Длина очереди диска в мониторе ресурсов какая должна быть
С проблемой повышенной нагрузки на диски (дисковые хранилища и массивы, далее просто диски), сталкиваются почти все администраторы и специалисты технической поддержки при эксплуатации средних и крупных информационных систем на базе SQL Server (от 50 активных пользовательских сессий). Но всегда ли правильно идет интерпретация проблемы, попробуем разобраться на нескольких практических примерах.
Повышенная нагрузка на диски сервера баз данных
С проблемой повышенной нагрузки на диски (дисковые хранилища и массивы, далее просто диски), сталкиваются почти все администраторы и специалисты технической поддержки при эксплуатации средних и крупных информационных систем на базе SQL Server (от 50 активных пользовательских сессий). Но всегда ли правильно идет интерпретация проблемы, попробуем разобраться на нескольких практических примерах.
Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»:

Рис.1. Средняя длина очереди к диску для чтения и записи
На рис. 1 можно наблюдать типичную ситуацию с повышенной очередью к диску, «на пальцах» этот параметр можно объяснить, как среднее количество пакетных заданий для физического диска в очереди к выполнению. В моменты повышенной очереди к диску возникают задержки на всех, даже минимальных операциях с диском, что в ряде случаев приводит к общему падению производительности. Следует учитывать возможности каждого диска по параллельной обработке, так как от этого зависит критичность проблемы. В случае, если средняя очередь к диску больше, чем возможности диска, то проблема стоит очень остро и повлияет в общем на скорость всех операций и информационной системе. Если же средняя очередь к диску больше 1, но меньше возможностей диска, то диск справляется с нагрузкой за счет своих ресурсов, но это не значит, что проблемы не существует вообще, – повышенная нагрузка на диск может привести к уменьшению срока жизни механизмов диска.
Рассмотрим несколько основных причин повышенной нагрузки на диски для систем на базе MS SQL Server.
- Нагрузка на диски обусловлена быстрым вытеснением данных из кеша SQL Server.

Рис.2. Демонстрация вытеснения данных из кеша SQL Server
На рисунке 2 показаны 3 условных этапа различной нагрузки на диск. На этапе 1 и этапе 3 – очереди к диску были минимальны. Почему же на этапе 2 очередь резко возросла и это привело к появлению проблем производительности у пользователей? Ответ на этот вопрос легко найти на втором графике рисунка 2: «Ожидаемый срок жизни страницы памяти», который показывает предполагаемое время нахождения страницы данных в кеше SQL Server. Между двумя этапами видим резкое понижение этого графика со значения 3000 до 200. С точки зрения логики работы SQL Server это означает, что данные будут находится к кеше не 3000 секунд как раньше, а 200 секунд, следовательно, если пользователь запросит данные через 300 секунд, то SQL Server с почти 100% вероятностью не найдет их в оперативной памяти (кеше) и придется выполнять операцию чтения с диска. Этими операциями обеспечивается рост очереди к диску. В течение всего этапа 2 кеш «прогревался» (заполнялся данными) и на этапе 3 нагрузка на диск упала.
Мы определили вид проблемы, теперь рассмотрим варианты решения.
Что надо сделать:
- Найти тяжелые неоптимальные запросы, которые вытеснили данные из кеша SQL Server. Прошу обратить внимание, что это не всегда равносильно поиску длительных запросов, так как зачастую быстрые, но неоптимальные запросы SQL приводят к подобным проблемам.
- Возможно проблема в качестве обслуживания статистик и индексов MS SQL Server.
Что не надо делать:
- Не надо покупать новые диски (дисковые массивы), это не решает проблему, а скорее ее усугубляет.
Для написания материала мы использовали инструмент для мониторинга производительности PerfExpert, позволяющий обеспечить возможность сбора и глубокого анализа данных.
Рассмотрим еще несколько практических ситуаций с повышенной нагрузкой на диск, где причиной являются совершенно различные по природе причины.
2. Нагрузка на диски, обусловленная свопированием памяти на диски вследствие нехватки свободной памяти.

Рис.1. Практический пример повышенной нагрузки на диск
На рисунке 1 показана практическая ситуация на сервере БД SQL Server у клиента в течение 1,5 часов. Как видно по счетчику «Средней длины очереди к диску» диск нагружен и не справляется с количеством обращений к нему.
На рисунке также показаны два других показателя: «Нагрузка CPU», «Свободная оперативная память» для поиска причин торможения диска. Условно делим ситуацию на два этапа: первый этап – очередь к диску практически равна 0 и пользователи работают в обычном режиме, и второй этап – в течение которого очередь к диску поднимается до максимальных значений (342) и пользователи не могут качественно работать. Чем же обусловлена такая нагрузка на диск?
Нагрузка обусловлена процессом свопированием оперативной памяти на диск, при котором при нехватки оперативной памяти некоторые страницы записываются в специальную область на физический диск. При этом скорость работы с такими страницами падает, повышается нагрузка на диск и замедляются все операции в системе.
Показатель «Свободная оперативная память» как раз показывает доступность реальной оперативной памяти для других процессов, а, следовательно, чем его значение больше, тем меньше вероятность свопирования. На рисунке 1 значение свободной оперативной памяти на сервере баз данных постоянно уменьшается до 500 Мб, далее до 200 Мб, это в свою очередь и привело к нагрузке на диск (на этапе 2).
Встает вопрос – а зачем на рисунке 1 мы показали счетчик «Нагрузка CPU»? Все просто, на этапе 1 средняя загрузка CPU была около 50%, на этапе 2 – 40%, при этом в системе работало аналогичное количество пользователей. Такое уменьшение значения говорит о том, что процессор недозагружен и узкое место в производительности сместилось в сторону диска (он не справляется).
Для исправления этой ситуации достаточно правильно распределить потребление оперативной памяти и не допустить уменьшение ее объема до 500Мб (как рекомендация). Неправильным вариантом решения была бы покупка более производительного физического диска или хранилища.
3. Нагрузка на диски, обусловленная внутренними механизмами работы SQL Server.

Рис. 2. Периодическая нагрузка на диск
Как видно из рисунка 2, периодически очередь к диску увеличивается, причем эти «скачки» происходят через одинаковые временные интервалы. Это может говорить о том, что есть периодически повторяемые регламентные операции.
Из нашего опыта это могут быть следующие операции:
- Увеличение размера файлов данных и лога транзакций (особенно если указан фиксированный размер прироста).
- Резервная копия файла данных или журнала транзакций.
Сбор и анализ данных осуществлялся с использованием мониторинга производительности PerfExpert.
1. Диспетчер задач
Диспетчер задач позволяет выполнять различные операции с процессами, например назначать приоритет, “привязывать” процессы к определенному процессору, создавать новые процессы, но наиболее частое применение - быстрый просмотр текущей загруженности системы и принудительное завершение “проблемных” приложений.
Способы запуска Диспетчера задач:
- щелкнуть правой кнопкой мыши на панели задач и выбрать в меню “Диспетчер задач”
- ввести команду “taskmgr” в окне “Выполнить” или командной строке.
- нажать комбинацию клавиш “Ctrl+Alt+Del” и выбрать “Диспетчер задач”
- нажать комбинацию клавиш “Ctrl+Shift+Esc”
Диспетчер задач отображает в реальном времени для каждого работающего процесса объем потребляемой оперативной памяти и нагрузку на процессор. Наиболее полная информация представлена на вкладке “Подробности”. Если щелкнуть мышью по заголовку любого столбца, строки будут отсортированы по его значениям. Для принудительного завершения процесса нужно щелкнуть правой кнопкой мыши по соответствующей строке и выбрать “Снять задачу”. Кроме этого в контекстном меню доступны дополнительные действия.

Вкладка “Службы” отображает состояние служб, а через контекстное меню можно выполнить остановку, запуск или перезапуск службы. На вкладке “Процессы” выполнена группировка процессов по типу, а на вкладке “Производительность” текущая активность компонентов компьютера представлена в графическом виде.
Диспетчер задач предоставляет пользователю минимальный объем информации о загруженности системы, с помощью которого можно выполнить первоначальную диагностику.
Метрики использования операций ввода-вывода хранилища
С помощью следующих метрик можно диагностировать узкие места в комбинации виртуальной машины и диска. Эти метрики доступны только в следующей конфигурации:
- Доступно только в ряде виртуальных машин, поддерживающих хранилище класса Premium.
- Недоступно для дисков ценовой категории "Ультра", все остальные типы дисков в этой серии виртуальных машин могут использовать эти метрики.
Метрики, помогающие диагностировать установку ограничений дисковых операций ввода-вывода:
- Процент использования операций ввода-вывода в секунду на диске данных — процент, рассчитываемый путем деления количества выполненных операций ввода-вывода в секунду диска данных на количество подготовленных операций ввода-вывода в секунду диска данных. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода в секунду, установленным пределом количества операций ввода-вывода в секунду для диска данных.
- Процент использования пропускной способности на диске данных — процент, вычисляемый путем деления использованной пропускной способности диска данных на подготовленную пропускную способность диска данных. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода, установленным пределом пропускной способности диска данных.
- Процент использования операций ввода-вывода в секунду на диске ОС — процент, вычисляемый путем деления количества выполненных операций ввода-вывода в секунду диска ОС на количество подготовленных операций для диска ОС. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода в секунду, установленным пределом количества операций в секунду для диска ОС.
- Процент использования пропускной способности на диске ОС — процент, вычисляемый путем деления использованной пропускной способности диска ОС на подготовленную пропускную способность диска ОС. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода, установленным пределом пропускной способности диска ОС.
Метрики, помогающие диагностировать установку ограничений операций ввода-вывода виртуальной машины:
- Процент использования кэшированных операций ввода/вывода в секунду виртуальной машиной — процент, вычисляемый путем деления общего количества выполненных операций ввода-вывода в секунду на максимальное ограничение кэшированных операций ввода-вывода в секунду на виртуальной машине. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода в секунду, установленным пределом количества кэшированных операций ввода-вывода в секунду на виртуальной машине.
- Процент использования кэшированной пропускной способности виртуальной машиной — процент, вычисляемый путем деления общей использованной пропускной способности диска на максимальную кэшированную пропускную способность виртуальной машины. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода, установленным пределом кэшированной пропускной способности виртуальной машиной.
- Процент использования некэшированных операций ввода/вывода в секунду виртуальной машиной — процент, вычисляемый путем деления общего количества операций ввода-вывода в секунду на виртуальной машине на максимальное ограничение некэшированных операций на виртуальной машине. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода в секунду, установленным пределом количества некэшированных операций ввода-вывода в секунду на виртуальной машине.
- Процент использования некэшированной пропускной способности виртуальной машиной — процент, вычисляемый путем деления общей пропускной способности диска на виртуальной машине на максимальную подготовленную пропускную способность виртуальной машины. Если это значение равно 100 %, ваше приложение работает с ограничением операций ввода-вывода, установленным пределом некэшированной пропускной способности на виртуальной машине.
C. Просмотр сетевой активности
На вкладке “Сеть” можно выявить процессы создающие нагрузку на сеть. Это могут быть сторонние приложения, как на скриншоте, так и внутренние процессы. Как пример можно привести автоматическое обновление операционной системы.
В разделе “TCP-подключения” будут полезны показатели “Процент потерянных пакетов” и “Задержка”, по этим параметрам можно оценивать качество сетевого соединения.
Кроме этого, на вкладке “Сеть” можно видеть прослушиваемые порты и состояние брандмауэра.

Диспетчер задач и монитор ресурсов могут выявить проблему только при условии, что она наблюдается в момент проведения диагностики, но очень часто проблема проявляется не постоянно, а эпизодически. Далее описываются инструменты для мониторинга состояния системы в течении определенного интервала времени.
Пример метрик операций ввода-вывода хранилища
Давайте рассмотрим пример использования этих новых метрик использования операций ввода-вывода хранилища, что поможет нам выполнить отладку, когда в системе есть узкое место. Настройка системы такая же, как в предыдущем примере, за исключением того, что подключенный диск ОС не кэшируется.
Настройка:
- Standard_D8s_v3
- Кэшированные операции ввода-вывода в секунду: 16 000
- Операции ввода-вывода в секунду без кэширования: 12 800
- Операции ввода-вывода в секунду: 5000
- Кэширование узла: Отключено
- Операции ввода-вывода в секунду: 5000
- Кэширование узла: Чтение и запись
- Операции ввода-вывода в секунду: 5000
- Кэширование узла: Отключено
Давайте выполним тест производительности для этого сочетания виртуальной машины и диска, создающего операции ввода-вывода. Дополнительные сведения о тестировании производительности операций ввода-вывода в Azure см. в статье Тест производительности диска. В средстве тестирования производительности можно увидеть, что при сочетании виртуальной машины и диска можно достичь 22 800 операций ввода-вывода в секунду:
![Screenshot of f i o output showing r=22.8k highlighted.]()
Standard_D8s_v3 может достичь всего 28 600 операций ввода-вывода в секунду. Давайте выясним, что происходит, с помощью метрик и определим узкое место операций ввода-вывода в хранилище. В области слева выберите Метрики:
![Screenshot showing Metrics highlighted on the left pane.]()
Сначала давайте взглянем на нашу метрику Процент использования кэшированных операций ввода/вывода в секунду виртуальной машиной:
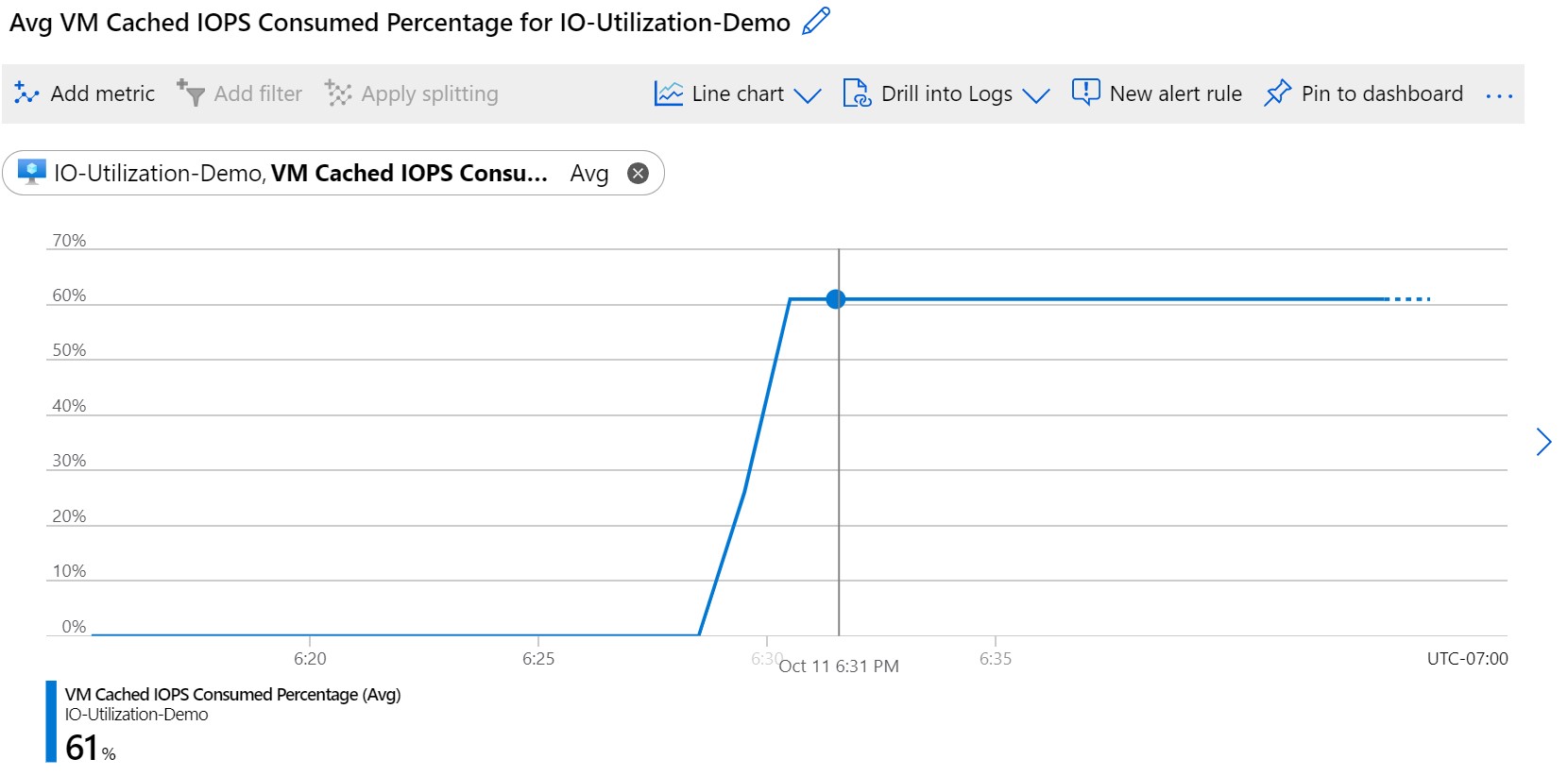
![Screenshot showing V M Cached I O P S Consumed Percentage.]()
Эта метрика указывает на то, что на виртуальной машине используется 61 % от 16 000 операций ввода-вывода, выделенных для кэшированных операций ввода-вывода в секунду. Этот процент означает, что узким местом операций ввода-вывода в хранилище являются не диски, которые кэшируются, так как значение метрики меньше 100 %. Теперь давайте взглянем на нашу метрику Процент использования некэшированных операций ввода/вывода в секунду виртуальной машиной:
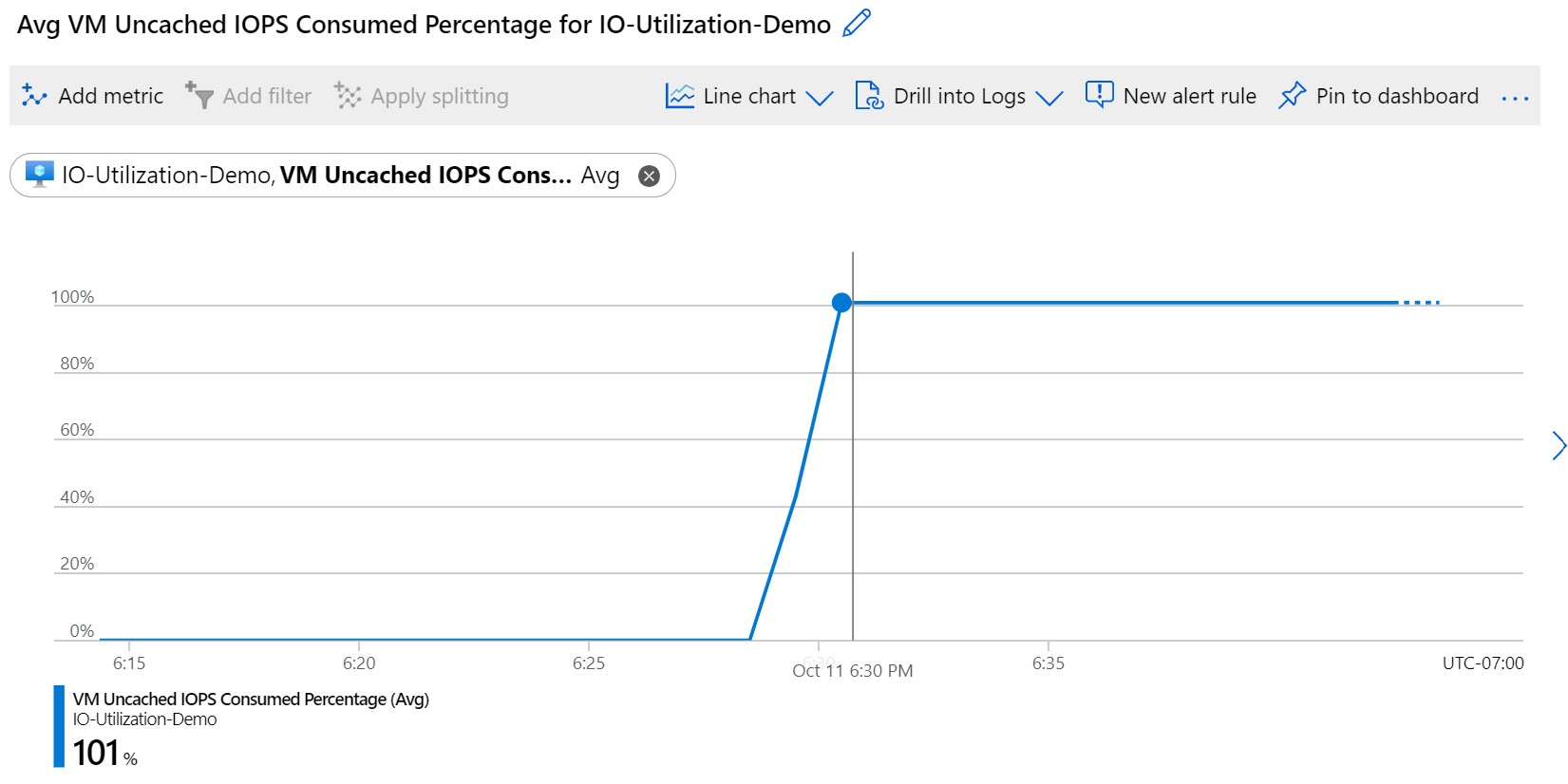
![Screenshot showing V M Uncached I O P S Consumed Percentage.]()
![Screenshot showing O S Disk I O P S Consumed Percentage.]()
Эта метрика указывает, что используется около 90 % из 5000 операций ввода-вывода в секунду, подготовленных для этого диска ОС P30. Этот процент означает, что на диске ОС нет узких мест. Теперь проверим диски данных, подключенные к виртуальной машине, просмотрев метрику Процент использования операций ввода-вывода в секунду для диска данных:
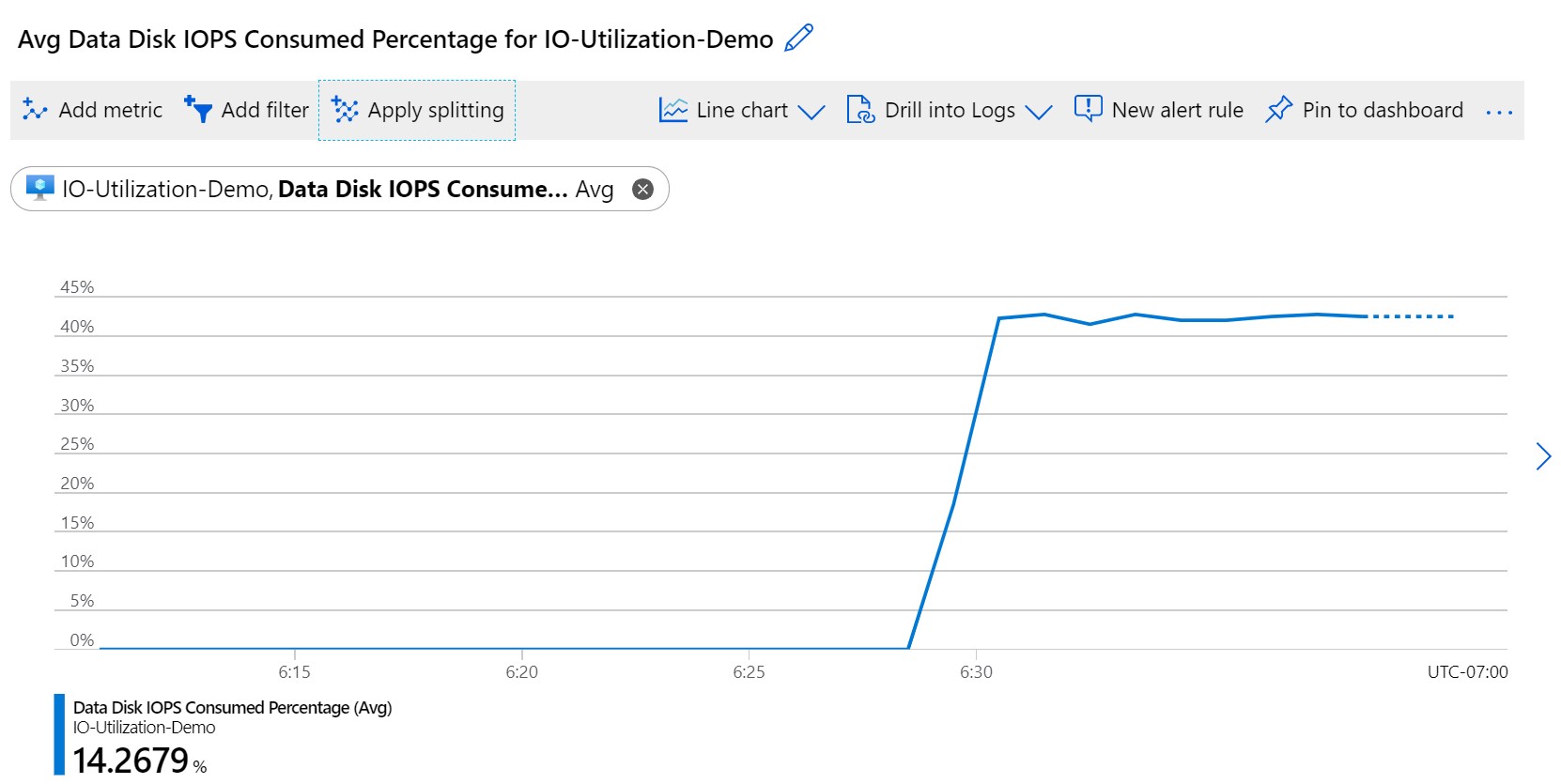
![Screenshot showing Data Disk I O P S Consumed Percentage.]()
Эта метрика указывает, что средний процент использования операций ввода-вывода в секунду во всех подключенных дисках составляет около 42 %. Этот процент вычисляется на основе операций ввода-вывода в секунду, используемых дисками и не обслуживаемых из кэша узла. Давайте подробно рассмотрим эту метрику, применив разделение к этим метрикам и разбив их по значению LUN:
![Screenshot showing Data Disk I O P S Consumed Percentage with splitting.]()
Эта метрика указывает, что диски данных, подключенные к LUN 3 и 2, используют около 85 % от подготовленных операций ввода-вывода в секунду. Ниже приведена схема операций ввода-вывода из архитектуры виртуальных машин и дисков:
тесты на чтение
Запуск: fio read.ini
Содержимое read.iniЗадача подобрать такой iodepth, чтобы avg.latency была меньше 10мс.
Специальные предложения
![Electronic Software Distribution]()
![Интеграция 1С с системой Меркурий]()
![Алкогольная декларация]()
![Готовые переносы данных]()
![54-ФЗ]()
![Управление проектом на Инфостарте]()
![Траектория обучения 1С-разработчика]()
![Маркетплейсы и 1С]()
![Инструментарий разработчика]()
(4) AlexO, vasyak319
Для невежды нет ничего лучше молчания, но если бы он знал,
что для него лучше всего, — не был бы он невеждой.Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и не читать, но рассмотрим подробнее.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определят проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и вовсе не читать, но все же рассмотрим подробнее, даже если автор против этого.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определяет проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.
Кратко:Понятно, что если данные в кэше (будем считать, что в ОЗУ, т.к. кэш может быть и на диске - это кто как реализует его хранение) - то чем чаще используется кэш, тем менее используются диски. Никаких графиков тут и не нужно - все эти графики "зависимости очереди от . страниц памяти. " - не более, чем красивые картинки, т.к. данная "проблема" - всего лишь отражение работы конкретного физического механизма: данные в кэше - используется кэш, нет данных - происходит обращение к диску.
И никакие "найти тяжелые неоптимальные запросы" (и остальные предложенные "приемы устранения проблемы") тут вообще роли не играют: если требуются данные, которых нет в кэше - вот хоть какой запрос будет легким, но все равно будет обращение к БД (диску).
Да, можно увеличить размер используемого кэша ОЗУ (всякие там "ключи использвоания памяти выше 2 ГБ" и т.д.), но это опять же "решения на час" - какого угодно размера кэш забьется, но если не будет необходимых данных - будет обращение к диску.2. Нагрузка на диски, обусловленная свопированием памяти на диски вследствие нехватки свободной памяти.
Это тоже понятно, что если своп (виртуальный кэш, используемый приложением) находится на диске - будет нагружаться диск, в ОЗУ - диск будет разгружен. Это все и без графиков понятно всем, из одного предложения.
Другое дело, что можно регулировать объем того и другого для приложений, но об этом - как раз ни слова (именно из-за неверной предпосылки - ушел в "объяснениях" совсем в другую сторону).А это вообще откровенная профанация (т.е. преднамеренное запутывание).
Не хочешь, чтобы "внутренние механизмы SQL" создавали нагрузку - отключи SQL. И никакой нагрузки не будет вовсе.
Регламентные операции - будь то резервное копирование, логирование и прочие, определяются не мифической "нагрузкой на диск из-за внутренних механизмов", а необходимостью: не нужно - отключи. Нужно, но тормозит - совершенствуй дисковую подсистему. Больше вариантов нет.
Log Shipping - это также регламентная операция передачи журнала транзакций, и суть её не в "создании нагрузки", а в резервировании лога транзакций: не нужно - отключи.
Т.е. по третьему пункту: автор, SQL слишком "тяжел" для твоих серверов - выключи его, переходи на файловую 1С.
Но не сваливай на регламент СУБД проблемы с дисковой подсистемой.По мнению большинства ИТ-специалистов, главная причина замедления быстродействия системы — повреждение жесткого диска или нехватка свободного пространства на нем. Однако время использования жесткого диска является не менее важным показателем. Под этим понимается время работы винчестера в процентном отношении к времени работы системы. Если жесткий диск используется, скажем, 80 % времени, производительность системы резко сокращается.
Другой фактор, который также следует учитывать, — это среднестатистическая длина очереди процессов, ожидающих возможности обратиться к жесткому диску. Этот показатель в сочетании с предыдущим не только свидетельствует о том, насколько интенсивно используется винчестер, но и сигнализирует о потенциальных проблемах.
К примеру, если диск используется 40 % времени, а коэффициент средней длины очереди составляет 2 или меньше, значит, винчестер справляется с возложенными на него задачами. Но если и время использования, и длина очереди очень высоки (80 % и 2 или более), значит, процессам приходится долго ждать возможности воспользоваться жестким диском, а это неизбежно приводит к ощутимому снижению быстродействия.
Оценка производительности жесткого диска
Чтобы оценить состояние жесткого диска, необходимо вычислить время его использования и среднюю длину очереди.
Для начала стоит осуществить дефрагментацию всех разделов диска, чтобы обеспечить непрерывность файлов и ускорить процессы чтения и записи. Утилиту «Дефрагментация диска» (Disk Defragmenter) можно запустить из меню «Пуск | Все программы | Стандартные | Служебные» (Start | All Programs | Accessories | System Tools).
После дефрагментации запустите Монитор производительности (Performance Monitor) из раздела «Администрирование» в Панели управления (Control Panel | Administrative Tools).
Совет: когда откроется окно Монитора производительности, выделите все ранее запущенные счетчики и нажмите [Delete]. Каждый запущенный счетчик влияет на быстродействие системы, пусть даже незначительно, поэтому для получения максимально точного результата большинство счетчиков следует отключить.
В окне Монитора производительности проделайте следующие действия:
После этого Монитор производительности начнет анализ использования диска (рис. A).
![Выявление процессов, поглощающих ресурсы жесткого диска]()
Рисунок A. Цифры под графиком указывают на время использования Диска 0 в процентах.Линии графика соответствуют выбранным счетчикам. К примеру, на рис. A преобладает розовая линия, соответствующая средней длине очереди для разделов «C:» и «D:» Диска 0. Чтобы получить конкретные показатели, нужно просто выделить соответствующий счетчик. Всегда лучше ориентироваться на цифры, а не на график — он может оказаться обманчивым, особенно если шкала выбрана неправильно.
Оцените статью: Голосовabstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
bonnie++ и iozone меряют скорость файловой системы. Которая зависит от кеша, задумчивости ядра, удачности расположения FS на диске и т.д. Косвенно можно сказать, что если в iozone получились хорошие результаты, то это либо хороший кеш, либо дурацкий набор параметров, либо действительно быстрый диск (угадайте, какой из вариантов достался вам). bonnie++ вообще сфокусирована на операциях открытия/закрытия файлов. т.е. производительность диска она особо не тестирует.dd без опции direct показывает лишь скорость кеша — не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
С опцией же direct (iflag=direct для чтения, oflag=direct для записи) dd проверяет лишь линейную скорость. Которая совершенно не равна ни максимальной скорости (если мы про рейд на много дисков, то рейд в несколько потоков может отдавать большую скорость, чем в один), ни реальной производительности.
IOmeter — лучше всего перечисленного, но у него есть проблемы при работе в linux. 64-битная версия неправильно рассчитывает тип нагрузки и показывает заниженные результаты (для тех, кто не верит — запустите его на ramdisk).
Спойлер: правильная утилита для linux — fio. Но она требует очень вдумчивого составления теста и ещё более вдумчивого анализа результатов. Всё, что ниже — как раз подготовка теории и практические замечания по работе с fio.
(текущая VS максимальная производительность)
Сейчас будет ещё больше скучных букв. Если кого-то интересует количество попугаев на его любимой SSD'шке, ноутбучном винте и т.д. — см рецепты в конце статьи.Все современные носители, кроме ramdisk'ов, крайне негативно относятся к случайным операциям записи. Для HDD нет разницы запись или чтение, важно, что головки гонять по диску. Для SSD же случайная операция чтения ерунда, а вот запись малым блоком приводит к copy-on-write. Минимальный размер записи — 1-2 Мб, пишут 4кб. Нужно прочитать 2Мб, заменить в них 4кб и записать обратно. В результате в SSD'шку уходит, например, 400 запросов в секундну на запись 4кб которые превращаются в чтение 800 Мб/с (. ) и записи их обратно. (Для ramdisk'а такая проблема могла бы быть тоже, но интрига в том, что размер «минимального блока» для DDR составляет около 128 байт, а блоки в тестах обычно 4кб, так что гранулярность DDR в тестах дисковой производительности оперативной памяти не важна).
Этот пост не про специфику разных носителей, так что возвращаемся к общей проблеме.
Мы не можем мерять запись в Мб/с. Важным является сколько перемещений головки было, и сколько случайных блоков мы потревожили на SSD. Т.е. счёт идёт на количество IO operation, а величина IO/s называется IOPS. Таким образом, когда мы меряем случайную нагрузку, мы говорим про IOPS (иногда wIOPS, rIOPS, на запись и чтение соотв.). В крупных системах используют величину kIOPS, (внимание, всегда и везде, никаких 1024) 1kIOPS = 1000 IOPS.
И вот тут многие попадают в ловушку первого рода. Они хотят знать, «сколько IOPS'ов» выдаёт диск. Или полка дисков. Или 200 серверных шкафов, набитые дисками под самые крышки.
Тут важно различать число выполненных операций (зафиксировано, что с 12:00:15 до 12:00:16 было выполнено 245790 дисковых операций — т.е. нагрузка составила 245kIOPS) и то, сколько система может выполнить операций максимум.
Число выполненых операций всегда известно и легко измерить. Но когда мы говорим про дисковую операцию, мы говорим про неё в будущем времени. «сколько операций может выполнить система?» — «каких операций?». Разные операции дают разную нагрузку на СХД. Например, если кто-то пишет случайными блоками по 1Мб, то он получит много меньше iops, чем если он будет читать последовательно блоками по 4кб.
И если в случае пришедшей нагрузки мы говорим о том, сколько было обслужено запросов «какие пришли, такие и обслужили», то в случае планирования, мы хотим знать, какие именно iops'ы будут.
Драма состоит в том, что никто не знает, какие именно запросы придут. Маленькие? Большие? Подряд? В разнобой? Будут они прочитаны из кеша или придётся идти на самое медленное место и выковыривать байтики с разных половинок диска?
- Тест диска (СХД/массива) на best case (попадание в кеш, последовательные операции)
- Тест диска на worst case. Чаще всего такие тесты планируются с знанием устройства диска. «У него кеш 64Мб? А если я сделаю размер области тестирования в 2Гб?». Жёсткий диск быстрее читает с внешней стороны диска? А если я размещу тестовую область на внутренней (ближшей к шпинделю) области, да так, чтобы проходимый головками путь был поболе? У него есть read ahead предсказание? А если я буду читать в обратном порядке? И т.д.
В результате мы получаем цифры, каждая из которых неправильная. Например: 15kIOPS и 150 IOPS.
Какая будет реальная производительность системы? Это определяется только тем, как близко будет нагрузка к хорошему и плохому концу. (Т.е. банальное «жизнь покажет»).
- Что best case всё-таки best. Потому что можно дооптимизироваться до такого, что best case от worst будет отличаться едва-едва. Это плохо (ну или у нас такой офигенный worst).
- На worst. Имея его мы можем сказать, что СХД будет работать быстрее, чем полученный показатель. Т.е. если мы получили 3000 IOPS, то мы можем смело использовать систему/диск в нагрузке «до 2000».
Ну и про размер блока. Традиционно тест идёт с размером блока в 4к. Почему? Потому что это стандартный размер блока, которым оперируют ОС при сохранении файла. Это размер страницы памяти и вообще, Очень Круглое Компьютерное Число.
Нужно понимать, что если система обрабатывает 100 IOPS с 4к блоком (worst), то она будет обрабатывать меньше при 8к блоке (не менее 50 IOPS, вероятнее всего, в районе 70-80). Ну и на 1Мб блоке мы увидим совсем другие цифры.
Всё? Нет, это было только вступление. Всё, что написано выше, более-менее общеизвестно. Нетривиальные вещи начинаются ниже.
- прочитать запись
- поменять запись
- записать запись обратно
Для удобства будем полагать, что время обработки нулевое. Если каждый запрос на чтение и запись будет обслуживаться 1мс, сколько записей в секунду сможет обработать приложение? Правильно, 500. А если мы запустим рядом вторую копию приложения? На любой приличной системе мы получим 1000. Если мы получим значительно меньше 1000, значит мы достигли предела производительности системы. Если нет — значит, что производительность приложения с зависимыми IOPS'ами ограничивается не производительностью СХД, а двумя параметрами: latency и уровнем зависимости IOPS'ов.
Начнём с latency. Latency — время выполнения запроса, задержка перед ответом. Обычно используют величину, «средняя задержка». Более продвинутые используют медиану среди всех операций за некоторый интервал (чаще всего за 1с). Latency очень сложная для измерения величина. Связано это с тем, что на любой СХД часть запросов выполняется быстро, часть медленно, а часть может попасть в крайне неприятную ситуацию и обслуживаться в десятки раз дольше остальных.
Интригу усиливает наличие очереди запросов, в рамках которой может осуществляться переупорядочивание запросов и параллельное их исполнение. У обычного SATA'шного диска глубина очереди (NCQ) — 31, у мощных систем хранения данных может достигать нескольких тысяч. (заметим, что реальная длина очереди (число ожидающих выполнения запросов) — это параметр скорее негативный, если в очереди много запросов, то они дольше ждут, т.е. тормозят. Любой человек, стоявший в час пик в супермаркете согласится, что чем длиннее очередь, тем фиговее обслуживание.
Latency напрямую влияет на производительность последовательного приложения, пример которого приведён выше. Выше latency — ниже производительность. При 5мс максимальное число запросов — 200 шт/с, при 20мс — 50. При этом если у нас 100 запросов будут обработаны за 1мс, а 9 запросов — за 100мс, то за секунду мы получим всего 109 IOPS, при медиане в 1мс и avg (среднем) в 10мс.
Отсюда довольно трудный для понимания вывод: тип нагрузки на производительность влияет не только тем, «последовательный» он или «случайный», но и тем, как устроены приложения, использующие диск.
Пример: запуск приложения (типовая десктопная задача) практически на 100% последовательный. Прочитали приложение, прочитали список нужных библиотек, по-очереди прочитали каждую библиотеку… Именно потому на десктопах так пламенно любят SSD — у них микроскопическая задержка (микросекундная) на чтение — разумеется, любимый фотошоп или блендер запускается в десятые доли секунды.
Трешинг. Я думаю, с этим явлением пользователи десктопов знакомы даже больше, чем сисадмины. Жуткий хруст жёсткого диска, невыразимые тормоза, «ничего не работает и всё тормозит».
По мере того, как мы начинаем забивать очередь диска (или хранилища, повторю, в контексте статьи между ними нет никакой разницы), у нас начинает резко вырастать latency. Диск работает на пределе возможностей, но входящих обращений больше, чем скорость их обслуживания. Latency начинает стремительно расти, достигая ужасающих цифр в единицы секунд (и это при том, что приложению, например, для завершения работы нужно сделать 100 операций, которые при latency в 5 мс означали полусекундную задержку. ). Это состояние называется thrashing.
Вы будете удивлены, но любой диск или хранилище способны показывать БОЛЬШЕ IOPS'ов в состоянии thrashing, чем в нормальной загрузке. Причина проста: если в нормальном режиме очередь чаще всего пустая
и кассир скучает, ожидая клиентов, то в условии трешинга идёт постоянное обслуживание. (Кстати, вот вам и объяснение, почему в супермаркетах любят устраивать очереди — в этом случае производительность кассиров максимальная). Правда, это сильно не нравится клиентам. И в хорошихсупермаркетаххранилищах такого режима стараются избегать. Если дальше начинать поднимать глубину очереди, то производительность начнёт падать из-за того, что переполняется очередь и запросы стоят в очереди чтобы встать в очередь (да-да, и порядковый номер шариковой ручкой на на руке).И тут нас ждёт следующая частая (и очень трудно опровергаемая) ошибка тех, кто меряет производительность диска.
Они говорят «у меня диск выдаёт 180 IOPS, так что если взять 10 дисков, то это будет аж 1800 IOPS». (Именно так думают плохие супермаркеты, сажая меньше кассиров, чем нужно). При этом latency оказывается запредельной — и «так жить нельзя».
Реальный тест производительности требует контроля latency, то есть подбора таких параметров тестирования, чтобы latency оставалась ниже оговоренного лимита.
И вот тут вот мы сталкиваемся со второй проблемой: а какого лимита? Ответить на этот вопрос теория не может — этот показатель является показателем качества обслуживания. Другими словами, каждый выбирает для себя сам.
Лично я для себя провожу тесты так, чтобы latency оставалась не более 10мс. Этот показатель я для себя считаю потолком производительности хранилища. (при этом в уме я для себя считаю, что предельный показатель, после которого начинают ощущаться лаги — это 20мс, но помните, про пример выше с 900 по 1мс и 10 по 100мс, у которого avg стала 10мс? Вот для этого я и резервирую себе +10мс на случайные всплески).
Выше мы уже рассмотрели вопрос с зависимыми и независимыми IOPS'ами. Производительность зависимых Iops'ов точно контролируется latency, и этот вопрос мы уже обсудили. А вот производительность в независимых iops'ах (т.е. при параллельной нагрузке), от чего она зависит?
Отдельно нужно говорить про ситуацию, когда хранилище подключено к хосту через сеть с использованием TCP. О TCP нужно писать, писать, писать и ещё раз писать. Достаточно сказать, что в линуксе существует 12 разных алгоритмов контроля заторов в сети (congestion), которые предназначены для разных ситуаций. И есть около 20 параметров ядра, каждый из которых может радикальным образом повлиять на попугаи на выходе (пардон, результаты теста).
С точки зрения оценки производительности мы должны просто принять такое правило: для сетевых хранилищ тест должен осуществляться с нескольких хостов (серверов) параллельно. Тесты с одного сервера не будут тестом хранилища, а будут интегрированным тестом сети, хранилища и правильности настройки самого сервера.
Последний вопрос — это вопрос затенения шины. О чём речь? Если у нас ssd способна выдать 400 МБ/с, а мы её подключаем по SATA/300, то очевидно, что мы не увидим всю производительность. Причём с точки зрения latency проблема начнёт проявляться задолго до приближения к 300МБ/с, ведь каждому запросу (и ответу на него) придётся ждать своей очереди, чтобы проскочить через бутылочное горлышко SATA-кабеля.
Но бывают ситуации более забавные. Например, если у вас есть полка дисков, подключенных по SAS/300x4 (т.е. 4 линии SAS по 300МБ каждая). Вроде бы много. А если в полке 24 диска? 24*100=2400 МБ/с, а у нас есть всего 1200 (300х4).
Более того, тесты на некоторых (серверных!) материнских платах показали, что встроенные SATA-контроллеры часто бывают подключены через PCIx4, что не даёт максимально возможной скорости всех 6 SATA-разъёмов.
Повторю, главной проблемой в bus saturation является не выедание «под потолок» полосы, а увеличение latency по мере загрузки шины.
Ну и перед практическими советами, скажу про известные трюки, которые можно встретить в индустриальных хранилищах. Во-первых, если вы будете читать пустой диск, вы будете читать его из «ниоткуда». Системы достаточно умны, чтобы кормить вас нулями из тех областей диска, куда вы никогда не писали.
Во-вторых, во многих системах первая запись хуже последующих из-за всяких механизмов снапшотов, thin provision'а, дедупликации, компрессии, late allocation, sparse placement и т.д. Другими словами, тестировать следует после первичной записи.
В третьих — кеш. Если мы тестируем worst case, то нам нужно знать, как будет вести себя система когда кеш не помогает. Для этого нужно брать такой размер теста, чтобы мы гарантированно читали/писали «мимо кеша», то есть выбивались за объёмы кеша.
Кеш на запись — особая история. Он может копить все запросы на запись (последовательные и случайные) и писать их в комфортном режиме. Единственным методом worst case является «трешинг кеша», то есть посыл запросов на запись в таком объёме и так долго, чтобы write cache перестал стправляться и был вынужден писать данные не в комфортном режиме (объединяя смежные области), а скидывать случайные данные, осуществляя random writing. Добиться этого можно только с помощью многократного превышения области теста над размером кеша.
Вердикт — минимум x10 кеш (откровенно, число взято с потолка, механизма точного расчёта у меня нет).
Разумеется, тест должен быть без участия локального кеша ОС, то есть нам надо запускать тест в режиме, который бы не использовал кеширование. В линуксе это опция O_DIRECT при открытии файла (или диска).
Итого:
1) Мы тестируем worst case — 100% размера диска, который в несколько раз больше предположительного размера кеша на хранилище. Для десктопа это всего лишь «весь диск», для индустриальных хранилищ — LUN или диск виртуальной машины размером от 1Тб и больше. (Хехе, если вы думаете, что 64Гб RAM-кеша это много. ).
2) Мы ведём тест блоком в 4кб размером.
3) Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.На выходе нас интересуют параметры: число IOPS, latency, глубина очереди. Если тест запускался на нескольких хостах, то показатели суммируются (iops и глубина очереди), а для latency берётся либо avg, либо max от показателей по всем хостам.
Тут мы переходим к практической части. Есть утилита fio которая позволяет добиться нужного нам результата.
Нормальный режим fio подразумевает использование т.н. job-файла, т.е. конфига, который описывает как именно выглядит тест. Примеры job-файлов приведены ниже, а пока что обсудим принцип работы fio.
fio выполняет операции над указанным файлом/файлами. Вместо файла может быть указано устройство, т.е. мы можем исключить файловую систему из рассмотрения. Существует несколько режимов тестирования. Нас интересует randwrite, randread и randrw. К сожалению, randrw даёт нам зависимые iops'ы (чтение идёт после записи), так что для получения полностью независимого теста нам придётся делать две параллельные задачи — одна на чтение, вторая на запись (randread, randwrite).
И нам придётся сказать fio делать «preallocation». (см выше про трюки производителей). Дальше мы фиксируем размер блока (4к).
Ещё один параметр — метод доступа к диску. Наиболее быстрым является libaio, именно его мы и будем использовать.
При тесте диска запускать её надо от root'а.
3. Системный монитор
Системный монитор позволяет отслеживать счетчики различных системных объектов операционной системы. Например, объект “Физический диск” содержит счетчики “Процент активности диска” и “Средняя длина очереди диска”, а объект “Память” - счетчик “Вывод страниц/с”.
- выбрать “Системный монитор” в меню “Средства” диспетчера серверов;
- выполнить команду “perfmon” в командной строке или окне “Выполнить”;
- выбрать “Системный монитор” в группе “Администрирование” панели управления.
Системный монитор состоит из трех основных компонентов: “Средства наблюдения”, “Группы сборщиков данных” и “Отчеты”. В разделе “Средства наблюдения” находится системный монитор, с помощью которого можно наблюдать показания счетчиков в реальном времени или просматривать ранее сохраненные отчеты. Раздел “Группы сборщиков данных” содержит набор счетчиков за которыми будет вестись наблюдение. Для диагностики можно воспользоваться двумя готовыми системными группами или создать собственные. В разделе “Отчеты” сохраняются результаты мониторинга.
Рассмотрим диагностику используя готовую группу сборщиков данных “System Performance (Производительность системы)”
1. Переходим в раздел “Группы сборщиков данных” - “Системные” и запускаем группу “System Performance (Производительность системы)”
![Поиск причины тормозов Windows - используем Системный монитор для сбора статистики]()
2. Ожидаем завершения сбора данных, продолжительность по умолчанию 1 минута, и открываем отчет в разделе “Отчеты” - “System Performance”
![Отчет Системного монитора о производительности Windows]()
В верхней части отчета отображается сводная информация по основным компонентам системы и рекомендации в случае обнаружения проблем. На тестовом сервере результаты диагностики показали нехватку оперативной памяти.
Для того, чтобы увидеть как изменялись значения счетчиков во время сбора данных нужно нажать на панели инструментов кнопку “Просмотреть данные в системном мониторе”. После этого щелкаем в нижней части окна на интересующий нас счетчик, например “% загруженности процессора” и нажимаем кнопку “Выделить” на панели инструментов, после чего соответствующий график станет выделен черной жирной линией. Под графиками отображаются среднее, максимальное и минимальное значения выбранного счетчика.
Отчеты хранятся в обычных файлах в папке “c:\Perflog”, поэтому их легко можно перенести на другой компьютер.
Встроенные группы сборщиков данных недоступны для редактирования, но для групп созданных вручную можно задавать различные параметры, например общую длительность сбора данных или время запуска по расписанию.
Для создания группы нужно щелкнуть правой кнопкой мыши по папке “Особые” в разделе “Группы сборщиков данных”, выбрать “Создать” - “Группа сборщиков данных” и следовать указаниям мастера. Если на созданной группе щелкнуть правой кнопкой мыши и выбрать “Свойства”, откроется окно в котором можно изменить параметры по умолчанию.![Создание собственной группы сборщиков данных о производительности Windows]()
4. Журнал событий
В журнале событий регистрируются все значимые изменения в работе операционной системы. Это может быть запуск или остановка службы, установка обновления, перезагрузка, ошибка чтения с диска или сбой в работе приложения. События делятся на информационные, критические, события ошибок и события предупреждений. Если операционная система Windows тормозит, зависает или работает со сбоями, а также какое-либо приложение работает нестабильно, то с большой долей вероятности в журнале событий будут соответствующие записи. Именно эти записи помогут понять причину тормозов и сбоев.
Способы запуска Журнала событий:
- выбрать “Просмотр событий” в меню “Средства” диспетчера серверов.
- выбрать “Просмотр событий” в группе “Администрирование” панели управления.
- выполнить команду “eventvwr” в командной строке или окне “Выполнить”
Журналы находятся в разделах “Журналы Windows” и “Журналы приложений и служб”. Скорее всего информация о сбоях будет находиться в журнале “Система” раздела “Журналы Windows”. Но если заранее неизвестно, что именно нужно искать, то можно воспользоваться готовым представлением “События управления”, в котором отображается информация из всех основных журналов. Готовое представление недоступно для редактирования, поэтому если возникнет необходимость изменить выводимые журналы или категории событий можно создать собственное представление или скопировать существующее.
Щелкнем правой кнопкой мыши на представлении “События управления” и выберем “Копировать настраиваемое представление”, в открывшемся окне нажимаем “Ок”. В результате появится новое представление “События Управления (1)”. Для редактирования нужно выделить созданное представление и нажать в правой части окна кнопку “Фильтр текущего настраиваемого представления”.
Для диагностики неисправности можно настроить вывод только ошибок и критических событий.
![Поиск причины зависания Windows с помощью журнала событий]()
Тесты на запись
(внимание! Ошибётесь буквой диска — останетесь без данных)
Специальные предложения
![Electronic Software Distribution]()
![Интеграция 1С с системой Меркурий]()
![Алкогольная декларация]()
![Готовые переносы данных]()
![54-ФЗ]()
![Управление проектом на Инфостарте]()
![Траектория обучения 1С-разработчика]()
![Маркетплейсы и 1С]()
![Инструментарий разработчика]()
(4) AlexO, vasyak319
Для невежды нет ничего лучше молчания, но если бы он знал,
что для него лучше всего, — не был бы он невеждой.Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и не читать, но рассмотрим подробнее.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определят проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.Как правило, повышенную нагрузку на диски можно определить различными способами. Основной из них – это получение счетчика «Средней длины очереди к диску»
Сразу неверное предположение, отсюда - неверные выводы.
И "решения", где-то правильные, где-то - бессмысленные, но точно не связанные с проблемой "повышенная нагрузка на диски", или связанная, но не так, как предположил автор.
Дальше статью можно и вовсе не читать, но все же рассмотрим подробнее, даже если автор против этого.
Очередь к диску сама по себе - это не "нагрузка на диск", а следствие интенсивного использования диска, т.е. следствие повышенной нагрузки .
Т.е. это очень важный показатель оценки работы дисковой подсимтемы, но не он определяет проблему, и бороться надо не с очередью к диску, а с причиной - недостаточной (или уже несоответствующей) скоростью записи-чтения системы HDD (что наиболее эффективно), либо, с другой стороны, заставлять приложения меньше использовать HDD, и больше - ОЗУ.
Вы, собственно, это и рассматриваете далее, но из-за неверной предпосылки - рассматриваете не в том контексте и верные, и неверные подходы.
Кратко:Понятно, что если данные в кэше (будем считать, что в ОЗУ, т.к. кэш может быть и на диске - это кто как реализует его хранение) - то чем чаще используется кэш, тем менее используются диски. Никаких графиков тут и не нужно - все эти графики "зависимости очереди от . страниц памяти. " - не более, чем красивые картинки, т.к. данная "проблема" - всего лишь отражение работы конкретного физического механизма: данные в кэше - используется кэш, нет данных - происходит обращение к диску.
И никакие "найти тяжелые неоптимальные запросы" (и остальные предложенные "приемы устранения проблемы") тут вообще роли не играют: если требуются данные, которых нет в кэше - вот хоть какой запрос будет легким, но все равно будет обращение к БД (диску).
Да, можно увеличить размер используемого кэша ОЗУ (всякие там "ключи использвоания памяти выше 2 ГБ" и т.д.), но это опять же "решения на час" - какого угодно размера кэш забьется, но если не будет необходимых данных - будет обращение к диску.2. Нагрузка на диски, обусловленная свопированием памяти на диски вследствие нехватки свободной памяти.
Это тоже понятно, что если своп (виртуальный кэш, используемый приложением) находится на диске - будет нагружаться диск, в ОЗУ - диск будет разгружен. Это все и без графиков понятно всем, из одного предложения.
Другое дело, что можно регулировать объем того и другого для приложений, но об этом - как раз ни слова (именно из-за неверной предпосылки - ушел в "объяснениях" совсем в другую сторону).А это вообще откровенная профанация (т.е. преднамеренное запутывание).
Не хочешь, чтобы "внутренние механизмы SQL" создавали нагрузку - отключи SQL. И никакой нагрузки не будет вовсе.
Регламентные операции - будь то резервное копирование, логирование и прочие, определяются не мифической "нагрузкой на диск из-за внутренних механизмов", а необходимостью: не нужно - отключи. Нужно, но тормозит - совершенствуй дисковую подсистему. Больше вариантов нет.
Log Shipping - это также регламентная операция передачи журнала транзакций, и суть её не в "создании нагрузки", а в резервировании лога транзакций: не нужно - отключи.
Т.е. по третьему пункту: автор, SQL слишком "тяжел" для твоих серверов - выключи его, переходи на файловую 1С.
Но не сваливай на регламент СУБД проблемы с дисковой подсистемой.По мнению большинства ИТ-специалистов, главная причина замедления быстродействия системы — повреждение жесткого диска или нехватка свободного пространства на нем. Однако время использования жесткого диска является не менее важным показателем. Под этим понимается время работы винчестера в процентном отношении к времени работы системы. Если жесткий диск используется, скажем, 80 % времени, производительность системы резко сокращается.
Другой фактор, который также следует учитывать, — это среднестатистическая длина очереди процессов, ожидающих возможности обратиться к жесткому диску. Этот показатель в сочетании с предыдущим не только свидетельствует о том, насколько интенсивно используется винчестер, но и сигнализирует о потенциальных проблемах.
К примеру, если диск используется 40 % времени, а коэффициент средней длины очереди составляет 2 или меньше, значит, винчестер справляется с возложенными на него задачами. Но если и время использования, и длина очереди очень высоки (80 % и 2 или более), значит, процессам приходится долго ждать возможности воспользоваться жестким диском, а это неизбежно приводит к ощутимому снижению быстродействия.
Оценка производительности жесткого диска
Чтобы оценить состояние жесткого диска, необходимо вычислить время его использования и среднюю длину очереди.
Для начала стоит осуществить дефрагментацию всех разделов диска, чтобы обеспечить непрерывность файлов и ускорить процессы чтения и записи. Утилиту «Дефрагментация диска» (Disk Defragmenter) можно запустить из меню «Пуск | Все программы | Стандартные | Служебные» (Start | All Programs | Accessories | System Tools).
После дефрагментации запустите Монитор производительности (Performance Monitor) из раздела «Администрирование» в Панели управления (Control Panel | Administrative Tools).
Совет: когда откроется окно Монитора производительности, выделите все ранее запущенные счетчики и нажмите [Delete]. Каждый запущенный счетчик влияет на быстродействие системы, пусть даже незначительно, поэтому для получения максимально точного результата большинство счетчиков следует отключить.
В окне Монитора производительности проделайте следующие действия:
После этого Монитор производительности начнет анализ использования диска (рис. A).
![Выявление процессов, поглощающих ресурсы жесткого диска]()
Рисунок A. Цифры под графиком указывают на время использования Диска 0 в процентах.Линии графика соответствуют выбранным счетчикам. К примеру, на рис. A преобладает розовая линия, соответствующая средней длине очереди для разделов «C:» и «D:» Диска 0. Чтобы получить конкретные показатели, нужно просто выделить соответствующий счетчик. Всегда лучше ориентироваться на цифры, а не на график — он может оказаться обманчивым, особенно если шкала выбрана неправильно.
Оцените статью: Голосовabstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
bonnie++ и iozone меряют скорость файловой системы. Которая зависит от кеша, задумчивости ядра, удачности расположения FS на диске и т.д. Косвенно можно сказать, что если в iozone получились хорошие результаты, то это либо хороший кеш, либо дурацкий набор параметров, либо действительно быстрый диск (угадайте, какой из вариантов достался вам). bonnie++ вообще сфокусирована на операциях открытия/закрытия файлов. т.е. производительность диска она особо не тестирует.dd без опции direct показывает лишь скорость кеша — не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
С опцией же direct (iflag=direct для чтения, oflag=direct для записи) dd проверяет лишь линейную скорость. Которая совершенно не равна ни максимальной скорости (если мы про рейд на много дисков, то рейд в несколько потоков может отдавать большую скорость, чем в один), ни реальной производительности.
IOmeter — лучше всего перечисленного, но у него есть проблемы при работе в linux. 64-битная версия неправильно рассчитывает тип нагрузки и показывает заниженные результаты (для тех, кто не верит — запустите его на ramdisk).
Спойлер: правильная утилита для linux — fio. Но она требует очень вдумчивого составления теста и ещё более вдумчивого анализа результатов. Всё, что ниже — как раз подготовка теории и практические замечания по работе с fio.
(текущая VS максимальная производительность)
Сейчас будет ещё больше скучных букв. Если кого-то интересует количество попугаев на его любимой SSD'шке, ноутбучном винте и т.д. — см рецепты в конце статьи.Все современные носители, кроме ramdisk'ов, крайне негативно относятся к случайным операциям записи. Для HDD нет разницы запись или чтение, важно, что головки гонять по диску. Для SSD же случайная операция чтения ерунда, а вот запись малым блоком приводит к copy-on-write. Минимальный размер записи — 1-2 Мб, пишут 4кб. Нужно прочитать 2Мб, заменить в них 4кб и записать обратно. В результате в SSD'шку уходит, например, 400 запросов в секундну на запись 4кб которые превращаются в чтение 800 Мб/с (. ) и записи их обратно. (Для ramdisk'а такая проблема могла бы быть тоже, но интрига в том, что размер «минимального блока» для DDR составляет около 128 байт, а блоки в тестах обычно 4кб, так что гранулярность DDR в тестах дисковой производительности оперативной памяти не важна).
Этот пост не про специфику разных носителей, так что возвращаемся к общей проблеме.
Мы не можем мерять запись в Мб/с. Важным является сколько перемещений головки было, и сколько случайных блоков мы потревожили на SSD. Т.е. счёт идёт на количество IO operation, а величина IO/s называется IOPS. Таким образом, когда мы меряем случайную нагрузку, мы говорим про IOPS (иногда wIOPS, rIOPS, на запись и чтение соотв.). В крупных системах используют величину kIOPS, (внимание, всегда и везде, никаких 1024) 1kIOPS = 1000 IOPS.
И вот тут многие попадают в ловушку первого рода. Они хотят знать, «сколько IOPS'ов» выдаёт диск. Или полка дисков. Или 200 серверных шкафов, набитые дисками под самые крышки.
Тут важно различать число выполненных операций (зафиксировано, что с 12:00:15 до 12:00:16 было выполнено 245790 дисковых операций — т.е. нагрузка составила 245kIOPS) и то, сколько система может выполнить операций максимум.
Число выполненых операций всегда известно и легко измерить. Но когда мы говорим про дисковую операцию, мы говорим про неё в будущем времени. «сколько операций может выполнить система?» — «каких операций?». Разные операции дают разную нагрузку на СХД. Например, если кто-то пишет случайными блоками по 1Мб, то он получит много меньше iops, чем если он будет читать последовательно блоками по 4кб.
И если в случае пришедшей нагрузки мы говорим о том, сколько было обслужено запросов «какие пришли, такие и обслужили», то в случае планирования, мы хотим знать, какие именно iops'ы будут.
Драма состоит в том, что никто не знает, какие именно запросы придут. Маленькие? Большие? Подряд? В разнобой? Будут они прочитаны из кеша или придётся идти на самое медленное место и выковыривать байтики с разных половинок диска?
- Тест диска (СХД/массива) на best case (попадание в кеш, последовательные операции)
- Тест диска на worst case. Чаще всего такие тесты планируются с знанием устройства диска. «У него кеш 64Мб? А если я сделаю размер области тестирования в 2Гб?». Жёсткий диск быстрее читает с внешней стороны диска? А если я размещу тестовую область на внутренней (ближшей к шпинделю) области, да так, чтобы проходимый головками путь был поболе? У него есть read ahead предсказание? А если я буду читать в обратном порядке? И т.д.
В результате мы получаем цифры, каждая из которых неправильная. Например: 15kIOPS и 150 IOPS.
Какая будет реальная производительность системы? Это определяется только тем, как близко будет нагрузка к хорошему и плохому концу. (Т.е. банальное «жизнь покажет»).
- Что best case всё-таки best. Потому что можно дооптимизироваться до такого, что best case от worst будет отличаться едва-едва. Это плохо (ну или у нас такой офигенный worst).
- На worst. Имея его мы можем сказать, что СХД будет работать быстрее, чем полученный показатель. Т.е. если мы получили 3000 IOPS, то мы можем смело использовать систему/диск в нагрузке «до 2000».
Ну и про размер блока. Традиционно тест идёт с размером блока в 4к. Почему? Потому что это стандартный размер блока, которым оперируют ОС при сохранении файла. Это размер страницы памяти и вообще, Очень Круглое Компьютерное Число.
Нужно понимать, что если система обрабатывает 100 IOPS с 4к блоком (worst), то она будет обрабатывать меньше при 8к блоке (не менее 50 IOPS, вероятнее всего, в районе 70-80). Ну и на 1Мб блоке мы увидим совсем другие цифры.
Всё? Нет, это было только вступление. Всё, что написано выше, более-менее общеизвестно. Нетривиальные вещи начинаются ниже.
- прочитать запись
- поменять запись
- записать запись обратно
Для удобства будем полагать, что время обработки нулевое. Если каждый запрос на чтение и запись будет обслуживаться 1мс, сколько записей в секунду сможет обработать приложение? Правильно, 500. А если мы запустим рядом вторую копию приложения? На любой приличной системе мы получим 1000. Если мы получим значительно меньше 1000, значит мы достигли предела производительности системы. Если нет — значит, что производительность приложения с зависимыми IOPS'ами ограничивается не производительностью СХД, а двумя параметрами: latency и уровнем зависимости IOPS'ов.
Начнём с latency. Latency — время выполнения запроса, задержка перед ответом. Обычно используют величину, «средняя задержка». Более продвинутые используют медиану среди всех операций за некоторый интервал (чаще всего за 1с). Latency очень сложная для измерения величина. Связано это с тем, что на любой СХД часть запросов выполняется быстро, часть медленно, а часть может попасть в крайне неприятную ситуацию и обслуживаться в десятки раз дольше остальных.
Интригу усиливает наличие очереди запросов, в рамках которой может осуществляться переупорядочивание запросов и параллельное их исполнение. У обычного SATA'шного диска глубина очереди (NCQ) — 31, у мощных систем хранения данных может достигать нескольких тысяч. (заметим, что реальная длина очереди (число ожидающих выполнения запросов) — это параметр скорее негативный, если в очереди много запросов, то они дольше ждут, т.е. тормозят. Любой человек, стоявший в час пик в супермаркете согласится, что чем длиннее очередь, тем фиговее обслуживание.
Latency напрямую влияет на производительность последовательного приложения, пример которого приведён выше. Выше latency — ниже производительность. При 5мс максимальное число запросов — 200 шт/с, при 20мс — 50. При этом если у нас 100 запросов будут обработаны за 1мс, а 9 запросов — за 100мс, то за секунду мы получим всего 109 IOPS, при медиане в 1мс и avg (среднем) в 10мс.
Отсюда довольно трудный для понимания вывод: тип нагрузки на производительность влияет не только тем, «последовательный» он или «случайный», но и тем, как устроены приложения, использующие диск.
Пример: запуск приложения (типовая десктопная задача) практически на 100% последовательный. Прочитали приложение, прочитали список нужных библиотек, по-очереди прочитали каждую библиотеку… Именно потому на десктопах так пламенно любят SSD — у них микроскопическая задержка (микросекундная) на чтение — разумеется, любимый фотошоп или блендер запускается в десятые доли секунды.
Трешинг. Я думаю, с этим явлением пользователи десктопов знакомы даже больше, чем сисадмины. Жуткий хруст жёсткого диска, невыразимые тормоза, «ничего не работает и всё тормозит».
По мере того, как мы начинаем забивать очередь диска (или хранилища, повторю, в контексте статьи между ними нет никакой разницы), у нас начинает резко вырастать latency. Диск работает на пределе возможностей, но входящих обращений больше, чем скорость их обслуживания. Latency начинает стремительно расти, достигая ужасающих цифр в единицы секунд (и это при том, что приложению, например, для завершения работы нужно сделать 100 операций, которые при latency в 5 мс означали полусекундную задержку. ). Это состояние называется thrashing.
Вы будете удивлены, но любой диск или хранилище способны показывать БОЛЬШЕ IOPS'ов в состоянии thrashing, чем в нормальной загрузке. Причина проста: если в нормальном режиме очередь чаще всего пустая
и кассир скучает, ожидая клиентов, то в условии трешинга идёт постоянное обслуживание. (Кстати, вот вам и объяснение, почему в супермаркетах любят устраивать очереди — в этом случае производительность кассиров максимальная). Правда, это сильно не нравится клиентам. И в хорошихсупермаркетаххранилищах такого режима стараются избегать. Если дальше начинать поднимать глубину очереди, то производительность начнёт падать из-за того, что переполняется очередь и запросы стоят в очереди чтобы встать в очередь (да-да, и порядковый номер шариковой ручкой на на руке).И тут нас ждёт следующая частая (и очень трудно опровергаемая) ошибка тех, кто меряет производительность диска.
Они говорят «у меня диск выдаёт 180 IOPS, так что если взять 10 дисков, то это будет аж 1800 IOPS». (Именно так думают плохие супермаркеты, сажая меньше кассиров, чем нужно). При этом latency оказывается запредельной — и «так жить нельзя».
Реальный тест производительности требует контроля latency, то есть подбора таких параметров тестирования, чтобы latency оставалась ниже оговоренного лимита.
И вот тут вот мы сталкиваемся со второй проблемой: а какого лимита? Ответить на этот вопрос теория не может — этот показатель является показателем качества обслуживания. Другими словами, каждый выбирает для себя сам.
Лично я для себя провожу тесты так, чтобы latency оставалась не более 10мс. Этот показатель я для себя считаю потолком производительности хранилища. (при этом в уме я для себя считаю, что предельный показатель, после которого начинают ощущаться лаги — это 20мс, но помните, про пример выше с 900 по 1мс и 10 по 100мс, у которого avg стала 10мс? Вот для этого я и резервирую себе +10мс на случайные всплески).
Выше мы уже рассмотрели вопрос с зависимыми и независимыми IOPS'ами. Производительность зависимых Iops'ов точно контролируется latency, и этот вопрос мы уже обсудили. А вот производительность в независимых iops'ах (т.е. при параллельной нагрузке), от чего она зависит?
Отдельно нужно говорить про ситуацию, когда хранилище подключено к хосту через сеть с использованием TCP. О TCP нужно писать, писать, писать и ещё раз писать. Достаточно сказать, что в линуксе существует 12 разных алгоритмов контроля заторов в сети (congestion), которые предназначены для разных ситуаций. И есть около 20 параметров ядра, каждый из которых может радикальным образом повлиять на попугаи на выходе (пардон, результаты теста).
С точки зрения оценки производительности мы должны просто принять такое правило: для сетевых хранилищ тест должен осуществляться с нескольких хостов (серверов) параллельно. Тесты с одного сервера не будут тестом хранилища, а будут интегрированным тестом сети, хранилища и правильности настройки самого сервера.
Последний вопрос — это вопрос затенения шины. О чём речь? Если у нас ssd способна выдать 400 МБ/с, а мы её подключаем по SATA/300, то очевидно, что мы не увидим всю производительность. Причём с точки зрения latency проблема начнёт проявляться задолго до приближения к 300МБ/с, ведь каждому запросу (и ответу на него) придётся ждать своей очереди, чтобы проскочить через бутылочное горлышко SATA-кабеля.
Но бывают ситуации более забавные. Например, если у вас есть полка дисков, подключенных по SAS/300x4 (т.е. 4 линии SAS по 300МБ каждая). Вроде бы много. А если в полке 24 диска? 24*100=2400 МБ/с, а у нас есть всего 1200 (300х4).
Более того, тесты на некоторых (серверных!) материнских платах показали, что встроенные SATA-контроллеры часто бывают подключены через PCIx4, что не даёт максимально возможной скорости всех 6 SATA-разъёмов.
Повторю, главной проблемой в bus saturation является не выедание «под потолок» полосы, а увеличение latency по мере загрузки шины.
Ну и перед практическими советами, скажу про известные трюки, которые можно встретить в индустриальных хранилищах. Во-первых, если вы будете читать пустой диск, вы будете читать его из «ниоткуда». Системы достаточно умны, чтобы кормить вас нулями из тех областей диска, куда вы никогда не писали.
Во-вторых, во многих системах первая запись хуже последующих из-за всяких механизмов снапшотов, thin provision'а, дедупликации, компрессии, late allocation, sparse placement и т.д. Другими словами, тестировать следует после первичной записи.
В третьих — кеш. Если мы тестируем worst case, то нам нужно знать, как будет вести себя система когда кеш не помогает. Для этого нужно брать такой размер теста, чтобы мы гарантированно читали/писали «мимо кеша», то есть выбивались за объёмы кеша.
Кеш на запись — особая история. Он может копить все запросы на запись (последовательные и случайные) и писать их в комфортном режиме. Единственным методом worst case является «трешинг кеша», то есть посыл запросов на запись в таком объёме и так долго, чтобы write cache перестал стправляться и был вынужден писать данные не в комфортном режиме (объединяя смежные области), а скидывать случайные данные, осуществляя random writing. Добиться этого можно только с помощью многократного превышения области теста над размером кеша.
Вердикт — минимум x10 кеш (откровенно, число взято с потолка, механизма точного расчёта у меня нет).
Разумеется, тест должен быть без участия локального кеша ОС, то есть нам надо запускать тест в режиме, который бы не использовал кеширование. В линуксе это опция O_DIRECT при открытии файла (или диска).
Итого:
1) Мы тестируем worst case — 100% размера диска, который в несколько раз больше предположительного размера кеша на хранилище. Для десктопа это всего лишь «весь диск», для индустриальных хранилищ — LUN или диск виртуальной машины размером от 1Тб и больше. (Хехе, если вы думаете, что 64Гб RAM-кеша это много. ).
2) Мы ведём тест блоком в 4кб размером.
3) Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.На выходе нас интересуют параметры: число IOPS, latency, глубина очереди. Если тест запускался на нескольких хостах, то показатели суммируются (iops и глубина очереди), а для latency берётся либо avg, либо max от показателей по всем хостам.
Тут мы переходим к практической части. Есть утилита fio которая позволяет добиться нужного нам результата.
Нормальный режим fio подразумевает использование т.н. job-файла, т.е. конфига, который описывает как именно выглядит тест. Примеры job-файлов приведены ниже, а пока что обсудим принцип работы fio.
fio выполняет операции над указанным файлом/файлами. Вместо файла может быть указано устройство, т.е. мы можем исключить файловую систему из рассмотрения. Существует несколько режимов тестирования. Нас интересует randwrite, randread и randrw. К сожалению, randrw даёт нам зависимые iops'ы (чтение идёт после записи), так что для получения полностью независимого теста нам придётся делать две параллельные задачи — одна на чтение, вторая на запись (randread, randwrite).
И нам придётся сказать fio делать «preallocation». (см выше про трюки производителей). Дальше мы фиксируем размер блока (4к).
Ещё один параметр — метод доступа к диску. Наиболее быстрым является libaio, именно его мы и будем использовать.
При тесте диска запускать её надо от root'а.
2. Монитор ресурсов
Монитор ресурсов содержит более детальную информацию. Кроме загрузки процессора и оперативной памяти, для каждого процесса в реальном времени отображаются операции чтения и записи на диск, открытые файлы, связанные службы и библиотеки, сетевая активность.
Как запустить мониторинг ресурсов? Есть несколько способов:
- нажать кнопку “Открыть монитор ресурсов”, расположенную на вкладке “Производительность” диспетчера задач;
- ввести команду “resmon” в командной строке или окне “Выполнить”;
- выбрать “Монитор ресурсов” в меню “Средства” диспетчера серверов.
На каждой вкладке монитора ресурсов информация представлена в табличном и графическом виде. Для того, чтобы в таблицах изменить набор столбцов, нужно щелкнуть по заголовку любого столбца правой кнопкой мыши и нажать “Выбрать столбцы”. Если на любой из вкладок пометить нужные процессы флажком, информация в других таблицах будет автоматически отфильтрована по выбранным значениям.
Сведения об активности процессора, памяти, дисков и сети представлены на отдельных вкладках, а вклада “Обзор” содержит сводную информацию по всем компонентам.
![Как запустить мониторинг ресурсов. Основные свойства инструмента]()
Рассмотрим некоторые полезные возможности монитора ресурсов на Windows.
A. Поиск процесса, блокирующего файл
Метрики ускорения
Следующие метрики обеспечивают наблюдение за функцией ускорения на дисках уровня "Премиум":
- Максимальная пропускная способность диска данных с ускорением — ограничение пропускной способности, которого могут достичь диски данных.
- Максимальная пропускная способность диска ОС с ускорением — ограничение пропускной способности, которого может достичь диск ОС.
- Максимальное количество операций ввода-вывода в секунду диска данных с ускорением — ограничение количества операций ввода-вывода в секунду, которого могут достичь диски данных.
- Максимальное количество операций ввода-вывода в секунду диска ОС с ускорением — ограничение количества операций ввода-вывода в секунду, которого может достичь диск ОС.
- Целевая пропускная способность диска данных — ограничение пропускной способности, которого могут достичь диски данных без ускорения.
- Целевая пропускная способность диска ОС — ограничение пропускной способности, которого может достичь диск ОС без ускорения.
- Целевое количество операций ввода-вывода в секунду диска данных — ограничение количества операций ввода-вывода в секунду, которого могут достичь диски данных без ускорения.
- Целевое количество операций ввода-вывода в секунду диска ОС — ограничение количества операций ввода-вывода в секунду, которого могут достичь диски данных без ускорения.
- Процент использованных кредитов для диска данных с ускорением (бит/с) — накопленный процент ускорения пропускной способности, используемый для дисков данных. Создается с 5-минутным интервалом.
- Процент использованных кредитов для диска ОС с ускорением (бит/с) — накопленный процент ускорения пропускной способности, используемый для диска ОС. Создается с 5-минутным интервалом.
- Процент использованных кредитов для операций ввода-вывода для диска данных с ускорением — накопленный процент ускорения операций ввода-вывода в секунду, используемый для диска данных. Создается с 5-минутным интервалом.
- Процент использованных кредитов для операций ввода-вывода для диска ОС с ускорением — накопленный процент ускорения операций ввода-вывода в секунду, используемый для диска ОС. Создается с 5-минутным интервалом.
B. Просмотр дисковой активности
На вкладке “Диск” отображаются операции чтения-записи с диска. На скриншоте показан случай, когда система активно обращается к файлу подкачки “c:/pagefile.sys”, обычно это существенно замедляет работу системы и свидетельствует о нехватки оперативной памяти.
Также следует обратить внимание на показатель “Длина очереди диска”, считается, что он не должен превышать более чем в два раза количество физических дисков. Если на сервере установлен один физический диск, нормальной считается длина очереди 1-2. Частые всплески этого показателя и высокое время активности диска могут говорить о низкой производительности дисковой подсистемы.
![Просмотр дисковой подсистемы через мониторинг ресурсов - простые способы повысить работоспособность Windows]()
Метрики дисковых операций ввода-вывода, пропускной способности и длины очереди
Для получения подробных сведений о виртуальных машинах, дисковых операциях ввода-вывода, пропускной способности и производительности длины очереди можно использовать следующие метрики:
- Длина очереди диска ОС — количество текущих необработанных запросов операций ввода-вывода, ожидающих чтения или записи на диск ОС.
- Скорость чтения с диска ОС (байт/с) — количество байтов, считываемых с диска ОС в секунду.
- Скорость чтения с диска ОС (операций/с) — количество операций ввода, считываемых с диска ОС в секунду.
- Скорость записи на диск ОС (байт/с) — количество байтов, записываемых на диск ОС в секунду.
- Скорость записи на диск ОС (операций/с) — количество операций вывода, записываемых на диск ОС в секунду.
- Длина очереди диска данных — количество текущих необработанных запросов операций ввода-вывода, ожидающих чтения или записи на диски данных.
- Скорость чтения с диска данных (байт/с) — количество байтов, считываемых с дисков данных в секунду.
- Скорость чтения с диска данных (операций/с) — количество операций ввода, считываемых с дисков данных в секунду.
- Скорость записи на диск данных (байт/с) — количество байтов, записываемых на диски данных в секунду.
- Скорость записи на диск данных (операций/с) — количество операций вывода, записываемых на диски данных в секунду.
- Скорость чтения с диска (байт/с) — общее количество байтов, считываемых в секунду со всех дисков, подключенных к виртуальной машине.
- Скорость чтения с диска (операций/с) — общее количество операций ввода, считываемых в секунду со всех дисков, подключенных к виртуальной машине.
- Скорость записи на диск (байт/с) — общее количество байтов, записываемых в секунду на все диски, подключенные к виртуальной машине.
- Скорость записи на диск (операций/с) — общее количество операций ввода, записываемых в секунду на все диски, подключенные к виртуальной машине.
Гибридные тесты
самая вкусная часть:
(внимание! Ошибётесь буквой диска — останетесь без данных)Во время теста мы видим что-то вроде такого:
В квадратных скобках — цифры IOPS'ов. Но радоваться рано — ведь нас интересует latency.На выходе (по Ctrl-C, либо по окончании) мы получим примерно вот такое:
^C
fio: terminating on signal 2
Нас из этого интересует (в минимальном случае) следующее:
read: iops=3526 clat=9063.18 (usec), то есть 9мс.
write: iops=2657 clat=12028.23Не путайте slat и clat. slat — это время отправки запроса (т.е. производительность дискового стека линукса), а clat — это complete latency, то есть та latency, о которой мы говорили. Легко видеть, что чтение явно производительнее записи, да и глубину я указал чрезмерную.
В том же самом примере я снижаю iodepth до 16/16 и получаю:
read 6548 iops, 2432.79usec = 2.4ms
write 5301 iops, 3005.13usec = 3msОчевидно, что глубина в 64 (32+32) оказалась перебором, да таким, что итоговая производительность даже упала. Глубина 32 куда более подходящий вариант для теста.
В данной статье мы расскажем, почему тормозит Windows и опишем популярные системы мониторинга, которые помогут выявить проблему. Данная информация будет полезна не только администраторам серверов на Windows, но и простым пользователям, которые работают с этой системой на своих ПК. Также материал будет полезен всем, кто использует виртуальный сервер на Windows и хочет добиться большей производительности.
Производительность сервера зависит от многих факторов. Условно все источники проблем можно разделить на несколько основных групп, а именно - процессор, оперативная память, жесткий диск, сеть и программное обеспечение. Если причина сбоев не очевидна, то в первую очередь нужно проверить состояние перечисленных компонентов. Для начала рассмотрим штатные инструменты для анализа производительности системы на примере Windows Server 2012 R2.
5. Монитор стабильности системы
Монитор стабильности системы можно рассматривать как дополнение к журналу событий. Для запуска нужно открыть “Панель управления”, перейти в раздел “Центр поддержки” и нажать “Показать журнал стабильности работы” в группе “Обслуживание”.
![Как запустить Мониторинг стабильности системы для поиска неисправностей в Windows]()
События в окне монитора сгруппированы по датам. Если выделить определенную дату, в нижней части экрана отобразится список связанных событий. В зависимости от степени критичности, в верхней части экрана строится линия стабильности, по которой можно оценивать динамику сбоев.
![Просмотр событий в мониторе стабильности системы]()
Описанные инструменты мониторинга взаимно дополняют друг друга, поэтому их комплексное использование позволяет получить наиболее полную информацию о работе системы.
Инструменты, перечисленные в данной статье, могут помочь выявить большинство причин зависания и тормозов Windows. Зачастую поиск и устранение неисправностей помогает восстановить скорость работы системы без переустановки Windows.
На портале Azure представлены метрики, с помощью которых можно получить представление о работе виртуальных машин и дисков. Метрики также можно получить с помощью вызова API. Эта статья разбита на 3 подраздела:
- Метрики дисковых операций ввода-вывода, пропускной способности и длины очереди. Эти метрики позволяют отслеживать производительность хранилища с точки зрения диска и виртуальной машины.
- Метрики для ускорения дисков — это метрики, обеспечивающие наблюдение за функцией ускорения на наших дисках уровня "Премиум".
- Метрики использования операций ввода-вывода хранилища — это метрики, с помощью которых можно диагностировать узкие места в производительности хранилища на дисках.
Все метрики создаются каждую минуту, за исключением метрики процента использованных кредитов для ускорения, которая создается каждые 5 минут.
![Поиск процесса блокирующего файл с помощью мониторинга ресурсов]()
Читайте также: