
Декодирование команды в процессоре это
На этой фазе определяются существенные зависимости (RAW) по данным между командами и преодолеваются несущественные (WAW, WAR), производится распределение команд по буферам команд функциональных устройств.
При декодировании команды создается одна или несколько упорядоченных троек, каждая из которых включает: 1) исполняемую операцию, 2) указатели на операнды, 3) указатель на место помещения результата.
Для преодоления лишнихWAR и WAW зависимостей, возникающих в результате ограниченности логических ресурсов (ячеек памяти, регистров), используется механизм динамического отображения определяемых текстом программы логических ресурсов на физические ресурсы микропроцессора. При данном подходе с одним логическим ресурсом может быть связано несколько значений в различных физических ресурсах, каждое из которых соответствует значению логической величины в один из моментов времени последовательного выполнения программы.
Когда команда создает новое значение для логического регистра, физический ресурс, в который помещается это значение, получает имя. Последующие команды, использующие это значение, снабжаются именем физического ресурса. Данная процедура называется переименованием регистров. Используются два основных способа переименования.
В первом, физический файл регистров больше логического. При необходимости переименования из списка свободных физических регистров берется один и ему сопоставляется соответствующее логическое имя. Если список свободных регистров пуст, диспетчеризация команд приостанавливается до момента появления свободных физических регистров.
Рассмотрим пример реализации данного способа переименования. Пусть требуется выполнить команду sub r3, г3, 5 (из значения регистра г3 вычесть константу 5 и поместить результат в регистр r3). Логические имена регистров начинаются со строчной буквы, а физические — с прописной. Пусть также в момент исполнения команды в таблице регистру r3 соответствует R1. Первым регистром в списке свободных пусть является R2. Поэтому в поле результата команды sub r3, r3, 5 регистр r3 заменяется на R2. Исполнимая команда приобретает вид sub R2, R1, 5. Любая следующая за sub команда, использующая ее результат, должна использовать в качестве операнда R2.
Остается вопрос о возвращении физических регистров в список свободных после того, как из них считаны данные в последний раз. Один из способов связывает счетчик с каждым физическим регистром. Счетчик увеличивается при каждом переименовании операнда в командах, использующих этот физический регистр. Соответственно при использовании операнда значения счетчика уменьшается на 1. При достижении счетчиком нуля физический ресурс должен быть переведен в список свободных.
Второй способ переименования использует одинаковое число логических и физических регистров и поддерживает их однозначное соответствие. В дополнение имеется буфер с одним вхождением для каждой инициированной на исполнение команды. Этот буфер называется переупорядочивающим, так как он используется также для установления порядка команд при прерываниях. Данный буфер можно рассматривать как FIFO очередь, выполненную в виде кольцевого буфера с указателями "начало" и "конец".
Команды помещаются в конец буфера. По завершению команды ее результат заносится в заранее предписанный ей элемент очереди, независимо от места в очереди, занимаемого этим элементом. К моменту достижения командой начала буфера, если она была исполнена, ее результат помещается в регистровый файл, а сама команда удаляется. Команда, находящаяся в буфере и не исполненная в виду отсутствия значения операнда, остается в нем вплоть до получения этого значения. Одновременно может выбираться из очереди или помещаться в нее несколько команд, однако всегда соблюдается дисциплина FIFO.
Значение логического регистра может быть размещено либо в физическом регистре, либо в переупорядочивающем буфере. В момент декодирования команды значению ее результата сопоставляется соответствующая результату позиция упорядоченной тройки команды в элементе переупорядочивающего буфера, в котором размещается рассматриваемая декодированная команда, и делается отметка в таблице соответствия значений, которая указывает, что значение результата может быть найдено в соответствующем элементе буфера. Поля источников и результата команды используются для доступа к полям таблицы. Таблица показывает, что соответствующий регистр содержит требуемую величину либо она может быть найдена в переупорядочивающем буфере. Когда переупорядочивающий буфер полон, диспетчеризация команд приостанавливается.

Рассмотрим выполнение переименования на примере команды sub r3,r3,5. Пусть значение г3 находится или будет находиться в переупорядочивающем буфере в элементе 6. Регистр г3 как источник заменяется на соответствующее поле результата элемента 6 буфера. Команда sub помещается в конец переупорядочивающего буфера, например, в элемент 7. Этот номер затем записывается в таблицу для использования командами-потребителями результата. Следует заметить, что переупорядочивающий буфер фактически вводит потоковую модель вычислений по готовности операндов.
Независимо от способа переименования в суперскалярном процессоре устраняются лишние зависимости по данным.
Моя коллекция старых компьютеров пополняется не очень быстро, поэтому я делаю старый компьютер своими руками.
Он работает полностью на электромагнитных реле и будет состоять из четырех блоков.
На сегодняшний день я закончил уже три из них: АЛУ, регистровый файл и управляющий модуль, который декодирует инструкции раздает остальным блокам указания что делать.
Тёплый ламповый щелкающий звук тактового генератора:
Все инструкции имеют одинаковую ширину, поэтому их чтение получилось совсем простым — достаточно защёлкнуть то, что пришло по шине данных. При этом те же самые реле частично выполняют функции декодирования инструкций, ведь в каждом из них по 4 переключателя.

В результате загрузкой, хранением и декодированием кода инструкции занимаются всего 46 реле, что меньше, чем у HPRC, который я использовал как образец.
Каждая инструкция выполняется за 10 тактов. Так много нужно потому что реле не могут срабатывать по фронту сигнала как микросхемы с несколькими параллельными входами. Приходится выделять целый такт на защёлкивание результата, например. Некоторым командам требуется на 1-2 такта меньше, но я не стал усложнять схему, поэтому эти 10 тактов пробегают всегда:
Команды процессора похожи на ARM — результат вычислений можно поместить в любой регистр. Например, возможна такая безумная операция как XOR PC, A, B. При вызове функции адрес возврата кладётся в регистр L (link register). Обращения к памяти только с помощью отдельных инструкций загрузки (но памяти всё равно пока нет).
Зато, в отличие от ARM, ширина кода инструкции значительно больше ширины регистров. Благодаря этому все загрузки констант, адресов, а также переходы кодируются одной инструкцией.
Есть флаги условного выполнения для переходов — можно проверять знак результата вычислений, равенство нулю и переполнение. Инструкции MOV, CALL и JUMP кодируются почти одинаково, да и делают почти одно и то же. JUMP — это просто пересылка значения в PC. Поэтому есть приятный побочный эффект — для MOV также работает возможность условного выполнения. Т.е. можно выполнить (или не выполнить) MOV NZ, A, 255.
Кроме загрузок и пересылок управляющий модуль умеет подключать регистры к АЛУ и получать результат из него. АЛУ делает сложение, вычитание, OR, XOR, AND, NOT, разные сдвиги на 1 бит. Причём в инструкциях АЛУ есть флаг, который отключает запись результата. То есть команда работает как CMP или TEST на x86, но при этом можно выбрать любую операцию. Например, проверить флаги, как если бы выполнился OR, но не портить никаких регистров.
Сейчас у компьютера нет никакой памяти кроме регистров, поэтому выполняемую инструкцию можно набрать с помощью тумблеров. Зато потом он может делать ее до бесконечности:
Поддерживаются две частоты тактовых импульсов. Более медленный режим нужен для наблюдения за происходящим внутри компьютера:
Никакой отладчик не нужен — дамп регистров считывается просто глазами:
Дальше осталось реализовать запоминающие устройства. Сейчас уже готов корпус для модуля, где они будут располагаться, так что скоро можно будет запустить программу сразу из нескольких инструкций.
Программа в фон-неймановской ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд. Действия, требуемые для выборки (извлечения из основной памяти) и выполнения команды, называют циклом команды. В общем случае цикл команды включает в себя несколько составляющих (этапов):
· формирование адреса следующей команды;
· вычисление адресов операндов;
Перечисленные этапы выполнения команды в дальнейшем будем называть стандартным циклом команды. Отметим, что не все из этапов присутствуют при выполнении любой команды (зависит от типа команды), тем не менее этапы выборки, декодирования, формирования адреса следующей команды и исполнения имеют место всегда.
В определенных ситуациях возможны дополнительные этапы, например, при обработке косвенной адресации.
Кратко охарактеризуем каждый из вышеперечисленных этапов стандартного цикла команды. Следует учитывать, что приводимое описание имеет целью лишь дать представление о сущности каждого из этапов. В то же время распределение функций по разным этапам цикла команды и последовательность выполнения некоторых из них в реальных ВМ могут отличаться от излагаемых.
Этап выборки команды
Цикл любой команды начинается с того, что центральный процессор извлекает команду из памяти, используя адрес, хранящийся в счетчике команд (СК). Двоичный код команды помещается в регистр команды (РК) и с этого момента становится «видимым» для процессора. Система команд многих ВМ предполагает несколько форматов команд, причем в разных форматах команда может занимать 1, 2 или более ячеек, а этап выборки команды можно считать завершенным лишь после того, как в РК будет помещен полный код команды. Информация о фактической длине команды содержится в полях кода операции и способа адресации. Обычно эти поля располагают в первом слове кода команды, и для выяснения необходимости продолжения процесса выборки необходимо предварительное декодирование их содержимого. Такое декодирование может быть произведено после того, как первое слово кода команды окажется в РК. В случае многословного формата команды процесс выборки продолжается вплоть до занесения в РК всех слов команды.
Этап формирования адреса следующей команды
Для фон-неймановских машин характерно размещение соседних команд программы в смежных ячейках памяти. Если извлеченная команда не нарушает естественного порядка выполнения программы, для вычисления адреса следующей выполняемой команды достаточно увеличить содержимое счетчика команд на длину текущей команды, представленную количеством занимаемых кодом команды ячеек памяти. Для однословной команды это описывается микрооперацией: +1СК: СК:= СК+1.
Длина команды, а также то, способна ли она изменить естественный порядок выполнения команд программы, выясняются в ходе предварительного декодирования. Если извлеченная команда способна изменить последовательность выполнения программы (команда условного или безусловного перехода, вызова процедуры и т.п.), процесс формирования адреса следующей команды переносится на этап исполнения операции. В силу сказанного, в ряде ВМ рассматриваемый этап цикла команды следует не за выборкой команды, а находится в конце цикла.
Этап декодирования команды
После выборки команды она должна быть декодирована, для чего ЦП расшифровывает находящийся в РК код команды. В результате декодирования выясняются следующие моменты:
· находится ли в РК полный код команды или требуется дозагрузка остальных слов команды;
· какие последующие действия нужны для выполнения данной команды;
· если команда использует операнды, то откуда они должны быть взяты (номер регистра или адрес ячейки основной памяти);
· если команда формирует результат, то куда этот результат должен быть направлен.
Ответы на два первых вопроса дает расшифровка кода операции, результатом которой может быть унитарный код, где каждый разряд соответствует одной из команд. На практике вместо унитарного кода могут встретиться самые разнообразные формы представления результатов декодирования, например адрес ячейки специальной управляющей памяти, где хранится первая микрокоманда микропрограммы для реализации указанной в команде операции.
Полное выяснение всех аспектов команды, помимо расшифровки кода операции, требует также анализа адресной части команды, включая поле способа адресации.
По результатам декодирования производится подготовка электронных схем ВМ к выполнению предписанных командой действий.
Как оформить тьютора для ребенка законодательно: Условием успешного процесса адаптации ребенка может стать.
Историческое сочинение по периоду истории с 1019-1054 г.: Все эти процессы связаны с деятельностью таких личностей, как.
Поиск по сайту
Программа в фон-неймановской ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд. Действия, требуемые для выборки (извлечения из основной памяти) и выполнения команды, называют циклом команды. В общем случае цикл команды включает в себя несколько составляющих (этапов):
• формирование адреса следующей команды;
• вычисление адресов операндов;
Перечисленные этапы выполнения команды называются стандартным циклом команды. Не все из этапов присутствуют при выполнении любой команды (зависит от типа команды), тем не менее этапы выборки, декодирования, формирования адреса следующей команды и исполнения имеют место всегда.
В определенных ситуациях возможны еще два этапа:
• реакция на прерывание.
Этап выборки команды. Цикл любой команды начинается с того, что центральный процессор извлекает команду из памяти, используя адрес, хранящийся в счетчике команд (СК). Двоичный код команды помещается в регистр команды (РК) и с этого момента становится «видимым» для процессора. Без учета промежуточных пересылок и сигналов управления это можно описать следующим образом: РК:= ОП [(СК)].
ПСтРК: РК(15-8):=0П[(СК)]; ‘Занесение в РК старшего
ПМлРК: РК(7-0):=ОП[(СК)]. ‘Занесение в РК младшего
Этап декодирования команды. После выборки команды она должна быть декодирована, для чего центральный процессор расшифровывает находящийся в регистре команд код команды. В результате декодирования выясняются следующие моменты:
• находится ли в регистре команд полный код команды или требуется дозагрузка остальных слов команды;
• какие последующие действия нужны для выполнения данной команды;
• если команда использует операнды, то откуда они должны быть взяты (номер регистра или адрес ячейки основной памяти);
• если команда формирует результат, то куда этот результат должен быть направлен.
Ответы на два первых вопроса дает расшифровка кода операции, результатом которой может быть унитарный код, где каждый разряд соответствует одной из команд, что можно описать в виде УнитК:=DECOD(Koп). На практике вместо унитарного кода могут встретиться самые разнообразные формы представления результатов декодирования, например адрес ячейки специальной управляющей памяти, где хранится первая микрокоманда микропрограммы для реализации указанной в команде операции.
Полное выяснение всех аспектов команды, помимо расшифровки кода операции, требует также анализа адресной части команды, включая поле способа адресации.
По результатам декодирования производится подготовка электронных схем вычислительной машины к выполнению предписанных командой действий.
Этап вычисления исполнительных адресов. Для физического доступа к основной памяти необходимо подать на ее адресные входы исполнительный адрес ячейки. В то же время, в адресной части команды обычно указывается лишь адресный код, который, в общем случае, отличается от исполнительного адреса. Поэтому для последующего исполнения команды адресный код предварительно должен быть преобразован в соответствующий исполнительный адрес. Такое преобразование составляет содержание рассматриваемого этапа цикла команды. При преобразовании руководствуются способом адресации, указанным в одноименном поле кода команды. Так, в случае индексной адресации для получения исполнительного адреса производится суммирование содержимого адресной части команды и содержимого индексного регистра.
Этап выборки операндов. Данный этап характерен для команд обработки операндов. Вычисленные на предыдущем этапе исполнительные адреса используются для считывания операндов из памяти и занесения в определенные регистры процессора. Например, в случае арифметической команды операнд после извлечения из памяти может быть загружен во входной регистр АЛУ. Однако чаще операнды предварительно заносятся в специальные вспомогательные регистры процессора, а их пересылка на вход АЛУ происходит на этапе исполнения операции.
Этап исполнения операции. На этом этапе реализуется указанная в команде операция. В силу различия сущности каждой из команд ВМ, содержание этого этапа также сугубо индивидуально.
Этап записи результата. Этап записи результата присутствует в цикле тех команд, которые предполагают занесение результата в регистр или ячейку основной памяти. Фактически его можно считать частью этапа исполнения, особенно для тех команд, которые помещают результат сразу в несколько мест.
Этап формирования адреса следующей команды. Для фон-неймановских машин характерно размещение соседних команд программы в смежных ячейках памяти. Если извлеченная команда не нарушает естественного порядка выполнения программы, для вычисления адреса следующей выполняемой команды достаточно увеличить содержимое счетчика команд на длину текущей команды, представленную количеством занимаемых кодом команды ячеек памяти. Для однословной команды это описывается микрооперацией: +1СК: СК:= СК +.
Длина команды, а также то, способна ли она изменить естественный порядок выполнения команд программы, выясняются в ходе предварительного декодирования. Если извлеченная команда способна изменить последовательность выполнения программы (команда условного или безусловного перехода, вызова процедуры и т. п.), процесс формирования адреса следующей команды переносится на этап исполнения операции. В силу сказанного, в ряде вычислительных машин рассматриваемый этап цикла команды следует не за выборкой команды, а находится в конце цикла.
Что ЦП выполняет инструкции программы, находящейся в памяти. Но знаете ли вы, что все они следуют одним и тем же общим правилам? Все они следуют одному и тому же командному циклу, который разделен на три отдельных этапа, называемых «выборка», «декодирование» и «выполнение», которые переводятся как выборка, декодирование и выполнение. Мы объясняем, как работают эти этапы и как они организованы.
Первый этап цикла обучения: выборка
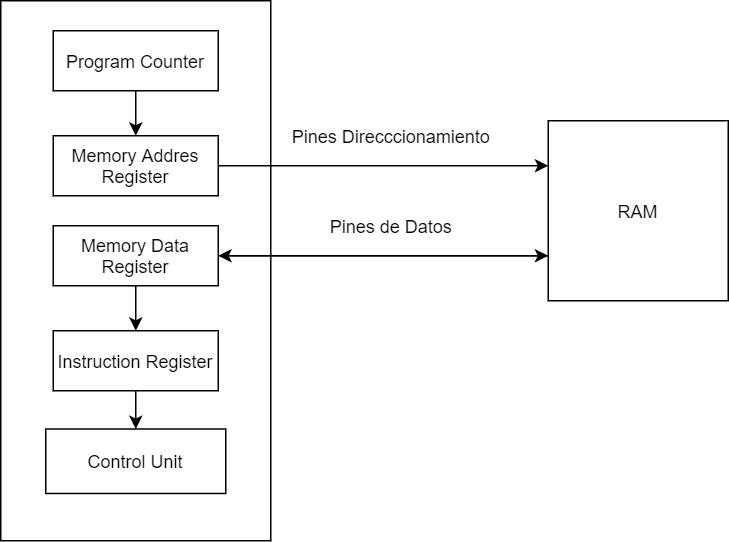
- Программный счетчик или Программный счетчик: Что указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в ОЗУ через адресационные контакты ЦП, которые соединены с адресными контактами самого ОЗУ.
- Регистр данных памяти или регистр данных памяти : В случае, если ЦП должен выполнить чтение памяти, MDR копирует содержимое этого адреса памяти во внутренний регистр ЦП, который является временным регистром передачи, прежде чем его содержимое будет скопировано в регистр команд. MDR, в отличие от MAR, подключается к выводам данных RAM, а не к контактам адресации, и в случае инструкции записи содержимое того, что вы хотите записать в RAM, также записывается в MDR.
- Реестр инструкций: Заключительной частью этапа выборки является запись инструкции в регистр инструкций, из которого блок управления процессором копирует ее содержимое для второго этапа цикла инструкций.
Эти 4 подэтапа происходят во всех процессорах, независимо от их полезности, архитектуры и двоичной совместимости или того, что мы называем ISA.
Визуализация цикла обучения
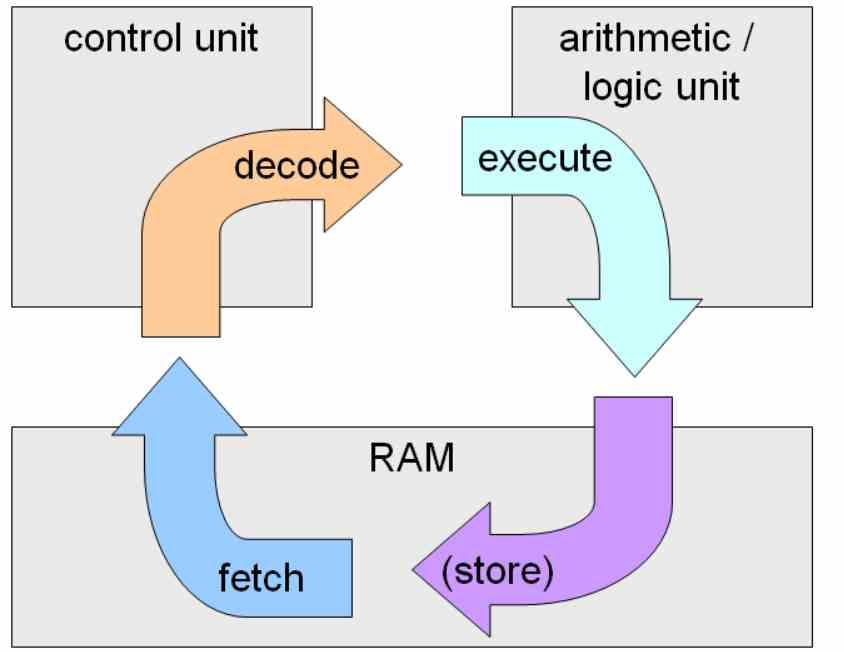
- Получить или захватить: В котором инструкция захватывается из ОЗУ и копируется в процессор.
- Декодирование или декодирование: В котором ранее захваченная инструкция декодируется и отправляется исполнительным блокам.
- Выполнили: Если инструкция разрешена, а результат записан во внутренние регистры процессора или в адрес памяти RAM
Эти три этапа выполняются в каждом процессоре. Существует четвертый этап, который является обратной записью, когда исполнительные блоки записывают результат, но это обычно учитывается на этапе выполнения цикла команд.
Второй этап: декодирование
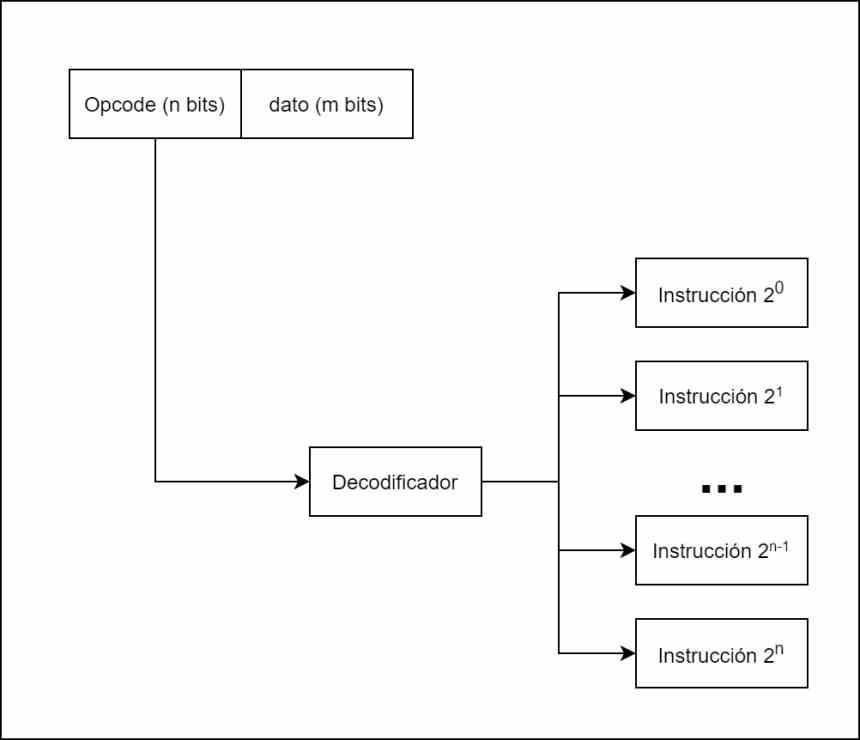
Существуют разные типы инструкций, и не все они делают одно и то же, поэтому в зависимости от типа инструкции нам нужно знать, в какие исполнительные единицы будут отправляться, и самый классический способ сделать это - использовать то, что мы называем декодером. , который принимает каждую инструкцию, делит ее внутри в соответствии с кодом операции или инструкцией и данными или адресом памяти, где она расположена.
Например, на диаграмме выше у нас есть диаграмма процессора всего с 8 инструкциями, которые могут быть закодированы только 3 битами. Каждая из инструкций после декодирования отправляется различным исполнительным блокам, которые их разрешат.

Этот цикл команд является самым сложным из всех и определяет тип архитектуры. В зависимости от того, есть ли у нас сокращенный или сложный набор инструкций, это повлияет на характер блока управления, в зависимости от формата инструкции или от того, сколько одновременно обрабатывается на этапе декодирования, и, следовательно, блок управления будет иметь разная природа. Другой.
Самый простой способ визуализировать происходящее - представить инструкции как поезда, движущиеся по сложной железнодорожной сети, и блок управления, направляющий их к конечной станции, которая является исполнительным блоком, который будет отвечать за выполнение инструкции.
устройство управления
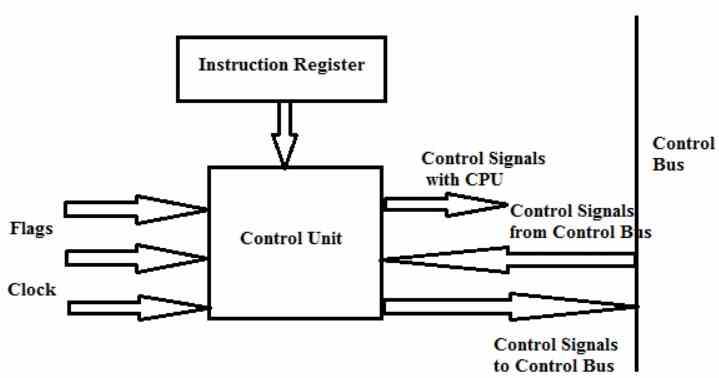
- Они отвечают за координацию движения и порядок, в котором данные перемещаются внутри и вне процессора, а также за различные подблоки, которые за это отвечают.
- В общем, считается, что блоки этапа захвата или Fetch являются частью оборудования, которое мы называем блоком управления, и это оборудование также называется Front-End процессора.
- Он интерпретирует инструкции и отправляет их различным исполнительным устройствам, к которым он подключен.
- Он передается различным ALU и исполнительным блокам процессора, которые действуют
- Он отвечает за захват и декодирование инструкций, а также за запись результатов в регистры, кеши или в соответствующий адрес ОЗУ.

Блок управления декодирует инструкции, и он делает это, потому что каждая инструкция на самом деле является своего рода предложением, в котором сначала идет глагол, а затем прямой объект или объект, на котором выполняется действие. Субъект в конечном итоге исключается на этом внутреннем языке компьютеров, поскольку понимается, что это сам компьютер выполняет его, поэтому каждое число битов представляет собой предложение, в котором первые 1 и 0 соответствуют действию, а единицы Далее идут данные или расположение данных, которыми нужно управлять.
Третий этап: Выполнить
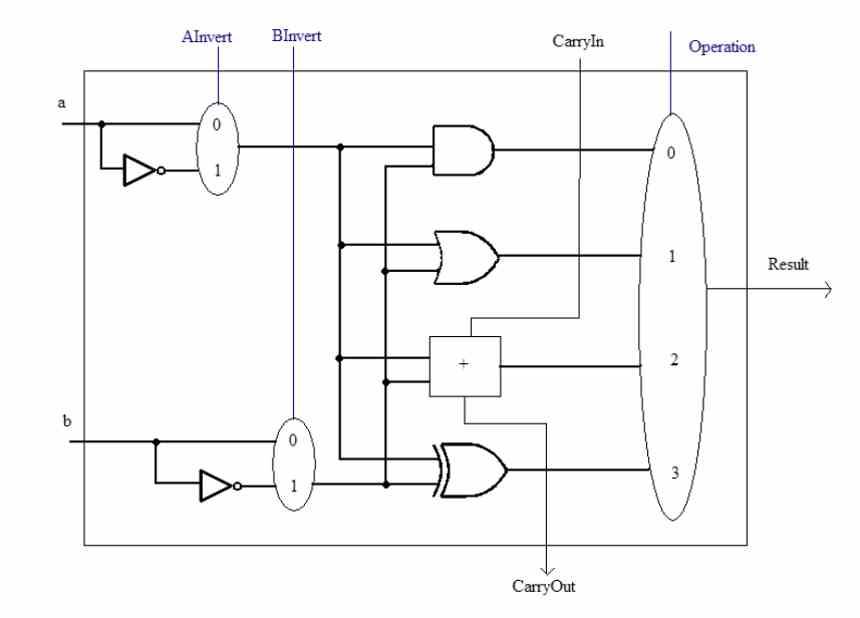
- Инструкции по перемещению долота: В котором осуществляется управление порядком битов, содержащих данные.
- Арифметические инструкции: Там, где выполняются математические и логические операции, они решаются в так называемых ALU или арифметико-логических устройствах.
- Инструкции по прыжкам: В котором изменяется следующее значение программного счетчика, что позволяет использовать код рекурсивно.
- Инструкция к памяти: Они используются процессором для чтения и записи информации из системной памяти.
Другой момент - это форматы инструкций, поскольку инструкция может применяться к данным, скаляру или нескольким данным одновременно, что мы знаем как SIMD. В заключение и в зависимости от формата данных существуют разные типы ALU для выполнения арифметических инструкций, например, сегодня у нас есть целые числа и блоки с плавающей запятой как дифференцированные блоки.
После того, как инструкция завершена, результат записывается в определенный адрес памяти, и выполняется следующий. Некоторые инструкции управляют не значениями памяти, а определенными регистрами. Таким образом, регистр программного счетчика модифицируется инструкциями перехода, если мы хотим читать или записывать данные, то управляются регистры MAR и MDR.
Читайте также: