
Core в видеокарте что значит
Одна из проблем, создаваемых маркетингом производителей видеокарт, заключается в том, что речь идет о количестве ядер, которые GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР имеет, мы предполагаем, что они лгут, чтобы преувеличить цифры. Но что мы понимаем под ядром в графическом процессоре, можем ли мы сравнить их с ядрами графического процессора? ЦП а какие есть отличия?
Когда вы идете покупать видеокарту последней модели, первое, что вы видите, это то, что вам говорят об огромном количестве ядер или процессоров, но что произойдет, если мы скажем вам, что это неправильная номенклатура?
Ловушка, которую делают производители, заключается в том, чтобы вызывать простые ALU или исполнительные блоки под именем ядер, например NVIDIA называет свои ALU ядрами CUDA, которые работают с 32-битными числами с плавающей запятой, но если мы будем строги, мы больше не сможем называть их ядрами или процессорами. Они не соответствуют основным требованиям, чтобы их можно было рассматривать таким образом.
Немного математики
Чтобы понять, что делают тензорные ядра и для чего они используются, нам сперва нужно выяснить, что такое тензоры. Любые микропроцессоры, независимо от типа, выполняют математические операции над числами (сложение, умножение и т.д.).
Иногда эти числа нужно сгруппировать, так как они имеют неразрывную связь друг с другом. Например, когда чип обрабатывает данные для рендеринга, он может иметь дело с одиночными целочисленными значениями (такими как +2 или +115) для коэффициента масштабирования, либо же с группой чисел с плавающей точкой (+0,1, -0,5, + 0.6) для определения координат какой-то точки в трехмерном пространстве. В последнем случае для определения местоположения точки требуются все три части данных.
Простейший тип тензора не имеет измерений и состоит из одного значения – это то же, что и скалярная величина. По мере увеличения количества измерений, появляются другие распространенные математические структуры:
- 1 измерение = вектор
- § 2 измерения = матрица
Строго говоря, скаляр – это тензор 0 x 0, вектор – 1 x 0, а матрица – 1 x 1, но для простоты мы рассмотрим только матричную структуру в контексте наших тензорных ядер в графическом процессоре.
Одна из важнейших математических операций, выполняемых с матрицами – это умножение. Давайте посмотрим, как умножаются две матрицы 4 х 4:
Результатом умножения всегда будет матрица с числом строк, равным числом строк в первой матрице, и числом столбцов, равным числу столбцов во второй. Итак, умножаем этих два массива:
Вам явно не хватит пальцев на руках и ногах, чтобы всё это посчитать.
Как видите, «простое» вычисление произведения матриц состоит из множества умножений и сложений. Поскольку любой процессор, представленный сегодня на рынке, может выполнять обе эти операции, это означает, что любой настольный компьютер, ноутбук или планшет может обрабатывать базовые тензоры.
В то же время, приведенный выше пример содержит 64 умножения и 48 сложений; каждый промежуточный результат вычислений необходимо где-то хранить, прежде чем все их окончательно сложить между собой и, в конце концов, сохранить итоговый результат вычисления тензора. Таким образом, хоть умножение матриц и является математически простым, оно ресурсоёмко – необходимо использовать множество регистров, а кэш должен справляться с большим количеством операций чтения/записи.
Процессоры AMD и Intel на протяжении многих лет предлагали различные расширения: MMX, SSE, а теперь AVX – все они являются SIMD (Single Instruction Multiple Data, «одиночный поток команд, множественный поток данных»), что позволяет процессору одновременно обрабатывать множество чисел с плавающей точкой – то есть именно то, что и нужно для умножения матриц.
Но есть особый тип процессора, специально разработанный для обработки SIMD-операций – да-да, это графический процессор (GPU).
Чем ядро графического процессора отличается от ядра процессора?

Основное различие заключается в том, что ЦП в первую очередь предназначены для параллелизма на уровне команд. , В то время Графические процессоры специализируются на параллелизме на уровне потоков.
Параллелизм на уровне команд предназначен для сокращения времени выполнения команд программы за счет одновременного выполнения нескольких одинаковых команд. Ядра, основанные на параллелизме на уровне потоков, принимают несколько программ одновременно и выполняют их параллельно. ,
Современные процессоры сочетают в своих архитектурах ILP и TLP, в то время как графические процессоры остаются чисто TLP. без какой-либо ILP, чтобы упростить блок управления и иметь возможность разместить как можно больше ядер.
У скоренный процессор (APU)
Чтобы уменьшить физические размеры и производственные затраты, производители нашли способы объединения компонентов электроники в один чип. Последняя итерация этой технологии - устройства System-on-a-Chip (SoC). В этом дизайне вся основная электроника объединена в единую матрицу. Это позволило рост недорогих вычислительных устройств и смартфонов.
Однако предшественником SoC был Ускоренный процессор или APU. Эти устройства объединили процессор и графический процессор в один чип, чтобы сформировать объединенный процессор. Это не только снижает стоимость, но и повышает эффективность. Минимизация физического расстояния между ними обеспечивает более быструю передачу данных и повышение производительности.
Поскольку графические процессоры оптимизированы для более высоких скоростей вычислений, центральный процессор может перенести часть работы на графический процессор. В отдельной установке выигрыш в эффективности от этого распределения нагрузки будет подорван физическим расстоянием и скоростью передачи данных между ними. Тем не менее, объединенная APU делает эти выгоды возможными.
Несмотря на это, APU не дает такой же производительности, как выделенный процессор и графический процессор. Вместо этого их лучше всего рассматривать как шаг вперед от интегрированной графики. Это делает APU доступным обновлением для тех, кто хочет обновить свои ПК.
Производитель процессоров AMD разрабатывает APU. Однако они были не единственными, кто объединял процессоры таким образом. Intel также начала интегрировать CPU и GPU. Основным отличием было то, что AMD выпустила выделенную линейку APU, а Intel и другие компании объединили их в свои линейки продуктов.
Тензорные ядра в потребительских GPU (GeForce RTX)
Но что если я куплю графическую карту Nvidia GeForce RTX, не являясь ни астрофизиком, решающим задачи римановых многообразий, ни специалистом, экспериментирующим с глубинами свёрточных нейронных сетей. Как я могу использовать тензорные ядра?
Чаще всего они не применяются для обычного рендеринга, кодирования или декодирования видео, поэтому может показаться, что вы потратили деньги на бесполезную функцию. Однако Nvidia встроила тензорные ядра в свои потребительские продукты в 2018 году (Turing GeForce RTX), внедрив при этом DLSS — Deep Learning Super Sampling.

Принцип прост: рендерим кадр в довольно низком разрешении, а после завершения повышаем разрешение конечного результата так, чтобы он совпадал с «родными» размерами экрана монитора (например, рендерим в 1080p, а затем изменяем размер до 1400p). Благодаря этому повышается производительность, ведь обрабатывается меньшее количество пикселей, а на экране всё равно получается красивое изображение.
Консоли имели такую функцию уже многие годы, и многие современные игры для PC тоже обеспечивают эту возможность. В Assassin's Creed: Odyssey компании Ubisoft можно уменьшить разрешение рендеринга до всего 50% от разрешения монитора. К сожалению, результаты выглядят не так красиво. Вот как игра выглядит в 4K с максимальными настройками графики:

В высоких разрешениях текстуры выглядят красивее, потому что сохраняют в себе больше деталей. Однако для вывода этих пикселей на экран требуется много обработки. Теперь взгляните на то, что происходит при установке рендеринга на 1080p (25% от предыдущего количества пикселей), с использованием шейдеров в конце для растягивания картинки до 4K.

Из-за сжатия jpeg разница может быть заметной не сразу, но видно, что броня персонажа и скала вдали выглядят размытыми. Давайте приблизим часть изображения для более детального изучения:

Изображение слева отрендерено в 4K; изображение справа — это 1080p, растянутые до 4K. Разница гораздо заметнее в движении, потому что смягчение всех деталей быстро превращается в размытую кашу. Частично чёткость можно восстановить благодаря эффекту резкости драйверов графической карты, но лучше бы нам вообще не приходилось этим не заниматься.
Именно здесь в ход идёт DLSS — в первой версии этой технологии Nvidia анализировались несколько выбранных игр; они запускались в высоких разрешениях, низких разрешениях, со сглаживанием и без него. Во всех этих режимах был сгенерирован набор изображений, загруженный затем в суперкомпьютеры компании, которые использовали нейронную сеть, чтобы определить, каким образом лучше всего превратить изображение в разрешении 1080p в идеальную картинку в более высоком разрешении.

Нужно сказать, что DLSS 1.0 не был идеальным: детали часто терялись и в некоторых местах возникало странное мерцание. К тому же он не использовал сами тензорные ядра графической карты (он выполнялся в сети Nvidia) и каждой игре с поддержкой DLSS для генерации алгоритма повышения масштаба требовалось отдельное исследование компанией Nvidia.

Когда в начале 2020 года вышла версия 2.0, в неё были внесены серьёзные улучшения. Самым важным стало то, что суперкомпьютеры Nvidia теперь использовались только для создания общего алгоритма увеличения масштаба — в новой версии DLSS для обработки пикселей с помощью нейронной модели (тензорными ядрами GPU) используются данные из отрендеренного кадра.

Нас впечатляют возможности DLSS 2.0, но пока его поддерживает очень мало игр — на момент написания статьи их было всего 12. Всё больше разработчиков хочет реализовать его в своих будущих играх, и на то есть причины.
Благодаря любому увеличению масштаба можно добиться серьёзного роста производительности, поэтому можно быть уверенными, что DLSS продолжит эволюционировать.

Хотя визуальные результаты работы DLSS не всегда идеальны, освободив занятые рендерингом ресурсы, разработчики смогут добавить больше визуальных эффектов или обеспечить один уровень графики на более широком диапазоне платформ.
Например, DLSS часто рекламируют вместе с трассировкой лучей (ray tracing) в играх с «поддержкой RTX». Карты GeForce RTX содержат дополнительные вычислительные блоки, называемые RT-ядрами, это специализированные логические блоки для ускорения вычислений пересечения луча с треугольником и обхода иерархии ограничивающих объёмов (bounding volume hierarchy, BVH). Эти два процесса являются очень длительными процедурами, определяющими способ взаимодействия света с другими объектами сцены.
Как мы выяснили, ray tracing — очень трудоёмкий процесс, поэтому чтобы обеспечить в играх приемлемый уровень частоты кадров, разработчики должны ограничить количество лучей и выполняемых в сцене отражений. При выполнении этого процесса могут создаваться зернистые изображения, поэтому необходимо применять алгоритм устранения шумов, что повышает сложность обработки. Ожидается, что тензорные ядра повысят производительность этого процесса благодаря устранению шумов с использованием ИИ, однако это ещё предстоит реализовать: большинство современных приложений по-прежнему использует для этой задачи ядра CUDA. С другой стороны, благодаря тому, что DLSS 2.0 становится вполне практичной техникой повышения размера, тензорные ядра можно будет эффективно использовать для повышения частоты кадров после применения в сцене трассировки лучей.
Существуют и другие планы по использованию тензорных ядер карт GeForce RTX, например, улучшение анимаций персонажей или симуляция тканей. Но как и в случае с DLSS 1.0, пройдёт ещё немало времени, прежде чем появятся сотни игр, использующие специализированные матричные вычисления на GPU.
Начало весьма многообещающее
Итак, мы имеем – тензорные ядра, изящные аппаратные частицы, которые пока встречаются лишь в некоторых видеокартах потребительского уровня. Изменится ли что-то в будущем? Поскольку Nvidia уже значительно повысила производительность каждого тензорного ядра в своей новейшей архитектуре Ampere, есть большая вероятность, что мы увидим больше моделей с тензорными ядрами среднего и бюджетного ценового класса.
AMD и Intel пока вовсе не используют их в своих GPU, но возможно в будущем мы увидим их вариант реализации. У AMD есть система повышения резкости или улучшения деталей в готовых кадрах ценой небольшого снижения производительности, так что они вполне могут просто придерживаться этого пути – тем более, что разработчикам нет нужды в интеграции этой системы, она просто включается в драйверах.
Также существует мнение, что площадь кристалла GPU рациональней использовать просто под дополнительные шейдерные ядра, что Nvidia и сделала в бюджетных версиях чипов Turing. Вместо тензорных ядер в таких картах как GeForce GTX 1650 стоят дополнительные шейдеры FP16.
Пока же, если вы хотите воспользоваться всеми преимуществами сверхбыстрой GEMM-обработки, у вас есть два варианта: либо накупить себе кучу огромных многоядерных процессоров, либо купить всего один GPU с тензорными ядрами.

В течение последних трёх лет Nvidia создавала графические чипы, в которых помимо обычных ядер, используемых для шейдеров, устанавливались дополнительные. Эти ядра, называемые тензорными, уже есть в тысячах настольных PC, ноутбуков, рабочих станций и дата-центров по всему миру. Но что же они делают и для чего применяются? Нужны ли они вообще в графических картах?
Сегодня мы объясним, что такое тензор, и как тензорные ядра используются в мире графики и глубокого обучения.
Умнее, чем просто калькулятор
В мире графики огромное количество данных необходимо в одно и то же время передавать и обрабатывать в виде векторов. Возможность GPU выполнять такую параллельную обработку делает их идеальными для вычисления тензоров, и все они сегодня поддерживают GEMM (General Matrix Multiplication, подпрограмма умножения матриц).
Это алгоритм, при котором произведение двух матриц результируется третьей матрицей. На формат матриц, количество их строк и столбцов, накладываются жёсткие ограничения.
Требования GEMM для строк и столбцов: матрица A (MxK), матрица B (KxN), матрица C (MxN)
Алгоритмы, используемые для операций с матрицами, как правило, работают лучше, когда матрицы не очень большие и квадратные (например, массив 10 x 10 обработается легче, чем 50 x 2). Но в любом случае, лучше всего эти алгоритмы работают на специально заточенном для таких операций оборудовании.
В декабре 2017 года Nvidia выпустила видеокарту с GPU на новой архитектуре Volta. Она был ориентирована на профессиональные рынки, поэтому ни в одной из моделей GeForce этот чип
никогда не использовался. Особенностью его было то, что это был первый графический процессор, который имел ядра только для тензорных вычислений.
Заложен ли в названии архитектуры какой-то смысл – мы без понятия, но тензорные ядра в ней обрабатывали 64 GEMM за такт на матрицах 4 x 4, содержащих значения FP16 (16-битные числа с плавающей точкой) или умножение FP16 со сложением FP32. Такие тензоры очень маленькие, поэтому при обработке фактических множеств данных, ядра обрабатывают большие матрицы по частям, формируя окончательный результат.
В начале этого года в GPU для дата-центров A100 дебютировала архитектура Ampere, и на этот раз Nvidia улучшила производительность (256 GEMM за цикл вместо 64), добавила дополнительные форматы данных и возможность очень быстро обрабатывать разреженные тензоры (матрицы с большим количеством нулей).
Для программистов доступ к тензорным ядрам в любом из чипов Volta, Turing или Ampere прост: соответствующий флаг в коде сообщает API и драйверам, что вы хотите задействовать тензорные ядра; ядра должны поддерживать ваш тип данных, а размерность матриц должна быть кратна 8. При удовлетворении этих условий, всем остальным займётся оборудование.
Все это прекрасно, но насколько тензорные ядра обрабатывают GEMM лучше, чем обычные ядра GPU?
Когда Volta только появилась, портал Anandtech провёл сравнительный математический тест трёх карт: новой Volta, топовой Pascal и старой Maxwell.
Понятие «точность» (precision) определяется количеством бит, используемых для чисел с плавающей точкой в матрицах: двойная (double) равно 64, одинарная (single) – 32 бита, и т.д. Горизонтальная шкала – шкала FLOPs, максимального количества операций с плавающей точкой в секунду (1 GEMM равен 3 FLOP).
Просто посмотрите, что получилось при использовании тензорных ядер вместо так называемых стандартных ядер CUDA! Они неоспоримо лучше справляются с подобными задачами, но в чём же их практическая польза?
Всё станет лучше с помощью математики
Тензорные вычисления крайне востребованы в физике и инженерии, с их помощью решаются различные сложные задачи в области механики жидкости, электромагнетизма или астрофизики,
но компьютеры, которые использовались для таких вычислений, обычно выполняли матричные операции с помощью больших процессорных кластеров.
Еще одна излюбленная область использования тензоров – это машинное обучение, особенно глубокое (deep machine learning). Это работа с громадными объёмами данных в гигантских массивах, называемых нейронными сетями. Связям между различными значениями данных присваивается определенный вес – число, выражающее значимость конкретной связи.
Поэтому, когда анализируется взаимодействие всех сотен или тысяч связей, каждый фрагмент данных в сети умножается на все возможные веса связей. Другими словами, происходит умножение двух матриц – а это классическая тензорная математика!
Именно поэтому все суперкомпьютеры для глубокого обучения оснащаются GPU, и почти всегда от Nvidia. Но некоторые компании пошли еще дальше, и создали свои собственные процессоры с тензорными ядрами. Так, например, Google в 2016 анонсировал свой первый TPU (Tensor Processing Unit, тензорный процессор), но эти чипы настолько узкоспециализированы, что кроме как выполнять операции с матрицами, больше ничего не умеют.
Итак, что такое ядро или процессор в графическом процессоре?
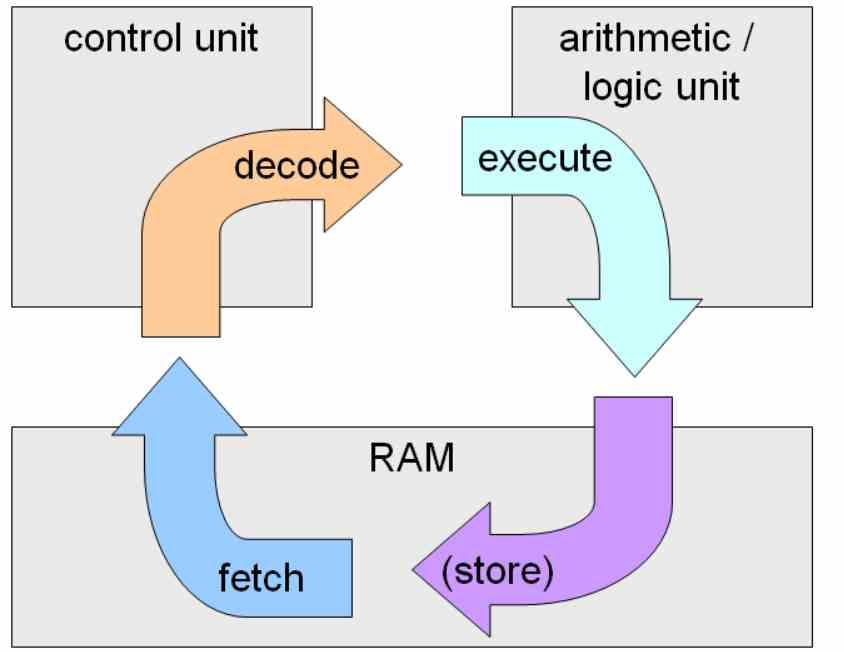
Ядро или процессор - это любая интегральная схема или ее часть, которые вместе могут выполнять полный цикл команд, это захват команд из памяти, их декодирование и их выполнение.
ALU - это всего лишь исполнительный блок, поэтому он должен быть полноценным ядром. А что считать полноценным ядром? Ну то, что NVIDIA называет SM, Intel вызывает Sub-Slice и AMD Вычислительный блок.
Причина этого в том, что именно в этих модулях происходит весь цикл команд, а не в ALU или исполнительных модулях, которые отвечают только за часть цикла команд.
Центральный процессор ( CPU )
Центральный процессор, или ЦП, является основным мозгом компьютера. В ранних компьютерах процессор был распределен по нескольким чипам. Тем не менее, для повышения эффективности и снижения производственных затрат, процессор теперь находится на одном кристалле. Эти маленькие процессоры также называют микропроцессорами.
Сокращение площади процессора также позволило проектировать и производить более компактные устройства меньшего размера. Настольные компьютеры можно рассматривать как устройства «все в одном», ноутбуки по-прежнему становятся тоньше, но при этом становятся более функциональными, а некоторые смартфоны стали более мощными, чем их традиционные аналоги.
ЦП выполняет основные вычислительные процессы для вашего компьютера. Инструкции, хранящиеся в оперативной памяти вашего устройства, отправляются на процессор для выполнения. Это система из трех частей, состоящая из этапов получения, декодирования и выполнения. В широком смысле это означает получение входных данных, понимание того, что они из себя представляют, и создание желаемого результата.
Используя это, ваш процессор помогает всем: от загрузки операционной системы, открытия программ и даже до выполнения расчетов с помощью электронных таблиц. Такие ресурсоемкие операции, как видеоигры, создают наибольшую нагрузку на ваш процессор. Вот почему тесты бенчмаркинга обычно проводятся по игровым стандартам.
Процессоры доступны во многих вариантах - от энергоэффективных одноядерных чипов до высокопроизводительных с несколькими ядрями. Intel использует свою технологию Hyper-Threading, чтобы заставить четырехъядерный процессор работать так, как если бы он был восьмиъядерным. Это помогает выжать максимум мощности и эффективности из вашего процессора.
Графический процессор (GPU)
Несмотря на все успехи, достигнутые процессорами за последнее десятилетие, они все еще имеют недостатки; а именно графика. Процессоры берут ввод и работают через него линейными шагами. Однако обработка графики требует одновременной обработки нескольких данных. Графический процессор (GPU) снижает нагрузку на процессор и повышает производительность видео.
Большинство компьютеров и ноутбуков оснащены процессором и графическим процессором, но это не всегда так. Иногда, особенно в более низких ценовых диапазонах, ваш компьютер будет иметь встроенную графику вместо выделенного графического процессора.
И GPU, и CPU выполняют сходные функции, но то, как они это делают, отличается. Параллельная структура GPU специально адаптирована для этой цели. Это помогает устройству достигать миллиардов вычислений в секунду, необходимых для игр и воспроизведения видео. Графический процессор часто располагается на отдельной видеокарте , которая также имеет собственную оперативную память.
Это позволяет карте хранить данные, которые она генерирует. Также благодаря этой встроенной оперативной памяти графический процессор может генерировать буфер, сохраняя готовые изображения до тех пор, пока вам не понадобится их отображать. Это особенно полезно, например, при просмотре видео.
Поскольку видеокарте легко заменяются, это часто считается одним из лучших обновлений, которые вы можете сделать для своего компьютера. Высокопроизводительные видеокарты обычно имеют высокую цену, тем не менее, есть и видеокарты для дешевых игр , что дает возможность к доступу ко многим играм.
Краткий урок математики
Чтобы понять, чем же заняты тензорные ядра и для чего их можно использовать, нам сначала разобраться, что такое тензоры. Все микропроцессоры, какую бы задачу они ни выполняли, производят математические операции над числами (сложение, умножение и т.д.).
Иногда эти числа необходимо группировать, потому что они обладают определённым значением друг для друга. Например, когда чип обрабатывает данные для рендеринга графики, он может иметь дело с отдельными целочисленными значениями (допустим, +2 или +115) в качестве коэффициента масштабирования или с группой чисел с плавающей точкой (+0.1, -0.5, +0.6) в качестве координат точки в 3D-пространстве. Во втором случае для позиции точки требуются все три элемента данных.
Тензор — это математический объект, описывающий соотношения между другими математическими объектами, связанными друг с другом. Обычно они отображаются в виде массива чисел, размерность которого показана ниже.

Простейший тип тензора имеет нулевую размерность и состоит из единственного значения; иначе он называется скалярной величиной. При увеличении количества размерностей мы сталкиваемся с другими распространёнными математическими структурами:
- 1 измерение = вектор
- 2 измерения = матрица
Одна из самых важных математических операций, выполняемых над матрицами — это умножение (или произведение). Давайте взглянем на то, как перемножаются друг на друга две матрицы, имеющие по четыре строки и столбца данных:

Окончательным результатом умножения всегда будет то же количество строк, что и в первой матрице, и то же количество столбцов, что и во второй. Как же перемножить эти два массива? Вот так:

На пальцах это посчитать не удастся
Как вы видите, вычисление «простого» произведения матриц состоит из целой кучи небольших умножений и сложений. Так как любой современный центральных процессор может выполнять обе эти операции, простейшие тензоры способен выполнять каждый настольный компьютер, ноутбук или планшет.
Однако показанный выше пример содержит 64 умножений и 48 сложений; каждое небольшое произведение даёт значение, которое нужно где то хранить, прежде чем его можно будет сложить с другими тремя небольшими произведениями, чтобы позже можно было сохранить окончательное значение тензора. Поэтому, несмотря на математическую простоту умножений матриц, они затратны вычислительно — необходимо использовать множество регистров, а кэш должен уметь справляться с кучей операций считывания и записи.

Архитектура Intel Sandy Bridge, в которой впервые появились расширения AVX
На протяжении многих лет в процессорах AMD и Intel появлялись различные расширения (MMX, SSE, а теперь и AVX — все они являются SIMD, single instruction multiple data), позволяющие процессору одновременно обрабатывать множество чисел с плавающей запятой; это как раз то, что требуется для перемножения матриц.
Но существует особый тип процессоров, который специально спроектирован для обработки операций SIMD: графические процессоры (graphics processing unit, GPU).
APU vs CPU vs GPU: теперь вы знаете всё!
Теперь мы рассмотрели основные процессоры, и вы знаете, что для вашего компьютера существует множество вариантов. Если вы выберете отдельный процессор и графический процессор, вы, скорее всего, потратите больше, но также получите более значительный прирост производительности.
Выбор APU является компромиссом между бюджетом и производительностью. Если вы в настоящее время работаете с интегрированной графикой, то APU - это достойное обновление, которое не подорвет ваш карман.
Однако, прежде чем инвестировать в APU, CPU или GPU, вы должны быть уверены, что выбираете наиболее выгодное предложение для вашей машины.
Если статья была для вас полезной, просим поставить лайк и подписаться на наш канал . Также посетите наш сайт , чтобы увидеть больше подобного контента.
Думаю, для большинства пользователей это уже не секрет, но все-таки мы рассмотрим, и вникнемся за что отвечают те или иные блоки и сами гигабайты.
- Ширина шины памяти , измеряется в битах — количество бит информации, передаваемой за такт. Важный параметр в производительности карты.
- объём видеопамяти , измеряется в мегабайтах — объём собственной оперативной памяти видеокарты. Больший объём далеко не всегда означает большую производительность.
- частоты ядра и памяти — измеряются в мегагерцах, чем больше, тем быстрее видеокарта будет обрабатывать информацию.
- текстурнаяипиксельнаяскорость заполнения , измеряется в млн. пикселей в секунду, показывает количество выводимой информации в единицу времени.
- Количество вычислительных (шейдерных) блоков или процессоров
- Блоки текстурирования (TMU)
- Блоки операций растеризации (ROP)
- И пожалуй тип памяти (GDDR-X или HBM-X)
- Количество вычислительных (шейдерных) блоков или процессоров
Пожалуй, сейчас эти блоки — главные части видеочипа. Они выполняют специальные программы, известные как шейдеры. Причём, если раньше пиксельные шейдеры выполняли блоки пиксельных шейдеров, а вершинные — вершинные блоки, то с некоторого времени графические архитектуры были унифицированы, и эти универсальные вычислительные блоки стали заниматься различными расчётами: вершинными, пиксельными, геометрическими и даже универсальными вычислениями.
Впервые унифицированная архитектура была применена в видеочипе игровой консоли Microsoft Xbox 360 , этот графический процессор был разработан компанией ATI (впоследствии купленной AMD ). А в видеочипах для персональных компьютеров унифицированные шейдерные блоки появились ещё в плате NVIDIA GeForce 8800 . И с тех пор все новые видеочипы основаны на унифицированной архитектуре, которая имеет универсальный код для разных шейдерных программ (вершинных, пиксельных, геометрических и пр.), и соответствующие унифицированные процессоры могут выполнить любые программы.
По числу вычислительных блоков и их частоте можно сравнивать математическую производительность разных видеокарт. Большая часть игр сейчас ограничена производительностью исполнения пиксельных шейдеров, поэтому количество этих блоков весьма важно. К примеру, если одна модель видеокарты основана на GPU с 384 вычислительными процессорами в его составе, а другая из той же линейки имеет GPU с 192 вычислительными блоками, то при равной частоте вторая будет вдвое медленнее обрабатывать любой тип шейдеров, и в целом будет настолько же производительнее.
Эти блоки GPU работают совместно с вычислительными процессорами, ими осуществляется выборка и фильтрация текстурных и прочих данных, необходимых для построения сцены и универсальных вычислений. Число текстурных блоков в видеочипе определяет текстурную производительность — то есть скорость выборки текселей из текстур.
Хотя в последнее время больший упор делается на математические расчеты, а часть текстур заменяется процедурными, нагрузка на блоки TMU и сейчас довольно велика, так как кроме основных текстур, выборки необходимо делать и из карт нормалей и смещений, а также внеэкранных буферов рендеринга render target.
С учётом упора многих игр в том числе и в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность также являются одними из важнейших параметров для видеочипов. Особенное влияние этот параметр оказывает на скорость рендеринга картинки при использовании анизотропной фильтрации, требующие дополнительных текстурных выборок, а также при сложных алгоритмах мягких теней и новомодных алгоритмах вроде Screen Space Ambient Occlusion.
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как мы уже отмечали выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт всех времён. И хотя в последнее время её значение также несколько снизилось, всё ещё попадаются случаи, когда производительность приложений зависит от скорости и количества блоков ROP. Чаще всего это объясняется активным использованием фильтров постобработки и включенным антиалиасингом при высоких игровых настройках.
В бюджетных видеокартах в основном стоит GDDR3 , но и бывает GDDR5 , соответственно лучше GDDR5 , но в наше время, лучший тип памяти это - GDDR6 или HBM2 (пока слишком дорогая).
Это пусть и не самый главный, но далеко не маловажный аспект в видеопамяти, благодаря охлаждению, будут более приемлемые температуры и более низкий уровень шума. Что сделает видеокарту, более приятной и не сбрасывающей вольтаж/частоты, соответственно подарит ей более стабильную и долгую работу.
Ну и не забываем про тип подключения основной - PCI-Express х16 3.0 пока что, но уже у AMD есть PCI-Express х16 4.0 и к примеру для RX 5500 XT этот параметр важен, видеокарта становится производительнее до 40% , но это особенность видеокарты, ведь дорожек у нее не ( х16 ), а всего ( х8 ).
Вывод таков, всегда выбирайте те или иные видеокарты с умом, и желательно предварительно просматривать тесты в играх, которые необходимы, или можете захватить сразу все, чтобы было видно результат "на лицо".
В течение последних трех лет Nvidia производит графические чипы с дополнительными ядрами, помимо обычных, используемых для шейдеров. Эти загадочные блоки, известные как тензорные ядра, можно найти в тысячах настольных ПК, ноутбуках, рабочих станциях и дата-центрах по всему миру. Но что они собой представляют и для чего используются? Нужны ли они вообще в наших видеокартах?
Сегодня мы объясним, что такое тензор и как тензорные ядра применяются в мире графики и глубокого обучения.
Работа на графическом процессоре по сравнению с работой на процессоре
В большинстве случаев, когда поток достигает ALU ядра графического процессора, он содержит инструкцию и данные напрямую, но бывают случаи, когда данные необходимо искать в кэшах и в памяти, чтобы избежать задержек в выполнении планировщика ядра графического процессора. то, что он делает, называется циклическим перебором и передает этот поток для последующего выполнения.
В ЦП это невозможно сделать, причина в том, что потоки представляют собой очень сложные наборы инструкций и с высокой степенью зависимости между ними, в то время как в графическом процессоре для этого нет проблем, поскольку потоки выполнения чрезвычайно малы, поскольку они самодостаточны в «ядрах» много раз на протяжении одной инструкции.
На самом деле графические процессоры собирают набор ядер в так называемой волне, назначая каждую волну ALU графического процессора, они выполняются каскадно и по порядку. Каждое ядро имеет ограничение по потокам или ядрам, которые будут держать его занятым некоторое время, пока ему не понадобится новый список, таким образом избегая того, что огромное количество ядер постоянно делает запросы к памяти.
Когда приходит время покупать новый компьютер, знание разницы между процессором, графическим процессором и APU является значительным преимуществом. Это может даже сэкономить деньги, особенно, если вы планируете собрать свой собственный компьютер.
Данные технологии часто группируются, но выполняют отдельные роли. Знание функции каждого из них, поможет вам в выборе.
Итак, в чем именно разница между APU, CPU и GPU?
Умнее, чем обычный калькулятор?
В мире графики одновременно необходимо передавать и обрабатывать огромные объёмы информации в виде векторов. Благодаря своей способности параллельной обработки GPU идеально подходят для обработки тензоров; все современные графические процессоры поддерживают функциональность под названием GEMM (General Matrix Multiplication).
Это «склеенная» операция, при которой перемножаются две матрицы, а результат затем накапливается с другой матрицей. Существуют важные ограничения на формат матриц и все они связаны с количеством строк и столбцов каждой матрицы.

Требования GEMM к строкам и столбцам: матрица A(m x k), матрица B(k x n), матрица C(m x n)
Алгоритмы, используемые для выполнения операций с матрицами, обычно лучше всего работают, когда матрицы квадратные (например, массив 10 x 10 будет работать лучше, чем 50 x 2) и довольно небольшие по размеру. Но они всё равно будут работать лучше, если обрабатываются на оборудовании, которое предназначено исключительно для таких операций.
В декабре 2017 года Nvidia выпустила графическую карту с GPU, имеющим новую архитектуру Volta. Она была нацелена на профессиональные рынки, поэтому этот чип не использовался в моделях GeForce. Уникальным он был потому, что стал первым графическим процессором, имеющим ядра только для выполнения тензорных вычислений.

Графическая карта Nvidia Titan V, на которой установлен чип GV100 Volta. Да на ней можно запустить Crysis
Тензорные ядра Nvidia были предназначены для выполнения по 64 GEMM за тактовый цикл с матрицами 4 x 4, содержащими значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 со сложением FP32. Такие тензоры очень малы по размеру, поэтому при обработке настоящих множеств данных ядра обрабатывают небольшие части больших матриц, выстраивая окончательный ответ.

В начале этого года архитектура Ampere дебютировала в графическом процессоре дата-центра A100, и на этот раз Nvidia повысила производительность (256 GEMM за цикл вместо 64), добавила новые форматы данных и возможность очень быстрой обработки разреженных тензоров (sparse tensor) (матриц со множеством нулей).
Программисты могут получить доступ к тензорным ядрам чипов Volta, Turing и Ampere очень просто: код всего лишь должен использовать флаг, сообщающий API и драйверам, что нужно применять тензорные ядра, тип данных должен поддерживаться ядрами, а размерности матриц должны быть кратными 8. При выполнении всех этих условий всем остальным займётся оборудование.
Всё это здорово, но насколько тензорные ядра лучше в обработке GEMM, чем обычные ядра GPU?
Когда появилась Volta, сайт Anandtech провёл математические тесты трёх карт Nvidia: новой Volta, самой мощной из линейки Pascal и старой карты Maxwell.
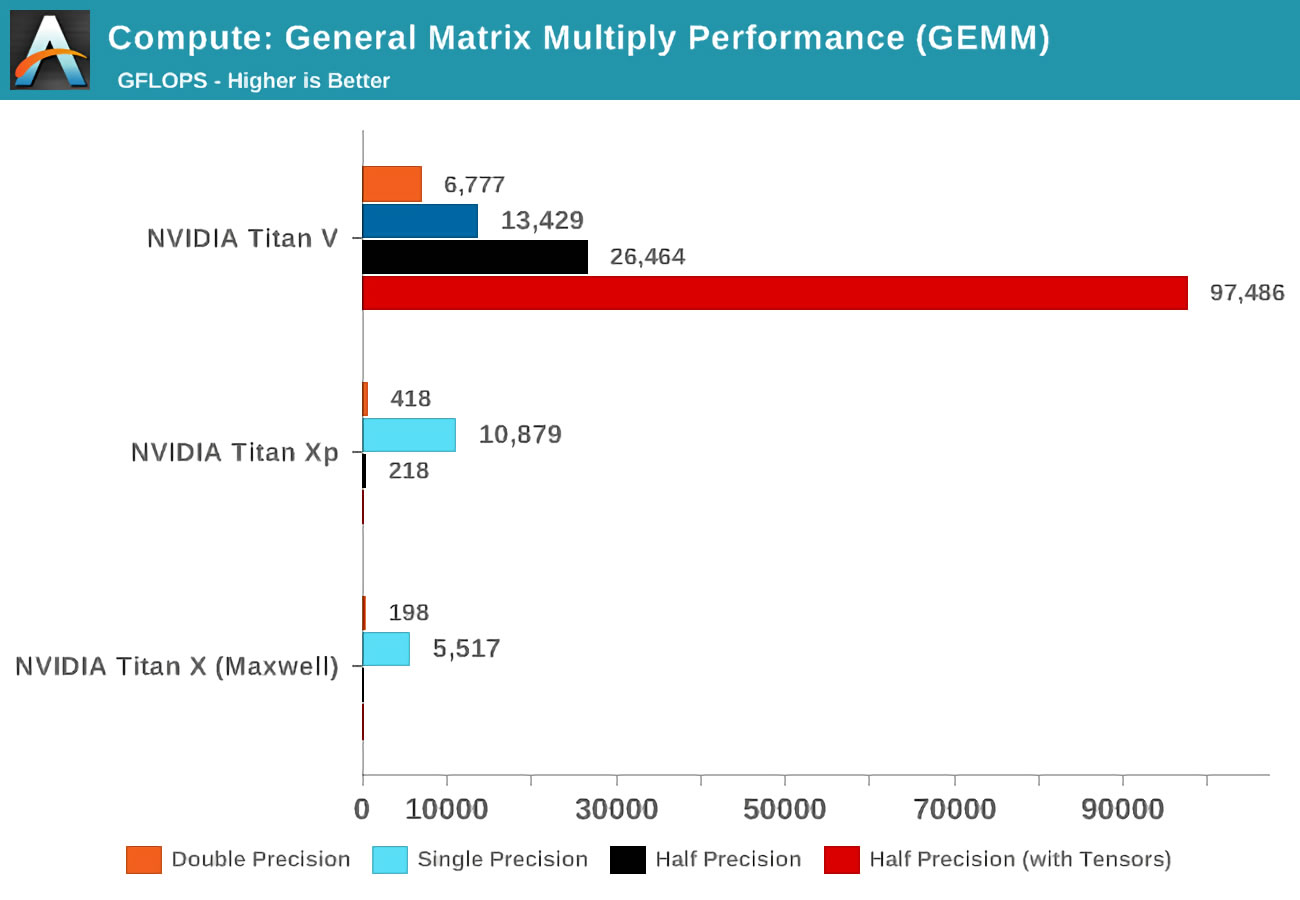
Понятие точности (precision) относится к количеству бит, использованных для чисел с плавающей запятой в матрицах: двойная (double) обозначает 64, одиночная (single) — 32, и так далее. По горизонтальной оси отложено максимальное количество операций с плавающей запятой, выполняемое за секунду, или сокращённо FLOPs (помните, что одна GEMM — это 3 FLOP).
Просто взгляните на результаты при использовании тензорных ядер вместо так называемых ядер CUDA! Очевидно, что они потрясающе справляются с подобной работой, но что же мы можем делать при помощи тензорных ядер?
Графические процессоры не «запускают» программы

Имейте в виду, что графические процессоры не выполняют программы в том виде, в каком мы их знаем, а представляют собой последовательность инструкций. Исключение составляют шейдерные программы, которые работают на ядрах графического процессора.
Программы шейдеров манипулируют наборами данных или графическими примитивами на разных этапах. Но на уровне аппаратной функциональности они представлены в виде ядер.
Ядра, не путать с ядрами операционных систем, представляют собой автономные наборы данных и инструкций, которые также называются потоками в контексте графического процессора.
Тензорные ядра для обычных пользователей (GeForce RTX)
Но что, если я не астрофизик, озабоченный проблемой решения римановых многообразий, и даже не увлекаюсь экспериментами в глубинах сверхточных нейросетей? Мне какой толк от покупки GeForce RTX ?
Может показаться, что вы зря потратили деньги на бесполезную функцию, поскольку тензорные ядра практически не используются для привычного рендеринга и кодирования/ декодирования видео. Однако в 2018 году Nvidia встроила тензорные ядра в свои потребительские продукты (Turing GeForce RTX), одновременно представив DLSS – Deep Learning Super Sampling .
Суть проста: кадр сперва рендерится на пониженном разрешении, а по окончании этого – разрешение увеличивается до исходного размера экрана монитора (например, сперва рендерится на 1080p, а затем изменяется до 1400p). Благодаря этому, повышается производительность, поскольку обрабатывается меньшее количество пикселов, при этом на экране всё равно получается отличная картинка.
Консоли уже многие годы практикуют нечто подобное, и многие современные PC-игры тоже обеспечивают такую возможность. В Assassin's Creed: Odyssey от Ubisoft вы можете изменить разрешение рендеринга до 50% от разрешения монитора. К сожалению, качество картинки ощутимо страдает. Вот так игра выглядит в 4K с максимальными настройками графики:
На высоких разрешениях текстуры выглядят намного лучше, поскольку сохраняют все мелкие детали. Но к сожалению, такое качество требует большого объёма обработки. Что произойдёт,
если игру настроить на рендеринг с разрешением 1080p (в 4 раза меньше пикселей на прорисовку), а затем увеличить до 4К с помощью шейдеров.
Из-за компрессии JPEG и масштабирования на сайте, разница в глаза может не броситься, но видно, что броня на персонаже и скала вдали несколько размыты. Внимательней посмотрим на увеличенный фрагмент:
Изображение слева отрендерено в 4K, а справа – в 1080p с последующим масштабированием до 4K. Разница становится более очевидной в движении, когда алгоритмы смягчения деталей быстро превращают всё в размытую кашу. Частично этого можно избежать с помощью повышения резкости в настройках видеокарты, но это совсем не то, чем бы нам хотелось заниматься.
Здесь и проявляет себя DLSS – Nvidia проанализировала несколько игр в первой версии этой технологии, используя разные разрешения, со сглаживанием и без него. Сгенерированные на разных режимах изображения были загружены в суперкомпьютеры компании, которые с помощью нейросетей искали наилучший вариант превращения изображения 1080p в идеальную картинку с высоким разрешением.
Стоит сказать, что DLSS 1.0 был не идеальным: детали часто терялись или мерцали в некоторых местах. К тому же, он не использовал тензорные ядра вашей видеокарты (это выполнялось сетью Nvidia), и каждая игра, поддерживающая DLSS, должна была быть проанализирована Nvidia для определения наилучшего алгоритма масштабирования для неё.
Когда в начале 2020 года вышла версия 2.0, в нее были внесены серьезные улучшения. Самым примечательным из них было то, что теперь суперкомпьютеры Nvidia использовались только для создания общего алгоритма масштабирования – в новой версии DLSS для обработки пикселей (тензорными ядрами вашего GPU) используются данные из отрендеренного кадра с применением нейронной модели.
Возможности DLSS 2.0 впечатляют, но пока что его поддерживает очень мало игр – на момент написания этой статьи их насчитывалось всего 12. Тем не менее, всё больше разработчиков стремятся реализовать его в своих проектах, и на то есть основания.
Любое масштабирование – это способ заметно повысить производительность, поэтому с полной уверенностью можно утверждать, что DLSS будет продолжать развиваться.
И хотя у DLSS имеются некоторые недочеты визуализации на выходе, высвободив занятые рендерингом ресурсы, разработчики могут добавлять больше эффектов или обеспечивать одинаковый уровень графики для более широкого диапазона платформ.
В частности, DLSS часто сопутствует с трассировкой лучей (ray tracing) в играх «с поддержкой RTX». Графические процессоры GeForce RTX содержат дополнительные вычислительные блоки, называемые RT-ядрами: особые логические блоки для ускорения вычислений пересечения «луч-треугольник» и обхода иерархии ограничивающих объемов (BVH, Bounding Volume Hierarchy). Эти два процесса занимают много времени для определения взаимодействия света с объектами сцены.
Поскольку трассировка лучей – процесс крайне трудоёмкий, разработчики вынуждены ограничивать число лучей и отражений в сцене, чтобы обеспечить приемлемый уровень игровой производительности. Кроме того, в результате этого процесса может появляться зернистость изображения, поэтому необходимо использовать алгоритм шумоподавления, что ещё более усложняет обработку. Ожидается, что тензорные ядра помогут повысить производительность с помощью шумоподавления на основе ИИ, но этому ещё предстоит материализоваться, поскольку большинство современных приложений по-прежнему используют для этих целей ядра CUDA. С другой стороны, имея DLSS 2.0 как перспективную технологию масштабирования, становится возможным эффективно использовать тензорные ядра для увеличения FPS после применения трассировки лучей к сцене.
Известны и другие планы относительно тензорных ядер в картах GeForce RTX, такие как улучшенная анимация персонажей или симуляция тканей. Но, как и в случае с DLSS 1.0, пройдет ещё немало времени, прежде чем появятся сотни игр, обыденно использующие специализированные матричные вычисления на GPU.
Многообещающее начало
Итак, ситуация такова — тензорные ядра, отличные аппаратные блоки, которые, однако, встречаются только в некоторых картах потребительского уровня. Изменится ли что-то в будущем? Так как Nvidia уже значительно улучшила производительность каждого тензорного ядра в своей архитектуре Ampere, есть большая вероятность того, что они будут устанавливаться и в модели нижнего и среднего ценового уровня.
Хотя таких ядер пока нет в GPU компаний AMD и Intel, возможно, в будущем мы их увидим. У AMD есть система повышения резкости или улучшения деталей в готовых кадрах ценой небольшого снижения производительности, поэтому компания, возможно, будет придерживаться этой системы, особенно учитывая то, что её не нужно интегрировать разработчикам, достаточно включить её в драйверах.
Существует также мнение, что пространство на кристаллах в графических чипах лучше было бы потратить на дополнительные шейдерные ядра — так поступила Nvidia при создании бюджетных версий своих чипов Turing. В таких продуктах, как GeForce GTX 1650, компания полностью отказалась от тензорных ядер и заменила их дополнительными FP16-шейдерами.
Но пока, если вы хотите обеспечить сверхбыструю обработку GEMM и воспользоваться всеми её преимуществами, то у вас есть два варианта: купить кучу огромных многоядерных CPU или просто один GPU с тензорными ядрами.
Математика, делающая всё лучше
Тензорные вычисления чрезвычайно полезны в физике и проектировании, они используются для решения всевозможных сложных задач в механике жидкостей, электромагнетизме и астрофизике, однако компьютеры, которые использовались для обработки подобных чисел, обычно выполняли операции с матрицами в больших кластерах из центральных процессоров.
Ещё одна область, в которой любят применять тензоры — это машинное обучение, особенно её подраздел «глубокое обучение». Его смысл сводится к обработке огромных наборов данных в гигантских массивах, называемых нейронными сетями. Соединениям между различными значениями данных задаётся определённый вес — число, выражающее важность конкретного соединения.
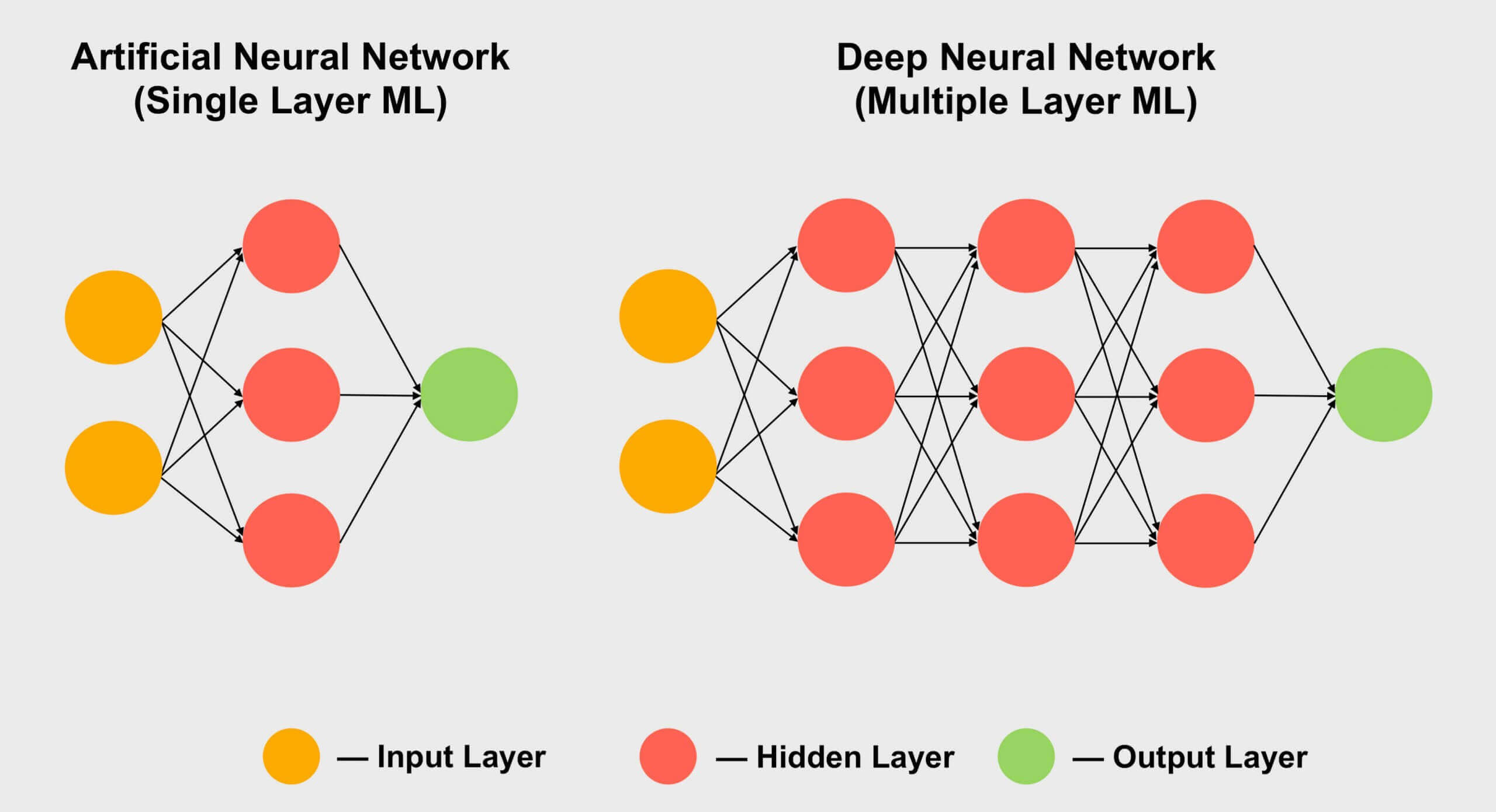
Поэтому когда нам нужно разобраться, как взаимодействуют все эти сотни, если не тысячи соединений, нужно умножить каждый элемент данных в сети на все возможные веса соединений. Другими словами, перемножить две матрицы, а это классическая тензорная математика!

Чипы Google TPU 3.0, закрытые системой водяного охлаждения
Именно поэтому во всех суперкомпьютерах глубокого обучения используются GPU, и почти всегда это Nvidia. Однако некоторые компании даже разработали собственные процессоры из тензорных ядер. Google, например, в 2016 году объявила о разработке своего первого TPU (tensor processing unit), но эти чипы настолько специализированные, что не могут выполнять ничего, кроме операций с матрицами.
Читайте также: