
Что такое тпа в видеокарте
С приходом AMD Radeon RX 5700, новый параметр был представлен в технические характеристики видеокарты что даже не осталось NVIDIA равнодушны, поскольку они тоже поспешили сообщить об этом. Это TGP и в этой статье мы объясним, что это такое, чем оно отличается от TDP и почему вы должны это учитывать.
До сих пор энергопотребление видеокарт было несколько неопределенным из-за NVIDIA, которая начала использовать для обозначения такие сокращения, как TDP. Однако, к счастью, сейчас все изменилось, и NVIDIA, и AMD гораздо более конкретны в этом вопросе, поэтому давайте посмотрим, как TGP имеет отношение ко всему этому.
Turing
Выпуском в 2018 году Turing компания Nvidia произвела свой «крупнейший за десять лет архитектурный шаг вперёд» [13] . В «Turing SM» появились не только специализированные ядра Tensor с искусственным интеллектом, но и ядра для трассировки лучей (rautracing, RT). Такая фрагментированная структура напоминает мне многослойную архитектуру, существовавшую до Tesla, и это ещё раз доказывает, что история любит повторения.
Кроме новых ядер, в Turing появилось три важные особенности. Во-первых, ядро CUDA теперь стало суперскалярным, что позволяет параллельно выполнять инструкции с целыми числами и с числами с плавающей запятой. Если вы застали 1996 год, то это может напомнить вам об «инновационной» архитектуре Pentium компании Intel.
Во-вторых, новая подсистема памяти на GDDR6X, поддерживаемая 16 контроллерами, способна теперь обеспечивать 14 гигафлопс.
В-третьих, потоки теперь не имеют общих указателей инструкций (IP) в warp-е. Благодаря появившейся в Volta диспетчеризации Independent Thread Scheduling, каждый поток имеет собственный IP. В результате этого SM способны гибче настраивать диспетчеризацию потоков в warp-е без необходимости как можно более быстрого их схождения.
Флагманская карта NVIDIA GeForce GTX 2080 Ti с кристаллом TU102 и 68 TSM имеет 4352 и достигает 13 45 гигафлопс [14] . Я не стал рисовать структурную схему, потому что она выглядела бы как размытое зелёное пятно.
Maxwell
В 2014 году Nvidia выпустила GPU десятого поколения под названием Maxwell. Как говорится в технической документации GM107 [8] , девизом первого поколения архитектуры стали «Максимальная энергоэффективность и чрезвычайная производительность на каждый потреблённый ватт». Карты позиционировались для «ограниченных в мощности сред, таких как ноутбуки и PC с малым форм-фактором (small form factor, SFF)».
Важнейшим решением стал отказ от структуры Kepler с количеством ядер CUDA в SM, не являющимся степенью двойки: некоторые ядра стали общими и вернулись в работе в режиме половины warp-ов. Впервые за всю историю архитектуры SMM имел меньше ядер, чем его предшественник: «всего» 128 ядер.
Согласование количества ядер и размера warp-ов улучшило сегментацию кристалла, что привело к экономии площади и энергии.
Один SMM 2014 года имел столько же ядер (128), сколько вся карта GTX 8800 в 2006 году.
Второе поколение Maxwell (описанное в технической документации GM200 [9] ) значительно повысило производительность, сохранив при этом энергоэффективность первого поколения.
Техпроцесс оставался на уровне 28 нанометров, поэтому инженеры Nvidia не могли для повышения производительности прибегнуть к простой миниатюризации. Однако уменьшение количества ядер SMM снизило их размер, благодаря чему на кристалле удалось разместить больше SMM. По сравнению с Kepler, второе поколение Maxwell удвоило количество SMM, при этом всего на 25% увеличив площадь кристалла.
В списке усовершенствований также можно найти упрощённую логику диспетчеризации, позволившую снизить количество избыточных повторных вычислений диспетчеризации и задержку вычислений, что обеспечило повышение оптимальности использования warp-ов. Также на 15% была увеличена частота памяти.
Изучение структурной схемы Maxwell GM200 уже начинает напрягать глаза. Но мы всё равно внимательно его исследуем. Флагманская карта NVIDIA GeForce GTX 980 Ti с кристаллом GM200 и 24 SMM обещала 3072 ядер и 6 060 гигафлопс [10] .
GM200, установленный в GeForce GTX 980 Ti.
Pascal
В 2016 году Nvidia представила Pascal. Техническая документация GP104 [11] оставляет ощущение дежавю, потому что Pascal SM выглядит точно так же, как Maxwell SMM. Отсутствие изменений SM не привело к стагнации производительности, потому что 16-нанометровый техпроцесс позволил разместить больше SM и снова удвоить количество гигафлопс.
Среди других серьёзных улучшений была система памяти, основанная на совершенно новой GDDR5X. 256-битный интерфейс памяти благодаря восьми контроллерам памяти обеспечивал скорости передачи в 10 гигафлопс, увеличив на 43% пропускную способность памяти и снизив время простоя warp-ов.
Флагман NVIDIA GeForce GTX 1080 Ti с кристаллом GP102 и 28 TSM обещал 3584 ядер и 11 340 гигафлопс [12] .
GP104, установленный в GeForce GTX 1080.
Kepler
В 2012 году Nvidia выпустила архитектуру Kepler, названную в честь астролога, наиболее известного открытием законов движения планет. Как обычно, взглянуть внутрь нам позволила техническая документация GK104 [6] .
В Kepler компания Nvidia значительно улучшила энергоэффективность кристалла, снизив тактовую частоту и объединив частоту ядер с частотой карты (ранее их частота различалась вдвое).
Такие изменения должны были привести к снижению производительности. Однако благодаря вдвое уменьшившемуся техпроцессу (28 нанометров) и замене аппаратного диспетчера на программный, Nvidia смогла не только разместить на чипе больше SM, но и улучшить их конструкцию.
Next Generation Streaming Multiprocessor (SMX) — это монстр, почти все показатели которого были удвоены или утроены.
Благодаря четырём диспетчерам warp-ов, способным на обработку целого warp-а за один такт (Fermi мог обрабатывать только половину warp-а), SMX теперь содержал 196 ядер. Каждый диспетчер имел двойную диспетчеризацию, позволявшую выполнять вторую инструкцию в warp-е, если она была независима от текущей исполняемой инструкции. Двойная диспетчеризация была не всегда возможна, потому что один столбец из 32 ядер был общим для двух операций диспетчеризации.
Такая схема усложнила логику диспетчеризации (к этому мы ещё вернёмся), но благодаря выполнению до шести инструкций warp-ов за такт SMX обеспечивал удвоенную производительность по сравнению с SM архитектуры Fermi.
Заявлялось, что флагманская NVIDIA GeForce GTX 680 с кристаллом GK104 и восемью SMX имеет 1536 ядер, достигающими 3 250 гигафлопс [7] . Элементы кристалла стали настолько запутанными, что мне пришлось убрать со схемы все подписи.
GK104, установленный в GeForce GTX 680.
Обратите внимание на полностью переделанные подсистемы памяти, работающие с захватывающей дух частотой 6 ГГц. Они позволили снизить количество контроллеров памяти с шести до четырёх.
Что такое майнинг?
Возьмем в качестве примера блокчейн биткоина. Если максимально упростить, то вычислительные мощности майнинговых компьютеров направлены на шифрование операций по переводу биткоинов с одного кошелька на другой.
Как это выглядит?
Предположим, Сатоши Бутерин со своего кошелька переслал 1 биткоин на кошелек Виталика Накамото. Согласно сути блокчейна, нужно зашифровать информацию, содержащую адреса кошельков Сатоши и Виталика, а также количество переведенных биткоинов. Тут в дело вступает майнинговое оборудование — ему нужно найти правильный вариант шифровки.
Согласно алгоритму хеширования SHA-256, на котором построен блокчейн биткоина, сделать это нужно строго определенным способом. Например, алгоритм предписал зашифровать информацию так, чтобы на конце шифрованной строки был ноль. Подобное требование исходит от разработчиков криптовалюты — им нужен шифр с определенным символом, чтобы повысить устойчивость к взлому.
«Железо» начинает работать — решать эту математическую задачу методом подбора. Информация «Satoshi Buterin wallet ---> 1 BTC ---> Vitalik Nakamoto wallet» превращается в зашифрованную строку вроде «dh523456l29e4f6ab42d99c81156d3a17228d6e1eef4139be78dgw5jh63f2348». Но в этом варианте на конце не стоит ноль. Тогда «железо» начинает подбирать новый вариант шифровки, добавляя в информацию символ, который не меняет ее смысл.

Едва только нужная комбинация шифровки найдена, она записывается в базу данных (блокчейн), а конкретнее — в небольшой кусочек этой базы данных, который называется блоком.
Блокчейн — это база данных, которая по сути является журналом транзакций. Основные его идеи, заложенные разработчиками:
- пусть будет единый журнал транзакций;
- пусть копия журнала будет у всех;
- все записи журнала будем шифровать, чтобы не достались врагу;
- разобьем журнал на блоки, а блоки свяжем в цепочки.
Разработчики блокчейна биткоина определили, что максимальный размер блока не может превышать ~1 Мб. И чтобы блок считался сформированным, его нужно заполнить зашифрованными записями транзакций. Как только блок сформирован, блокчейн автоматически генерирует эмиссионную транзакцию биткоинов, чтобы наградить майнера за его работу.
Но не стоит думать, что можно просто взять и спокойно перебрать тысячу комбинаций, найдя нужную. Над одной задачей может «трудиться» не один десяток, или даже не одна сотня мощностей. И кто окажется первым, «того и тапки». Получается, что чем больше у тебя вычислительная мощность, тем выше шанс первым найти нужный вариант шифровки.
Но один человек-майнер может формировать отдельный блок на своем компьютере очень долго. Вряд ли кого-то обрадует перспектива майнить несколько лет без перерыва, формируя один-единственный блок, и получить потом за него 12,5 биткоинов в награду (именно такое количество биткоинов сейчас выдается за формирование нового блока). Поэтому люди объединяют свои мощности в пулы. В этом случае сеть биткоина выделяет награду за сформированные блоки не отдельному майнеру, а пулу. Пул, в свою очередь, распределяет награды отдельным майнерам, в соответствии с потраченным временем и мощностью (за вычетом комиссии).
Тупик
Вплоть до 2006 года архитектура GPU компании NVidia коррелировала с логическими этапами API рендеринга [2] . GeForce 7900 GTX, управлявшаяся кристаллом G71, состояла из трёх частей, занимавшихся обработкой вершин (8 блоков), генерацией фрагментов (24 блоков), и объединением фрагментов (16 блоков).
Кристалл G71. Обратите внимание на оптимизацию Z-Cull, отбрасывающую фрагмент, не прошедший бы Z-тест.
Эта корреляция заставила проектировщиков угадывать расположение «узких места» конвейера для правильной балансировки каждого из слоёв. С появлением в DirectX 10 ещё одного этапа — геометрического шейдера, инженеры Nvidia столкнулись со сложной задачей балансировки кристалла без знания того, насколько активно будет использоваться этот этап. Настало время для перемен.
Термопаста для видеокарты
Графические процессоры, как и другие электронные компоненты, нуждаются в эффективном отводе тепла. Термоинтерфейсы, использующиеся в кулерах ГПУ, обладают теми же свойствами, что и пасты для центральных процессоров, поэтому для охлаждения видеокарты можно использовать «процессорную» термопасту.
Продукты разных производителей отличаются по составу, теплопроводности и, конечно же, цене.
Состав
По составу пасты делятся на три группы:
- На основе силикона. Такие термопасты являются наиболее дешевыми, но и менее эффективными.
- Содержащие серебро или керамическую пыль обладают меньшим тепловым сопротивлением, чем силиконовые, но стоят дороже.
- Алмазные пасты – самые дорогие и эффективные продукты.
Fermi
Tesla была рискованным ходом, оказавшимся очень успешным. Она была настолько успешной, что стала фундаментом для GPU компании NVidia на следующие два десятка лет.
«Хотя с тех пор мы, конечно же, внесли серьёзные архитектурные изменения (Fermi была серьёзным изменением архитектуры системы, а Maxwell стал ещё одним крупным изменением в проектировании процессоров), фундаментальная архитектура, представленная нами в G80, и сегодня осталась такой же [Pascal]».
В 2010 году Nvidia выпустила GF100, основанный на совершенно новой архитектуре Fermi. Внутренности её последнего чипа подробно описаны в технической документации Fermi [4] .
Модель выполнения по-прежнему основана на warp-ах из 32 потоков, диспетчеризируемых в SM. NVidia удалось удвоить/учетверить все показатели только благодаря 40-нанометровому техпроцессу. Благодаря двум массивам из 16 ядер CUDA, SM теперь мог одновременно диспетчеризировать два полу-warp-а (по 16 потоков). При том, что каждое ядро выполняло по одной инструкции за такт, SM по сути был способен исключать по одной инструкции warp за такт (в четыре раза больше, чем у SM архитектуры Tesla).
Количество SFU также увеличилось, однако не так сильно — мощность всего лишь удвоилась. Можно прийти к выводу, что инструкции такого типа использовались не очень активно.
Присутствует полуаппаратная поддержка float64, при которой комбинируются операции, выполняемые двумя ядрами CUDA. Благодаря 32-битном АЛУ (в Tesla оно было 24-битным) GF100 может выполнять целочисленное умножение за один такт, а из-за перехода от IEEE 754-1985 к IEEE 754-2008 имеет повышенную точность при работе с конвейером float32 при помощи Fused Multiply-Add (FMA) (более точного, чем используемое в Tesla MAD).
С точки зрения программирования, объединённая система памяти Fermi позволила дополнить CUDA C такими возможностями C++, как объект, виртуальные методы и исключения.
Благодаря тому, что текстурные блоки стали теперь SM, от концепции TPC отказались. Она была заменена кластерами Graphics Processor Clusters (GPC), имеющими по четыре SM. И последнее — SM теперь одарён Polymorph Engine, занимающимся получением вершин, преобразованием окна обзора и тесселяцией. Карта-флагман GeForce GTX 480 на основе GF100 рекламировалась, как содержащая 512 ядер и способная обеспечить 1 345 гигафлопс [5] .
GF100, установленный в GeForce GTX 480. Обратите внимание на шесть контроллеров памяти, обслуживающих GPC.
Для чего нужно знать TDP видеокарты
Если вы не заинтересованы в поломке вашего видеоадаптера от перегрева, необходимо подыскивать себе девайс с приемлемым уровнем и типом охлаждения. Вот тут-то незнание о TDP может стать фатальным, ведь именно этот параметр помогает определить необходимый графическому чипу способ охлаждения.
Количество выделяемого видеоадаптером тепла производители указывают в ваттах. Обязательно необходимо обратить внимание на установленное в неё охлаждение — это один из решающих факторов продолжительности и бесперебойности работы вашего устройства.
Графическим адаптерам с низким потреблением энергии и, соответственно, малым выделением тепла, подойдёт одно лишь пассивное охлаждение в виде радиаторов и/или медных, а также металлических трубок. Решениям помощнее, вдобавок к пассивному отводу тепла, потребуется ещё и активное охлаждение. Чаще всего оно предоставляется в виде кулеров с разными возможными размерами вентилятора. Чем длиннее вентилятор и чем выше показатель совершаемых оборотов в минуту, тем больше тепла он способен рассеять, но это может сказываться на громкости его работы.

Для топовых графических решений в разгоне может потребоваться ещё и водяное охлаждение, но это крайне недешёвое удовольствие. Обычно такими вещами занимаются только оверклокеры — люди, специально разгоняющие до предела видеокарты и процессоры, чтобы запечатлеть этот результат в истории оверклокинга и протестировать оборудование в экстремальных условиях. Тепловыделение в таких случаях может стать колоссальным и потребуется прибегнуть даже к жидкому азоту для охлаждения своих разгонных стендов.

Предназначение TDP видеоадаптера
Конструктивные требования производителя по теплоотводу указывают нам на то, какое количество тепла способна выделить видеокарта при каком-нибудь виде нагрузки. От производителя к производителю этот показатель может разниться.
Кто-то замеряет тепловыделение во время выполнения достаточно тяжёлых и специфичных задач, например, рендеринга долгого видеоролика со множеством спецэффектов, а какой-то производитель может просто указать значение тепла, выделяемого устройством во время просмотра FullHD-видео, сёрфинга в сети или при обработке прочих тривиальных, офисных задач.
При этом производитель никогда не будет указывать значение TDP видеоадаптера, который он даёт во время тяжёлого синтетического теста, допустим, от 3DMark, созданного специально для того, чтобы «выжимать» всю энергию и производительность из компьютерного железа. Аналогично, не будут указаны показатели во время процесса майнинга криптовалюты, но только в том случае если производитель нереференсного решения не выпустил данный продукт специально под нужды майнеров, ведь логично указывать тепловыделение во время типичных и рассчитанных для такого видеоадаптера нагрузок.

Свойства
Если состав термоинтерфейса нас, как пользователей, не особо интересует, то способность проводить тепло волнует гораздо больше. Основные потребительские свойства пасты:
- Теплопроводность, которая измеряется в Ваттах, деленных на м*К (метр-кельвин), Вт/м*К. Чем выше эта цифра, тем эффективнее термопаста.
- Диапазон рабочих температур определяет значения нагрева, при которых паста не потеряет своих свойств.
- Последнее важное свойство – проводит ли термоинтерфейс электрический ток.
Определение TDP видеокарты
Узнать значение данной характеристики можно при помощи двух сайтов, на которых собран каталог графических чипов и их характеристик. Один из них поможет вам определить все известные параметры устройства, а второй — только TDP собранных в его каталоге видеоадаптеров.
Этот сайт является интернет-супермаркетом компьютерной техники и с помощью поиска по нему можно найти значение TDP для интересующего нас девайса.
- В левом верхнем углу сайта находим меню для ввода поискового запроса. Нажимаем на него и вводим название нужной нам видеокарты. Нажимаем на кнопку «Поиск» и вслед за этим попадаем на страницу, выведенную по нашему запросу.
- В открывшейся странице выбираем нужную нам разновидность устройства и нажимаем по ссылке с его названием.
- Катим вниз ползунок страницы продукта, пока не увидим заголовок таблицы с характеристиками видеокарты, который будет выглядеть по такому шаблону: «Характеристики Название_видеокарты». Если вы обнаружили такой заголовок, значит вы делаете всё верно и остался последний, следующий шаг данной инструкции.
- Перетаскиваем ползунок дальше вниз, пока не увидим сегмент таблицы, который называется «Питание». Под ним вы увидите ячейку «Потребление энергии», которая и будет являться значением TDP выбранной вами видеокарты.
Этот зарубежный сайт посвящён обзорам техники, видеокарт в том числе. Поэтому редакция данного ресурса составила список видеокарт с их показателями тепловыделения с ссылками на собственные обзоры приведённых в таблице графических чипов.
- Переходим по ссылке выше и попадаем на страницу с таблицей значений TDP множества различных видеокарт.
- Для ускорения поиска нужной видеокарты нажимаем на сочетание клавиш «Ctrl+F», которое позволит произвести нам поиск по странице. В появившемся поле введите название модели вашей видеокарты и браузер сам перебросит вас к перовому упоминанию введённого словосочетания. Если по какой-либо причине не удаётся воспользоваться данной функцией, вы всегда можете просто прокрутить страницу, пока не наткнётесь на требуемую видеокарту.
- В первом столбце вы увидите название видеоадаптера, а во втором — числовое значение выделяемого им тепла в ваттах.
Теперь вы знаете, чем важен показатель TDP, что он значит и как его определить. Надеемся, что наша статья помогла вам узнать необходимую для вас информацию или просто подтянула уровень вашей компьютерной грамотности.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Чем TDP отличается от TGP?
TDP происходит от английской аббревиатуры Thermal Design Power (также известной как Thermal Design Point и Thermal Design Parameter) и относится к количеству тепла, которое теплоотвод графической карты должен уметь рассеивать на основе тепла, генерируемого графическим процессором. Например, 100 Вт TDP означает, что графический приемник должен быть спроектирован таким образом, чтобы рассеивать такое количество тепла, и не отражает потребление графическим процессором.
Однако теперь и AMD, и NVIDIA используют его вопреки тому, что происходит в радиаторах процессора, чтобы выразить потребление только графическим процессором.
В итоге, вот условия, которые мы можем найти:
- TDP: Расчетная тепловая мощность, количество тепла, которое теплоотвод должен уметь рассеивать. В графике они используют его для выражения потребления только графического процессора, а не графики в целом.
- ТГП: Total Graphics Power, общее энергопотребление видеокарты.
- ТВР: Общая мощность платы, эквивалентная предыдущей.
- ГПК: Видеокарта Power, эквивалентная предыдущим.
- ПДК: Максимальная потребляемая мощность В некоторых случаях мы можем видеть этот термин, и он относится к пиковой мощности, которую он потребляет максимум.
В общем, NVIDIA продолжает неохотно им пользоваться. Например, в Техническом документе графики архитектуры Тьюринга он продолжает выражать его в TDP, но затем указывает, что это относится только к потреблению графического процессора.

Итак, теперь, когда вы смотрите на спецификации видеокарты, вы должны знать, что TDP относится только к потреблению графического процессора, а если они указывают на TGP, то это общее потребление графики.
Последние выходные я потратил на освоение программирования CUDA и SIMT. Это плодотворно проведённое время закончилось почти 700-кратным ускорением моего «рейтрейсера на визитке» [1] — с 101 секунд до 150 мс.
Такой приятный опыт стал хорошим предлогом для дальнейшего изучения темы и эволюции архитектуры Nvidia. Благодаря огромному объёму документации, опубликованному за долгие годы «зелёной» командой, мне удалось вернуться назад во времени и вкратце пройтись по удивительной эволюции её потоковых мультипроцессоров.
В этой статье мы рассмотрим:
Что такое TGP видеокарты?
TGP является аббревиатурой на английском языке для ” Общая графическая мощность «, Или« общее потребление графики », если перевести это на испанский язык. Фактически, это потребляемая мощность. GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР видеокарты, и она пришла на смену способу, которым мы определяли до сих пор TDP. Его еще называют ТБФ для «Общая мощность платы» или «Типичная мощность платы» в случае графики AMD, и определяет общее потребление графики включая GPU, память, VRM и т. д.
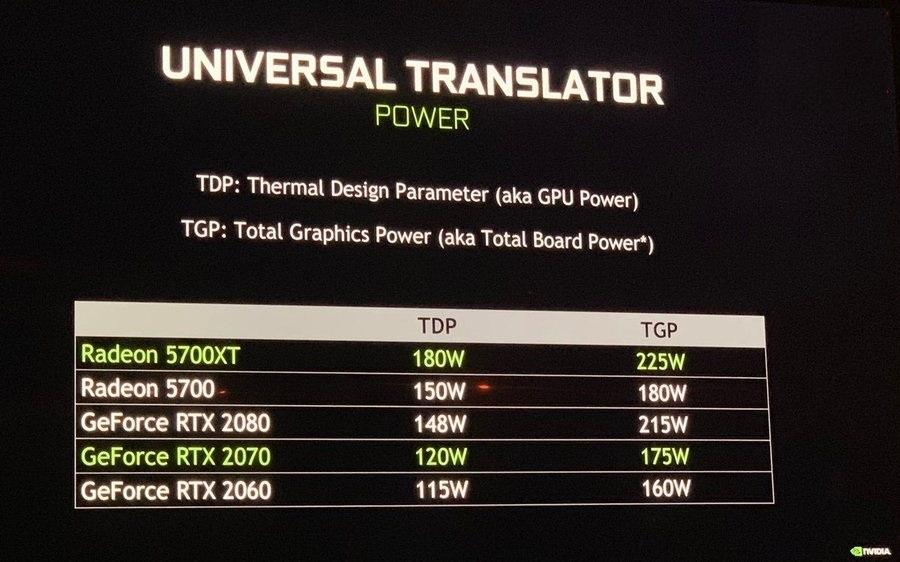
Поэтому, когда мы смотрим, какой источник питания является наиболее подходящим для нашей системы с учетом графической карты, параметр, который мы должны принять во внимание, - это TGP, а не TDP, поскольку именно он сообщит нам общий расход устройства. И, как мы говорили, сейчас оба производителя уже указывают это в своих технических характеристиках, даже в профессиональном ассортименте.
Tesla
Nvidia решила проблему роста сложности при помощи «объединённой» архитектуры Tesla, выпущенной в 2006 году.
В кристалле G80 больше не было различий между слоями. Благодаря возможности выполнения вершинного, фрагментного и геометрического «ядра», потоковый мультипроцессор (Stream Multiprocessor, SM) заменил все существовавшие ранее блоки. Уравновешивание нагрузки выполнялось автоматически, благодаря замене выполняемого каждым SM «ядра» в зависимости от требований конвейера.
«Фактически, мы выбросили всю шейдерную архитектуру NV30/NV40 и с нуля создали новую, с новой общей архитектурой универсальных процессоров (SIMT), в которой также были введены новые методологии проектирования процессоров».
Больше не имеющие возможности выполнять инструкции SIMD «блоки шейдеров» превратились в «ядра», способные выполнять по одной целочисленной инструкции или по одной инструкции с float32 за такт. SM получает потоки в группах по 32 потока, называемых warp. В идеале все потоки одного warp выполняют одновременно одну и ту же инструкцию, только для разных данных (отсюда и название SIMT). Многопотоковый блок инструкций (Multi-threaded Instruction Unit, MT) занимается включением/отключением потоков в warp-е в случае, если их указатель инструкций (Instruction Pointer, IP) сходится/отклоняется.
Два блока SFU помогают выполнять сложные математические вычисления, например, обратный квадратный корень, sin, cos, exp и rcp. Эти блоки также способны выполнять по одной инструкции за такт, но поскольку их только два, скорость выполнения warp-а делится на четыре. Аппаратная поддержка float64 отсутствует, вычисления выполняются программно, что сильно влияет на скорость выполнения.
SM реализует свой максимальный потенциал, когда способен скрывать задержки памяти благодаря постоянному наличию диспетчеризируемых warp-ов, но также когда поток в warp-е не отклоняется (управляющая логика удерживает его на одном пути выполнения инструкций). Состояния потоков хранятся в 4-килобайтных файлах регистров (Register File, RF). Потоки, занимающие слишком большое пространство в стеке, снижают количество возможных потоков, которые могут выполняться одновременно, понижая при этом производительность.
Кристаллом-флагманом поколения Tesla был 90-нанометровый G80, представленный в GeForce 8800 GTX. Два SM объединены в кластер обработки текстур (Texture Processor Cluster, TPC) вместе с текстурным блоком (Texture Unit) и кешем Tex L1. Обещалось, что G80 с 8 TPC и 128 ядрами генерирует 345,6 гигафлопс [3] . Карта 8800 GTX была в своё время чрезвычайно популярна, она получила замечательные отзывы и полюбилась тем, кто мог себе её позволить. Она оказалась таким превосходным продуктом, что спустя тринадцать месяцев после выпуска оставалась одним из самых быстрых GPU на рынке.
G80, установленный в 8800 GTX. Render Output Units (ROP) занимаются выполнением сглаживания.
Вместе с Tesla компания Nvidia представила язык программирования C для Compute Unified Device Architecture (CUDA) — надмножество языка C99. Это понравилось энтузиастам GPGPU, приветствовавшим альтернативу обмана GPU при помощи текстур и шейдеров GLSL.
Хотя в этом разделе я в основном рассказываю о SM, это была только одна половина системы. В SM необходимо передавать инструкции и данные, хранящиеся в памяти GPU. Чтобы избежать простоев, GPU не пытаются минимизировать переходы в память при помощи больших кешей и прогнозирования, как это делают CPU. GPU пользуются задержкой, насыщая шину памяти для удовлетворения потребностей ввода-вывода тысяч потоков. Для этого кристалл (например, G80) реализует высокую пропускную способность памяти при помощи шести двусторонних шин памяти DRAM.
GPU пользуются задержками памяти, в то время как CPU скрывают их при помощи огромного кеша и логике прогнозирования.
Почему именно видеокарты, а не CPU?
Архитектуры графического процессора (GPU) и центрального процессора (CPU) сильно отличаются. Современные CPU состоят из 4-8 ядер — это делает их подходящими для решения больших и сложных задач. Вдобавок при такой архитектуре они могут быстро переключаться с выполнения одной задачи на выполнение другой.
А графические процессоры были созданы для того, чтобы решать огромное множество небольших и несложных задач. Поэтому они состоят не из пары больших ядер, а из тысяч маленьких ядрышек. В таком виде им гораздо удобнее обрабатывать миллионы пикселей и полигонов. Но выполнять сложные задачи, вдобавок переключаясь от одной к другой — чересчур сложно для GPU.

Создатели видеокарт изначально стремились к улучшению изображения и его обработки в компьютерных играх. И они точно не ожидали, что подобная архитектура их графических процессоров как нельзя лучше подойдет для майнинга.
Ведь что такое майнинг? Это перебор сотен тысяч различных комбинаций для шифровки, различающихся по сути только одним символом. С такой однотипной несложной работой куда быстрее справляются тысячи ядер GPU, чем 4-8 умных, но малочисленных ядер CPU.
Для сравнения: ядро CPU обрабатывает восемь 32-битных инструкций за такт (AVX). А процессор видеокарты Radeon HD 5970 обрабатывает 3200 32-битных инструкций за такт.
Но есть устройства, на которых майнинг происходит еще быстрее — их называют ASIC.
В переводе с английского application-specific integrated circuit означает «интегральная схема специального назначения». Это оборудование, которое сделано с целью решения строго конкретной задачи. Если говорить об ASIC для майнинга, то по сути это «все в одном»: блок питания, охлаждающее устройство и небольшая плата, на которой расположены CPU, ПЗУ, ОЗУ и другие блоки. И если видеокарты изначально не были созданы для майнинга, то подобное железо «заточено» именно под эту задачу.
Возьмем в качестве примера популярную у добытчиков биткоина видеокарту AMD Radeon RX 580. Стоит она порядка 26 000 р., и мощность ее майнинга составляет 1,5 GH/s. Поставим против нее ASIC AntMiner R4: при стоимости в ~100 000 р. его мощность составляет 8,7 TH/s. Разница очевидна.

AntMiner R4
Причем производители майнинговых ASIC создают их для добычи определенной криптовалюты. Они подбирают компоненты и настраивают софт в асике таким образом, чтобы он лучше всего справлялся с решением задач по конкретному алгоритму, на котором построена конкретная криптовалюта (например, SHA-256 для майнинга биткоина). То есть, в теории асик для биткоина можно использовать для майнинга другой криптовалюты, но его производительность в таком случае не будет впечатлять.
Но если видеокарту потом можно воткнуть в компьютер и спокойно играть с ее помощью в различные игры, то с ASIC такого сделать нельзя — на них устанавливают сильно упрощенные операционные системы, чьи способности «заточены» специально для добычи криптовалют.
Мы представили майнинг на примере биткоина в упрощенном виде и постарались объяснить его наиболее понятным способом. Следует отметить, что для разных криповалют больше подойдут видеокарты от разных изготовителей: одной больше подойдет Nvidia, а для другой лучшим решением будет AMD. Так получается из-за того, что криптовалюты построены на разных алгоритмах: с каждым конкретным лучше всего справляется та видеокарта, чьи конструктивные особенности лучше всего подходят.

Термопаста (термоинтерфейс) – многокомпонентная субстанция, призванная улучшить передачу тепла от чипа к радиатору. Эффект достигается заполнением неровностей на обеих поверхностях, наличие которых создает воздушные прослойки, обладающие высоким тепловым сопротивлением, а значит, и низкой теплопроводностью.
В этой статье поговорим о видах и составах термопаст и выясним, какую пасту лучше использовать в системах охлаждения видеокарт.
Выбор термопасты
При выборе термоинтерфейса необходимо руководствоваться свойствами, приведенными выше, и конечно, бюджетом. Расход материала достаточно невелик: тюбика, весом 2 грамма, хватит на несколько применений. При необходимости менять термопасту на видеокарте один раз в 2 года, это совсем немного. Исходя из этого, можно приобрести более дорогой продукт.
Если же вы занимаетесь масштабным тестированием и часто демонтируете системы охлаждения, то имеет смысл взглянуть на более бюджетные варианты. Ниже приведем несколько примеров.
- КПТ-8.
Паста отечественного производства. Один из самых дешевых термоинтерфейсов. Теплопроводность 0.65 – 0.8 Вт/м*К, рабочая температура до 180 градусов. Вполне подойдет для использования в кулерах маломощных видеокарт офисного сегмента. В силу некоторых особенностей требует более частой замены, примерно один раз в 6 месяцев.
Данная термопаста является токопроводящей, поэтому не стоит допускать ее попадания на элементы платы. Вместе с тем, производитель позиционирует ее как не засыхающую.
Цены на Arctic Cooling достаточно высоки, но они оправданы высокими показателями.
Наиболее распространенными являются Deepcool Z3, Z5, Z9, Zalman серии ZM, Thermalright Chill Factor.
Крайне не рекомендуется использовать жидкий металл в кулерах, имеющих алюминиевую подошву. Многие пользователи сталкивались с тем, что термоинтерфейс разъедал материал системы охлаждения, оставляя на нем довольно глубокие каверны (рытвины).
Сегодня мы поговорили о составах и потребительских свойствах термоинтерфейсов, а также о том, какие пасты можно найти в розничной продаже и их отличиях.
Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Еще статьи по данной теме:
Добрый день можно такой вопрос у меня амд saphir r7360 в играх выше 75 градусов не бывает но проверял msi avtobyrner до ходило 90 проверял на стабильность в Аида 64 75 я бы хотел узнать карта перегреваеться или в норме? можете посоветовать какую термопасту раньше пользовался кпт 8 продавец посоветовал hy 410 спасибо
Бессмысленная статья, производители по-разному замеряют теплопроводность, реальных тестов не приведено, а некоторые пасты ещё и ведут себя по-разному на процессорах и на картах. Название максимум «о видах термопаст» можно сделать, не более
Соглашусь. А шутку про «смена акрктик mx-4 раз в пол года» я вообще не понял.
Я мх4 обновляю раз в год на процессоре и видеокарте, по своим местам скажу так, на процессоре пасты хватает максимум на 2 года( хорошие температуры) если далее использовать то будет повышаться. На видеокарте год, далее поднимается но через 2 года эксплуатации вентиляторы уже по 80-90% и темпер в норме. Раз в год мх4 я считаю нормальным менять, но раз в 6 месяцев, это уже роскошь
Есть ли реальные сроки годности у термопаст или в закрытых упаковках могут храниться годами?
Не информативно сказки про феноменальное охолождения жидкого металла.
Задайте вопрос или оставьте свое мнение Отменить комментарий

TDP (Thermal Design Power), а по-русски «требования по теплоотводу», является очень важным параметром, который необходимо держать в голове и обращать на него пристальное внимание при подборе комплектующего для компьютера. Больше всех электричества в ПК потребляют центральный процессор и дискретный графический чип, проще говоря, видеокарта. Прочитав эту статью вы узнаете, как определить TDP вашего видеоадаптера, почему этот параметр важен и на что он влияет. Приступим!
Что ждёт нас дальше
По слухам, следующая архитектура под кодовым названием Ampere будет объявлена в 2020 году. Так как Intel доказала на примере Ice Lake, что по-прежнему существует потенциал миниатюризации при помощи 7-нанометрового техпроцесса, почти нет сомнения в том, что Nvidia использует его для дальнейшего уменьшения SM и удвоения производительности.
Интересно будет посмотреть, как Nvidia продолжит эволюцию идеи кристаллов, имеющих три типа ядер, выполняющих разные задачи. Увидим ли мы кристаллы, целиком состояние из Tensor-ядер или RT-ядер? Любопытно.

Что представляет собой майнинг? Почему для майнинга криптовалют в подавляющем большинстве случаев лучше подходят видеокарты, а не CPU? Чем так хороши асики? В этом посте я постарался понятным языком рассказать об основах технической стороны майнинга.
Для понимания общей картины информация дана в упрощенном виде, некоторые детали опущены.
Читайте также: