
Горячая замена диска raid
В: Что такое RAID и зачем он нужен? Какой RAID лучше использовать?
О: Ответу на этот вопрос посвящен раздел [ RAID ].
В: Можно ли использовать в RAID массиве диски разного размера?
О: Да. можно. Но, при этом, используемая емкость у ВСЕХ дисков будет равна емкости наименьшего диска.
Из этого следует, что добавлять в уже существующий RAID массив можно только диски такого же или большего размера.
В: Можно ли использовать в RAID массиве диски разных производителей?
О: Да, можно. Но при этом надо иметь ввиду, что точные размеры дисков одинаковой емкости (36/73/146. ГБ) у разных производителей могут отличаться на несколько килобайт. Когда вы создаете новый RAID массив, на это можно не обращать внимание, но если вы добавляете диски к уже существующему массиву (например, меняете вышедший из строя диск), то важно, чтобы новый диск был больше чем старые, или точно такого же размера.
В: Что такое Write Through и Write Back?
О: Это способ записи данных, полученных RAID контроллером, на дисковый массив. По другому эти способы еще называются так: прямая запись ( Write Through ) и отложенная запись ( Write Back ). Какой из этих способов будет использоваться определяется в BIOS-е контроллера (либо при создании массива, либо позднее).
- Write Through - данные записываются непосредственно на дисковый массив. Т.е. как только данные получены, они сразу же записываются на диски и после этого контроллер подает сигнал управляющей ОС о завершении операции.
- Write Back - данные записываются сначала в кэш , и только потом (либо по мере заполнения кэш -а, либо в моменты минимальной загрузки дисковой системы) из кэш -а на диски. При этом, сигнал о завершении операции записи передается управляющей ОС сразу же по получении данных кэш -ем контроллера.
Избежать описанной проблемы можно или с помощью установки на RAID контроллер BBU (см. ниже), или посредством подключения всего сервера через источник бесперебойного питания (UPS) с функцией программируемого выключения.
Кстати, некоторые RAID контроллеры не позволяют включить функцию Write Back без установленного BBU .
В: Что такое BBU и зачем он нужен?
О: BBU (Battery Backup Unit ) необходим для предотвращения потери данных находящихся в кэш -е RAID контроллера и еще не записанных на диск (отложенная запись - "write-back caching"), в случае аварийного выключения компьютерной системы.
Существуют три разновидности BBU :
- Просто BBU : это аккумулятор, который обеспечивает резервное питание кэша через RAID контроллер.
- Переносимые (Transportable) BBU (tBBU): это аккумулятор, который размещен непосредственно на модуле кэш и питает его независимо от RAID контроллера. В случае выхода из строя RAID контроллера, это позволяет перенести данные, сохраненные в кэш -е, на резервный контроллер и уже на нем завершить операцию записи данных. : основная идея заключается в следующем: в случае сбоя питания RAID контроллер копирует содержимое кэш -а в энергонезависимую память (например, в случае с технологией Adaptec »Zero-Maintenance Cache Protection - на NAND флэш накопитель). Питание, необходимое для завершения этого процесса, обеспечивается встроенным супер-конденсатором. После восстановления питания, данные из флэш памяти копируются обратно в кэш контроллера.
В: Что такое Hot Spare (Hotspare)?
О: Hot Spare - (Резервная Замена Дисководов ("Горячее резервирование")) - Одна из наиболее важных особенностей, которую обеспечивает RAID контроллер, с целью достичь безостановочное обслуживание с высокой степенью отказоустойчивости. В случае выхода из строя диска, восстанавливающая операция будет выполнена RAID контроллером автоматически, если выполняются оба из следующих условий:
- Имеется "резервный" диск идентичного объема, подключенный к тому же контроллеру и назначенный в качестве резервного, именно он и называется Hotspare ;
- Отказавший диск входит в состав избыточной дисковой системы, например RAID 1 , RAID 3 , RAID 5 или RAID 0+1 .
Обратите внимание: резервирование позволяет восстановить данные, находившиеся на неисправном диске, если все диски подключены к одному и тому же RAID контроллеру.
"Резервный" диск может быть создан одним из двух способов:
- Когда пользователь выполняет утилиту разметки, все диски, которые подключены к контроллеру, но не сконфигурированы в любую из групп дисководов, будут автоматически помечены как "резервные" ( Hotspare ) диски (автоматический способ поддерживается далеко не всеми контроллерами).
- Диск может также быть помечен как резервный ( Hotspare ), при помощи соответствующей утилиты RAID контроллера.
В течение процесса автоматического восстановления система продолжает нормально функционировать, однако производительность системы может слегка ухудшиться.
Для того, что бы использовать восстанавливающую особенность резервирования, Вы должны всегда иметь резервный диск ( Hotspare ) в вашей системе. В случае сбоя дисковода, резервный дисковод автоматически заменит неисправный диск, и данные будут восстановлены. После этого, системный администратор может отключить и удалить неисправный диск, заменить его новым диском и сделать этот новый диск резервным.
В этом разделе использованы материалы с сайта "3dnews".
В: Что такое Copyback Hot Spare?
О: Copyback Hot Spare это функция RAID контроллера, которая позволяет пользователям закрепить физическое расположение диска "горячего резерва" ( Hot Spare ), что позволяет улучшить управляемость системы.
В: Что такое JBOD?
О: JBOD (Just a Bunch of Disks) это способ подключить диски к RAID контроллеру не создавая на них никакого RAID . Каждый из дисков доступен так же, как если бы он был подключен к обычному адаптеру. Эта конфигурация применяется когда необходимо иметь несколько независимых дисков, но не обеспечивает ни повышения скорости, ни отказоустойчивости.
В: Что такое размер страйпа (stripe size)?
О: размер страйпа ( stripe size ) определяет объем данных записываемых за одну операцию ввода/вывода. размер страйпа задается в момент конфигурирования RAID массива и не может быть изменен позднее без переинициализации всего массива. Больший размер страйпа обеспечивает прирост производительности при работе с большими последовательными файлами (например, видео), меньший - обеспечивает большую эффективность в случае работы с большим количеством небольших файлов.
В: Нужно ли заниматься архивированием данных в случае использования RAID?
О: Конечно да! RAID это вовсе не замена архивированию, основное его назначение это повышение скорости и надежности доступа к данным в нормальном режиме работы. Но только регулярное архивирование данных гарантировано обеспечит их сохранность при любых отказах оборудования, пожарах, потопах и прочих неприятностях.
Решил написать эту статью после знакомства с публикацией «HP, Dell и IBM: компоненты, отвечающие за надёжность сервера», поскольку имею другое мнение насчёт некоторых моментов. Эта статья не претендует на инновационные подходы, а просто описывает полученный опыт и, надеюсь, предотвратит банальные ошибки.
Итак, начнём с того, что попробуем выяснить, зачем бесперебойность и беспрерывность серверам? Собственно, серверам бесперебойность не обязательна, но она нужна сервисам, которые предоставляют эти сервера. Наилучшая беспрерывность обеспечивается только распределёнными системами, которые могут функционировать независимо друг от друга с автоматическим переключением между ними (для скорости) и разнесённые географически (катастрофоустойчивость). Но это выдвигает особые (не всегда реализуемые) требования к программному обеспечению. Недостатками таких решений являются повышеная стоимость, проблемы с репликацией данных, передача состояния для бесшовного переключения на резервную систему. Дополнительными плюсами является то, что при правильной реализации системы, возможно повышение быстродействия — клиенты делятся между двумя или более локациями, а при сбое перераспределяются.
Но есть задачи, настолько критичные и специфические, что требуют особой бесперебойности серверов, для них делают особые сервера, например менфреймы, с возможностью горячей замены всех компонентов, включая процессоры, память и даже материнские платы. Но такие решения стоят гораздо дороже обычных серверов и те кто их покупает — понимаю зачем это надо.
Вернёмся к серверам начального и среднего уровней. Существенно повышает беспрерывность работы серверов возможность горячей замены компонентов.
Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Что такое Write Through и Write Back?
Это способ записи данных, полученных RAID контроллером, на дисковый массив. По другому эти способы еще называются так: прямая запись (Write Through) и отложенная запись (Write Back). Какой из этих способов будет использоваться определяется в BIOS-е контроллера (либо при создании массива, либо позднее).
- Write Through - данные записываются непосредственно на дисковый массив. Т.е. как только данные получены, они сразу же записываются на диски и после этого контроллер подает сигнал управляющей ОС о завершении операции.
- Write Back - данные записываются сначала в кэш, и только потом (либо по мере заполнения кэш-а, либо в моменты минимальной загрузки дисковой системы) из кэш-а на диски. При этом, сигнал о завершении операции записи передается управляющей ОС сразу же по получении данных кэш-ем контроллера.
Избежать описанной проблемы можно или с помощью установки на RAID контроллер BBU (см. ниже), или посредством подключения всего сервера через источник бесперебойного питания (UPS) с функцией программируемого выключения.
Кстати, некоторые RAID контроллеры не позволяют включить функцию Write Back без установленного BBU.
Можно ли использовать в RAID массиве диски разного размера?
Да. можно. Но, при этом, используемая емкость у ВСЕХ дисков будет равна емкости наименьшего диска.
Из этого следует, что добавлять в уже существующий RAID массив можно только диски такого же или большего размера
Как начинается процесс восстановления поврежденного диска RAID
Если у вас в системе есть назначенные Global Hot Spare и Dedicated Hot Spare и они полностью отвечает требованиям восстановления поврежденного диска RAID, восстановление начнется автоматически. Hot Spare диски должны быть запланированы до начала восстановления и должны соответствовать всем требованиям для виртуального диска. Если вы удалите виртуальный диск, то Dedicated Hot Spare станет Global Hot Spare.

Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Что такое Hotswap?
Что такое RAID и зачем он нужен?
Акроним RAID (Reudant Array of Independed Disks) избыточный массив независимых дисков, впервые был использован в 1988 году исследователями из института Беркли Паттерсоном (Patterson), Гибсоном (Gibson) и Кацем (Katz). Они описали конфигурацию массива из нескольких недорогих дисков, обеспечивающих высокие показатели по отказоустойчивости и производительности.
Наиболее "слабой" в смысле отказоустойчивости частью компьютерных систем всегда являлись жесткие диски, поскольку они, чуть ли не единственные из составляющих компьютера, имеют механические части. Данные записанные на жесткий диск доступны только пока доступен жесткий диск, и вопрос заключается не в том, откажет ли этот жесткий диск когда-нибудь, а в том, когда он откажет.
RAID обеспечивает метод доступа к нескольким жестким дискам, как если бы имелся один большой диск (SLED - single large expensive disk), распределяя информацию и доступ к ней по нескольким дискам, обеспечивая снижение риска потери данных, в случае отказа одного из винчестеров, и увеличивая скорость доступа к ним.
Обычно RAID используется в больших файл серверах или серверах приложений, когда важна, высока скорость и надежность доступа к данным. Сегодня RAID находит применение так же в настольных системах, работающих с CAD, мультимедийными задачами и когда требуется обеспечить высокую производительность дисковой системы.
Можно ли использовать в RAID массиве диски разных производителей?
Да, можно. Но при этом надо иметь ввиду, что точные размеры дисков одинаковой емкости (36/73/146. ГБ) у разных производителей могут отличаться на несколько килобайт. Когда вы создаете новый RAID массив, на это можно не обращать внимание, но если вы добавляете диски к уже существующему массиву (например, меняете вышедший из строя диск), то важно, чтобы новый диск был больше чем старые, или точно такого же размера.
Что такое Hot Spare (Hotspare)?
Hot Spare - (Резервная Замена Дисководов ("Горячее резервирование")) - Одна из наиболее важных особенностей, которую обеспечивает RAID контроллер, с целью достичь безостановочное обслуживание с высокой степенью отказоустойчивости. В случае выхода из строя диска, восстанавливающая операция будет выполнена RAID контроллером автоматически, если выполняются оба из следующих условий:
- Имеется "резервный" диск идентичного объема, подключенный к тому же контроллеру и назначенный в качестве резервного, именно он и называется Hotspare ;
- Отказавший диск входит в состав избыточной дисковой системы, например RAID 1, RAID 3, RAID 5 или RAID 0+1.
Обратите внимание: резервирование позволяет восстановить данные, находившиеся на неисправном диске, если все диски подключены к одному и тому же RAID контроллеру.
"Резервный" диск может быть создан одним из двух способов:
- Когда пользователь выполняет утилиту разметки, все диски, которые подключены к контроллеру, но не сконфигурированы в любую из групп дисководов, будут автоматически помечены как "резервные" ( Hotspare ) диски (автоматический способ поддерживается далеко не всеми контроллерами).
- Диск может также быть помечен как резервный ( Hotspare ), при помощи соответствующей утилиты RAID контроллера.
В течение процесса автоматического восстановления система продолжает нормально функционировать, однако производительность системы может слегка ухудшиться.
Для того, что бы использовать восстанавливающую особенность резервирования, Вы должны всегда иметь резервный диск ( Hotspare ) в вашей системе. В случае сбоя дисковода, резервный дисковод автоматически заменит неисправный диск, и данные будут восстановлены. После этого, системный администратор может отключить и удалить неисправный диск, заменить его новым диском и сделать этот новый диск резервным.
Горячая замена дисков
Горячую замену дисков можно производить практически со всеми вариантами интерфейсов. Конечно, есть и некоторые ограничения.
IDE устройства редко переносят отключение/подключение второго устройства на шлейф — велик риск пропадания работающего устройства из системы. Главная проблема интерфейса IDE в правильной обработке операционной системой этого события. Так как интерфейс IDE не предусматривает горячей замены, в большинстве случаев необходимо вручную запустить сканирование устройств для определения нового оборудования. Важный момент — интерфейс подключается/отключается к обесточенному диску (подключение: сначала интерфейс, потом питание, отключение: сначала питание, потом интерфейс).
ОТКАЗ ОТ ОБЯЗАТЕЛЬСТВ: выполняя отключение/подключение устройств IDE Вы делаете это на свой страх и риск — никто не гарантирует сохранение работоспособности оборудования, и стабильность работы ОС.
Интерфейсы FC, SAS, SATA (AHCI) — поддерживают горячую замену дисков в полном объеме, проблемы могут быть в операционной системе. Если дисковый контроллер SATA находится в режиме совместимости IDE — то, возможно, понадобится вручную запустить сканирование шины. В режиме AHCI в большинстве случаев диск определится автоматически. Рекомендую использовать AHCI, если ваша ОС это позволяет, т.к. этот режим также повышает производительнось диска; TRIM поддерживается только в этом режиме работы контроллера.
При отключении дисков для продления срока их службы рекомендую предварительно отключать их программным методом и извлекать после остановки шпинделя, т.е. через примерно 30 секунд после выключения для дисков 7200RPM. Если диск невозможно отключить программно и он установлен в hot-swap корзинке, рекомендую вытащить диск на минимальное расстояние, при котором диск будет отключен, подождать остановки шпинделя и извлечь окончательно. В большинстве систем — это расстояние полностью отведённой ручки корзинки. Конечно, эти действия не несут практического смысла, если диск вышел из строя, но, возможно, он просто «завис» и вам не поменяют его по гарантии и придется использовать в некритичном оборудовании.
Так же важно понимать, что диск находится в составе RAID или как отдельное блочное устройство. При использовании отдельного диска необходимо предварительно его отмонтировать для избежания сбоев в работе ОС и программного обеспечения. Даже если диск не используется в текущий момент, после извлечения примонтированого диска зачастую наблюдаются лаги всей ОС. Конечно же, диск, на котором установлена ОС, извлечь без «зависания» не получится.
Большинство серверов позволяет подсветить индикатором диск по команде с сервера, по возможности пользуйтесь этой функцией, для минимизации ошибочных извлечений дисков. Например на серверах SuperMicro номер корзинки указан на самой корзинке, и может не совпадать с номером слота на бэкплейне. Такая-же проблема есть у многих производителей.
Так же перед отключением желательно получить информацию о диске (модель, объем, серийный номер) для сопоставления сразу после извлечения диска. Во многих случаях при ошибочном извлечении другого диска это позволит устранить ошибку сразу, а иногда даже предотвратить сбой в работе или потерю данных.
В случае использования RAID-массивов, рекомендую отключать диски программно (помечать как сбойные), перед извлечением это устранит снижение производительности дисковой системы сразу после отключения диска.
Проблем с SSD дисками при частом горячем подключении/извлечении не заметил, хотя использовал несколько именно в таком режиме.
На этом первая часть заканчивается, в следующей частях про RAID массивы, память для серверов, системы удалённого управления и про важность мониторинга.
Я обнаружил, что в интернете очень мало (и не очень внятно) объяснено, как mdadm работает с общими (глобальными) дисками горячей подмены. В заметке я опишу, что это такое, и объясню, почему shared hotspare не отмечены в /proc/mdstat как общие, а вместо этого выглядят как вполне себе локальные.
(Я пишу не для новичков, так что галопом по европам)
Если массив обладает избыточностью и один из его дисков вышел из строя, то существует возможность восстановить избыточную информацию на резервный диск. Если диск добавляется в массив руками (админу пришло письмо о сбое, он прочитал письмо, проснулся/оделся, приехал на работу, вынул сбойный диск, вставил запасной, добавил его в массив, дал команду на восстановление избыточности), то такой диск называется cold-spare. Просто «запасной диск».
Если же в сервере есть простаивающий диск, на который осуществляется восстановление избыточности сразу после сбоя любого из дисков массива, то такой диск называется hot-spare. Главное достоинство — оно отребилдится (восстановит избыточность) даже если админ письмо прозевал или не успел вовремя приехать.
Обычно запасной диск добавляется для массива, то есть если в массиве сбой, то его резервный диск и используется. Если сбой происходит в соседнем массиве, то hot-spare из «чужого» массива не используется.
Это на самом деле логично — если у нас стоит выбор — использовать hot-spare для восстановления избыточности системного раздела или раздела с данными, то надо восстанавливать избыточность раздела с данными. А если системный раздел уже «занял» hot-spare, то будет бяка. Более того, некоторые производители предлагают 1EE hotspare, в которой резервный диск используется и для хранения данных (пустое место «размазано» между дисками массива, обеспечивая возможность быстрого ребилда и увеличивая производительность в нормальном режиме).
Однако, бывает так, что массивов с данными много. И им всем нужны hot-spare диски. Но дисков жалко. И тогда возникает желание иметь «общий» диск, который может быть использован для любого из массивов (а ещё лучше 2-3 таких диска).
Это было вступление. Теперь переходим к сути вопроса.
mdadm (ядерный модуль в DM-стеке) не поддерживает shared hot-spare. Диск может быть добавлен как hot-spare только в конкретный массив.
Именно так. mdadm поддерживает, ядерный модуль — нет. Mdadm реализует общий hot-spare методом «перекинуть hotspare с одного массива на другой, повреждённый».
Для возможности распределять диски между разными массивами есть понятие spare-group, то есть группа, в пределах которой возможно перекидывание дисков. Таких групп может быть много — и hot-spare переносятся только между ними.
Как легко понять из вышенаписанного про mdadm/linux md, в /proc/mdstat нет и не может быть ничего про spare-group. Потому что это личные мысли и соображения mdadm'а, а ядро про это ни сном, ни духом (файлы-то в /proc создаются модулями ядра. ).
Таким образом, обеспечивать shared hot-spare можно только с с помощью mdadm. Тут два варианта: если группа указана для массива, собирающегося при загрузке (/etc/mdadm/mdadm.conf), то там можно указать hot-spare, примерно так:
ARRAY /dev/md1 level=raid1 num-devices=2 metadata=1.2 spares=1 spare-group=myhostparegroupname name=server:1 UUID=18219495:03fda335:3f1ad1ee:a5f5cd44
devices=/dev/sda,/dev/sdb,/dev/sdc
ARRAY /dev/md2 level=raid1 num-devices=2 metadata=1.2 spare-group=myhostparegroupname name=server:2 UUID=18219495:03fda335:3f1ad1ee:a5f5cd45
devices=/dev/sdd,/dev/sde
(сразу отвечаю на вопрос, где столько умных слов взять — mdadm --detail --scan --verbose )
Дописано по сравнению с выводом mdadm тут только spare-group. Обратите внимание — во втором массиве НЕТ hot-spare, однако, т.к. группа указана, то в случае сбоя будет использоваться диск из другого массива с той же самой группой. В нашем случае это будет /dev/md1.
Разумеется, всё это произойдёт, только если у нас есть запущенный в режиме -F mdadm. В debian он в выводе ps выглядит так:
Самих групп при этом на одной системе может быть несколько.
Кстати, тут есть мелкая гадость: при вызове mdadm с --detail упоминания о spare-groups не будет, их нужно будет дописывать самим.
А вот тут, увы, йок. Насколько я знаю, mdadm не поддерживает одновременно и локальные (которые будут принадлежать только одному массиву) и общие hotspare. Если есть два массива с одним spare-group, то все hot-spare из одного массива могут быть использованы на благо другого.
Сценарий не такой редкий, как кажется. Вот простенькая топология:
SYS_ARRAY
DATA_ARRAY
2 hot-spare
Логично было бы один hot-spare сделать принадлежащим только DATA_ARRAY, а второй сделать общим, чтобы использовался и как резерв для SYS_ARRAY, и как «второй уровень резерва» для DATA_ARRAY.
Увы, увы, увы, этого нет (если меня разубедят в комментариях, я буду очень рад).
Что применяется первым из Global Hot Spare и Dedicated Hot Spare
Предположим, что у вас есть два виртуальных диска, для каждого из них есть по одному Dedicated Hot Spare и два общих Global Hot Spare, если выходит из строя один из дисков виртуального массива, вопрос, куда буду переноситься данные? Правильный ответ:
- В первую очередь будет использован "Выделенный горячий резерв (Dedicated Hot Spare)"
- Потом уже будет использоваться глобальный диск резервного назначения (Global Hot Spare)
Что такое размер страйпа (stripe size)?
размер страйпа (stripe size) определяет объем данных записываемых за одну операцию ввода/вывода. размер страйпа задается в момент конфигурирования RAID массива и не может быть изменен позднее без переинициализации всего массива. Больший размер страйпа обеспечивает прирост производительности при работе с большими последовательными файлами (например, видео), меньший - обеспечивает большую эффективность в случае работы с большим количеством небольших файлов.
Что такое BBU и зачем он нужен?
BBU (Battery Backup Unit) необходим для предотвращения потери данных находящихся в кэш-е RAID контроллера и еще не записанных на диск (отложенная запись - "write-back caching"), в случае аварийного выключения компьютерной системы.
Существуют три разновидности BBU:
- Просто BBU: это аккумулятор, который обеспечивает резервное питание кэша через RAID контроллер.
- Переносимые (Transportable) BBU (tBBU): это аккумулятор, который размещен непосредственно на модуле кэш и питает его независимо от RAID контроллера. В случае выхода из строя RAID контроллера, это позволяет перенести данные, сохраненные вкэш-е, на резервный контроллер и уже на нем завершить операцию записи данных.
- Flash BBU: основная идея заключается в следующем: в случае сбоя питания RAID контроллер копирует содержимое кэш-а в энергонезависимую память (например, в случае с технологией Adaptec » Zero-Maintenance Cache Protection - на NAND флэш накопитель). Питание, необходимое для завершения этого процесса, обеспечивается встроенным супер-конденсатором. После восстановления питания, данные из флэш памяти копируются обратно в кэш контроллера.
Что такое Copyback Hot Spare?
Copyback Hot Spare это функция RAID контроллера, которая позволяет пользователям закрепить физическое расположение диска "горячего резерва" (Hot Spare), что позволяет улучшить управляемость системы.
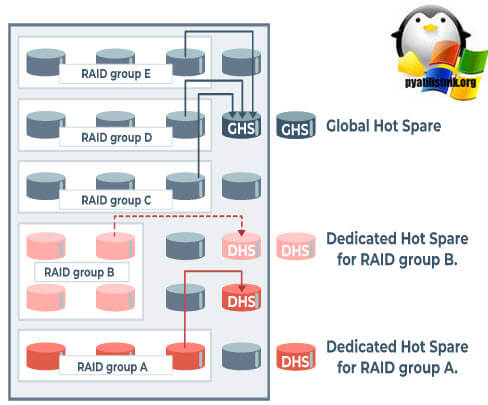
Что такое Global Hot Spare и Dedicated Hot Spare
Если вы хоть раз настраивали сервер, то наверняка задавались вопросом его отказоустойчивости, которая может быть на разных уровнях, например два блока питания или дисковая подсистема, которая для сервера очень важна. Потеря данных просто неприемлема в современной модели бизнеса. Для этого существует технология RAID, где за счет избыточности достигается некий баланс безопасности и денег.
Существует много видов RAID массивов и у каждого свое количество дисков которое может выйти, прежде чем весь массив развалится. Для дополнительной защиты принято выделять один или несколько запасных дисков горячей замены, которые должны успеть подменить выходящий из строя диск, до момента его замены. Существует два вида дисков горячей замены, это Global Hot Spare и Dedicated Hot Spare.
Global Hot Spare - Глобальный диск горячего резервирования позволяет не потерять данные при выходе из строя одного из дисков массива. Это неиспользуемый резервный диск в группе дисков. Данный диск находятся в режиме ожидания и будет активирован на любом из виртуальных дисков, когда возникает сбой физического или повреждение диска, на то он и глобальный. Диск горячего резервирования автоматически активируется только в случае повреждения диска массива. Когда диск горячего резерва активирован, он восстанавливает данные для всех резервных виртуальных дисков, в которых использовался неисправный физический диск. Затем, после замены диска, данные отправляются обратно на новый диск с резервного диска. Следует помнить, что Global Hot Spare диск и физический диск массива должны использовать одну и ту же дисковую технологию и размер (размер может быть больше, но не меньше).
Dedicated Hot Spare - В ыделенный горячий резервный диск - это диск "горячего" резерва, который может использоваться только для одного резервного виртуального диска. Также возможно назначить выделенный Dedicated Hot Spare для защиты более чем одного логического диска; это называется резервным пулом (pool reserve). Прежде чем вы сможете назначить выделенный резервный диск для защиты массива, вы должны создать логический диск.
Из схемы видно, что выделенные диски будут являться резервными только для группы A и B, а вот глобальный Hot Spare для всех массивов.
Что такое JBOD?
JBOD (Just a Bunch of Disks) это способ подключить диски к RAID контроллеру не создавая на них никакого RAID. Каждый из дисков доступен так же, как если бы он был подключен к обычному адаптеру. Эта конфигурация применяется когда необходимо иметь несколько независимых дисков, но не обеспечивает ни повышения скорости, ни отказоустойчивости.
Нужно ли заниматься архивированием данных в случае использования RAID?
О: Конечно да! RAID это вовсе не замена архивированию, основное его назначение это повышение скорости и надежности доступа к данным в нормальном режиме работы. Но только регулярное архивирование данных гарантировано обеспечит их сохранность при любых отказах оборудования, пожарах, потопах и прочих неприятностях.
Читайте также: