
Длина очереди процессора что это
Анализ загруженности оборудования для Windows
Для своевременного обнаружения узких мест в оборудовании необходимо проводить постоянный мониторинг загруженности всех основных аппаратных компонентов системы. К ним в первую очередь относятся:
- Все рабочие сервера кластера 1С:Предприятия
- Сервер СУБД
- Клиентские рабочие станции, работающие под большой нагрузкой
Для каждого из этих компьютеров необходимо настроить сбор информации по загруженности оборудования.
Сбор информации по загруженности оборудования
Во время работы системы рекомендуется осуществлять постоянный мониторинг и запись основных показателей загруженности оборудования. Для этого можно использовать разные средства, в данной статье будет рассказано, как это можно сделать с помощью Performance Monitor, входящего в состав операционной системы Windows, и ЦКК – Центра контроля качества, типовой конфигурации, входящая в Корпоративный инструментальный пакет.
Настройка сборка данных в Performance Monitor (Windows Server 2012 R2)
Для запуска Performance Monitor выберите соответствующий пункт меню раздела Administrative Tools контрольной панели Windows.
Добавьте в список наборов счетчиков (Data Collector Sets) новый набор (User Defined – пользовательский):

Настройка будет осуществляться вручную – в диалоговом окне нужно выбрать соответствующий пункт и нажать «Далее»:

Выберите, какие именно данные будут собираться. Нас интересуют Счетчики производительности:

На следующем шаге выбираются сами счетчики, которые будут входить в набор.


Мы рекомендуем в обязательном порядке собирать данные по следующим счетчикам:
"\Processor(_Total)\Interrupts/sec"
"\LogicalDisk(_Total)\% Free Space"
"\Memory\Available Mbytes"
"\PhysicalDisk(_Total)\Avg. Disk Queue Length"
"\PhysicalDisk(_Total)\Avg. Disk Sec/Read"
"\PhysicalDisk(_Total)\Avg. Disk Sec/Write"
"\Processor(_Total)\% Idle Time"
"\Processor(_Total)\% Processor Time"
"\Processor(_Total)\% User Time"
"\System\Context Switches/sec"
"\System\File Read Bytes/sec"
"\System\Context Switches/sec"
"\System\File Read Bytes/sec"
"\System\File Write Bytes/sec"
"\System\Processes"
"\System\Processor Queue Length"
"\System\Threads"
Состав счетчиков может меняться в зависимости от роли компьютера. Например, для сервера приложений 1С:Предприятие к перечисленным выше стоит добавить показатели работы процессов 1с:Предприятие:
"\Process("1cv8*")\% Processor Time"
"\Process("1cv8*")\Private Bytes"
"\Process("1cv8*")\Virtual Bytes"
"\Process("ragent*")\% Processor Time"
"\Process("ragent*")\Private Bytes"
"\Process("ragent*")\Virtual Bytes"
"\Process("rphost*")\% Processor Time"
"\Process("rphost*")\Private Bytes"
"\Process("rphost*")\Virtual Bytes"
"\Process("rmngr*")\% Processor Time"
"\Process("rmngr*")\Private Bytes"
"\Process("rmngr*")\Virtual Bytes"
Обратите внимание, что имена счетчиков могут незначительно отличаться в зависимости от версии вашей операционной системы
Рекомендуемая частота получения значений для рабочей системы – один раз в 15 секунд. В нагрузочных тестах рекомендуем собирать счетчики чаще, например, один раз в 1 секунду, т.к. длительность каждого непрерывного нагрузочного теста обычно не превышает десятка часов, а анализировать более детальные данные удобнее.По окончании выбора нажмите «Далее», укажите директорию хранения логов, при необходимости – пользователя, от имени которого будет запускаться процесс сборщика, и сохраните набор.
Откройте для дальнейшего редактирования его свойства (например, кликнув по нему в списке двойным щелчком мыши):

Можно выбрать формат файла логирования: бинарный удобен, если планируется анализировать графические данные, CSV – если планируется как-либо программно обрабатывать данные. В данном примере выбран бинарный.

На закладке «Files» можно настроить шаблон имени файлов и режим записи. Для сохраненного набора также можно настроить расписание и задать ограничения и условия окончания сбора.


В данном случае замер не стартует автоматически, но на продуктивных площадках рекомендуется не забыть настроить планировщик задач на автозапуск выбранного счетчика, например, каждый час, если сбор данных ещё не запущен.
После сохранения можно запустить замер (при помощи кнопки Start контекстного меню).
Команда создания набора будет выглядеть так:
logman create counter 1C_counter -f bincirc -c "\Processor(_Total)\Interrupts/sec" "\LogicalDisk(_Total)\% Free Space" "\Memory\Available Mbytes" "\PhysicalDisk(_Total)\Avg. Disk Queue Length" "\PhysicalDisk(_Total)\Avg. Disk Sec/Read" "\PhysicalDisk(_Total)\Avg. Disk Sec/Write" "\Processor(_Total)\% Idle Time" "\Processor(_Total)\% Processor Time" "\Processor(_Total)\% User Time" "\System\Context Switches/sec" "\System\File Read Bytes/sec" "\System\Context Switches/sec" "\System\File Read Bytes/sec" "\System\File Write Bytes/sec" "\System\Processes" "\System\Processor Queue Length" "\System\Threads" -si 5 -v mmddhhmm
Анализ сохраненного замера
Для просмотра данных откройте бинарный файл замера .blg, по умолчанию Windows откроет такой тип при помощи Performance Monitor:

Выделить график, относящийся к конкретному счетчику, можно, встав на линию графика либо на строку счетчика в списке снизу. Для него при этом отобразятся среднее, минимальное, максимальное и последнее значение за период замера:

Интерес представляют, как правило, среднее значение и «пики» - максимум / минимум в зависимости от смысла счетчика.
Ниже в таблице приведены описания и предельные значения некоторых из них:

Счетчик Processor Queue Length является одной из самых важных метрик центрального процессора и показывает сколько запросов в данный момент находится в очереди к ЦП . Я не упоминал о нем в своих недавних статьях (Счетчики производительности процессора и Анализ счетчиков производительности CPU), ведь в них главным образом идет речь о счетчиках из двух групп — Процессор (Processor) и Сведения о процессоре (Processor Information), а Processor Queue Length (Длина очереди процессора) принадлежит группе Система (System).
Если вам интересны счетчики производительности Windows, рекомендую обратиться к основной статье тематики — Счетчики производительности.
«Системный монитор» Windows
Инструменты Windows «Менеджер задач» (Task-Manager) и «Монитор ресурсов» (Ressource monitor) весьма известны, однако дают лишь поверхностное представление, так как отображают лишь несколько параметров и представляют их не очень гибко. Больше возможностей предлагает «Системный монитор» в версиях Windows 7, 8 и 10.
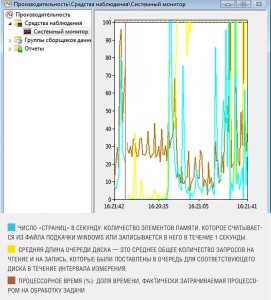
Системный монитор Windows
Инструмент, происходящий из семейства Windows Server, может отображать все возможные характеристики в виде графиков, причем многие сотни возможных значений с частично зашифрованными названиями представляют новую задачу. Мы выбрали самые важные из них, которые указывают на типичные затруднения в действующей ОС Windows и расскажем, как их устранить.
В самом благоприятном случае это удается с помощью простых изменений конфигурации или (если первый вариант не помог) путем целенаправленного обновления аппаратного обеспечения.
Системный монитор Windows организует сведения о производительности по дюжине категорий, из которых для домашнего ПК наиболее интересными являются следующие: процессор, ОЗУ, жесткий диск, процессы (включая отдельные программы) и система.
Во всех категориях следует обращать внимание на различные характеристики для того, чтобы определить, вызвана ли проблема производительности только одной программой или она возникает в результате взаимодействия нескольких причин. В первом случае с помощью диспетчера задач или монитора ресурсов вы можете узнать, какая программа является виновником, и «обезвредить» ее.
Во втором случае, если чрезмерный многозадачный режим перегружает процессор или жесткий диск, доступны однозначные индикаторы производительности. С их помощью можно проанализировать все категории вашей системы для поиска и устранения причины «торможения».
Процесс | Байты данных ввода/вывода
Если одна программа постоянно «держит в напряжении» жесткий диск или сетевую карту (см. п. 6), добавьте данный индикатор и выберите в качестве «Экземпляра» соответствующую программу.
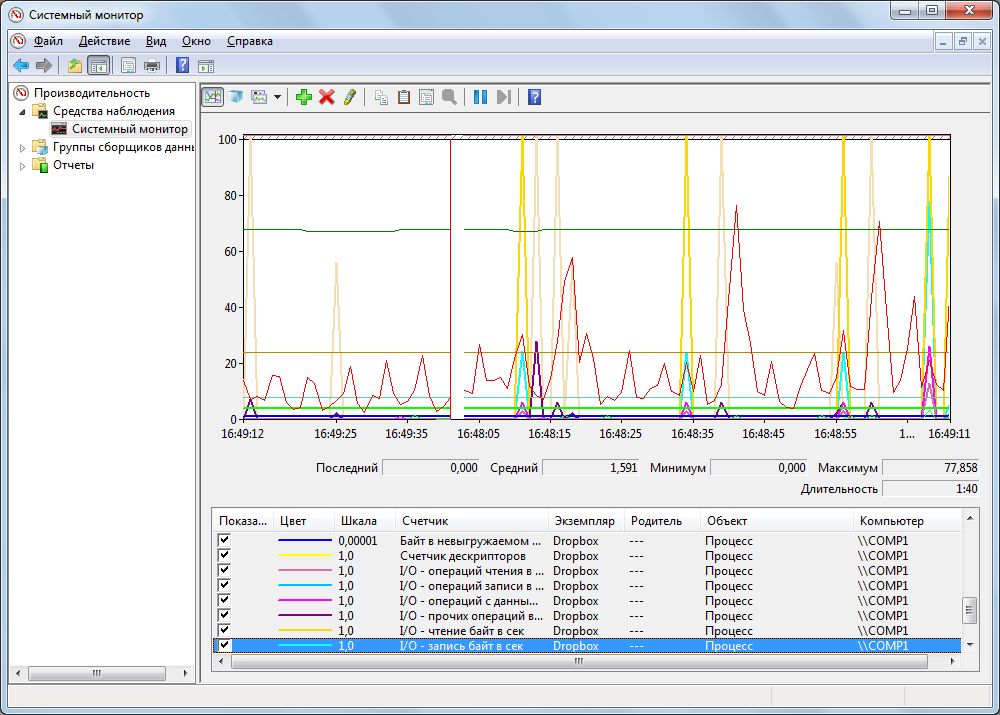
Теперь вы можете проконтролировать успешность изменений конфигурации, например, при отключении автоматических инструментов синхронизации, таких как Google Drive и One Drive.
0. Оглавление
1. Где и зачем вести мониторинг?
Прежде чем приступать к настройке мониторинга загрузки оборудования системы, необходимо понять, является ли сервер, где планируется вести замер, виртуальным? В случае работы с виртуальными машинами замер следует вести как на самом виртуальном сервере так и на физической машине. Т. к. возможна ситуация, когда счетчики производительности на виртуальном сервере не будут фиксировать значительную нагрузку оборудования, когда как физический сервер может быть загружен «соседними» виртуальными машинами или собственными работающими службами. И наоборот, анализ только физического сервера не даст четкого понимания о загрузке виртуальной машины. Только сопоставив данные замера физического и виртуального серверов можно сделать правильные выводы о загруженности оборудования.
В случае анализа загруженности серверов, на которых работают компоненты системы «1С:Предприятие» прежде всего необходим мониторинг:
- Сервера баз данных
- Серверов, на которых запущен кластер серверов «1С:Предприятия»
- В редких случаях сервера терминалов, если такой имеет место быть
Анализ «сбойного» процесса загрузки
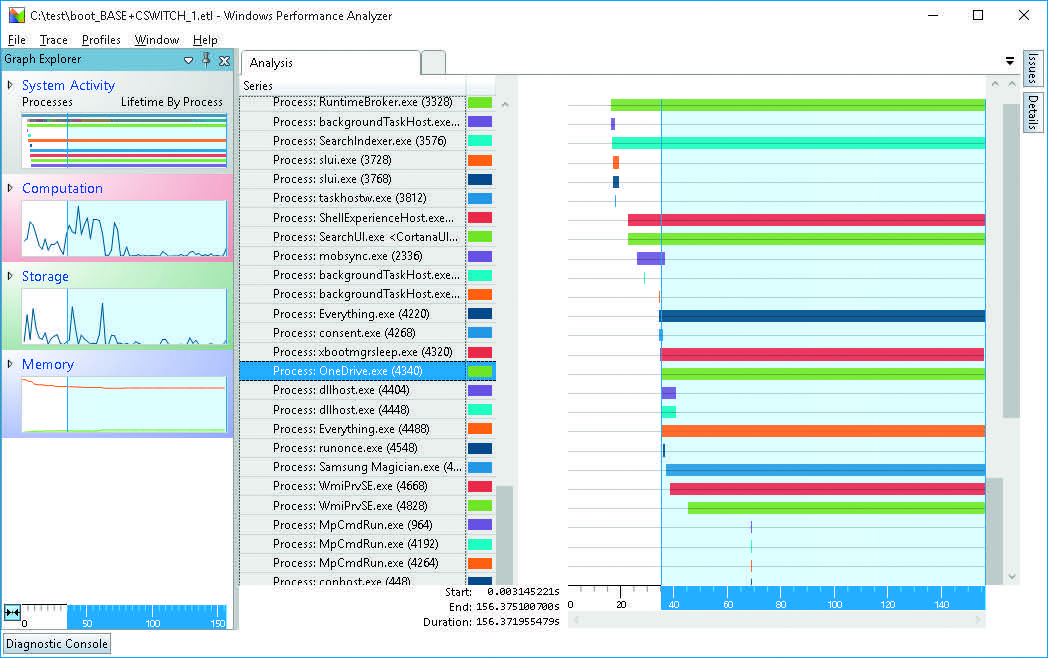
Протокол может быть открыт с помощью утилиты «Анализатор производительности Windows», который показывает, какой процесс требует какого времени. После этого вы можете обновить или удалить соответствующую программу или изменить ее конфигурацию.
Процессор | Время обработки прерывания
Наряду с вычислительными задачами процессор также нагружают запросы на прерывания. Программное или аппаратное обеспечение выдают их, если загруженная в подсистему задача выполнена или пользователем осуществляется ввод данных.
Затруднения возникают, если подключенное устройство не удается инициализировать и оно постоянно отправляет новые запросы или сетевая карта сервера перегружена чрезмерным трафиком. С помощью диалогового окна «Добавить» системного монитора добавьте к работающей диаграмме содержательные графики.
Признаком подобных проблем является «торможение» системы при подключении или активации подозрительного устройства (сетевого или жесткого диска). В этом случае проконтролируйте его индикатор производительности.
Если значение увеличивается после подключения или во время использования, вы можете попытаться обновить соответствующий драйвер, подключить устройство по-другому (например, в другой PCI-слот) или заменить его.
Память | Число «страниц» в секунду
Данный индикатор показывает, сколько минимальных элементов памяти («страниц») считывается из файла подкачки или записывается в него в течение 1 секунды. Если данная характеристика увеличивается во время запуска программы, это показывает, что объем физической памяти мал и системе приходится сохранять слишком много данных на жесткий диск.
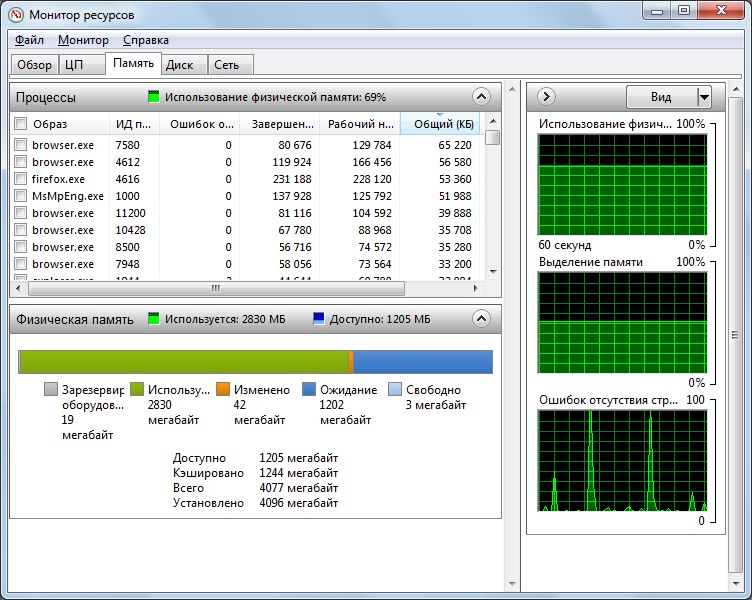
Запустите «Монитор ресурсов» через поле поиска меню «Пуск» отсортируйте перечень во вкладке «Память» по параметру «Общий КБ» и завершите самые «прожорливые» программы, в которых вы больше не нуждаетесь. Очистите меню автозапуска (см. п. 1) и по возможности увеличьте объем оперативной памяти.
Физический носитель данных | Время (%)
Если данное значение при системе в состоянии покоя остается в верхней области, вероятно, активность жестких дисков «тормозит» ваш ПК. Перейдите в «Мониторе ресурсов» на вкладку «Диск» и отсортируйте «Процессы с активностью носителя» по параметру «Всего (байт/с)».
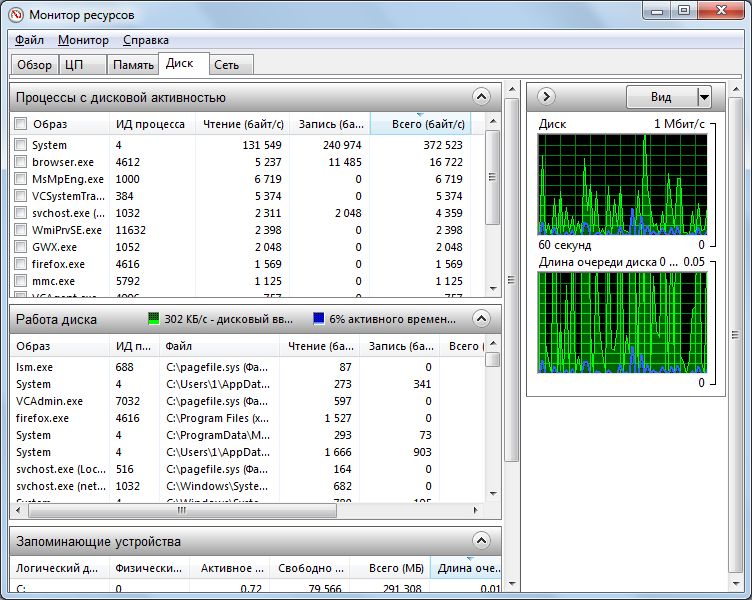
Проверьте возможность завершения или изменения конфигурации процессов с наиболее интенсивным объемом ввода/вывода. Например, настройте антивирусное ПО таким образом, чтобы ежедневное сканирование выполнялось только в том случае, если оно не мешает основной работе. Наиболее эффективным решением станет переход на SSD-накопитель.
Смотрите также:
При попытке установить типовую конфигурацию системы «1С:Предприятие» 7.7 в 64-разрядных операционных системах вместо необходимых каталогов с информационными базами увидим ошибку: «Версия этого файла несовместима с используемой версией Windows. С помощью сведений о…
Установка платформы 1С:Предприятие 7.7 на 64-х битную операционную систему сопряжена с некоторыми трудностями. Дело в том, что установить 1С через обычный установщик не получится, даже если запускать программу в режиме…
По умолчанию поиск в Windows (в данном примере в Windows 7) ищет файлы по имени. Содержимое учитывает только в проиндексированных расположениях. Чтобы поиск искал по содержимому всех документов, нужно изменить…
С проблемой повышенной нагрузки на диски (дисковые хранилища и массивы, далее просто диски), сталкиваются почти все администраторы и специалисты технической поддержки при эксплуатации средних и крупных информационных систем на базе SQL Server (от 50 активных пользовательских сессий). Но всегда ли правильно идет интерпретация проблемы, попробуем разобраться на нескольких практических примерах.
Повышенная нагрузка на диски сервера баз данных
С проблемой повышенной нагрузки на диски (дисковые хранилища и массивы, далее просто диски), сталкиваются почти все администраторы и специалисты технической поддержки при эксплуатации средних и крупных информационных систем на базе SQL Server (от 50 активных пользовательских сессий). Но всегда ли правильно идет интерпретация проблемы, попробуем разобраться на нескольких практических примерах.
Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»:

Рис.1. Средняя длина очереди к диску для чтения и записи
На рис. 1 можно наблюдать типичную ситуацию с повышенной очередью к диску, «на пальцах» этот параметр можно объяснить, как среднее количество пакетных заданий для физического диска в очереди к выполнению. В моменты повышенной очереди к диску возникают задержки на всех, даже минимальных операциях с диском, что в ряде случаев приводит к общему падению производительности. Следует учитывать возможности каждого диска по параллельной обработке, так как от этого зависит критичность проблемы. В случае, если средняя очередь к диску больше, чем возможности диска, то проблема стоит очень остро и повлияет в общем на скорость всех операций и информационной системе. Если же средняя очередь к диску больше 1, но меньше возможностей диска, то диск справляется с нагрузкой за счет своих ресурсов, но это не значит, что проблемы не существует вообще, – повышенная нагрузка на диск может привести к уменьшению срока жизни механизмов диска.
Рассмотрим несколько основных причин повышенной нагрузки на диски для систем на базе MS SQL Server.
- Нагрузка на диски обусловлена быстрым вытеснением данных из кеша SQL Server.

Рис.2. Демонстрация вытеснения данных из кеша SQL Server
На рисунке 2 показаны 3 условных этапа различной нагрузки на диск. На этапе 1 и этапе 3 – очереди к диску были минимальны. Почему же на этапе 2 очередь резко возросла и это привело к появлению проблем производительности у пользователей? Ответ на этот вопрос легко найти на втором графике рисунка 2: «Ожидаемый срок жизни страницы памяти», который показывает предполагаемое время нахождения страницы данных в кеше SQL Server. Между двумя этапами видим резкое понижение этого графика со значения 3000 до 200. С точки зрения логики работы SQL Server это означает, что данные будут находится к кеше не 3000 секунд как раньше, а 200 секунд, следовательно, если пользователь запросит данные через 300 секунд, то SQL Server с почти 100% вероятностью не найдет их в оперативной памяти (кеше) и придется выполнять операцию чтения с диска. Этими операциями обеспечивается рост очереди к диску. В течение всего этапа 2 кеш «прогревался» (заполнялся данными) и на этапе 3 нагрузка на диск упала.
Мы определили вид проблемы, теперь рассмотрим варианты решения.
Что надо сделать:
- Найти тяжелые неоптимальные запросы, которые вытеснили данные из кеша SQL Server. Прошу обратить внимание, что это не всегда равносильно поиску длительных запросов, так как зачастую быстрые, но неоптимальные запросы SQL приводят к подобным проблемам.
- Возможно проблема в качестве обслуживания статистик и индексов MS SQL Server.
Что не надо делать:
- Не надо покупать новые диски (дисковые массивы), это не решает проблему, а скорее ее усугубляет.
Для написания материала мы использовали инструмент для мониторинга производительности PerfExpert, позволяющий обеспечить возможность сбора и глубокого анализа данных.
Рассмотрим еще несколько практических ситуаций с повышенной нагрузкой на диск, где причиной являются совершенно различные по природе причины.
2. Нагрузка на диски, обусловленная свопированием памяти на диски вследствие нехватки свободной памяти.

Рис.1. Практический пример повышенной нагрузки на диск
На рисунке 1 показана практическая ситуация на сервере БД SQL Server у клиента в течение 1,5 часов. Как видно по счетчику «Средней длины очереди к диску» диск нагружен и не справляется с количеством обращений к нему.
На рисунке также показаны два других показателя: «Нагрузка CPU», «Свободная оперативная память» для поиска причин торможения диска. Условно делим ситуацию на два этапа: первый этап – очередь к диску практически равна 0 и пользователи работают в обычном режиме, и второй этап – в течение которого очередь к диску поднимается до максимальных значений (342) и пользователи не могут качественно работать. Чем же обусловлена такая нагрузка на диск?
Нагрузка обусловлена процессом свопированием оперативной памяти на диск, при котором при нехватки оперативной памяти некоторые страницы записываются в специальную область на физический диск. При этом скорость работы с такими страницами падает, повышается нагрузка на диск и замедляются все операции в системе.
Показатель «Свободная оперативная память» как раз показывает доступность реальной оперативной памяти для других процессов, а, следовательно, чем его значение больше, тем меньше вероятность свопирования. На рисунке 1 значение свободной оперативной памяти на сервере баз данных постоянно уменьшается до 500 Мб, далее до 200 Мб, это в свою очередь и привело к нагрузке на диск (на этапе 2).
Встает вопрос – а зачем на рисунке 1 мы показали счетчик «Нагрузка CPU»? Все просто, на этапе 1 средняя загрузка CPU была около 50%, на этапе 2 – 40%, при этом в системе работало аналогичное количество пользователей. Такое уменьшение значения говорит о том, что процессор недозагружен и узкое место в производительности сместилось в сторону диска (он не справляется).
Для исправления этой ситуации достаточно правильно распределить потребление оперативной памяти и не допустить уменьшение ее объема до 500Мб (как рекомендация). Неправильным вариантом решения была бы покупка более производительного физического диска или хранилища.
3. Нагрузка на диски, обусловленная внутренними механизмами работы SQL Server.

Рис. 2. Периодическая нагрузка на диск
Как видно из рисунка 2, периодически очередь к диску увеличивается, причем эти «скачки» происходят через одинаковые временные интервалы. Это может говорить о том, что есть периодически повторяемые регламентные операции.
Из нашего опыта это могут быть следующие операции:
- Увеличение размера файлов данных и лога транзакций (особенно если указан фиксированный размер прироста).
- Резервная копия файла данных или журнала транзакций.
Сбор и анализ данных осуществлялся с использованием мониторинга производительности PerfExpert.
Система | Контекстных переключений в секунду
Если указанные индикаторы производительности остались без видимых изменений или их оптимизация не привела к успеху, следует оценить данное значение. Оно показывает, как часто процессору приходится переключаться между задачами, что каждый раз приводит к незначительной потере производительности.
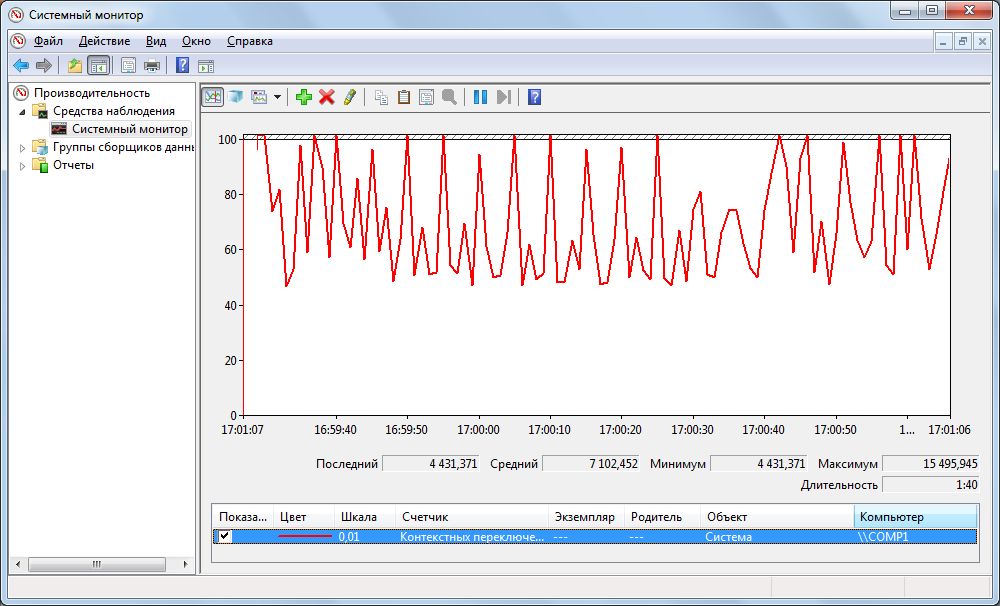
Если этот график у обычного домашнего ПК постоянно находится в верхней четверти диаграммы и компьютер «тормозит», необходимо закрыть все программы, в которых вы сейчас не нуждаетесь, например, браузер со многими открытыми вкладками с флэш-анимацией или работающий музыкальный проигрыватель. Не в последнюю очередь следует подумать об отключении ненужных пунктов в автозагрузке (см. п. 1).
Используем «Системный монитор»
Инструмент мониторинга скрыт в глубинах системы управления Windows. Проще всего найти его, написав «Системный» в окне поиска меню «Пуск», после чего появится ссылка на инструмент. После запуска он показывает только один график с указанием процессорного времени. Щелчком на зеленом символе «+» можно добавить к индикатору новые графики.
Для этого раскройте категорию, отмеченную синим шрифтом, выберите в появившемся перечне требуемый индикатор производительности и при необходимости «Экземпляр» (например, процесс или носитель данных, для которого требуется контроль), затем нажмите «Добавить» и «ОК».
Мы указываем имена по схеме «Объект | индикатор производительности». Хотя параметры обладают различными единицами измерения, системный монитор масштабирует их в сопоставимые графики. С помощью диалогового окна свойств каждого индикатора можно настроить масштаб и цвет графика.
2. Основные счетчики производительности
Приведем примеры основных счетчиков производительности, разбив их по типу исследоваемого оборудования (для разных версий Windows названия счетчиков могут немного отличаться).
2.1 Процессоры
Для анализа загруженности процессоров системы, как правило, достаточно 2 счетчиков производительности:
Для того, чтобы точно оценить, достаточно ли процессорных мощностей на сервере, может также понадобиться счетчик потоков.
2.2 Оперативная память
Для анализа достаточности / нехватки оперативной памяти на рабочем сервере, как правило, применяют 2 следующих счетчика:
2.3 Жесткие диски
2.4 Сетевые интерфейсы
Для каждого из используемых сетевых адаптеров на сервере можно скорость передачи данных через сеть с помощью следующего счетчика:
Память | Виртуальная память
Проблемы с оперативной памятью начинаются, когда ее слишком мало. Это происходит, если индикатор «Память | Байт выделенной виртуальной памяти» превышает значение суммы объема ОЗУ и половины объема файла подкачки. Для этого проанализируйте абсолютное число байт, отображаемое системным монитором при среднем значении.
Размер файла подкачки можно узнать так: нажмите Win+Pause, затем «Дополнительные параметры системы», выберите «Быстродействие | Параметры» и затем «Дополнительно | Изменить». Файл подкачки обычно увеличивается динамически, за исключением тех случаев, когда вы установили его фиксированный размер или жесткий диск заполнен.
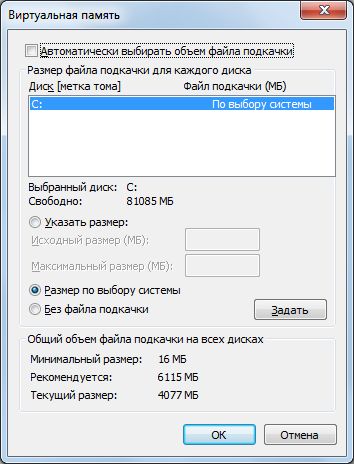
Настройка виртуальной памяти
Освободите место на диске и разрешите системе управлять размером файла подкачки. Если улучшения не произойдет, воспользуйтесь советами в следующем пункте.
Средняя длина очереди диска
Если значение индикатора «Физический диск | Средняя длина очереди диска» остается высоким, жесткий или твердотельный накопитель перегружен конкурирующими запросами.
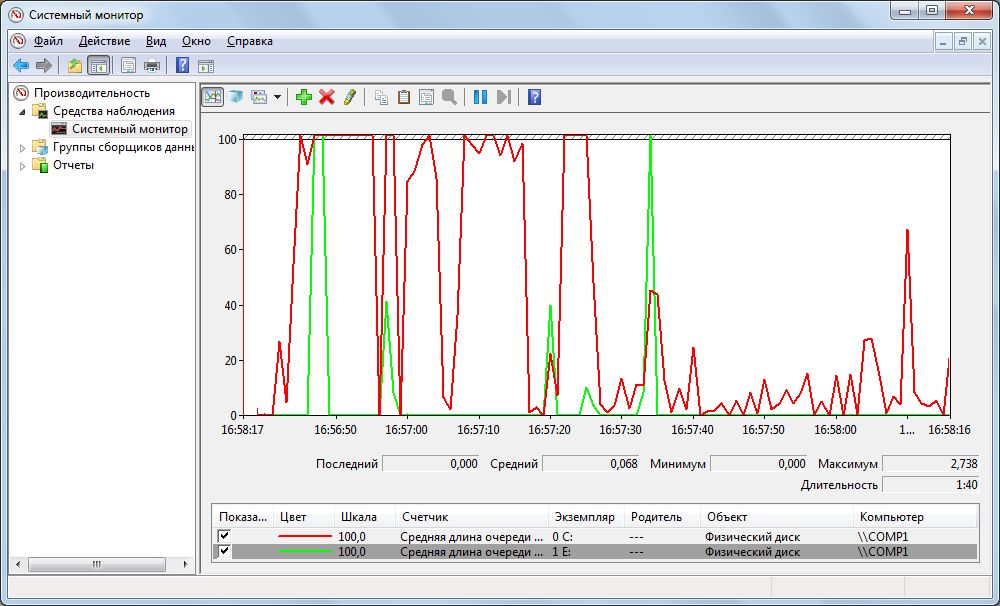
В случае одного жесткого диска помогает уменьшение количества процессов (см. п. 1) или использование SSD-накопителя в качестве системного диска. Если в компьютере установлены два жестких диска, добавьте для каждого из них свой график (в диалоговом окне добавления данных в пункте «Экземпляры» щелкните на диск, затем выберите «Добавить»).
С помощью монитора ресурсов проанализируйте, какая программа становится причиной ввода/вывода данных (см. п. 7) и измените ее конфигурацию и организацию файлов таким образом, чтобы на менее нагруженный диск поступало больше задач: например, музыкальный проигрыватель может располагать свои MP3-файлы на втором диске, чтобы слегка «разгрузить» системный диск.
Система | Длина очереди процессора
Если все ядра процессора заняты, задачи накапливаются в очереди. Если параметр «Длина очереди процессов» постоянно превышает ориентировочное значение, равное двадцатикратному числу ядер процессора, в большинстве случаев работа системы значительно замедляется. У домашних ПК это обычно происходит только в случае процессов с большим объемом вычислений, например, при кодировании видео.
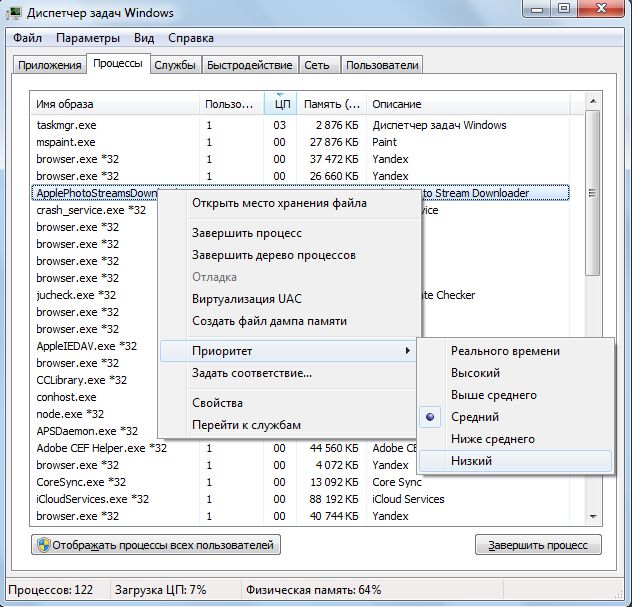
Для спокойной работы над приоритетными задачами вызовите менеджер задач, перейдите на вкладку «Процессы», правой кнопкой мыши щелкните на ресурсоемком процессе и выберите пункт «Приоритет | Низкий», после чего система будет обрабатывать этот процесс как второстепенный. В некоторых программах-кодировщиках видео, например, Avidemux, вы можете указать в настройках, чтобы кодирование всегда проводилось с низким приоритетом.
Отображение отчета о надежности
Низкая производительность может часто становиться причиной нестабильности. Если компьютер «зависает», уже поздно что-либо предпринимать: причину можно определить после перезагрузки. Для этого перейдите из меню «Пуск» в утилиту «Просмотр журнала надежности системы». Появляется временная шкала, на которой отображаются ошибки приложений, ошибки Windows, предупреждения и т.д.
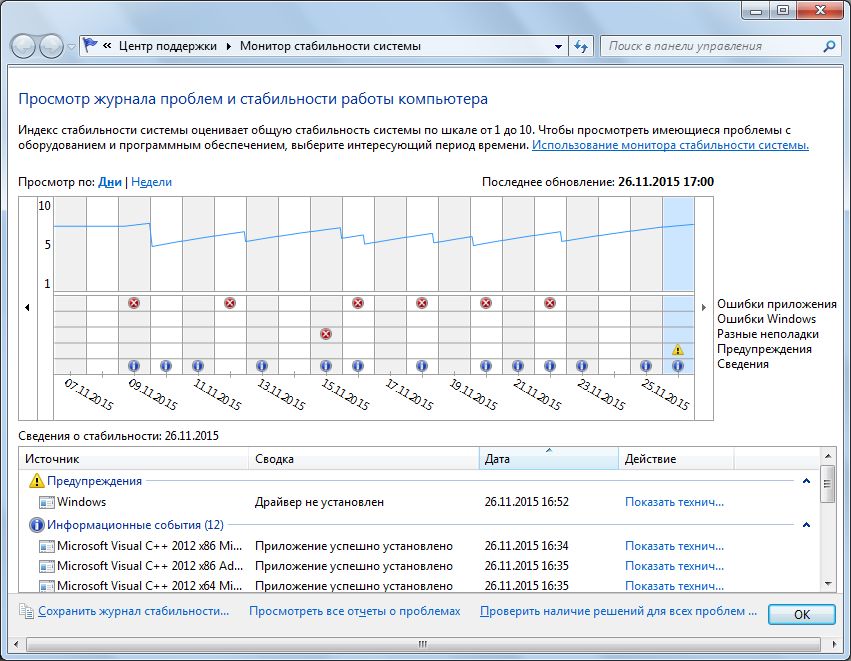
Благодаря этому вы после сбоя системы можете определить, какая программа или компонент оборудования стали причиной. Хотя сведения в пункте «Показать технические подробности» являются зашифрованными, они предлагают исходные точки для поиска решения проблемы в Интернете.
Processor Queue Length
Показания счетчика действительно очень важны для поиска проблем с производительностью процессора. Постоянное наличие большой очереди запросов к ЦП явно свидетельствует о том, что процессор не справляется с обработкой данных и является узким местом. Тем не менее до конца непонятно какие показания счетчика считаются явно плохими и указывающими на проблему, а какие являются нормой. В интернете вы не найдете исчерпывающей информации по этому вопросу, большинство ресурсов ограничивается простым описанием принципа работы счетчика, который и так очевиден.
На основе реальных данных попробуем разобраться что можно считать плохим или хорошим.
О чем реально может говорить большое количество запросов в очереди к ЦП в конкретный момент времени?
- Что ЦП как минимум задействован в работе и не простаивает. Это очевидный момент;
- Что ЦП по каким-либо причинам не смог переварить запросы в короткий промежуток времени и в связи с этим образовалась очередь;
- Какое-то приложение\оборудование генерирует запросы к ЦП;
- Какое-то приложение\драйверы имеют не слишком оптимизированный код и в связи с этим ЦП проводит много времени в ожидании между потоками.
Первый пункт в комментариях не нуждается, а вот второй нужно рассмотреть более детально. Обратимся к графику загрузки CPU реального сервера.

Вверху вы можете увидеть график длины очереди процессора на сервере Exchange 2013. Вылезают очень неприятные пики, в то время как по общеизвестным рекомендациям не должны встречаться ситуации, когда очередь составляет больше двукратного количества центральных процессоров на сервере (у меня один ЦП, значит максимальная очередь — 2, в разных источниках критической называют длину очереди 10 для одного CPU). Но теперь обратим внимание на загрузку ЦП, а именно на счетчик % Processor Time:

Как вы можете заметить, на графике даже пиковые значения загрузки ЦП не достигают и 50%, а это практически идеально подобранная производительность ЦП для тех задач, которые решает сервер — одновременно нет лишних простоев, но есть и запас производительности для периодов повышенной загрузки. В итоге делаем вывод:
Краткосрочные высокие значения очереди CPU являются нормой
Для примера рассмотрим ещё один график, но уже другого сервера — сервера СУБД MS SQL.

Пиковые значения очереди тут встречаются уже значительно чаще, но, надо отметить, они не совпадают с периодами максимальной загрузки ЦП (показательный случай выделен красной рамкой), а наоборот встречаются в моменты сравнительно низкой загрузки. В периоды своей низкой загрузки ЦП значительно чаще переходит в состояния пониженного энергопотребления и из этого можно сделать вывод, что, возможно, это тоже является причиной возникновения очередей.
То есть, как бы это парадоксально ни звучало, но графики говорят о том, что очередь может возникать во время простоев ЦП и причиной этому являются переходы В и выходы Из состояний пониженного энергопотребления. В этом случае анализируйте показания счетчиков % C1 Time, % C2 Time, % C3 Time, C1 Transitions/sec, C2 Transitions/sec, C3 Transitions/sec. Отключайте на уровне bios сам функционал перехода.
Хорошо, два примера выше иллюстрируют нормальное поведение ЦП, но что тогда считать проблемой? Есть у меня пример и на этот случай:

Это график одного из серверов, который выполняет требовательные к CPU задачи и на графиках явно видны ситуации, когда процессору не хватало мощности для обработки всего объема. В какой-то момент времени начались даже проблемы с доступностью данных счетчика % Processor Time — на нижнем графике есть достаточно большой пробел. По данным на графиках косвенно можно сделать вывод, что загрузка ЦП в момент очереди выше 10 была больше критической. Это подтверждает момент, когда очередь процессора стабильно находилась на уровне 6-8 единиц и % Processor Time показал загрузку >85% (на графике период выделен красной рамкой). Делаем вывод: проблемой является состояние, когда очередь ЦП находится стабильно выше 2. Ключевое слово стабильно.
Стоит отметить, что в каждом конкретном случае критическими могут быть разные значения. Главным критерием должна быть отзывчивость приложения. Например если сервер 1С стал регулярно выдавать средние значения очереди в 3 единицы, но пользователи при этом не заметили ухудшений вообще, то можно оставить все как есть. Если же пользователи стали резко жаловаться на тормоза программы и вы действительно заметили увеличение времени реакции ПО при выполнении обычных задач, вам нужно увеличить процессорную мощность.
Обращать внимание на Processor Queue Length > 2 в течение 5 минут. Критическим будет значение очереди >10 в течение 5 минут
Раннее я уже писал о Системном мониторе и Сборщиках данных загруженности оборудования в операционных системах семейства Windows. В данной статье на примере работы программ системы «1С:Предприятие» версии 8 рассмотрим, где и какие счетчики необходимо включать в замер производительности, а также попробуем проанализировать полученную информацию и сделать соответствующие выводы (данная статья будет полезна не только в случае анализа работы системы «1С:Предприятие» на текущем оборудовании, но и в целом для мониторинга загруженности серверов под управлением Windows).
Специальные предложения









(4) AlexO, vasyak319
Для невежды нет ничего лучше молчания, но если бы он знал,
что для него лучше всего, — не был бы он невеждой.
Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и не читать, но рассмотрим подробнее.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определят проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.
Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и вовсе не читать, но все же рассмотрим подробнее, даже если автор против этого.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определяет проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.
Кратко:
Понятно, что если данные в кэше (будем считать, что в ОЗУ, т.к. кэш может быть и на диске - это кто как реализует его хранение) - то чем чаще используется кэш, тем менее используются диски. Никаких графиков тут и не нужно - все эти графики "зависимости очереди от . страниц памяти. " - не более, чем красивые картинки, т.к. данная "проблема" - всего лишь отражение работы конкретного физического механизма: данные в кэше - используется кэш, нет данных - происходит обращение к диску.
И никакие "найти тяжелые неоптимальные запросы" (и остальные предложенные "приемы устранения проблемы") тут вообще роли не играют: если требуются данные, которых нет в кэше - вот хоть какой запрос будет легким, но все равно будет обращение к БД (диску).
Да, можно увеличить размер используемого кэша ОЗУ (всякие там "ключи использвоания памяти выше 2 ГБ" и т.д.), но это опять же "решения на час" - какого угодно размера кэш забьется, но если не будет необходимых данных - будет обращение к диску.
2. Нагрузка на диски, обусловленная свопированием памяти на диски вследствие нехватки свободной памяти.
Это тоже понятно, что если своп (виртуальный кэш, используемый приложением) находится на диске - будет нагружаться диск, в ОЗУ - диск будет разгружен. Это все и без графиков понятно всем, из одного предложения.
Другое дело, что можно регулировать объем того и другого для приложений, но об этом - как раз ни слова (именно из-за неверной предпосылки - ушел в "объяснениях" совсем в другую сторону).
А это вообще откровенная профанация (т.е. преднамеренное запутывание).
Не хочешь, чтобы "внутренние механизмы SQL" создавали нагрузку - отключи SQL. И никакой нагрузки не будет вовсе.
Регламентные операции - будь то резервное копирование, логирование и прочие, определяются не мифической "нагрузкой на диск из-за внутренних механизмов", а необходимостью: не нужно - отключи. Нужно, но тормозит - совершенствуй дисковую подсистему. Больше вариантов нет.
Log Shipping - это также регламентная операция передачи журнала транзакций, и суть её не в "создании нагрузки", а в резервировании лога транзакций: не нужно - отключи.
Т.е. по третьему пункту: автор, SQL слишком "тяжел" для твоих серверов - выключи его, переходи на файловую 1С.
Но не сваливай на регламент СУБД проблемы с дисковой подсистемой.

Со временем ОС Windows замедляет свою работу; однако в ее составе есть мощные инструменты для определения и устранения ошибок.

Любой компьютер может выдержать только одно: высокую производительность. Параметры постоянно ухудшаются в основном у «пожилых» систем Windows. Так как в большинстве случаев это происходит медленно и без видимых причин, то пользователю приходится сначала осуществлять поиск и устранение ошибок практически наугад.
Операционная система непрерывно записывает многочисленные параметры, оказывающие влияние на производительность, анализ которых показывает, какие именно процессы замедляют систему.
Процесс | Рабочий набор
Если вы с помощью предыдущих пунктов определили программу-«пожирателя» памяти, то можно ограничить ее потребности. Добавьте индикатор «Процесс | Рабочий набор» и в пункте «Экземпляры …» выберите подозрительную программу, которая часто является браузером со многими дополнениями и открытыми вкладками.
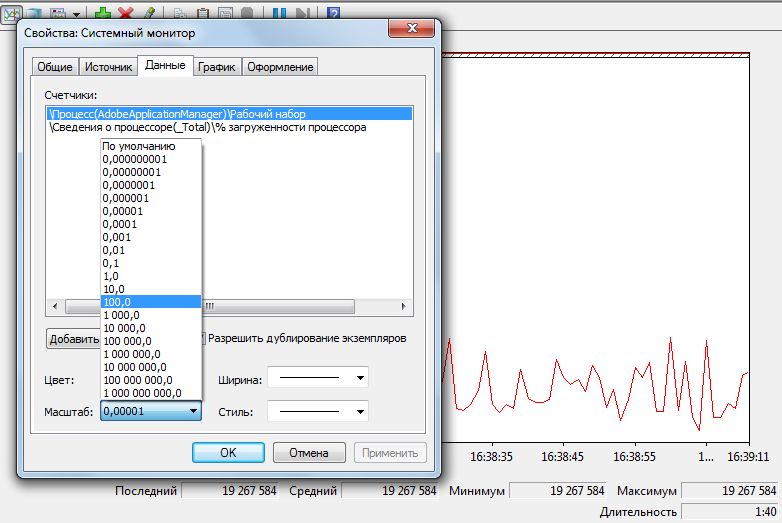
Проверьте, что произойдет, если отключить дополнения, например, блокировщик рекламы (Adblock), которые часто потребляют много памяти. Если значение уже в самом начале увеличивается до 100%, щелкните в перечне правой кнопкой на индикаторе, затем на «Свойства» и измените масштаб до ближайшего меньшего значения.
Процесс | Загруженность процессора (%)
Данное значение отображается при запуске системного монитора. Оно указывает, на сколько процентов используется вычислительная мощность ПК. Естественно, что данное значение увеличивается при нагрузке компьютера. Следует задуматься, если значение не снижается менее 5-10% при отсутствии запущенных программ. Вызовите менеджер задач, нажав Ctrl+Shift+Esc, перейдите на вкладку «Процессы» и отсортируйте список по значению «ЦП».
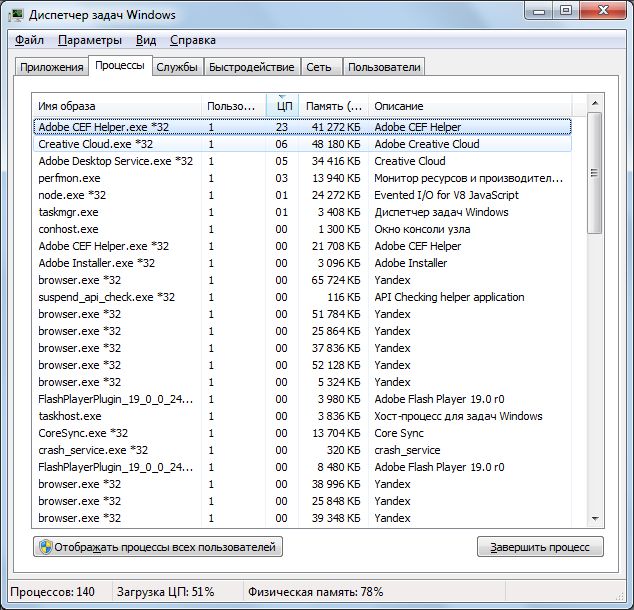
Затем исследуйте процесс, максимально нагружающий процессор: добавьте индикатор «Процесс | % загруженности процессора» и в пункте «Экземпляры выбранного объекта» выберите соответствующую программу. Если значения данного графика увеличиваются и уменьшаются одновременно с общим процессорным временем, то, вероятно, эта программа и является «виновником».
В нашем компьютере процесс Adobe CEF Helper.exe, вызываемый программой Adobe Creative Cloud, постоянно нагружает процессор на 10%. Отключение синхронизации файлов прекращает этот процесс. Если процесс не является необходимым, можно отключить его из автозагрузки.
Читайте также: