
Fma это в процессоре
В популярных публикациях много слов о «глубоком обучении», причем, с появлением каждого нового функционального расширения, формулировки повторяются снова и снова. Видимо, каждый раз обучение становится еще более глубоким. Между тем, обратившись к документации (и позвав на помощь эмулятор Intel SDE), нетрудно убедиться, что составными частями для реализации технологий со столь замысловатыми названиями являются операции линейной алгебры: последовательности умножений и сложений.
С целью оптимизации машинного кода, необходимого для реализации алгоритмов линейной алгебры, в частности, — обработки векторов и матриц, разработано семейство функциональных расширений FMA (Fused Multiply and Add). Именно их применение позволяет комбинировать в одной процессорной инструкции арифметические действия умножения и сложения. Заметим, что FMA инструкции оперируют числами с плавающей точкой, в то время как функциональное расширение VNNI (Vector Neural Network Instructions) используется для обработки целочисленных операндов.

Блок-схема выполнения векторной операции Fused Multiply and Add
Дополнительным плюсом FMA является улучшение точности вычислений, поскольку при выполнении нескольких последовательных арифметических операций одной инструкцией округлению подвергается только окончательный результат, в то время как при использовании умножений и сложений отдельными инструкциями, потеря точности имеет место после каждого действия.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Экспериментаторам на заметку
Мнение, согласно которому четырехоперандные FMA-инструкции являются непозволительной роскошью, как правило, ассоциируют с политикой Intel, «репрессировавшей» FMA4-формат. По другой версии, причиной блокировки является ошибка в дизайне FMA-блока процессоров Ryzen. Вместе с тем, источник заявляет о недокументированной поддержке и перспективах возрождения (уже в документированном виде) FMA4 в процессорах AMD.
Под недокументированной поддержкой в этом контексте понимается ситуация, при которой CPUID-бит, указывающий на поддержку FMA4, обнулен, но попытка использовать инструкции FMA4 вместо предусмотренной в таком «аварийном» случае генерации исключения по недопустимому коду операции приводит к нормальному ее выполнению.
Экспериментаторы, желающие самостоятельно проверить такой сценарий, должны предусмотреть обработку возможных исключений, чтобы избежать аварийного завершения приложения. Кроме того, в силу деликатности ситуации, до обретения FMA4-инструкциями официального статуса, нет гарантии, что результат выполнения окажется корректным.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Совмещенная операция умножения-сложения (англ. Fused multiply-add, FMA ) — операция микропроцессора над числами с плавающей точкой, совмещающая умножение и сложение в одной инструкции. Имеет три аргумента: a,b,c . Вычисляет a + b * c . Включена в стандарт IEEE 754-2008.
При реализации в микропроцессоре она обычно быстрее, чем пара инструкций умножения и сложения. Данная инструкция позволяет более эффективно реализовать операции деления и извлечения квадратного корня (при отсутствии аппаратной реализации). Кроме того, в отличие от пары инструкций умножения и сложения, не требуется промежуточное округление до N бит после умножения перед сложением. Сложение выполняется над более точным внутренним представлением, и только после него происходит округление. Это позволяет увеличить точность.
Быстрая инструкция FMA может ускорить и увеличить точность операций перемножения векторов, перемножения матриц, вычисления полиномов (по схеме Горнера).
В стандарт 1999 года на язык программирования Си включена поддержка операции FMA (функция fma() из math.h)
Инструкция реализована в микропроцессорах IBM POWER1 (1990) и старше, Fujitsu SPARC64 (1995), HP PA-8000 (1996), Intel Itanium (2001), IBM Cell (2005), Loongson-2F (2008). Планируется добавить инструкции FMA3 и FMA4 в процессоры Intel и AMD примерно к 2012 году (см. также SSE5 и Intel AVX).
Инструкция FMA имеется в графических процессорах NVIDIA GeForce начиная с серии 200 (GTX 200) и NVIDIA Tesla T10 (GPGPU).
Инструкции FMA, реализованные в процессорах Intel Sandy Bridge
VFMADD a = b * c + d
VFMSUB a = b * c − d
VFNMADD a = − b * c + d
VFNMSUB a = − b * c − d
VFMADDSUB Aodd = Bodd * Codd + Dodd
VFMSUBADD Aeven = Beven * Ceven + Deven
Прерывания
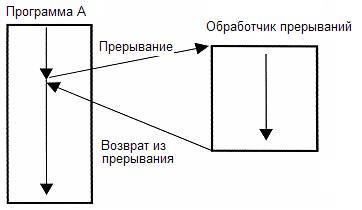
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
О документированных возможностях
Выполним несколько простых проверок, опираясь исключительно на документированную функциональность процессора AMD EPYC 7351 16-Core Processor.

Расширение FMA, в «классической» трехоперандной форме, официально поддерживается процессором AMD EPYC 7351 16-Core Processor, о чем свидетельствует CPUID функция 00000001h, регистр ECX, бит 12

Расширение FMA, в «продвинутой» четырехоперандной форме, официально не поддерживается процессором AMD EPYC 7351 16-Core Processor, о чем свидетельствует CPUID функция 80000001h, регистр ECX, бит 16
«Легальные» результаты выполнения инструкции CPUID неожиданностей не принесли: FMA поддерживается, FMA4 — нет. Оценим производительность инструкций FMA.

Цикл вычисления скалярного произведения векторов, по оси X откладывается размер каждого из двух перемножаемых векторов в байтах, по оси Y — производительность в гигабайтах в секунду (около 45.6), исследование в окрестности X = объем кэш-памяти данных L1, работает один поток
В FMA-тесте утилиты NCRB вычисляется скалярное произведение двух векторов, поэтому адресуется два читаемых массива, размер которых в байтах отложен по X. Тест использует формат двойной точности (double precision), одно число занимает 8 байт (64 бита) это необходимо учитывать при пересчете результата в GFLOPS. Одна векторная 256-битная операция обрабатывает 256 / 64 = 4 операнда. Ввиду наличия двух массивов, теоретический момент переполнения L1 должен иметь место при
X = 32 KB / 2 = 16 KB
При использовании SMT кэш-память каждого ядра обслуживает два потока, поэтому теоретический момент переполнения L1 еще в два раза ниже
X = 16 KB / 2 = 8 KB
Напомним, размер кэш-памяти данных первого уровня процессора AMD EPYC 7351 составляет 32 килобайта.
Время выполнения операции определяется двумя составляющими, первая из которых зависит от времени доставки данных из кэш-памяти, а вторая — не зависит.
- Чтение элементов перемножаемых векторов из кэш-памяти в операционный блок.
- Вычисления: операции умножения и сложения и манипуляции с данными внутри операционного блока.

Цикл вычисления скалярного произведения векторовб по оси X откладывается размер каждого из двух перемножаемых векторов в байтах, по оси Y — производительность в гигабайтах в секунду (около 733.9), исследование в окрестности X = объем кэш-памяти данных L1; работает 32 потока
Выводы
Начав исследование с документированной формы FMA, мы обнаружили неплохой уровень масштабирования производительности. При условии размещения обрабатываемых массивов в кэш-памяти данных первого уровня, соотношение производительности двух вариантов: с использованием одного логического процессора и всех 32 логических процессоров составляет 45.6 к 733.9 что весьма близко к 16. А это, напомним, количество ядер исследуемого процессора.
FMA - набор инструкций процессора, ускоряющий операции умножения-сложения чисел с плавающей запятой. Аббревиатура FMA образована от англ. Fused Multiply-Add, что переводится как умножение-сложение с однократным округлением.
Операции умножения-сложения очень распространены и играют важную роль в работе вычислительной техники. Особенно, когда речь идет о цифровой обработке аналоговых сигналов (двоичное кодирование видео, звука и другие подобные операции). В связи с этим, поддержка инструкций FMA внедрена не только в центральные процессоры, но и в графические процессоры многих современных видеокарт.
В центральных процессорах инструкции FMA используются в двух вариантах:
• FMA4 (4-operand FMA) - разработан компанией AMD, впервые реализован в архитектуре Buldozer;
• FMA3 (3-operand FMA) - разработан компанией Intel, используется в процессорах Intel, начиная с архитектуры Haswell, а также в процессорах AMD, начиная с архитектуры Piledriver.
Инструкции FMA3 и FMA4 обладают практически одинаковой функциональностью, но не взаимозаменяемы. В некоторых процессорах AMD реализована поддержка обоих вариантов, в то время как в процессорах Intel поддержка FMA4 отсутствует.
Основная разница между FMA3 и FMA4 состоит в количестве используемых операндов. С инструкциями FMA4 процессор работает по схеме a = b + (c x d). FMA3 предполагает схему a = a + (b x c).
Таким образом, 4-операндная схема позволяет сохранять результат вычислений в отдельный операнд, в то время как в 3-операндной результат записывается в один из обрабатываемых операндов, изменяя его.
На первый взгляд, FMA4 является более прогрессивным вариантом и обеспечивает повышенную гибкость программирования. Однако, на аппаратном уровне (в процессоре) его значительно сложнее реализовать. Кроме того, использование программистами инструкций FMA3 обеспечивает более короткий код, чем в случае с FMA4.

НАПИСАТЬ АВТОРУ

Технологии и инструкции, используемые в процессорах
Люди обычно оценивают процессор по количеству ядер, тактовой частоте, объему кэша и других показателях, редко обращая внимание на поддерживаемые им технологии.
Отдельные из этих технологий нужны только для решения специфических заданий и в "домашнем" компьютере вряд ли когда-нибудь понадобятся. Наличие же других является непременным условием работы программ, необходимых для повседневного использования.
Так, полюбившийся многим браузер Google Chrome не работает без поддержки процессором SSE2. Инструкции AVX могут в разы ускорить обработку фото- и видеоконтента. А недавно один мой знакомый на достаточно быстром Phenom II (6 ядер) не смог запустить игру Mafia 3, поскольку его процессор не поддерживает инструкции SSE4.2.
Если аббревиатуры SSE, MMX, AVX, SIMD вам ни о чем не говорят и вы хотели бы разобраться в этом вопросе, изложенная здесь информация станет неплохим подспорьем.

Таблица совместимости процессоров и материнских плат AMD
Одной из особенностей компьютеров на базе процессоров AMD, которой они выгодно отличаются от платформ Intel, является высокий уровень совместимости процессоров и материнских плат. У владельцев относительно не старых настольных систем на базе AMD есть высокие шансы безболезненно "прокачать" компьютер путем простой замены процессора на "камень" из более новой линейки или же флагман из предыдущей.
Если вы принадлежите к их числу и задались вопросом "апгрейда", эта небольшая табличка вам в помощь.

Сравнение процессоров
В таблицу можно одновременно добавить до 6 процессоров, выбрав их из списка (кнопка "Добавить процессор"). Всего доступно больше 2,5 тыс. процессоров Intel и AMD.
Пользователю предоставляется возможность в удобной форме сравнивать производительность процессоров в синтетических тестах, количество ядер, частоту, структуру и объем кэша, поддерживаемые типы оперативной памяти, скорость шины, а также другие их характеристики.
Дополнительные рекомендации по использованию таблицы можно найти внизу страницы.

Спецификации процессоров
В этой базе собраны подробные характеристики процессоров Intel и AMD. Она содержит спецификации около 2,7 тысяч десктопных, мобильных и серверных процессоров, начиная с первых Пентиумов и Атлонов и заканчивая последними моделями.
Информация систематизирована в алфавитном порядке и будет полезна всем, кто интересуется компьютерной техникой.

Таблица процессоров
Таблица содержит информацию о почти 2 тыс. процессоров и будет весьма полезной людям, интересующимся компьютерным "железом". Положение каждого процессора в таблице определяется уровнем его быстродействия в синтетических тестах (расположены по убыванию).
Есть фильтр, отбирающий процессоры по производителю, модели, сокету, количеству ядер, наличию встроенного видеоядра и другим параметрам.
Для получения подробной информации о любом процессоре достаточно нажать на его название.

Как проверить стабильность процессора
Проверка стабильности работы центрального процессора требуется не часто. Как правило, такая необходимость возникает при приобретении компьютера, разгоне процессора (оверлокинге), при возникновении сбоев в работе компьютера, а также в некоторых других случаях.
В статье описан порядок проверки процессора при помощи программы Prime95, которая, по мнению многих экспертов и оверлокеров, является лучшим средством для этих целей.

ПОКАЗАТЬ ЕЩЕ

Как выяснилось, выполнение некоторых специфичных инструкций FMA3 на процессоре AMD Ryzen приводит к критическому сбою ОС.
Инструкции типа FMA3 (Fused-Multiply-Add) поддерживаются и Intel (в Haswell), и AMD. Это инструкции типа d = round(a × b + c) , где d должна быть в том же регистре, что и a, b или c. Для сравнения, инструкции FMA4 поддерживает только AMD (в процессорах Buldozer и более поздних). Там a, b, c и d могут быть в разных регистрах.
Баг в процессоре обнаружен во Flops version2 — простой и малоизвестной утилите для тестирования ЦП. Следует заметить, что разработчик этой утилиты Александр "Mystical" Йи (Alexander «Mystical» Yee) позиционирует её как специфическую утилиту тестирования, которая чувствительна к микроархитектуре процессоров. В других бенчмарках баг так и не проявился.
С утилитой Flops version2 поставляются специфические бинарники для всех основных архитектур x64 (Core2, Bulldozer, Sandy Bridge, Piledriver, Haswell, Skylake). Но на данный момент ни среди бинарных сборок под Windows, ни под Linux нет версии для тестирования Zen. Поэтому сейчас для тестирования Ryzen применяли бинарники других архитектур, а именно наиболее близкой Haswell. Вышеупомянутая ошибка с инструкциями FMA3 обнаружена две недели назад самим автором программы Flops, когда он запустил тест со стоковым бинарником для Haswell на компьютере следующей конфигурации:
- Ryzen 7 1800X
- Asus Prime B350M-A (BIOS 0502)
- 4 x 8GB Corsair CMK32GX4M4A2400C14 @ 2133 MHz
- Windows 10 Anniversary Update
Иногда тест проходит эту операцию успешно, но всё равно зависает на какой-нибудь другой операции в дальнейшем.
Разработчик объясняет, что его тест — с открытым исходным кодом, и если вы не доверяете результатам, то можете сами взять и скомпилировать бинарник в Visual Studio, и перепроверить результаты.
Александр понимал, какое внимание привлечёт, сообщая об ошибке в разрекламированном процессоре. Поэтому он многократно перепроверил результаты. Процессор вешал систему на всех тактовых частотах. А при работе в однопотоковом режиме систему вешало каждое ядро.
Оставались какие-то вероятности, что причина сбоя может быть всё-таки не в процессоре, а в чём-то другом. Например, в специфической материнской плате, в специфическом BIOS, в специфической операционной системе… Что ещё может быть?
Разработчик поделился результатами с коллегами, чтобы они проверили другие версии Zen на своих компьютерах. Сбои подтвердились и для других процессоров, на разных материнских платах, под разными версиями Windows и под Linux.
В первые дни после призыва Алекса тесты запустили пять владельцев процессоров Ryzen. Вот какие получены результаты:
- 1800X + Asus Prime B350M-A (BIOS 0502)
- 1700 + Asus Prime B350M-A (BIOS . )
- 1700 + Asus Crosshair VI Hero
- 1700 + Asus Crosshair VI Hero (BIOS 5803) (два банка памяти G.Skill + Kingston)
- 1800X + Asus Crosshair VI Hero (Windows 7) — один раз прошёл тест, многократно не прошёл.
- Пока нет
Ему не давала покоя только одна деталь: хотя тест написан правильно, но почему-то зависания не присходило в других бенчмарках, таких как prime95 и y-cruncher, хотя они тоже используют FMA в тестировании.
Так что некоторая неопределённость оставалась.
Плохая новость в том, что его могут использовать злоумышленники для DoS-атак. То есть главным образом эта ошибка — проблема информационной безопасности. Ведь обычная пользовательская программа, работающая в user mode, а не на уровне ядра ОС, никак не должна намертво вешать систему. Но это происходит.
То, что тест запускали на бинарнике для другой архитектуры — не так принципиально. Любой процессор должен успешно воспроизводить тесты из любого бинарника, если он поддерживает соответствующий набор инструкций, пишет автор бенчмарка. Но даже если запустить тест с использованием несовместимых инструкций, программа не должна вешать систему намертво.
Опасность уязвимости в безопасности усугубляется тем, что вредоносный код можно запустить даже из-под виртуальной машины, он всё равно подвесит всю систему. Компьютер с новым процессором Ryzen может подвесить любая вредоносная программа. Возможно, даже через браузер.
Как уже было сказано, AMD работает над обновлением протокола AGESA. После этого патчи будут выпущены для всех версий BIOS во всех материнских платах.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
В чем отличие FMA и FMA4
Рассмотрим выражение, вычисление которого достаточно типично для операций линейной алгебры:
В трехоперандном варианте (FMA, синоним FMA3 instructions), регистр-получатель результата Y всегда совпадает с одним из трех операндов-источников X1, X2, X3. Поэтому нельзя выполнить операцию, сохранив все регистры-аргументы неизменными — один из них будет использован для формирования результата и его исходное значение будет потеряно.
Четырехоперандный вариант (FMA4 instructions) рассчитан на использование четырех независимых операндов, что позволяет сохранить в неприкосновенности содержимое всех аргументов.
Читайте также: