может проявляться в виде новых исполнительных модулей и даже поддержки сопроцессоров.
Почему гибридные ядра увеличивают IPC процессоров?

Причина проста: наличие большего количества исполнительных блоков, а также то, что оборудование этапа декодирования не используется совместно, является причиной того, что нет того, что называется конфликтом, это происходит, когда две или более инструкций сражаются над одним ресурсом таким образом, что один должен ждать завершения другого.
Почему процессоры не разработаны без этой проблемы? Дизайн можно спроектировать, но бюджет на транзисторы ограничен, и именно поэтому архитекторы обманывают, ставя общие точки на пути. Многие из незначительных обновлений архитектуры обычно основаны на избежании конфликтов такого типа путем добавления дополнительных внутренних путей, чтобы не возникало конфликтов.
IPC в качестве маркетингового термина больше не является количеством одновременных инструкций, которые ядро процессора может выполнять одновременно в наилучших условиях, этот термин теперь основан на проведении эталонного теста и просмотре среднего количества инструкций за цикл, которые оно выполняет. выводит процессор. Вот почему так важно избегать конфликтов между инструкциями, и именно поэтому гибридные ядра с этапами декодирования и выполнения, разделенными типом ядра, идеально подходят для увеличения IPC.
Другие причины неверной трактовки термина «загрузка процессора»
Процессор может выполнять свою работу медленнее не только из-за потерь времени на ожидание данных из ОЗУ. Другими факторами могут быть:
- Перепады температуры процессора
- Вариирование частоты процессора технологией Turboboost
- Вариирование частоты процессора ядром ОС
- Проблема усреднённых расчётов: 80% средней загрузки на периоде измерений в минуту могут не быть катастрофой, но могут и прятать в себе скачки до 100%
- Спин-локи: процессор загружен выполнением инструкций и имеет высокий IPC, но на самом деле приложение стоит в спин-локах и не выполняет реальной работы
Вывод
Итак, и IPC и производительность на ядро используются для оценки производительности процессора.
реклама
IPC представляет собой более строгую и «универсальную», легко сравнимую характеристику. Эта характеристика постоянна, не изменяется в процессе работы. Напротив, одноядерная производительность подвержена изменчивости, зависит от множества факторов, непостоянна.
Изменяя тактовую частоту процессора, можно добиться паритета в одноядерной производительности с процессором, IPC которого отличается.
Подпишитесь на наш канал в Яндекс.Дзен или telegram-канал @overclockers_news - это удобные способы следить за новыми материалами на сайте. С картинками, расширенными описаниями и без рекламы.
Как же понять, чем на самом деле занят процессор
Используя аппаратные счетчики производительности. В Linux они могут быть прочитаны с помощью perf и других аналогичных инструментов. Вот, например, замер производительности всей системы в течении 10 секунд:
Ключевая метрика здесь это "количество инструкций за такт" (insns per cycle: IPC), которое показывает, сколько инструкций в среднем выполнил процессор на каждый свой такт. Упрощённо: чем больше это число, тем лучше. В примере выше это число равно 0.78, что, на первый взгляд кажется не таким уж плохим результатом (78% времени выполнялась полезная работа?). Но нет, на этом процессоре максимально возможным значением IPC могло бы быть 4.0 (это связано со способом получения и выполнения инструкций современными процессорами). То есть наше значение IPC (равное 0.78) составляет всего 19.5% от максимально возможной скорости выполнения инструкций. А в процессорах Intel начиная со Skylake максимальное значение IPC уже равно 5.0.
В облаках
Когда вы работаете в виртуальном окружении, то можете и не иметь доступа к реальным счетчикам производительности (это зависит от используемого гипервизора и его настроек). Вот статья о том, как это работает в Amazon EC2.
Изменчивость оценки
Из неопределенности единицы времени в понятии одноядерной производительности следует изменчивость, непостоянство оценки производительности на ядро. Какую единицу времени выбрали – такую оценку и получили. В противоположность IPC всегда константа, всегда постоянна для конкретного процессора.
IPC совершенно не зависит от других характеристик процессора, а производительность на ядро зависит.
реклама
Пусть X – время прохождения бенчмарка. Это время используется для оценки одноядерной производительности. При изменении тактовой частоты процессора изменяется и X – изменяется оценка производительности на ядро. Изменение тактовой частоты не затрагивает IPC, оно изменяет только число тактов. Число же операций в отдельно взятом такте (IPC) остается неизменным.
Читайте также: