
Jbd2 sda1 8 грузит диск
jbd2/md2-8 нагружает диск debian, как его нафиг выключить или ограничить?
Из-за него растет iowait la растет, сайт тормозит.
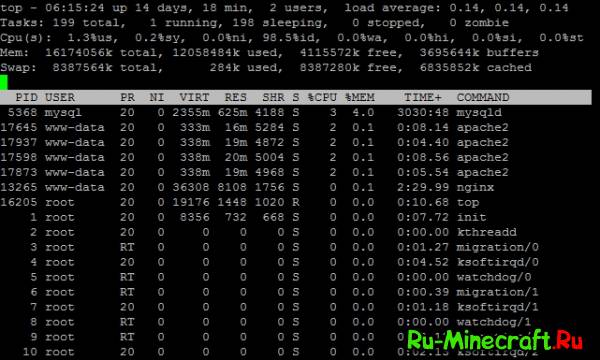
Вот такая картина:
smartctl --all /dev/sd* - вывод дисков.
south_park:
Простите но я нуб :(
jbd2/md2-8 нагружает диск debian, как его нафиг выключить или ограничить?
commit череват потерей данных.
Либо в данный момент идет синхронизация массива, либо он-то в порядке, но вы генерируете нагрузку на массив такую, что он вон полез в top .
В первом случае можно либо подождать, либо немного зажать скорость синхронизации:
Есть много IP-сетей в аренду под прокси, парсинг, рассылки (optin), vpn и хостинг. Телега: @contactroot ⚒ ContactRoot команда опытных сисадминов (/ru/forum/861038), свой LIR: сдаем в аренду сети IPv4/v6 (/ru/forum/1012475).
Glueon:
Либо в данный момент идет синхронизация массива, либо он-то в порядке, но вы генерируете нагрузку на массив такую, что он вон полез в top .
В первом случае можно либо подождать, либо немного зажать скорость синхронизации:
телепаты в отпуске, я для чего попросил данные ? что бы не гадать , давайте дождёмся а потом будем советы давать..
Ну и судя по наличию MySQL в io может имеет смысл вывод mysqltunner.pl посмотреть.
madoff:
телепаты в отпуске, я для чего попросил данные ? что бы не гадать , давайте дождёмся а потом будем советы давать..
Хоспади, ну ок. Я думал и так понятно, что действия надо предпринимать исходя из данных, которых мы ждем. :)
Glueon:
Ну и судя по наличию MySQL в io может имеет смысл вывод mysqltunner.pl посмотреть.
Хоспади, ну ок. Я думал и так понятно, что мы действия надо предпринимать исходя из данных, которых мы ждем. :)
mysql тут не причём. Вот именно надо ждать данные зачем гадать ? в этом направлении много проблем надо проверять..
Personalities : [raid1]
md3 : active raid1 sda4[0] sdb4[1]
1847608639 blocks super 1.2 [2/2] [UU]
md2 : active raid1 sda3[0] sdb3[1]
1073740664 blocks super 1.2 [2/2] [UU]
md1 : active raid1 sda2[0] sdb2[1]
524276 blocks super 1.2 [2/2] [UU]
md0 : active raid1 sda1[0] sdb1[1]
8387572 blocks super 1.2 [2/2] [UU]
Sep 7 14:38:38 r kernel: [68128.950531] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:38 t kernel: [68129.002805] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:38 rt kernel: [68129.070382] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:38 r kernel: [68129.070669] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:38 rt kernel: [68129.126637] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:38 rt kernel: [68129.154588] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 t kernel: [68129.221612] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 t kernel: [68129.271953] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rt kernel: [68129.272181] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rt kernel: [68129.330699] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rt kernel: [68129.381133] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rft kernel: [68129.448251] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rt kernel: [68129.515387] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 rt kernel: [68129.515665] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 t kernel: [68129.582641] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Sep 7 14:38:39 raft kernel: [68129.774748] EXT4-fs warning (device md2): ext4_dx_add_entry: Directory index full!
Я вчера сам уже похоже причину нашел. папка mod-tmp в ней 19+ миллионов файлов.
Поставил на удаление ночью, за 2 с небольшим часа удалило только 1.3 млн.
Прервал в 7 утра, с удалением сайт вообще еле работал, народ попрет, ушатает сервер в конец, этой ночью продолжу, а там видно будет.
В общем, откуда и что это за процесс, можно ли его выключить и не катастрофично ли будет это для системы?
Перемещено JB из talks



Ядрёный процесс. Журналирование.
Не знаете, а периодичность этого журналирования для конкретного раздела можно задать свою?
Вот у меня и загуглилось jbd"2", именно надо было и писать, а не jbd просто
Ребят, я тут подумал, раз уж такое нетихое журналирование идет и связанно оно по времени с размером раздела, как я понял, может тогда раздел из ext3 в ext2 переделать и хранить на нем информацию в какой-то мере не нужную или которою смогу восстановить, ну а на другом разделе с ext3/4 и хранить важные документы, коды и т.д.
что скажите, на счет ext2 именно интересно, как оно в деле, просто с рейзер (др. ФС) у меня ни раз был печальный опыт в сравнение с той же ext3, которая до сих пор крутится?

А не проще просто журнал в ext3/4 выключить?
В принципе проще. я пока что не нахожу как, может не то гуглю инфу по jbd2 пока что какую-то старую нашел, именно интересует, что в данный момент у меня включено, что бы это выключить.
--
На счет же ext2; Меня еще надежность интересует, что бы файлы не были битыми и т.д. от копирования/перемещения с раздела на раздел, можно на ext2 рассчитывать?
Также процесс md2_raid1 все время показывает 99% нагрузки на IO, хотя и нет чтения или записи: iotop показывает, что у него 99%, но чтение и запись = 0. Может быть, это так и нужно - я не очень разбираюсь в технологии.
Также часто поднимается процесс flush-9:2 - я так понимаю, он из этой же серии, он отнимает немало процессора.
Я так понимаю, по ссылке они решили вопрос увеличением времени сброса буферов, но и само решение не слишком безопасное, и для Debian'а оно не подходит.
Может ли в этом случае помочь переход на аппаратный RAID? Хотелось бы, конечно, найти способ настроить программный, чтобы не терять денег, но если другого выхода нет - будет ли эта потеря оправданной?
Писать безграмотно - значит посягать на время людей, к которым мы адресуемся, а потому совершенно недопустимо в правильно организованном обществе. © Щерба Л. В., 1957
при сбоях форума см.блог
Писать безграмотно - значит посягать на время людей, к которым мы адресуемся, а потому совершенно недопустимо в правильно организованном обществе. © Щерба Л. В., 1957
при сбоях форума см.блог
Да, используется ext4. Диски не SSD.
А может ли помочь в данном случае переход на аппаратный RAID?
Mirror
а вы рекомендации из приведённой ссылки опробовали?
Писать безграмотно - значит посягать на время людей, к которым мы адресуемся, а потому совершенно недопустимо в правильно организованном обществе. © Щерба Л. В., 1957
при сбоях форума см.блог
Mirror
а вы рекомендации из приведённой ссылки опробовали?
Я попробую рекомендации, которые были приведены по ссылке. Надеюсь, это поможет.
Что-то от выставление таких параметров не наблюдается улучшения. Часто jbd2/md2-8 занимает весь дисковый ввод-вывод, php-fpm зависает. При этом vmstat показывает большой процент на время, которое процессор ожидает завершения ввода-вывода. Таким образом, вопрос про аппаратный RAID становится особенно актуальным.
А кем/чем определено использование именно ext4 в Вашем конкретном случае?
Я могу Вам пообещать смоделировать ситуацию, подобную Вашей; но только не раньше выходных.
Чисто аппаратному RAID, IMHO, пофигу, какую файловую систему Вы будете наносить на раздел
устройства, сформированного из-под подобного контроллера.
Пока что, честно, я запамятовал, наносил ли я ext4 на LinuxRAID1.
ext4 поставили сотрудники хостинг-провайдера.
Спасибо за желание помочь )
Сейчас, могу сказать, ситуация стабилизировалась. Причем, решающую роль сыграло решение, которое, казалось бы, не должно было ее сыграть - связь для меня лично очень неявная. Мы отказались от использования APC Cache для кеширования переменных в PHP в пользу Memcache. И проблема с софтовым RAID'ом решилась.
Я даже не знаю, что предполагать. Можно было бы предположить какой-нибудь активный своппинг, но vmstat вроде бы показывал si=0, so=0. Но факт остается фактом - после отказа от APC проблема исчезла.
Детектировать медлительность APC удалось с помощью профайлера XHProf. Если когда-нибудь человечество столкнется с подобной проблемой - профилирование кода очень помогает.
Мне чертовски не достает квалификации до Вашей.
Я, безусловно, изучу Ваши изыскания, изложеннные в Вашем последнем посте;
только вот я не счел бы излишним изначально обкатывать серверные решения
в локальном варианте.
Это, конечно, верно, но в локальном варианте трудно создать такие же условия, как на основном сервере. Есть разные утилиты для нагрузочных тестов, но как правило они не способны создать нагрузку, сравнимую с реальной - из-за проблем с несколькими тысячами исходящих соединений с одного компьютера; еще с их помощью трудно тестировать запросы, изменяющие состояние сервера, особенно эмулировать много разных сессий.
А проблем с APC кешем я вообще не ожидал, и при тестировании они абсолютно не проявлялись - помогло только профилирование в реальных условиях.
Теперь будет опыт - использовании этого модуля для хранения переменных может вызвать проблемы, в то время как с Memcache проблем нет.
Я вот тут подцепил дополнительно к одной машине два SSD на фэйковый навесной контроллер
просто в режиме SATA Host Adapter, и сформировал на них LinuxRAID1; на котором разметил пару
разделов, на один из которых нанес ext4 под корень системы.
Ко второй машине я прилепил дополнительно два HDD на аппаратный RAID-контроллер LSI SAS 9260-8i,
на котором инициализировал виртуальный диск с RAID1, на котором тоже разметил пару разделов с нанесением ext4.
Так вот, после установки ОС что на одну, что на другую машину я не увидел никакой загрузки I/O дисковой подсистемы.
Естественно, я не запускал никаких серверных приложений (кроме sshd) и не имитировал массовые обращения к серверу.
Мне сдается, что само по себе обслуживание программнного RAID не есть первоопределяющая причина тормозов.
Я вот тут подцепил дополнительно к одной машине два SSD на фэйковый навесной контроллер
просто в режиме SATA Host Adapter, и сформировал на них LinuxRAID1; на котором разметил пару
разделов, на один из которых нанес ext4 под корень системы.
Ко второй машине я прилепил дополнительно два HDD на аппаратный RAID-контроллер LSI SAS 9260-8i,
на котором инициализировал виртуальный диск с RAID1, на котором тоже разметил пару разделов с нанесением ext4.
Так вот, после установки ОС что на одну, что на другую машину я не увидел никакой загрузки I/O дисковой подсистемы.
Естественно, я не запускал никаких серверных приложений (кроме sshd) и не имитировал массовые обращения к серверу.
Мне сдается, что само по себе обслуживание программнного RAID не есть первоопределяющая причина тормозов.
Ясно, спасибо. Мы тоже пришли к выводу, что первопричина не в софтовом RAID'е. После отказа от APC Cache все наладилось. Сейчас для кеширования байткода мы используем XCache, а для хранения переменных - Memcache.
Есть разные утилиты для нагрузочных тестов, но как правило они не способны
создать нагрузку, сравнимую с реальной - из-за проблем с несколькими тысячами
исходящих соединений с одного компьютера; еще с их помощью трудно тестировать
запросы, изменяющие состояние сервера, особенно эмулировать много разных сессий.
Мне трудно судить, для каких именно целей люди в том или ином случае хостятся,
но только если Вашей задачей является потенциально высокопосещаемый веб-ресурс;
лично мне было бы интересно потестить таковой (свой) ресурс изо-всех сил.
Есть ли в Вашем арсенале вещи типа ab, httperf или siege?
Я это спрашиваю лишь в плане "помощи клуба" и технического интереса.
Да, используем siege. Но с его помощью не получилось создать такую нагрузку, с которой мы столкнулись в итоге )
Я прошу прощения, что навещаю тему лишь наскоками; вот только создать нагрузку
на Ваш сервер не составляет никакого труда, раз уж Вы состоите в Сообществе
(только заявите). По Вашему сценарию (если захотите) Ваш сервер могут пробомбить
десять-двадцать-пятьдесят хостов с максимальным количеством коннектов. Мало ли
интересующихся. Заодно, посмотрим, насколько могуч Ваш хостинг-провайдер.
А там можно и анализировать нагрузку на дисковую подсистему.
Я прошу прощения, что навещаю тему лишь наскоками; вот только создать нагрузку
на Ваш сервер не составляет никакого труда, раз уж Вы состоите в Сообществе
(только заявите). По Вашему сценарию (если захотите) Ваш сервер могут пробомбить
десять-двадцать-пятьдесят хостов с максимальным количеством коннектов. Мало ли
интересующихся. Заодно, посмотрим, насколько могуч Ваш хостинг-провайдер.
А там можно и анализировать нагрузку на дисковую подсистему.
Да я тоже не слишком регулярно посещаю тему ))
Буду иметь в виду в другой раз ) Теперь-то нагрузка постоянная, можно ставить эксперименты, следить за эффектом.
i Уведомление от модератора перемещу в администрирования, оставив ссылку в debian.
т.к. дебиан-специфичного тут нет, а в адм. возможно кто-нибудь заинтересуется.
Солнце садилось в море, а люди с неоконченным высшим образованием выбегали оттуда, думая, что море закипит.
Данная статья никак не относится к Minecraft.
Сразу хочу сказать, что я нуб в администрировании серверов, но как следует из этой долгой истории данную проблему много кто не знает и не может быстро детектировать.
Уже оказывается долгое время наш сайт, а точнее сервер на котором он стоит преследует одна мелкая но пакостная проблема.
Все было давно, более года назад, этот сайт жил на vds (сервер с соседями) сервере колобриджа, система была дебиан или центос не помню точно.
Спустя какое то время сайт стал тормозить, просмотр top обнаружил высокий процент wa, (дисковая активность). (тогда я был совсем нуб нубом )
Простым языком все было нормально, но сервер не успевал читать и писать на диск информацию, отсюда шли тормоза.
Обвинив хостера и не добившись ничего от техподдержки(не детектировали проблему) я принял решение переезжать в хетзнер на свой сервер.
После переезда все было отлично, La - 0.2-0.5 и это при 40-60 тыс человек в день, я привык к дебиану и решил его использовать, ставил систему не сам, воспользовался ispmanager, панель сама все настроила, да и сама панель удобная. Все было в ажуре 4-5 месяцев, потом я заметил la 1-3 и временами 5, я не придал сильного значения, сайт не тормозил, спустя 1-2 недели la был уже 5-10 и временами 20, начались тормоза.
Изучение top опять детектировало высокую дисковую активность, вверху списка прыгал mysql, валил на него, крутил конфиги, безуспешно.
Тогда, я создал тему на форуме, и мне к сожалению не помогли, вызвался помочь человек с темой о администрировании серверов и многими отзывами.
Крутил сервер около 2 часов, настроил mysql, поставил прочую фигню и без которой все отлично работало.
Снизив на тот момент La с 15 до 7 (хотя он и так постоянно прыгал туда сюда).
При этом заметные тормоза сайта остались, этот недоадмин сказал что сервер слабый, винтам хана, давай мне мои заработанные 100$
Переехал на другую машину, аналогичную, проблема ушла, подумав на неисправность дисков (ведь хетзнер это лоухост) я забыл о сервере на 3 месяца.
И вот, настал тот миг, новый сервер, и снова проблема точь в точь.
Теперь я решил разбираться в сути проблемы, новая тема на форуме, и ура на форуме помогли, но еще раньше я сам случайно нашел проблему.
Долго курив интернет, поставив iotop я увидел злосчастный процесс jbd2/md2-8 который жрет всю дисковую активность(занимает диск).
Гуглив дальше узнал, что это журналирование файловой системы, и да оно бывает нагружает диск.
Начал курить как выключить жуналирование на debian, не нашел.
Обратился к системному администратору знакомого человека.
Он попытался ограничить данный журнал покрутив файл etc\fstab, проблема не ушла, человек сказал что винтам хана, переезжай скорее, хоть денег не взял.
Я уже был морально готов к очередной смене машины, но случайно зашел в заветную папку и понеслось.
Нашел ее случайно, ползал по папкам, заметил подозрительно много файлов и решил проверить.
Хотя ребята на форуме попросили вывод одной команды и когда я ее выполнил я бы тоже погуглив понял и нашел бы этот же источник гадости.
И так, проблема jbd2/md2-8 или дисковой активности, низкой производительности диска на debian является Directory index full.
Эта ошибка вызывается огромным количеством файлов в какой то директории, настолько огромным, что просто убивает диск нафиг, индексы кончаются журнал пишет о ошибках забивая дисковую активность.
Данная папка расположена в папке вашего пользователя и называется она mod-tmp, в ней хранятся временные файлы сессий(когда человек заходит на сайт, создается файл сессии), да да, "временные файлы" которые не хотят сами удаляться.
Это проблема Debian(возможно и других систем) установленного ispmanager, и она у многих, просто не у всех сайты с такой посещаемостью и чтоб накопить такое количество сессий необходимо 2-3 или более лет.
В моем случае в папке за 3 с небольшим месяца накопилось аж 19.4 миллиона файлов. с 6 утра и до 15.00 накопилось более 100 000 файлов, масштаб огромен.
Собственно необходимо удалить все файлы к чертям, но тут еще одна проблема, так просто не удалить, стандартные решения плохо работают и сильно нагружают диск, сайт лежит.
Теперь рекомендации как удалить много файлов из директории Debian не нагружая сервер
Все операции лучше проводить ночью, когда людей на ваших сайтах нет.
Начнем с подсчета количества файлов:
Данная операция может затянуться на 10-15 минут и положить сайты.
Как удалить относительно небольшое количество файлов:
Лично у меня производительность была выше, удаляет примерно 2.5 млн за 1 час. Удаляет папку, по этому надо переименовать текущую, а на ее место создать новую.
Если вы запустили удаление, сайт повис, а вам надо отменить удаление, включить top, дождитесь процесса find и посмотрите его pid, после чего введите kill и его pid.
Если у вас уже как у меня LA под 10 или 20, чтоб снять нагрузку, переименуйте папку, а на ее место создайте другую такую же, с такими же правами, мне помогло, нагрузка тут же упала.
Способ по удалению файлов который предложил человек с форума: Ссылка на его тему
Где /dir адрес директории (полный), а 0.5 длинна задержки, чем меньше тем быстрее идет удаление.
Что бы посмотреть работает ли команда и узнать Pid процесса для остановки вводим команду:
Вы увидите часть вашей команды.
Если ввести команду в putty она перестанет выполняться после закрытия соединения, я добавил команду в крон(планировщик задач), не знаю почему но когда запустил и проверил выполнение, там оказалось два процесса, я завершил один и оставил так на несколько дней. Крон поставил на выполнение раз в год, если я остановил процесс, то просто запускаю в ручную.
После ручного завершения процесса удаления(оценить сколько файлов удалило) через 2-3 дня, у меня несколько минут грузил сервер процесс ls, видимо обновлял список файлов, не знаю, но всегда лучше делать это ночью когда сервер не нагружен.
Мой сервер нормально работал с La 1-3, без видимых тормозов с задержкой 0.1, ночью иногда включал с задержкой 0.03, удаляет быстро, но днем не потянет.
Скорость удаления с задержкой 0.1 примерно 1 миллион файлов в сутки.
Теперь как предотвратить накопление файлов:
Главное, вам надо удалить все текущие файлы сессий перед данной процедурой, а иначе он начнет чистить и положит вам сервер, например у меня он положил бы часов на 10 не меньше.
Необходимо создать файл /etc/php5/conf.d/session-gc.ini с содержимым:
Перезагрузить apache.
Все, проблема решена, более сессии копиться не будут.

В Linux JBD - это независимый интерфейс журналирования блочных устройств в файловых системах ext3, ext4 и OCFS2 (Oracle Cluster File System). OCFS2 начиная с Linux 2.6.28, а также ext4 используют "форк" JBD известный как JBD2.
В показаниях top|iotop интерфейс журналирования блочных устройств JBD (Journaling Block Device) появляется в виде процесса под именем jbd2 или sda2-8, который проявляет активность по умолчанию с интервалом в 5 сек.:
jbd2 (sda2-8) часто обращается к диску для журналирования изменений и из-за того, что процесс jbd2 (sda2-8) постоянно дергает диск, многие предпочитают завышать параметр "commit=nrsec" в опциях монтирования файловой системы надеясь на прирост производительности.
Собственно в описаниях параметра и сказано " Setting it to very large values will improve performance. ", что установка очень больших значений позволит повысить производительность, но разумеется в ущерб производительности данных.
Но, не всё так просто, как может показаться на первый взгляд и для того чтобы точно знать какое именно значение " commit=nrsec " поможет увеличить производительность, мы должны чётко себе представлять как в Linux работает JBD (Journaling Block Device) интерфейс журналирования блочных устройств.
Какие данные журналирует JBD/JBD2
Официальная документация гласит:
Что в переводе означает:
- data=journal - В журнал заносятся все данные про изменения в файловой системе перед записью в главную файловую систему. Включение этого режима отключает "отложенное размещение" и поддержку O_DIRECT.
- data=ordered - Метаданные заносятся в журнал до записи в главную файловую систему с предварительной группированием метаданных и блоков данных в единое целое называемое транзакцией (transaction).
- data=writeback - Метаданные, без их группирования, заносятся в журнал после записи в главную файловую систему.
По факту режим data=journal является самым медленным, но существует мнение, что в отдельных тестах при одновременной записи и одновременном чтении, скорость чтения была выше чем при других режимах журналирования, и, что мол этот режим больше всего подходит там где часто выполняются одновременные чтение и запись - опять же, не факт.
Вполне возможно скорость чтения при data=journal будет чуть выше, чем скорость записи, но при условии если результат чтения не зависит от результата записи. Например чтение PHP скрипта, который обращается к БД с целью записи - в таком случае прирост скорости чтения нивелируется понижением скорости записи.
Опытным путём установлено, что для веб-сервера режим data=writeback является самым производительным.
Рекомендуемый контент
Вы не любите рекламу!? Напрасно!:) На нашем сайте она вовсе ненавязчивая, а потому для нашего сайта можете полностью отключить AdBlock (uBlock/uBlock Origin/NoScript) и прочие блокировщики рекламы! AdBlock/uBlock может препятствовать нормальной работе системы поиска по сайту, отображению рекомендуемого контента и прочих сервисов Google. Рекомендуем полностью отключить блокировщик рекламы и скриптов, а также разрешить фреймы (aka iframe).
Меня нет ни в Инстаграмме ни в Фейсбуке, я просто хожу по улицам и рассказываю первым встречным: сколько зарабатываю; с кем дружу; где живу и чем дышу. У меня даже появилось несколько подписчиков: ПСИХоЛОХ и участковый полицай!
Комментарии
Хочу поинтересоваться, использовал ли уважаемый автор опцию "-o discard" на практике? Если да, не замечал ли каких-либо побочных эффектов?
Команда TRIM (aka '-o discard') информирует SSD, что конкретные (принадлежащие к удалению файлы) блоки диска более не используются и потому могут быть стёрты и вновь использованы. Без discard скорость диска SSD со временем понижается и ухудшается равномерное использование ячеек при помощи алгоритмов SSD контроллера.
- Применение discard для корневого раздела на SSD с ФС ext3 может привести к тому, что он будет смонтирован в read-only.
- Перед монтированием раздела с флагом discard стоит убедится, что SSD поддерживает TRIM/discard/fstrim, иначе можно потерять данные!
The file system will be mounted with the discard mount option. This will cause the file system driver to attempt to use the trim/discard feature of some storage devices (such as SSD’s and thin-provi-sioned drives available in some enterprise storage arrays) to inform the storage device that blocks belonging to deleted files can be reused for other purposes. (This option is currently only supported by the ext4 file system driver in 2.6.35+ kernels.)
Файловая система будет смонтирована с опцией диска discard. Это приведет к тому, что драйвер файловой системы попытается использовать функцию обрезки/сброса на некоторых устройствах хранения (таких как SSD и тонкопрофильные диски, доступные в некоторых корпоративных массивах хранения), чтобы сообщить устройству хранения, которое блокирует принадлежащие к удалению файлы, что они могут быть повторно использован/стёрты/уничтожены для других целей. (Эта опция поддерживается только драйвером файловой системы ext4 в ядрах 2.6.35+.)
Хочу поинтересоватьс я, использовал ли уважаемый автор опцию "-o discard" на практике? Если да, не замечал ли каких-либо побочных эффектов?
Commit в JBD/JBD2
Как JBD (JBD2) совершает запись в журнал? Журналирование транзакции представляет собой процесс регистрации одного или нескольких атомарных операций файловой системы в журнале на диске. Только после успешного совершения (Commit) транзакции (transaction), операция может считаться полной и гарантируется, что даже в случае краха, эти операции смогут быть восстановлены файловой системой.
Commit выполняется в 8 основных этапов. Основной функцией, которая совершает Commit-ы является journal_commit_transaction(). Когда пришло время добавить данные в журнал, журнал уже находится в рабочем состоянии (T_RUNNING), в момент же совершения записи статус изменяется на T_LOCKED, а все новые потоки данных переходят в режим ожидания до завершения уже начатой транзакции.
В момент завершения транзакции предпринимаются попытки очистить все буферы, принадлежащие зарезервированным спискам (t_reserved_list), а также освободить память, избавившись от буферов сидя на списке контрольных точек (t_checkpoint_list). Интервал Commit-ов регулируется параметром "commit=nrsec".
Как оптимизировать работу Journaling Block Device
Самым популярным способом оптимизации JBD (JBD2) является параметр commit=nrsec, установка которого в очень высокие значения может улучшить производительность - это даже согласно оф. документации. Но это не тот случай, когда " кашу маслом не испортишь "!
Прежде чем шаманить параметрами файловой системы, нужно взять во внимание общее состояние системы, т.е. как минимум знать общий объём физической (оперативной) памяти и скорость доступа к диску.
Например, мы знаем, что между commit-ами JBD/JBD2 хранит данные о изменении ФС в памяти (в буферах, кэше), а значит:
- При завышенных значениях параметра commit=nrsec объём данных накапливаемых между длинными commit-ами будет значительно выше, чем между короткими промежутками;
- Большие порции данных при длинных commit-ах будут записываться на жесткий диск дольше, вызывая при этом ощутимый интервал I/O Wait если скорость доступа к диску относительно мала;
- Затяжной commit отнимет больше памяти, чем короткий.
Следовательно, если у нас слабый диск, мало РАМы, и, мы хотим избежать длительного I/O Wait при "коммитах", то не стоит устанавливать очень большие значения для commit=nrsec.
Хорошим ходом к оптимизации будет понижение I/O приоритета на commit операции:
По умолчанию journal_ioprio=3 , большее значение понижает приоритет:
Не лишними также будут и следующие параметры (нет времени на перевод, переводите сами;-):
Ну, и разумеется смена режима журналирования на writeback, удаление некоторых излишних функций, а также финальная правка /etc/fstab:
При использовании твердотельных SSD (solid-state drive) накопителей ещё можно применить " tune2fs -o discard /dev/sda1 ".
А раз уж мы затронули тему оптимизации, то ещё вскользь упомянём и про такие навязчивые процессы как kswapd0 и pdflush (ещё ака flush-8:0):
Читайте также:
- Пример текстового процессора укажите правильный вариант ответа word блокнот paint excel
- Какой блок питания нужен для i7 10700k
- Жесткий диск a data nobility nh13 не видит компьютер
- Как звучит процессор line 6 hx stomp и как настроить на рок н ролл
- Как сочетается процессор с другими частями компьютера